Recently with the explosive growth of the amount of content on the Internet, it has become increasingly difficult for users to search and utilize information. Content providers it is also difficult to classify and understand their user’s need. The traditional web search engines often return hundreds or thousands of results for a search, which is time consuming for users to browse. Thus, the process of handling multiple data by multiple users can be time consuming and not efficient.
Basically, there are three types of information that need to be handled in a web site: content, structure and log data (Batista
Web usage mining can be defined as automatic discovery and analysis of pattern of user access from web server (Cooley
In this paper, we present on the task of prepro-cessing in query log of web usage mining. For this project, we will use query logs from an online news-pa-per company. The query logs will undergo pre-proce-ssing stage, in which the clickstream data is cleaned and partitioned into a set of user interactions which will represent the activities of each user during their visits to the site. The rest of the paper is organized as follows: In section 2, we review some literatures in web usage min-ing and web log. Section 3 describes the implementation of preprocessing process which includes the preproces-sing algorithm. Results are shown in section 4 and section 5 acknowledge persons that permitting us to use the web server logs for the purpose of this study and finally section 6 summarizes the paper and future work.
Recently, many researchers are interested in web usage mining area. Web mining is the process of extracting knowledge from artifacts and activity related to World Wide Web (Cooley
According to Cooley
A Web server log is an important source for performing Web Usage Mining because it explicitly records the browsing behavior of site visitors. The data recorded in server logs reflects the access of a Web site by multiple users (Markellou
3. DATA PREPARATION AND PREPROCESSING
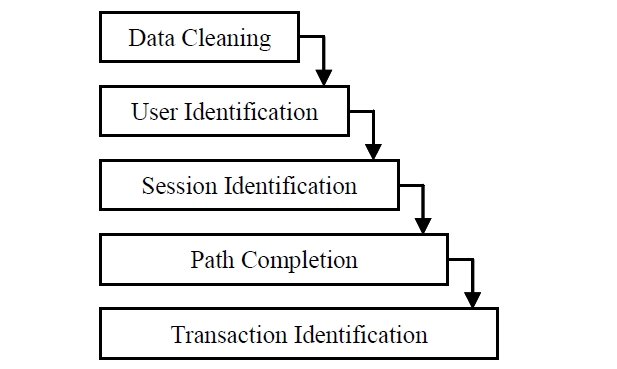
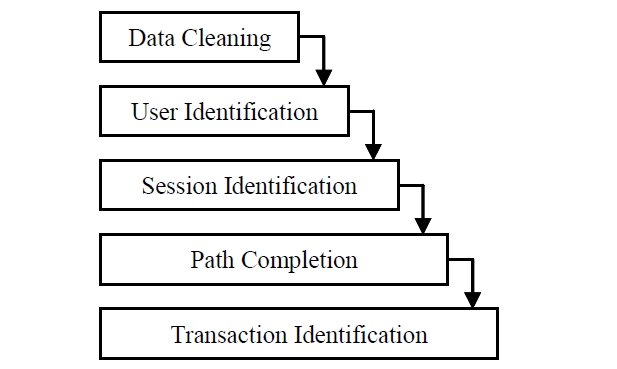
Basically, several pre processing tasks need to be done before implementing web mining algorithm on web server logs. There are five preprocessing tasks as illustrated in Figure 2. The tasks are data cleaning, user identification, session identification, path completion and transaction identification (Cooley
Step 1: Format the data. The data is retrieved from Nginx web server. It does not follow the conventional Common Log File (CLF) and Extended Log File (ELF) format.
Step 2: Remove image files such as .jpg, .gif, .css and all folders contain images
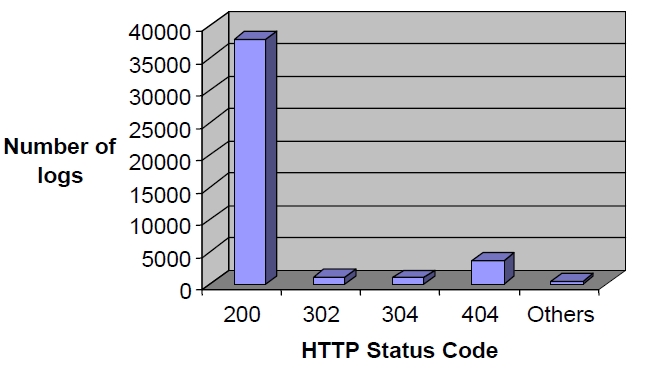
Step 3: Remove HTTP status code other than 200. Status code 200 denotes as the request is successful. Other HTTP status codes found are 302, 304 (Not modified) and 404 (Not found).
Step 4: Remove request method other than GET and POST. HEAD request method is considered irrelevant because it returns only headers in answer without content (Nicholas et al., 2004). Other request method such as PUT, DELETE, TRACE, CONNECT may contain bad request, properties of the server or visits of robots.
After the data has gone through extensive data cleaning, the next step is to identify user. A user can be defined as someone trying to access the web pages from the web server. In this paper, the following rules are observed (Dixit and Gadge, 2010).
New IP address indicates new user
If there is same IP Address, but the log files show different user agent, it represents new user.
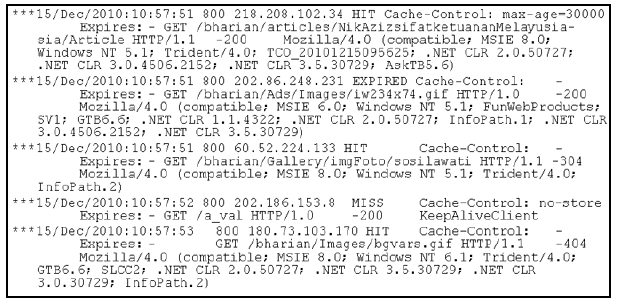
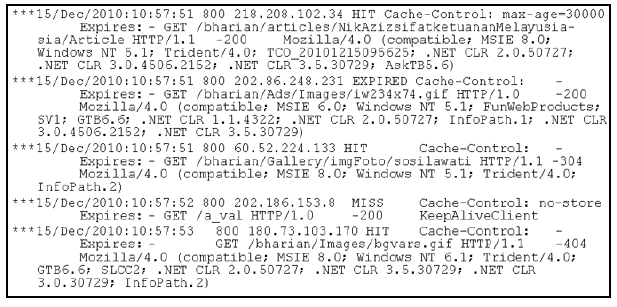
Berita Harian uses cache server to expedite service requests by clients. This can be achieved because the cache server keeps local copies of frequently requested resources. If a user re-request the same data from the server, the cache re-send the same answer without requesting the server. The goal of caching to eliminate the need to send requests in many cases, and to eliminate the need to send full responses in many other cases. In web server logs, the cache status is either indicated by HIT, MISS, EXPIRED, UPDATING or STALE. HIT means that the page requested is available in the cache; MISS means that the request in not available in cache and to be read from the web server, EXPIRED happens when the cache age has expired. The use of cache server may cause problems of underreporting of site traffic, loss of referring site information and identifying site’s usage. Proxy level caching could also cause a single request to be viewed by multiple users throughout an extended period of time. Consequently, user session identification will be difficult, because it is an arduous task to determine when the user’s session is actually over (Srivastava
3.3 Preprocessing Algorithm
The following is the extract of algorithm for preprocessing, done in Python 2.6. The web server logs are given to us are in the .tar format. The first step taken was to compile the web server logs based on the format. Most log files have their own unique characteristics format. As for this web server logs, we standardized the format according to date, time, time zone, IP address, cache status and cache control. Once the format is ready, we search the HTTP request based on Nginx HTTP log, which are method, path, protocol, status and browser. Then, the first stage of preprocessing of data cleaning; remove unnecessary image files. Here, we used regular expressions to remove all image files in the page request. Sometimes, the images are saved in folders, because Berita Harian always have gallery of images for their special content such as election pages, special events like Election, World Cup, images for button ads and many more. Once the images have been removed, the .tar file is parsed and put into a new database. The last step is to display the results in graph. The results are divided to status codes, cache status, HTTP method, browser and operating system of users.
Step 1: Compile the log file based on format desired; which is date, time, time zone, IP address, ca-che status and cache control

