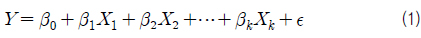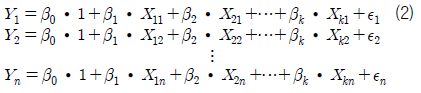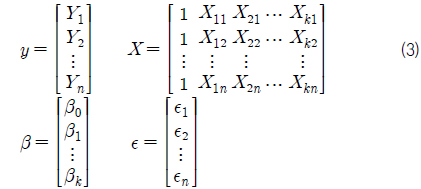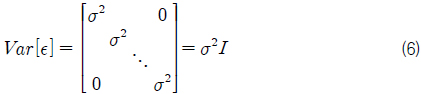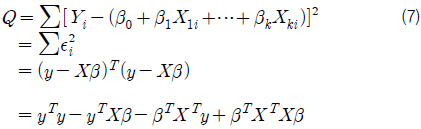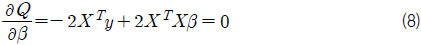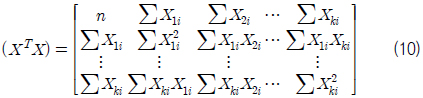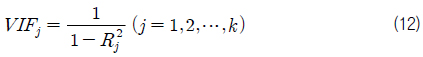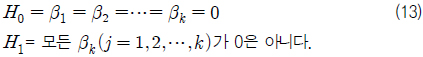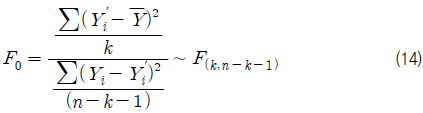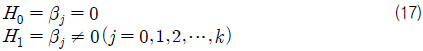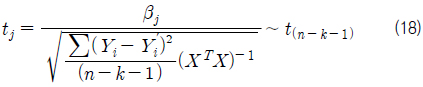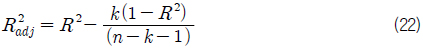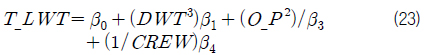The weight estimation of floating offshore structures such as FPSO, TLP, semi-Submersibles, Floating Offshore Wind Turbines etc. in the preliminary design, is one of important measures of both construction cost and basic performance. Through both literature investigation and internet search, the weight data of floating offshore structures such as FPSO and TLP was collected. In this study, the weight estimation model was suggested for FPSO. The weight estimation model using non-linear regression analysis was established by fixing independent variables based on this data and the multiple regression analysis was introduced into the weight estimation model. Its reliability was within 4% of error rate.
세계 에너지 수요가 상승하고 고유가가 지속됨에 따라 해양 구조물 사업은 블루 오션으로 각광받고 있다. 이는 해양 구조물 사업이 조선 사업과는 달리 제품이 표준화되어 있지 않으며, 환경·안전 등에 대한 요구 수준이 높고 자원개발과 연계되어 수행되기 때문에 부가가치가 높다는 이유에서다. 이러한 추세에 맞추어 현재 부유식 석유․가스 생산 설비는 점점 늘어가고 있으며, 기존의 고정식 구조물과 더불어 심해 채굴이 가능한 부유식 해양 구조물 또한 널리 사용되고 있다 (Kang, et al., 2012).
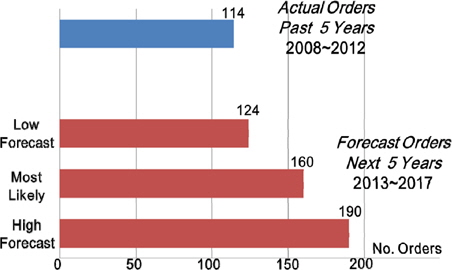
Fig. 1의 2013년 IMA(International Maritime Association)(2013)의 자료에 의하면, 향후 5년간 세계 경제와 오일의 수요 그리고 에너지 가격에 따라 매년 124대에서 190대의 부유식 해양 구조물의 주문이 있을 것이라고 예상하고 있다.
한편, 해양 구조물의 설계에 있어서 중량 정보는 생산을 위한 물량 추정과 생산 공법 결정 등에 필수적인 정보이며, 나아가 해당 구조물의 생산 비용 및 생산 기간에 영향을 미치는 요소이다. 따라서 정확한 중량의 추정이 가능하다면, 보다 효과적으로 중량을 통제할 수 있고, 또한 안정적으로 생산 비용을 산출할 수 있다.
현재 운영되고 있는 부유식 해양 구조물의 63%를 차지하는 FPSO의 경우, FEED 단계에서 정확한 중량 추정이 이루어지지 못해 추정된 중량과 후속 설계 단계나 생산 단계에서의 상부(topsides) 중량이 과도한 차이를 보이게 되면, 선체의 전반적인 설계에 심각한 문제가 발생할 수 있다. 이러한 문제가 발생한 경우, 선체의 설계를 변경하고 검증하여 FEED와 비교해야 하며, 그로 인해 비용 증가와 일정 지연이 뒤따르게 된다 (Hwang, et al., 2009).
한편, 중량의 추정과 관리 기술은 매우 중요하게 취급되고 있고 조선소의 경쟁력을 결정짓는 중요한 기술이기 때문에 기업 비밀로 분류되고 있어 중량 관리에 대한 연구 자료는 거의 공개되지 않은 실정이다.
선박 및 해양 구조물의 중량 추정 관련 연구를 간략히 소개하면 다음과 같다.
