In this paper we propose a model of human sentence processing that is based on Optimality Theory (OT). In contrast to most other OT approaches to language processing, we use constraints from OT semantics rather than OT syntax to address on-line comprehension. We illustrate the workings of our model by investigating the processing of coordinated structures. The psycholinguistic evidence that is currently available suggests that the on-line comprehension of coordination is influenced by constraints from many different information sources: pragmatics, discourse semantics, lexical semantics, and syntax. The model we propose formalizes this cross-modular interaction of constraints, and yields concrete predictions with respect to both intermediate parsing preferences and final interpretations. Our ultimate aim is to develop a model of processing performance that at the same time is a fully functional model of linguistic competence.
Optimality Theory (OT) is a powerful model of decision making in situations where there are multiple constraints pertaining to one or more alternative options. It was originally introduced as a model of linguistic
In most constraint-based models of language processing (e.g., models proposed by MacDonald, Pearlmutter, & Seidenberg, 1994, and by Trueswell & Tanenhaus, 1994), the interpretation of language input is conceived of as a process where many different, often probabilistic, factors provide support for one or the other syntactic structure that is possible under the current language input. The syntactic structure that receives the most support from the various sources of information will eventually be chosen by means of a competition process (MacDonald, 1994; MacDonald et al., 1994; McRae, Spivey-Knowlton, & Tanenhaus, 1998; Spivey-Knowlton & Sedivy, 1995; Tanenhaus & Trueswell, 1995; Trueswell & Tanenhaus, 1994). To differentiate between these standard models based on
2. Proposed OT Model: General Mechanism
In OT, inputs are mapped onto outputs by first generating the possible candidates for each input, which is accomplished by the function GEN (short for
In our present model, linguistic knowledge
Our model of sentence processing builds upon findings in two distinct but complementary approaches in OT. In
In the last few years it has become increasingly clear that speaking and listening are highly interdependent processes (e.g., Blutner, 2000; Blutner, de Hoop & Hendriks, 2006; Boersma, 1998; Bouma, 2008; Clark, 1996; Hendriks, de Hoop, Krämer, de Swart & Zwarts, 2010). Listeners may take into account the (syntactic) possibilities that speakers have to their disposal to realize their messages, and speakers are sometimes influenced by their knowledge of the listener. Thus, message formulation and comprehension seem to be closely intertwined. In Sections 3.2 and 3.3 we will give examples of constraints that apply to message formulation and comprehension alike. This interrelation of speaker’s demands on the one hand and hearer’s demands on the other is sometimes also modeled by
So how does our OT model work? Look, for example, at the following table, which in OT-terminology is called a ‘tableau’:
[Tableau 1.] Optimization of a sentence fragment
Optimization of a sentence fragment
In this tableau constraints are listed from left to right in order of descending strength, so constraint 1 is stronger than constraint 2 (and stronger also than any other constraint that is placed on the right of it), which can be expressed as “Constraint 1 >> Constraint 2 >> ...”. Importantly, violation of a stronger constraint is more serious than violation of a weaker constraint. The input is given in the top left-hand corner of the tableau, and candidate outputs are listed in the first column below the input. For expository reasons, only a relevant subset of candidate outputs is present, in the form of possible parses of the input form (e.g., S-coordination, VP-coordination, NP-coordination). One should keep in mind, though, that the actual output is not merely a syntactic structure, but also a semantic - and a pragmatic - interpretation of this structure. That is, terms like S-coordination, VP-coordination and NP-coordination are used here to refer to aspects of interpretation, such as whether an NP must be interpreted as a subject or an object or whether the subject of the verb preceding the conjunction also is the subject of the verb following the conjunction, rather than to purely structural properties of an expression. The candidates do have a syntactic structure, though, and can be accepted or rejected on the basis of syntactic constraints. To get a flavor of what these candidates might look like, let us look at a very simple input utterance: “dog bites man”. The candidate interpretations, each of which consists of a pairing between the given input form and the possible interpretation (
This is of course a very simplified example, and candidate interpretations also carry information regarding event structure, anaphoric relations etc. Basically, we adhere to the ‘immediacy of comprehension’ hypothesis formulated by Just and Carpenter (1980), and assume that even incomplete sentences are interpreted as completely as possible, up to and including the highest level of discourse.
The success of an enterprise such as ours crucially depends on showing the applicability of the model for every structure in a given language, especially where ambiguity or complexity are concerned. To this end, we will first make an in-depth excursion into one area, coordinated structures, essentially to identify the relevant constraints and establish their hierarchical order on the basis of empirical evidence regarding on-line processing, but also to provide an existence proof that our proposed incremental OT model of interpretation can work. Some confidence that this is indeed the case comes from the pioneering work of Stevenson and Smolensky (2006) who showed that several instances of syntactic ambiguity resolution can - in principle - be described in terms of an incremental OT model of syntactic competence and performance (cf., Fanselow, Schlesewsky, Cavar, & Kliegl, 1999; Singh, 2002; but see Gibson & Broihier, 1998). Our approach is in many ways very similar to the one described earlier by Stevenson and Smolensky (2006), but crucially extends their model by using constraints from OT
We want to make it clear that we aim to use constraints that have already been proposed in the theoretical and empirical literature, and that have received some form of independent support. All other constraints will be viewed as tentative. In addition, it is essential that constraints are formulated as generally as possible, as we want to identify the general principles that are involved in comprehension. Finally, using the same constraints in the same order for every sentence in the language, as required by the OT definition of grammar, will permit us to generate clear predictions. First, in the next section, we will show that OT is indeed a feasible model of language processing by looking at the processing of (temporarily) ambiguous coordinated structures.
