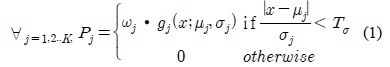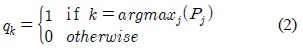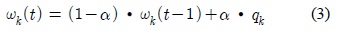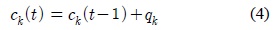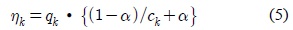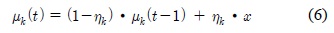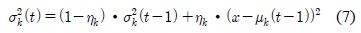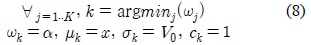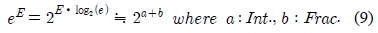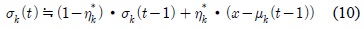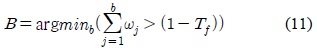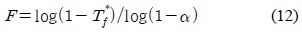영상에서 움직임이 있는 객체 영역을 검출하기 위한 이동 객체 검출(moving object detection; MOD) 알고리듬을 EGML(effective Gaussian mixture learning) 기반 배경 차분 방법을 적용하여 하드웨어로 설계하였다. EGML 계산 일부의 근사화를 통해 하드웨어 복잡도를 줄였으며, 파이프라이닝 적용을 통해 동작속도를 개선하였다. Verilog-HDL을 이용하여 하드웨어를 설계하였으며, MATLAB/Simulink와 FPGA가 연동된 FPGA- in-the-loop 환경에서 하드웨어 동작을 검증하였다. 설계된 MOD 프로세서는 XC5VSX95T FPGA 디바이스에서 2,218 슬라이스로 구현되었으며, 102 MHz의 클록 주파수로 동작하여 102 MS/s의 처리율을 갖는 것으로 평가되었다. IEEE CDW-2012 데이터 세트의 12가지 영상에 대해 MOD 프로세서의 성능을 분석한 결과, 평균 recall 값은 0.7631, 평균 precision 값은 0.7778, 그리고 평균 F-measure 값은 0.7535로 각각 평가되었다.
A hardware implementation of MOD(moving object detection) algorithm using EGML(effective Gaussian mixture learning)- based background subtraction to detect moving objects in video is described. Some approximations of EGML calculations are applied to reduce hardware complexity, and pipelining technique is adopted to improve operating speed. The MOD processor designed in Verilog-HDL has been verified by FPGA-in-the-loop verification using MATLAB/Simulink. The MOD processor has 2,218 slices on the Virtex5-XC5VSX95T FPGA device and its throughput is 102 MSamples/s at 102 MHz clock frequency. Evaluation results of the MOD processor for 12 images in the IEEE CDW-2012 dataset show that the average recall value is 0.7631, the average precision value is 0.7778 and the average F-measure value is 0.7535.
MOD는 카메라로부터 입력받는 영상에서 배경을 제외한 이동 객체 영역을 검출해 내는 기술을 일컫는다. MOD는 영상보안을 비롯한 로봇제어, 엔터테인먼트 등 다양한 분야에 적용될 수 있다. MOD를 위한 다양한 기법들이 존재하지만 주로 차 영상, 배경 차분, 광류 흐름 방법이 적용된다.
이 3가지 접근법 중에 배경 차분 기법은 복잡한 배경을 갖는 영상에서도 우수한 성능을 나타내기 때문에 일반적으로 많이 적용되며[1], 사용되는 배경 학습 알고리듬의 종류에 따라 MOD 정확도, 계산의 복잡도 그리고 메모리 요구량 등이 달라진다[2].
가우시안 혼합 모델(Gaussian mixture model; GMM) 기반의 배경 학습 알고리듬은 입력 영상에 대한 평균, 분산, 가중치를 각 가우시안 별로 계산하여 다중 분포를 갖는 확률 모델을 생성한다. GMM 기반의 MOD 알고리듬은 정확도 측면에서는 우수하게 평가되지만 계산의 복잡성 문제로 인해 실시간 영상처리를 위해서는 고성능 프로세서 환경이 요구되어 비용 및 전력소모 측면에서 효율적이지 않다. 이러한 단점을 극복하기 위해서는 저전력 환경에서도 고성능 계산이 가능하도록 전용 ASIC으로 개발하는 것이 필요하다. MOD의 실시간 영상처리를 위해 GMM을 비롯한 다양한 알고리듬들이 하드웨어로 구현되고 FPGA 환경에서 검증하는 연구들이 활발히 진행되고 있다[3,4].
본 논문에서는 GMM 기반의 EGML 알고리듬[6]을 적용하여 배경을 학습하고 이동 객체를 검출하는 MOD 알고리듬을 Verilog-HDL을 사용하여 하드웨어로 설계하였으며, 설계된 HDL 모델을 MATLAB/Simulink와 FPGA가 연동된 FPGA-in-the-loop 환경에서 하드웨어의 동작을 검증하였다. MOD 성능평가를 위해 IEEE CDW-2012 데이터 세트[5]를 사용하였으며, 타 MOD 알고리듬과 상대적인 성능을 비교하였다. 본 논문은 다음과 같이 구성된다. Ⅱ장에서는 EGML 기반의 MOD 알고리듬에 대한 설명과 효율적인 하드웨어 설계를 위한 EGML 계산 일부의 근사화 적용에 대해 설명하였으며, Ⅲ장에서는 설계된 하드웨어의 구조에 대하여 기술하였다. Ⅳ장에서는 MOD 프로세서의 기능 검증, MOD 성능 평가 그리고 FPGA 합성 결과에 대해 기술하였으며, Ⅴ장에서 결론을 맺는다.
