The purpose of this study was to investigate whether the degree of difficulty in the integration of a word into a sentence could be determined by not only how likely the word would be for a given context but also how likely the thematic role associated with the word would be to occur. For our aim, we used dative sentences in Korean in which three arguments (i.e., agent, recipient, and patient/theme) appeared prior to a sentence-final verb. We manipulated 1) the degree of role predictability corresponding to the third argument by scrambling the internal arguments that occurred after an agent and 2) the predictability of words corresponding to the third arguments that was either highly likely or unlikely for a given context. A self-paced moving window reading with a secondary judgment task was conducted. A linear mixed-effect regressions on the reading times of the words corresponding to the third arguments was run while controlling for the effects of lexical frequencies and lengths on the processing of target words. The results from the model revealed that the words were read faster when they were highly likely for given contexts than when they were unlikely, and importantly, that the words were read faster when the roles associated with the words were strongly expected than when they were weakly expected. Our results showed that both role predictability and word predictability had independent effects on the processing of a word in a sentence. We claim that a processing model should be loaded with at least two components that take into account role predictability as well as word predictability.
One of characteristics of human sentence comprehension is that readers integrate incoming information into sentences incrementally and immediately without waiting for the moment that they become completely clear where to integrate incoming information into. The maximum case of incrementality and immediate processing is often discussed under the aspects of expectation (Altmann & Mirković, 2009; Elman, 1990; 2009). Namely, sentences are processed even anticipatorily in a way that more expected information is easier to be integrated than less expected information (Ashby, Rayner, & Clifton, 2005; Bicknell, Elman, Hare, McRae, & Kutas, 2010; Ehrlich & Rayner, 1981; Frisson, Rayner, & Pickering, 2005; Staub, 2011; DeLong, Urbach, & Kutas, 2005; Federmeier, Wlotko, De OchoaDewald, & Kutas, 2007; Otten & Van Berkum, 2008; Van Berkum, Brown, Zwitserlood, Kooijman, & Hagoort, 2005).1 The easier processing of more expected words or phrases is possible, presumably, because more expected words or phrases are more strongly activated than less expected ones which in turn more activated information requires less amount of processing effort in processing (c.f., Hale, 2001; Levy, 2008).
The expectation-based comprehension could take place at multiple levels. For example, given the sentence fragments like (1), readers might have syntactic expectation that they would encounter a direct object in the form of a noun phrase. Or, they might exploit the participant role information encoded by the verb,
As illustrated above, although it is not intuitively difficult to follow that readers’ expectation could develop at multiple levels, it is not empirically evident yet whether the expectation taking place at each level would actually have its independent effect on sentence comprehension. In this paper, our goal was to explore this issue. In particular, we pinned our primary focus on whether the effect associated with thematic role expectation would be independent from or might be mediated through the effect associated with word expectation on sentence comprehension.
By doing so, we attempt to test two existing claims. First, one of the predominant views in computational modeling has posited that the effect due to the simultaneous activation occurring at multiple domains during online comprehension can be fully mediated by the predictability of word for a given context (i.e., word expectation). Thus, how likely a word would be in a given context could play a role as a perfect mediator in predicting the degree of processing difficulty, as illustrated in Equation (1), (Boston, Hale, Patil, Kliegl, & Vasishth, 2008;
Processing difficulty ∝ -logP (wi | w1…i-1 , CONTEXT) Equation (1) In this study, we argued that head-final languages, not head-initial languages, provide appropriate condition to test the effects of role expectation and word expectation during online sentence comprehension. Unlike the predominant claims by previous studies, we proposed to test a hypothesis that both thematic role predictability and word predictability have effects on proc in the integration of words into sentences.
