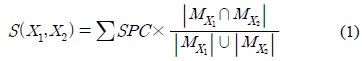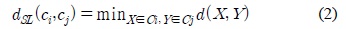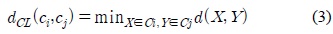Recently, researches have been developing efficient techniques for accessing, querying, and managing XML documents which are frequently used in the Internet. In this paper, we propose a parent-child matrix to cluster XML documents efficiently. A parent-child matrix analyzes both the content and structural features of an XML document. Each cell of a parent-child matrix has either the value of a node in an XML tree or the value of a child node, where a parent-child relationship exists in the XML tree. Then, the similarity between two XML documents can be measured by the similarity between two corresponding parent-child matrices. The experiment shows that our proposed method has good performance.
최근 들어, 인터넷에서 자주 사용되는 XML 문서들에 대한 접근, 질의와 관리를 위한 효율적인 기법들이 연구 되어 왔다. 이 논문에서, 우리는 XML 문서를 효율적으로 군집화하기 위해 부모-자식 행렬 기법을 제안한다. 부모-자식 행렬은 XML 문서의 내용과 구조의 특징들을 분석한다. 부모-자식 행렬의 각 셀은 XML 트리 노드의 값이거나, 트리에서 부모-자식 관계가 존재할 때의 자식 노드의 값이 된다. 따라서 두 XML 문서의 유사도는 대응하는 부모-자식 행렬들의 유사도로 측정된다. 실험을 통해 우리가 제안하는 기법이 좋은 결과를 냄을 보였다.
As the Internet continues to grow and evolve, XML has become the world’s most widely accepted data representation and exchange format. An XML document consists of a content and a structure, and in this way differs from traditional data. This requires new effective methods to process, organize, and retrieve the semi-structural nature of XML data.
The general purpose of data clustering is to derive some relevant information from the various data for further data processing. The clustered data may show some tendency or regularity in the data and may even show some relevant knowledge worth noting. The clustering of XML documents is to group similar documents to facilitate searching because similar documents can be searched and processed within a specific category. The appropriate clustering of XML documents is also effective for systematic document management, data integration, XML retrieval, efficient storage of XML documents, and even for system protection purposes because unusual document can be discovered easily. XML clustering methods can be categorized into three main groups: methods based on content, methods based on structure, and methods based on both content and structure.
A nested structure of an XML document can be modeled as an ordered labeled tree. An element and an inclusion relationship of an XML document corresponds to a node and a level of the corresponding tree, respectively1). Therefore, we can find similar XML trees corresponding to XML documents for clustering. However, the difficult task is to find partially matched sub-trees between XML trees. The studies to find partially matched sub-trees between XML trees that have been made so far are complex, and have an overhead[1-3]. Thus, in this paper, we propose a parent-child matrix to find both semantically and structurally matched sub-trees between XML trees efficiently. In fact, a parent-child matrix can represent not only parent-child relationships but also ancestordescendant relationships between nodes in an XML tree. Each cell of a parent-child matrix has either the value of a node in an XML tree or the value of a child node, where a parent-child relationship exists in the XML tree. Then, the similarity between two XML documents can be measured by the similarity between two corresponding parent-child matrices. The experiment shows that the clusters are formed well and efficiently when a parent-child matrix is used to cluster XML documents.
The rest of the paper is organized as follows. The related works are discussed in section 2. In section 3, we propose a parent-child matrix method to cluster XML documents. In section 4, we test and verify the effectiveness of our algorithm with synthetic and real data. Finally, we make a conclusion in section 5.
1)In a tree representation, attributes are not distinguished from elements, both are mapped to the tag name set; thus, attributes are handled as elements.
