This paper introduces an algorithm to obtain an estimate of the missing value from incomplete data using decision trees. As a classifier to construct a decision tree, C4.5 and SVM series algorithms with different characteristics are used, and the characteristics and performance of the two classifiers are examined through the implementation process. The decision tree is selected as a handling technique for incomplete data because each node of the decision tree has the classification information (hyperplane) of the input patterns, and the path from the root to the terminal node combines the hyperplanes to form a single domain. Therefore, the key idea of this paper for incomplete data is to enter the missing event in the root and find the area most similar to the missing information through traversal. Then, an estimate of the missing information is obtained from the events in this domain. From the implementation point of view, the training data is divided into lossy data and non-lossy data, and the decision tree is completed by inputting the non-lossy data into C4.5/SVM. Next, after inputting the loss data into this decision tree, the traversal is repeated until reaching the terminal node according to the condition for finding the most similar property.
불완전한(incomplete) 데이터는 유비쿼터스 환경과 같이 서로 다른 기기와 원거리로부터 지속적으로 데이터가 수집되는 경우에 발생한다[1]. 실제로 데이터(
그동안 이 문제와 관련된 연구로 데이터 구조 면에서 데이터 확장 기법을 이용하는 방법[3,4]과 결정 트리를 이용하는 방법[5] 등이 제안되었다. 그리고 결측값을 추정하는 방법으로 엔트로피를 이용하는 방법[6,7], 집락 분석(clustering) 기법 중에 OCS 알고리즘을 이용하는 방법[8], 분류기로 분류한 후 가장 유사한 영역을 찾아 이곳의 속성을 이용하는 방법[9] 등이 제안되었다. 마지막으로 결측값을 추정치로 대치한 후에 시스템의 성능을 평가하기 위해 C4.5[10], SVM[4,11], 딥러닝 알고리즘[6,12] 등이 이용되었다.
제안 논문의 접근 방법은 학습 중에 결정 트리를 구성하는 C4.5와 Fisher의 선형분리함수를 이용하는 SVM 계열의 알고리즘을 이용한다. 분류기로 결정 트리를 구성하는 것은 전체 패턴들 중에 유사하지 않은 패턴들을 분리해내는 과정으로 결국 트리의 말단(terminal)에는 유사한 사건들만 남아있게 된다[13]. 이에 따라 제안 논문에서 불완전한 데이터를 해결하는 핵심 아이디어는 결측값을 포함하는 사건(
이를 구현의 의미에서 보면 학습 데이터 중에 완전(손실되지 않은) 사건들로 C4.5/SVM 알고리즘을 사용하여 결정 트리를 생성하고, 이 결정 트리의 말단 노드에 모여 있는 정보를 이용하여 결측값의 추정치를 구한다. 즉, 손실 사건을 차례로 결정 트리에 입력하고, 경로에 따라 순회하며, 결측값과 가장 유사한 특성을 가지는 영역을 찾아간다.
본 논문에서 사용하는 분류기는 다음과 같이 서로 다른 특성을 가진다. C4.5는 정보를 가장 많이 포함하는 속성을 선택하는 기준 즉, 이득 함수가 엔트로피를 기반이므로 학습 데이터가 정수로 한정되고, 속성의 좌표와 직교의 방향으로만 분류가 이루어진다는 점이 성능에 영향을 줄 수 있다. 반면 SVM은 속성값이 정수, 실수인 모두에서 사용할 수 있고, 분류면의 방향에 제한이 없다는 점을 가지고 있다. 실제 데이터를 가지고 구현하는 과정을 통해 이러한 특성이 성능에 미치는 영향을 살펴보고 결정 트리를 구성하기 위한 노드 수도 서로 비교한다.
2장에서는 학습 데이터로부터 결정 트리를 생산하는 2가지 분류기의 특성을 소개한다. 3장은 결정 트리로부터 결측값의 추정치를 구하는 방법을 알아본다. 그리고 4장은 실험 과정을 통해 서로 다른 분류기로 구현된 성능과 결정 트리의 노드 수를 비교한다.
분류기의 역할은 전체 패턴 공간에 대해 부류(class)의 영역별로 구분하고, 입력패턴(X)을 이 구분된 공간에 사상함으로써 어느 부류에 속하는지를 결정하도록 하는 것이다. k개의 부류를 가지는 전체 패턴 공간이 n 차원일 때 Rn으로 표시하고 Rn의 공간 중에 부류 i에 할당된 공간을 Hin으로 정의하면, Rn은 부류 수만큼의 영역으로 분할된다.
Hin은 여러 개의 분류면(P)으로 구성되며, 부류 i의 영역이 여러 개로 분리되어있는 경우 이를 모두 합하여 부류 i의 영역으로 한다. 여기서 분류면을 결정하는 방법에 따라 분류기 알고리즘의 종류가 결정되는데 본 논문에서는 상반된 특성을 가지고 학습 중에 결정 트리를 만들어 가는 2가지 알고리즘을 소개하고 이들을 이용한 분류 영역을 이용해 결측값의 근사값을 구하여 이의 성능을 서로 비교한다.
