Inspired by
Research into the question of whether language influences thought has been greatly facilitated by Talmy’s (1985, 2000) demonstration of the logical separability between the linguistic encoding of a motion event and conceptual elements of the event itself. Talmy identified six elements of complex motion 1 : the moving object (figure), the reference object (ground), the fact of motion, the trajectory (path), the way in which the figure moves (manner), and the cause. These six elements may be encoded in a variety of combinations across lexical items. Nonetheless, with particular attention to verbs and satellites, Talmy argued that languages will demonstrate characteristic lexicalization patterns, and that these patterns are a source of typological variation amongst languages.
Of particular note has been the distinction between languages like English, which tend to encode manner in the verb, and languages like Spanish, which tend to encode path in the verb. Talmy (2000) proposed a two-way typology focused on where path is encoded in a motion description, referring to English-type languages as satellite-framed, or S-framed, and to Spanish-type languages as verb-framed, or V-framed, as illustrated in (1) and (2).
While elicited descriptions of motion across languages reveal striking typological differences in the relative prevalence of path and manner verbs (e.g., Berman & Slobin, 1994; Gennari, Sloman, Malt, & Fitch, 2002; Naigles, Eisenberg, Kako, Highter, & McGraw, 1998; Papafragou, Massey, & Gleitman, 2002, 2006; Slobin, 1996), the evidence for cognitive effects of these differences is mixed (e.g., Cifuentes-Férez & Gentner, 2006; Filipović, 2011; Finkbeiner, Nicol, Greth, & Nakamura, 2002; Gennari et al., 2002; Kersten, Meissner, Lechuga, Schwartz, Albrechtsen, & Iglesias, 2010; Naigles & Terrazas, 1998; Papafragou, Hulbert, & Trueswell, 2008;Papafragou et al., 2002). For example, Gennari et al. (2002) examined recognition memory and similarity judgments for simple motion events with English-speaking and Spanish-speaking participants, some of whom were required to provide a linguistic description of each clip during the encoding phase. After a delay, all participants were asked to perform both a recognition task and a similarity judgment task. Gennari et al. observed a difference in accuracy in recognition responses to previously viewed items, whereby English speakers evidenced greater accuracy than did Spanish speakers. However, they found no effect of language on accuracy in recognition responses to new items, precluding a clear conclusion either for or against a linguistic effect on recognition memory. Turning to the similarity judgments, Gennari et al. found that Spanish speakers made more same-path choices than did English speakers (consistent with the typology of their languages), but only if they had provided linguistic descriptions for the events earlier, suggesting that language may influence similarity judgments if it has been accessed previously within the experimental context. In a similar vein, Papafragou, Hulbert, and Trueswell (2008) examined Greek speakers’ and English speakers’ visual attention to path and manner elements of short motion animations. They found that the patterns of eye movements differed when participants were told they would need to produce verbal descriptions, with Greek speakers looking more often than English speakers to the path endpoint (again consistent with the typology of their languages), particularly early in the animation. This effect was not in evidence, however, when participants were simply told to memorize the events. Furthermore, amongst those participants not asked to produce linguistic descriptions, memory for the animations was poorer for Greek speakers than for English speakers, suggesting “that Greek speakers’ efforts to attend to both the manner and the path during encoding came at a cost” (Papafragou et al., 2008, p. 179). Importantly, this cost was not evident in the data from the English speakers, for whom the encoding of both manner and path is habitual (see below). Taken together, the mixed pattern of results revealed across these experiments suggests that the open questions in this domain address when and how language influences thought, rather than whether it does.