XML data can be represented using a common data model such as rooted labeled trees, directed acyclic graphs, or vector-based techniques for clustering. The data models capture either content, structure, or content and structural features of XML data, and it is the basis for the identification of the features to be exploited in the similarity computation. XML documents can be represented as labeled trees. Several authors have provided algorithms for computing the optimal edit distance between two XML trees, which is the generalization of the problem of computing the distance between two strings[4]. In general, edit distance measures the minimum number of node/sub-tree insertions, deletions, and updates required to convert one XML tree T1 into another XML tree T2. The distance between T1 and T2 is then defined to be the cost of such a sequence[1-3,5-9]. However, a clustering based on the notion of edit distance between the tree representations of an XML document is too costly to be practical. Thus, an effective summarization, which can distinguish documents among different clusters, would be highly desirable. Based on this direction, Ref. [10] developed the notion of the s-graph to represent XML data and suggested a distance metric to perform clustering on XML data. They have shown that the s-graph of an XML document can be encoded by a cheap bit string, and clustering can then be efficiently applied on the set of bit strings for the whole document collection.
XML data can be represented as vectors in an abstract n-dimensional feature space. A feature can be either element, text, level, path, or any component of an XML document/tree. Then, the feature vectors are compared to find similar XML documents. Ref. [11] applies a K-means clustering technique to XML documents represented in a vector-space model. In this representation, each document is represented by an N-dimensional vector with N being the number of document features such as text features, tag features, and a combination of both in the collection. However, they only consider the contents of XML. In Refs. [12,13], a new bitmap indexing based technique to cluster XML documents is described. A BitCube is presented as a 3-dimensional bitmap index of triplets (document, XML-element path, word). BitCube indexes can be manipulated to partition documents into clusters by exploiting bit-wise distance and popularity measures. Ref. [14] devises features for XML data, focusing on content information extracted from textual elements and structural information derived from tag paths. They introduce the notion of tree tuple in the definition of an XML representation model that allows for mapping XML document trees into transactional data, i.e., variable length sequences of objects with categorical attributes. A partitional clustering approach has been developed and applied to the XML transactional domain. Ref. [15] transforms XML trees into vectors in a high-dimensional Euclidean space based on the occurrences of the features in the documents. Next, they apply principal component analysis (PCA) to the matrix to reduce its dimensionality. Finally, they use a K-means algorithm to cluster the vectors residing in the reduced dimensional space and place them in appropriate categories. Refs. [16,17] propose a method to extract representative paths from the XML trees by various pattern mining techniques. Then, the XML documents are clustered by the path similarities.
Ⅲ. PARENT-CHILD MATRIX SIMILARITY MEASURE FOR XML DOCUMENTS
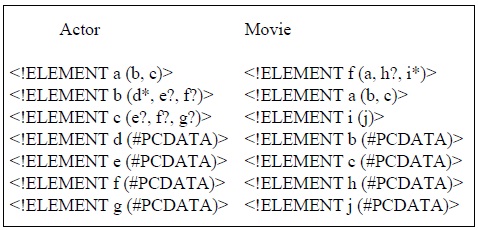
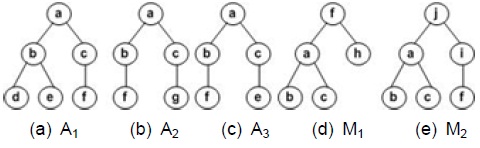
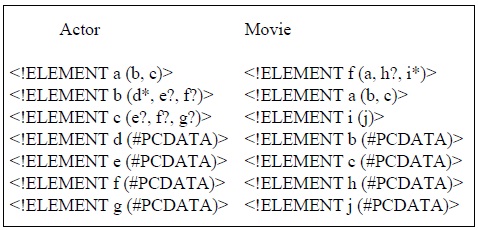
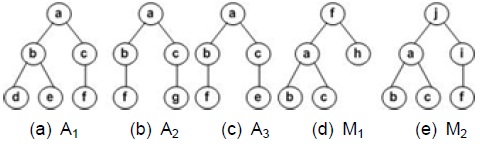
The similarity between two XML documents can be measured by their content and structure features. Let us assume that Figs. 2(a), 2(b) and 2(c) are the corresponding XML trees of the XML documents A1, A2, and A3 generated by the Actor DTD of Fig. 1. Let us also assume that Figs. 2(d) and 2(e) are the corresponding XML tress of the XML documents M1 and M2 generated by the Movie DTD of Fig. 1. These XML trees share the nodes of a, b, c, and f, and they also share nodes b and c as the child nodes of node a. In other words, they share node f and a sub_tree rooted at the node a. Therefore, the XML documents A1, A2, A3, M1, and M2 are similar to each other.
