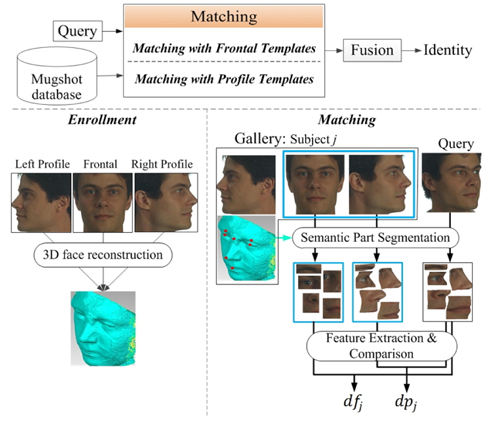
Mugshot face images, routinely collected by police, usually contain both frontal and profile views. Existing automated face recognition methods exploited mugshot databases by enlarging the gallery with synthetic multi-view face images generated from the mugshot face images. This paper, instead, proposes to match the query arbitrary view face image directly to the enrolled frontal and profile face images. During matching, the 3D face shape model reconstructed from the mugshot face images is used to establish corresponding semantic parts between query and gallery face images, based on which comparison is done. The final recognition result is obtained by fusing the matching results with frontal and profile face images. Compared with previous methods, the proposed method better utilizes mugshot databases without using synthetic face images that may have artifacts. Its effectiveness has been demonstrated on the Color FERET and CMU PIE databases.
Mugshot face images are widely used for identity recognition in forensic and security applications. They usually consist of frontal and profile face images, which are routinely collected by police. The frontal and profile face images provide complementary information of the face, and are thus believed to be useful for pose-robust face recognition if both of them are effectively utilized. However, most existing automated face recognition methods [1-3] are devised for the scenario of only frontal face images in the gallery. To recognize non-frontal faces, they usually adopt one of the following three ways: (i) Normalizing the non-frontal probe face to frontal pose and matching it to the enrolled frontal faces [4-6], (ii) Generating synthetic face images from the frontal faces in the gallery according to the pose of the probe face, and then comparing the probe face with these synthetic face images [7, 8], (iii) Extracting pose-adaptive features directly from the gallery and probe face images for comparison [9, 10].
When both frontal and profile face images are available in the gallery, in order to utilize the profile face images to better recognize arbitrary view faces, Zhang
This paper proposes a novel approach to better use mugshot face images to deal with arbitrary view face recognition. Unlike previous approaches, we directly compare probe face images to both frontal and profile gallery face images with assistance of 3D face shape models reconstructed from the gallery mugshot face images. This way, it gets rid of potential artifacts in synthetic face images, and meanwhile effectively exploits the information in both frontal and profile face images. Experiments performed on two challenging public face databases, Color FERET [13] and CMU PIE [14], have proven its effectiveness.
The remainder of the paper is organized as follows. Section II introduces in detail the proposed mugshot based arbitrary view face recognition approach. Section III reports the experimental results on the Color FERET [13] and CMU PIE [14] databases along with some discussion on the results. Finally, a conclusion is drawn in Section IV.
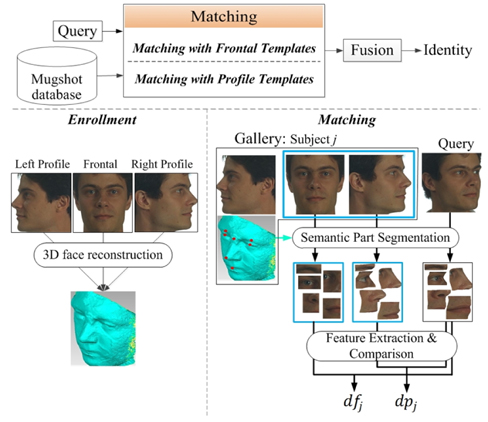
An overview of the proposed approach is depicted in Fig. 1. As can be seen, it includes two phases: enrollment and matching.
During enrollment, mugshot face images are captured. Here, we assume that three face images of each subject are included, i.e., frontal, left and right profile face images. This is a conventional configuration in forensic mugshot databases. Based on these three face images, the 3D face shape is reconstructed for each subject by using the method in [15]. Motivated by the component-based face recognition method in [16], we define on the frontal faces a set of local patches (called semantic parts in this paper) around the following seven facial fiducial points: two eyebrow centers, two eye centers, nose tip, nose root, and mouth center (see Fig. 1 and Fig. 2). When a face changes its head pose, these patches will deform according to the pose angles. The deformed patches of a subject under different poses can be easily computed by transforming his/her 3D face shape, and features are extracted from semantic parts on the frontal and profile face images as enrolled templates.
Given a new query face image to be recognized, its head pose is estimated and fiducial points are located. To compare it with a subject in the gallery, its semantic parts are segmented according to its head pose and the subject's 3D face shape. Features are then extracted from the semantic parts, and compared with the enrolled templates. Matching results with the enrolled frontal and profile templates are fused to give the final recognition result, i.e., the identity of the query face image. Next, we introduce in detail the matching steps.
