Traditional document clustering methods are based on the bag of words (BOW) model, which represents documents with features, such as weighted term frequencies. However, these methods ignore semantic relationships between terms within a document set. The clustering performance of the BOW model is dependent on a distance measure of document pairs. However, this distance measure cannot reflect the real distance between two documents because the documents are composed of high-dimension terms with respect to complicated document topics. Further, the results of clustering documents are influenced by the document properties or the cluster forms desired by the user. Recently, internal and external knowledge-based approaches have been used for overcoming the problems of the vector model-based document clustering method [1-3].
Internal knowledge-based document clustering determines the inherent structure of a document set by using a factorization technique [4-9]. These methods have been studied intensively, and although they have many advantages, the successful construction of semantic features from the original document set remains limited with respect to the organization of very different documents or the composition of similar documents [10].
External knowledge-based document clustering exploits the term ontology constructed using an external knowledge database with respect to Wikipedia or WordNet [11-14]. The term ontology techniques can improve the BOW term representation of document clustering. However, it is often difficult to locate a comprehensive ontology that covers all the concepts mentioned in the document collection, which leads to a loss of information [1,12]. Moreover, the ontology-based method incurs a relatively high cost as the ontology has to be constructed manually by knowledge engineers and domain experts.
In order to resolve the limitations of knowledge-based approaches, in this paper, we propose a text document clustering method that uses non-negative matrix factorization (NMF) and WordNet. The proposed method combines the advantages of the internal and external knowledge-based methods. In the proposed method, first, meaningful terms of a cluster for describing the cluster topics of documents are extracted using NMF. The extracted terms well represent the document clusters through semantic features (i.e., internal knowledge) that have the inherent structure of the documents. Second, the term weights of documents are calculated using the term mutual information (TMI) of the synonyms of documents terms obtained from WordNet (i.e., external knowledge). The term weights can easily classify documents into an appropriate cluster by extending the coverage of a document with respect to a cluster label.
The rest of this paper is organized as follows: Section II reviews related works on text document clustering. Section III describes the NMF algorithm. Section IV presents the proposed text document clustering method. Finally, Section V presents the evaluation and experimental results, and Section VI concludes this paper.
Recently, a knowledge-based document clustering method, which is used for increasing the efficiency of document clustering, has been proposed; the techniques used in the method can be divided into internal and external knowledgebased techniques.
As an internal knowledge-based approach, Li et al. [8] pro-posed a document clustering algorithm, called the adaptive subspace iteration (ASI), which explicitly models the subspace structure and works well for high-dimensional data. This is influenced by the composition of the document set for document clustering. To overcome the orthogonal problem of latent semantic indexing (LSI), Xu et al. [4] proposed a document partitioning method based on NMF in the given document corpora. The results from the abovementioned method have a stronger semantic interpretation than those from LSI, and the clustering result can be derived easily using the semantic features of NMF. However, this method cannot be kernelized because the NMF must be performed in the original feature space of the data points. Wang et al. [9] used clustering with local and global regularization (CLGR), which uses local label predictors and global label smoothing regularizers. They achieved satisfactory results because the CLGR algorithm uses fixed neighborhood sizes. However, the different neighborhood sizes cause the final clustering results to deteriorate [9].
The external knowledge-based techniques for document clustering include TMI with conceptual knowledge by WordNet [11], concept mapping schemes from Wikipedia [12], concept weighting from domain ontology [13], and fuzzy associations with condensing cluster terms by WordNet [14].
III. NON-NEGATIVE MATRIX FACTORIZATION
This section reviews the NMF theory along with the corresponding algorithm. In this paper, we define the matrix notation as follows: Let

where
Further, an objective function is used for minimizing the Euclidean distance between each column of
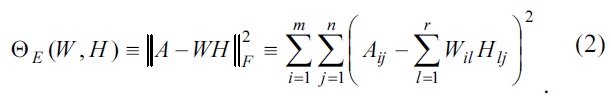
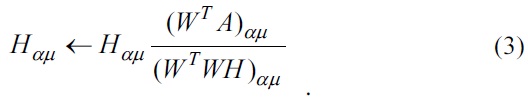
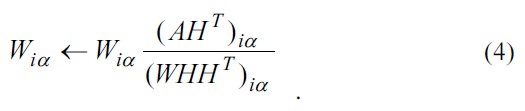
IV. PROPOSED DOCUMENT CLUSTERING METHOD
This paper proposes a document clustering method that uses cluster label terms generated by NMF and term weights based on the TMI of WordNet. The proposed method consists of three phases: preprocessing, extraction of cluster terms and term weights, and document clustering. In the subsections below, each phase is explained in full.
