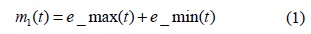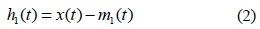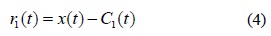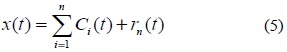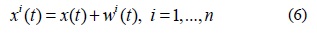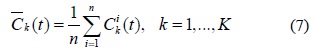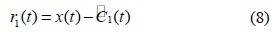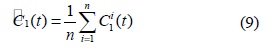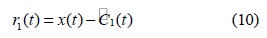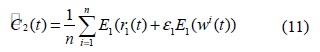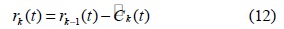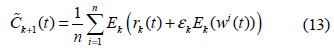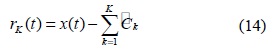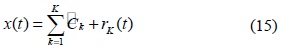EMD는 미리 정의된 어떠한 기저함수도 사용하지 않으며 사용자에 의해 미리 정의된 파라미터값도 필요치 않은 완전히 데이터에 기반한 신호 처리의 특징을 갖는다. 그러나 유사한 스케일을 갖는 신호 모드로 분해하는 것을 방해하는 모드 혼합이 발생하는 단점이 있다. 이를 해결하기 위해 EEMD 알고리즘이 도입되었으며, EEMD는 처리하고자 하는 신호에 가우시안 백색 잡음을 혼합하여 앙상블 수만큼 신호를 만들어 EMD 방법을 적용함으로써 모드 혼합문제를 해결한다. 그럼에도 EEMD는 잡음이 추가된 신호 분해 시 원 신호와 상이한 모드 수를 만들어 내며, 분해된 신호들을 원 신호로 재구성 시에도 레지듀 잡음이 포함된다. 본 논문은 개선된 EEMD알고리즘으로 EMD의 모드 혼합 문제를 해결하고 원신호를 정확히 재구성하며 EEMD 보다 적은 연산 비용으로 신호 모드 분리를 제안한다. 실험결과는 EEMD 방법과 비교하여 적은 체과정의 반복으로 빠른 모드 분리를 보여 주었으며 EEMD 방법의 20.87%의 비용만으로 완전한 신호 분해가 가능하였고, 신호 복원에 있어서도 EEMD 보다 우수한 성능을 보여주었다.
EMD is a fully data-driven signal processing method without using any predetermined basis function and requiring any user parameters setting. However EMD experiences a problem of mode mixing which interferes with decomposing the signal into similar oscillations within a mode. To overcome the problem, EEMD method was introduced. The algorithm performs the EMD method over an ensemble of the signal added independent identically distributed white noise of the same standard deviation. Even so EEMD created problems when the decomposition is complete. The ensemble of different signal with added noise may produce different number of modes and the reconstructed signal includes residual noise. This paper propose an modified EEMD method to overcome mode mixing of EMD, to provide an exact reconstruction of the original signal, and to separate modes with lower cost than EEMD's. The experimental results show that the proposed method provides a better separation of the modes with less number of sifting iterations, costs 20.87% for a complete decomposition of the signal and demonstrates superior performance in the signal reconstruction, compared with EEMD.
EMD (Empirical Mode Decomposition)는 비선형적이며 비정상적인 신호를 분석하기 위해 도입된 적응적인 모드이다[1-3]. EMD에 의해 분해된 신호 모드는 지역적(local)이고 완전히 데이터에 기반한(data-driven) 빠르고 느린 진동의 분리로 구성된다. EMD는 신호를 몇 개의 모드(mode) 또는 IMF (Intrinsic Mode Function)라 불리는 유한개의 함수로 분해한다. 모드들 은 원신호의 고유한 속성을 보존하면서 분해 단계가 증가할수록 신호의 복잡도와 스케일이 감소한다[2]. 그러나 EMD는 같은 모드 내에서 동일한 스케일을 가진 신호로 분해하지 않고, 한 모드 내에 이질적인 진폭을 가진 진동이 존재하거나 서로 다른 모드 내에 유사한 진동이 존재하는 모드 혼합(mode-mixing)의 문제가 발생한다. 이러한 문제를 해결하기 위해 가우시안 백색 잡음을 추가한 신호의 앙상블 상에 EMD를 수행하는 EEMD (Ensemble Empirical Mode Decomposition)라 불리는 새로운 방법이 제안되었다[4-6]. 가우시안 백색잡음의 추가는 시간-주파수 공간에 잡음이 존재하도록 함으로써 EMD가 dyadic 필터뱅크처럼 동작하도록 하여 모드 혼합 문제를 풀 수 있다[4]. 그러나 EEMD는 원신호에 백색 잡음을 추가한 앙상블 신호의 분해이므로 원신호의 모드와 다른 모드의 수를 만들어 내며, 복원 된 신호가 레지듀 잡음을 포함하게 되어 상이한 신호가될 수 있다[5,6]. 이런 문제를 극복하기 위해 본 논문은 EEMD에 적용된 수식을 개선하여 EMD의 모드 혼합 문제를 해결하고 적은 연산 비용으로 효율적인 모드 분리와 원신호의 정확한 복원을 제안하고자 한다.