The majority of experiments investigating potential linguistic effects on thought in the domain of motion events, like those reviewed above, are often designed to test whether speakers of satellite-framed languages, with their extensive reliance on manner verbs, are more sensitive to manner than path information; while speakers of verb-framed languages, with their extensive reliance on path verbs, will evidence the opposite pattern of sensitivity. These experiments are grounded in a misinterpretation of the linguistic data, based solely on Talmy’s (1985) account of cross-linguistic variation regarding which element of a motion event is most likely to be encoded
A fuller picture of the ways in which languages encode motion can be found in the work of Slobin (1996, 2003, 2004, 2006). Slobin’s examinations of elicited narratives of Mercer Mayer’s picture storybook
In this vein, Feist, Rojo, and Cifuentes (2007) asked whether the low salience of manner in Spanish might account for the unacceptability of Spanish manner verbs in boundary crossing events observed in previous studies (Aske, 1989; Slobin & Hoiting, 1994). They presented speakers of English and Spanish with videotaped motion events followed by onesentence descriptions of the events paired with photos of the actors in the target clips; the descriptions always included a manner verb as the main verb. Participants were asked to verify whether the sentences described the pictured actor’s movement in the corresponding videos. Reasoning that a contrast on one dimension while another is held constant would draw participants’ attention to the contrasted dimension, Feist et al. manipulated the salience of manner information by having some participants view multiple video clips in which path was held constant while manner was varied (High Manner Salient) while others viewed just one video clip (Low Manner Salient). The addition of video clips for the High Manner Salient condition appeared to increase the difficulty of the task for English speakers, as evidenced by a slowing of response time relative to the Low Manner Salient condition. This result makes sense, given that participants in the High Manner Salient condition were being asked to verify a description of one randomly chosen video clip out of a set of three that they had been shown, while participants in the Low Manner Salient condition were simply asked to verify a description of the single video clip that they had viewed. However, this effect was not evident for Spanish speakers, for whom response times did not differ between Manner Salience conditions. This pattern of results suggests that the increased salience of manner for Spanish speakers, who may not habitually attend to manner information (Slobin, 2003, 2004), counteracted the elevated difficulty of the High Manner Salient condition.
Using a different measure of cognitive performance, Kersten et al. (2010) examined English speakers’ and Spanish speakers’ performance on a category learning task involving novel motion events. Participants were presented with short animations in which the path and manner of motion of bug-like creatures were independently varied; in one set of conditions, attention to manner was required to correctly categorize the animations, while path was irrelevant; in the other set of conditions, attention to path was required and manner was irrelevant. The findings revealed no crosslinguistic differences in performance when categorization was based on path, in line with observations about the prominence of path in both Spanish and English (Kersten et al., 2010; Slobin, 1996, 2003, 2004, 2006). In contrast, English speakers outperformed Spanish speakers when the basis of categorization was manner of motion, in line with cross-linguistic differences in the likelihood of encoding manner of motion (Slobin 1996, 2003, 2004, 2006), suggesting that language-related effects may be limited to specific conceptual elements.
More recently, Feist (in press) examined the relation between codability and accessibility of manner information more directly. She asked speakers of English and Spanish to provide one-word descriptions of videos like those used by Feist et al. (2007). She then compared the codabilities of the manners depicted (as measured by length of description and rate of interparticipant agreement) with the cognitive costs associated with producing a description (as measured by response latency and the rate at which participants changed their responses). In line with prior typological work (e.g., Talmy 1985, 2000; Slobin 2004), she found that manner was indeed more codable for speakers of English than for speakers of Spanish. In addition, she found that the costs associated with producing descriptions were greater for speakers of Spanish than for speakers of English, providing further evidence for a connection between the codability and the cognitive accessibility of manner information.
In contrast to work comparing attention to path with attention to manner, the results reviewed above suggest that within-dimension variations in salience may influence speakers’ performance on linguistically-mediated tasks. Building on this work, the current study asks whether within- dimension variations in salience may likewise influence performance on a non-linguistic task. Concretely, will cross-linguistic variation in the salience of manner correlate with between-group differences in performance on a recognition memory task? In other words, is there evidence for linguistic relativity in recognition memory for motion events when the comparison between path and manner information is removed? In order to more clearly focus on the importance of the single dimension, we also ask whether the salience of manner can be manipulated on an individual level, such that speakers evidence heightened attention to the dimension even if it is not highly codable in their language.
1Talmy (2000) argues that a basic motion event is made up of just four elements:the figure, the ground, the path, and the fact of motion.
In order to investigate these questions, we asked English and Spanish speakers to watch short video clips of motion events and remember them for later recognition. We manipulated the contextual salience of manner through the number of motion events participants were shown at study: either seven events (High Manner Salient, or HMS, condition) or three events (Low Manner Salient, or LMS, condition). All clips depicted motion along a single path, with a unique manner for each motion event; hence, memory for the video clip was dependent upon memory for the manner of motion depicted.
The first question is whether speakers of high-manner-salient English are less likely to make errors in recognition memory for manner of motion than are speakers of low-manner-salient Spanish, as might be expected due to the difference in the salience of manner in the two languages. If the salience of manner in event memory is correlated with the salience of manner in the language, as hypothesized by Slobin (2003), we should observe a lower incidence of errors among speakers of high-manner-salient English relative to low-manner-salient Spanish.