In the preprocessing phase, Rijsbergen’s stop words list is used for removing all stop words, and word stemming is removed using Porter stemming algorithm [15]. Then, the term document frequency matrix
>
B. Cluster Term Extraction and Term Weight Calculation
This section consists of two phases: cluster term extraction and term weight calculation. The cluster terms corresponding to the properties of the document clusters are extracted by using the semantic features of NMF; these terms can explain the topic of the document cluster well.
The extraction method can be described as follows: First, the term document frequency matrix
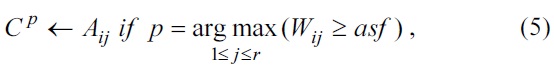
where
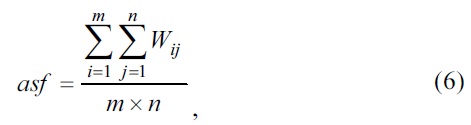
where
Example 1 illustrates the cluster term extraction.
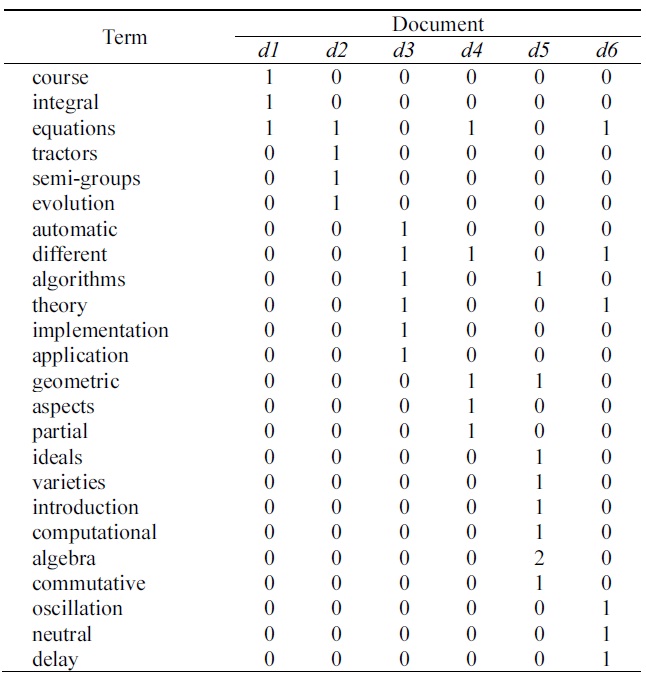
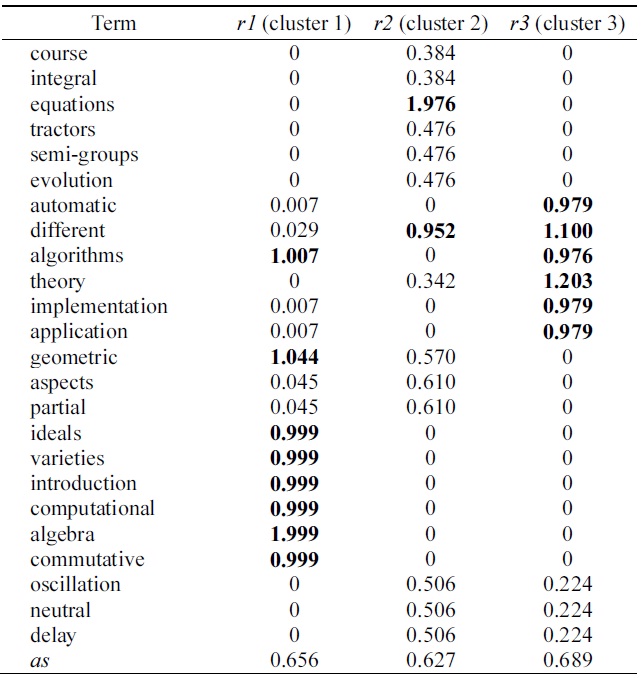
Example 1. Table 1 shows the six documents (i.e., the extracted the [2]’s Figure 4.10). Table 2 shows the term document frequency matrix generated in the preprocessing phase, described in Table 1. Table 3 presents the sematic feature matrix
The term weights are calculated using TMI based on the synonyms of WordNet. WordNet is a lexical database for the English language where words (i.e., terms) are grouped in synsets consisting of synonyms and thus representing a specific meaning of a given term [16].