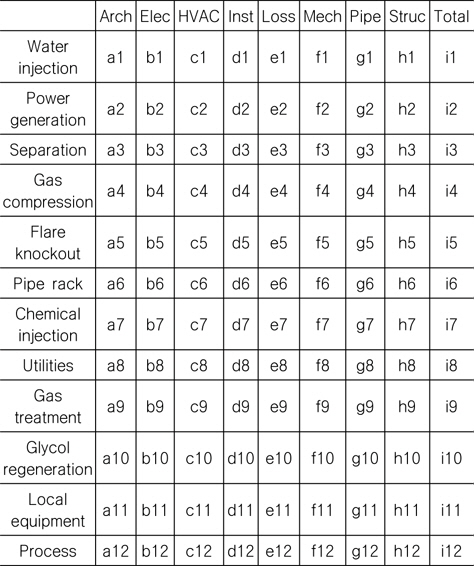
Bolding (2001)은 지금까지 건조된 많은 FPSO의 중량 보고서를 분석하여, FPSO 상부의 평균 부피 계수(Bulk Factor, [kg/m3])를 도출하였다. 부피 계수는 Table 1에서 보는 바와 같이 FPSO 상부를 구성하는 모듈들을 물 주입(water injection), 전력 생성(power generation), 분리(separation), 가스 압축(gas compression) 등과 같이 기능별로 분류한 뒤, 각 모듈을 다시 전기, 기기-통신, 기계 등으로 보다 세분화하여 구분하였다. Cho (2011)는 컨테이너선을 대상으로 통계적 방법을 이용하여 선박의 중량 추정 모델을 개발하였으며 이를 초기 설계 단계에서 활용하고자 하였다.
[Table 1] Bulk factor for topsides modules
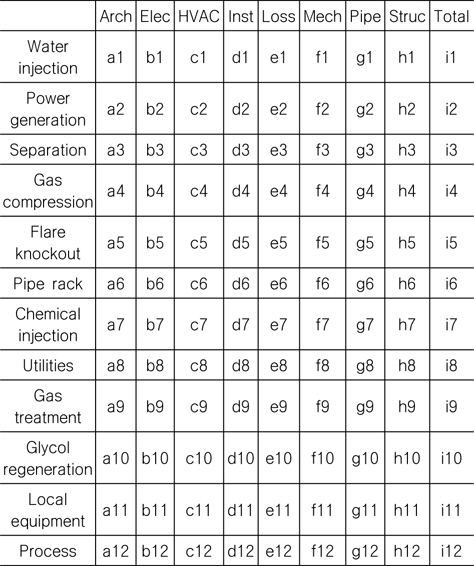
Bulk factor for topsides modules
Cimino and Dominick (2007)은 선박 및 해양 구조물 설계 분야에 적용 가능한 중량 추정 방법, 즉 파라미터 방법, 추론적 방법, 통계적 방법, 체적 밀도법 등을 소개하였다.
또한, 통계적 방법을 이용한 추정식 개발과 관련된 연구를 간략히 소개하면 다음과 같다.
Sung, et al. (2010)은 기차용 콘크리트 궤도에서 레일 두부 표면의 요철량, 운행 속도, 레일 휨 응력의 상관 관계를 분석하였고, 다중 회귀 분석을 통해 표면 요철, 운행 속도에 따른 레일의 휨 응력 예측식을 도출하였다. Lee, et al. (2009)은 전단 강도에 영향을 주는 몇 가지의 토질 물성치를 이용하여 토층의 정수를 쉽게 산정할 수 있도록 전단 강도 산정 모델을 개발하였다. 상용 통계 처리 프로그램인 SPSS의 상관 분석을 통해 토질 시험 결과 중, 강도 정수에 유효한 토질 인자(간극비 및 건조 단위 중량, 소성지수)를 선별한 후 선별된 인자들과의 관계를 선형 회귀 분석으로 공식화하였다.
Seo, et al. (2013)은 통계적 방법을 기반으로 부유식 해양 구조물 상부의 중량 추정 모델을 제안하였다. 이들은 상관 분석과 다중 회귀 분석을 통해 선형 형태의 중량 추정 모델을 개발하였다.
본 연구에서는 기존 연구 (Seo, et al., 2013)를 보다 확장하여 비선형 형태의 중량 추정 모델을 개발하고자 하였다. 이를 위해, 중량에 영향을 미치는 독립 변수들을 선정하고, 비선형 회귀 분석을 수행하여 종속 변수에 비선형 기본 모델 별로 각 독립 변수가 미치는 영향을 파악한 후, 그 결과를 활용하여 1차 독립 변수들을 추출하였다. 그리고 추출된 변수에 대한 다중 회귀 분석을 통하여 중량 추정 모델, 즉 중량 추정식을 개발하였다. 또한, 별도의 검증 데이터를 활용하여 개발된 중량 추정 모델의 신뢰성을 검토하였다.
2. 통계적 방법을 이용한 비선형 중량 추정 모델 개발
본 연구에서의 통계적 방법을 이용한 비선형 중량 추정 모델의 개발 과정은 Fig. 2와 같다. 먼저, 자료 수집을 통해 중량 추정 모델에 포함될 가능성이 높은 독립 변수를 선정한다. 이후, 비선형 회귀 분석을 이용하여 추정 대상인 종속 변수(예, FPSO 상부 중량)에 비선형 기본 모델 별로 각 독립 변수가 미치는 영향을 파악하고, 그 결과를 활용하여 중량 추정 모델에 포함될 독립 변수를 1차적으로 추출한다. 그리고 나서 다중 회귀 분석을 통해 중량 추정 모델에 최종적으로 포함될 독립 변수를 결정한다. 마지막으로, 그 변수들을 활용한 중량 추정식, 즉 중량 추정 모델을 생성한다.
회귀 분석은 하나의 변수(독립 변수)를 이용하여 다른 변수(종속 변수)의 값을 설명하거나 예측할 수 있는 모델을 가지고 데이터를 분석하는 것을 말한다. 여기서, 다중 회귀 분석이란 독립 변수의 수가 여러 개인 회귀 분석을 말한다. 즉, 다중 회귀 분석은 k개의 독립 변수가 있을 때, 식 (1)과 같은 다중 회귀 모델의 유의성(유효성)을 확인하는 것이다.