1.1 Issues on Role Predictability vs. Word Predictability
In the psycholinguistic literature, there have been arguments on what exactly facilitates the processing of words or phrases associated with arguments encoded by verbs. On the one hand, studies have showed that the verb’s argument information is anticipatorily used to facilitate the processing of words or phrases corresponding to the roles encoded by verbs. Using a visual world paradigm in which participants saw a depicted picture on the computer screen while they were listening to a sentence, Altmann and Kamide (1999) demonstrated that the verb’s argument information led to participants’ anticipatory looks to the objects that were not auditorily expressed yet. For example, participants looked at a picture depicting a boy sitting on the floor surrounded by objects like a cake, a toy train, a toy ball, and a toy helicopter while they were listening to a sentence. They launched their eyes to the depicted
The anticipatory use of the verb’s argument information was found in wh-filler gap studies (Boland, Tanenhaus, Garnsey, & Carlson, 1995). Using nonsensical and sensible wh-filler gap sentences, Boland et al. (1995) observed immediate anomaly effects in gap filling before the occurrence of explicit evidence for a gap that fronted wh-fillers were to be filled in. For instance, in sentences like
The anticipatory use of the verb’s argument information was found in the processing of active declarative sentences (Yun, Mauner, & Koenig, 2006; Warren, McConnell & Rayner, 2008). Using sentences like
On the other hand, in contrast to the view emphasizing on the effect of the verb’s argument information, there is another view claiming that the situational (world) knowledge embedded in the prior context, not the verb
In the situational knowledge-based view, the effect elicited by the verb’s argument information during comprehension might not be necessarily independent beyond the effect elicited by the use of the situational knowledge in context (Hare, Jones, Thomson, Kelly, & McRae, 2009). For example, the results of Altmann and Kamide (1999) could be re-explained without putting an emphasis on the effect of the verb’s argument information. In their study, listeners might actively use the situational information from the context;
Although the situational knowledge-based approach has attempted to explain many previous findings in its view, the approach has not actually provided convincing evidence that the verb’s argument information does not play an independent role in sentence comprehension. Moreover, the claim by the situational-based approach could be challenged by the findings of Boland (2005) in which in her Experiment 1, visual objects corresponding to arguments received more anticipatory looks than visual objects corresponding to adjuncts, regardless of how likely auditory words referring to visual objects were for given contexts. Even unlikely argument objects received anticipatory looks.2 That is to say, it is not properly investigated yet whether the anticipatory effect by the verb’s argument information has additional contribution to sentence comprehension or might be entirely mediated through the anticipatory effect driven by the situational knowledge. For clear understanding, a fair test should be able to examine the effect of word expectation on the integration of words into sentences as a function of whether the expectation of roles corresponding to words is strong or weak.
Having a fully factored design of role and word expectation is not easy, especially, if head-initial languages like English are used. In part, this is related to the fact that when verbs are processed before arguments encoded by the verbs appear, the recognition of the verbs automatically leads to assigning thematic roles to to-be-encountered words (i.e., role fillers). As a result, thematic roles associated with those words are expected to encounter in any way, regardless of how likely word (i.e., role filler) would appear. For example, in Bicknell et al. (2010)’s study, the thematic role for
A similar difficulty was found in Boland (2005). She observed the typicality effect that visual objects received more anticipatory looks when they were likely than when they were unlikely during the temporal window of 500-1000ms from the verb onset. Crucially, the effect appeared only when likely and unlikely objects were depicted together in the same visual scenes and the typicality effect occurred regardless of whether auditory words corresponding to those visual objects were arguments or adjuncts (Experiment 2). However, the same typicality effect did not emerge when likely and unlikely objects were presented separately and the anticipatory looks to either likely or unlikely objects always occurred more when auditory words corresponding to visual objects were arguments than when auditory words corresponding to visual objects were adjuncts (Experiment 1). Boland (2005)’s results also suggested that testing word expectation and role expectation independently was not easy in head-initial language, English.