신호 분해 방법으로 EMD는 웨이블릿과 달리 미리 정의된 기저 함수를 사용하지 않으며, 사용자에 의한 파라미터 값들의 적용 없이 완전히 데이터에 기반하여 신호를 분해한다. 따라서 원신호의 고유한 비선형성‧비정상성의 특징을 그대로 보존할 수 있다[7].
2.1. EMD (Empirical Mode Decompositon)
EMD는 신호
단계 1. 신호
단계 2. 단계 (1)에 의해 추출된 극점들은 큐빅 스플라인으로 연결하여 상위 포괄선
단계 3. 상위 포괄선과 하위 포괄선의 평균 함수
단계 4. 신호
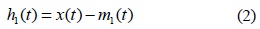
만일

단계 5. 신호
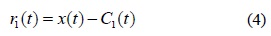
단계 6. 만일 레지듀
원 신호
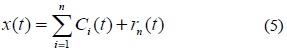
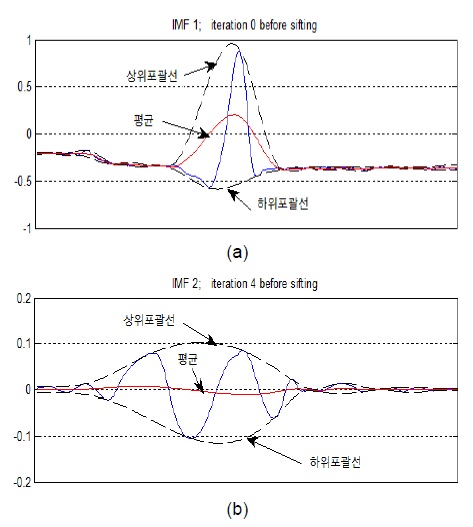
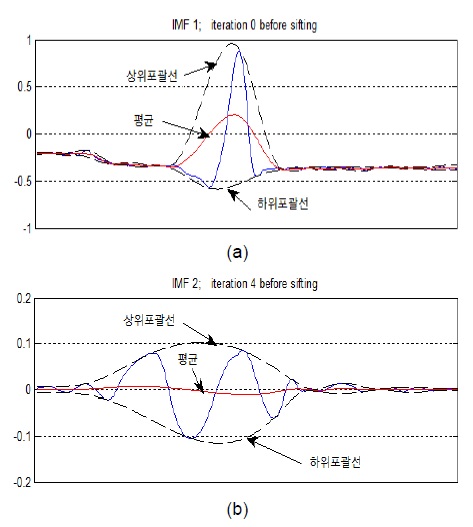
EMD는 사용자에 의해 미리 정의된 파라미터값이나 선택된 기저함수를 사용하지 않고 완전히 데이터에 기반하므로 원신호의 특성을 잘 보존한다. 그림 1(a)는 EMD 알고리즘의 단계 1-3을 구현한 것으로 신호의 극대‧극소점을 찾아 큐빅스플라인으로 연결한 후 상위포괄선과 하위포괄선의 평균을 구한 결과이고, 그림 1(b)는 IMF를 구하기 위한 체과정으로 EMD 알고리즘의 단계 4-6의 과정으로 IMF를 구하기 위한 위의 두 가지 조건을 만족할 때까지 반복한다.