C4.5 분류기[10]는 엔트로피 함수를 사용해 하향식 분할과 정복 방식으로 결정 트리를 구성해 나간다. 이 트리의 각 노드들은 하나의 속성(attribute)을 가지며 말단 노드에서는 규칙(rule)이 생성된다. 이를 완성하기 위한 과정은 다음과 같다.
1. 입력 패턴에 대해 (1) 식과 같은 Gain_ratio의 정보 이득 함수를 적용해 현 노드에서 분류하기 가장 좋은 속성(attribute, A)을 선택한다. (1) 식의 함수는 임의의 속성(A)을 선택했을 때 얻을 수 있는 정보의 획득량을 나타내며 각 속성에 적용하여 가장 큰 값을 가지는 속성을 선택하게 된다. 다시 말해 Gain_ratio 값은 같은 부류를 가지는 유사한 패턴들이 얼마나 하나의 영역에 모이게 할 수 있는지를 측정하는 척도이며, 작은 깊이(height)와 적은 말단 노드 수로 결정 트리를 구성할 수 있도록 한다. 2. 선택된 속성의 값에 따라 패턴들이 하부 노드로 전달되며 분기된다. 즉, 이 속성의 값에 따라 자식 노드를 하나씩 생성하고, 패턴들을 이 속성값에 따라 분류하여 자식 노드에 할당한다. 따라서 어느 노드의 자식 노드 수는 이 노드가 가지고 있는 속성의 cardinality 수와 같아서 포리스트(forest) 트리 형식의 결정 트리를 형성해 간다. 3. 자식 노드로 분기한 후, (2) 식의 Gain(A) 값이 0에 근접할 때(한 노드에서 부류 수가 하나가 될 때)까지 위 과정을 반복한다. 즉, 같은 부류를 가지는 사건들이 임의의 영역으로 모두 모아질 때까지 반복 실행하면 이 과정 중에 결정 트리가 완성된다.
(1) 식을 설명하기 위해 다음을 정의 한다.
⏺ S: 각 노드에서 패턴들의 집합 ⏺ |S|: 집합 S 에서 사건의 개수 ⏺ SAj: 집합 S 에서 속성 A가 j인 S의 부분 집합 ⏺ |SAj|: SAj집합에서 데이터 개수 ⏺ freq(Ci, S): S에서 부류가 Ci인 패턴의 개수, i=1,...,k
(1) 식에서 정보획득량의 척도인 Gain(A)는 (2) 식과 같이
여기서
(1) 식의 Split_info(A) 함수는 왼/오른쪽으로 결정 트리가 치우치지 않도록 하며 (3) 식과 같다.
2.2 Fisher의 선형 분리 함수를 이용한 SVM 알고리즘
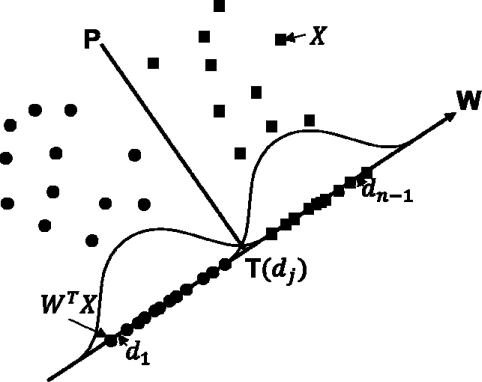
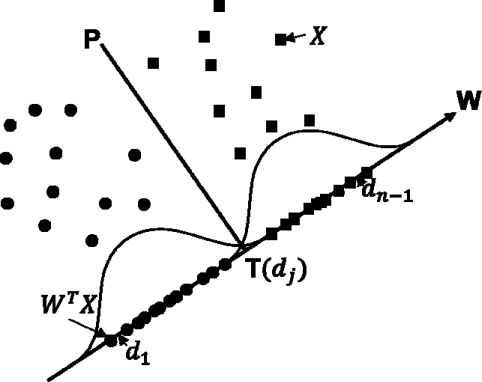
Fisher의 선형분리함수를 이용하는 분류 알고리즘은 여러 개의 분류면(hyperplane : P)으로 구성되며 분류면은 (4)식과 같이 가중치(W)와 임계값(T)으로 나타내진다.
각 노드에서 입력된 패턴들은 (5)식과 같이 P를 기준으로 왼/오른쪽(PL, PR) 노드로 이동하여 이진 트리 형태의 결정 트리를 형성해 간다.
