Natural language production requires a grammar and a lexicon. We will deal here only with the latter, trying to enhance an existing electronic resource to allow for search via navigation in a huge associative network. The structure and the process are somehow akin to the mental lexicon (ml). We have a network composed of nodes (mainly words) and links (mainly associations). Search, or rather, navigation consist in entering the network at some point by providing a query —(usually a word, somehow related to the target word)— and following the links to get from the source word (Sw) to the target word (Tw), the goal. While our lexical graphs are different from the multilayered networks of the human brain (weight, decomposition, automaticity), functionally speaking there are some important similarities between the two, in particular with respect to navigation. While spreading activation is generally automatic and outside of the user’s control, its counterpart (navigation) is deliberate and in slow motion. Our primary focus in this paper will be on the structure of the lexicon and its indexing scheme. These two points have often been overlooked, yet they are crucial, as they determine the extent to which users, — (hence, not only readers, but also authors) — can find the word they are looking for. While researchers of the natural language generation (nlg)-community have devoted a lot of work to lexicalization (i.e. the mapping of meanings to forms), lexical access has never received any attention at all. Lexicalization is generally considered to be only a choice problem, the assumption being, that data that is stored can also be accessed. While this may hold for machines, it certainly does not apply for people, at least not always, as is well attested via the ‘tip-of-thetongue’ problem (Brown and McNeill, 1966). Yet, even machines may ‘experience’ access problems. We will illustrate this last point via a small experiment, showing how a well known lexical resource (WordNet) does not always reveal information (words) it contains. In the remainder we will then show how a lexicon should be organized to allow language producers (speakers/writers) to find quickly and naturally what they are looking for, in our case, the target word.
1. Problem: finding the needle in a haystack
One of the most vexing problems in speaking or writing is the inability to recall or access a known word when needed. This kind of search failure, known as
The problem with which we are concerned in this article is the problem of how to find words in the places where they are stored: the human brain or an external resource such as a dictionary. Our work being confined to lexical access, we have started to develop a semantic map and a compass to help language producers find the words they are looking for. More precisely, we try to build an index and a navigational tool allowing people to access words, no matter how incomplete their conceptual input may be. Our approach is based on psychological findings concerning the mental lexicon (Aitchison, 2003; Roelofs, 2004), that is,