3. Proposed OT Model: Introducing the Constraints Relevant for
Coordination
On the basis of a set of studies (e.g., Frazier, 1987a; Frazier & Clifton, 1997; Hagoort, Brown, Vonk, & Hoeks, 2006; Hoeks, 1999; Hoeks, Vonk, & Schriefers, 2002; Hoeks, Hendriks, Vonk, Brown, & Hagoort, 2006; Kaan & Swaab, 2003) regarding the on-line processing of coordination, we will argue that the interpretation of coordinate structures is dependent on a number of constraints of different kinds: 1) pragmatic , 2) discourse-semantic, 3) syntactic, and 4) lexical-semantic. Adopting the framework of OT allows us to formalize this
It was hypothesized that readers prefer to take the ambiguous NP
With these materials it is possible to compare sentences that are identical in sentence meaning, and to compare regions that are identical in length, frequency, and syntactic category. Hoeks et al. (2006) found modest, but reliable evidence for the NP-coordination preference. The same materials were used by Hagoort et al. (2006) in an ERP experiment examining how the brain responds to reading temporarily ambiguous S-coordinations. They found that these sentences evoke a P600-effect, or SPS (i.e., Syntactic Positive Shift) relative to unambiguous control sentences. A P600/SPS is an ERP component generally elicited by ungrammatical sentences (Hagoort, Brown, & Groothusen, 1993; Osterhout & Holcomb, 1992), sentences with an unpreferred syntactic structure (Osterhout & Holcomb, 1992) or syntactically complex sentences (Kaan, Harris, Gibson, & Holcomb, 2000), although the P600 has also been reported to occur following semantic violations (e.g., Hoeks, Stowe, & Doedens, 2004). The size of the P600-effect in the Hagoort et al. experiment was relatively small, indicating that the processing difficulty as a result of the NP-coordination preference is rather modest. This same conclusion can be reached from the results of a study by Kaan and Swaab (2003). Though they did not report the statistical reliability for the comparison that is of interest here, their figures show a (modest) P600/SPS for the non-preferred S-coordination (e.g.,
In sum, all of the studies on the NP- versus S-coordination ambiguity show that when the ambiguous NP is encountered, readers prefer to interpret it as an argument of the first main verb (i.e., NP-coordination) instead as the subject of a new clause (i.e., S-coordination). As a result, temporarily ambiguous S-coordinations give rise to (modest) processing difficulty. It has generally been ignored, however, that there is an earlier point at which the sentence is ambiguous, and that is at the connective itself. Before the ambiguous NP is read, the sentence can continue as an NP- or an S-coordination, but also as a
And indeed, recent evidence from sentence completion studies has shown that language users strongly prefer to continue a fragment such as (4) as a VP-coordination.
In about 86% of all cases coordinated VPs were produced, as opposed to 9% NP-coordinations and 5% S-coordinations (Hoeks et al., 2002, Exp. 1).1 This outcome suggests that language comprehenders expect the connective to be followed by a VP, not by an NP. Only when the NP is actually presented, and VP-coordination is no longer possible, NP-coordination becomes the preferred structure. This finding provides us with important clues as to which constraints may be necessary to describe the processing of coordinate structures. Of course, it is necessary to supplement the observations from the off-line completion study with solid
3.1 OT Constraint (1): A Pragmatic Constraint on Coordination
Why should there be a VP-coordination preference at the connective? According to Hoeks et al. (2002) the preference for VP-coordination derives from the fact that language users, and especially readers, must construct their own default ‘topic-structure’ in the absence of prosodic or other topicmarking cues. Topic-structure can be loosely defined as describing the relation between the
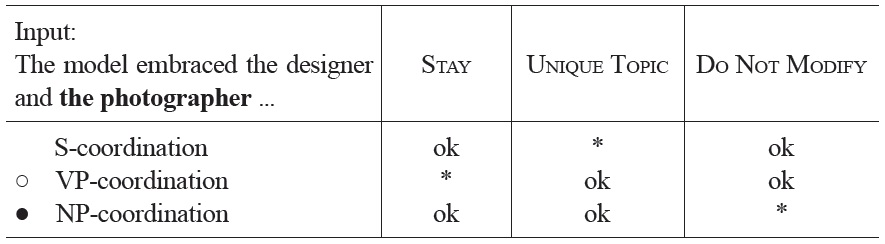
Importantly, the UNIQUE TOPIC constraint does not differentiate between VP-coordination and NP-coordination, as both constructions have but one topic, namely the subject of the sentence (see Tableau 2).
[Tableau 2.] Optimization of sentence fragment (4) at the occurrence of and

Optimization of sentence fragment (4) at the occurrence of and
However, language users do seem to prefer VP-coordination over NPcoordination at the connective. Thus, another constraint must be involved in creating this preference.2
3.2 OT Constraint (2): A Discourse-Semantic Constraint on Coordination
We would like to propose that the constraint prohibiting NP-coordination is the discourse-semantic constraint Do Not Modify, which is a variant of a constraint proposed earlier by Singh (2002) as “Do not excessively modify any thing or event” (Singh, 2002, p.35) and belongs to the family of economy constraints in OT (e.g., Legendre et al., 2001).
If additional information has to be incorporated into the hearer’s model of the discourse, this constraint clearly favors the introduction of a new event to elaboration of a previously introduced event. In the sentence at hand, the listener therefore prefers VP-coordination as in (3), where there are two distinct events (e.g., embracing and laughing), to NP-coordination where there is only one event (e.g., embracing) which is modified by adding another participant (e.g., the photographer).