In a nutshell, using head-initial languages, it was feasible to manipulate and test the effect of word expectation in sentence comprehension without considering the issue of role expectation. Or, vice-versa, it was fair to test the effect of role expectation during sentence comprehension without considering the degree of how likely a word would be as a role filler for a given context. However, when the two types of expectation have to be considered, it was not clear and easy to test the effect of each type of expectation independently. As a solution, we propose to use head-final languages like Korean as a target language to examine our issue. The following section serves to explain how using Korean could be a way to investigate our question.
1.2 Head-final Language as a Target Language
In Korean like many other head-final languages, verbs appear sentencefinally and scrambling constituents is allowed. Notice that verbs in Korean cannot assign thematic roles anticipatorily to the arguments that the verbs encode in a similar way that thematic roles are assigned anticipatorily upon the recognition of verbs in head-initial languages. In what follows, we introduced two studies demonstrating that the anticipatory role assignments in head-final languages could take place by other grammatical constraint such as case markers, although the integration of arguments should be completed later on at verbs.
First, Kamide, Altmann, and Haywood (2003) have showed that the case-marker information in Japanese resulted in eliciting the expectation of upcoming thematic roles. In their visual-world study, listeners looked at a picture describing a waitress was approaching to a customer sitting next to a dining table where a plate of hamburger was put on, while they were listening to sentences like (2a) or (2b). The researchers observed anticipatory looks to depicted objects (e.g., hamburger) referring to patient roles at adverbial positions (e.g., merrily), prior to the explicit mention of the objects, when listeners heard recipients (e.g., customer-DAT) attached with dative case markers (i.e.,
Second, similar results were also observed in the processing of Korean dative sentences. Hong, Nam, and Kim (2012) conducted an eye-tracking reading study using sentences like (3a-b). They observed that readers took longer to read the phrases of patients and recipients, in order, such as sentences like (3b) than the phrases of recipients and patients, in order, such as sentences like (3a), in the measurements of second-pass reading times, total gaze durations, and regressions. The results of Hong et al. (2012) and Kamide et al. (2003) have revealed that in the processing of dative sentences, Korean and Japanese language processors seemed to develop the expectation of upcoming patient roles when recipient roles were provided, but not
In order to make it sure that the degree of role expectation as a function of the presentation order of thematic roles was a significant factor to predict the degree of processing difficulty, Yun, Nam, and Hong (2013) built a probability-based statistical model on Hong et al.’s eye-tracking data. First, using the Hong et al.’s experimental materials in a cloze task, the researchers estimated the degree of role expectation per item by computing the conditional probability of an upcoming role for a given context. The results of the cloze task revealed that the mean conditional probability that patient/theme roles would occur after the presence of recipients was a way high at .84, whereas the mean conditional probability that recipient roles would occur after patients/themes was extremely low at .04. Yun et al.’s cloze results were consistent to the corpus results by Choi (2007). Using Sejong corpus, she showed that dative sentences where recipients with dative markers appeared before patients with accusative markers (i.e., 86% - 598 out of 712 tokens) occurred more frequently than dative sentences where patients with accusative markers appeared before recipients with dative markers (i.e., 16% - 114 out of 712 tokens). Both Yun et al.’s cloze results and Choi’s corpus results confirmed that the order of recipients and patients was canonical in Korean dative sentences.
Second, Yun et al. (2013) built a statistical model by submitting the conditional probability of roles as a predictor on the eye-tracking measurements of Hong et al. (2012) while controlling for the effect of the lengths and lexical frequencies of target words. The results of the model yielded that the conditional probability of thematic roles significantly predicted the processing difficulty that Hong et al.’s participants had in their measurements of second pass reading times, total gaze duration, and regression. That is, the reading times of the phrases (recipient + theme, or theme + recipient) took longer as the degree of the conditional probability of thematic roles increased. Yun et al. (2013) demonstrated that the canonicality effect in the processing of Korean dative sentences could be accounted for under the notion of expectation-based sentence comprehension.