We propose a parent-child matrix to represent this kind of content and structural features of the XML trees corresponding to the XML documents.
Both the vertical and horizontal axes of a parent-child matrix represent all the distinct nodes in the given XML trees. Each cell of a parent-child matrix has either the value of a node in an XML tree or the value of a child node, where a parent-child relationship exists in the XML tree. However, XML documents can encompass many optional and repeated elements. Thus, the value of a node becomes the summation of each node’s value when the nodes with the same name occur multiple times in an XML tree in order to reflect repetitions of elements in similarity measure.
Definition 1: A parent-child
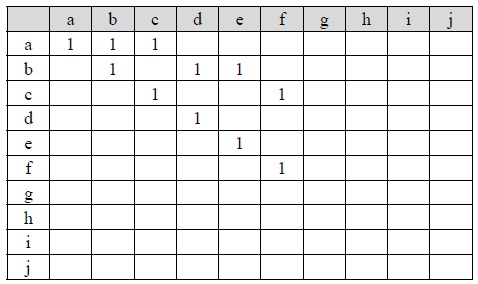
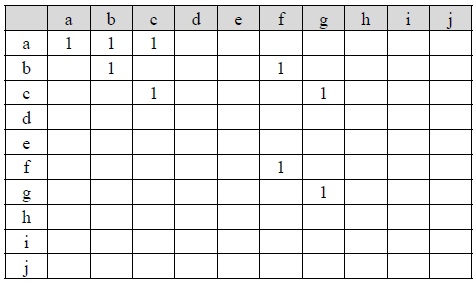
For example, when the value of each node is 1, Tables 1 and 2 are the parent-child matrices of the XML documents A1 and A2 , respectively. Any parent-child relationship between two nodes in an XML tree is represented by a parent-child matrix. A parent-child relationship between node
[Table. 1] Parent-child Matrix of XML Document A1
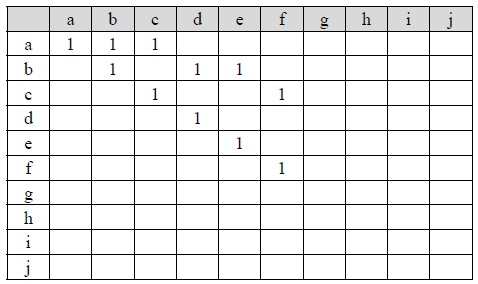
Parent-child Matrix of XML Document A1
[Table. 2] Parent-child Matrix of XML Document A2.
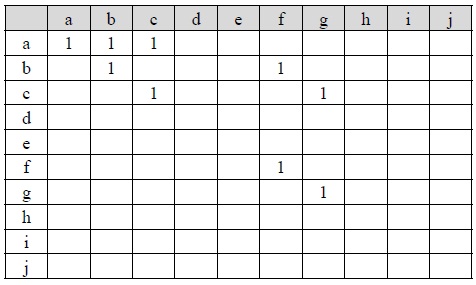
Parent-child Matrix of XML Document A2.