Under the analysis we propose, this aversion to modification of events arises because at the point where the first object NP (e.g., the designer) has been processed, the ‘embracing’ event seems sufficiently described from the point of view of the reader, and all thematic roles of the verb are satisfied by the two available arguments. This stable interpretation would then be disturbed by the addition of an element that is new, that has not been introduced, and that somehow has to receive an extra argument role. The effect of DO NOT MODIFY, then, is the promotion of events that are only minimally elaborated. This constraint is not specific for coordination: it applies to all kinds of modification and as such it is closely related to the ‘principle of referential success’, proposed by Crain and Steedman (1985). There, it is assumed that readers or hearers do not expect modifiers of things or events unless those are expressly required for unique identification. Many language comprehension studies have provided support for this principle (Altmann & Steedman, 1988; Ni, Crain, & Shankweiler, 1996; Van Berkum, Brown, & Hagoort, 1999; but see also Clifton & Ferreira, 1989; Mitchell, Corley, & Garnham, 1992).
To summarize, with the two constraints defined above, we can now describe one step in the incremental comprehension of coordinated structures, and explain how the VP-coordination preference arises at the connective in structures such as (4). Tableau 3 displays how the optimal VPcoordination interpretation is chosen from among the alternatives (we only show the most prominent ones). In OT it is assumed that constraints are hierarchically ordered, that is, from strongest constraint to weakest constraint. However, in this case both orderings, namely UNIQUE TOPIC >> DO NOT MODIFY and DO NOT MODIFY >> UNIQUE TOPIC produce the same optimal candidate, VP-coordination. In such instances, where there is no direct conflict between constraints, more evidence is needed to specify the correct ranking. This is signified by a dashed instead of a solid boundary between the constraints in Tableau 3 (see Anttila & Cho, 1998, for a discussion of ‘partial ranking’ within OT).
[Tableau 3.] Optimization of sentence fragment (4) at the occurrence of and

Optimization of sentence fragment (4) at the occurrence of and
3.3 OT Constraint (3): A Syntactic Constraint on Coordination
Now let us consider the situation in which the conjunction
We have seen that at the time the conjunction
So, the VP-coordination parse violates the constraint STAY if the second conjunct starts with an NP. If the constraints STAY and UNIQUE TOPIC both outrank DO NOT MODIFY, as in Tableau 4, this will account for the empirical observations discussed above that support the NP-coordination preference for (5). This fact also settles the indeterminacy of the ordering of UNIQUE TOPIC and DO NOT MODIFY. If namely the ordering STAY >> DO NOT MODIFY >> UNIQUE TOPIC is assumed, this will yield S-coordination as the optimal parse, which goes against our empirical observations.3
Note that the optimal parse of (5), corresponding to the NP-coordination interpretation, violates the DO NOT MODIFY constraint, which made NPcoordination sub-optimal in sentence fragment (4) (see Tableau 3). Nevertheless, NP-coordination is optimal in (5) because the competing analyses violate stronger constraints.
[Tableau 4.] Optimization of sentence fragment (5) at the occurrence of the photographer
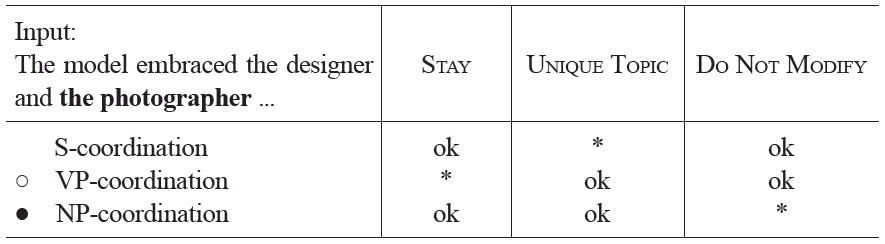
Optimization of sentence fragment (5) at the occurrence of the photographer
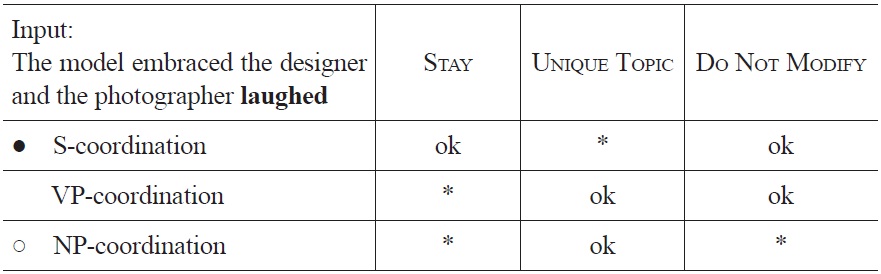
Finally, when in a sentence such as (5) the ambiguous NP is followed by a finite verb, as in (6), all options but the S-coordination are rejected by STAY and other, not further specified syntactic constraints, as no NP-coordinated or VP-coordinated sentence can be construed from the current ordered set of words (for convenience we will use STAY as a label for all of those).
During the processing of the S-coordinated sentence (6), there are two occasions where there is a shift from one interpretation to another: 1) when the ambiguous NP is read, the preference for VP-coordination shifts to a preference for NP-coordination, as VP-coordination becomes structurally impossible, and NP-coordination does not violate the UNIQUE TOPIC constraint, and 2) on the arrival of the disambiguating verb the NP-coordination reading becomes impossible and the S-coordinated alternative that has long been suboptimal, then becomes the optimal interpretation of the sentence.