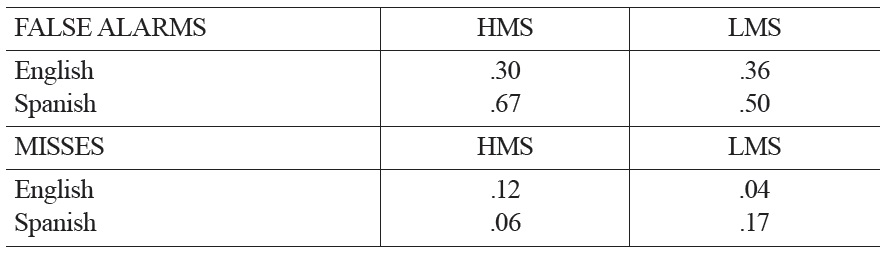
If we do observe a difference in memory for manner, two questions follow. First, we ask whether differences show up equally for both types of recognition error – misses and false alarms. Taken in isolation, differences in the miss rate (i.e., the error rate on previously viewed items) might indicate that the initial event itself is more recognizable to speakers of one language than to speakers of the other, easing the task of recognizing it when it is re-presented. Differences in the false alarm rate (i.e., the error rate on newly presented items), on the other hand, might indicate that novel manners are less easily discriminated for speakers of one language than for speakers of the other, raising the likelihood that they will be falsely recognized.2 Previous work examining memory for motion in speakers of English and Spanish found a cross-linguistic difference in miss rates, but not in false alarm rates (Gennari et al., 2002), suggesting that the two types of errors may interact differently with language.
The second question regards the influence of contextual differences in the salience of manner, as implemented through the condition manipulation. All of the motion events depicted a single path in a single setting, with the only sources of variation being the actors and the manners of motion. By showing multiple video clips contrasting in manner but not path, we can increase the contextual salience of manner of motion. In previous work employing a linguistic acceptability task, we found that this addition of videos increased the task difficulty for English speakers, leading to poorer performance in the HMS condition, likely due to the larger number of items that must be held and manipulated in memory. For the Spanish speakers, however, there was no difference in performance between the conditions, suggesting that the heightened salience of manner counteracted the increased difficulty of the task (Feist et al., 2007; see above). Similarly, we expect that the increased memory load in the HMS condition in the current task will increase the difficulty of the task relative to the LMS condition, resulting in decreased accuracy for the English speakers. However, as in our previous study, we expect the increase in manner salience to counteract the heightened difficulty for the Spanish speakers, who would not otherwise automatically attend to manner of motion (Slobin, 2003).
Participants 64 native English speaking students at the University of Louisiana at Lafayette (30 in the HMS condition; 34 in the LMS condition) and 40 native Spanish speaking students at the University of Murcia, Spain (20 in the HMS condition; 20 in the LMS condition) volunteered or received course credit for their participation.3
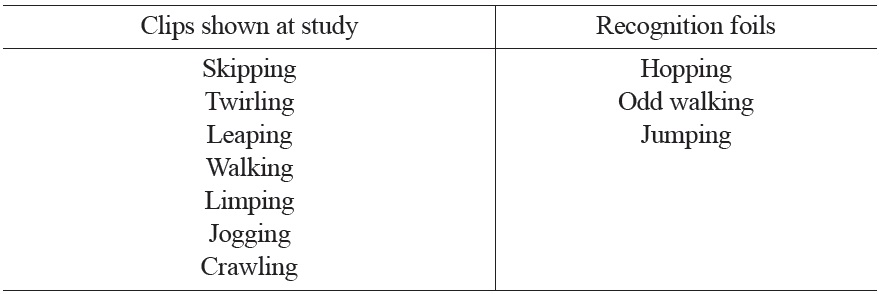
Materials We used a set of ten short video clips (each lasting between 2 and 8 seconds, depending on the manner of motion shown4) depicting motion along a single path (down a hallway, turning to the actor’s right and entering a room), each with a unique manner of motion. The setting was identical for all ten clips (a university hallway). There were 4 actors and 3 actresses in the clips, with 3 of them (2 actors and 1 actress) participating in two videos each.
The clips were distributed through the experiment as follows. Seven video clips were chosen to be used in the study portion of the experiment. These seven clips shared a setting and a path, but each depicted a unique actor or actress performing a unique manner of motion. All seven clips were shown to participants in the HMS condition; only three of these clips were shown to participants in the LMS condition.
