전자상거래 시대의 도래는 사람들이 쇼핑하는 방식을 변화시켰고, 동시에 사용자들은 쇼핑할 때 많은 양의 데이터를 생성한다. 이러한 데이터는 오프라인 계산으로 분석이 가능하지만 오프라인 분석 결과는 실시간 성능이 부족하다. 본 논문에서는 전자상거래 이용자의 로그 데이터와 비즈니스 데이터를 실시간으로 처리함으로써 처리 결과의 피드백을 신속하게 실현할 수 있다. 스파크 빅데이터 컴퓨팅 프레임워크는 실시간 컴퓨팅 기능과 높은 처리량의 장점을 가지고 있다. 스파크 스트리밍(Spark Streaming)은 스파크 코어의 확장으로서 스파크 컴퓨팅 플랫폼의 실시간 스트림 처리 구성 요소이다. 본 논문에서는 스파크를 통해 실시간으로 데이터를 처리한다. Maxwell을 통해 MySQL 데이터베이스의 비즈니스 데이터 변경에 대한 실시간 모니터링을 수행하고 모니터링한 데이터를 Kafka로 전송한다. 로그 데이터는 Kafka로 직접 전송한다. 스파크 스트리밍은 Kafka에서 데이터를 소비한 후 요구사항에 따라 데이터에 대한 특정 처리를 수행하며 처리된 데이터는 Elasticsearch에 저장한다. 이 논문은 정확한 1차 데이터 소비를 달성하기 위해 offset를 수동으로 제출하여 Kafka에서 적어도 하나의 데이터 소비를 실현한다. Elasticsearch는 멱등 쓰기를 지원하기 때문에 데이터에 대한 정확한 1차 소비가 가능하다. 수동으로 제출한 offset은 Redis에 저장된다. 마지막으로 비즈니스 요구 사항에 따라 처리 결과에 대한 구체적인 조회를 수행한다.
With the rapid development of society, we have entered the era of big data, and many big data computing frameworks have also appeared. Hadoop is an open-source framework based on distributed computing[1,2]. The core components of Hadoop are HDFS and MapReduce. HDFS and MapReduce were inspired by technologies created inside Google—Google File System (GFS) and Google MapReduce, respectively[3]. HDFS adopts a master-slave structure, which consists of a NameNode and multiple DataNodes, and a SecondaryNameNode as the backup of the master node, which can assist in restoring the master node in an emergency. The process of MapReduce is summarized into two parts: decomposition and aggregation, which are represented by two functions, map and reduce. Map is responsible for processing a single task, and reduce is responsible for aggregating the results of multiple tasks after decomposition.
Spark is an in-memory based distributed processing framework[4]. Its ecosystem includes Spark Core, Spark Streaming, MLLib, GraphX and other components[5]. These components combine with each other to form a whole. Spark Core provides the framework for in-memory computing and is the core of all other components. Spark Streaming is an extension of the core Spark API[6]. Using Spark Streaming, data stream processing can be performed. It receives data in real-time and integrates the data into small batches for processing at certain time intervals, and the processing delay can reach the second level. Spark Streaming can fetch data in real-time from various data sources such as Kafka, Flume, Kinesis, etc.[7]. Spark can make up for Hadoop's inability to do batch processing in real-time. This paper uses Spark as the real-time processing framework, combines Kafka[8], Maxwell, Redis[9], Elasticsearch[10], MySQL and other technologies to process e-commerce log data and business data in real-time, and query the processing results according to business requirements.
Chapter 2 describes the system design, chapter 3 describes the System implementation, chapter 4 shows the system test, and chapter 5 desciibes the concolusion.
2.1 System Architectural Design
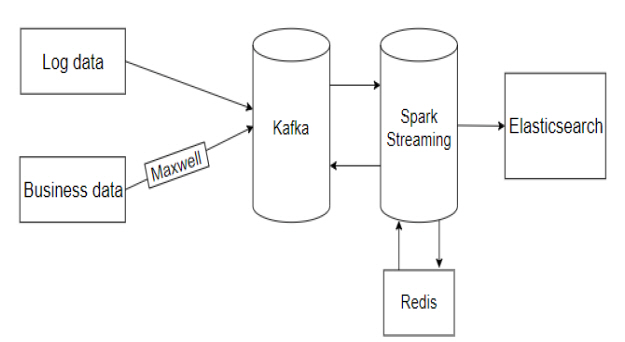
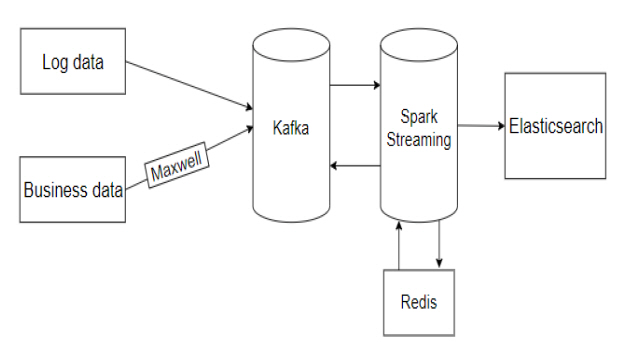
The system architecture is shown in <Figure 1>.