Based on the ‘Linking Hypothesis’ (i.e., linking linguistic competence and performance) proposed by Stevenson and Smolensky (2006), our assumption is that each of these shifts from one interpretation to another gives rise to processing difficulty. We also concur with them in that
[Tableau 5.] Optimization of sentence fragment (6) at the occurrence of laughed
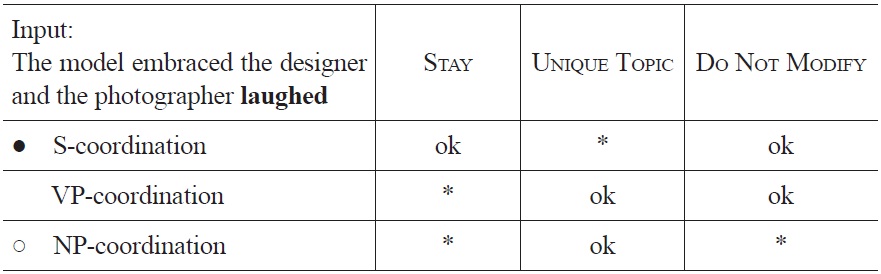
Optimization of sentence fragment (6) at the occurrence of laughed
In the beginning of this section, we summarized a number of studies showing that there is indeed processing difficulty at the disambiguating verb of the S-coordinated sentences that are in focus here. Unfortunately, there is no empirical work explicitly testing whether there is processing difficulty due to the VP-coordination preference at the ambiguous NP in structures such as (5). Nevertheless, the OT model that is formulated in Tableau 5 seems to adequately capture all relevant aspects of processing coordinated sentences such as (6) and predicts that there will be processing difficulty at the ambiguous NP due to the VP-coordination preference. Future research must determine whether this prediction is borne out.
The constraints on language comprehension that were introduced in this section and the previous one, DO NOT MODIFY and STAY are strongly tied to language
Crucially, the two constraints are
3.4 OT Constraint (4): A Lexical-Semantic Constraint on Coordination
An important factor in the interpretation of linguistic utterances that we have not dealt with yet is plausibility. Plausibility can be thought of as involving three broad, interrelated categories of conceptual knowledge: 1) lexical semantic, or ‘thematic’ knowledge (e.g., how well thematic elements fit their thematic roles), 2) knowledge about the discourse that is presently under consideration, and 3) general knowledge about the world. For our purposes, we will only discuss the role the first kind of plausibility, that is, the one regarding thematic information, plays in our model. According to McRae et al. (1998), a thematic role is “.. the semantic role or mode of participation played by an entity in the activity or event denoted by the verb” (McRae et al., 1998, p. 284). Thematic fit, then, is event-specific world knowledge, reflecting the degree to which the semantic features or an entity fit the requirements of the thematic role it is assigned by the associated verb. The chances for alternative interpretations to be optimal decline if thematic fit of an argument is poor given the requirements of the thematic role assigner that is associated with it. The use of thematic role information in parsing has been studied extensively (e.g., Clifton, Traxler, Mohamed, Williams, Morris, & Rayner, 2003; Just & Carpenter, 1992; Ferreira & Clifton, 1986; McElree & Griffith, 1995; McRae, Feretti, & Amyote, 1997; McRae et al., 1998; Stowe, 1989; Tanenhaus, Carlson, & Trueswell, 1989; Trueswell, Tanenhaus, & Garnsey, 1994; see also Pickering & Traxler, 1998). One of the best known sentences in this context is undoubtedly (7), taken from Ferreira and Clifton (1986).
In this sentence, the verb
Here, the poor thematic fit between
Thus a lexical-semantic factor such as thematic fit is of great influence on the processing of coordination. We will call the associated constraint THEMATIC FIT (adapted from de Hoop and Lamers, 2006; Lamers and de Hoop, 2005)
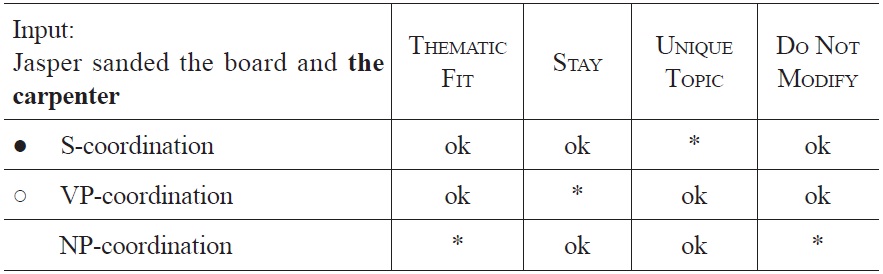
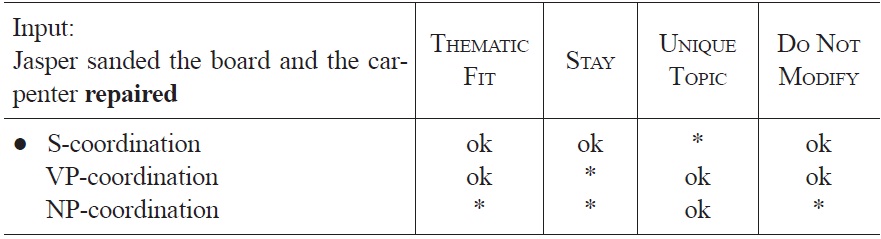
Tableau 6 shows how the constraints interact at the time the ambiguous NP
[Tableau 6.] Optimization of sentence fragment (9a) at the occurrence of the carpenter
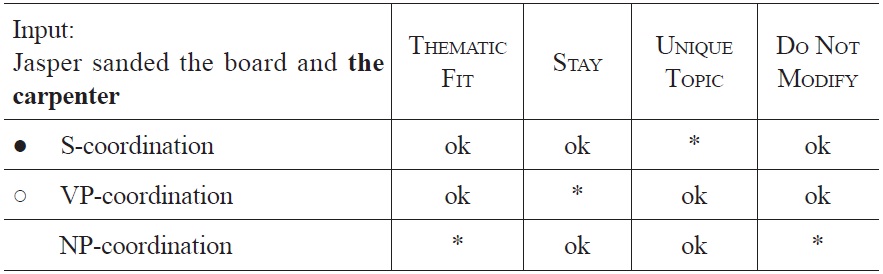
Optimization of sentence fragment (9a) at the occurrence of the carpenter
[Tableau 7.] Optimization of sentence fragment (9a) at the occurrence of repaired
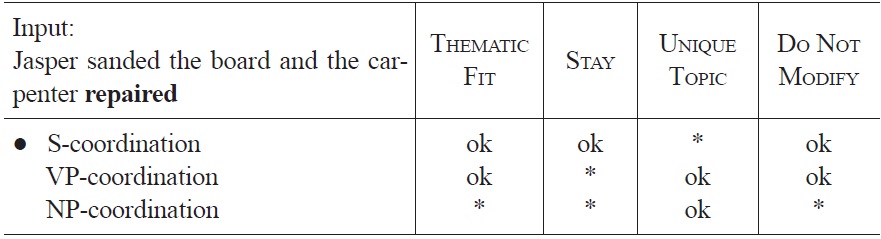
Optimization of sentence fragment (9a) at the occurrence of repaired
Because the preferred analysis at the ambiguous NP is the same as at the following verb (i.e., both times S-coordination), there is no shift from one interpretation to another, and hence no processing difficulty is predicted at the disambiguating verb.