분류면이 가중치 벡터와 임계값으로 구성되므로 패턴 분류기는 이들 W, T를 최적으로 결정하는 것이 가장 중요한 역할이다. 이에 대해 (6)식의 Fisher의 선형 분리 함수는 입력 패턴들이 이루는 임의 분포에 대해 최적의 분류 가중치 벡터(W)를 결정한다. 가중치 벡터에 따라 각 패턴들을 투사면(
(6)식을 최대로 하는 W 벡터를 얻기 위해
이제 투사면(W)에 각각의 입력패턴을 투사(WTX)하면 투사점들이 임의의 분포를 가지게 되는데 이들 투사점 사이에 각각 (7) 식과 같은 엔트로피를 구하여 가장 작은 값을 가지는 위치의
여기서 투사점들을 나열하면
xij=왼/오른쪽의 각 영역에서 부류 j 패턴의 갯수
pij = xij / ni
지금까지 과정을 단계별로 설명하면 다음과 같다.
1. 학습 패턴 데이터들을 입력 노드에 입력한다. 2. 임의의 노드에서 W와 T를 구하여 결정 트리의 현재 층에 저장한다. 3. (5)식과 같이 분류면을 기준으로 학습 패턴을 왼쪽(오른쪽) 패턴으로 분류한다. 4. 임의의 왼쪽(오른쪽) 노드에서 완전한 분류가 이루어지지 않았으면, 이 노드로 이동한 후 2번 과정을 반복한다.
3. 결정 트리에서 분류된 영역의 평균을 구하여 결측값을 처리하는 방법
결측값을 처리한다는 것은 손실되지 않은(비손실) 정보들을 이용해 손실된 정보의 추정값을 구하는 것이다[14]. 이에 관해 결정 트리를 이용하는 방법은 비손실 정보를 분류기에 입력해 결정 트리를 구성한다. 그리고 결측값을 포함하는 사건들을 결정 트리에 입력하고 순회하는 과정에서 결측값과 가장 유사한 영역을 찾아내고, 이 영역의 평균값으로 결측값의 추정치를 대체하는 것이다. 분류기의 기본 역할은 점진적으로 입력 패턴들을 분류해 유사한 정보들을 하나의 영역에 모으는 것이다.
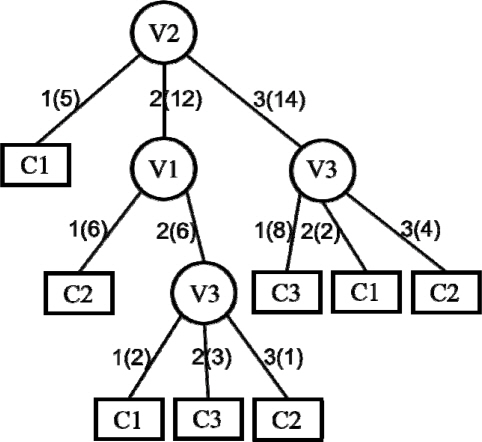
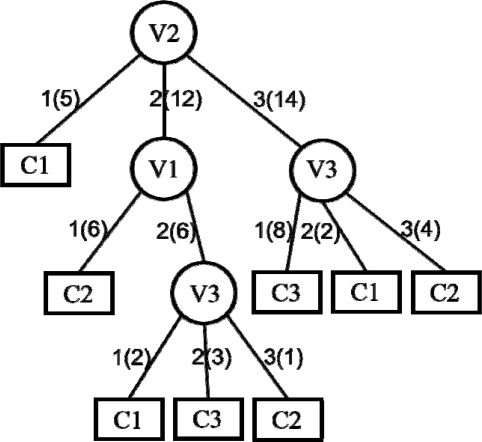
결측값을 처리하기 위한 C4.5는 먼저 전체 데이터를 손실과 비손실 데이터로 분류하고, 비손실 데이터 만으로 학습 과정을 통해 <그림 2>와 같은 결정 트리를 산출한다. <그림 2>에서 동그라미 노드는 (1)식을 가지고 선택된 변수를 의미하며, 노드와 노드 사이의 수들(ex: 1(5))은 변수값(분류된 자식 노드에 입력된 사건의 수)을 표시한다. 또한 네모 노드는 각 부류의 영역을 의미하는 말단 노드이다.
<그림 2>의 결정 트리에 {1, 3, -} 사건이 입력되었을 때, 루트 노드의 선택된 속성이 V2이므로 루트 노드에서 V2=3으로 경로를 이동한다. 그러면 현재 노드에서 V3 값에 따라 다음 노드를 순회하는데 V3의 값이 소실되었다. 이 사건의 경로를 VL 형식으로 표시하면 [V2=3][V3=?]와 같이 된다. 이때 현 노드인 V3 노드가 14개의 사건이 있고 C1, C2, C3와 같이 3개의 부류를 가지고 있다. 여기서 14개 사건에서 V3의 평균을 구하여 손실변수인 V3에 할당한다. 다음 예로 {2, 2, -}이 입력된 경우, [V2=2][V1=2] 경로로 이동한 다음 V3 노드가 손실되었으므로 V3 노드에 입력된 6개의 사건에서 V3 속성의 평균을 구하여 V3 값에 할당한다. {-, 1, 3} 사건은 [V2=1] 경로로 이동했을 때 말단 노드에 도달되어 이미 분류가 완료되었다. 따라서 C1 부류를 가지는 사건들의 평균으로 V1의 손실 변수를 채우게 된다. 마지막으로 {2, -, 3} 사건의 예는 결정 트리의 루트 노드인 V2가 손실되어 더 이상 순회 과정을 진전할 수 없다. 이런 경우 모든 학습 데이터인 29개 사건의 평균값으로 결측값의 추정치를 구한다.