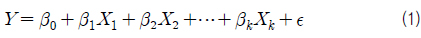
여기서, X1, X2,⋯, Xk 는 독립 변수, Y 는 종속 변수, β0, β1 ,⋯, βk 는 회귀 계수로서 미지의 상수이며, ε 는 오차항으로서 통계적 추론을 가능하게 하기 위해서, 기대값 0, 분산 σ2인 정규 분포를 따른다고 가정한다 (Walpole & Myers, 1985).
k개의 독립 변수들과 종속 변수 Y 의 관계가 식 (1)과 같다는 조건은 변수들간 상당히 강한 제약을 나타낸다. 복잡하고 다양한 실제 데이터를 모델화(수식화)하는데 있어서 선형 모델이 부적합한 경우가 간혹 있다. 또한, 이공 분야에서 수리적으로 증명된 이론들은 식 (1)과 같이 단순하지 않다. 위의 모델은 회귀 계수에 관해서도 선형적이며 변수들(Y, X1, X2,⋯, Xk)도 선형 관계를 가진다. 이 모델은 종속 변수 Y 를 수직 축에, 각 독립 변수를 수평 축에 표현한 산점도(scatter plot)들이 모두 직선 형태를 가질 때 활용 가능한 것이다.
사실 선형 회귀 모델에서 “선형”의 의미는 변수들 간의 관계라기보다는 회귀 계수들에 대한 선형임을 뜻한다. 따라서 독립 변수들과 종속 변수들은 비선형 관계이지만, 회귀 계수와는 선형인 경우에는, 원래의 변수들을 변환시켜 얻은 새로운 변수를 가지고 분석하는 것이 효과적이다. 이를 비선형 회귀 분석이라 한다 (Seo, et al., 2009).
[Table 2] Non-linear functions for the weight estimation model

Non-linear functions for the weight estimation model
본 연구에서는 비선형 회귀 분석을 위한 기본 모델로서 아래의 네 가지 함수를 채택하였다. 물론 기본 모델로서 보다 다양한 형태를 활용할 수 있으나 본 연구에서는 비교적 간단한 형태의 모델들을 기본 모델로 채택하여 활용하였다.
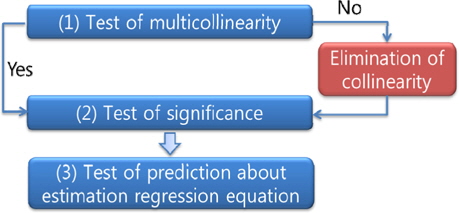
회귀 분석의 전체 과정은 회귀 계수(식 (1)의 βk)의 추정 단계와 이를 통해 만들어진 회귀식(식 (1)의 다중 회귀 모델)의 검정 단계로 구성된다.
먼저, 본 연구에서는 최소 자승법(least square method)을 이용하여 회귀 계수를 추정하였다. 다중 회귀 모델의 행렬식을 정리하면 식 (2)~(6)과 같다.
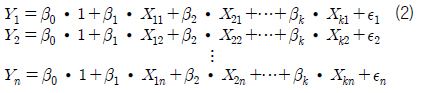
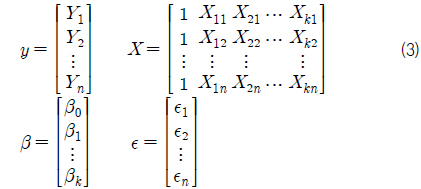


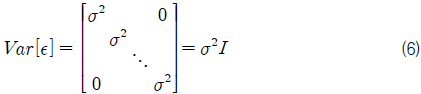
그리고 오차항의 제곱합 Q는 식 (7)과 같이 표현 할 수 있다. 이때 최소자승법에 의한 회귀 계수 추정은 식 (7)~(9)와 같이 제곱합 Q를 각 β 에 대해 편미분하고 이를 0으로 하는 연립 방정식을 풀어 각각의 βk 를 구하는 것이다.
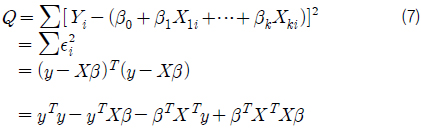
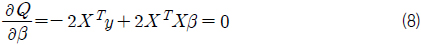

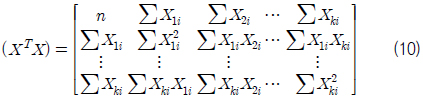

이 과정을 통해 회귀 계수 βk 가 결정되었으므로 식 (1)과 같은 다중 회귀 모델, 즉 회귀식을 구성할 수 있으며, 이제 이 모델에 대한 검정이 필요하다. 다중 회귀 분석의 일반적인 검정 과정은 아래와 같다 (Lee, et al., 2009).
(1) 독립 변수에 대한 다중 공선성의 검정
독립 변수 사이에 상관 관계를 갖고 있는 현상을 다중 공선성(multicollinearity)이라고 한다. 어떤 독립 변수가 다른 독립 변수들의 선형 결합, 예를 들어 X2=5X1과 같이 표현될 수 있으면 완전 공선성(perfect collinearity)이 존재하는 것이다. 이 경우 식 (9)에서의 역행렬 (XTX )-1이 산출되지 않기 때문에 회귀 계수를 추정할 수 없게 된다. 비록 이와 같이 완전 공선성은 없을지라도 변수간에 상당히 높은 선형 관계가 존재하면 역행렬 (XTX)-1을 산출하는데 있어 매우 큰 오차가 유발되는데 이 현상을 다중 공선성이라고 한다.
본 연구에서는 다중 공선성의 척도로서 분산 팽창 계수(VIF: variance inflation factor)를 채택하였다. j번째 회귀 계수 βj에 대한 분산 팽창 계수는 다음과 같이 정의된다.