The three remaining clips served as recognition foils for the three clips that were shown to participants in both conditions during the study period. These clips each depicted a motion event performed by the same actor or actress as in the paired study clip, differing from the study clip only in the manner of motion.5 At recognition, each participant saw one member of each pair: either the study clip or its recognition foil.
The motion events depicted in the seven study clips and the three recognition foils are described in Table 1, with the recognition foils appearing to the right of their associated study clips.
[Table 1.] Motion Events Used in the Experiment
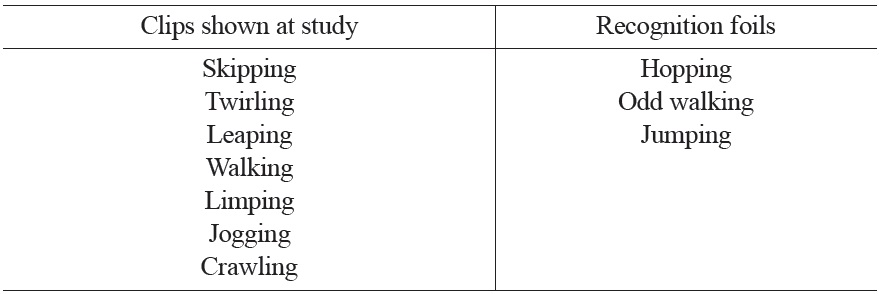
Motion Events Used in the Experiment
Procedure The task was divided into two phases: study and recognition. Participants were randomly assigned to one of two conditions for the study portion. In the HMS condition, participants were shown seven video clips; in the LMS condition, participants were shown three video clips.6 The clips were presented in a different random order for each participant. After completing a brief filler task (in which participants rated the similarity between color swatches), all participants were given the same yes/no recognition test, in which they were shown three motion events, one from each of the standard-clip/foil pairs, in random order, and they were asked to indicate whether or not they had seen each recognition clip during the earlier study phase. The status of each of the recognition events (old or new) was randomly determined by a computer program. No participant was shown both a previously viewed clip and its recognition foil during the recognition task.
Predictions If speakers of English are indeed more attuned to manner distinctions than are speakers of Spanish, we should expect to see a higher incidence of errors in Spanish speakers than in English speakers, as the foils differ from the target videos only with regard to manner.
There are two potential kinds of errors in this experiment: misses and false alarms. In previous work, Gennari et al. (2002) observed an effect of language (Spanish or English) on miss rates, but not on false alarms. Thus, we also ask separately for each kind of error whether there is a difference in performance between English and Spanish speakers.
Finally, in line with previous work, we expect the overall difficulty of the task to be greater in the HMS condition than in the LMS condition, but that this difference in task difficulty may be modulated by the participant’s native language (Feist et al., 2007). Thus, both for the error rate overall and for each kind of error individually, we ask whether English speakers’ performance is worse in the HMS condition than in the LMS condition. Finally, if the increase in manner salience counteracts task difficulty for a recognition memory task as it did for the previous sentence verification task, we should see that evidence of a difference in task difficulty between the conditions is either modulated or completely absent in Spanish speakers.
2A third issue, regarding differences in discrimination sensitivity to changes in manner (as measured by d’), cannot be directly examined in the current design due to the small number of stimuli required for the manner salience manipulation. A finding of different effects for misses and for false alarms, however, would suggest that any observed language effects reflect memory differences, rather than cross-cultural differences in response biases. 3Given the level of education of our participants, it was unlikely that we would find speakers who were strictly monolingual. In fact, many of our English speakers and most of our Spanish speakers had had exposure to other languages. However, Kersten et al (2010) found similar language effects when comparing the performance of English speakers to that of Spanish-speaking bilinguals (Experiment 1) and that of monolinguals (Experiment 2) on a manner of motion categorization task, indicating that cross-linguistic differences in attention to manner of motion could be found despite participants’ exposure to other languages. 4Because we wanted to keep the path traversed constant across the set of video clips, the duration of the clips necessarily varied, with faster manners of motion (e.g.,running) resulting in shorter clips than slower manners of motion (e.g., limping). 5It should be noted that it is possible to describe the foils and their associated study clips using the same verb, both in English and in Spanish. In addition, however, it is also possible to describe each foil with the same verb as would be used to describe a different, unrelated clip from the study portion. For example, the Spanish verb saltar can be used to name four clips: the skipping clip and its foil, as well as the leaping clip and its foil. Likewise, the English verb jump can be used to name the same four clips. Thus, while a strategy of using language at encoding could lead to a higher rate of false alarms, this should be equally likely in the two language groups, and is likely unrelated to the particular study clip-foil pairings. 6It was necessary to keep the number of trials small in order to guard against a situation in which manner would become highly salient in the LMS condition. In previous work, we found manner to be more salient for participants when they viewed three clips rather than one, with no interval between initial encoding and test (Feist et al., 2007). To increase difficulty for the current task, we increased the number of clips for both the HMS and LMS conditions.