2.2. EEMD (Ensemble Empirical Mode Decompositon)
EMD 방법에 의한 신호 분해 시 각각의 모드는 유사한 스케일의 진동으로 분리되어야 하지만 상이한 스케일의 진동이 포함되는 모드 혼합 문제가 발생할 수 있다. EEMD에 있어 앙상블이라 함은 원신호
단계 1. 원 신호
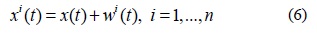
단계 2. EMD 방법을 잡음 추가 신호인
단계 3. 구하고자 하는 분해 과정의 최종 IMFs 는 로 대응되는 의 앙상블의 평균으로 다음 수식과 같이 구한다.
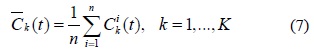
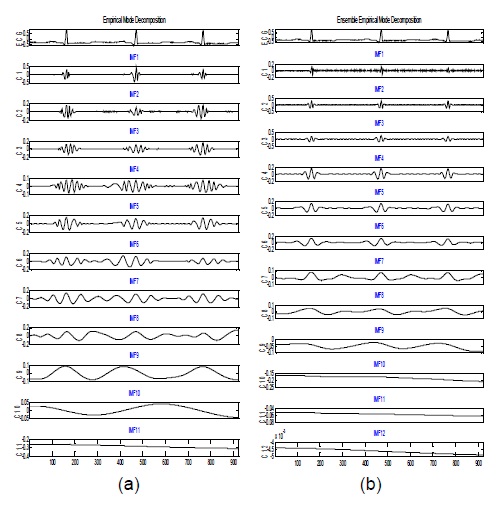
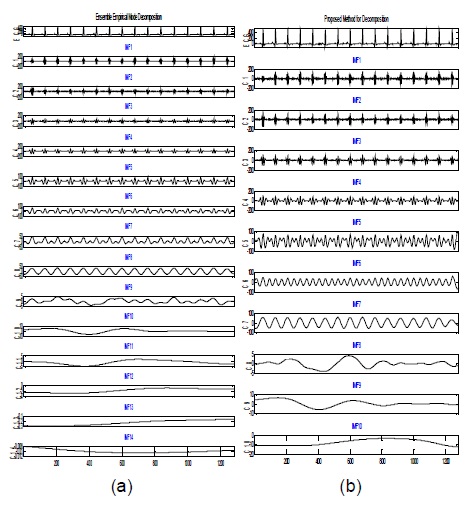
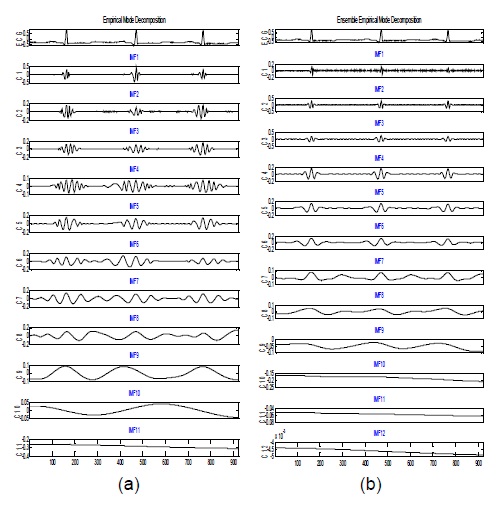
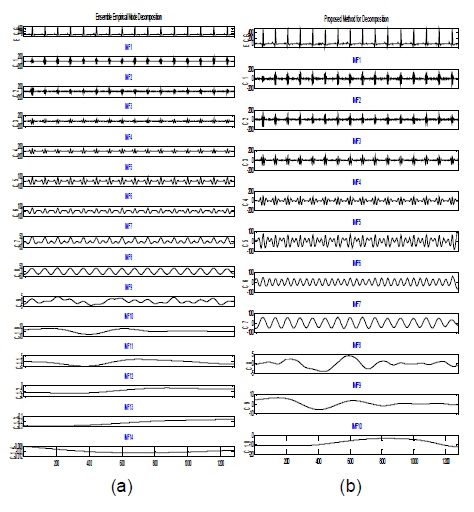
그림 2(a)는 EMD 방법에 의해 10개의 IMF와 1개의 레지듀 신호로 분해된 결과이며, 그림 2(b)는 EEMD 방법에 의해 11개의 IMF와 1개의 레지듀 신호로 분해를 보여준다. EMD 방법에 의한 신호 분해 모드들은 한 스케일에서 다른 스케일로 이행단계에서 간헐적 진동인 에일리어스에 의해 유사한 스케일을 가진 신호를 추출하는 것을 어렵게 만든다. EEMD 방법에 있어 분해하려는 데이터는 식 (6)에서 주어진 것처럼 신호와 잡음의 혼합이다. 측정의 정확성을 기하고자 앙상블 평균 방법을 사용하였으며, 앙상블 아이디어를 일반화하기 위해 원 신호에 서로 다른 백색잡음을 도입하여 수 많은 물리적 실험을 반복할 수 있는 신호를 만들 수 있게 된다. 백색 잡음을 추가하는 것이 낮은 SNR을 초래할 지라도 EMD 방법에 의한 신호 분해를 용이하게 하여 균등한 스케일 분포를 제공할 수 있다. 실제로 신호 데이터에 서로 다른 백색 잡음의 추가함으로써 신호 분해 방법에 영향을 미치지 않고 모드 혼합을 피하도록 하여 신호를 향상시킬 수 있음이 증명되었다[4]. 그림 2 (b)는 식 (6-7)을 적용하여 신호를 분해한 결과로 그림 2(a)의 EMD에 의한 신호 분해보다 균등한 스케일의 분해를 보여준다.
