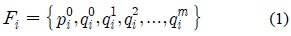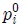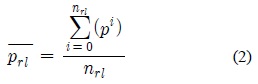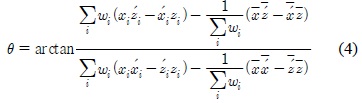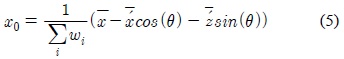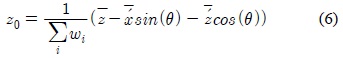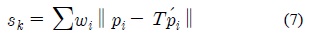This paper introduces an algorithm for computing similarity between two poses in the motion capture data with different scale of skeleton, different number of joints and different joint names. The proposed algorithm first performs the topological analysis on the skeleton hierarchy for classifying the joints into more meaningful groups. The global joints positions of each joint group then are aggregated into a point cloud. The number of joints and their positions are automatically adjusted in this process. Once we have two point clouds, the algorithm finds an optimal 2D transform matrix that transforms one point cloud to the other as closely as possible. Then, the similarity can be obtained by summing up all distance values between two points clouds after applying the 2D transform matrix. After some experiment, we found that the proposed algorithm is able to compute the similarity between two poses regardless of their scale, joint name and the number of joints.
모션캡처 데이터는 자연스러운 3차원 캐릭터의 애니메이션을 생성하기 위해 가장 많이 쓰이는 방법 중 하나이다. 이 방법은 광학적 마커(Optical Marker)가 부착된 사용자의 3차원 움직임을 여러 대의 카메라를 통해 추적 한 후, 이 마커의 3차원 위치를 파악하여 파일 형태로 저장하며, 이 데이터를 3차원 캐릭터에 적용해 캐릭터의 애니메이션을 생성한다. 컴퓨터 그래픽스 연구자들은 다양한 고수준 데이터 구조와 시그널 처리 기법을 이용하여 애플리케이션에 맞게끔 모션 데이터를 변형하여 상용하고 있다[1,2].
