Most linguists (ourselves included) claim that linguistics finds its
It is our intention to address these questions in this paper by focusing on a particular issue pertaining to the nature of the lexicon and of linguistic variation.
The histories of modern linguistics and modern cognitive science are intimately intertwined, ever since the Chomskyan attack on behaviorism in the 1950s. Much like we believe the ultimate goal of cognitive science to be the development of biologically plausible accounts of human cognition (“cognitive biology”), linguists repeatedly claim that the ultimate goal of the language sciences is to uncover the biological foundations of the language faculty (“biolinguistics”). But it is fair to say that the connection between linguistics and the various disciplines that make up biology has so far remained, for the most part, fairly abstract (and, for the most part, rhetorical). Recently, though, there are signs that things are changing for the better. At least some linguists are beginning to take active steps towards engaging with adjacent disciplines and ensuring a more fruitful integration with biology (for a review of this recent trend that began with Hauser, Chomsky, and Fitch 2002, see Boeckx 2013a). We would like to provide a concrete illustration of this recent turn in the pages that follow, and in so doing contribute to this trend. We will do so in several steps. First, we will sketch a general framework through which we think genuine interdisciplinary can be achieved. Next we will argue that adopting this framework not only enhances interdisciplinarity, it also favors a certain rapprochement between research traditions within linguistics that many still view as antagonistic and incompatible. In other words, our claim will be that
2. An interdisciplinary framework
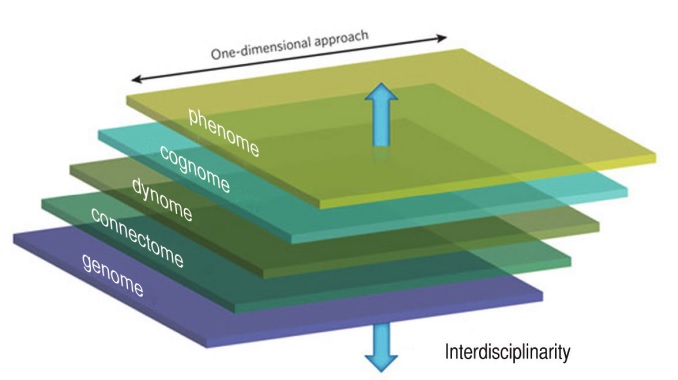
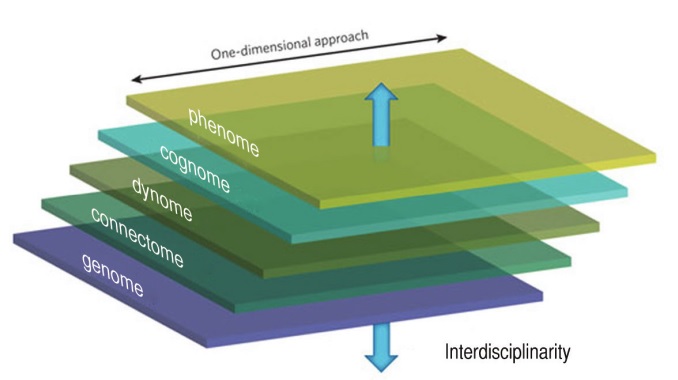
Traditionally speaking, linguists working under the banner of “biolinguistics” have approached language in modular terms, studying it separately from other cognitive domains. This one-dimensional approach has undoubtedly led to significant progress within linguistics, but it is equally unquestionable that this approach has had the collateral effect of isolating linguistic research from the rest of cognitive science, to the point that the field of linguistics now occupies a fairly marginal place in the context of cognitive studies.
Such a modular or one-dimensional approach is to be contrasted with the modus operandi advocated by Marr (1982), who encouraged working on cognitive issues across several dimensions or levels (for Marr, these were the computational, algorithmic, and implementational levels). In this section, we would like to advocate an approach that is very much in line of Marr’s vision.
It’s long been clear to biologists, and (we hope) it is clear to cognitive scientists as well, that there is no direct way from the genotype to the phenotype. As Marcus (2004) put it, genes code for proteins, not for cognition. To relate the genotype to the phenotype, several intermediate steps will have to be taken, in the form of linking hypotheses. Work at the genome level will have to be related (via the proteome and the transcriptome) to what is now known as the connectome (Sporns et al. 2005), the set of all neural connections within an organism’s nervous system. In turn, the connectome will have to be related to the “dynome” (Kopell et al. 2014), linking brain connectivity with brain dynamics, specifically brain oscillations. In turn, the dynome will have to be connected to the “cognome” (Poeppel 2012), understood as the comprehensive list of elementary mental representations and operations. Finally, the cognome will have to be related to the phenotypic level (phenome). This last step will show how elementary mental representations and operations are able to provide the basis for the richness and diversity that has captured the attention of so many students of language and cognition until now.