The log data generator and the business data generator are used to generate the log data and business data required for this paper. Log data is generated directly into Kafka. The business data is generated into the MySQL database, and the changes of the business data in the MySQL database are monitored in real-time through Maxwell, and the changed data is sent to Kafka[11]. Spark Streaming consumes log data and business data in Kafka. Then the data is processed through certain rules. The processed data is written to Kafka. Later, consume the processed data in Kafka through Spark Streaming. Then perform specific processing operations on the data. The manually submitted offsets are saved to the Redis database during data processing. Finally, the data processing results are saved to Elasticsearch through idempotent writing.
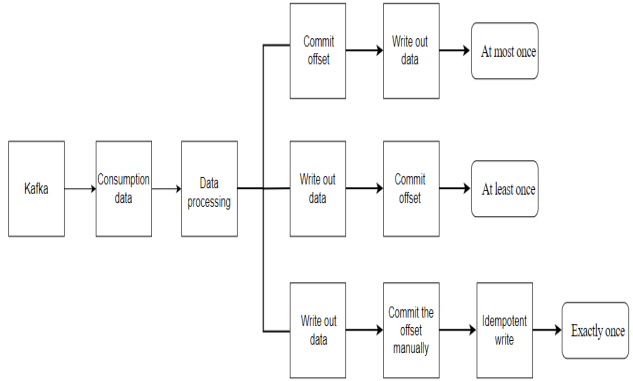
2.2 Exactly-once Consumption Design
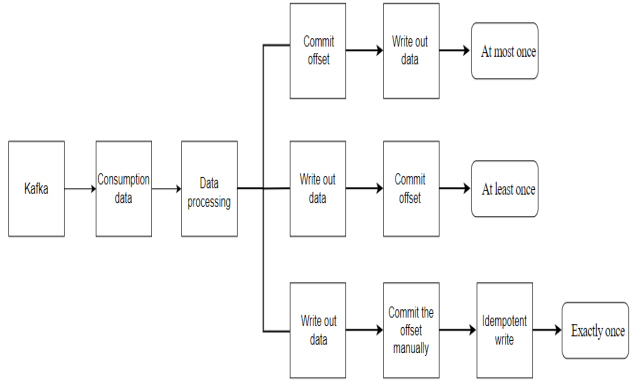
Kafka provides at-most-once, exactly-once, and at-least-once delivery. As shown in <Figure 2>, at-most-once means that the offset is submitted first and then the data is written, which will cause data loss. at-least-once means that writing data first and then submitting offsets will cause data duplication. This paper achieves exactly-once consumption by manually submitting offsets and idempotent writes[12-14].
At most once: When a real-time computing task performs calculations, the process crashes before the data results are saved to disk. Assuming that Kafka adjusted the offset before the process crashed, then Kafka will think that the data has been processed, and even if the process restarts, Kafka will start from the new offset. Therefore, the data that has not been saved before is lost.
At least once: If the data calculation result has been saved and the process crashes before Kafka adjusts the offset, Kafka will think that the data has not been consumed. When the process restarts, it will start to consume from the old offset again, then the data will be consumed twice, and the data will be stored twice.
Exactly once: First, write out the data and then manually submit the offset to ensure that the data will not be lost but will cause repeated consumption problems. Manually committed offsets are stored in the Redis database. The Elasticsearch supports idempotent writing. The data will not be doubled even if the same batch of data is repeatedly saved multiple times during idempotent writing. Therefore, exactly-once consumption is achieved by writing the processed result idempotently.
The offset management scheme is to first read the offset starting point from Redis and consume the data in Kafka by specifying the offset. Then process the data and write out the data. Finally, save the offset end point to Redis.