EEMD에서 각
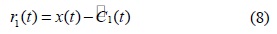
여기서 는 EEMD에서와 같은 방법으로 구한다. 수식을 적용하여 를 구하고 서로 다른 독립 동일 분포의 잡음이 추가된
식의
단계 1. 첫 번째 모드들을 얻기 위하여
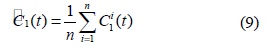
단계 2. 첫 번째 단계인
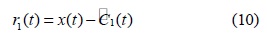
단계 3.
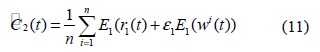
단계 4.
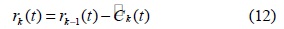
단계 5.
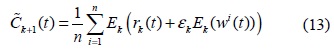
단계 6. 단계 4로 가서 다음
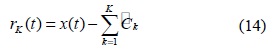
전체 모드의 수
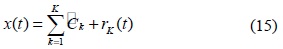
식 (15)는 제안한 신호 분해 후에 IMF 집합인 (
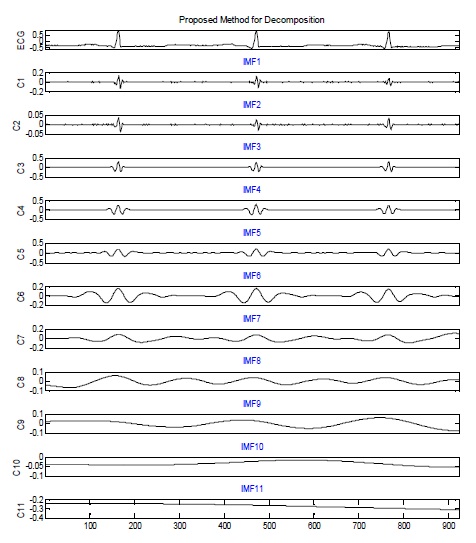
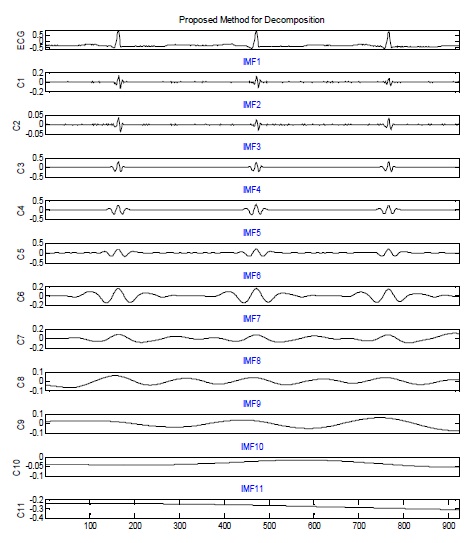
그림 3은 제안하는 방법에 의한 식 (9-15)를 구현한 결과를 보여준다. 그림 3의 맨 위는 잡음이 섞인 ECG 신호를 나타내며 은 분해 모드인 IMFs, 은 레지듀 신호를 나타낸다.
그림 3의 제안한 방법과 그림 2(b)의 EEMD 방법에 의한 분해 결과를 비교할 때, 그림 3의 에서 더 균등한 스케일을 보이고 있으며, 체과정을 통해 얻은 모드 수에 있어서도 EEMD 방법보다 적은 계산 비용이 소요되었다.