2.1. Semantic Part Segmentation
Segmenting the semantic parts (i.e., deformed local patches around fiducial points) is the key of the proposed approach to handle arbitrary view face images. An essential difficulty in recognizing arbitrary view face images is due to the non-linear deformation occurring to 2D face images when rotating the face in 3D space [10]. To compute the distance between two face images that have different pose angles, it is important to find their corresponding semantic parts because comparison between different semantic parts is nonsense.
In this paper, we consider the following semantic parts. For each enrolled subject, we first project its 3D face shape to 2D plane via orthogonal projection to get a frontal face image. We define ten local patches w.r.t. the seven fiducial points on the 2D frontal face image (See Fig. 2(a)). These patches are then mapped back to the 3D face shape to get the semantic parts in 3D space. Without loss of generality, we assume that the inter-ocular distance is about 90 pixels, and sizes of the semantic parts are then scaled as follows:
⋅Eyebrow - 20×50 pixels
⋅Eye - 40×45 pixels
⋅Mouth - 55×50 pixels
⋅Nose root - 55×50 pixels
⋅Nose tip - 60×50 pixels
In order to get the semantic parts on an arbitrary view 2D face image to be matched with the subject, the above defined semantic parts have to be projected onto 2D face images. This is done by estimating a 3D-to-2D projection based on the corresponding fiducial points in the 3D face shape and the 2D face image. Let {

where the projection
2.2. Feature Extraction and Comparison
Extracting features from an arbitrary view 2D face image consists of two steps. First, visible semantic parts are segmented according to the head pose of the 2D face image. For example, for frontal and nearly-frontal 2D face images, all semantic parts are visible and will be used for feature extraction and comparison; for left-profile and nearlyleft-profile 2D face images, only the semantic parts on the left side of the face are visible, and thus to be considered. Second, once the semantic parts have been segmented from the 2D face image, certain features are extracted from them. In this paper, we extract local binary pattern (LBP) features [17] for the sake of simplicity, but other more elaborated features could be used also.
To compute the distance between two face images, their corresponding visible semantic parts are first determined. The distances between these semantic parts are then computed. In this paper, we employ the chi-square distances for LBP features of the semantic part defined as
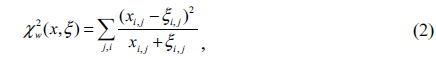
in which
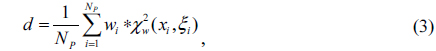
where
2.3. Fusion of Frontal and Profile Comparisons
If the probe face image is frontal or near frontal (i.e., facing [-15, 15] degrees), it is directly compared with the enrolled frontal face templates. Otherwise, it will be compared with both frontal and profile templates, and matching results will be fused.
Let
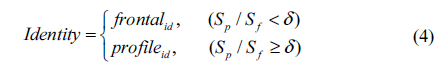
where
In this section, we evaluate the proposed approach on the Color FERET [13] and CMU PIE [14] databases. Color FERET database contains face images of 768×512 pixels with multiple pose variations (see Fig. 3). Among them, we manually remove the face images whose poses are inaccurately labelled, resulting in 461 subjects used in the experiments. CMU PIE database consists of 884 face images of 68 persons under 13 various poses. The size of these face images is 486×640 pixels. For all the face images, facial fiducial points are manually marked, and they are then normalized to 233×187 pixels by affine transformation based on the fiducial points.
In order to evaluate the effectiveness of comparing deformed semantic parts, we also implement a method that uses the same local features as the proposed method, but extracts features from regular (rather than pose-deformed) local patches (baseline) [17]. In addition, a commercial off-the-shelf face matcher, VeriLook [18], is also considered in the comparison experiments.
Table 1 reports the rank-1 and rank-10 recognition accuracy of different methods on Color FERET at various yaw angles. It can be seen that the proposed method works consistently well under varying yaw angles. When yaw angles are larger than 60 degrees, the proposed method still achieves about 80% rank-1 recognition accuracy, whereas the accuracy of the counterpart methods drastically decreased to about 60% or even lower than 30%.