3.1 Exactly-once Consumption Implementation
First, write a Kafka tool class for producing data and consuming data. Based on Spark Streaming, use the specified offset to consume data and obtain KafkaDStream. After consuming the data from Kafka, extract the end point of the offset. When the log data and business data are processed and written out, the end point extracted to the offset needs to be stored in the Redis database. Offsets also need to be read from Redis before consuming Kafka data. The code for reading and storing the offset is as follows.
The log data and business data are processed and the results are saved to the Elasticsearch through idempotent writes. The code for the idempotent write is as follows.
3.2 Log Data Processing Implementation
① Generate user log data through the e-commerce user log data generator and send it to the BASE_LOG topic of Kafka.
② Create StreamingContext. Consume data in the BASE_LOG topic through Spark Streaming. The offset needs to be read from Redis before consuming data. If the offset is empty, use the default offset for consumption. If the offset is not empty, use the specified offset for consumption. Then extract the end point of the offset.
③ This step starts to process the log data. First, data conversion is performed to convert log data into JSONObject. Then, the log data is distributed, and the page access data is sent to the PAGE_LOG topic of Kafka. Finally, the flush method is called in the foreachPartition to force the data of the buffer to be flushed to the Broker, and save the offset end point to Redis at a position inside foreachRDD and outside foreachPartition.
④ Consume the data in the PAGE_LOG topic through step 2, convert the consumed data structure into a dedicated object, and then start to count the number of daily active users. This paper's statistics of daily active users only consider the user's first visit behavior. Each batch of data uses the filter method to filter out the data whose last_page_id is not empty in the page access data to realize the self-examination operation. The mid (device id) of active users on the day is maintained through Redis, and each piece of data after self-examination needs to be compared and deduplicated in Redis through mid. If Redis does not contain the mid, save the mid to Redis. Process the date field and associate the processed date data with the data after deduplication to form a wide table. Finally, the results are saved to Elasticsearch through idempotent writing and save the offset end point to Redis at a position inside foreachRDD and outside foreachPartition.
3.3 Business Data Processing Implementation
① The user business data is generated into the MySQL database through the e-commerce user business data generator. Maxwell monitors the changes in the MySQL database in real-time and sends the changed data to the BASE_BUSINESS topic of Kafka.
② Prepare the real-time processing environment. Read the offset from Redis, consume the data in the BASE_BUSINESS topic through Spark Streaming, and then extract the end point of the offset. Before consumption, judge whether the offset is empty to decide whether to consume through the specified offset or the default offset.
③ This step starts to process the business data. The business data in this paper includes order table data, order detail table data. First, convert the consumed business data into JSONObject, and then determine the type of change operation of the consumed business data, including operations such as insertion and deletion, and determine which table the changed data belongs to. Save the changed data to the topic of the corresponding operation and table name, such as ORDER_INFO_INSERT, ORDER_DETAIL_INSERT, etc. Finally, the flush method is called in the foreachPartition to force the data of the buffer to be flushed to the Broker and save the offset end point to Redis at a position inside foreachRDD and outside foreachPartition.
④ Repeat step 2. But the difference from step 2 is that the consumed data includes the data of the two topics ORDER_INFO_INSERT and ORDER_DETAIL_INSERT. Consuming data from two topics requires maintaining two offsets, so two offsets need to be read from Redis, and two offsets are also extracted at the end point of the offset. Convert the consumed data structure into the corresponding dedicated object. Process the date field of the data consumed in the ORDER_INFO_INSERT topic. The data consumed from the ORDER_INFO_INSERT topic is associated with the processed date field to form a wide table. The id field of the wide table and the order_id field of the order detail table perform the Join operation. The wide table and the order detail table have a one-to-many relationship. In order to solve the data delay problem of dual-stream join, fullOuterJoin ensures that the data of successful or unsuccessful join will appear in the result. Then use Redis for data caching, wide table and order detail table to solve the data delay problem through read cache and write cache. Finally, the idempotent writing of the result after the join is saved to Elasticsearch, and save the two offset end points to Redis at a position inside foreachRDD and outside foreachPartition.
This paper uses VMware to build three virtual machines and build a distributed cluster on them[15], the master is the hostname of the master node, and slave1 and slave2 are the hostnames of the slave nodes, using ssh to log in to three machines without password. The cluster environment is shown in <Table 1>.