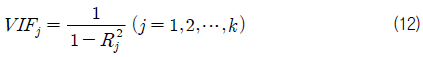
여기서 은 Xj (j번째 독립변수)를 종속 변수로 하고 나머지 변수를 독립 변수로 하는 회귀 모델에서의 결정 계수를 말한다. 이 값은 선형관계가 강할수록 1에 가깝게 될 것이다. 식 (12)에서 알 수 있듯이 Xj (j번째 독립변수)가 나머지 독립 변수들과 상관관계가 없다면(Rj 2=0) VIF 는 1이 되고, 완전한 상관관계가 있다면(Rj 2=1) VIF = ∞가 될 것이다. 일반적으로 가장 큰 VIFj 값이 10을 넘으면 다중 공선성이 있다고 할 수 있다. 여기서 10이라는 기준 값은 명확하게 정해진 것이 아닌, 일반적인 기준일 뿐이다. 그러나 10이라는 기준이 일반적으로 사용되는 기준이므로, 본 연구에서 또한 10을 기준 값으로 사용하도록 한다 (Jeon, et al., 2004).
(2) 다중 회귀식의 선형 유의성 검정
한편, 다중 회귀식의 종속 변수와 독립 변수들 사이에 1차 선형 관계가 유의하게(유효하게, 즉 약간의 오차는 가지지만) 성립하는 지를 보고자 하는 유의성 검정(Fig. 3의 (2))은 회귀성 검정과 개별 회귀 계수의 검정으로 나눌 수 있다. 전자는 회귀 모델 전체의 유의성을 검정하는 방법으로 F-검정을 사용하는 것이다. 이 방법은 독립 변수의 개수와 상관 없이 독립 변수를 모두 합하여 회귀 모델에서 독립 변수가 종속 변수에 끼치는 영향의 유의성을 검정한다. 그러나 이 방법은 독립 변수들이 종속 변수에 유의한 영향력을 끼친다고 하더라도 그 중에서 어떤 독립 변수가 더 유의한지는 알 수 없다. 반면, 후자는 k개의 회귀 계수가 있을 때 개별적인 회귀 계수 βk에 대해 t-검정을 하는 것이다 (Lee & Kang, 2009).
회귀성 검정은 β0를 제외한 모든 회귀 계수가 0의 값을 갖는가 또는 그렇지 않은가를 검정하는 것이다. 따라서 귀무 가설(H0)과 대립 가설(H1)은 다음과 같다.
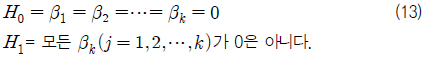
β0를 제외한 모든 회귀 계수가 0일 때 회귀성이 없다고 말하며(H0 채택), 그 중 하나라도 0이 아니라고 판단되면 H0는 기각되고, 회귀성이 있다고 말하게 된다. 위 가설을 검정하기 위한 검정통계량으로 식 (14)과 같은 F-값을 이용하며, 그 값은 F-분포를 따르게 된다.
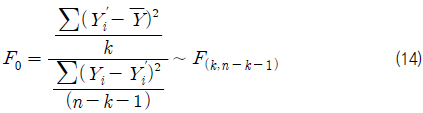
따라서 식 (15) 또는 F0에 대응되는 p-valueF가 산출되어 있을 경우에는 식 (16)과 같을 때, 유의 수준(α)에서 가설 H0를 기각하고, 회귀식이 유의하다고 결론을 내린다.


개별 회귀 계수의 검정은 각 독립 변수에 대한 검정을 할 수 있으므로 어느 독립 변수가 종속 변수에 유의한 영향을 끼치는지 알 수 있다. 따라서 귀무 가설(H0)과 대립 가설(H1)은 다음과 같다.
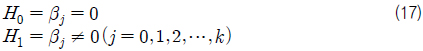
개별 회귀 계수를 검정하기 위한 t-값의 계산은 식 (18)과 같으며, 그 값은 t-분포를 따르게 된다.
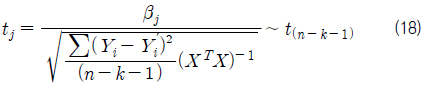
따라서 식 (19) 또는 ∣tj∣에 대응 되는 p-valuet가 산출되어 있을 경우에는 식 (20)과 같을 때, 가설 H 0를 기각하고 유의 수준(α)에서 Xj (j번째 독립변수)가 종속변수 Y에 유의한 영향을 미친다고 결론을 내린다 (Lee & Kang, 2009).


여기서, 유의성 검정의 기준이 되는 유의수준(α)는 신뢰수준의 반대 의미로 사용되며, 검정의 신뢰도를 높이기 위하여 0.1(10%)보다는 0.05(5%), 0.01(1%) 등이 사용되며, 이들 3가지가 유의수준의 일반적인 값이다. 유의수준이 10%에서 5%로 된다는 것은 검정의 정도가 까다로워진다는 것을 의미한다. 즉, 수치상으로 그 값이 작을수록 "유의수준이 높아졌다"라고 한다. 그러나 유의수준이 얼마가 되어야 한다는 기준은 없으며, 본 연구에서는 F-검정의 유의수준은 0.05, t-검정의 유의수준은 0.05로 정하였다.
(3) 회귀식에 대한 예측력 검정
회귀식에 대한 예측력 검정 단계(Fig. 3의 (3) 참조)에서 본 연구에서는 결정 계수(R2)가 아닌, 조정된 결정 계수(R 2adj)를 활용하였다. 여기서, 결정 계수(R2)는 회귀식이 얼마나 정확하게 종속 변수의 값을 예측하는 가에 대한 값이다. 그 값이 1에 가까울수록 예측력이 높다는 것을 의미한다. 그러나 결정 계수(R2)는 독립 변수가 추가됨에 따라 항상 증가함으로 독립 변수 수에 따른 결정 계수(R2)의 증가분에 대한 조정을 필요로 한다. 조정된 결정계수(R2adj)는 식 (22)와 같이 정의 되는데 독립 변수의 추가에 의해 증가된다는 결정 계수(R 2)의 결점을 보완한 것이다.