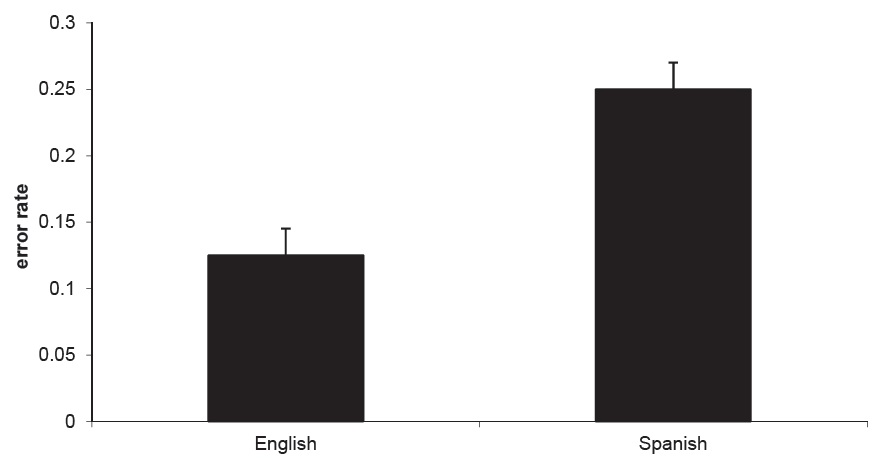
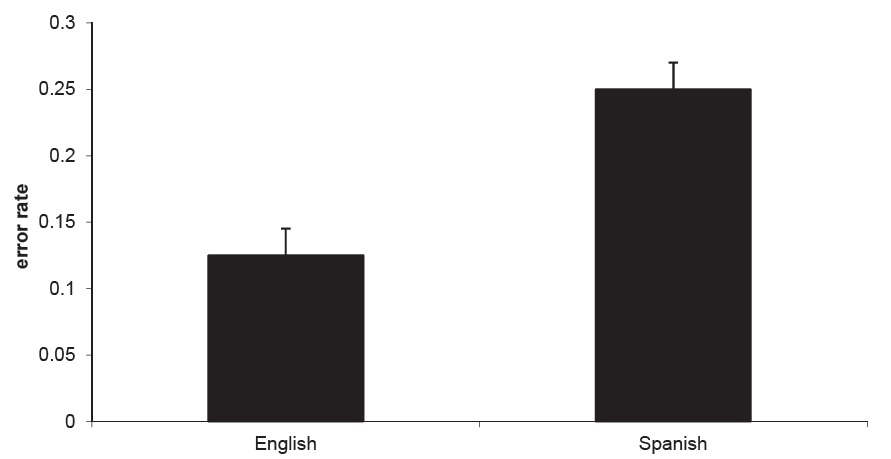
Overall error rate Our first question was whether we would observe a lower incidence of errors in speakers of English than in speakers of Spanish. In fact, we observed a difference in the overall error rate, whereby Spanish speakers evidenced more errors than did English speakers (Fig.1). This result was confirmed through a by-subjects ANOVA on the overall error rates,
There was no effect of condition on overall error rate, nor was there an interaction of language and condition.7
In order to better understand the cross-linguistic difference in errors, we looked separately at the results for false alarms and for misses.