1.1 The author’s problem: choosing words, finding them, or both?
Given the expressive power of language,2 natural language generation (NLG) researchers view lexicalization mainly as a choice problem (McDonald, 1980; Stede, 1995; Reiter 1991). Though this may be correct, it does not follow that word access is not a problem worthy of consideration. Obviously, before making any choice, one must have something to choose from. Put differently, one must have accessed at least one word, if not more. Yet, since access does not seem to be a problem for machines—computers generally manage to retrieve stored information—NLG researchers consider
While this attitude may be justifiable in the case of (fully automated) text generation, it is not acceptable in the case of language production by people, or interactive, computer-mediated language production (our problem here). Words may elude speakers at any moment, typically when they need them most, at the very moment of speaking or writing. Alas, the fact that speakers have memorized the words they are searching for does nothing other than to create frustration, as they feel deprived of something they know but cannot get hold of.4 This is generally the moment at which speakers reach for a dictionary, provided that they care and have the time and access to an appropriate resource.
While there are many kinds of dictionaries, very few of them are really helpful for the writer or speaker. To be fair though, one must admit that great efforts have been made to improve the situation. In fact, there are quite a few
One detail often overlooked is the fact that in searching the dictionary speakers rarely access the desired information
In this article, we pursue the following two goals: (a) to show that even computers may fail to access stored information; (b) to describe a way to help people access a momentarily unavailable word. To this end we will explain some design features of a dictionary suitable for the language producer.
1.2 Storage does not guarantee access
To test this claim we ran a small experiment, comparing an extended version of
1.2.1 Using WordNet as a corpus
WN is a lexical database for English, developed under the guidance of G. Miller, a well-known cognitive psychologist (Miller
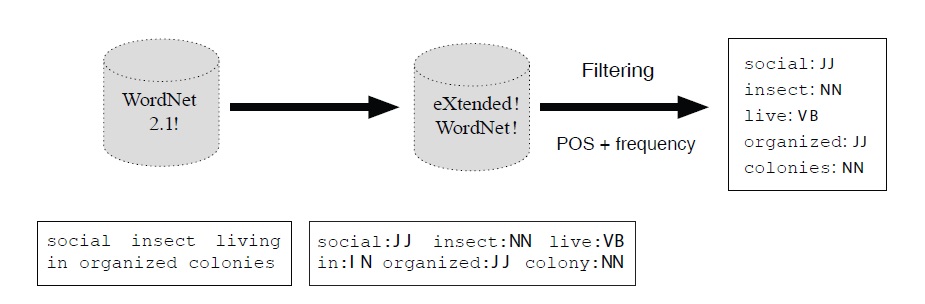
While
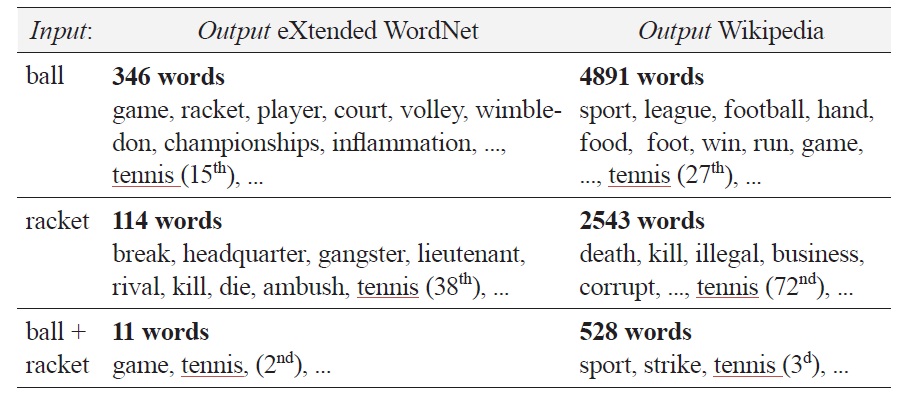
Despite all this, two important problems remain: the size of the corpus (our version contains only about 144.000 words) and the lack of encyclopedic knowledge, i.e. syntagmatic associations, which, taken together may impede word access (see below). Indeed, concepts that are functionally related in normal life (dine-table-meal; to fish-net-tuna, etc.) should evoke each other, yet this is not really the case in
1.2.2 Using WikiPedia as a corpus
In order to compare
1.3 Exploitation and comparison of the resources
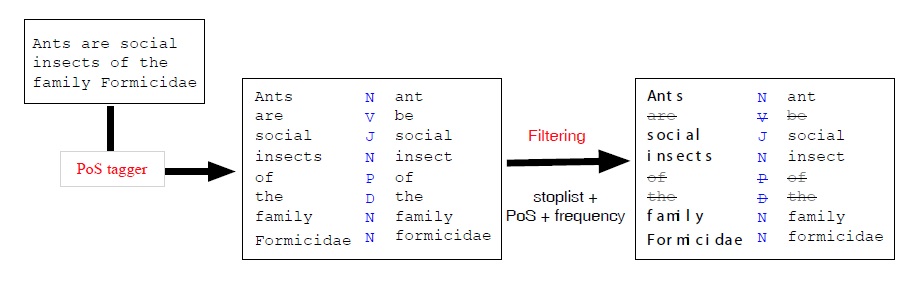