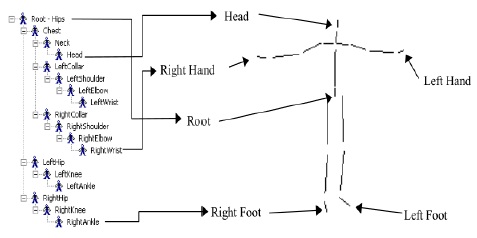
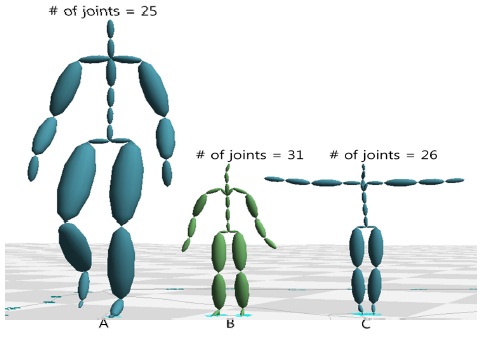
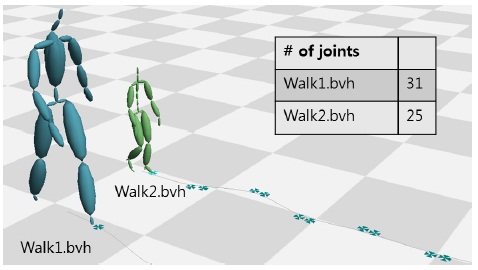
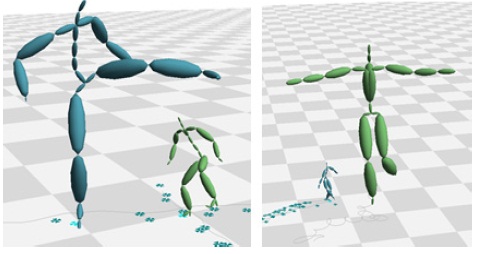
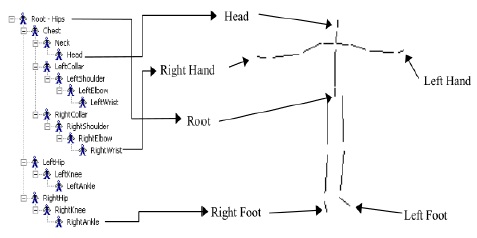
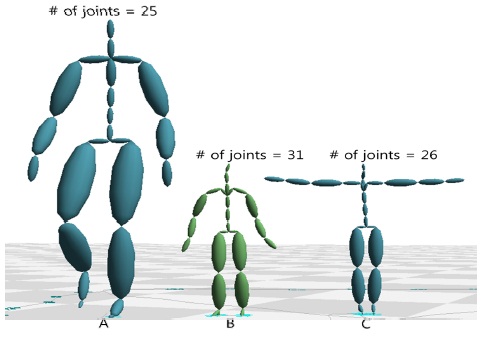
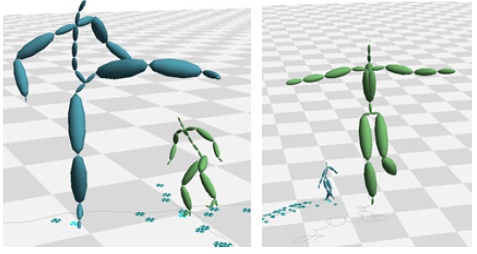
영화나 게임을 위해 캡처되는 모션들은 적게는 수천 프레임, 많게는 수만 프레임에 달하며, 이처럼 방대한 모션 데이터에서 필요한 데이터를 빠르게 검색하는 작업은 모션 캡처 이용에서 가장 중요한 과정 중 하나이다. 하지만 특정 포즈를 검색하는 문제는 해결하기 쉬운 문제가 아니다. 가장큰 문제는 캡처되는 모션 캡처 장비, 마커의 세팅, 혹은 후처리 작업자에 따라, 설정되는 데이터의 형태가 아주 다양하다는 데 있다. 예를 들면, 같은 장비를 사용한다고 하더라도, 마커의 위치와 개수에 따라 생성되는 스켈레톤(Skeleton)의 조인트 계층구조(Hierarchy)는 달라지며. 조인트 이름 또한 사용자에 따라 임의로 정해진다(그림 1). 그림 2는 두 개의 모션 캡처 스켈레톤을 비교한 것으로, A 스켈레톤은 25개의 조인트 개수를 가지며, B 스켈레톤은 30개의 조인트를 가진다. 이와 같은 다른 구조를 가진 스켈레톤의 모션데이타 검색에서 심각한 문제를 일으킨다. 즉, 특정 포즈를 모션캡처 데이터에서 검색할 때, 찾고자 하는 포즈와 검색의 대상이 되는 모션 데이터와 정확히 일치하는 계층구조를 갖지 않는다면, 일일이 조인트를 비교하여 입력 포즈의 특정 조인트가 대상이 되는 모션 데이터의 어느 조인트에 해당하는지 수작업을 통해 알려야 한다. 이와 같은 수작업은 아주 많은 시간과 노력이 필요로 하며, 전체 모션캡처 처리 파이프라인을 느리게 하는 가장 큰 원인 중 하나이다.
이를 해결하기 위한 모션 데이터 검색 알고리즘은 다음 조건을 만족하여야 한다.
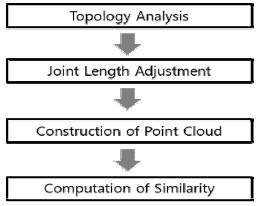
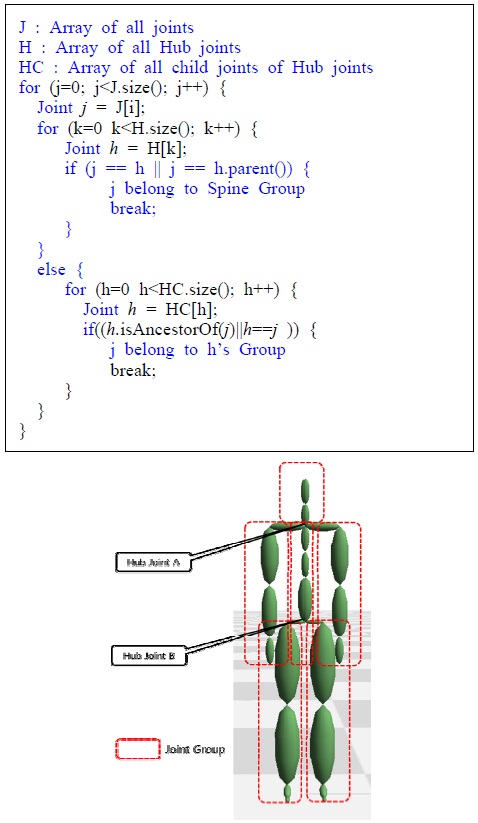
본 논문은 위의 조건을 만족하기 위해 위상분석(Topological Analysis)기법을 이용하여 입력 포즈와 비슷한 포즈를 모션데이터에서 자동으로 검출하는 방법을 제안한다. 본 연구에서 제안하는 위상 분석은 스켈레톤 조인트 구조의 이름에 상관없이 구조 자체에 대한 위상 분석을 통해 어떤 조인트가 다리에 해당하고, 어떤 조인트가 팔에 해당하는지 혹은 척추에 해당하는지에 대해 파악 하며, 이에 따라 전체 조인트를 몇 개의 의미가 있는 조인트 그룹으로 나눈다. 