[Table 1.] Document set of composition of six documents

Document set of composition of six documents
[Table 2.] Term document frequency matrix from Table 1
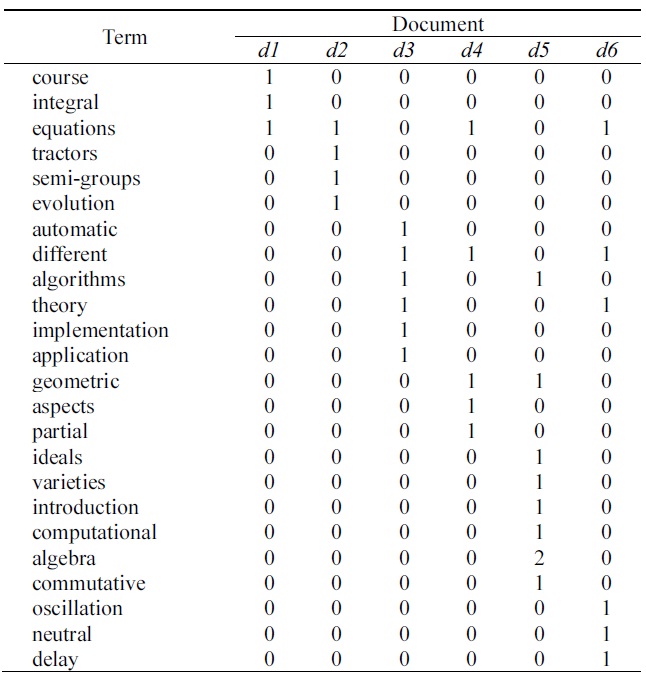
Term document frequency matrix from Table 1
[Table 3.] The asf and semantic feature matrix W by NMF from Table 2
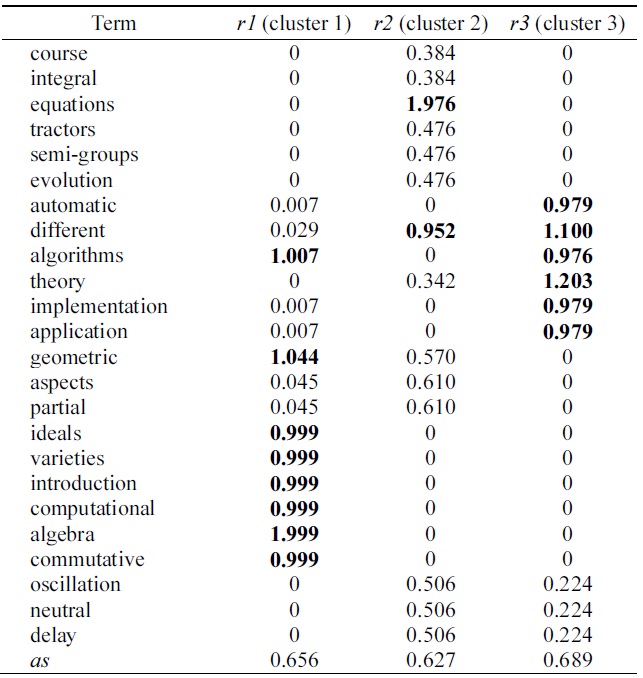
The asf and semantic feature matrix W by NMF from Table 2
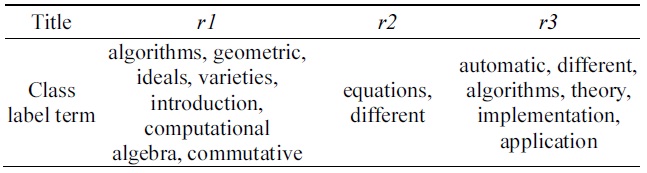
[Table 4.] Extracted cluster terms
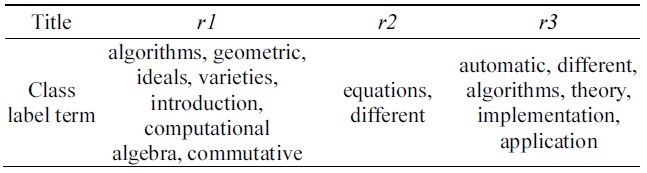
Extracted cluster terms
Class label terms may be restricted by the properties of a document cluster and the document composition. To resolve this problem, in this study, we use the term weight of documents by using the TMI on synonyms obtained from WordNet. Term weights of the document are calculated by using Jing’s TMI as in Eq. (7) [11]. In the equation for Jing’s TMI,
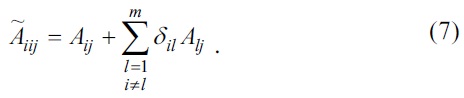
This section explains document clustering using cosine similarity between the cluster terms and the term weights of the documents. The proposed method is described as follows: First, the cosine similarity between the cluster terms and the term weights is calculated using Eq. (8). Then, the document having the highest similarity value with respect to the class label is added to a document cluster [3,15].