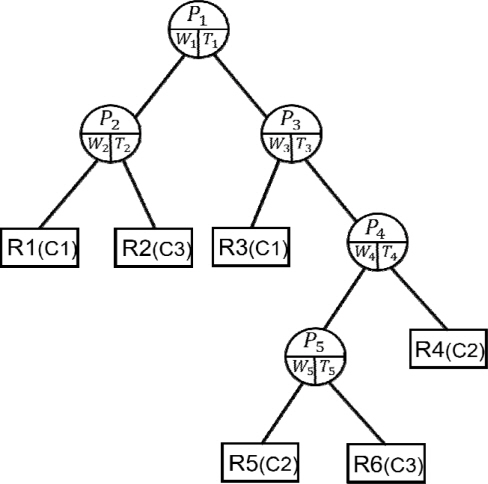
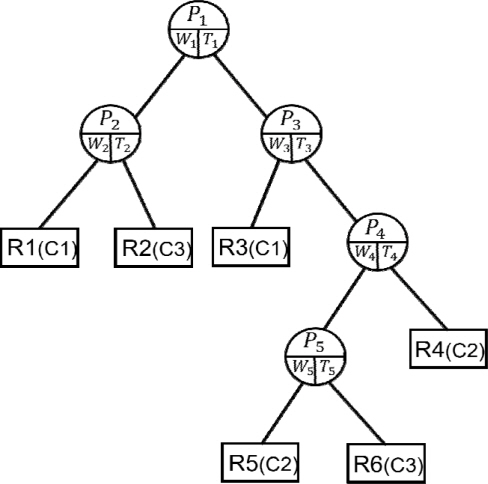
2.2절의 분류 알고리즘으로 임의의 영역에 하나의 부류만 남을 때까지 분류를 반복하면 <그림 3>의 결정 트리가 얻어진다. 여기서 동그라미 모양의 중간 노드들은 가중치(W)와 임계값(T)을 요소로 가지며, 이는 각 분류 영역을 형성하는 초평면(
이 알고리즘은 다음과 같이 단계별로 실행된다.
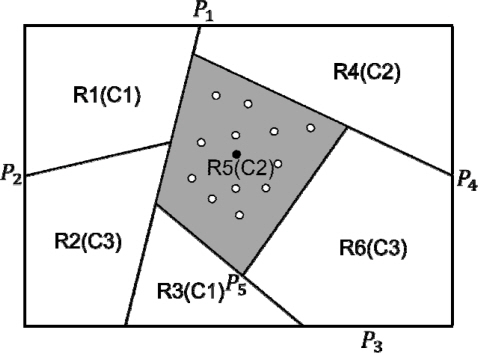
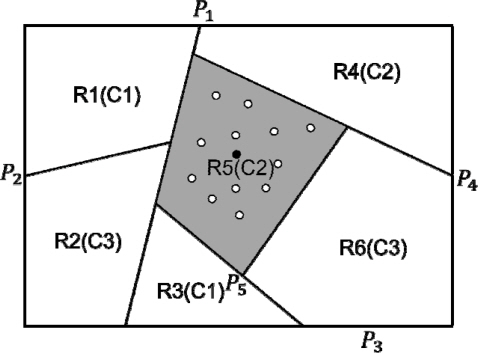
1. 학습 데이터를 손실 사건(Xe)들과 비손실 사건(Xs)들로 분리한다. 2. 비손실 사건들만을 2.2절의 SVM 알고리즘에 입력하여 결정 트리를 구성한다. 3. 손실 사건들은 단계 2의 결정 트리에 입력하여 순회 과정을 통해 결측값을 보상한다. 이 순회 과정을 자세히 설명하면 다음과 같다. 3.1. 손실 사건(Xi)을 차례로 결정 트리의 루트에 입력한다. 3.2. 각 노드에 저장된 정보(W, T)를 이용해 WTXi와 T를 비교한다. (5) 식에서 PL(PR)이면 현 노드의 왼쪽(오른쪽) 노드로 이동하는 과정을 말단 노드에 도달할 때까지 반복한다. 3.3. 결정 트리의 말단 노드에 도달했을 때, 이 노드 사건들의 평균값으로 손실 변수의 추정값에 할당한다. 예로 <그림 4>에서 R5(회색) 영역이 손실 사건에 따르는 말단 노드로 정해졌을 때, 이 영역에 있는 사건(∘)들의 평균(∙)으로 손실 사건을 대체한다.