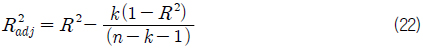
여기서,
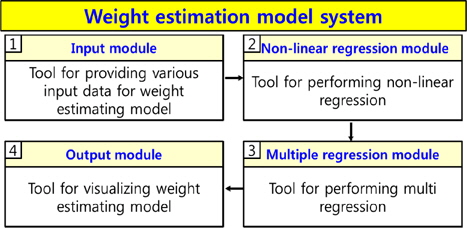
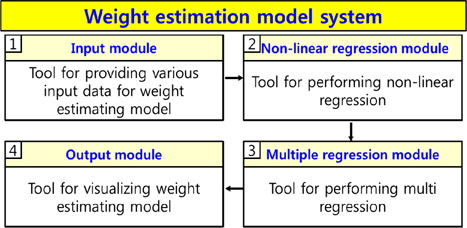
본 연구에서는 비선형 회귀 분석과 다중 회귀 분석을 통해 중량 추정 모델을 생성하는 프로그램을 자체적으로 개발하였다. Fig. 4는 개발한 프로그램의 전체 구성도를 나타낸다. Fig. 4에 나타나 있듯이, 본 프로그램은 입력 모듈(중량 추정 모델 생성을 위한 데이터 입력), 비선형 회귀 분석 모듈(종속 변수와 각각의 독립 변수 간에 비선형 회귀 분석), 다중 회귀 분석 모듈(다중 회귀 분석 수행), 출력 모듈(중량 추정 모델 생성)로 이루어져 있다.
입력 모듈(Fig. 4의 ①)은 실적 자료로부터 중량 추정 모델의 생성을 위한 각종 자료, 즉 중량(종속 변수)과 여러 독립 변수를 입력한다. 여기서 자료의 입력은 조사된 자료를 숫자로 배열한 것에 불과하다. 그러나 이렇게 배열된 숫자가 의미하는 바가 무엇이고, 각 변수들이 갖는 의미를 제대로 파악하는 것이 중요하다.
비선형 회귀 분석 모듈(Fig. 4의 ②)은 종속 변수와 각각의 독립 변수 간에 비선형 회귀 분석을 수행한다. 그 후, 네 가지 비선형 기본 모델 중에서 추출 기준을 최대한 만족시키는 모델을 채택하여 변환된 변수를 1차 독립 변수로 추출한다.
다중 회귀 분석 모듈(Fig. 4의 ③)은 1차적으로 추출된 독립 변수들과 종속 변수간에 다중 회귀 분석을 수행하여 중량 추정 모델을 도출한다. 그 후, Fig. 3과 같이 검정 과정을 수행한다.
마지막으로, 출력 모듈(Fig. 4의 ④)은 다중 회귀 분석 모듈로부터 생성된 중량 추정 모델을 출력하고 가시화하는 기능을 수행한다.
아무리 많은 실적선 자료를 수집했더라도, 중량의 분류 기준이 동일하지 않으면 활용이 어렵다. 따라서 본 연구에서는 실적선 자료 수집 전 Fig. 5와 같은 분류 방법을 기준으로 삼았다.
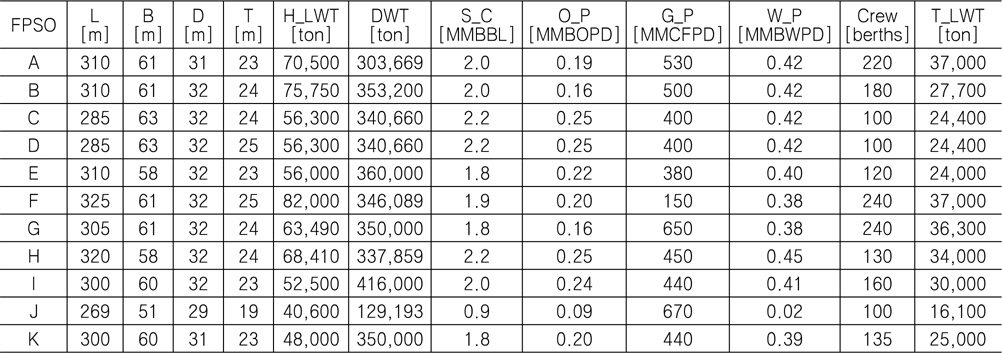
이후 중량 추정 모델을 개발하기 위해 실적 데이터를 수집하였다. 조선소로부터 정확한 데이터를 얻는 것이 보다 정도 높은 모델 개발에 필요하나 보안 등의 이유로 어려웠기 때문에 본 연구에서는 인터넷 또는 각종 문헌 조사를 통해 Table 3과 같이 총 11척의 FPSO 실적 자료를 확보하였다. 이들 중 10척의 자료 (A~J)는 중량 추정 모델을 만들기 위한 학습 데이터로서 활용하였고, 1척의 자료(K)는 개발된 중량 추정 모델의 검증에 활용하였다.
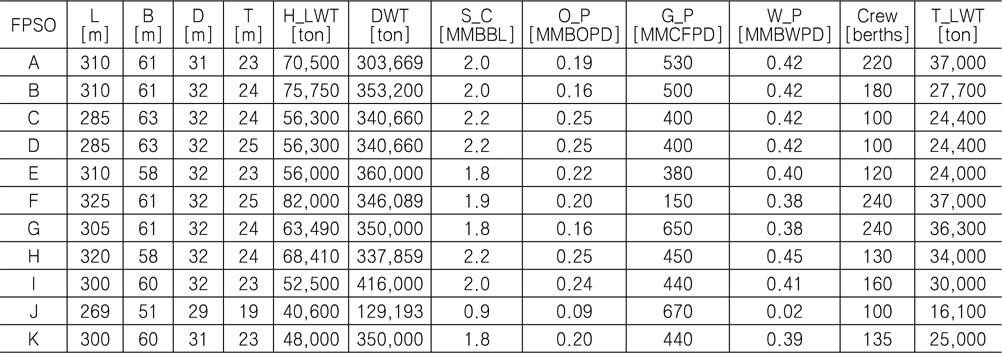
Principal particulars of 11 FPSO data used for developing the weight estimation model in this study
Table 4는 FPSO 상부 중량(“T_LWT”라는 이름의 종속 변수로 가정)에 영향을 미치는 선체(hull)와 상부(topsides)의 독립 변수를 조사한 결과이다.