Taken together, studies using head-final languages like Korean and Japanese suggested that the expectation of thematic roles could occur in the sequences of arguments attached with case markers. Importantly, the degree of role expectation by the canonical order had significant effects on sentence comprehension. Phrases of canonically ordered arguments were of strong role expectation and easy to process, whereas, phrases of noncanonically ordered arguments were of weak role expectation and difficult to process. However, there was one lacking point in these studies. They examined the expectation-based sentence processing at the level of thematic roles but have not investigated how the degree of processing difficulty could be influenced by the expectation of words aside from or in addition to the expectation of roles. This lacking part is what we attempted to investigate in our study. In particular, our goal was to test whether the expectation of thematic roles could play an independent role in predicting the degree of difficulty in the integration of words into sentences, in addition to the expectation of words.
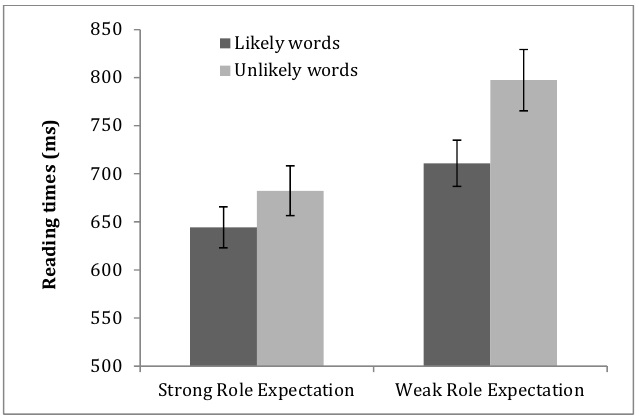
We hypothesized that role expectation and word expectation, respectively, would have independent effects on sentence comprehension. If our hypothesis were correct, we predicted that it would be the easiest to integrate words into sentences when the words were highly likely for given contexts and the thematic roles associated with the words were strongly expected. However, if words were unlikely and the roles associated with the word were weakly expected, the integration of the words into sentences would be the most difficult. More precisely saying, we proposed to test three hypotheses. First, the words whose roles are strongly expected would be easier to process than the words whose roles are weakly expected. Second, the words that are highly likely for a given context would be easier to process than the words that are unlikely for a given context. Consequently, third, the highly-likely words whose roles are strongly expected would be the easiest to process, whereas the least-likely words whose roles are weakly expected would be the most difficulty to process.
1For clarification, we use the terminology ‘expectation’ or ‘predictability’ broadly without making specific distinctions. Thus, the effect of expectation refers to the situations on either when particular information is anticipated, prior to its presence, leading to easy processing or when particular information might not be anticipated but easy to integrate into a sentence at the moment of its presence. 2We appreciate an anonymous reviewer’s comment to point out Boland (2005)’s results for this matter.
We planned to test our hypotheses by examining the processing of Korean dative sentences in which three arguments appeared before sentence-finally occurring verbs. Our study was conducted in an order that is illustrated in Figure 1. First, a cloze task (Taylor, 1953) was run to measure the degree of role expectation. In this measure, we computed the likelihood of the third argument occurring given the consecutive presentation of the two previous arguments. Second, a listing task was run to build the probability distribution of possible words that would fit to the role corresponding to the third argument as role fillers. The results of the listing study were also used in order to select experimental items for our online reading study. Third, an online reading study was conducted in order to obtain readers’ behavioral responses (i.e., reading times per a presentation unit). Finally, with the probability measures on roles and words being submitted as predictors, a linear mixed-effect regression model was built on the reading times of target words.
2.1 Measuring Role Predictability
The role predictability refers to the likelihood of the third argument occurring given the consecutive presentation of two arguments; that is, how likely patients/themes would occur after the presentation of recipients given sentence fragments like (4a) or how likely recipients might appear following the presentation of patients/themes given sentence fragments like (4b). With respect to the Yun et al. (2014)’s results, we expected that the occurrence of patients/themes after recipients would be highly likely whereas the occurrence of recipients after patients/themes would be unlikely.