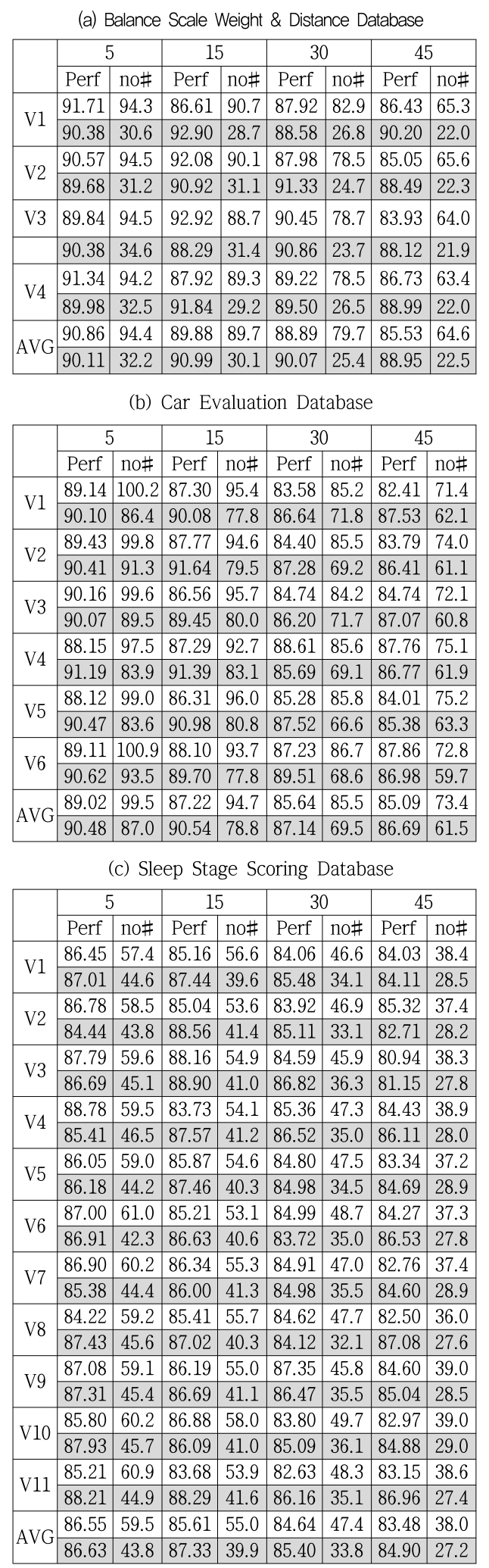
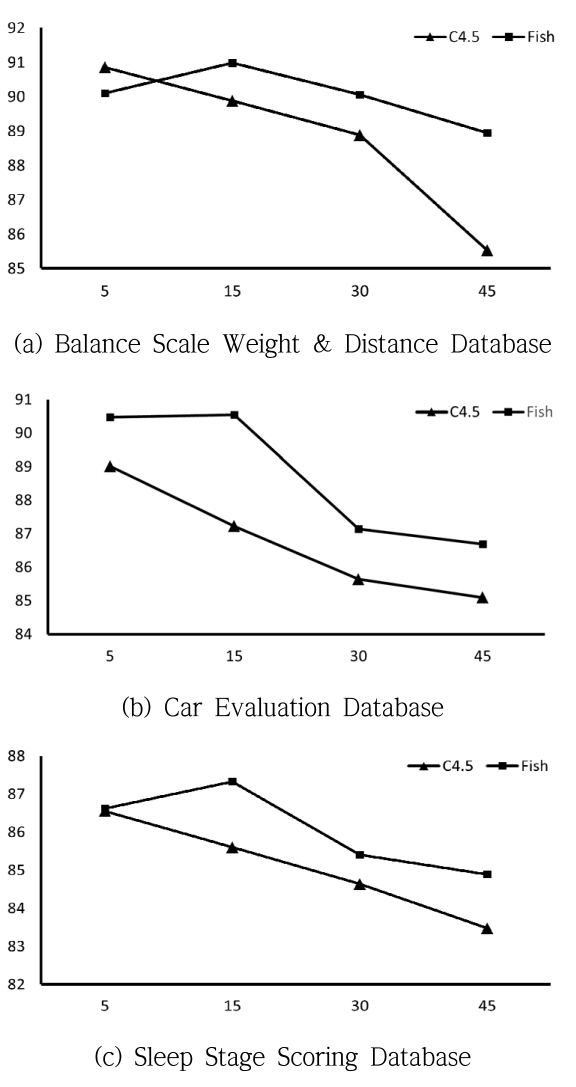
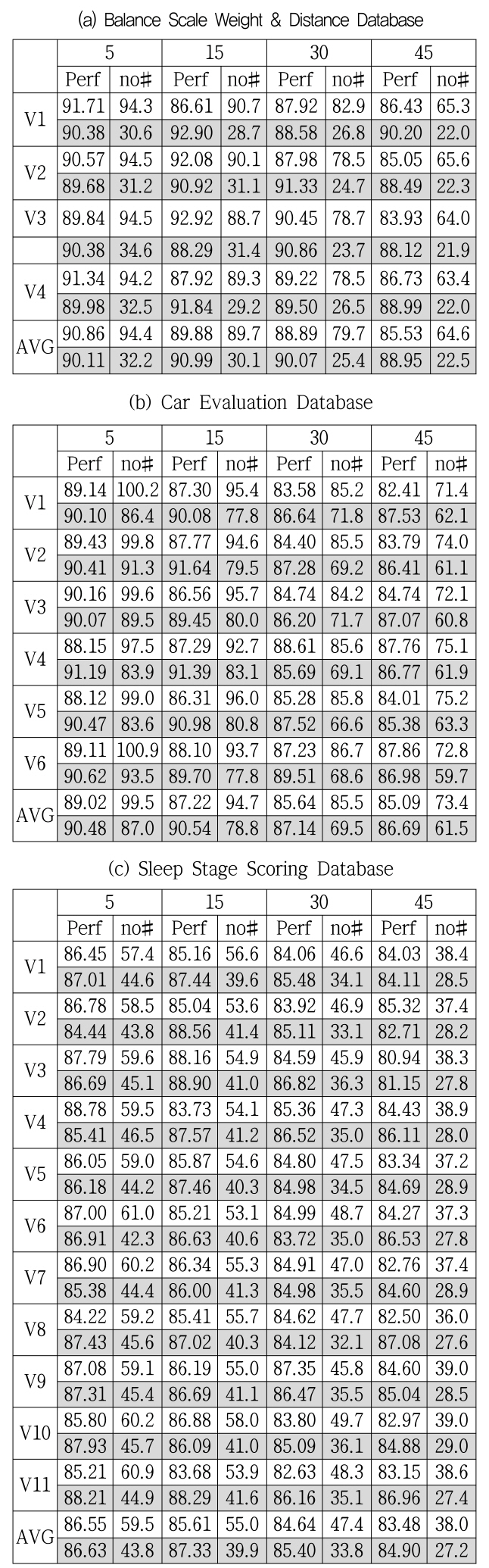
결정 트리로부터 결측값의 추정치를 구하는 알고리즘들의 구현 결과는 2가지(성능과 결정 트리에 사용한 노드의 수) 면에서 살펴본다. 실험에 사용된 데이터는 UCI 기계저장소[15]의 “Car Evolution(1728 사건, 6변수, 4부류)”와 “Balance and Scale(625 사건, 4변수, 3부류)” 데이터와 피실험자가 수면 중에 11개의 센서로 뇌파를 수집한 후 수치화하고, 6단계의 수면 상태로 분류한 “Sleep stage scoring (799 사건, 11변수, 6부류)” 데이터를 사용하였다. 성능 평가를 위한 결과 산출은 “10겹 교차 검증 방법(10-fold cross validation)”을 사용하였다. 즉 학습 데이터의 각 변수에 대해 4가지 손실률로(5%, 15%, 30%, 45%) 손실시키며 결과를 알아보았으며 이 과정을 10번 반복한 후 평균을 산출하였다. 이에 대한 결과가 변수의 손실률 별로 <표 1>에 나타나는데, 변수와 손실률이 만나는 셀에서 위 줄(하얀색)은 C4.5로 결정 트리를 구성하는 방법의 결과이고, 아래 줄(회색)은 Fisher의 선형분리식을 이용한 방법의 결과이다.