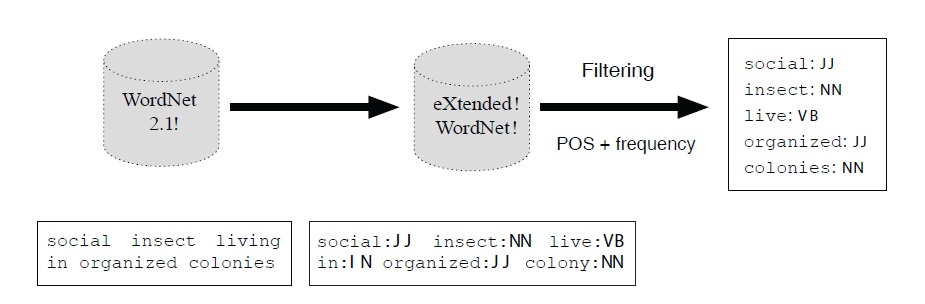
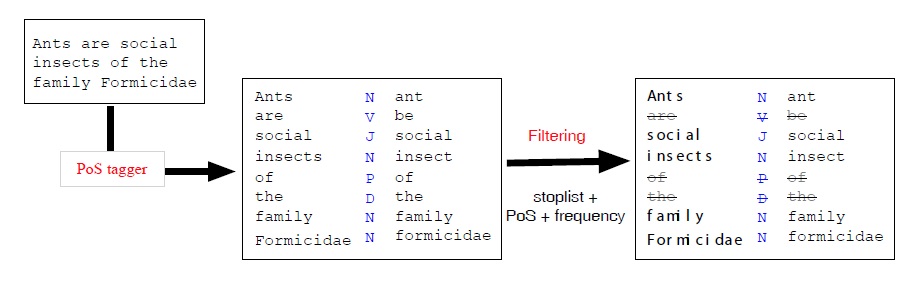
Constructing the resource requires the processing of a corpus and the building of a database. To this end we used a corpus applying our direct neighborhood function fdng to a predetermined window (a paragraph in the case of encyclopedias). The result (i.e. the co-occurrences) are stored in the database, together with their weight, (i.e. number of times two terms appear together) and the type of link. As mentioned above, this kind of information is needed later on for ranking and navigation.15
At present, co-occurences are stored as triplets (Sw, Tw,
1.3.1 Usage
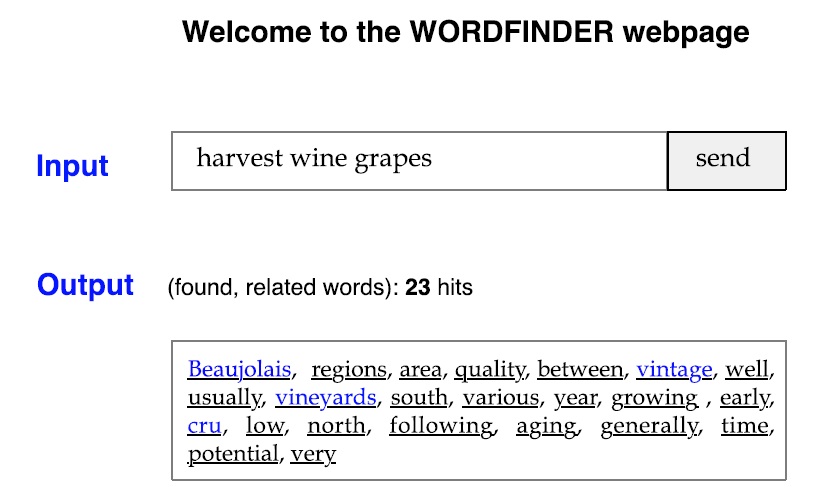
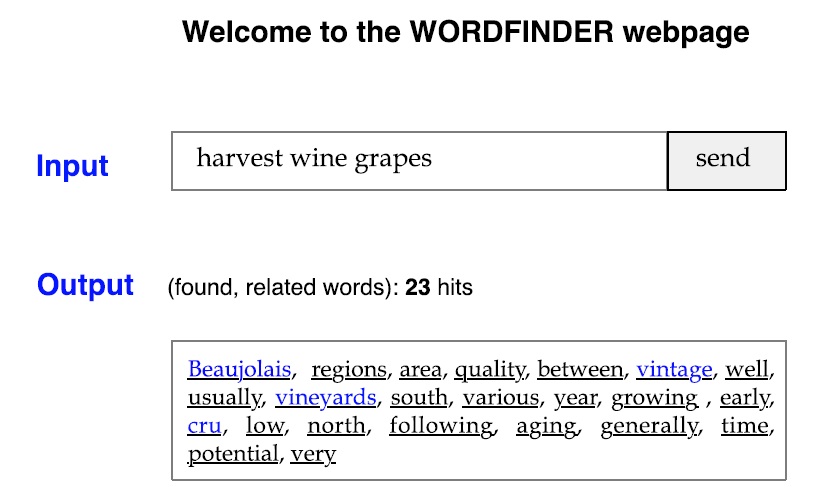
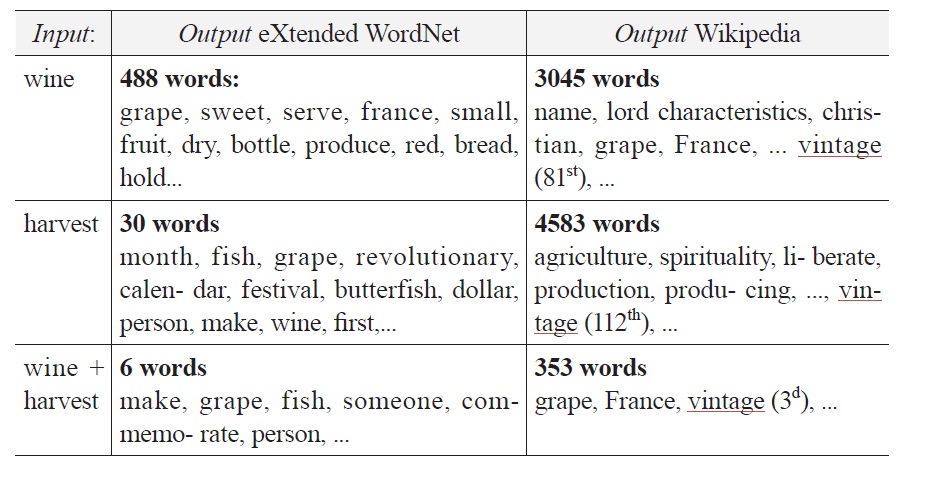
To show the relative efficiency of a query (see Figure 3), we have developed a website in Java as a servlet which will soon be released on our respective homepages. Usage is quite straightforward: people add or delete a word from the current list, and the system produces some output. For example, if the inputs were “harvest, wine, grapes”, the system would display all cooccuring words (i.e direct associations). Of course, if we use more than one corpus, as we do, we will have to display the results for each one of them.
The output is an ordered list of words, the order of which depends on the overall score (i.e. the number of co-occurrences between the Sw and the directly associated word, called the ‘potential target word’ (PTw)). For
example, if the Sw ‘bunch’ co-occured five times with ‘wine’ and eight times with ‘harvest’, we would get an overall score or weight of 13: ((wine, harvest), bunch, 13). Weights can be used for ranking (i.e. prioritizing words) and the selection of words to be presented, both of which may be desirable when the list becomes long.
1.3.2 Examples and comparison of the two corpora
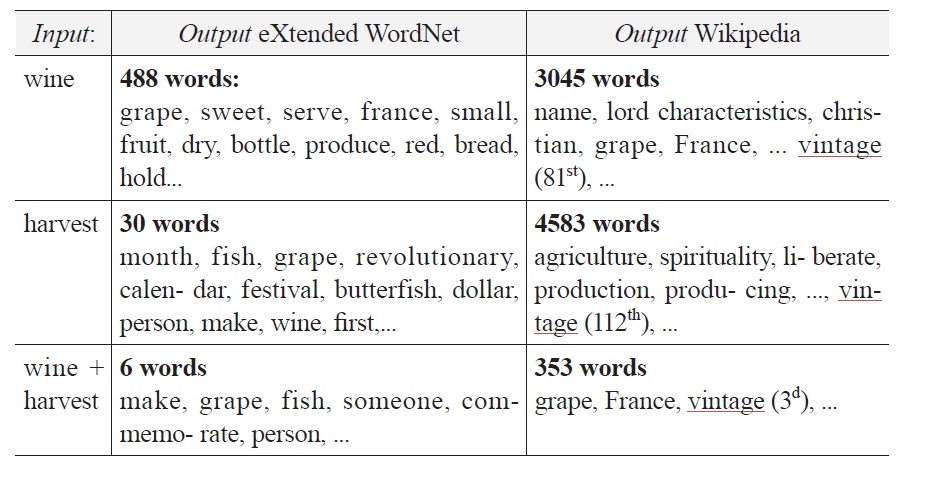
Listed below in Figure 4a are the results produced by
Our goal was to find the word ‘vintage’. As the results show, ‘harvest’ is a better query term than ‘wine’ (488 vs 30 hits), and their combination is better than either of them (6 hits). What is more interesting is the fact that none of these terms allows us to access the target even though it is contained in the database of
Things are quite different if we build our index on the basis of information contained in
We hope that this example is clear enough to convince the reader that it makes sense to use real text (ideally, a well-balanced corpus) to extract from it the information needed (associations) in order to build indexes allowing users to find the words they are looking for.
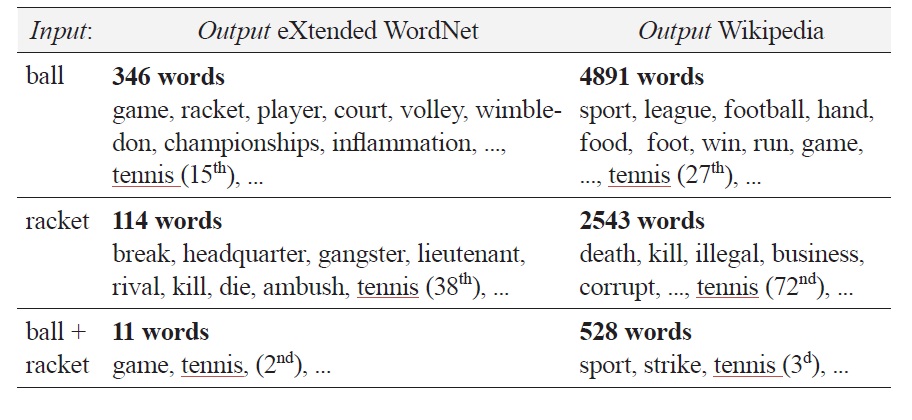
1.3.3 Analysis of this relative failure
One may wonder why we failed to access information contained in
Nevertheless, in order to be fair towards
In the remainder of this paper we will briefly sketch our roadmap for building a dictionary for the language producer.