Step 2: Search HTTP request based on Nginx HTTP log; which is method, path, protocol, status and browser.

Step 3: Define the regular expressions to remove all images in the page request

Step 4: Read the log files. The log files is in the format of .tar

Step 5: Put each entry of log file into database named as totallog
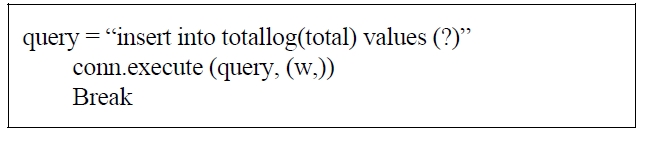
Step 6: Count each HTTP status code (200, 302, 304, 404), count each cache status (MISS, HIT, EXPIRED), count each HTTP method (GET, POST, HEAD), count each browser (Internet Explorer, Firefox, Mozilla, Safari, Chrome, others), count each operating systems (Windows, Linux) display in chart

An experiment using web server logs was conducted to test our algorithm. For this experiment, we used 750MB of data, which results to 401809 entries of logs. The first step in our data cleaning stage is to remove all images, which include .gif, .jpeg, and .css. Due to the format of the log file, some of the images are hidden in folder. Therefore, the log file has to be examined carefully to find image folders, as well as the image files. Table 1 shows that the number of log files has considerably decrease after all the images are removed, from 401809 to only 44014, which constitutes approximately 11% of the original data.
[Table 1.] Results of Log Files After Removing Image Files.