조인트 그룹별로 나뉜 입력 포즈와 검색 대상의 모션 데이터베이스는 조인트의 전역위치를 이용한 포인트 클라우드(Point cloud)로 다시 표현되며, 두 개의 포인트 클라우드는 가중치 값에 따라 차이가 비교되며 이 차이 값의 합은 하나의 거리 값(metric)으로 표시된다. 이때 나타나는 거리 값 계산은 포즈의 2D 변환과 크기변환에 무관하며 실제로 두 포즈가 얼마나 다른지를 나타내는 지표가 된다. 실험결과, 본 논문에서 제안하는 알고리즘은 계층구조에 상관없이 비슷한 입력 포즈와 비슷한 포즈를 거리 순서대로 찾아 줌을 알 수 있었다.
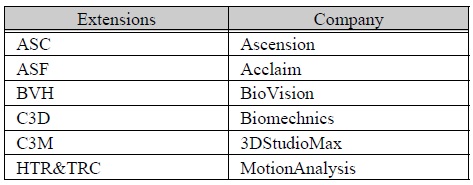
모션캡처데이터는 모션캡처 상용서비스 업체에 따라 다양한 포맷으로 제공되고 있다. 표 1은 이와 같은 모션캡처 포맷 형태의 확장자와 서비스 업체의 목록을 나타낸 것이다. 모든 포맷은 스켈레톤의 정의 부분과 실제 시간 축에 대한 조인트 데이터 부분으로 나뉘며, 포맷에 따라 조인트의 3차원 위치 및 3차원 오리엔테이션 값이 들어 있다.
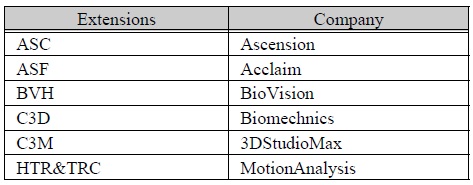
모션캡처 파일 포맷
본 연구의 목적으로 하는 모션캡처데이터의 포즈 비교 문제를 해결하기 위해 Kovar등은 논문[1]을 통해 포인트 클라우드를 이용한 유사도 계산방식을 제안하였다. 하지만 이 방법은 모든 비교 대상 스켈레톤들이 모두 같은 조인트 이름의 계층구조로 되어 있다고 가정하며, 조인트의 정의 순서 또한 정확히 일치하여야 한다. 이와는 다르게 조인트 오리엔테이션 자체의 값을 이용한 거리 측정방법이 제안되었다 [2]. 이 방법은 조인트 오리엔테이션을 이용하기 때문에 크기 변환에 무관한 장점이 있으나, 모든 조인트들이 같은 수의 조인트 개수를 가져야 한다는 단점이 있다. Müllers는 인간형의 모션데이터를 몸 여러 부분끼리의 기하학적인 관계에 대한 추상화를 통한 모션 템플릿을 기법을 제안하였으며, 이 템플릿 위에 입력모션의 기하학적인 관계에 대한 매칭을 통해 관련 없는 모션들을 삭제함으로써 논리적으로 관련 있는 모션을 검색 하였다[3]. 이 방법은 모션의 시 공간적인 특징을 하나의 템플릿으로 저장할 수 있다는 장점이 있지만, 복잡한 모션에 대한 정확한 기하학적 연관관계를 표현하기 쉽지 않은 단점이 있다. Deng et al은 모션을 몸의 부분에 따라 세그먼트 한 후에 확률적 PCA(Principle Component Analysis) 방법에 의해 그룹핑 한 후, 이를 여러 개의 패턴인덱스(pattern index)로 표현하는 방법을 제안하였다[4]. 이후, 입력모션 또한 패턴 인덱스로 표현하여, 이 두 개의 패턴 인덱스 간의 매칭을 통해 유사도를 계산하였다. 이 방법은 비슷한 모션을 쉽게 검색할 수 있으나, 모션을 몸의 부분 부분으로 나누는 세그먼트 작업을 수작업으로 수행하여야 한다는 단점이 있다.