1To avoid possible misunderstandings, our goal is not so much to build yet another lexicon as to add to it one or several indexes in order to ease navigation, as this is precisely what is lacking in most resources. 2Most ideas or concepts can be expressed via a set of means, i.e. semantically equivalent linguistic forms: synonyms (big-tall), paraphrases (minimize-limit the amount), periphrases (smarter-more smart), circumlocutions (scissor-tool for cutting paper), etc. 3It is interesting to note that while lexicalization has been a much studied problem in nlg—for excellent surveys see (Robin, 1990; Stede, 1995; Wanner, 1996), or, for some earlier work (Goldman, 1975) —the issue of lexical access has not been addressed at all, neither by any of the aforementionned authors nor by Cahill & Reape, 1999 or Ward (1988), who presents a problem catalog. Conversely, there is an enormous amount of research in psycholinguistics published either as edited volumes (Bonin, 2004; Levelt, 1992; Marslen-Wilson, 1979), as monographs (Aitchison, 2003; Jarema et al., 2002; Stemberger, 1985), or as journal papers. Many of them are devoted to speech errors (Butterworth, 1982; Cutler, 1982; Fay and Cutler, 1977; Fromkin, 1973), the tip-of-the-tongue phenomenon (Brown and McNeill, 1996, Burke et al. 1991), or the lexeme/lemma distinction (Kempen and Huijbers, 1983; Roelofs, 1992). While all these publications deal with the problem of lexical access, they do not consider how computers can be utilized to help humans in their task. This is precisely our goal. 4This experience is very similar to the feeling one has when looking for an existing object in the household or when trying to recall someone’s name. In all these cases something has been stored, but cannot be accessed in time. 5OneLook can be accessed on-line at http://onelook.com/reverse-dictionary.shtml. 6Imagine not knowing the meaning of ‘mitre’ or the differences between closely related words (‘caiman’, ‘crocodile’, ‘alligator’). 7Suppose one wanted to know whether the French say ‘le lune’ or ‘la lune’, when referring to the moon (lune). 8We used WN 2 rather than the most recent version WN 3. Nevertheless, the claim we make here applies to all dictionaries, regardless of their size. The weak point does not lie in the data (lexical coverage), but in the (lack of) quality of the index (structure of the dictionary). 9Optimal size is an empirical question, which may vary with the text type (encyclopedia vs. raw text). 10The reader not familiar with this groundbreaking work may consult the WordNet website (http://wordnet.princeton.edu/). 11Wikipedia is a collaboratively built, multilingual encyclopedia, freely accessible on the internet (http://www.wikipedia.org). The collaborative building of such resources (dictionaries, encyclopedias, etc.) has become quite popular over the last few years. For example, there have been two workshops devoted the collaborative building of semantic resources and their role and influence in NLP (ACL,2009; coling, 2010). 12Strangely, it did not have the same success in circles dealing with language production, neither among psychologists, nor in the NLG community. 13This problem has been recognized by the authors as the tennis problem (Fellbaum, 1998), meaning that topically related words are not stored together or cross-referenced. Hence, ‘ball’, ‘racket’, and ‘umpire’ appear on different branches of the hierarchy, even though all of them could be part of the very same topic, “the game of tennis”. Likewise, ‘instrument’ and ‘used_for’, appear in different parts of the resource, though they are (quasi-) synonyms. It should be noted though that efforts have been made to overcome these problems. For example, information may be found in the glosses (in the case of ‘used for’ and ‘instrument’), and topically related words may be accessed now to some extent (Boyd-Graber et al. 2006). 