Research in the language comprehension literature has demonstrated that people use a variety of information sources in the moment-by-moment comprehension of sentences, including lexical information, syntactic structure, the lausibility of the described events, the discourse context, and – for auditory input – prosody (Tanenhaus & Trueswell, 1995; Gibson & Pearlmutter, 1998). An important architectural question in this literature is whether all or only some of these information sources can
Research from the lexical access literature has established that lexical processing proceeds independent of the existing
In the reading paradigm, when the context is neutral with regard to the different meanings of an equi-biased sense-ambiguous word, it takes comprehenders longer to process the word, compared to a biased ambiguous word or an unambiguous control word (Duffy, Morris & Rayner, 1988; Rayner, Pacht & Duffy, 1994; Binder & Rayner, 1998; Binder, 2003). This has been explained in terms of competition between the two equally available meanings of the balanced word (e.g., Duffy et al., 1988). Furthermore, when the context is consistent with the subordinate meaning of a biased sense-ambiguous word, it takes comprehenders longer to process the biased ambiguous word, compared to unambiguous controls. This phenomenon has been termed the subordinate bias effect (Rayner et al., 1994), and has been argued to reflect competition between the two meanings of the word, where the dominant meaning is highly available due to its frequency, and the subordinate meaning is made available by the contextual information. These results dovetail nicely with the evidence from the semantic priming paradigm: both sets of results suggest that lexical frequency and semantic context are two independent sources of information that the processor uses in comprehending words in a sentence.
There has been less research investigating lexical access in different
There is little evidence from the literature manipulating lexical frequencies of the different meanings of category-ambiguous words and syntactic context using a reading method. In an early paper investigating these constraints in reading, Frazier & Rayner (1987) examined noun-verb ambiguous words like
Recently, more direct tests of whether syntactic and lexical constraints are independent have been conducted using a reading method. In one set of eye-tracking studies, Boland & Blodgett (2001) manipulated the syntactic context to be biased to expect either a noun (e.g.,
In another set of eye-tracking reading studies, Folk & Morris (2003) failed to find a subordinate bias effect for verb-biased noun-verb ambiguous words in noun contexts in early eye-tracking measures (although they did find such an effect in second pass times). As in the case of Boland & Blodgett’s studies, however, there were issues with Folk & Morris’s experiments that make interpretation of their results difficult. In particular, in their first experiment, Folk & Morris used rich syntactic and semantic contexts (e.g.,
More recently, a subordinate bias effect has been observed with respect to a category-ambiguous word: the word
Both research groups found that the region consisting of
Finally, a recent event-related potentials (ERP) study on category-ambiguous words provides further evidence for the independence of lexical and syntactic constraints. In particular, Thierry et al. (2008) investigated a phenomenon where a word is used in a syntactic context that is inconsistent with the word’s dominant category meaning. Such conversion of one part of speech into another (what the authors call “functional shift”) is a common literary device. Thierry et al. focused on materials from Shakespeare’s writings where this device is used extensively. For example, one item from Thierry et al.’s study was
To summarize the results from the literature reported above: (1) multiple meanings are activated during lexical access under most circumstances (except for accessing the low-frequency meaning of a word that appears in a context that supports its high-frequency meaning), (2) biased ambiguous words can cause processing difficulty when the context supports the lowfrequency interpretation, resulting in a subordinate bias effect, (3) with respect to syntactic category mbiguities, the subordinate bias effect has been observed for the category-ambiguous word
To address this gap in the literature, the current studies seek to examine the interaction of lexical frequency and syntactic context in sentence processing using a productive syntactic category ambiguity: the noun-verb ambiguity in English. These studies are thus similar to those of Boland & Blodgett and Folk & Morris, but with more items, more sophisticated analyses, and materials presented in minimal syntactic contexts without any preceding semantic / discourse context, in order to narrow in on the interaction of only lexical frequency and syntactic context. If lexical information guides interpretation independent of syntax, then we should observe a subordinate bias effect, much like that observed by Tabor et al. (1997) and Gibson (2006) with respect to the complementizer / determiner ambiguity of
To select a set of materials for our experiments, we initially conducted a study using meta-linguistic judgments (Norming Study 1). Subsequently, we used the materials selected based on the results of Norming Study 1 in an elicited production study (Norming Study 2) and in a corpus study. As will be discussed below, the results from all three studies were highly correlated (rs >.75), suggesting that the lexical biases in the materials used in Experiments 1 and 2 are reliable. We will now describe the methods and the results of the two norming studies and of the corpus study. We will then go on to describe the two experiments.
1Boland & Blodgett also varied the discourse context prior to the critical sentence, so that it was biased toward the noun or the verb reading. We focus on the conditions where the discourse context was consistent with the syntactic context, because the data patterns with regard to the relationship between lexical bias and syntactic context are easiest to interpret in these conditions. 2Tabor et al. discuss the processing slowdown in examples like (1a) in terms of context-dependent lexical access (similar to proposals by Swinney & Hakes, 1976; Cairns & Hsu, 1980; Carpenter & Daneman, 1981; Simpson, 1981), but other results from the literature on lexical access in context make this interpretation unlikely (Duffy et al., 1988; Rayner et al. 1994, among others). Furthermore, Gibson (2006) provides direct evidence against the context-dependent lexical access interpretation of this particular ambiguity.