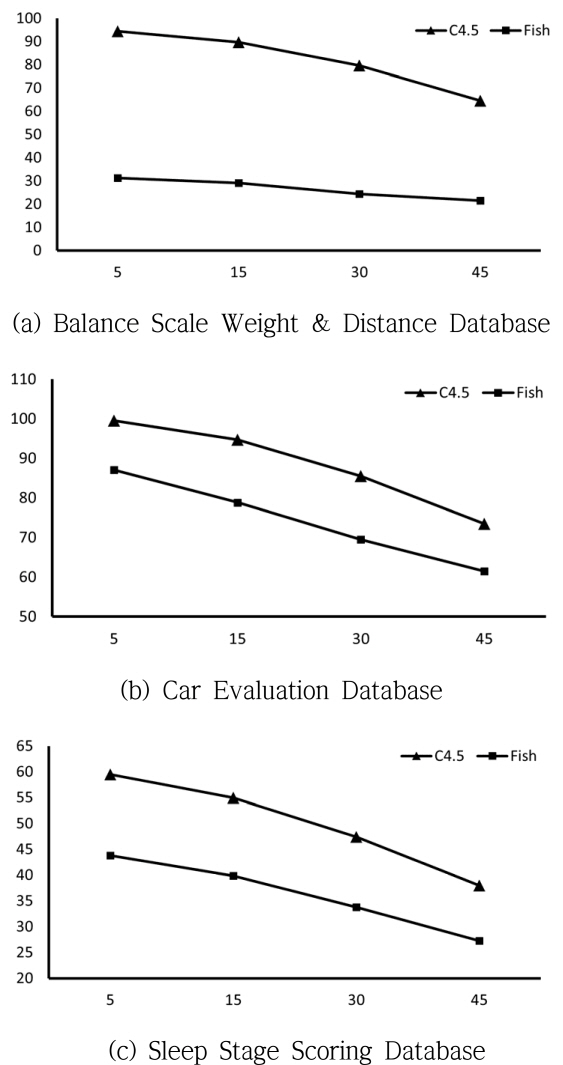
다음으로 분류 알고리즘에서 학습 중에 결정 트리를 완성할 때까지 사용한 노드들도 <표 1>에서 비교해 보았다. C4.5의 결정 트리는 변수의 카디너리티에 따라 분기되는 포레스트 트리 형식을 가지고, Fisher의 식을 이용한 SVM의 결정 트리는 이진 트리 형식으로 말단 노드를 포함한 모든 노드의 수를 비교 대상으로 하면 C4.5가 불리하므로 중간 노드의 수만을 표시하였다. 중간 노드는 분류면(P)을 표현하는 의미가 있어 노드의 수가 적다는 것은 입력패턴에 대해 “효율이 높은 분류를 한다” 또는 “성능이 높다”라는 관계와 연관된다. 실제로 노드의 수와 성능은 반비례하는 관계가 있음을 실험 결과에서 확인할 수 있었다.
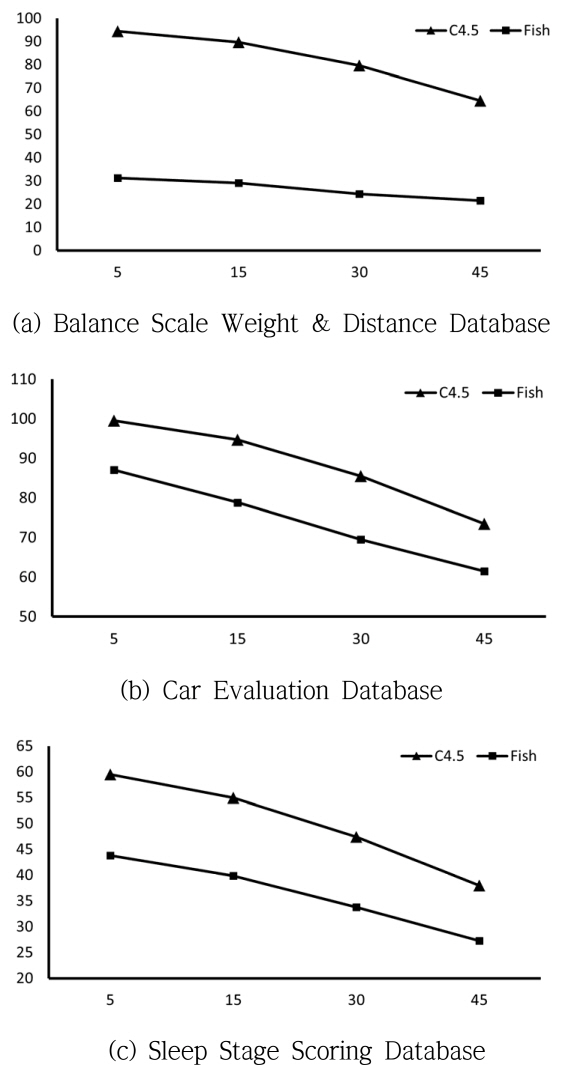
실험 결과
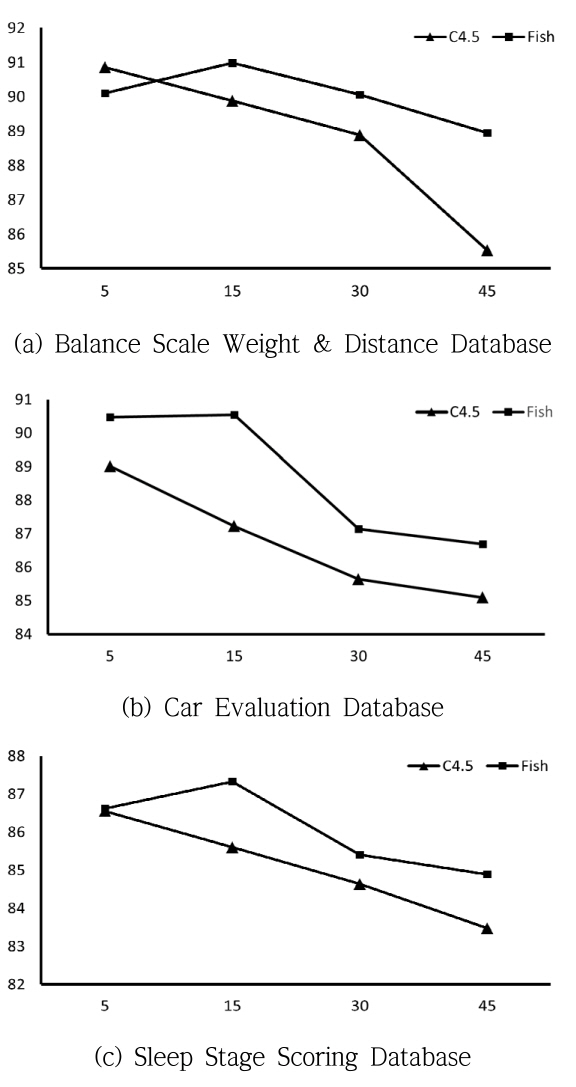
<표 1>의 결과는 수치로 표현되어 변수 또는 손실률에 따르는 변화를 쉽게 파악하기 힘들 수 있어 이들 실험 데이터를 그래프 형식으로 표시한 것이 <그림 5>와 <그림 6>에 나타나 있다. 그래프에서 C4.5 알고리즘을 사용한 결과는 “C4.5”로, Fisher의 선형 분리함수를 이용한 방법은 “Fish”로 표시하였다. <그림 5>는 <표 1>의 도표에서 손실률에 따르는 각 변수의 평균(“AVG”)를 그래프로 나타낸 것으로 가로축은 손실률을 세로축은 성능을 나타낸다. 이 결과의 대부분에서 “Fish”의 결과가 우수한 것으로 나타났다. 이와 유사한 결과는 결정 트리 중간 노드 수의 평균을 표시한 <그림 6>에서도 확인할 수 있는데 여기서는 “Fish”의 결과가 현저하게 적은 노드를 사용하여 결정 트리를 구성하는 것을 확인할 수 있다. 이와 같은 결과는 “C4.5”가 변수와 직교한 방향으로만 분류하는 한정된 분류면을 가지는 알고리즘인데 반해, “Fish”는 Fisher의 선형분리함수를 사용하여 분류면의 각도가 자유로운 것에 대한 결과로 해석된다.