14In this experiment, we used our own part-of-speech tagger based on the English dictionary of forms, the DELA (http://infolingu.univ-mlv.fr/DonneesLinguistiques/ Dictionnaires/telechargement.html). 15This latter aspect is not implemented yet, but will be added in the future, as it is a necessary component for easy navigation (see Section 2.2.3).
2. A dictionary for the language producer
Obviously, dictionaries for the writer ought to be different from dictionaries for the reader with regard to the input, the structure, the index, and search facilities. There are at least three things that authors know when looking for a specific word: its
However, people seem to know more than that. Psychologists who have studied people in the tip-of-the-tongue state (Brown & McNeill, 1966; Vigliocco
2.1 A possible search scenario
When looking for a word, people tend to start from a close neighbour. For the sake of the argument, let us assume that they cannot think of a directly connected word, the only token coming to their mind being a word they know to be somehow connected to the Tw. Suppose, one were to express the following ideas:
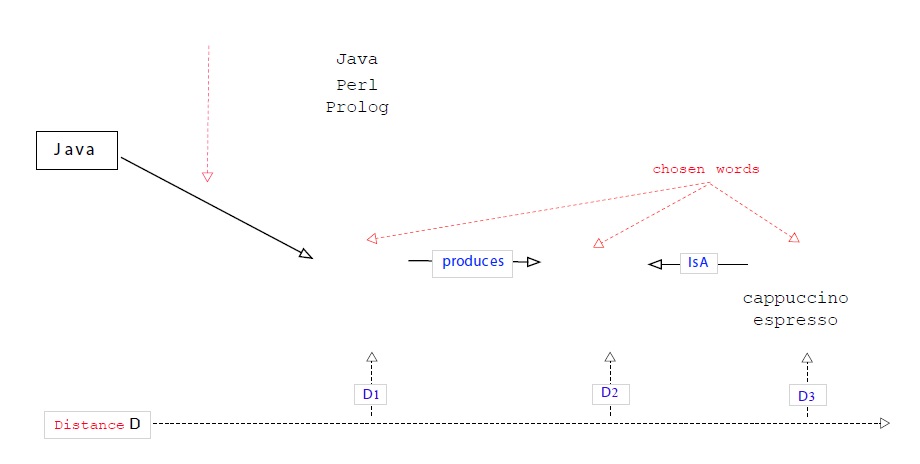
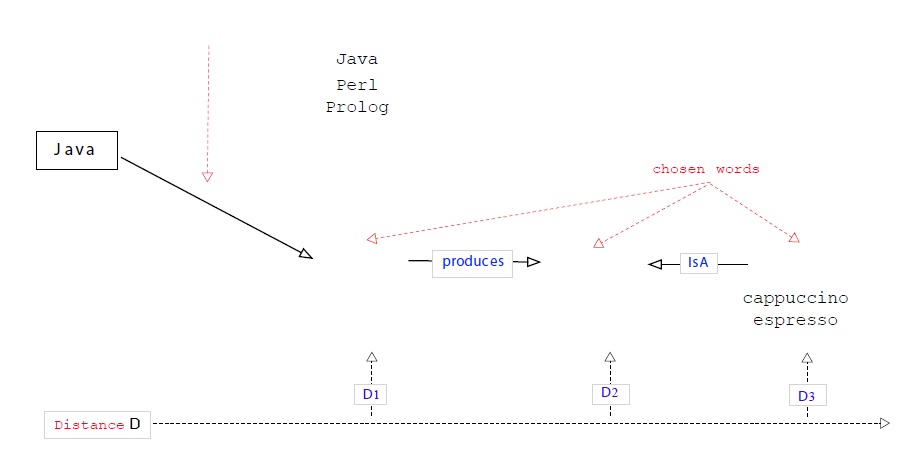
Let us see how this could work. Suppose one was looking for the word ‘mocha’ (target word: Tw), yet the only token coming to mind was ‘Java’ (query- or source word: Sw)18. Taking the latter word as the starting point, the system would show all the connected words. However, being ambig-uous—‘Java’ is a homonym, referring either to an island or to a
Of course, the word ‘Java’ might just as well trigger ‘Kawa’ which not only rhymes with the Sw, but also evokes ‘Couawa’, also written ‘Kawa’, an argotic word of coffee in French, or ‘Kawa Igen’, a javanese volcano. Last, but not least, the user could well have started with any other coffee producing country, unless she would start right away from a closely related associate of mokka, namely, a type of coffee or beverage made out of beans (probably the most frequent starting point). However, we wanted to show precisely that even if one does not start from a direct neighbour, it generally takes only a few mouse clicks to get from the Sw to the Tw.
Since everything is connected, words can be accessed via multiple routes. Also, while the distance covered in our example is quite unusual, it is possible to reach the goal quickly. It took us actually very few moves, to find a connection between the word ‘Java’ and ‘coffee beans’ or the drink made out of them. Of course, ‘cybercoffee’ fans, people thinking of a particular port city on the Red Sea coast of Yemen (Mocha), or people familiar with the fact that Melville’s novel
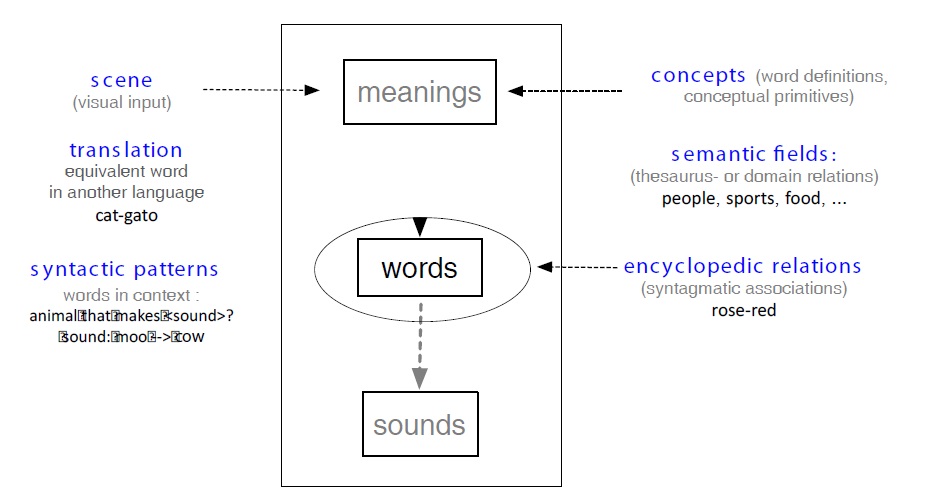
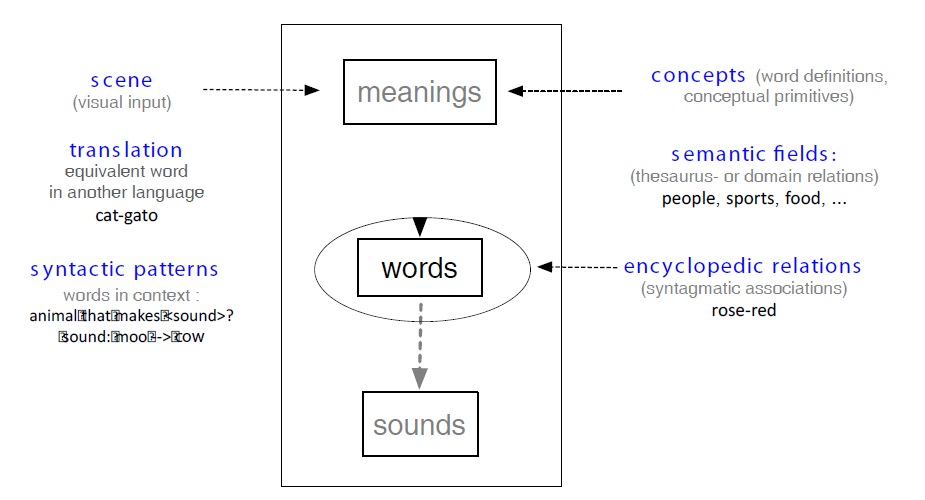
Search usually takes place somewhere, in some kind of space, and in order to help people find their way, we have built a map. Such maps can be built for many things, including a lexicon. Since our maps are mainly based on semantic information, we refer to them as semantic maps. Lexical graphs are such maps, with words being nodes, and the links being the roads leading from one word to the other. This is the fundamental structure of the network. In addition, links are qualified or typed (isa, synonym, etc.), and they are quantified (i.e. weighted).