Four independent raters were presented with a list of 240 noun-verb ambiguous items (generated by two of the authors, Fedorenko and Gibson). Each rater was asked to provide a judgment for each word with regard to whether the word is more likely to be a noun, a verb, or equally likely to be both.3
The goal of the study was to select three subsets of words which would be noun-biased, verb-biased and equi-biased.
For each word, the number of noun-biased, verb-biased and equi-biased responses was counted. The following criteria were applied to select the three subsets of words. A word was considered noun-biased if it had 3 or 4 noun-biased responses and 0 verb-biased responses. Similarly, a word was considered verb-biased if it had 3 or 4 verb-biased responses and 0 nounbiased responses. A word was considered equi-biased if it had no more than 2 noun-biased responses and no more than 2 verb-biased responses. Based on these criteria, 60 words were selected for each bias group for a total of 180 items.
3In the current studies we focus on the syntactic category ambiguity of the nounverb ambiguous words and do not take into consideration (a) the degree of semantic relatedness between the noun and the verb readings, or (b) the within-category sense ambiguities for the noun and/or the verb reading. Both of these factors may play a role in the relationship between syntax and lexical information. We decided to ignore differences among noun-verb ambiguous words along these dimensions for two reasons. First, we wanted to use a large set of items (an advantage over previous studies), and having additional constraints on the materials would have decreased the potential set of noun-verb ambiguous words. And second, many decisions about how related some meanings are to one another (either between the noun and the verb reading, or among the different noun or verb readings) are subjective, with the consequence that estimating frequencies for different senses separately is less straightforward than estimating the frequencies of the noun vs. the verb reading (the latter is straightforward because the contexts in which nouns and verbs are used are almost entirely non-overlapping).
This study used an elicited production task to determine the bias of the ambiguous words. Fifty-six participants from MIT and the surrounding community took part in the study. All were between the ages of 18 and 40, native speakers of English and naive as to the purposes of the study. None had participated in Norming Study 1. All participants were paid for their participation.
The 180 items selected in Norming Study 1 were used in this study. The list was divided in half, such that each participant only saw 90 critical items (30 noun-biased, 30 verb-biased and 30 equi-biased). This was done due to the time-consuming nature of the task (written sentence generation), such that the participants would not have to spend more than one hour on the experiment. 90 category-unambiguous fillers were included in addition to the critical items (these included 30 verbs, 20 prepositions, 20 adjectives and 20 adverbs; no unambiguous nouns were included because we reasoned that there is an a priori bias to treat single words as nouns in this sentence generation task). Four pseudo-random lists were created (two for each of the two halves of the target items) such that no more than two ambiguous words appeared in a row, and then four additional lists were created by reversing the order of these lists. Thus there were eight experimental lists. Seven participants saw each of the lists.
Participants were instructed to create a short (4-7 words long) sentence with each of the words. They were told to write the first thing that came to their mind. They were also told that they could change the form of the words: for example, they could make a noun plural and put a verb in the past or future tense. The study took approximately one hour to complete.
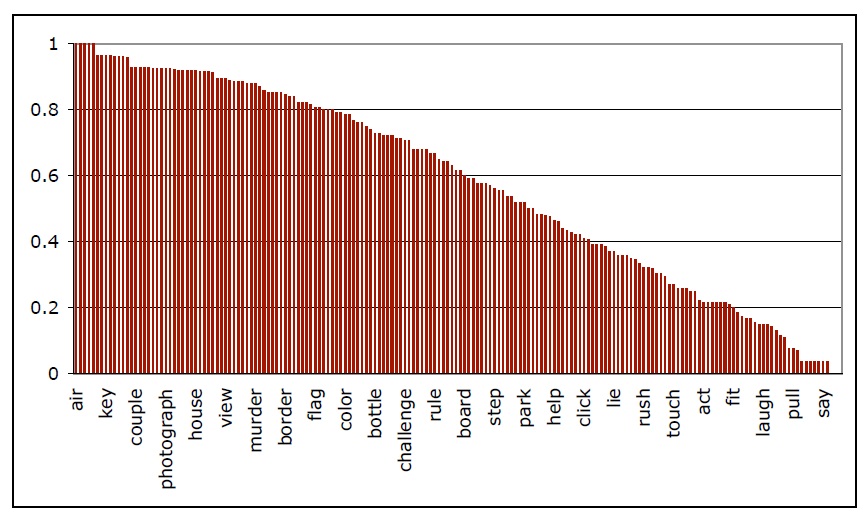
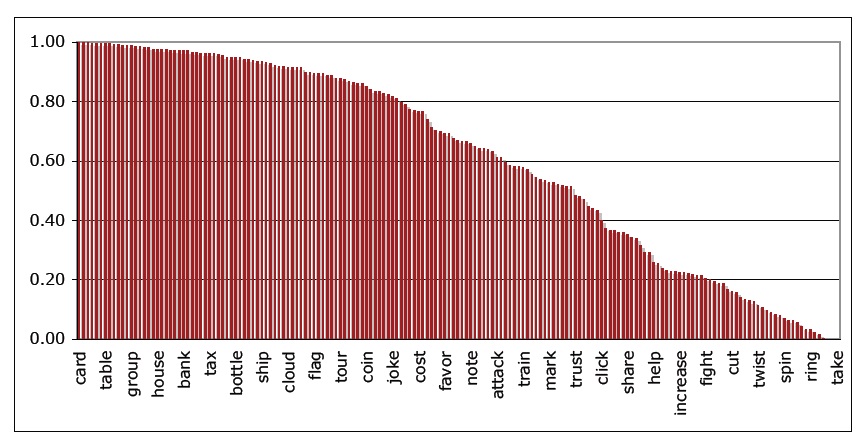
For each word the number of noun and verb uses was counted by handparsing the participants’ responses. 6.8% of the responses could not be coded as a noun or a verb use: either the word remained ambiguous or it was used in a different category (e.g., as an adjective). The analysis of the responses revealed a smooth distribution of the lexical bias across the items, as shown in Figure 1. A correlation analysis between the results of the two norming studies revealed a highly significant correlation (r=.82; F(1,178)=356.3; p<.001).