실험을 위한 데이터는 MIT-BIH 심전도 데이터베이스로부터 획득하였으며[8], 1028 길이의 샘플링된 신호를 발생시켜 EEMD 방법과 제안한 방법을 비교 실험하였다. 그림은 ECG 신호에 EEMD와 제안한 방법을 적용한 신호 분해 결과를 보여준다. 앙상블의 크기
EEMD 방법의 신호 분해는 식 (6)과 같이 서로 다른 잡음이 섞인 신호
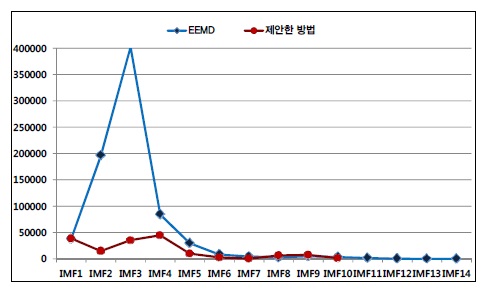
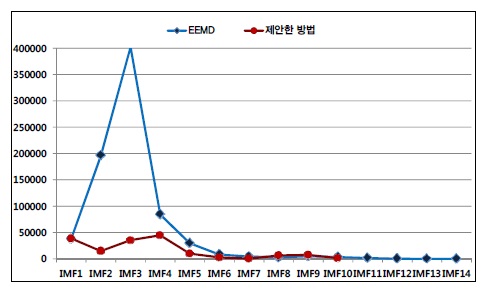
EEMD 방법과 비교했을 때 제안한 방법의 또 다른 장점은 체과정의 반복횟수가 적다는 것이다. EEMD 방법은 신호 분해를 위해 774510번의 체과정을 필요로 한 반면 제안한 방법은 161666번의 체과정을 필요로 하였다.
그림 5는 각 IMF 모드를 얻기 위해 필요한 체과정의 총 반복횟수를 나타내고 있으며, EEMD 방법과 제안한 방법의 그래프를 보여준다. 그림 5에서 알 수 있듯이 제안한 방법은 EEMD 방법에 의한 체과정의 20.87%만이 ECG 신호 분해에 요구되었다.
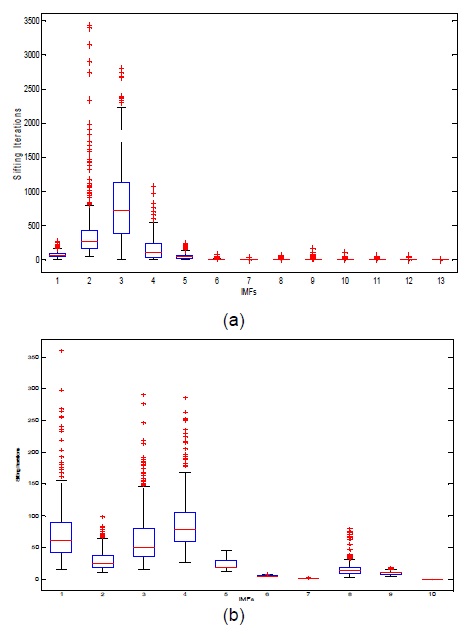
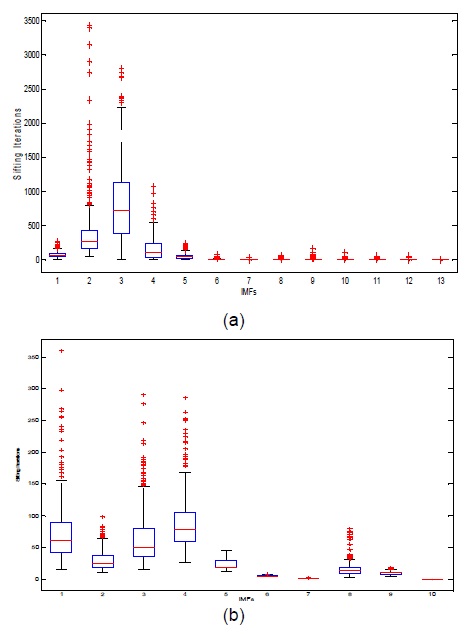
신호의 분해에 요구되는 각 모드의 체과정 반복에 대한 박스 도표는 그림 6에서 제시된다. 각 IMF의 단계에서 보여진 붉은 색의 +표식은 EMD 방법의 신호 분해조건을 만족하기 위한 반복 횟수를 나타낸다. 그림 6의(a)와 (b)의 박스도표에서 반복 횟수를 보여주는 y축의 단위가 EEMD 방법은 35000을 나타내고, 제안하는 방법은 350을 보임으로써 제안한 방법의 연산 비용이 적음을 알 수 있다.