69 students attending at Konkuk University took part in the cloze task as a part of class activities. They were asked to complete sentence fragments like (4a-b) with whatever came up into their minds at first. We collected 2578 numbers of completions after removing 24 ungrammatical or irrelevant responses (e.g., vulgar expression). Then, we coded the completions by their semantic categories. The key part in coding was whether the completions produced in sentence fragments like (4a) were noun phrases associated with recipients and whether the sentence completions produced in sentence fragments like (4b) were noun phrases associated with patients or themes.
As found in Yun et al. (2013), the proportions that patients/themes were produced when agents and recipients were presented like (4a) (
2.2 Measuring Word Predictability
The word predictability indicates how likely a specific word associated with relevant roles would be as a role filler for a given context. That is, in sentence fragments like (4a), we were interested in figuring out the probability distribution of possible words as appropriate role fillers corresponding to patient/theme roles. For example, we would like to know which word would be the most or least likely role fillers for the prior contexts like
74 students from Konkuk University took part in this listing task as a part of class activities. Because the goal of this task was to know which word would be possible at how much likelihood under the assumption that a particular role would occur, we specifically asked the participants to produce five possible role fillers in the order that they came up in their minds. Before we measured the conditional probability of each role filler for each context, we first had to make some changes of some completions. First, if the completions were the form of noun phrases, we removed the modifiers of the noun phrases. For example, for the context (4a), if there was a completion like
We only took into account the first three completions out of the five completions, not only because many participants did not fill up five possible completions but also because many completions listed in the fourth and fifth ranks were not appropriate. In addition, we weighted the completions by the ranks that they were listed. The completion listed in the first rank was weighted most by multiplying its frequency by three and the frequency of the completion listed in the second rank was multiplied by two. Finally, the completion in the third rank was weighted by being multiplied by one. The conditional probability of each completion in each item was estimated based on the weighted frequency that was held by collapsing the weighted frequencies of the top three completions across all participants. The weighted frequency of a particular word, Wk, in a particular item, Ij, was divided by the total sum of weighted frequencies across all possible word choices produced in that particular item, as illustrated in Equation (2).
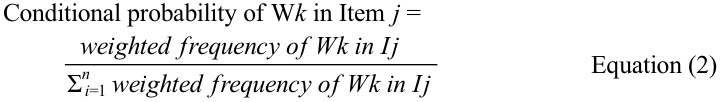
Based on the results that we estimated, we selected words that were either highly likely or unlikely in each sentence fragments like either (4a) or (4b). These words were used for our online reading time study. We prepared 24 sets of experimental materials. The conditional probability of target words differed between highly likely (
2.3 Obtaining Behavioral Responses
The purpose of the online study was to obtain readers’ processing behaviors in the integration of words into sentences. We hypothesized that the processing difficulty of particular words would be affected not only by how likely they were in given contexts but also by how strongly roles associated with the words were expected. In particular, we predicted that the processing of words would be the easiest when they were highly likely and when the roles corresponding to the words were strongly expected. In contrast, the processing of unlikely words would be more difficult when the expectation for the roles associated with them were weak than when it was strong. In order to test our hypotheses, we conducted a 2 Role Predictability (Strong, Weak) x 2 Word Predictability (Highly Likely, Unlikely) experiment.
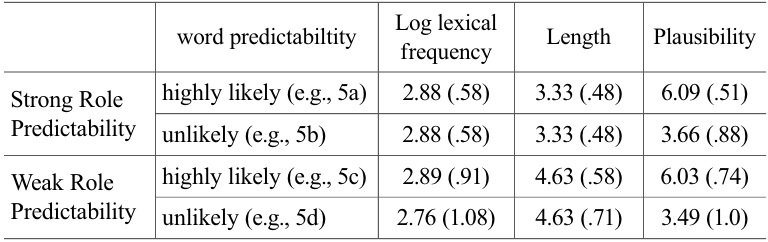
The underlined words that were the third word of each sentence were crucial for our study. While we were making experimental materials, we had to have the same words for the patient position in (5a-b) but different words for the recipient position in (5c-d). Thus, it was extremely important to control other lexical properties associated with target words across conditions. By doing so, we were sure that any differences of processing times could be only due to the differences of predictability degrees but not due to the differences of other properties like lexical frequencies, word lengths, or plausibility ratings.