The CELEX database (Baayen et al., 1995) was used to determine the bias of the ambiguous words. As in Norming Study 2, the items selected in Norming Study 1 were used in this study. Five of the items were not found in the CELEX database, so only 175 items were included. Lemma frequencies (normalized out of 1,000,000) were used. The relative biases were calculated by adding the frequency values for the noun and for the verb readings and then dividing the noun and the verb frequency value by the summed value.
Similar to Norming Study 2, the analysis of the relative biases revealed a smooth distribution across the items, as shown in Figure 2.
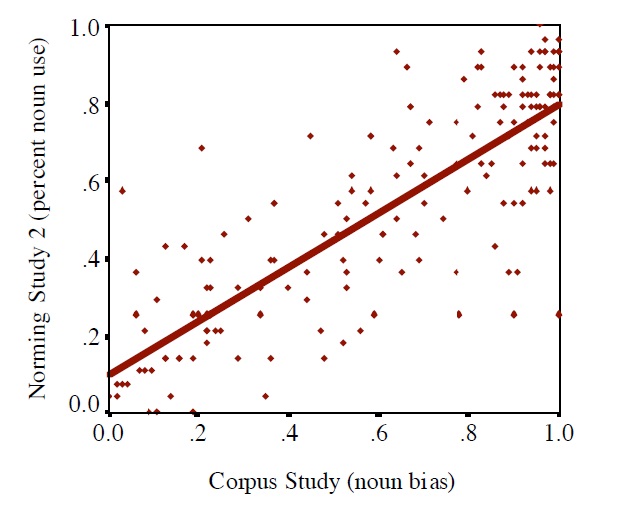
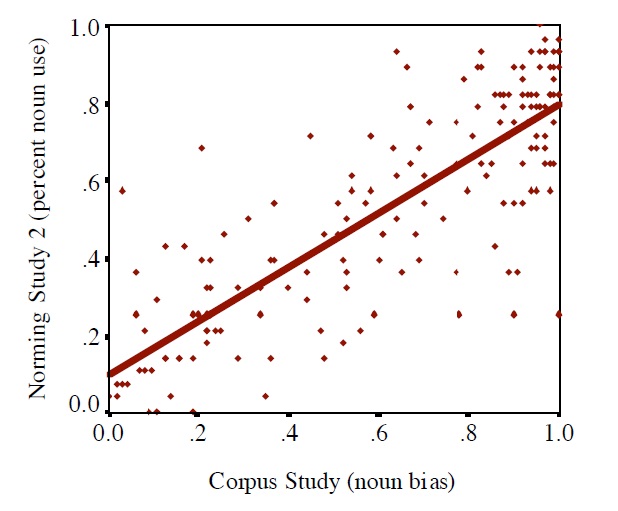
A correlation analysis between the results of the Corpus Study and the two Norming Studies revealed highly significant correlations: Corpus Study and Norming Study 1 (r=.75; F(1,173)=221.7; p<.001); Corpus Study and Norming Study 2 (r=.82; F(1,173)=367.5; p<.001) (Figure 3).
As discussed above, if lexical information guides interpretation independent of syntax, then a word with a dominant noun interpretation should be read slowly in a syntactic context biased to expect a verb (e.g., following the infinitival marker
In both experiments we decided not to use unambiguous controls, matched in frequency to the subordinate reading, and rather to directly compare the processing of category-ambiguous words – ranging in lexical biases (in Experiment 1) or sampled from the ends of the distribution (in Experiment 2) – in different syntactic contexts. The rationale for not including unambiguous controls was two-fold. First, given the lexico-semantic complexity of many noun-verb ambiguous words in English, it is unclear what the unambiguous controls for the subordinate category meaning should be matched to in terms of frequency (and other nuisance variables). In particular, as discussed above, in addition to the category ambiguity between a noun and a verb reading, most words – in our set and more generally – have many different senses for both the noun and the verb reading. As a result, especially in paradigms with minimal syntactic contexts where there is little control over which sense(s) will be retrieved by the comprehender, it is far from obvious what a proper set of unambiguous controls would look like. Consequently, the results may be difficult to interpret.