[그림 6.] EMD와 EEMD 방법에 의한 신호 분해 (a) EEMD 방법에 의한 각 모드에 따른 체과정의 박스 도표 (b) 제안한 방법에 의한 IMF에 따른 체과정의 박스 도표
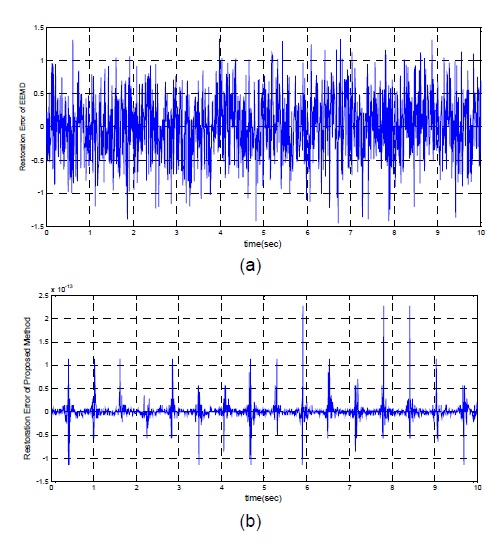
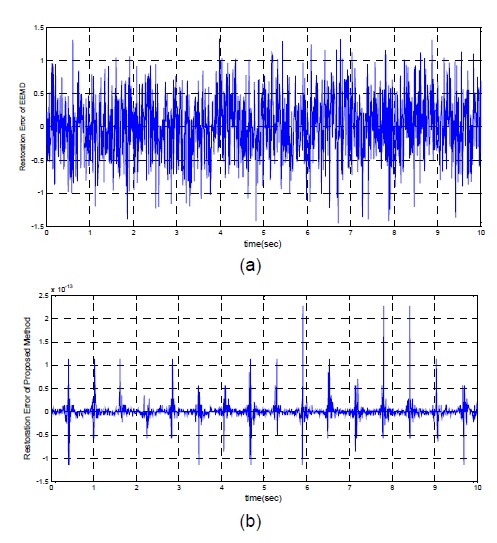
분해된 신호들을 식 (15)의 IMF들과 최종 레지듀의 합으로 재구성할 수 있다. 그림 7(a), (b)는 EEMD와 제안한 방법에 의한 복원 오류의 결과를 ECG 원신호와 모드들의 합의 차로 계산하여 그래프로 나타내었다. 제안한 방법의 경우 오류 표준편차 2.38×10−14이고 최대 진폭은 2.5×10−13 이다. EEMD 방법을 적용하여 이러한 정밀성에 도달하기 위해서는 식 (16)을 고려할 때[5], 백색 잡음이 포함된 신호의 수를 1026이상으로 증가시켜야 하므로 엄청난 연산 비용이 요구된다.

본 논문에서 비선형적이고 비정상적인 신호를 분석하고 처리하기 위해 데이터에 기반한 신호 처리 알고리즘을 ECG 신호에 적용하여 실험하였다. 신호 분해를 위한 연산과정에서 EEMD 알고리즘을 개선하여 보다 적은 신호 앙상블을 적용함으로써 연산 비용의 감소를 가져왔고, 각 단계의 신호 분해 모드인 IMF들을 EEMD방법의 20.87% 정도의 체과정 만으로 해결할 수 있었다. 그리고 EEMD 방법은 백색 잡음의 추가 등으로 EMD 방법의 모드 혼합 문제를 해결하였음에도 원신호를 복원하는데 있어 완전히 데이터에 기반한 모드가 아니므로 정확한 복원이 어려웠으나 제안한 방법은 EEMD 방법에 의해 놓친 EMD 속성의 일부를 복원할 수 있었으며, 분해된 모드들의 합으로 원 신호를 정확히 복원할 수 있었다.