모션캡처 데이터는 시간 축 상으로
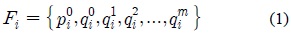
where
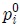
즉, 포즈
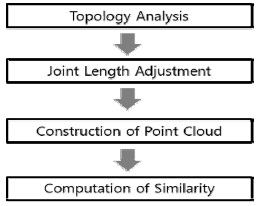
본 논문이 제안하는 위상분석을 통한 포즈 검색방법은 그림 4와 같은 순서를 따른다. 첫째, 입력된 모션캡처 데이터의 한 포즈와 검색 대상에 되는 모션 데이터베이스의 모든 모션 프레임에 대해 위상 분석을 통해 조인들을
이때, 각 조인트 그룹에 포함되는 포인트 수를 일치시킨다. 네 번째, 조인트 그룹별로 할당된 가중치를 이용하여 조인트 그룹별로 유사도를 계산하여, 이를 합산한 최종 유사도 값을 계산한다.
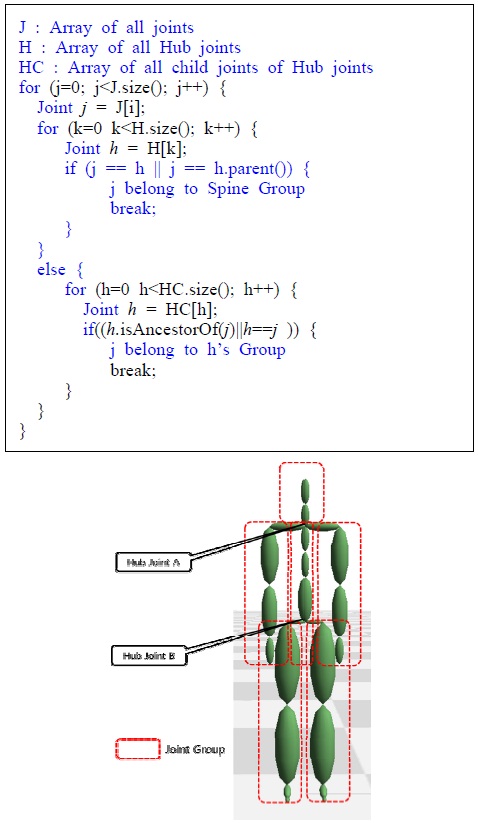
검색 포즈와 모션 데이터베이스에 들어 있는 모션들의 조인트의 개수, 조인트 이름, 스켈레톤의 크기는 모두 다를 수 있으므로, 이와 같은 차이와 무관하게 같은 포즈라면 높은 유사도를 나타내도록 해야 한다. 본 연구에서는 이와 같은 요구조건을 만족하게 하기 위해 스켈레톤에 대한 위상정보(Topology)를 자동으로 분석 후, 이 위상정보에 따라 포즈의 유사도 계산한다. 위상 분석의 목적은, 조인트들의 계층 구조를 분석하여 이들을 의미 있는 그룹들로 구분하는 것이다. 예를 들면, 사람 모션의 경우의 경우, 조인트들을 6개의 그룹 <오른 쪽 다리>, <왼쪽 다리>, <오른쪽 팔>, <왼쪽 팔>, <척추>, <머리>등으로 자동 구분한다. 그림 5는 그룹화 된 조인트 계층구조를 나타낸다. 이를 위해, 수식(1)에서 나타낸 벡터의 모든 조인트 오리엔테이션 인
다음 분류 알고리즘을 통해
3.2.1. 다리 그룹 판별
가장 먼저 양다리에 해당하는 <왼쪽 다리>,<오른쪽 다리> 그룹에 대한 판별은 조인트 중에 가장 바닥의 위치와 가까이에 있는 조인트가 포함된 두 개의 그룹을 찾는다. 이 두 개의 그룹을
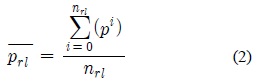
수식 (2)와 같은 방식으로 도 계산된다. 계산된 을 이용하여, 이 두 포인트와 루트 조인트의 전역 위치 을 잇는 두 벡터 계산 할 수 있으며, 이 두 벡터와 업벡터
3.2.2. 머리 그룹 판별
머리 조인트 그룹은 다리 그룹으로 판별된 그룹을 제외한 그룹을 대상으로 수식 (2)와 같은 방법을 이용하여 평균 조인트의 위치를 계산한 후, 이 위치 중에 Y축으로 가장 높은 그룹을 머리 그룹