Second, as discussed in the Introduction, some of the earlier results in the literature strongly suggest that the subordinate bias effect reflects interference from the word’s dominant category reading, rather than the difficulty of accessing a low-frequency (subordinate) reading. In particular, Tabor et al. (1997) and Gibson (2006) observed a subordinate bias effect for the category- ambiguous word
As a result, we focused on including a large set of noun-verb ambiguous words – normed carefully for category biases – in order to seek stronger evidence for a subordinate bias effect in a productive category ambiguity in English (cf. Boland & Blodgett, 2001; Folk & Morris, 2003).
The logic of this experiment relies on the assumption that the lexical decision speed may be affected by the context in which the word appears (e.g., Swinney, 1979; Tanenhaus et al., 1979).
Methods
Participants Sixty-three participants from MIT and the surrounding community took part in the experiment. All were between the ages of 18 and 40, native speakers of English and naïve as to the purposes of the study. Participants were paid for their participation. None participated in either of the Norming Studies.
Design and Materials The experiment had a 3 x 3 factorial design crossing (1) lexical bias (Noun, Verb, Equi), and (2) context (Noun, Verb, Null). As described above, based on the results of Norming Study 1, 180 noun-verb ambiguous items were selected from the original set of 240 items: 60 Nounbiased items (e.g.,
In addition to the 180 experimental materials, 180 pronounceable nonword fillers were included. The fillers were generated using the ARC Nonword Database (Rastle et al., 2002; available at http://www.maccs.mq.edu. au/~nwdb/) and were matched for length in letters with the experimental materials (p=.97).
Procedure The participants were told that they would be presented with a series of letter-strings and they would be asked to decide as quickly as possible whether each letter-string was a real word of English or not. They were told to indicate their decision by pressing one of two buttons. The participants were further told that on some trials the words / letter-strings would appear with a determiner (e.g.,
Results
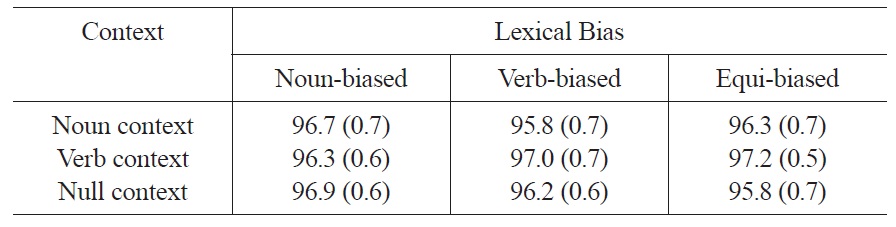
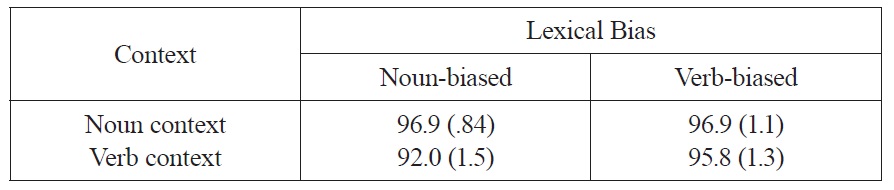
Accuracy data Across the nine conditions, participants answered correctly 96.5% of the time. There were no effects or interactions in the accuracy data (Fs<1.5). Table 1 presents the mean accuracies across the nine conditions of Experiment 1.
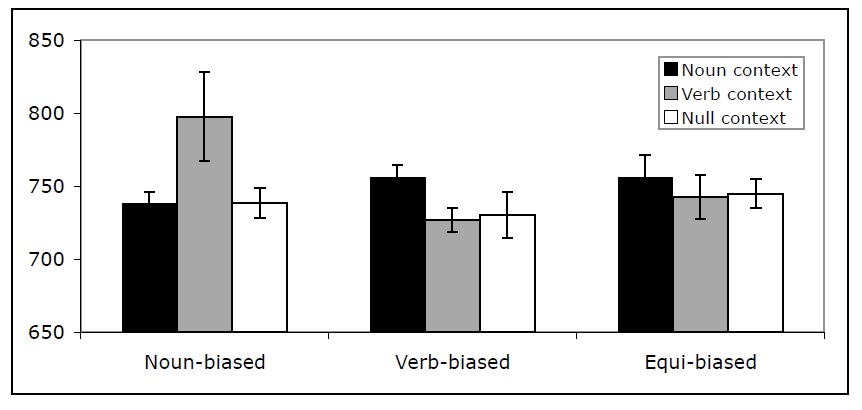
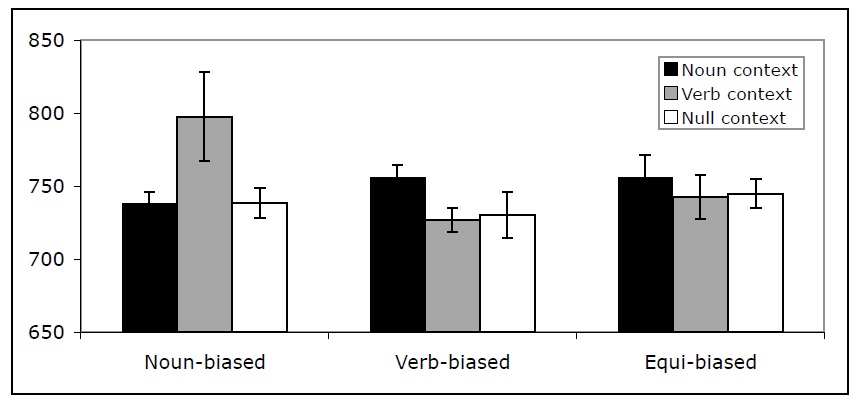
Reaction time data Across the nine conditions, the mean reaction time (RT) was 744 ms. In the analyses presented below we only included the trials on which the word/non-word decision was made correctly. The data patterns were similar in the analyses of all the trials. Reaction time data points that were more than three standard deviations away from the mean RT within a condition were excluded from the analysis, affecting 1.42% of the data. Figure 4 presents the mean RTs across the nine conditions of Experiment 1.