[Table 4] Independent variables for estimating the topsides weight of FPSO

Independent variables for estimating the topsides weight of FPSO
여기서, L, B, D, T는 각각 해양 구조물 선체의 길이, 폭, 깊이, 흘수를 나타내고, H_LWT는 선체 중량, DWT는 재화 중량을 나타낸다. 그리고 S_C, O_P, G_P, W_P는 각각 해양 구조물의 저장 용량, 오일 생산량, 가스 생산량, 물 주입량을 나타낸다. 끝으로 Crew는 해양 구조물의 작업 인원을 나타낸다.
본 연구에서는 종속 변수와 각각의 독립 변수간에 비선형 회귀 분석을 수행하여, 유의 확률(Sig.)이 0.1 이하인 모델 가운데 결정 계수가 가장 큰 모델을 채택 후, 변수 변환을 거쳐 1차 독립 변수를 추출하였다.
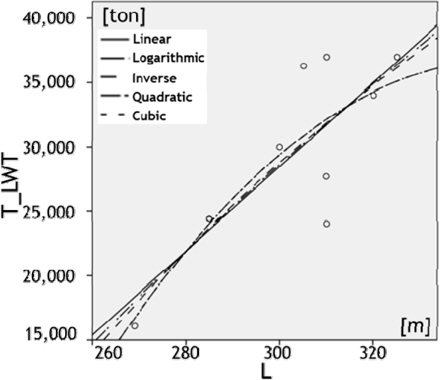
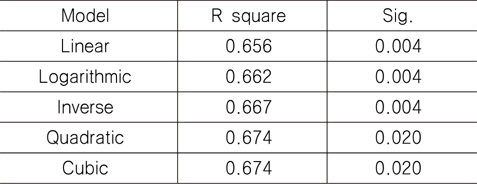
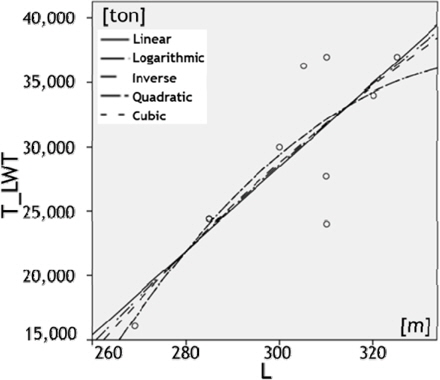
여기서는 11개의 독립 변수 중에 하나인 L과 종속 변수 T_LWT간의 비선형 회귀 분석 결과와 1차 독립 변수를 추출하는 과정을 살펴보기로 한다. 비선형 회귀 분석 결과를 나타내는 Fig. 6과 Table 5를 살펴보면, 기준을 만족하는 것은 2차(quadratic)와 3차(cubic) 모델임을 알 수 있다. 따라서 둘 중 상대적으로 간단한 2차 모델을 활용하기로 하며, 그 결과 L과 L2을 1차 독립 변수에 포함시킨다. 이와 같은 방법을 나머지 독립 변수들에 대해 적용하면, 총 26개의 독립 변수를 1차적으로 추출할 수 있다. 나머지 10개의 독립 변수들과 종속 변수간의 비선형 회귀 분석 결과는 지면 관계상 생략하였다.
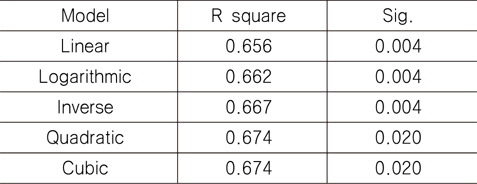
The values of R-squared and significance probability by the non-linear function between L and T_LWT
이후 비선형 회귀 분석을 통하여 1차적으로 추출된 26개의 독립 변수들과 종속 변수(T_LWT)간에 다중 회귀 분석을 수행하였다.
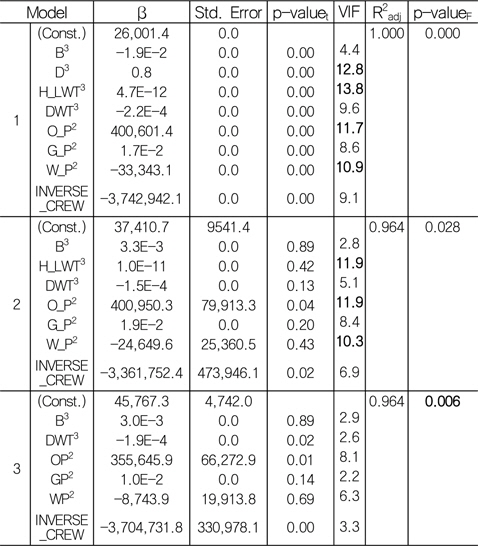
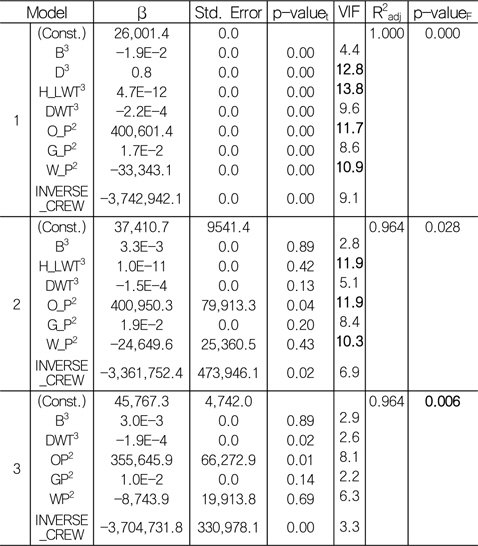
Table 6은 다중 회귀 분석의 검정 과정 중 첫 단계인 다중 공선성 검정(Fig. 3의 (1) 참조)을 보여주고 있다.