3.2.3. 팔 그룹 판별
팔 조인트 그룹은, 다리와 팔, 머리 그룹으로 판별된 그룹을 제외한 그룹들을 대상으로 수식 (2)와 비슷한 방법을 이용하여 판별한다. 먼저 그룹들의 기본포즈에서 의 평균 조인트 위치인 을 계산하고, 이 평균 조인트 위치들의 중간 위치 를 계산한다. 이 중간 위치와 각 평균 조인트 위치 를 뺀 두 벡터 와 머리 그룹의 평균 위치를 이용한 벡터 를 구한 후, 이 두 벡터 간의 외적 벡터 를 계산하여 이 외적 벡터의
3.2.4. 척추 그룹 판별
위의 판별 단계를 통해 판별되지 않는 나머지 그룹은 척추 그룹으로 판별 한다
포즈에 대한 검색은 스켈레톤의 크기에 무관해야 하므로, 본 연구는 비교 대상이 되는 두 스켈레톤의 크기를 비교하여 이에 대한 비율을 구한 후 이를 유사도 계산에 이용한다. 먼저 두 스켈레톤의 크기 비율

두 포즈를 비교하기 위해서 조인트 오리엔테이션만을 이용하면, 3차원 오리엔테이션의 비선형 특성으로 인하여 포즈의 차이를 정확히 파악하기 어렵다[5]. 본 연구는 Kovar et al이 제안한 포인트 클라우드 방식을 변형하여 두 포즈를 비교한다. 이 방식은 조인트의 전역 위치에 가상의 3차원 마커가 있다고 가정하고, 이 가상의 마커의 3차원 위치들로 이루어진 포인트 클라우드를 구축하여 이들 간의 거리 차이를 이용해 포즈의 유사도를 계산한다. Kovar가 제안한 방법은 위상분석이 없이, 모든 포즈를 하나의 포인트 클라우드로 표현한 반면, 본 논문에서는 위상분석을 통해 얻는 6개의 조인트 그룹별로 포인트 클라우드를 구축한 후, 포인트 클라우드 간의 유사도를 각각 계산한다.
예들 들면, 오른쪽 다리 그룹에 대한 포인트 클라우드 와 같이 표현되며, 여기에서
비교 대상이 되는 두 스켈레톤은 전체 조인트 개수가 다를 수 있으므로, 이에 따라 분류된 조인트 그룹 내부의 포인트 개수에도 차이가 있을 수 있다. 예를 들면, 의 포인트 개수가 각각 로 차이가 난다면 중에 작은 수를 기준으로 두 포인트 클라우드의 포인트 수의 차를 계산한 후, 그 차이만큼 개수가 많은 포인트 클라우드에서 포인트를 삭제한다. 포인트 삭제 시, 가장 나중에 삽입된 포인트부터 삭제하며, 이는 조인트 계층구조 상, 나중에 삽입된 포인트가 종말조인트(end-effector)에 가까우므로, 중요도가 낮기 때문이다.