First, we computed the lexical frequencies of target words using Sejong corpus and log-transformed them. The lexical frequencies of highly likely words did not differ between when roles were strongly expected and when roles were weakly expected (
Second, we also measured the degree of plausibility for target words. Here, we asked participants to rate how plausible it would be for target words to occur given context from 1 corresponding to being implausible to 7 corresponding to being highly plausible. The means of the plausibility ratings for all target words were above 3 out of 7, suggesting that all items were relatively sensible. Not surprisingly, the differences of the plausibility ratings between highly likely words and unlikely words were significant in both when roles were strongly expected (
Third, the lengths of target words were equated between highly likely and unlikely words in the condition of weak role expectation (
[Table 1.] The means (standard deviations) of lexical properties associated with target words

The means (standard deviations) of lexical properties associated with target words
The experimental sentences were pseudo-randomly intermixed with 77 filler sentences. The syntactic structures of these fillers were various. Some filler sentences had the forms of relative clauses, complex sentences, and simple declarative sentences. Because we asked participants to reject sentences at the point that they thought the sentences did not make sense while they were reading sentences, we included non-sensible sentences. Most experimental sentences were likely to be judged sensible. However, given the fact that some sentences, especially when target words were unlikely, the low plausibility of those sentences may have elicited some rejections. The fillers were either sensible or nonsensical. 30% of the distractor sentences, which were 25% of the total number of trials, were designed not to make sense. Nonsensical filler sentences were rejected due to diverse reasons. That is, some sentences did not make sense due to semantic reasons. Some sentences had to be rejected due to the violations of grammar, tense, or agreements.
One of the problems was that the lengths of target words were not equally controlled across all conditions. Especially, the lengths of target words were longer when their roles corresponded to recipients than when they did patients. This was basically because the case marker for recipients (i.e.,
2.4 Establishing a Linear Mixed-effect Regression
In order to examine the effect associated with the expectation of roles and words while the effects of lexical frequency and length were controlled for, a linear mixed effect regression was conducted. Our analyses were conducted using the R statistics program (version 3.0.2, R Development Core Team, 2013) and languageR libraries (version 1.4.1, Baayen, 2013).
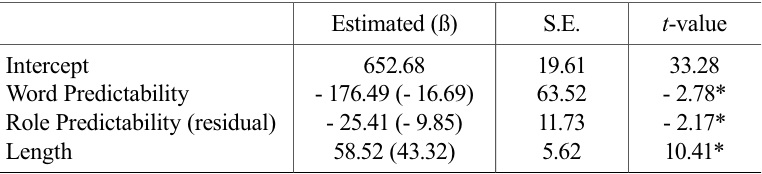
“Yes” reading times of target words that participants judged to make sense were submitted to a linear mixed-effect regression. 4 reading times that were greater than 3,000 milliseconds were omitted. In order to model the “Yes” reading times of target words, we initially used four fixed factors: Word Predictability, Role Predictability, Length, and Frequency. Word Predictability referred to how likely target words were in their given sentence contexts. Word predictability was their cloze conditional probabilities, as we reported above in Section 2.2. Role Predictability referred to how predictable thematic roles associated with target words were in given sentence contexts, as indicated in Section 2.1. Because we found high correlations between Role Predictability and Length (
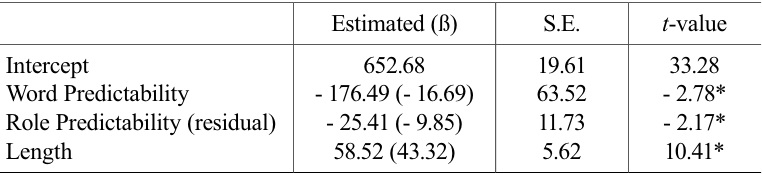
Results from a linear mixed effect regression which tested the reading times of target constituents
In addition, the significant effect of role predictability was also investigated by testing whether or not a model fit was improved. Two models were conducted. The first model included role filler predictability and length (Log-likelihood = - 23057; AIC = 46135; BIC = 46196) and the second model included role predictability in addition to the existing predictors (Log-likelihood = - 23051; AIC = 46130; BIC = 46216). A loglikelihood test revealed that the second model provided significantly better fit than the first model (χ2 (4) = 21.74,