지금까지 2가지 분류기를 이용하여 결정 트리를 구성하고 이 결정 트리들로부터 손실된 사건을 포함하는 불완전한 데이터를 처리하는 방법에 대해 살펴보았다. 이 방법의 핵심은 결정 트리의 말단 노드에는 유사한 정보들이 모여 있다는 것이다. 이에 따라 손실 사건들을 결정 트리의 특성에 따라 순회를 하여 손실 사건과 가장 유사한 정보를 가지는 말단 노드를 찾는 과정을 살펴보았다. 그리고 이 노드 사건들의 평균 정보를 이용해 손실된 속성의 추정치를 구하였다.
본 논문에서는 분류기로 서로 다른 특성을 가지는 C4.5와 SVM 계열의 2가지를 사용했고, 제시된 이론에 따라 구현된 각각의 성능과 구현 과정에서 사용된 노드의 수를 비교하였다. 일반적으로 분류기의 성능과 사용 노드 수는 반비례하는 것으로 알려져 있다. 즉 성능이 좋은 분류기는 입력패턴에 대해 근사 최적의 분류면들을 반복적으로 정하며 불필요한 노드들을 만들지 않는다는 것이다. 실제로 <표 1>과 <그림 5>, <그림 6>의 구현 결과들로부터 C4.5에 비해 SVM의 결과가 우수한 것으로 나타났다. 물론 결정 트리의 구조와 구성하는 방법의 차이는 있고, 학습 데이터의 차이에 따른 결과의 변화가 다소 있을 수 있으나 제시한 결과를 뒤집는 변화는 없을 것으로 본다. C4.5는 속성 벡터에 직교 방향의 분류면을 가지는 반면, SVM은 자유로운 각도로 분류면을 정하기 때문이다. 즉 대부분의 데이터들은 속성 벡터와 무관하게 임의의 패턴들을 가지고 있어 SVM이 효율적인 분류를 하기에 유리하다고 해석한다.
앞으로 제시한 두 분류기가 절단(pruning) 과정을 통해 약한 분류기(weak learner)를 구성할 수 있으므로 Adaboost와 같은 알고리즘으로 새로운 실험을 하고 비교해 볼 수 있을 것으로 본다.