A similarity between two XML documents can be measured by the similarity between two corresponding parent-child matrices. In this paper, when both the corresponding cells between two parent-child matrices have some value, we call those cells as a paired cell. Then, the number of paired cells and the summation of all the paired cells' values between A1 and A2 is 6 and 12, respectively, because Figs. 2(a) and 2(b) share the nodes of
Definition 2. The similarity
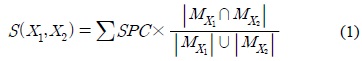
where ∑
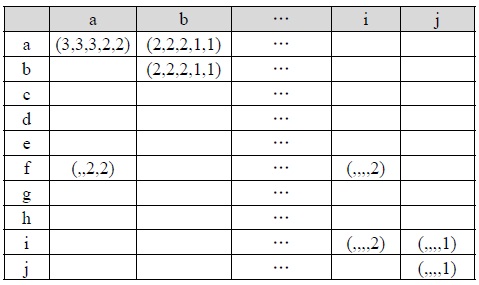
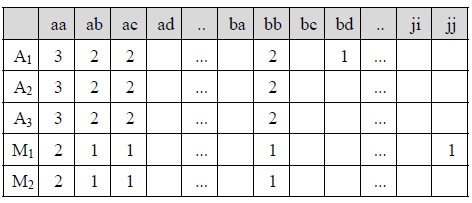
For example, if we give a weighted value of 3, 2, and 1 to a node in the first, second, and third level of an XML tree, respectively, table 3 shows the combination of the five parent-child matrices for XML documents A1, A2, A3, M1, and M2. In this case, the similarity between A1 and A2 is 24×(6/20), because their total cells' number, the paired cells' number and the summation of all the paired cells' values is 20, 6 and 24, respectively. On the other hand, the similarity between A1 and M1 is 21×(6/20) because their total cells' number, the paired cells' number and the summation of all the paired cells' values is 20, 6 and 21, respectively. Therefore, the similarity between A1 and A2 is greater than the similarity between A1 and M1. In the similar way, the similarity between A1 and M1 is 21×(6/20) and the similarity between A1 and M2 is 21×(6/22). Therefore, the similarity between A1 and M1 is greater than the similarity between A1 and M2. Since A2 and A3 have an additional ancestor-descendant relationships between node
[Table. 3] Combination of the Parent-child Matrices for XML documents A1, A2, A3, M1, and M2
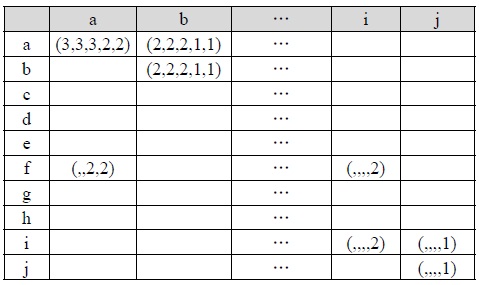
Combination of the Parent-child Matrices for XML documents A1, A2, A3, M1, and M2
Ⅳ. CLUSTERING XML DOCUMENTS BY PARENT-CHILD MATRIX
We use a hierarchical clustering algorithm to cluster XML documents. The hierarchical clustering algorithms produce a hierarchy of nested clustering. A clustering
Different agglomerative clustering algorithms are obtained by using different methods to determine the similarity of clusters. The single-linkage algorithm is obtained by defining the distance between two clusters to be the smallest distance between two patterns such that one pattern is in each cluster. Therefore, if Ci and Cj are clusters, the distance between them is defined as in
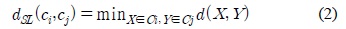
where,

where,
[Table. 4] Parent-child vectors for XML documents A1, A2, A3, M1, and M2
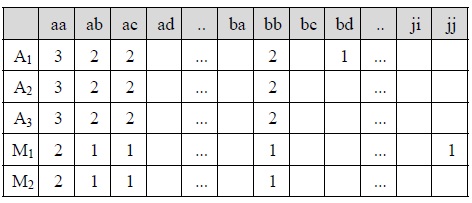
Parent-child vectors for XML documents A1, A2, A3, M1, and M2
A pseudo code of the algorithm for computing the similarity among all the given XML documents is given Fig. 4. The algorithm requires O(n2) for each comparison, where n is the total number of distinct elements of all the given XML documents.