The cosine similarity function between the sentence vectors and the query is computed as follows [15]:
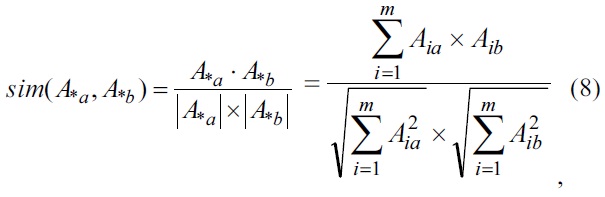
where
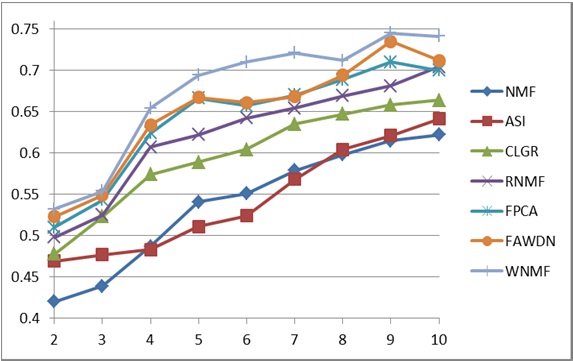
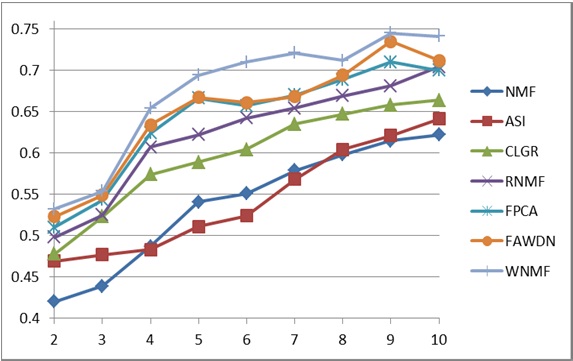
In this study, we use the dataset of 20 newsgroups for the performance evaluation [17]. To evaluate the proposed method, mixed documents were randomly chosen from the abovementioned dataset. A normalized mutual information metric related to Eqs. (9) and (10) was used for measuring the document clustering performance [2-4, 7-9]. The cluster numbers for the evaluation method were set in the range of 2 to 10, as shown in Fig. 1. For each given cluster number
The normalized mutual information metric
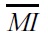
was used for measuring the document clustering performance [2-4,7-9]. To measure the similarity between the two sets of document clusters
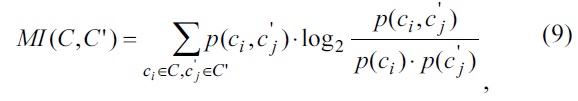
where
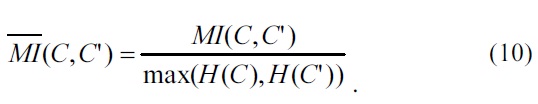
In this study, seven different document clustering methods were implemented, as shown in Fig. 1. The NMF, ASI, CLGR, RNMF, and FPCA methods are document clustering methods based on internal knowledge, and the FAWDN and TMINMF methods are clustering methods based on a combination of the internal and the external knowledge. WNMF denotes the proposed method described in this paper. FAWDN denotes the previously proposed method that is based on WordNet and fuzzy theory [14]. FPCA is the previously proposed method based on principal component analysis (PCA) and fuzzy relationships [6], and RNMF is the method proposed previously using NMF and cluster refinement [5]. NMF denotes Xu’s method using NMF [4]. ASI is Li’s method using adaptive subspace iteration [8]. Lastly, CLGR denotes Wang’s method using local and global regularization [9].
As seen in Fig. 1, the average normalized metric of WNMF is 14.99% higher than that of NMF, 14.48% higher than that of ASI, 9.21% higher than that of CLGR, 6.66% higher than that of RNMF, 4.80% higher than that of FPCA, and 3.98% higher than that of FAWDN.
In this paper, we proposed an enhanced text document clustering method using NMF and WordNet. The proposed method uses the semantic features of the document on the basis of the internal knowledge of NMF for extracting the
cluster terms, which are well represented within the important inherent structure of the document cluster. In order to solve the limitation of the internal knowledge-based clustering methods with respect to the influence of the internal structure of documents, the proposed method uses TMI of WordNet to calculate the term weights of documents. Further, this method uses a similarity between the cluster terms and the term weights to improve the quality of the text document clustering. It was demonstrated that the value of the normalized mutual information metric is higher in the case of the proposed method than in the case of the other text document clustering methods for a dataset of 20 newsgroups.