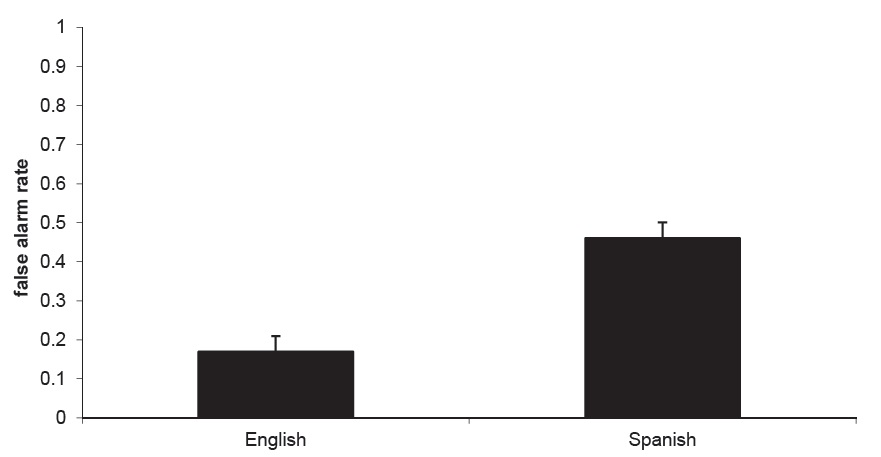
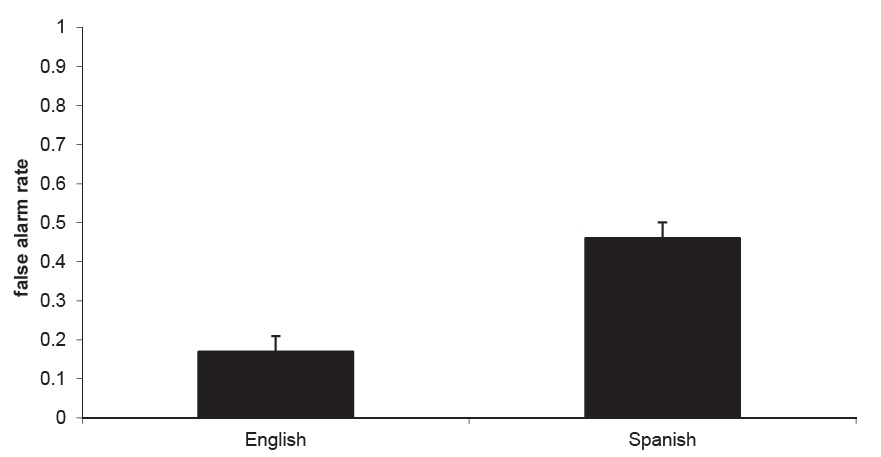
False alarms As with overall errors, we observed a higher incidence of false alarms from our Spanish-speaking participants than from our English-speaking participants (Fig.2). This result was confirmed through a by-subjects ANOVA on the false alarm data, which showed an effect of language
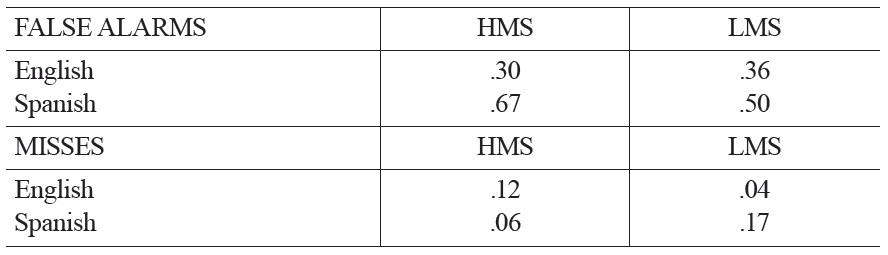
Because the presentation of old and new items was randomly decided by a computer program, there was variation in the opportunity that participants had for misses and false alarms. Thus, we grouped participants by native language and condition, then looked qualitatively at the proportion of participants in each group with the opportunity for each kind of error who actually made the error (Table 2). For false alarms, the dominant factor appears to be language, with more Spanish speakers than English speakers making errors in both conditions, in line with the overall results.