Of course, there are various methods to build such a map. One way is to obtain lists of associations by asking people (Deese, 1965). This has been the main strategy of the psychologists who have built word association norms (Nelson
2.3 Navigating in the resource by using a lexical compass
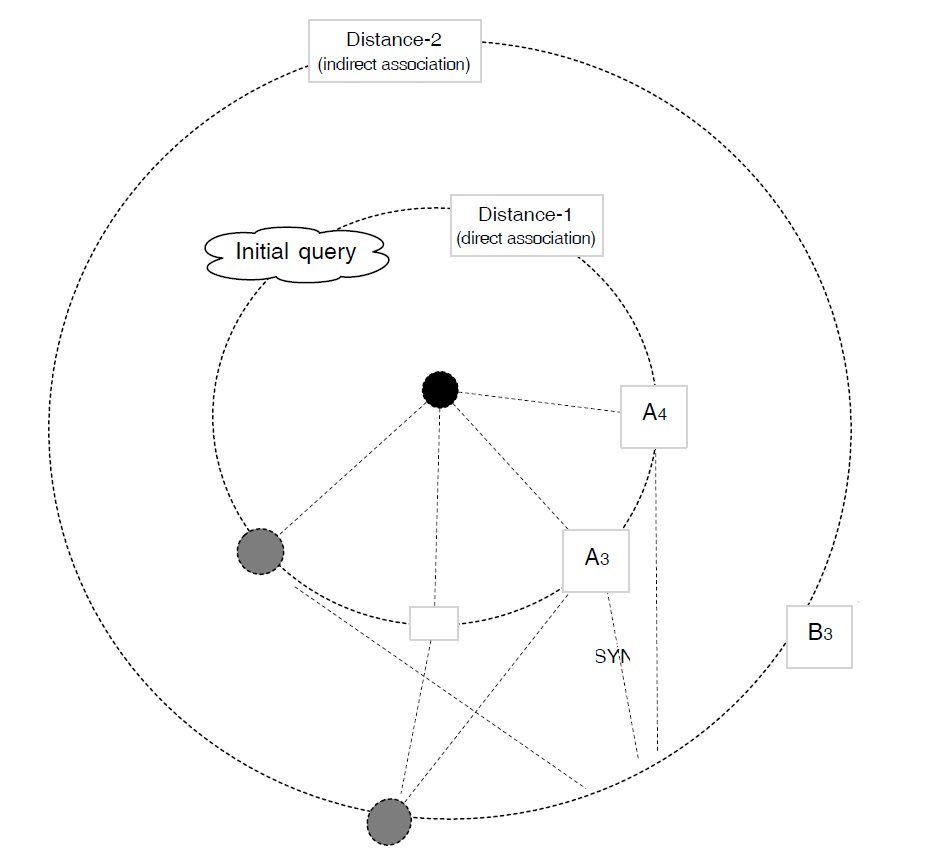
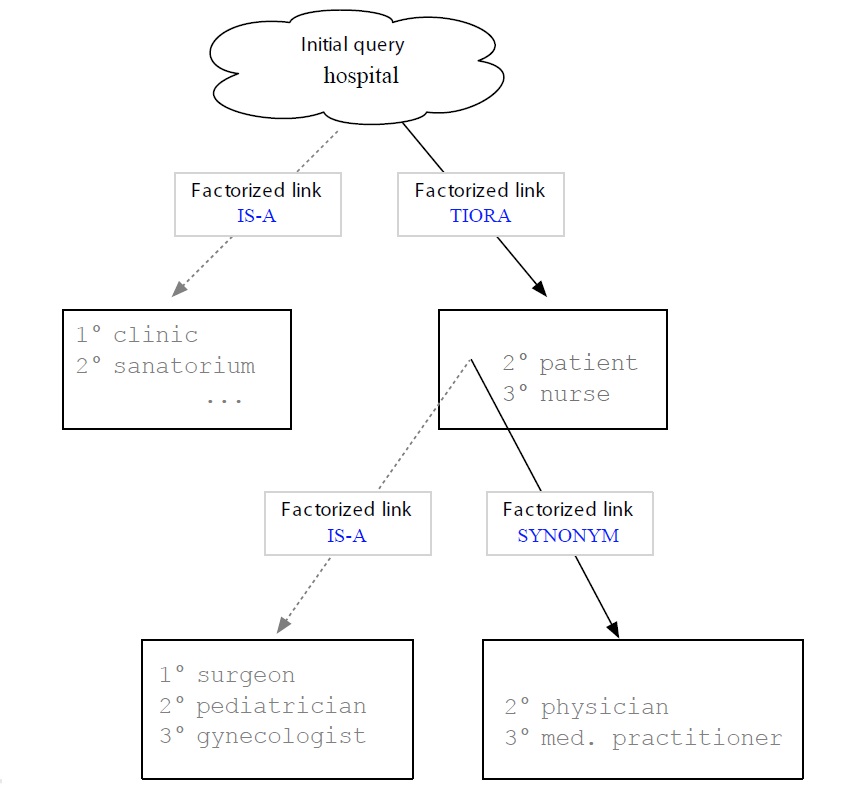
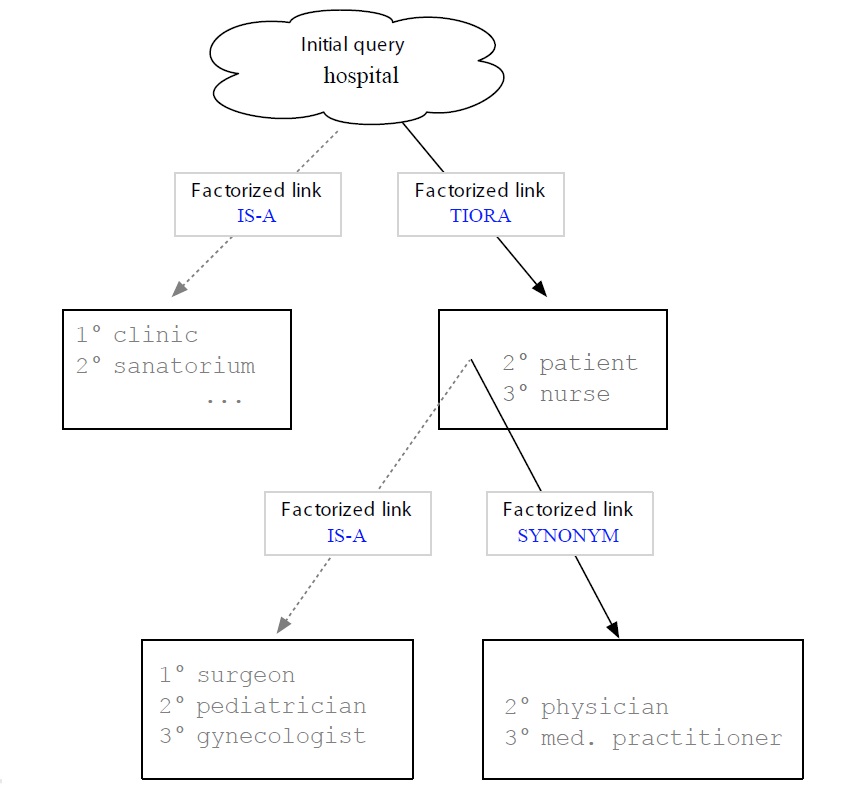
Once this resource is built, access is straightforward. The user gives as input a word he believes to be directly or indirectly connected to the Tw,25 say ‘hospital’, to which the system would answer with all immediate associates (‘clinic’, ‘sanatorium’, ‘doctor’). If the list contains the Tw, the search stops, otherwise it continues. The user chooses a word from the list (say, ‘doctor’) or a word being evoked by them (indirect association), and the system will reveal again all directly associated terms: ‘surgeon’, ‘pediatrician’, ‘medic’.