A 3 x 3 ANOVA crossing lexical bias (Noun, Verb, Equi) with context (Noun, Verb, Null) revealed a significant interaction between the two factors (F1(2,248)=5.45; MSe=29720; p < .001). (Note that because lexical bias is a between-items factor, the analysis by items is not meaningful in this design.) This interaction results from the fact that noun-biased items took participants longer to respond to in the verb-context condition (784 ms), compared to the noun-context (735 ms) or the null-context (737 ms) conditions, and verb-biased items took participants longer to respond to in the noun-context condition (755 ms), compared to the verb-context (724 ms) or the null-context (726 ms) conditions. Note that for both noun-biased and verb-biased items the RTs for the null-context conditions were very similar to the RTs for the congruent conditions, suggesting that in the null context participants interpreted the ambiguous word in its more frequent category. An alternative possibility for why no facilitation was observed for the noun-biased items in the noun context relative to the noun-biased items in the null context (or for verb-biased items in the verb context relative to the verb-biased items in the null context) is that in the noun and verb context materials consisted of two words, whereas in the null context they consisted of only a single word. As a result, it is possible that the facilitation that would have been observed due to the match between the dominant reading and the context, compared to cases with no context, was counteracted by the differences in the length of the materials in the noun/verb context compared to the null context conditions.
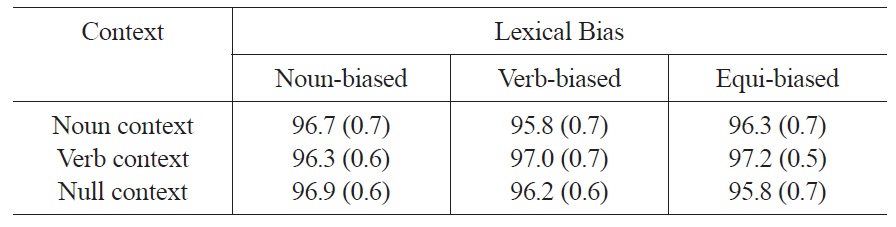
Accuracies in percent correct, as a function of lexical bias and context across the nine conditions of Experiment 1 (standard errors in parentheses).
The analysis also revealed an unpredicted main effect of bias such that across the different contexts, the verb-biased items were processed faster than the equi-biased items and the noun-biased items. This difference may have resulted from a variety of factors that have been shown to affect wordlevel processing but were not controlled across the three bias groups (e.g., overall lexical frequency, length, familiarity, imageability, concreteness, age of acquisition, etc.).
Regression analysis In addition to the analysis of variance, we performed a mixed-effects regression analysis (Gelman & Hill, 2006; Baayen, 2008) on the log reaction times using subjects and items as random effects. Following Boland & Blodgett (2001), we used the difference between the noun-reading log frequency and the verb-reading log frequency values as an independent variable (Log N Freq – Log V Freq), as well as syntactic context. The regression also controlled for word length and log overall frequency.
Only correct responses were analyzed, and data points more than three standard deviations from the mean response time per context condition were removed, accounting for 5% of the data. Analyses were carried out using the R statistical programming language with the packages lme4 (Bates, 2005) and languageR (Baayen, 2008). Significance values were computed using Markov chain Monte Carlo method, and sampling was run for 50,000 steps.
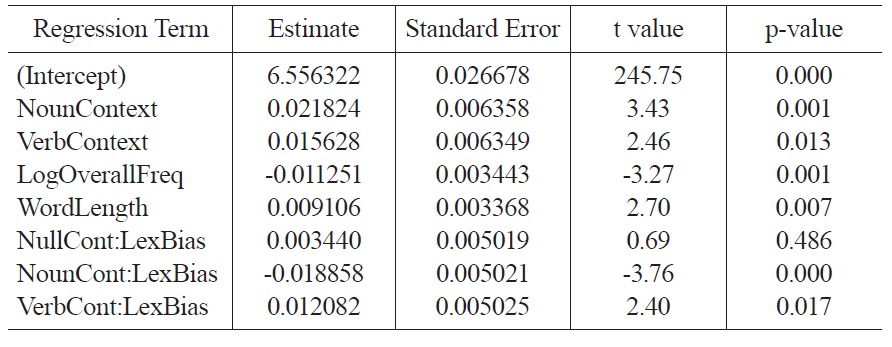
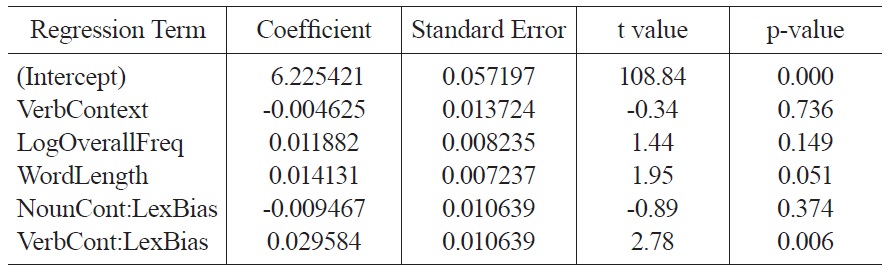
The regression was structured to test for an interaction between lexical bias and syntactic context to evaluate the research question. In particular, since a positive lexical bias indicates a noun-biased word, positive lexical biases should increase reaction times in verb contexts. In contrast, negative lexical biases should increase reaction times in noun contexts. All coefficients were standardized. The fixed effects from the regression analysis are shown in Table 2.