As this last sentence makes clear, work in linguistics has mainly taken place at the level of the phenome, or at the border between the phenome and the cognome. As a matter of fact, linguists would claim that most of the work in the discipline has taken place at the cognome level, with attention being placed on deducing a variety of linguistic phenomena to a narrow set of ‘primitive’ properties. We would like to take issue with this claim. Although we recognize the effort of linguists to formulate compact and elegant theories, we believe that (rare exceptions aside) little attention has been devoted to examining the bio-cognitive plausibility of the resulting theoretical primitives. Indeed most primitives or atomic units formulated by linguists have a modular,
We think that this has the (so far) under-appreciated consequence of bringing into contact two linguistic traditions, one (“Chomskyan”) seeking to reduce linguistic complexity to a set of elementary primitives, and the other (“Cognitive”) seeking to account for linguistic processes in terms of general ‘cognitive’ mechanisms. The challenge ahead is to marry these two traditions, showing that elementary primitives used by Chomskyan linguists to explain various linguistic phenomena can be understood in terms of generic processes that in turn can be translated into what we know about how the brain works (dynome, connectome, and ultimately genome).
We think that this ‘translational’ research program at the heart of Figure 1 is the way to proceed for cognitive biology. Although in practice cognitive studies cannot be expected to work at all levels at once, we would like to stress the need to bear all these levels in mind when formulating specific hypotheses at a given level, to avoid re-establishing disciplinary boundaries that only serve to delay progress.
We also would like to take this opportunity to emphasize the fact that linguistic, or more generally cognitive studies, should take the brain as their focus, for this is the real nexus in Figure 1. For too long linguists have disregarded what we know about the brain, claiming that we still know so little about it that it is pointless to try to relate mind and brain now. We think this view must be retired. We readily concede that not everything is known about the brain, but we think that enough is known to guide us in our formulation of the cognome. Specifically, it is fairly well-established that information processing at the brain level is achieved by a meaningful interaction of oscillations at various frequencies generating by populations of neurons (Buzsaki 2006). We therefore urge linguists to frame their discussion in light of this working hypothesis about brain rhythms and offer concrete proposals at the cognome level that can be translated in rhythmic terms. Short of that, the slash between mind and brain (“mind/brain”) is there to remain.
As an example of this shift of perspective from domain-specific atomic units to neurally more plausible generic primitives, we’d like to focus on the nature and structure of the lexicon (for another example, see Appendix). In generative studies of the past 25 years or so, this issue has been intimately related to the nature and structure of what is known as the parametric space (Chomsky 1981), taken to be the set of options the child must choose from to converge on the language of the environment. Our question in this section is how to understand this “parametrome”. Traditionally, this parametric space has been defined in terms of “parameters”. These are conceived of as the atoms of linguistic variation. They are domain-specific, and informationally encapsulated, as expected from the orthodox modular stance in linguistics. As far their biological nature is concerned, they are claimed to be “part of the child’s genetic makeup”, never mind the fact that genes don’t code for parameters. When pressed, linguists such as David Lightfoot point to a certain parallelism with the visual system, as in the following passage:
The problem we have with this perspective is that grammatical options (such as Verb first or Verb last) cannot be seriously taken to be on par with visual orientation cues. The latter have had millions of years, and very good adaptationist reasons, to be coded for, biologically speaking. Options like left/right, vertical/horizontal are plausibly primitive, in a way that “subject”, “object”, “verb”, etc. aren’t. It is somewhat foolish to believe that these two sets of options are coded for in the same way, and that the innateness of one can justify the innate status of the other. This seems to us to be the strongest argument against taking parameters to be primitives. (For a detailed list of reasons why ‘parametric options’ cannot reasonably be taken to be part of our “genetic make-up”, we refer the interested reader to Longa and Lorenzo, 2008, 2012, and Lorenzo & Longa, 2009.)