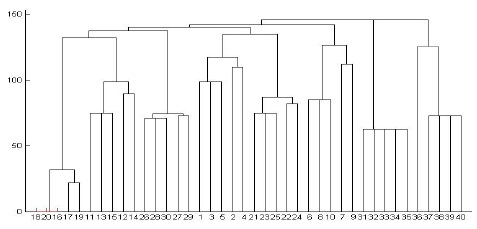
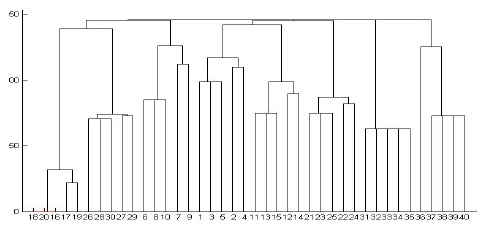
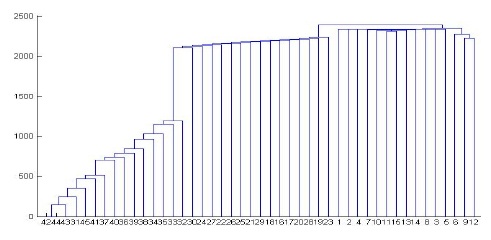
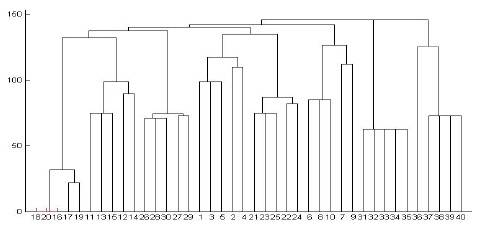
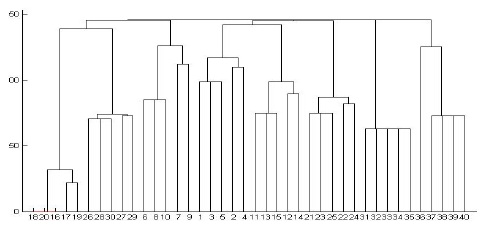
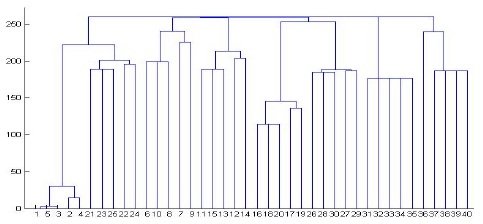
We performed experiments on both synthetic and real data sets. We generated the synthetic data using DTDs of the XML data bank of the University of Wisconsin[18]. This data bank provides 8 DTDs, such as actor, bibliography, club, department, movies, personal information, company profiles, and stock quotes. A parent-child vector for each XML document is used to cluster XML documents. We give a weighted value of 5, 4, 3, 2, and 1 to a node in the first, second, third, fourth, and the remaining levels of an XML tree, respectively. Simple cardinality constraints can be imposed on the elements using regular expression operators ?, +, or * in DTD. As a result, algorithms for comparing XML documents should be aware of such repetitions to effectively assess structural similarity[1,2]. We therefore test our algorithm by controlling the sub-tree repetitions in the XML tree. First, we restrict a special symbol such as ?, +, or * in DTD, which occurs at most one time in the generated XML document. Fig. 5 shows the dendrogram when a single-linkage algorithm is applied. In Fig. 5, the horizontal axis represents the XML documents and the vertical axis represents the dissimilarity measure. We test 40 XML documents generated from 8 DTDs in order to show the result in one diagram. All the XML documents are numbered in order to observe the result easily: Actor (1-5), Bibliography(6-10), Club(11-15), Department (16-20), Movies(21-25), Personal(26-30), Profile (31-35), and Stock(36-40). The diagram illustrates that all the documents are clustered correctly. Department documents are clustered first because they have the greatest number of elements; on the other hand, Actor documents are clustered last because they have the smallest number of elements. The similarities among Profile documents are the same because Profile DTD does not have a special symbol, such as ?, +, or *. Among the eight clusters, Department and Club documents are clustered first because they share many nodes with the same name such as name, phone, email, address, lastname, and firstname. Fig. 6 shows the dendrogram when a complete-linkage algorithm is applied to the same XML documents. Fig. 6 illustrates that all the documents are clustered correctly even though the sequence of the clustering process is different from the case of a single-linkage algorithm.