[Table 6] The process of multicollinearity testing
The process of multicollinearity testing
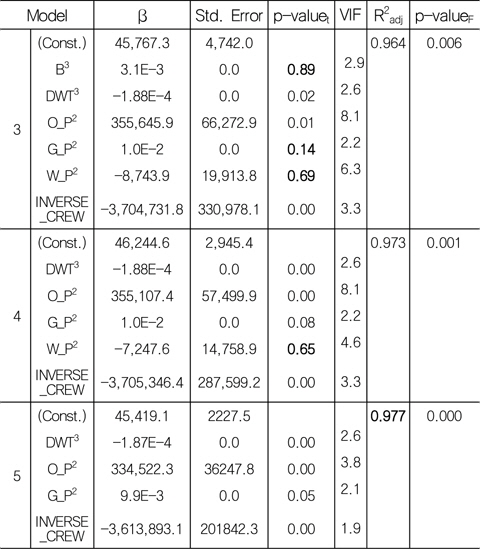
Table 6의 Model 1과 같이 회귀 계수가 도출되면, 먼저 다중 공선성 검정을 하기 위하여, 그 척도인 분산 팽창 계수(VIF)가 10이 넘어가는 독립 변수를 살펴본다. 그 결과 D3, H_LWT3, O_P2, W_P2 간에 다중 공선성이 존재함을 알 수 있다. 여기서 다중 공선성이 존재하는 D3, H_LWT3, O_P2, W_P2 중 임의의 것을 제거하는 것이 아니라 상관 관계를 검토하여 상관 계수가 보다 적은 것을 선택하여 제거해야 한다. 종속 변수(T_LWT)와 네 독립 변수(D3, H_LWT3, O_P2, W_P2)들 간에 상관 분석을 실시하여, 상관 계수가 상대적으로 작은 독립 변수부터 제거하였다. 따라서, Model 1에서는 D3을, Model 2에서는 H_LWT3을 제거하였다. 마지막으로 도출된 Model 3을 보면 분산 팽창 계수(VIF) 값이 10이상인 값이 없는 것으로 나타나 다중 공선성이 모두 제거된 것을 확인할 수 있다.
여기서 β, Std. Error, p-valuet, VIF, R2adj, p-valueF는 각각 회귀 계수, 표준 오차, 개별 회귀 계수의 유의 확률, 분산 팽창 계수, 조정된 결정 계수, 회귀 모델 전체의 유의 확률을 나타낸다.
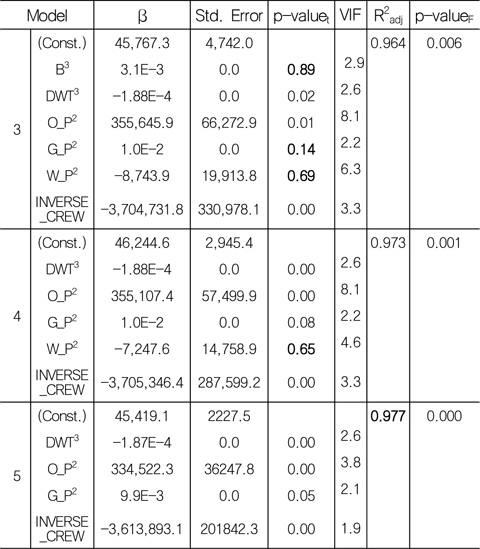
다음으로 선형 유의성 검정(Fig. 3의 (2) 참조)을 한다. 회귀성 검정의 경우, Model 3은 Sig. of F=0.006으로 유의 수준(α) 0.05 하에서 회귀성이 있는 것으로 검정되었다. Table 7은 개별 회귀 계수의 검정을 보여주고 있다.
[Table 7] The process of t-testing
The process of t-testing
Model 3을 살펴보면, 유의 수준(α) 0.1 하에서 유효하지 않은 회귀 계수가 B3, GP2, WP2 임을 알 수 있다. 유효하지 않은 변수라고 해서 반드시 모델에서 제거해야 하는 것은 아니다. 변수의 제거는 연구 의도에 따라 결정된다고 할 수 있다. 비록 유효하지 않은 변수라 하더라도 연구자의 판단에 의해 중요한 변수라고 생각된다면 모델에 포함시킬 수 있다. 물론 그에 따른 타당한 이유와 근거가 제시되어야 한다 (Lee & Kang, 2009). 본 연구에서는 유의확률이 높은 순서대로 변수를 하나씩 제거하면서, 최종적인 모델을 도출하였다. 그 결과, Model 5는 유의 수준(α) 0.1하에서 모두 유효한 변수를 가지고 있음을 확인할 수 있다.
다음으로 회귀식에 대한 예측력 검정(Fig. 3의 (3) 참조)을 한다. Model 5는 조정된 결정 계수(R2adj) 0.977로 종속 변수 총 변동의 97.7%를 설명할 수 있는 것으로 나타났다.
앞서, 비선형 회귀 분석을 통해 1차적으로 26개의 독립 변수를 추출하였고, 이후 다중 회귀 분석을 통해 FPSO 상부 중량을 추정하기 위한 추정식을 개발하였다.
Table 7의 회귀 분석 결과와 식 (1)을 활용하여 FPSO 상부의 중량 추정 모델을 표현하면 식 (23)과 같다.
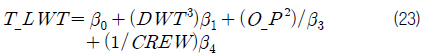
where,
본 연구에서는 앞서 개발된 중량 추정 모델의 유효성을 검증하기 위해 추정 모델을 이용한 추정 중량과 실적선 중량의 차이에 대한 오차 분석을 수행하였다.