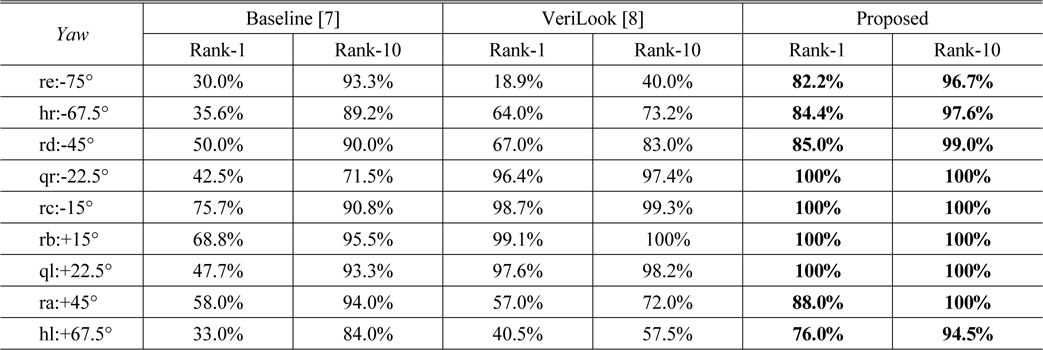
Rank-1 and Rank-10 recognition accuracy of different methods: Using regular patches [17] (Baseline, for short), VeriLook [18] and Proposed deformed patches (Proposed, for short) on the Color FERET database [13] at various yaw angles
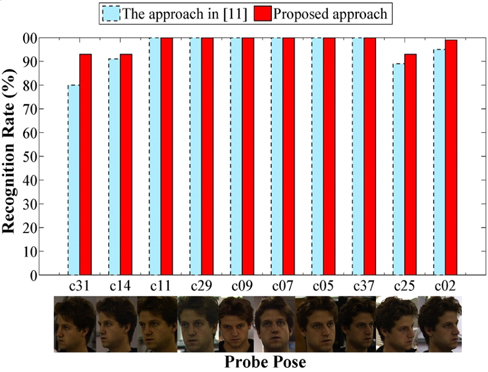
We also compare the proposed method with the one in [11]. It is the only published research work we are aware of that reported mugshot-based face recognition accuracy on the CMU PIE database. For a fair comparison, following the protocol in [11], we choose pose c27 as the frontal face, and c22 and c34 as the left profile face and right profile face, respectively. The remaining 10 poses of 68 persons are considered as probe images. The results are shown in Fig. 4, which again proves the effectiveness of the proposed method in recognizing face images of large pose angles. The rank-1 accuracy of the proposed method is better than the one in [11] especially for large poses (i.e., c31, c14, c25, c02). The recognition rate of the method in [11] for pose c31 is 80%, whereas our recognition rate reaches 93%. The rank-1 accuracy of the proposed method is firmly higher than the other one across poses. The mean accuracy among various poses of probe images by our method and the method in [11] are 97.8% and 95.5%, respectively. The standard deviations across various probe poses by them are 3.32% and 6.86%, respectively.
The superior performance of the proposed method is likely due to several factors. (i) The semantic parts are much more robust to distortions caused by pose variation. (ii) The semantic parts provide pixel-level matching rather than matching local patches around facial fiducial points. (iii) The proposed method can enlarge the inter-class variation thanks to the specific-subject 3D face model to segment the semantic parts. Figure 5 shows some example off-angle probe face images and the results by the proposed and baseline methods.
This paper proposed a method to better utilize mugshot databases to recognize arbitrary view face images. It directly matches probe face images to frontal and profile gallery face images based on their corresponding semantic parts. Compared with previous methods, it not only makes better use of both frontal and profile face images, but also avoids synthesizing novel view face images, which often contain artifacts. Evaluation results on public databases have demonstrated the effectiveness of the proposed method in recognizing large off-angle face images. A major limitation of the proposed method is its relatively high computational cost. According to our experiments using Matlab R2012b on an Intel core i5 2.60-GHz desktop computer with 4-GB memory, the proposed method takes, on average, around 9 seconds to recognize a probe face from a background database of 68 subjects. In the future, we will improve the efficiency, investigate automatic facial fiducial point detection methods, and explore more semantic parts and advanced local features.



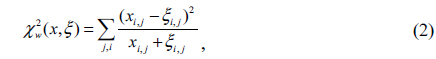
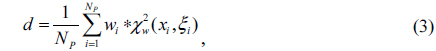
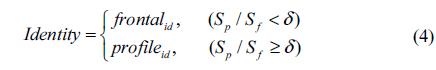
![Example multi-view face images of two subjects in the Color FERET database [13].](http://oak.go.kr/repository/journal/20681/E1OSAB_2016_v20n2_239_f003.jpg)
![Rank-1 and Rank-10 recognition accuracy of different methods: Using regular patches [17] (Baseline, for short), VeriLook [18] and Proposed deformed patches (Proposed, for short) on the Color FERET database [13] at various yaw angles](http://oak.go.kr/repository/journal/20681/E1OSAB_2016_v20n2_239_t001.jpg)
![Rank-1 recognition accuracy of our proposed method and the method in [11] on the CMU PIE database [14].](http://oak.go.kr/repository/journal/20681/E1OSAB_2016_v20n2_239_f004.jpg)
![Example off-angle probe face images from the Color FERET database [13] and the results obtained by the proposed and the baseline methods. The first to third columns show, respectively, the probe face images, the rank-1 gallery face images identified by the baseline method, and the rank-1 gallery face images identified by the proposed method. The table gives the rank of the true gallery face images for these probe images obtained by the two methods.](http://oak.go.kr/repository/journal/20681/E1OSAB_2016_v20n2_239_f005.jpg)