To drive the point home, let us stress also that unlike visual orientation cues that provide the basics for low-level visual perception, parameters are typically conceived of at a much higher level of ‘abstraction’ (in the sense of remoteness from biological substrate). In this sense, our take differs sharply from Chomsky’s recent appeal to “three factors” in language design. Whereas Chomsky continues to insist on the role of a first factor (genetic endowment) that he sees as domain specific, we want to emphasize that for us genes cannot be so construed.
What must be done is find a level of description at the cognome layer of which one can then ask how biology codes for it. As we will now show, this level necessarily implies the abandonment of atomic units like parameters, and favors implementational solutions that are much closer in spirit to the theoretical vocabulary employed by cognitive linguists, as well as representational options that are plausibly shared across species.
A first step in this direction was taken by linguists like Yang (2002 et seq.), who sought to combine the setting of parametric options with the gradual consolidation of rules on the basis of statistical learning in light of the revival of Bayesian learning studies (Saffran et al. 1996). An equally important step was taken by cognitive scientists like Mehler’s team (Endress et al., 2009; Gervain & Mehler, 2010), who relied on attested and cognitively ancient perceptual and memory constraints to structure the data input (‘data intake’). This type of work led to the formulation of an explicit learning algorithm constructing the lexicon in Boeckx and Leivada 2014. This algorithm has the advantage of relying on mechanisms and initial representations that are plausibly shared across cognitive domains. The algorithm rests on the ability for ‘reasoning under uncertainty’ at the heart of Bayesian learning. A central aspect of this reasoning is the ability to entertain overhypotheses and constraints on hypotheses at the same time, that is to work at both levels at the same time: while trying to generalize (overhypotheses), paying attention to singularities (exceptions) (Kemp et al. 2007). In other words, tracking down both types and tokens.
In this context, the efficient learner should be able to integrate in the process of acquisition some conflicting tendencies, such as the need to formulate generalizations over input, without however generalizing so much as to require subsequent backtracking in light of numerous exceptions. More specifically, the efficient learner internalizes linguistic knowledge by making use of biases that simultaneously allow for both overgeneralizing hypotheses (e.g., Boeckx’s 2011 Superset Bias), leading to the formulation of ever more general types, but also for adequately constraining overgeneralizations. This is fully in line with Briscoe & Feldman’s (2011) Bias/Variance Trade-off, according to which learners adopt an intermediate point on the bias/variance continuum in order to refrain from over-fitting, backtracking and reanalyzing data.
Another property of the efficient learner is the ability to pay attention to statistical distributions. Many studies point out that humans are powerful statistical learners (e.g., Saffran et al., 1996). Yang (2005) suggests that productivity of hypothesized rules is subject to the Tolerance Principle, which seeks to define how many exceptions to a hypothesized rule can be tolerated without the learner deciding to abandon the rule as unproductive. One of the more recent formal representations of the Tolerance Principle holds that Rule R is productive if T(ime)(N,M) < T(N,N), with (N-M) being the rule-following items and M the exceptions (Yang, 2005; Legate & Yang, 2012). If T(N,N) < T(N,M), then R is not productive and all items are listed as exceptions (M=N, all items are stored as exceptions). This principle accurately predicts rule productivity and inference in the course of acquisition in terms of overhypotheses formulated by the learner.
The upshot of this discussion is that frequency and the type/token distinction refined over the learning processes starting with generic categories are at the heart of the construction of the lexicon, a claim that is much more congenial to work in cognitive linguistics than to work in the Chomskyan tradition. The key point is that the primitive representation one starts with progressively gets refined and entrenched (in pretty much the sense of Langacker 1999) as a result of usage (see Bybee 2010). Rather than seeing the acquisition of the lexicon as the setting of pre-specified parametric options, the lexicon is constructed. The grammar progressively grammaticalizes, and is not fixed ab initio.
The representations produced by the algorithm have a lot in common with Inheritance hierarchies found in many studies in Construction Grammar. Such Inheritance hierarchies offer concise representations of how specific languages (final states of the language faculty) organize themselves in various families of increasingly abstract constructions (see Goldberg and Jackendoff 2004; also Jackendoff 2010). The grammar/lexicon divide dissolves in our perspective in much the same way it does for work in the cognitive tradition.
But the algorithm proposed by Boeckx and Leivada 2014 cannot be taken to be fully adequate until it can be translated into brain terms, in accordance with the research program sketched in the previous section. This is what we will focus on in the rest of this section.