Proportion of participants with the opportunity to produce false alarms and misses who did so, by language and condition
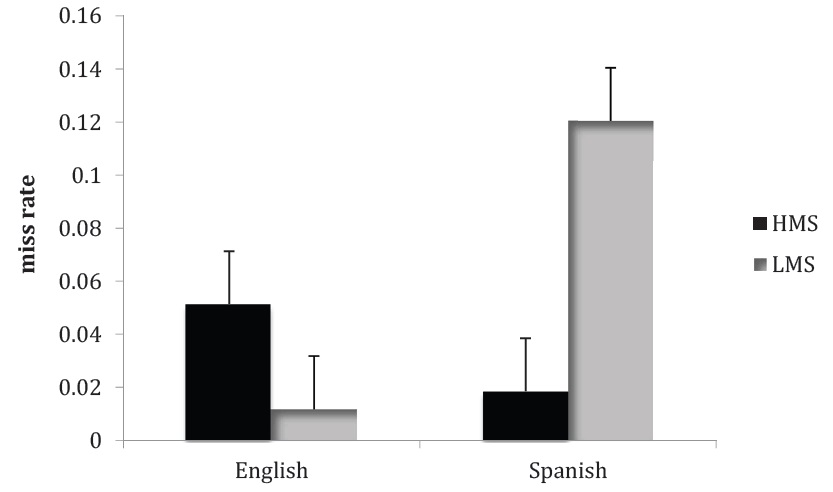
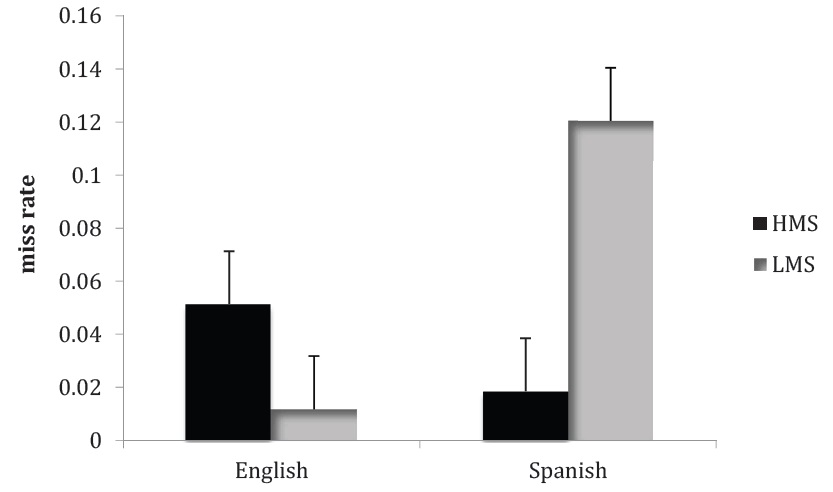
Misses Unlike with the false alarms, a by-subjects ANOVA on the miss rates revealed no main effect of language (English
As with the false alarm data, we followed up on this result by examining the proportion of participants who were presented with an old item at recognition and produced errors in their responses to the old item (Table 2). Mirroring the overall results, we observed a striking interaction between language and condition whereby more English speakers were prone to errors in the HMS condition, while more Spanish speakers demonstrated errors in the LMS condition.
7We also asked whether the pattern of responses differed for the three recognition stimulus pairs. A chi-squared test showed that there was an association between the responses and the stimulus pairs, X2 (6, N = 312) = 15.42, p < .02. A closer look at the data showed that the pattern of responses to the skipping foil differed from the pattern for the other two foils. We then examined the responses to the skipping foil across languages and conditions and found no association, X2 (3, N = 56) = 4.35, p > .05, suggesting that the cross-linguistic differences were not driven by responses to a single stimulus.
Cross-linguistic variation in the lexicalization of motion events has led many to ask whether speakers of languages that encode path in the main verb will attend more to path than to manner, while speakers of languages that encode manner will evidence the opposite pattern (Gennari et al., 2002; Naigles & Terrazas, 1998; Papafragou et al., 2008; Papafragou et al., 2002, 2006;
Slobin (2003) argued that a complete picture of the effects of linguistic relativity requires an understanding of “consequential effects”: cognitive effects that arise after an event has been experienced, including effects on memory for the event. The current study contributes to our understanding of these effects in two ways. First, taking variation in the salience of manner as the locus of cross-linguistic difference, we asked whether speakers of a high-manner-salient language would evidence superior memory for manner of motion than would speakers of a low-manner-salient language. In line with Slobin’s (2003) hypothesis, we observed a greater incidence of errors in a test of manner-of-motion recognition amongst speakers of low-mannersalient Spanish than amongst speakers of high-manner-salient English. Second, we asked whether contextual variation in the salience of manner information might heighten attention to manner of motion, with the result that the performance deficit for speakers of a low-manner-salient language would be modulated or eliminated, implicating the salience of manner itself in the cross-linguistic cognitive difference. Looking more closely at the patterns of errors, we found very different effects in the false alarm rates than in the miss rates. Most notably, we observed an interaction between language and manner salience condition for the miss rates, whereby speakers of high-manner-salient English evidenced a higher miss rate in the HMS condition, but speakers of low-manner-salient Spanish evidenced a higher miss rate in the LMS condition. Rounding out our examination of “consequential effects”, we observed no effect of manner salience condition on the rate of false alarms. The differences in effects for the misses and the false alarms suggest that the cross-linguistic differences in this task may not simply be explained through cross-cultural differences in response bias.