This problem cannot be solved via the well-known algorithm computing the shortest path between two nodes in a network, as this supposes that one knows both points. In our case we know only the starting point (user query), but not the end point (goal); if we knew it, there would be no need for search to begin with, we would just display the Tw. Nevertheless, even though the user does not know the Tw, he can recognize it (goal) if he sees it in a list.26 He can do even more. If, following his query (Sw), we give him a set of words, he will (arguably) know in most cases which one of them is the most promising one (i.e. the one closest to the Tw). As the reader can see, search is interactive. The user provides the
Obviously, there are some important differences between a conventional compass and our navigational tool. While the former automatically points to the north, letting the user compute the path between his current location and the desired goal (destination), the latter assumes the user knows the goal or at least her direction. While the user cannot name the goal (she has only passive knowledge), the system cannot guess it. However it can make valuable suggestions. In other words, the system can give hints concerning potential goals, but it is nevertheless the user who decides on the direction to go, as only she knows which suggestion corresponds to the goal, or which one of them is the most closely connected.
2.4 Potential interface problems
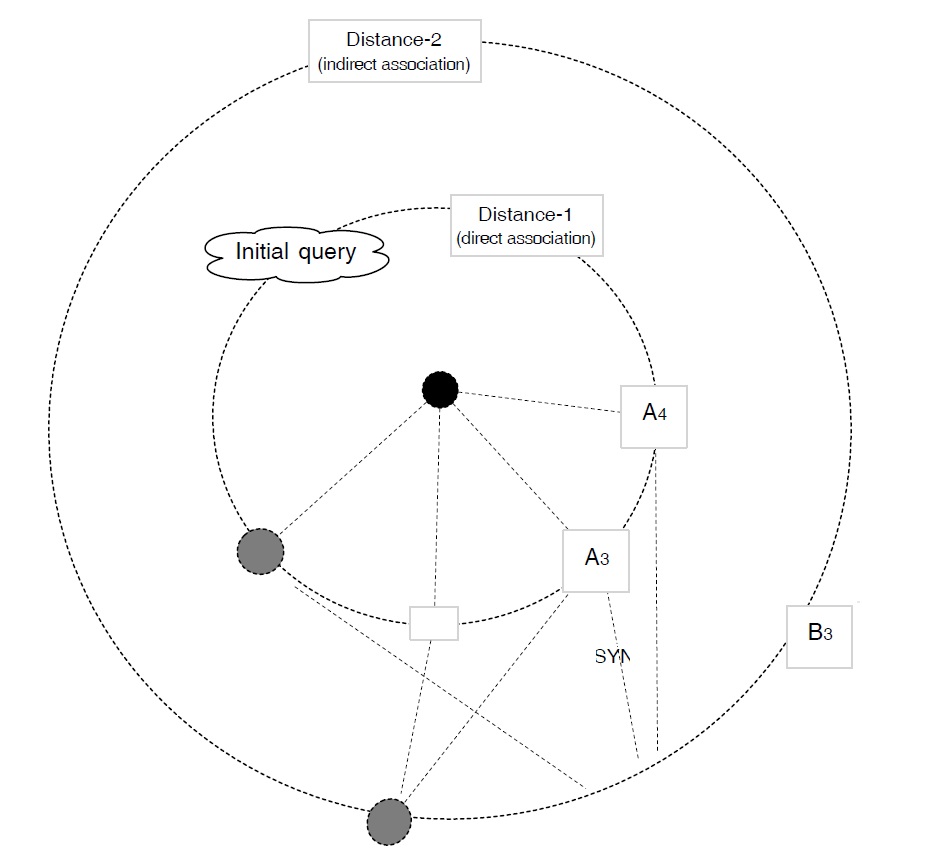
Since words occur in many different settings or syntactic contexts, every word is likely to have a rich set of connections. Obviously, the greater the number of words associated with a term, and the more numerous the type of links, the more complex the graph will be. This reduces considerably their interface value and their potential to support navigation. There are at least three factors impeding readability:
We believe that there is a fairly straightforward solution to the problem. Since all words are connected via one-directional links, we have a graph in which everything can be reached from anywhere, regardless of the starting point. However, our graph can also be seen as a set of trees. Since a search could be launched at any point—any node of the graph could become the query or starting point (i.e. the root of the tree)—we have as many trees as the graph contains nodes. Hence, the input (Sw, say ‘hospital’) would become the root of the tree, and the associated terms (i.e. output or potential target words) would be the leaves: ‘clinic’, ‘sanatorium’, ‘doctor’, ‘nurse’. If the input and output are linked via different kinds of association (‘hospitalclinic’ vs. ‘hospital-ambulance’), we create an intermediate node for each link, giving it the name of the link (‘subtype’ vs. ‘part-of’). Put differently, we create as many nodes as there are different kinds of links emanating from a given node.