3We think that the effect of word predictability is observable only when readers carefully process the semantic information of the context. To confirm our behavioral results, we are conducting follow-up studies using sensitive methods like ERPs and eye-tracking reading rather than a straight-reading task. 4Using the same methods, we also analyzed the RTs of the region immediately after the target words and found no effect at the post-critical region. 5We residualized role predictability over length to keep the correlation of these variables in the model (under .1), so that we could be safe from any potential concern of multicolinearity. A reviewer expressed his (her) worry about the fact that we used residualized role predictability for a non-necessary reason (Wurm & Fisicaro, 2014). Crucially, even when we did not residualize the variable, we observed that the effect of role predictability was still significant (coefficient = -23.99, S.E. = 10.74, t = -2.23) while the other predictors had significant effects. As a final model, we reported the results of the model with residualized role predictability, as shown in Table 2.
In this study, we raised a question about whether the integration of words into sentences would be easy not only when the words were highly likely for a given context but also when the roles associated with the words were strongly expected. Our hypothesis was that role expectation and word expectation would have independent effects on sentence comprehension. The results that we observed supported our hypotheses. First, the words that were highly likely for given contexts were easier to process than the words that were unlikely for given contexts. For example,
Our results suggest that readers actively and anticipatorily exploited the argument information carried by case markers as well as the situational knowledge in context during online sentence comprehension. When recipients with dative case markers were presented after agents, readers seemed to be ready to encounter theme or patient roles coming next. Recall that the conditional probability that a theme or patient role would occur after the consecutive presentation of an agent and a recipient was up to .74. Given that high role probability, readers’ processing difficulty would not be greatly influenced by how likely theme role would occur. Yet, their processing difficulty would be the function of how good a word would be as a role filler for the upcoming theme or patient role. That is, upon the recognition of recipients, which role would be coming up might be activated and thus the pre-activated role information might have led to the facilitation of processing words associated with the roles. Finally, due to the use of the situational knowledge in context, words referring to likely role fillers were easier to process than words corresponding to unlikely role filler.
On the contrary, when theme or patient arguments with accusative case markers were presented after agents, accounting for readers’ processing difficulty was not that simple. In this case, readers did not expect to see a recipient role appearing after a theme or patient role. The mean of role predictability was only .03. Instead, readers highly expected to see a sentence-final verb at .9, although the sentence would be grammatical even if they encounter a recipient role instead of a verb. In this condition, readers were almost sure that the sentence fragment would be completed with sentence-final verbs. However, contrary to their strong expectation, a word corresponding to recipient roles actually appeared. On encountering recipients, readers might have been greatly surprised and had difficulty in generating a new slot for such an unexpected role. In part, due to the use of the situational knowledge in context, they might have felt easier with highly likely words than with unlikely words. Altogether, our results suggested that both the argument information by case markers and the situational knowledge in context were effectively used in facilitating the integration of upcoming words into sentences.
It is of interest to note that unlikely words whose roles were strongly expected were read faster than likely words whose roles were weakly expected. We think that the argument information carried by case markers might play a role in constituting a slot for an upcoming role and then the situational knowledge in context cues which word would be more or less likely role filler for the role slot. Presumably, which word would be coming up or the degree of thematic fit of a word to context could have an effect on comprehension only after readers are assured of which thematic role would be appearing for the upcoming position.