[Table 1.] Cluster environment
Cluster environment
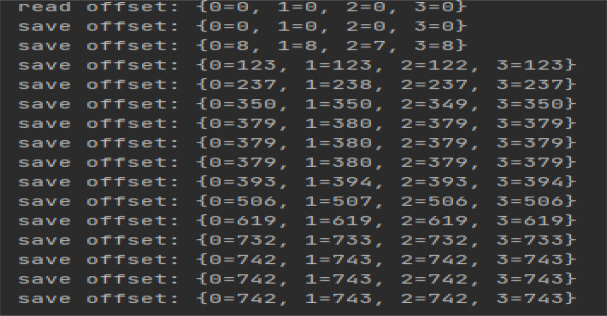
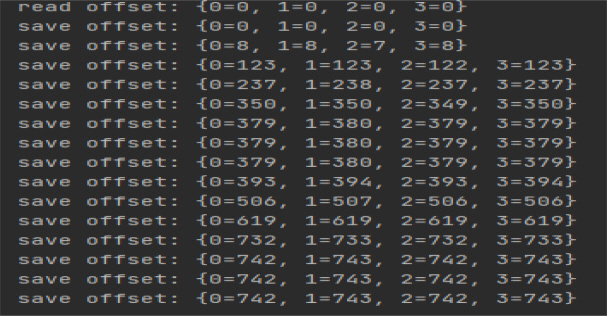
This paper takes log data processing as an example to test the reading and saving of offsets. The same is true for the offset test during business data processing. As shown in <Figure 3>, when the data in the topic is consumed for the first time, Redis has no offset storage information, and the read offset is 0. At this time, there is no data on the topic, so the stored offset is also 0. When there is data in the topic, Spark Streaming consumes the data in the topic, then processes the log data, and finally stores the offset. At this time, the stored offset is not 0.
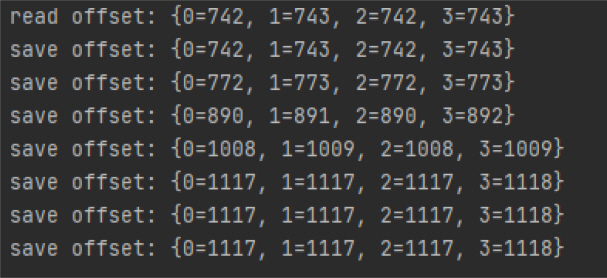
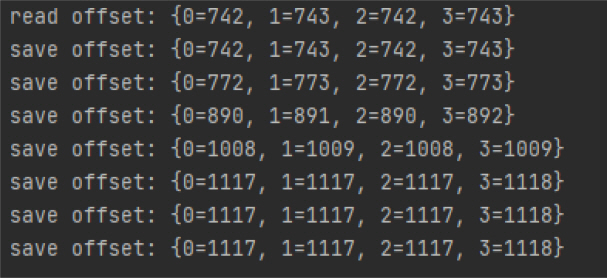
As shown in <Figure 4>, when the program starts again, the offset stored in Redis will be read, and the read offset is the same as the last saved offset. When processing log data, the value of the saved offset changes.
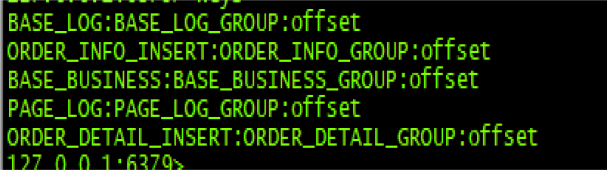
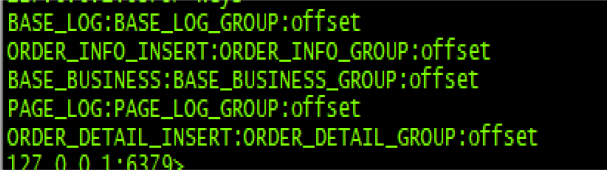
Redis is used to maintain the required offsets, as shown in <Figure 5>.
Kibana is open source analytics and visualization platform designed for Elasticsearch. This article uses Kibana to search data stored in Elasticsearch indexes. First, query the log data processing results in Elasticsearch in real-time according to the date and time. The query statement is as follows.