Consistent with the hypothesis that lexical information can guide interpretation independent of syntax, these results show the effects in the interaction terms. First, the coefficient of NounContext:LexicalBias is significantly negative (p < .001), indicating that a positive lexical bias decreases reaction times in noun contexts, and a negative lexical bias increases reaction times. Second, the coefficient of VerbContext:LexicalBias is significantly positive (p < .02), indicating the opposite pattern for verb contexts. The coefficient of NullContext:LexicalBias is not significant (p > 0.48), indicating that in null contexts, lexical bias did not affect reaction times. In addition, the regression shows significant effects of log overall word frequency and length: more frequent words are read more quickly and longer words are read more slowly. Finally, the regression shows significant main effects of NounContext (p < 0.005) and VerbContext (p < 0.02), indicating that words in these conditions are responded to slower than in the null-context condition.
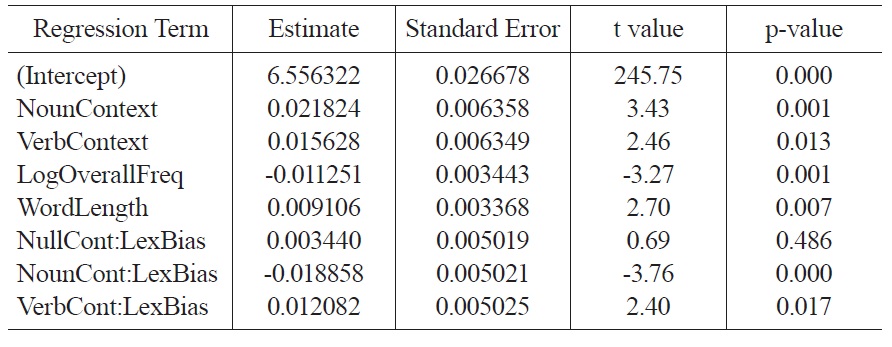
Fixed effects in a mixed model regressing log lexical decision reaction times on context and lexical bias. (Following R notation, interaction terms are denoted using colons.)
Discussion
The ANOVA results of Experiment 1 demonstrated that there is some difficulty associated with processing noun-biased words in a verb context and with processing verb-biased words in a noun context. Furthermore, the regression results demonstrated that this difficulty is modulated by the degree of lexical bias, across the 180 items in the experiment. This pattern of results is as predicted by the hypothesis that lexical information can guide interpretation independent of syntax, but not by the hypothesis whereby lexical access is filtered according to the syntactic context.
This experiment was conducted to extend the findings from Experiment 1 to a more natural language comprehension task where the critical words were presented in larger syntactic contexts.
Methods
Participants Twenty-four participants from MIT and the surrounding community took part in the experiment. All were between the ages of 18 and 40 years old, native speakers of English, and naïve as to the purposes of the study. None participated in either of the two Norming Studies or in Experiment 1. All participants were paid for their participation.
Design and Materials This experiment had a 2 x 2 design crossing (1) lexical bias (Noun, Verb), and (2) context (Noun, Verb). A subset of the items used in Experiment 1 was used: 24 noun-biased items and 24 verb-biased items, for a total of 48 items. The experimental sentences were constructed such that the noun-context and the verb-context conditions were minimally different prior to the critical ambiguous word, by including sentence initial phrases like
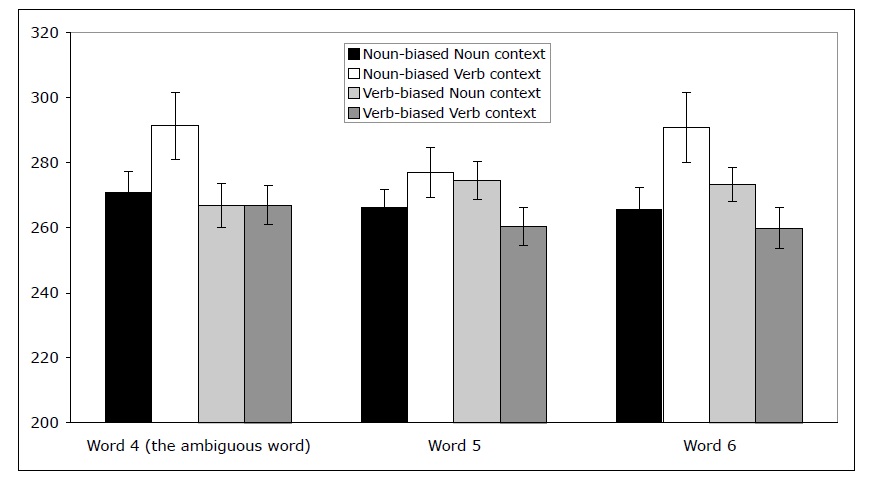
Because many of the ambiguous words were short and because it is often difficult to see the effects on a single word in sentence processing, we defined three critical regions: (1) the ambiguous word, (2) the word immediately following the ambiguous word, and (3) the word two words after the ambiguous word.