Our results posed problems to the processing mechanism claimed by the situational knowledge-based approach. As mentioned earlier, the approach has argued that the processing difficulty of a word in a sentence is determined as a function of the degree to which the word has a thematic fit to the context. In this approach, our results that likely words were easier to process than unlikely words made sense in that likely words provided better thematic fit to the context than unlikely words did. However, recall that we also successfully equated the ratings of plausibility for target words between the conditions of whether or not roles were expected. Thus, in this view, we should not observe the difference of processing difficulty as a function of the degree of role expectation. Nonetheless, the main effect of role expectation yielded that words whose roles were strongly expected were processed faster than words whose roles were weakly expected. Contrary to the claim of the situation-based approach, the lexical or grammatical information carried by case markers that in particular corresponded to the argument information played its own role in sentence processing, independently from the situational knowledge in context.
Subsequently, our results drew our attention to issues on what to be considered in modeling readers’ behaviors. In particular, our data cause some difficulty to computational approaches like the surprisal model. As mentioned earlier, the surprisal model basically claim that processing difficulty of a word during online sentence comprehension is entirely mediated by the predictability of a word given a context (Boston et al., 2008; Hale, 2001; Levy 2008; Pado et al., 2009). In this view, our data is not completely wrong but it is not completely correct either. First, the surprisal model predicts our finding of word predictability such that more likely words were easier to process than less likely words. Second, the surprisal model also predicts our finding of role predictability such that words whose roles were more strongly expected were easier to process than words whose roles were weakly expected. Third, however, when both role predictability and word predictability were taken into account, the surprisal model does not predict that each factor has an independent effect, respectively. Instead, the model predicts that the effect of word predictability should subsume that of role predictability. Our results clearly show that word predictability alone was not accurate enough to account for the degree of processing difficulty in the integration of a word into a sentence.
In fact, we are not the only group who argued against the surprisal model. Roland, Yun, Mauner, and Koenig (2012) showed that semantic similarity between a target word and other possible words that could occur had an additional effect above and beyond the predictability of a word in the estimation of processing difficulty. In addition to the effect of word predictability, Roland and his colleague found that readers felt easier to process words by the degree to which the words were semantically similar to the other possible word choices that could have occurred instead of the target words. Furthermore, Yun, Mauner, Koenig, and Roland (2012) demonstrated that the effect of semantic similarity emerged conditionally only when the contextual information did not strongly constrain the set of possible words. The processing of words could be facilitated by the degree of shared semantic featural information between the words and the other possible words that could occur instead, only when the contexts did not provide strongly constraining information to what particular word should be. The modulated effect of semantic similarity as a function of the degree of the contextual constraint suggests that the unique role of word predictability is possible only when context provides particular expectation for particular words.
Taken together, we propose that a better processing model would allow multiple components that are supposed to reflect the information activation occurring across multiple levels. In particular, given our results, we claim that a processing model should have at least two components: One component takes into consideration the effect elicited by the use of the argument information at the thematic role level and the other component does for the effect by the situational knowledge in context at the word level (for similar claim, see Kuperberg, 2007). Alternatively, a processing model might allow different processes to operate in a single component instead of having different components: One process might be effective for word (lexical) processing and the other should consider the processing of how words are integrated into sentences (for a similar claim, see Brouwer, Fitz, & Hoeks, 2012). We will keep studying the modeling issue for our future studies.
The goal of our study was to demonstrate the expectation-based sentence comprehension that was effective across multiple levels, by using head-final language, Korean. Our results revealed that readers’ processing difficulty was significantly influenced by readers’ expectation for which role would be coming up as well as which word would appear as an appropriate role filler for a given context. Readers actively and anticipatorily used both the argument information conveyed by case markers and the situational knowledge in context during online processing. We claimed that a singleoutlet processing model is not accurate enough, rather, a processing model should be able to take into account the information activated across multiple levels.