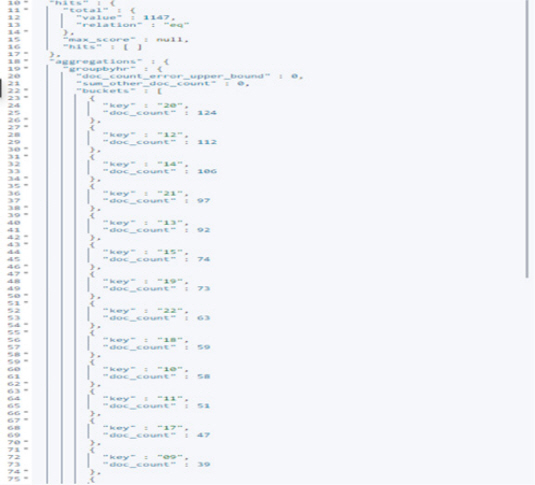
GET log_info_2022-09-10/_search { "aggs": { "groupbyhr": { "terms": { "field": "hr", "size": 24 } } } , "size": 0 }
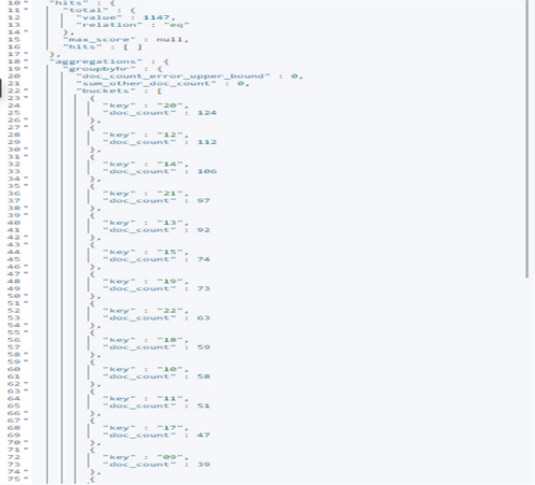
The log data query result is shown in <Figure 6>.
Perform a specific transaction analysis result query on the results of business data processing in Elasticsearch based on dates and keywords. The query statement is as follows.
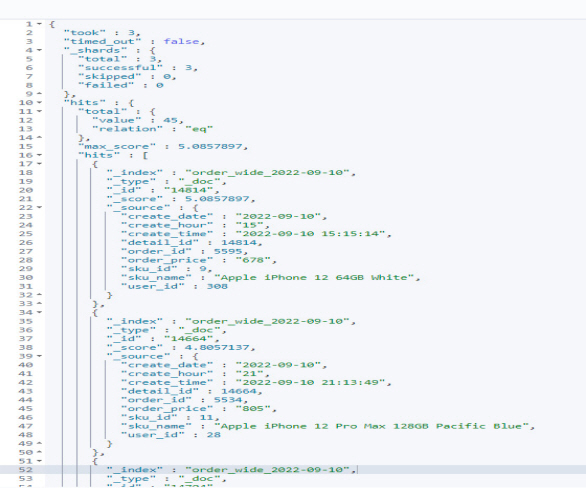
#Modify the default value of size. PUT /_settings { "index.max_result_window":"5000000" } GET order_wide_2022-09-10/_search {"query": { "match": { "sku_name": { "query": "Apple iPhone" ,"operator": "and" } } } , "size": 5000000 }
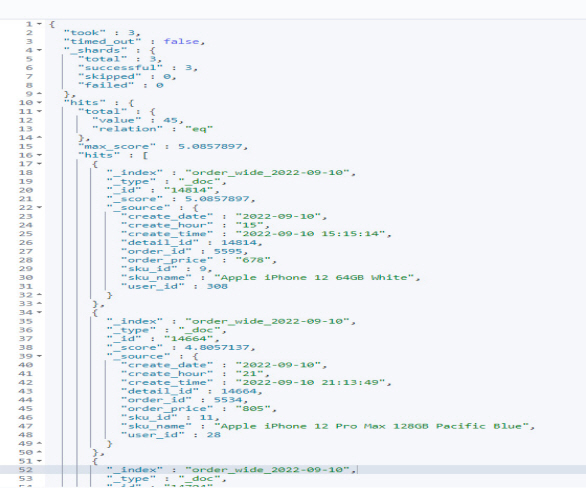
The business data query result is shown in <Figure 7>.
With the rapid development of society, people rely more on online shopping. Real-time processing of user-generated data is becoming more and more important in order to better understand the current state of the platform. This paper uses Spark as the real-time processing framework, combined with Kafka, Elasticsearch, Redis and other technologies to realize real-time processing of user log data and business data and to to query the processing results according to specific requirements.
Subsequent use of algorithms to dig deep into user data to discover the potential needs of users. In-depth discussion of Spark's operating principle to give full play to the advantages of distributed computing to further improve computing efficiency.