The current data support the hypothesis that the linguistic salience of manner plays a role in speakers’ memory for manner: speakers of English made fewer errors than did speakers of Spanish. Furthermore, the overall error rate did not differ across manner salience conditions, nor was there a condition by language interaction, strengthening the conclusion that speakers of a language which routinely encodes manner information will evidence higher salience for manner in their memory for events than will speakers of a language which less readily encodes manner information (cf., Slobin, 2003).
Looking individually at false alarms and misses, however, it becomes evident that the linguistic influences are more subtle and complex than the broad-stroke conclusion that the salience of manner in the language correlates with the salience of manner in event memory. For false alarms, the data mirror the overall error rate data, with fewer false alarms amongst English speakers than amongst Spanish speakers, but no effect of condition nor condition by language interaction. This result suggests that the habitual attention to manner that comes with speaking a high-manner-salient language may result in greater attention to fine details of manner (Slobin, 2003) and hence lessened likelihood of mistaking a novel manner as a previously seen one. Speakers of low-manner-salient Spanish, in contrast, may be less likely to encode fine details of manner and hence more likely to accept an unseen manner as one that was previously seen.
The situation is more complex with misses, where there is no main effect of language or of condition, but there is a language by condition interaction. We observed that English speakers in the HMS condition more often failed to recognize the events that they saw than English speakers in the LMS condition, likely due to the heavier memory load associated with keeping seven items in memory rather than three, and consistent with the sentence verification results found previously (Feist et al., 2007). Unlike English speakers, however, Spanish speakers in the
By focusing on the salience of a single conceptual element of a motion event rather than comparing the salience of two conceptual elements, the present study aims to provide a more nuanced test of linguistic relativity in this domain. Our conclusions are limited, however, by our reliance on just two languages in this initial test: English and Spanish. Future research is needed to provide further evidence from other High Manner Salient languages such as German, Danish, Dutch or Russian and other Low Manner Salient languages such as Portuguese, French, Turkish, Korean or Japanese in order for us to better understand the role of the salience of manner, whether linguistic or contextual, in memory for motion events.
In contrast to the strong typological differences noted in descriptions of motion events across languages (e.g., Berman & Slobin, 1994; Gennari et al., 2002; Naigles et al., 1998; Papafragou et al., 2002, 2006; Slobin, 1996), evidence for the influence of language on thought in this domain has been mixed (e.g., Cifuentes-Férez & Gentner, 2006; Filipović, 2011; Finkbeiner, Nicol, Greth, & Nakamura, 2002; Feist, in press; Feist et al., 2007; Gennari et al., 2002; Kersten, Meissner, Lechuga, Schwartz, Albrechtsen, & Iglesias, 2010; Naigles & Terrazas, 1998; Papafragou et al., 2008; Papafragou et al., 2002). We believe that part of the problem in much of this research is the focus on a single class of lexical item – the verb – rather than on the motion description as a whole, as an index of the linguistic resources available to speakers. We propose an alternate way to address this question, focusing on cross-linguistic differences in the codability of a single dimension – manner – rather than on cross-linguistic differences in the preferred dimension for encoding in the main verb (cf., Feist, 2010; Kersten et al., 2010; Slobin, 2004, 2006). Our results suggest that higher codability of manner of motion correlates with improved memory for manner (cf., Filipović, 2011; Kersten et al., 2010). However, the linguistic influences in this domain are complex and subtle, with different effects observed for different measures of recognition. While the habitual linguistic encoding of manner appears to improve a speaker’s likelihood of recognizing as novel a previously unseen event, this habitual encoding, or lack thereof, does not appear to alter the ease of retrieval of an event which has been viewed. In contrast, contextual strengthening of the salience of manner information does seem to increase ease of retrieval, provided that manner is not already highly salient via habitual linguistic encoding. In sum, the salience of manner, both linguistic and contextual, appears to influence recognition performance. When remembering how, the question may not be