As we pointed out above in the context of Lightfoot’s quote, the classical parametric model offers no plausible brain mechanism for the formation of the lexicon. Instead, an algorithm that relies on frequency tracking can already draw on the literature identifying the neural basis of statistical learning. This literature (see Karuza et al. 2013, Schapiro et al. 2014) highlights the role of usual suspects such as Broca’s area and the temporal lobe, but crucially also implicates subcortical structures such as the basal ganglia and the hippocampus. We would like to point out, however, that we think that it would be a mistake to reduce these findings to the now well-established procedural vs. declarative memory system (Ullman 2004). Although we believe this distinction to be useful, it is often taken as a way to cash out at the brain level the lexicon/grammar divide (Ullman et al. 1997). Since we are skeptical of this distinction, we want to caution against multiplying memory systems.
To this literature on the neural basis of statistical learning, which tends to be focused on linguistic issues and give the impression of identifying neural structures dedicated to specific cognitive domains, we would like to draw attention to recent work on how the brain makes categorical decisions about ambiguous stimuli — that is, how it learns categories. Work by Miller and colleagues (Roy et al. 2014, Antzoulatos and Miller 2014, Buschman and Miller 2014) has highlighted the importance of the functional connectivity between the prefrontal cortex and the striatum in this task. This work shows two systems working in concert. A basal ganglia-centred system that quickly learns simple, fixed goal-directed behaviors (think of these as “tokens”), and a prefrontal cortex-centred system that gradually learns more complex, more abstract goal-directed behaviors (think of them as types or over hypotheses). As Miller and colleagues show, interactions between these two systems, mediated by the thalamus, allow top-down control mechanisms to learn how to direct behavior towards a goal but also how to guide behavior when faced with a novel situation. This interaction takes the form of a combination of neural oscillations at various frequencies, especially gamma, beta, alpha, and theta. These form the neural ‘language’ of what we referred to earlier as the bias/variance trade-off, entrenchment, and ultimately grammaticalization (at the level of ontogeny).
Buschman and Miller observe that because interactions between the basal ganglia and the pre-frontal cortex work in both directions, this functional connectivity provides a powerful computational mechanism that allows for new experiences to be compared to expectations from previous ones, and in so doing find the optimal balance between (general) “rules” and “exceptions”.
As Buschman and Miller 2014 point out, this dual architecture—”fastlearning in more primitive, non- cortical structures training the slower, more advanced, cortex”—may be a general brain strategy, and in our view complements the procedural/declarative duality that is better known to cognitive scientists. If we are correct about the basal ganglia-pre-frontal cortex recurrent network to constitute the backbone of the lexicon, our line of argument leads us to anticipate neuroimaging findings where the acquisition of the lexicon is shown to implicate both cortical and subcortical structures, in particular the basal ganglia and the thalamus, and is thus fully in line with the reports in Mestres-Missé et al. 2008 and Ripollés et al. 2014.
Being a general strategy the dual architecture advocated here has the advantage of meeting Poeppel’s genericity desideratum. Our point here is that this genericity must be matched at the cognome level as well. It is for this reason that lexical atomic units like parameters have to be abandoned and replaced by a much more dynamic, and ‘constructivist’ system that allows for the lexicon to grow. We think that this is the message that the brain findings reported on here are giving us, and we would be wrong not to take this ‘data point’ seriously in our attempt to formulate adequate theories of linguistic knowledge.
Let us conclude this section with a few remarks. First, we wish you dispel an impression that we may have given when describing the role of the basal ganglia in the preceding paragraphs. Readers of Miller’s work on which we draw may be tempted to view the role of the basal ganglia in behavioristic terms (simple stimulus-response learning mechanisms). But we think this would be mistaken. Attention to the basal ganglia in recent years has certainly revived behaviorist concepts such as operant self-learning (Mendoza et al. 2014), but it is important to recognize that even the very fast, token-based learning for which the basal ganglia plays a crucial role is nonetheless quite abstract, and quite distinct from what Skinner would have been willing to endorse.