1There is evidence that using so-called ‘bare plurals’ instead of definite NPs as grammatical objects may change the pattern of completion (Blodgett and Boland, 1998). Explaining why this might be the case goes beyond the scope of this paper. 2In this example and subsequent ones, we will assume that readers only consider coordination of elements of the same category, that is: S and S, or NP and NP, but not S and NP. However, we believe that this is not so much a constraint on interpretation, but rather an effect of readers taking into account production results. Following Gáspár (1999), we assume sentence production to be subject to the constraint Fusion, which forces duplicate elements to be fused. If this constraint is ranked above the constraints responsible for X-bar structure, the X-bar schema is predicted to be violable. However, violations will only be allowed in order to satisfy Fusion, that is, to yield a coordinate structure. The resulting structures will generally conform to the so-called ‘law of coordination of likes’ (see, e.g., Chomsky, 1957; Schacter, 1977). If we assume that readers take into account which structures are possible structures in production (as is formalized in bidirectional OT, cf. Blutner, 2000), it follows that they will only consider options where the conjuncts are of the same type in comprehension. 3At the ambiguous NP, two constraint orderings produce the desired NP-coordination preference, namely, STAY >> UNIQUE TOPIC >> DO NOT MODIFY and UNIQUE TOPIC >> STAY >> DO NOT MODIFY. At the disambiguating verb, there are three constraint orderings that produce the S-coordination as the optimal candidate, namely STAY >> UNIQUE TOPIC >> DO NOT MODIFY, STAY >> DO NOT MODIFY >> UNIQUE TOPIC, and DO NOT MODIFY >> STAY >> UNIQUE TOPIC. Because OT requires an invariant ordering of constraints, STAY >> UNIQUE TOPIC >> DO NOT MODIFY must be the correct order.
4. The Proposed OT Model Compared to Other Models of Performance
OT and existing constraint-based models are actually very close with respect to their theoretical foundation. Both are based on principles of interacting constraints from all linguistic levels and both assume that syntactic information has no special status, as in, for instance, the garden-path model (e.g., Frazier, 1987a). In fact, OT can be seen as a special case of constraintsatisfaction theory, where instead of numerical strength- and weightparameters, a hierarchy of constraints is assumed that is characterized by strict domination. Thus, OT and the standard models may make the same predictions in all cases where multiple constraints interact. If two theories have equally broad empirical coverage, the only thing to decide between them are meta-theoretical advantages that we will show our model has. In the following, we will discuss these
As we said, our present OT model of sentence processing has very much in common with the standard constraint-based models proposed by Trueswell and Tanenhaus (1995) and MacDonald et al. (1994). These models were the first in which the interaction of multiple constraints during ambiguity resolution was given a theoretical foundation. In the best-known computer-implementation of the constraint satisfaction process, the so called competition-integration model (McRae et al., 1998; Spivey-Knowlton & Sedivy, 1995; Spivey & Tanenhaus, 1998), syntactic alternatives (typically two) are represented as pre-existing localist nodes in a connectionist network. The nodes representing the alternatives are connected to ‘source’ nodes representing a variety of information sources: semantic (e.g., thematic fit of a given NP-Verb combination, as estimated by off-line ratings), syntactic (e.g., a general bias for a certain syntactic structure, as estimated from a corpus), pragmatic (e.g., a discourse context biasing towards one of the syntactic alternatives, again estimated from off-line ratings), lexically probabilistic (e.g., the frequency with which a given lexical item is used with a specific argument structures, estimated from a corpus or completion study), but also ‘practical’ factors such as the possibly disambiguating information that can be gleaned from parafoveal preview during reading. Each of these constraints provides some degree of support for one or both of the syntactic alternatives, depending on a) the
Though the OT model and the standard models are quite close, and will in many circumstances make identical predictions regarding ambiguity resolution (and sentence processing as a whole) there are also important differences that set them apart. First, standard constraint-based models have no explicit, testable model of linguistic competence. For instance, the competition-integration model (e.g., McRae et al. 1998; Spivey-Knowlton & Sedivy, 1995; Spivey & Tanenhaus, 1998) relies on an unspecified module to produce the syntactic alternatives that enter the competition process. The lexicalist model proposed by MacDonald (1994) is more explicit about how syntactic structure is actually produced, but seems to depend on unspecified sources of syntactic knowledge from outside the lexicon to construct syntactic representations. Some researchers have voiced doubt on whether it is possible to devise a purely lexically based parser, especially because it may not work well for verb-final languages (e.g., Frazier, 1995). In addition, coordination may present an extra problem for this kind of model, as evidenced by the computational model for a lexical grammar developed by Vosse and Kempen (2000), which is unable to handle coordinated structures (Vosse & Kempen, p. 130). In our OT model, however, the model of competence and the model of performance coincide, as constraints of the grammar