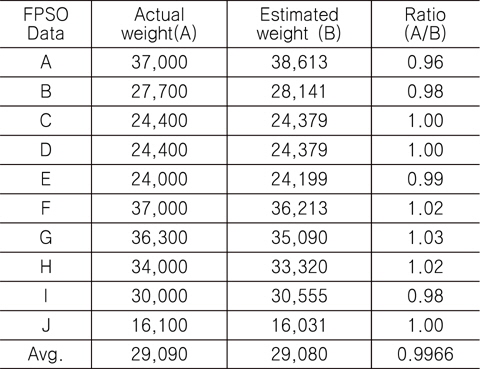
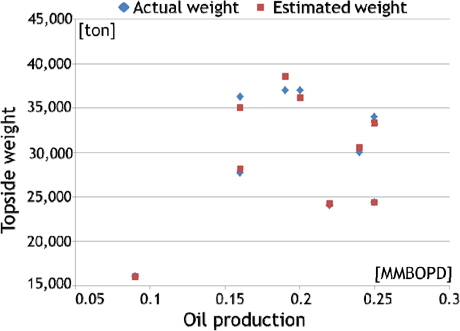
Table 8에 나타나 있듯이, 실적선 중량과 추정 중량의 비의 평균은 0.9966, COV(Coefficient Of Variation)는 0.02이다. 즉, 실적선 중량과 추정 중량 사이의 오차가 2%라는 것을 나타낸다. Fig. 7은 실적선 중량과 추정 중량의 차이를 나타낸 것이다.
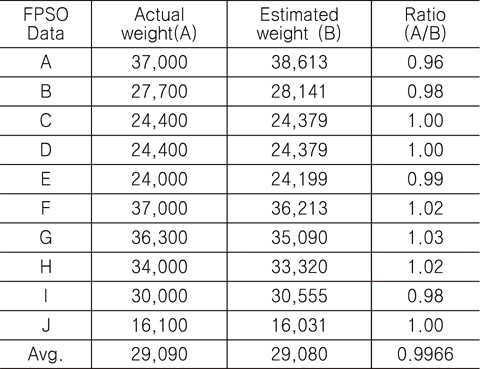
Error analysis for examining the validity of the weight estimation model using 10 FPSO data
그리고 중량 추정 모델을 개발하기 위하여 활용한 FPSO 자료 외에 별도의 실적선 자료(FPSO K)를 앞서 개발된 추정식의 유효성 검증에 활용하였다. 그 결과는 Table 9와 같다.

Weight comparison between estimation model and additional FPSO data for examining the validity
Table 10은 기존 연구를 통해 개발한 선형 중량 추정 모델 (Seo, et al., 2013)과 본 연구에서 개발한 비선형 중량 추정 모델을 비교한 것이다. 조정된 결정 계수(R2adj)와 검증 데이터에 대한 예측력(A/B 비교)을 비교한 결과, 선형 중량 추정 모델보다 비선형 중량 추정 모델이 더 우수함을 알 수 있고, FPSO 상부와 관련된 변수를 더 많이 포함하고 있음을 볼 수 있다.
[Table 10] Comparison between linear and non-linear model for estimating topsides weight of FPSO
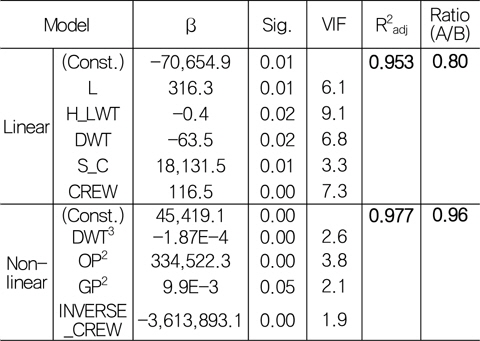
Comparison between linear and non-linear model for estimating topsides weight of FPSO
본 연구에서는 설계 초기 단계에서 활용할 수 있는 부유식 해양 구조물의 중량 추정 모델에 대해 연구하였다. 이를 위해, 먼저 실적선 자료 확보를 통해 중량에 영향을 미치는 독립 변수를 선정하였고, 이들에 대해 비선형 회귀 분석을 수행한 후 변수 변환을 통해 중량 추정 모델에 포함될 변수들을 1차적으로 추출하였다. 이후, 다중 회귀 분석을 통해 중량 추정 모델을 개발하였다. 끝으로 중량 추정 모델을 개발하기 위하여 활용한 자료 외에 별도의 실적선 자료를 개발된 추정 모델의 유효성 검증에 활용하였다.
이상과 같은 부유식 해양 구조물의 중량 추정 모델 개발 연구와 관련하여 아래와 같은 결과를 얻을 수 있었다.
(1) 해양 구조물의 주요 특성을 반영하고, 우리가 추정하고자 하는 중량(종속 변수)에 영향을 미치는 독립 변수의 도출이 중요하다. (2) 보다 정교한 중량 추정 모델을 개발하기 위해서는 이의 기반이 되는 실적선 자료의 확보가 중요하고 중량 관리 표준에 대한 논의가 필요하다. (3) 비선형 중량 추정 모델은 상부 중량 총 변동의 97%를 설명할 수 있는 것으로 나타나, 추정식이 초기설계단계에서 활용이 가능한 것으로 나타났다. 또한 별도의 실적선 자료를 통한 검증 결과, 오차율이 4%로 나타나, 추정방법의 유효성을 입증하였다.
향후에는 Semi-submersible(반잠수식 구조물), TLP(인장식 각 플랫폼), Floating offshore wind turbine(해상풍력발전기) 등 다양한 해양구조물에 대한 보다 많은 실적선 확보를 통해 보다 정교한 중량 추정 모델을 개발하고, 그 유효성을 검증할 예정이다.