In addition to the 48 target items, 96 filler materials were constructed. The filler sentences used constructions similar to those used in the target items (i.e.
Procedure The task was self-paced word-by-word reading with a movingwindow display (Just, Carpenter & Woolley, 1982). The experiment was run using the Linger 2.94 software. Each trial began with a series of dashes marking the length and position of the words in the sentence. Participants pressed the spacebar to reveal each word of the sentence. As each new word appeared, the preceding word disappeared. The amount of time the participant spent reading each word was recorded as the time between keypresses.
To make sure the participants read the sentences for meaning, at the end of each trial a comprehension question appeared asking about the propositional content of the sentence they just read. Participants pressed one of two keys to respond “Yes” or “No”. After an incorrect answer, the word “INCORRECT” flashed briefly. Before the experiment started, a short list of practice items and questions was presented in order to familiarize the participants with the task.
Participants took approximately 35 minutes to complete the experiment.
Results
Accuracy data Across the four conditions, participants answered correctly 95.4% of the time. A 2 x 2 ANOVA crossing lexical bias (Noun, Verb) with context (Noun, Verb) revealed an unpredicted effect of context, such that the verb-context conditions were less accurate than the nouncontext conditions (F1(1,23)=4.70; MSe=209; p<.05). (As in Experiment 1, because lexical bias is a between-items factor, the analysis by items is not meaningful in this design.) There was also an unpredicted marginal effect of bias, such that participants were less accurate in the noun-biased conditions than the verb-biased conditions (F1(1,23)=3.87; MSe=88; p=.06), and a marginal interaction (F1(1,23)=3.06; MSe=88; p=.09). These effects appear to be driven by the noun-biased/verb-context condition being less accurate than the other three conditions. One possible explanation for the difference among conditions is that the noun-biased words were more biased than the verb-biased words: specifically, the noun-biased words had an average bias of .94 and the verb-biased words had an average bias of .83. The higher bias in the noun-biased conditions combined with the incongruent syntactic context may have resulted in the noun-biased/verb-context condition being less accurate than the other three conditions. Table 3 presents the mean accuracies across the four conditions of Experiment 2.
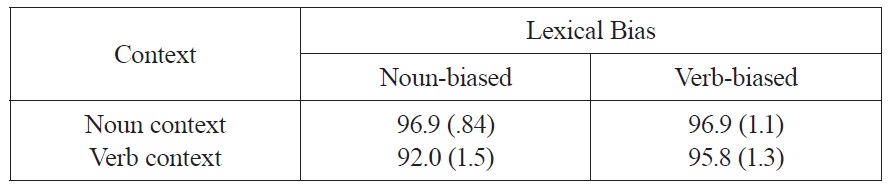
Accuracies in percent correct, as a function of lexical bias and context across the four conditions of Experiment 2 (standard errors in parentheses).
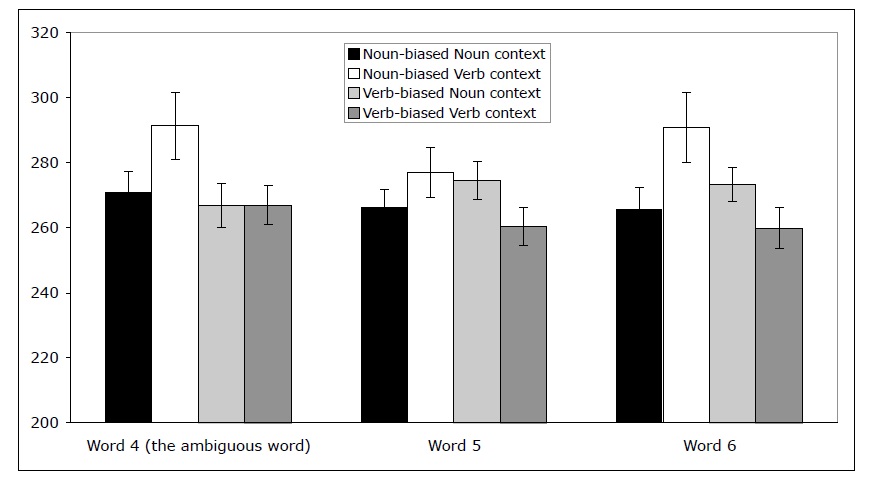
Reading time data A 2 x 2 ANOVA crossing lexical bias (Noun, Verb) with context (Noun, Verb) was conducted on different regions of the sentence as shown in 7 (the three critical regions are in bold).
At the first region (
We don’t report comparisons involving later regions in the sentences, because differences in materials across the different conditions make any potential differences hard to interpret.