A second disadvantage of standard models is the difficulty they pose in making concrete predictions. The mechanism underlying standard constraint-based models such as the competition-integration model (McRae et al., 1998) is such that specific predictions can only be derived by running the computer simulation, because so many continuous numerical parameters are involved, as we will see below. Running such a simulation, however, is very difficult because of problems with a) identification of the factors that are involved; b) assessment of the
Corpus frequencies may not agree with data from sentence completion studies aimed at finding the strength of a constraint. Again, coordination is a good example, as completion studies show a strong VP-coordination preference at the connective which is reflected in some fine-grained frequency counts but not in others, and certainly not in coarse-grained frequency counts. See Rayner and Clifton (2002) for an overview of the literature pertaining to the sometimes problematic use of frequency counts and completion data in sentence processing research (cf. Gibson & Schütze, 1999; Gibson, Schütze, & Salomon, 1996; Merlo, 1994; Pickering, Traxler, & Crocker, 2000; Roland & Jurafsky, 2002; but see Desmet, Brysbaert, & De Baecke, 2002; Mitchell, Cuetos, Corley, & Brysbaert, 1995; Swets, De Baecke, Drieghe, Brysbaert, & Vonk, 2006). And to the last point, (c), there is not yet a fool-proof recipe to independently establish valid weights for the different constraints in the simulation of the competition-integration model (see McRae et al., 1998; Spivey-Knowlton & Sedivy, 1995, Spivey & Tanenhaus, 1998, for discussion). OT, then, appears to be more transparent and to have the distinct, if meta-theoretical, advantage of permitting clear predictions, that can sometimes even be derived by hand, because it assumes that the same general set of constraints applies to all structures in the same invariant order. It is thus much stricter than the standard constraint-based models which seem, in a number of ways, too flexible (e.g., in terms of unconstrained number of factors and strength and weight parameters) to make concrete predictions (see also Hoeks, 1999; Narayanan & Jurafsky, 2004, for similar criticisms).
A third disadvantage of the standard models, and especially of lexicalist ones, is their inability to model the interpretation of ungrammatical utterances. It is generally accepted that ungrammatical utterances are rather frequent, especially in spoken language (cf. Antoine, Caelen, & Caillaud, 1994). Because an ungrammatical string cannot be
A final criticism concerns the mechanism that standard constraint-based models propose for the constraint interaction process. Syntactic alternatives are assumed to compete with each other on the basis of the evidence that is available for each, until the system settles into some kind of stable state. If all constraints favor one of the alternatives, this stable state is reached very quickly, at no or little processing cost. However, if the alternatives are equally strongly supported, it will take much longer before a stable state is reached, resulting in measurable processing difficulty. Until now the predictions made on the basis of this mechanism have not received unequivocal empirical support, especially when it comes to the processing of sentences that are globally ambiguous. Here, considerable processing difficulty is predicted when the evidence for each of the competing candidates is (approximately) equally strong. However, there is ample evidence that processing these global ambiguities is actually
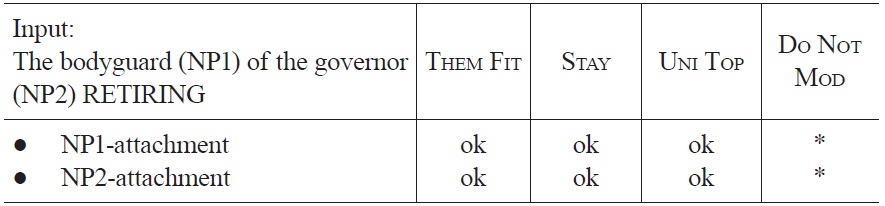
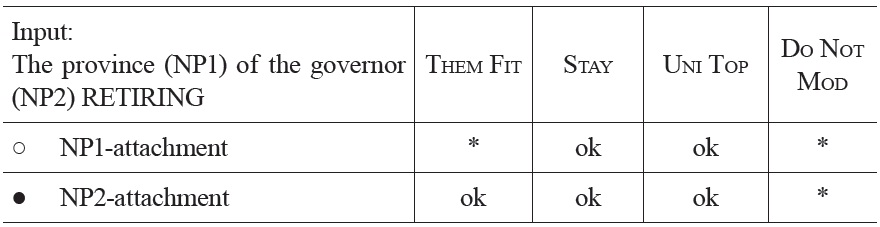
In sentences (10a-c), the relative clause ‘retiring after the troubles’ can either be attached to the first NP of the sentence (high attachment) or to the second NP (low attachment). In the first two sentences, competition between the alternative analyses can be rather short because plausibility information from the critical word
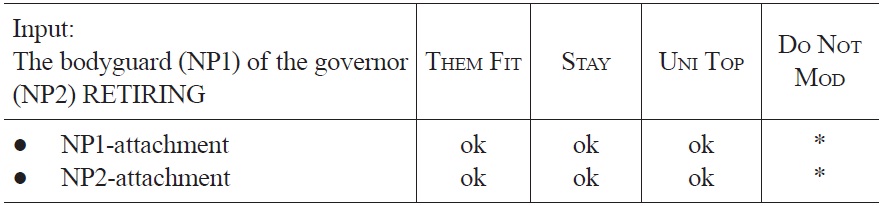
Optimization of the fragment “The bodyguard of the governor retiring ...” at the occurrence of retiring
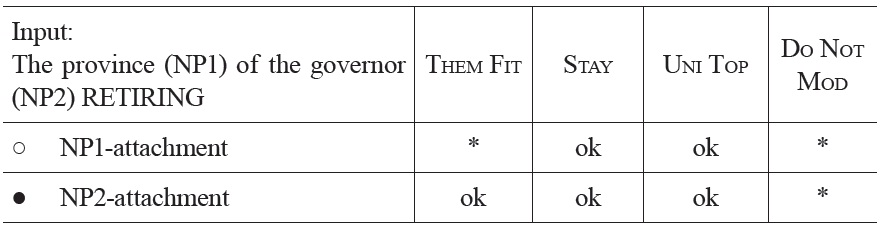
Optimization of the fragment “The province of the governor retiring ...” at the occurrence of retiring
In response to the findings by Van Gompel et al. (2005), Green and Mitchell (2006) reported a series of computer simulations suggesting that the competition-integration model can also account for the ambiguity advantage. However, a detailed investigation into Green and Mitchell’s simulations (Hoeks, Fitz, & Brouwer, submitted) has casted doubt on this conclusion and suggested that the solution Green and Mitchell propose is not psychologically plausible.