Results of Log Files After Removing Image Files.
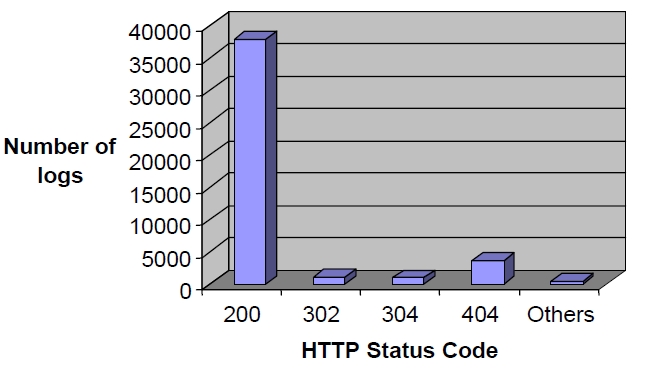
After the images are removed, the next step is to filter the status code. Figure 3 shows the different status codes were identified, and as a result, only status code of 200 is used.
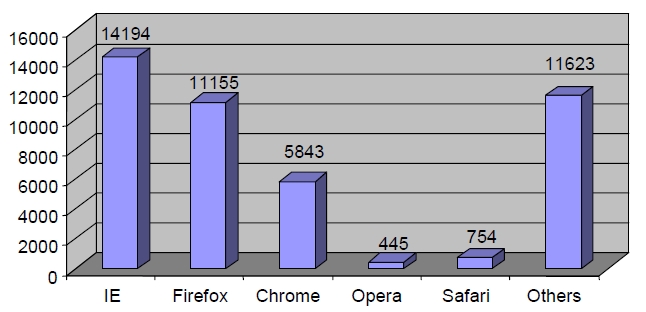
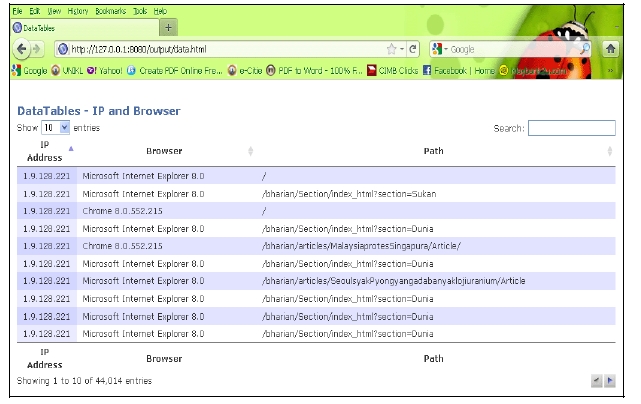
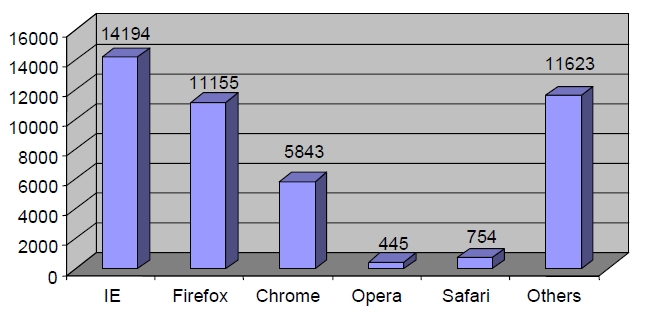
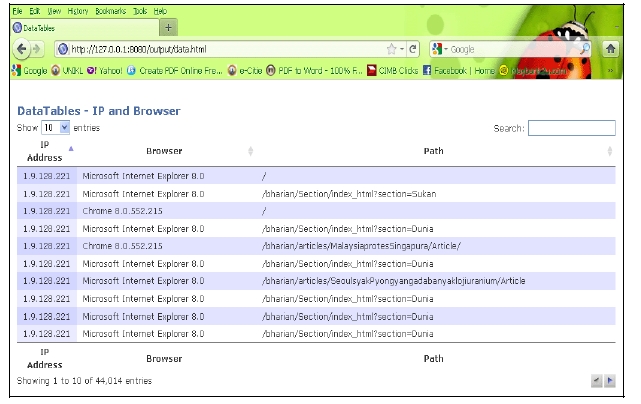
Figure 4 is the results of user identification. After the IP address of each user is identified, the users are further divided into different user agents. This is based on the rules states that if the IP address is the same, but user agent is different, then it denotes different user. From the graph, the highest user agent is Internet Explorer, followed by Firefox, Chrome, Opera and Safari. Other user agents include accesses from browsers used in wireless devices such as smart phone, iPhone or Blackberry. Figure 5 illustrates the user identification based on list of IP address, the different browser of each IP, and the page requested. In this figure, user is identified based on their IP address. Although there are many same IP address, but if the page is accessed from different browser, it shows that they are different users.
In this paper, we presented our detailed of preprocessing phase, which is used to clean web server logs. By using our script in Python 2.6, we define the regular expressions and provide rules for every requirement we need to clean. The experiment conducted has successfully cleaned the web server logs from unnecessary and non-significant information. The testing from the script shows the importance of preprocessing phase as it not just reduce the log file size, as well as increase the quality of available data, which will be used in the pattern discovery phase in the web usage mining phase later. Moreover, there are still issues that need to be resolved such as identifying session and transactionization. Future study will identify appropriate measure to session the data, due to the fact that cache server is used to access the most recent page request by the client.