두 포인트 클라우드인
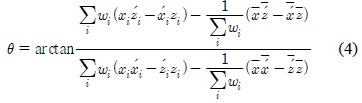
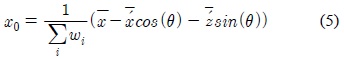
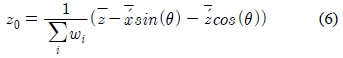
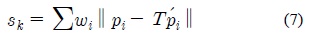

위 계산에서 정해지지 않은 부분은 가중치 값인
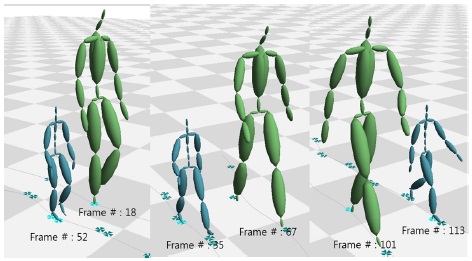
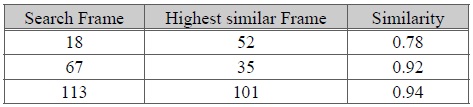
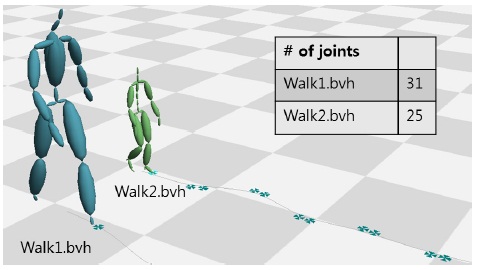
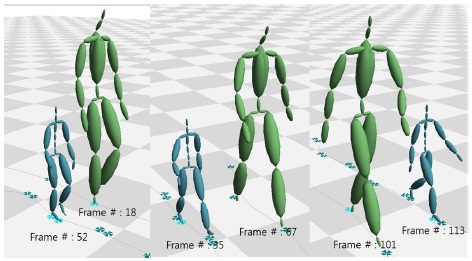
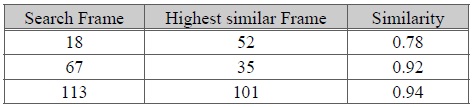
두 논문에서 제안한 알고리즘에 대한 테스트를 위하여 BVH(BioVision Hierarchy) 포맷의 모션캡처 데이터를 대상으로 실험을 수행하였다. 본 실험에서 사용된 두 개의 모션캡처 데이터는 스켈레톤의 크기/조인트 개수/조인트 이름이 모두 다른 데이터를 대상으로 하였다. 그림6은 실험 대상이 되는 두 개의 걷는 모션 캡처 데이터 Walk1.bvh와 Walk2.bvh의 스켈레톤과 루트 조인트의 궤적을 나타낸다. 그림7은 Walk1.bvh내 임의로 지정한 프레임에 대해 가장 비슷한 포즈를 walk2.bvh에서 검색한 것이다. 표 2은 검색된 프레임 번호와 유사도를 나타낸다. 그림 8은 martial art모션와 dancing모션에 대해 실험을 수행한 것이다. 이 실험을 통해 가장 비슷한 유사도를 가진 두 포즈를 한 화면에 나타냈다. 걷는 모션과 마찬가지로 두 모션은 다른 크기와 조인트 개수를 가진다.
유사도 실험 결과
실험 결과 반복적인 포즈가 많은 walking모션의 경우 비슷한 유사도를 가진 포즈가 많음을 알 수 있었고, 모션 자체의 단순함에 따라 높은 유사도를 가짐을 알수 있었으며, martial art나 dancing모션을 경우 상대적으로 복잡한 모션을 가지므로, 상대적으로 가장 높은 유사도를 가진 포즈도 walking모션보다는 유사도가 낮음을 알 수 있었다.
본 논문에서는 크기, 계층구조, 조인트 이름이 다른 모션데이터 간 특정 포즈에 대한 유사도를 자동으로 검색하는 알고리즘을 제안하였다. 본 알고리즘의 핵심은 스켈레톤을 이루는 조인트 계층구조에 대한 위상분석을 통해 조인트를 그룹화하는 데 있다. 위상분석을 통해 그룹으로 묶인 조인트들은 다시 각각 포인트 클라우드로 표현되며, 이 포인트 클라우드들은 스켈레톤의 크기 비율을 이용해 재조정되며, 내부의 포인트 개수 또한 일치된다. 그룹 당 생성된 포인트 클라우드들은 유사도 계산 수식에 의해 유사도가 계산되며, 이 유사도의 합을 통해 최종 유사도를 구하였다. 본 논문에서 사용되는 방법은 모션 그래프 및 다양한 모션 블렌딩 기법의 기반이 되는 핵심 기법으로 활용될 수 있으며, 많은 모션이 필요한 영화, 게임 제작에 응용될 수 있을 것으로 기대한다. 앞으로 향후 연구를 통해 제안한 알고리즘을 기반으로 비슷한 포즈를 GPU를 통하여 빠르게 검색하는 방법에 대한 연구를 수행할 예정이며, 하나의 특정 프레임 뿐 아니라 모션의 시멘틱한 의미가 충분히 드러나기 위하여 속도 및 가속도 정보를 이용하여 유사도의 정확도를 높힐 예정이다.