Regression analysis As in Experiment 1, we performed a mixed effect regression analysis on the log reading times using subjects and items as random effects and controlling for log overall frequency and length of the critical word. All coefficients were standardized. We used total reading time on the two words following the critical word as the dependent variable. Analyses were carried out using the R statistical programming language with the packages lme4 (Bates, 2005) and languageR (Baayen, 2008). As in Experiment 1, significance values were computed using Markov chain Monte Carlo method, and sampling was run for 50,000 steps.
As in Experiment 1, we tested for an interaction between lexical bias and syntactic context. The hypothesis whereby lexical information guides interpretation independent of syntactic information predicts that the interaction term NounContext:LexicalBias would be negative, and the interaction term VerbContext:LexicalBias would be positive. This corresponds to positive lexical biases (noun-biased words) slowing reading times in verb contexts, and to negative lexical biases (verb-biased words) slowing reading times in noun contexts. The fixed effects from the regression analysis are shown in Table 4.
[Table 4.] Fixed effects in a mixed model regressing log reading times on context and lexical bias.
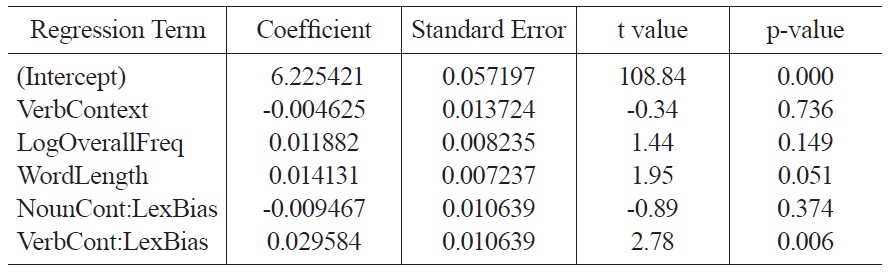
Fixed effects in a mixed model regressing log reading times on context and lexical bias.
Consistent with the hypothesis that lexical information can guide interpretation independent of syntax, the coefficient of VerbContext:LexicalBias is significantly positive (p < 0.01), indicating that a positive lexical bias increases reading times in verb contexts, and a negative lexical bias decreases reading times. However, although the coefficient of the NounContext:LexicalBias interaction term is in the direction predicted by the hypothesis that lexical information can guide interpretation (negative), it is not significantly different from zero (p > 0.37). This may result from the smaller number of subjects and items in this experiment, compared to Experiment 1.
Discussion
The ANOVA results of Experiment 2 demonstrated that in sentential contexts there is some difficulty associated with processing noun-biased words in a verb context and with processing verb-biased words in a noun context providing further support for the hypothesis that lexical information can guide interpretation independent of syntax. Furthermore, similar to Experiment 1, the regression results demonstrated that this difficulty is modulated by the degree of lexical bias. The fact that the regression results were only significant for the verb-context conditions (unlike in Experiment 1, where the regression results were consistent in both the noun- and verb-context conditions) can perhaps be explained by: (a) the fact that there were only 48 items in this experiment as compared to 180 in Experiment 1, resulting in a less powerful analysis; and (b) the fact that the noun-biased words were more biased than the verb- biased verbs, with the possible consequence that the verb-biased items may not have resulted in as much difficulty in the noun contexts as the noun-biased verbs in the verb contexts.
Overall, the pattern of results is similar to the pattern of results in Experiment 1, and is as predicted by the hypothesis that lexical information can guide interpretation independent of syntax, but not by the hypothesis whereby lexical access is filtered according to the syntactic context.
Two experiments were presented – a lexical decision experiment and a selfpaced reading experiment – that tested the independence of syntactic and lexical information sources in online language processing. Both experiments provided evidence that syntactic and lexical information guide interpretation independently. In particular, both experiments showed a subordinate bias effect (Duffy et al., 1988; Rayner et al., 1994), such that the dominant lexical meaning was highly available due to its frequency, and the subordinate meaning was made available by the syntactic context, giving rise to elevated RTs for the noun-biased words in a verb context and verb-biased words in a noun context. Furthermore, this set of results generalizes earlier findings from the category-ambiguous word
The current results thus fill the gap in the literature for processing category-ambiguous words in biasing contexts, using a reading paradigm. These results provide further evidence against syntactic information being the only source of information that can guide sentence processing. Like context (Altmann & Kamide, 1999; Grodner, Gibson & Watson, 2005) and semantic and plausibility information (Kuperberg et al., 2003; Kim & Osterhout, 2005), lexical information can also guide sentence processing, independent of the syntactic context (Tyler & Marslen-Wilson, 1977; Ford, Bresnan & Kaplan, 1982; Marslen-Wilson & Tyler, 1987; Culicover & Jackendoff, 2005).

![The distribution of the responses for 180 target items in Norming Study 2, sorted by the percentage of noun responses (plotted on the y-axis). [Note that although the graph contains all 180 data points, the words displayed on the x-axis are a small subset of the 180 words, because it would be impossible to display them all legibly.]](http://oak.go.kr/repository/journal/17649/NRF009_2012_v13n3_249_f0001.jpg)
![The distribution of the responses for 175 target items in the Corpus Study, sorted by the noun bias (plotted on the y-axis). [Note that although the graph contains all 175 data points, the words displayed on the x-axis are a small subset of the 175 words, because it would be impossible display them all legibly.]](http://oak.go.kr/repository/journal/17649/NRF009_2012_v13n3_249_f0002.jpg)