One final point we want to make is the following. An important feature of standard constraint-based models, namely their ability to handle probabilistic (lexical) information, may at first glance appear to be rather difficult to emulate in an OT model with strict domination. Information encoding for instance how frequently a verb is used with a specific argument structure, or how frequent a given syntactic structure is in a listeners’ linguistic environment may seem hard to capture in the general constraints that figure in OT. As we have seen above, it may not always be clear exactly which probability one needs to use, but one way to handle probabilistic information in an OT framework is to use a constraint that can ‘look up’ the necessary frequency information from the lexicon, as suggested by Singh (2002). In Singh’s proposal, alternative argument-structures (or subcategorizations, alternative meanings, word categories, etc.) for an ambiguous input are represented as a list of possible structures, ordered by frequency. The OT constraint PROBABILITY ACCESS then accesses the position of a given structure in the ordered list, and assigns violations to structures that are not on first position. Thus, probabilistic information can be used in OT decision making. Nevertheless, it may be a more sensible strategy to look for the cause of frequency biases, rather than just model them as they appear in a corpus or completion study. For example, Stevenson and Merlo (1997) propose that differences in frequency of usage are most likely caused by differences in thematic and syntactic aspects of the lexical items in question. In the same vein, Argaman and Pearlmutter (2002) strongly argue that the cause for frequency differences must be found at the level of lexical semantic primitives. This should make it possible to model the use of information that appears as probabilistic, but is, in fact, syntactic or semantic in nature.
OT thus has a number of important advantages with regard to standard constraint-based models. Some of these advantages also apply when comparing OT to another class of models that is relevant here. We will call these the ‘Bayesian’ models, after their proposed mode of combining probabilistic evidence (Jurafsky, 1996; Narayanan & Jurafsky, 2004; see Brouwer, Fitz, & Hoeks, 2010; Crocker & Brants, 2000, for a different implementation of combining probabilistic evidence). In Bayesian models, lexical entries, but also syntactic rules are represented as mental objects which may have different a priori probabilities or ‘resting activations’. During sentence comprehension, these lexical and structural entries are retrieved from memory, and crucially, all structures that are compatible with the input are constructed by the processor. In other words, at any given time many different alternative syntactic structures can be active in parallel, which are activated, or ranked, in accordance to their probability. There is, however, a limit to how improbable a syntactic alternative is allowed to be: if structures are very improbable relative to the other structures, they are pruned away. This can have the consequence that, at a given point in the sentence, the pruned syntactic structure turns out to be the correct structure after all. In that case, the reader is gardenpathed, because that structure is no longer available, and reanalysis must follow.
This kind of model does have an explicit syntactic theory, but most of the other criticisms that were leveled at the standard constraint-based models apply to the Bayesian models as well: 1) it is hard to make predictions for Bayesian models, for one thing because of the considerable difficulty of getting the right probability data from a corpus; 2) a Bayesian model can never account for the fact that language users can understand ungrammatical sentences, as these specific syntactic structures do not exist in the grammar that is generally used. It is certainly possible to use robust parsers that can cope with ungrammatical input, but it is not completely clear how the resulting structural representations can be used for further semantic interpretation in a straightforward way; 3) they make the wrong prediction about the processing of globally ambiguous sentences. Bayesian models assume parallel activation of syntactic alternatives. Thus, they predict that (10a-c) would be equally easy to process, as high attachment and low attachment analyses are equally probable and thus neither is pruned away. At the arrival of the disambiguating information (e.g., ‘retiring’), then, one of the alternatives will be discarded, leaving the other one to be chosen without causing any difficulty. As a final remark, it is hard to see how this kind of model can be extended to include factors such as semantic plausibility or discourse context that are very important for the comprehension of language.
A final class of models we will discuss here are the so-called ‘syntaxfirst’ models. In these models it is assumed that processing is not a one-stage parallel phenomenon, but falls into two distinct stages of processing: a first stage in which syntactic structure is built, and a second stage in which syntactic and non-syntactic information are used to construct the interpretation of an utterance (e.g., Frazier, 1987b; Frazier & Clifton, 1996; 1997; Frazier & Rayner, 1982). Though these models are called syntax-first, there is often no explicitly described and testable syntax module. In addition, making predictions for syntax-first models may seem straightforward, but predictions may vary if different grammar formalisms are used (see Crocker, 1992, for discussion). But what is more, syntax-first models are at best only partial models of sentence processing as they do not describe how information from the non-syntactic realm is used in constructing an
5. Proposed OT Model: Issues of Implementation
In Section 2 we provided a sketch of the OT architecture that underlies our model. In this section we will discuss this architecture and its associated mechanisms in some more detail. One important issue in this context is the stipulated ‘freedom of analysis’ for GEN, leading to an infinite number of candidates that can have all kinds of structure. Is this psychologically plausible? And what is more, can it be implemented?