In conclusion, rather than displaying all the connected words as a graph or as a huge flat list, we display them in hierarchically organized
This kind of presentation seems clearer and less overwhelming for the user than graphs, as it allows for categorical search, which is a lot faster than searching in a huge bag of words. Of course, this supposes that the user knows to which category a word belongs to, and that the labels (i.e. link names) are well chosen. This is crucial, as the names must be meaningful (i.e. interpretable by the user), which may be problematic in our example here. Figure 8 presents visually the rationale outlined above (Section 2.1), except that the Sw and Tw are not ‘Java’ and ‘mocha’ but ‘hospital’ and ‘medic’.
As one can see, the fact that the links are labeled has some very important consequences. First, while maintaining the power of a highly connected graph (possible cyclic navigation), it has at the interface level the simplicity of a tree: each node points only to data of the same type, (i.e. to the same kind of association). Second, with words being presented in clusters, navigation can be accomplished by clicking on the appropriate category. The assumption being that the user either knows to which category the target word belongs or can recognize within which of the listed categories it falls. It is also assumed that categorical search is in principle faster than search in a huge list of unordered (or, alphabetically ordered) words .
16WordNet++ is available at http://lcl.uniroma1.it/babelnet/. 17This feature of the mental lexicon (ML) is very important since if one method fails, it allows us to resort to another. It is also worth noting that a thesaurus and an encyclopedia can have an impact at two different levels, the level of ideas (brainstorming, conceptual level) and the level of words (linguistic level). Hence, a thesaurus can be used for conceptualization, that is, message specification (meaning) as well as for its expression (lexicalization). Indeed, authors often start from a broad concept (animal), which they gradually narrow down (reptile), before committing to a specific lexical form: alligator/crocodile/caiman. Likewise, encyclopedic relations (associations) may be used for message creation, as well as for finding a concrete lexical form. Concepts evoking (other) concepts (red-fire) and words priming other words (coffee-strong). In both cases the same mechanism is at work, though at different levels and operating on different elements: concepts in one case, words in the other. 18Note that this, just like many other homonyms, might lead us to a completely different domain: island vs. programming language. In other words, homonyms can be considered as a shortcut in the network. 19Note that ‘Java beans’, a notion inherent to java, the programming language, could get the user back on track, leading her to the desired target word expressing a specific beverage made out of coffee beans (mocha). 20http://www.eat.rl.ac.uk/ 21http://cyber.acomp.usf.edu/FreeAssociation 22http://www.schulteimwalde.de/resource.html 23http://www.coli. uni-saarland.de/projects/nag/ 24http://www.valdes.titech. ac.jp/ ~terry/jwad.html 25This is, or course a simple case. One could also think of several terms as input. 26This kind of passive knowledge is somehow akin to the tip-of-the tongue state. As psychologists (Brown and McNeill, 1966) have shown, people in this state have a lot of information concerning the Tw, to the point that, if this latter is presented to them, they can recognize it without ever making any mistakes. 27IS-A (subtype); SYN (synonym); TIORA (‘Typically Involved Object, Relation or Actor’, for example, tools, employees). 28Note, that the crossing of lines can be avoided in the immediate neighborhood (distance 1, i.e direct associations), but not at the next level. If two sets of words, say A1 and A3, on the one hand, and A2 and A4, on the other, have at the next level B1 and B2 as associates, then the links are bound to cross. Also, bear in mind that the scope is the entire graph and not only the next adjacent level (i.e. direct neighbors). Note also, that this crossing of links is a side-effect of mapping an n-dimensional graph on two dimensions. 29For example, a word like ‘coffee’ may be connected both to ‘beverage’ and to ‘export product’. Since words may participate in various scenarios (‘cat-chase-mouse’, ‘cat-play_with-mouse’ vs. ‘cat-cute’), they are connected via different kind of associations. Hence, a lemma may be accessed via different paths (i.e. it will be revealed at different points in the tree).
3. Conclusion and Future Works
We began this article by challenging the widely held assumption that stored information can always be accessed. Comparing two resources different in size and quality led to the conclusion that one needs a great deal of data of a various kind (encyclopedic, news) in order to index properly the lexcial resource. While indexes are vital for accessing data, there are many ways of building them. Since the ultimate users will be humans, the index should reflect their habits to classify objects or perceived relations between them.
Obviously, for a dictionary to be truly useful it must not only contain an abundance of information but must also reveal it when needed. To this end we suggest to index the data according to various points of view. This will yield a network in which anything is reachable from anywhere regardless of the starting point. As we know from every day life, and as psychologists studying the tip-of-the tongue problem have shown (Brown and Mc Neill, 1996), whenever we search for something we have stored, say, a word, we can access some kind of information concerning the target object. This kind of information should be utilized. However, knowledge is variable, changing from person to person, and moment to moment. Hence our tools should be able to accommodate this fact.
In order to capture the kind of information needed and in order to build the resource just described, we propose to take a mix of corpora and to extract both stable as well as dynamic knowledge. While the former is more likely to be found in encyclopedias and books containing more or less universally shared information, the latter is more local and often found in the news.
Among the many issues to be addressed is the building of a prototype for a small domain to see whether or not our intuitions hold, the final judge being of course the user. Among the problems that we have to address are the notion of links (there is no satisfying list available at the moment) and the problem of interpreting user queries. Obviously, a given query will have different meanings depending on the moment of its usage. For example, in the ‘mocha’ example, the user giving ‘island’ as key expects specific information concerning the ‘island Java’ and not just any island, or ‘islands’ in general.
While more work is needed, we do believe that it is worth the effort, for through this endeavor one will learn something about the functioning of the human mind and the structure of the mental lexicon. In addition, the problems addressed (indexing and navigation) go well beyond language and deal as well with human memory (i.e. how information is structured, indexed and stored).