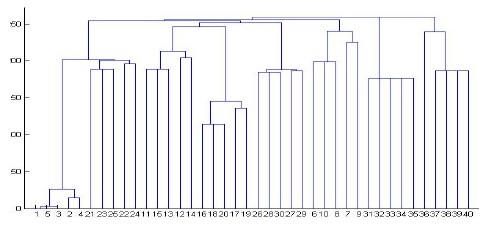
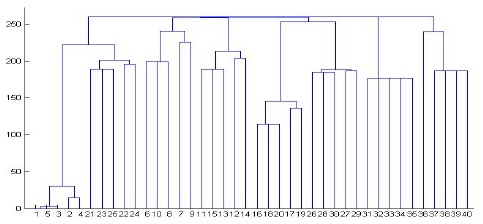
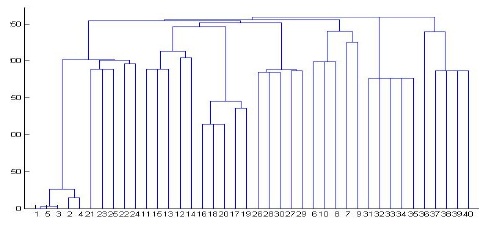
Since Actor documents are clustered last because they have the smallest number of elements, we intentionally allow a special symbol such as ?, +, or * in DTD to occur several times in the generated XML document. As shown in Figs. 7 and 8, Actor documents are clustered first because they have many repetitions of elements, and even sub-tress.
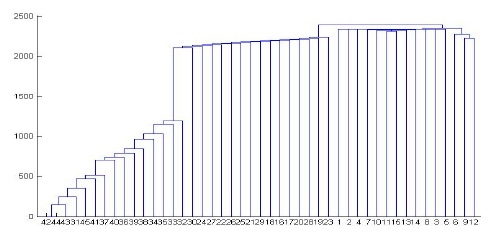
For a real data set, we used XML data obtained from the online XML version of the ACM SIGMOD Record[19]. Specifically, we sampled 15 documents randomly from each of the following DTDs: Index TermsPage.dtd, OrdinaryIssuePage.dtd, and Proceedings Page.dtd. Fig. 9 shows the dendrogram when an average-linkage algorithm is applied.
All the XML documents are numbered in order to observe the result easily: IndexTermsPage(1-15), OrdinaryIssuePage (16-30), and ProceedingsPage(31-45). The diagram illustrates that all the documents are clustered correctly. ProceedingsPage documents are clustered first because they have the greatest number of elements; on the other hand, IndexTermsPage documents are clustered last because they have the smallest number of elements. The similarities among the IndexTermsPage documents or the OrdinaryIssuePage documents are almost the same because their contents and size are almost similar.
An efficient clustering technique is required to process XML documents which are popular on the Internet for their data exchange format. Similar XML documents can easily be found if we can find partially matched sub-trees between the corresponding XML trees. The previous methods to find partially matched sub-trees between XML trees are complex and have an overhead. We therefore propose a parent-child matrix that represents not only a parent-child relationship but also ancestor-descendant relationships between nodes in XML trees. Since a parent-child matrix can find both semantically and structurally matched sub-trees between XML trees easily, it can cluster similar XML documents efficiently. A hierarchical clustering algorithm with a parent-child matrix is used to cluster XML documents. The experiment shows that by our method, clusters are formed correctly and efficiently.