The second remark we want to make concerns the context in which our appeal to the “goal-directed learning” model of Miller and colleagues is made. Whereas this model captures the basics of the type-token distinction, it is necessary to view it as part of a much broader “learning” brain. A full description of this broader system would take us too far afield here, but we want to highlight some of the key components that interact with the basal ganglia-prefrontal cortex loop system. One such component will be the (multi-sensorial) attention network, especially the dorsal attention network made up of fronto-parietal connections modulated by the higher-order thalamic nuclei (see Boeckx and Benitez-Burraco 2014 references). Another component, crucial to capture the entrenchment of learned items, will be the long-term memory system, primarily consisting of the hippocampus, but also other brain structures such as the precuneus, involved in memory retrieval, as well as the amygdala, known to modulate hippocampal activity. A third component will be the so-called working memory system, which not only involves parts of the pre-frontal cortex but also implicates other cortical (parietal and temporal) and subcortical (basal ganglia, and possibly as well, cerebellum) structures that work in tandem with the attention network, as well as with the long-term memory system. This working memory component provides a buffer space that is not only important in the context of parsing, but also in the context of keeping active the various options from which to choose, and eventually learn.
All these networks must be seen as interacting with the components of goal-directed learning discussed above to generate the proper ‘symphony’ of oscillations through which the brain will focus on, select, and retain lexical items, as it constructs the lexicon. We cannot emphasize enough the need to think of language-related tasks as ‘whole-brain’ affairs. Even if the modular organization of the mind and the brain still dominates, it is crucial to view complex tasks, such as constructing the lexicon, as operations that recruit numerous networks, none of which domain-specific, to arrive at mature domain-specific representations. Such representations, we believe, lie at the intersection of embedded oscillations, generated by dynamically forming neural networks. At the level of the connectome, it is clear that structures like the thalamus are likely to play an important role in coordinating these multiple networks, and in future work we hope to return to this issue in the context of the dynome, and show how the thalamus may tune in all these interacting oscillation ensembles (for initial steps in this direction, see Boeckx and Theofanopoulou to appear).
The third remark pertains to the vexed issue of ‘innateness’. As a reviewer points out, readers may well wonder whether our claim that “the grammar progressively grammaticalizes, and is not fixed ab initio” casts doubt on the idea that ‘language is innate’. We think it does, and this is why we believe it is important to distinguish between a ‘language-ready brain’ (the set of innate abilities, none language-specific, allowing for the acquisition of linguistic systems) and a mental grammar. The latter certainly relies on innate abilities, but its content is the result of growth and interaction with the environment. In this context it is worth pointing out that our ‘constructivist’ approach stands to benefit from a closer examination of neurodevelopmental data as well as data from developmental cognitive disorders to strengthen our claim that the lexicon is not ‘pre-formed’. As we discuss in related work (Boeckx and Theofanopoulou to appear)), our model leads us to expect cognitive disorders to translate in terms of deviant brain rhythms (‘oscillopathies’).
The fourth remark touches on another issue raised by a reviewer. It concerns the status of work trying to deconstruct semantic processing in terms of brain activity (e.g. Event Related Potentials) in the context of the framework we have sketched here. What are we to make of indices like the well-known N400 signal, routinely related to the processing of semantic information (N400)? Concerning this issue, we share the position advocated in Lau, Phillips and Poeppel 2008. After reviewing the literature on the N400 signal, these authors conclude that “at least some substantial part of the N400 effect reflects facilitated lexical access”, but they are quick to point out that this result, as interesting as it is, can only be taken as a starting point. It requires a deeper “understanding of the neuronal architecture” generating the signal, and (fully in line with the approach advocated here), it requires a deeper characterization of notions like “semantic integration” that the N400 signal indexes. In the words of Lau et al., “the notion of integration requires specification both at the level of cognitive models and at the level of neuronal mechanisms.” We could not agree more with them concerning the fact that theoretical notions like “semantic integration” “cover multiple sub-mechanisms”: [in this specific case] “encoding compositional structure, generating expectations, linking input with world knowledge, and controlling communication between different information sources.” Our approach deems it necessary to offer specific technical implementation of these mechanisms in terms of the dynamics of neuronal populations.
The fifth remark we would like to make concerns the shift of perspective that we have called for and that is captured Figure 1. What this shift is intended to do is change not so much the landscape of questions, the “puzzle” if you wish, that linguists should be interested in; the big questions that Chomsky 1986 listed, such as Plato’s problem, are there to stay. Rather it changes the nature of the pieces with which to solve the puzzle. It asks linguists to use pieces that can be made to fit with pieces other scientists working at other levels have discovered. For future students of the language sciences, we hope that this way of approaching the linguistic puzzle will lead them to more realistic representations of the biological nature of linguistic knowledge.