OT is in essence a hybrid cognitive architecture, combining rule-governed symbolic processing with parallel subsymbolic processing. It is rooted in connectionism, or neural network modeling, where computations are performed by a network of artificial neurons modeled after the human brain (Prince & Smolensky, 1993/2004, 1997). A neural network consists of artificial neurons, or units, and multiple connections between these units. The input to a network consists of a fixed pattern of activation. Activation then flows through the network to construct an output pattern of activation. The neural network thus maps a specific input pattern to a specific output pattern. Crucial for this mapping are the concepts of
These ideas found their way into linguistics when it was realized that the concept of harmony maximization in neural network modeling could be applied to theories of grammar. The result was a theory called Harmonic Grammar (cf. Legendre, Miyata, & Smolensky, 1990a, 1990b), at the heart of which lies the view that a grammar is a set of violable and potentially conflicting constraints that apply to combinations of linguistic elements. A grammatical structure is then one that optimally satisfies the total set of constraints defined by the grammar. In Harmonic Grammar, as in artificial neural networks, constraints are weighted. Through a process of summation, the overall effect of the total set of constraints can be determined. OT can be seen as a kind of ‘restricted’ Harmonic Grammar, where the weight of constraints is not formalized by numerical strengths anymore, but solely by a strict priority ranking. But the mechanism by which OT and Harmonic Grammar arrive at an outcome is essentially the same. In fact, it is possible to implement OT in an Harmonic Grammar framework by choosing a specific set of numerical weights (Smolensky & Legendre, 2006).
5.2 The Infinite Candidates of OT
A crucial feature of OT is the stipulation that the candidate set generated by the function GEN is infinite in size. To understand what this means, it is important to make a difference between 1) the
Nevertheless, it is possible that our OT model (and OT in general)
But what about the notion of the infinite candidate set, which seems to be psychologically and biologically impossible? Doesn’t it make OT less similar to the actual cognitive processes? The reason that we tend to say “no” to this question, is that at the level of neural computation of the formal model, the number of output candidates is only
There are a number of computer implementations of OT that are relevant for the present discussion, most of which can be found in the field of OT phonology, modeling how the optimal surface form is chosen for a given underlying form (Tesar, 1994, 1995, 1996; Ellison, 1994; Frank & Satta, 1998). Some of these OT models are implemented in an explicit generateand-test fashion, so without a neural network layer, and may suffer from the ‘decidability problem’, as argued by Kuhn (2002). This problem refers to the impossibility of deciding whether a given string is part of the language generated by the grammar, and is due to the (near to) infinite number of candidates that must actually be generated in this kind of computer implementation. The decidability problem can be solved, for practical purposes, by introducing extra conditions on how the constraints are evaluated (see Kuhn, 2002, for details). According to Kuhn, the decidability problem does not arise when optimizing from a given form to its optimal meaning, as in our present proposal, or in bidirectional optimization (Kuhn, 2001, Ch. 6).
In a different vein, the problems that ‘infinite candidates’ pose for computational models has been circumvented by Misker and Anderson (2003), who implemented OT in ACT-R, a hybrid connectionist/symbolic production-system-based architecture. They modeled the GEN function as finding analogies between the current input and previous inputs, determining the transformation that alters the analog input into its output, and then applying this transformation to the current input, in order to obtain a new output. The candidate set is never represented entirely, only the best candidate so far is stored. A competing candidate is generated and compared with the current best. Under this approach, only two candidates are active at any given time.
In our current proposal we have described a formal algorithm for constraint evaluation at the symbolic level, though we have only given a rather shallow description of the subsymbolic layer. We cannot at present offer a computer implementation of either layer; instead, we present a manual simulation in which we have singled out the most likely candidates for interpretation ‘by hand’, and where the optimal interpretation was chosen by applying the proposed constraints, also by hand. Although our model is incomplete and unimplemented, it is clear that it gives us great predictive power regarding garden paths and parsing preferences. In fact, the option of a ‘manual’ simulation mode makes it possible for other researchers to derive predictions for our OT model, without having to run a computerized simulation. Having no computer implementation of the subsymbolic level leaves us unable to explain more dynamic and graded phenomena in language processing, such as, for instance, word priming, sentence priming, or predicting the actual amount of processing difficulty for each construction. We can only make predictions on the symbolic level, which abstracts away from the actual sub-symbolic processing going on at each word. Exactly which properties should be explained at which level is partly a matter of debate. For instance, it might be preferable to model all temporary and dynamic aspects of language processing at the subsymbolic level, thus restricting the symbolic level to general and permanent forms of knowledge, whereas the subsymbolic level can be taken to represent all knowledge (temporary and permanent) at the same time. More research in this area is definitely needed.
In this paper we propose a model of human sentence processing according to which constraints from the grammar need not be augmented with separate processing restrictions, but rather are processing restrictions themselves. As a result, no distinction needs to be postulated between a competence model (grammar) and a performance model (human parser). This effect is achieved by using Optimality Theory as the competence and performance model. We illustrated the workings of this OT model of human sentence processing by investigating the phenomenon of coordination. Psycholinguistic evidence strongly suggests that the online comprehension of coordinate structures is influenced by constraints from many different information sources: pragmatics, discourse semantics, syntax, and lexical semantics. Adopting the framework of OT allows us to formalize this crossmodular constraint interaction. As we have shown, using the OT framework has many advantages: 1) linguistic competence and performance can be described within one model; 2) as a processing model, it accounts for processing phenomena associated with coordinated structures; 3) it also allows for the interpretation of ungrammatical utterances; and finally 4) it provides very clear and testable predictions. Thus, even though the model that is presented here represents only a first step, it could be a step towards a complete theory of language performance and competence.