적응적 가우시안 혼합 모델 기반의 배경 학습은 입력화소가 다중 분포 가우시안에 매칭되는 확률을 계산하여 각 가우시안의 파라미터를 갱신한다[7]. 각 가우시안의 파라미터들은 적용되는 학습율 크기에 따라 현재 영상에 대한 학습 비중이 달라진다. 학습율이 클수록 배경 학습의 수렴속도는 빨라지지만 안정도는 낮아지며, 반대로 작은 크기의 학습율을 적용시킬수록 높은 안정도와 느린 수렴속도를 갖는다. 안정도는 잡음 및 이동객체에 의한 영향을 줄여 배경을 안정적으로 학습하는 정도를 나타내며, 수렴속도는 배경의 변화에 빠르게 적응해나가는 정도를 나타낸다.
EGML 알고리듬은 가변 학습율을 적용하여 가우시안의 평균과 분산을 갱신함으로써 빠른 수렴속도와 높은 안정도를 갖도록 개선된 가우시안 혼합 모델 기반의 배경 생성 방법이다. 입력 화소가 최소 하나의 가우시안에 매칭되었을 경우, 가우시안 매칭 확률
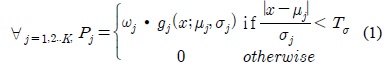
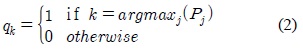
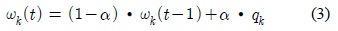
가우시안의 평균
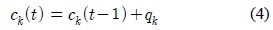
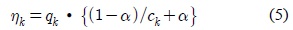
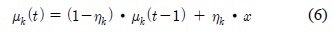
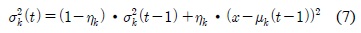
입력 화소값이 어느 가우시안에도 포함되지 않을 경우에는 식 (8)과 같이 가장 작은 가중치를 갖는 가우시안의 파라미터들이 초기화된다. 새롭게 생성되는 가우시안은
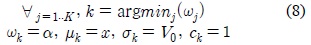
EGML 알고리듬의 하드웨어 구현에 있어서 불필요한 연산을 제거하고 공통적인 연산을 공유하여 연산량을 감소시켰으며, 복잡한 연산의 일부를 단순화시키는 근사화를 통해 회로 복잡도를 줄이고 하드웨어 동작속도를 향상시켰다.
가우시안 함수
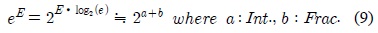
식 (9)의 지수 값
식 (5)에서 (1-
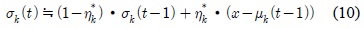
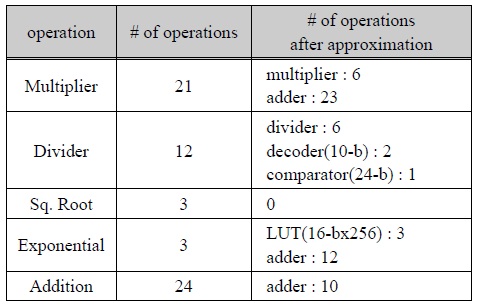
표 1은 EGML 알고리듬에서 요구되는 연산횟수와 본 논문에 적용된 근사화 EGML 알고리듬의 연산 복잡도를 비교한 것이다. 3회의 제곱근 계산이 제거되었으며, 일부의 곱셈과 나눗셈 연산이 가산기 및 기타 회로로 구현되어 전체적인 연산량이 감소되었다. 이를 통해 하드웨어 복잡도가 크게 감소된다.
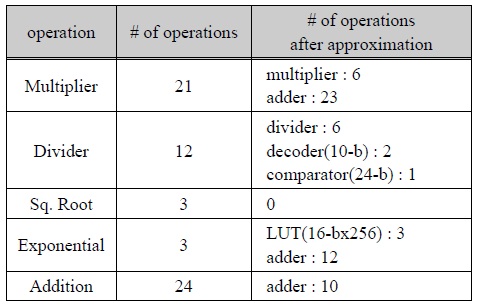
EGML 알고리듬의 연산 복잡도
시스템이 초기화되고 영상이 입력된 후, 최초로 생성 되는 배경 모델은 식 (11)에 의해 결정된다. 여기서
식 (11)과 식 (12)의
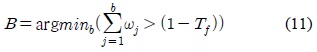
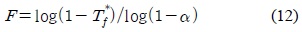
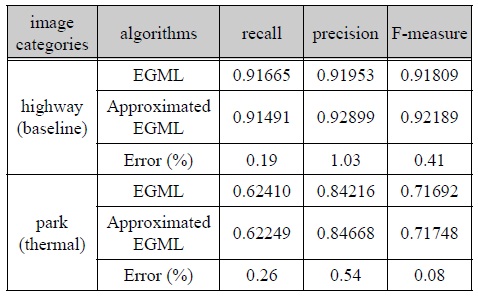
하드웨어 설계에 적용시킬 EGML 알고리듬의 유용성을 판단하기 위해 본래 EGML 알고리듬과 MOD 성능을 비교하였으며, 분석 결과는 표 2와 같다.
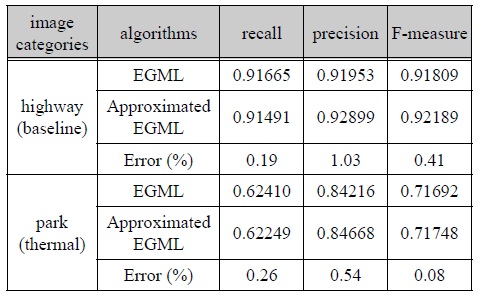
근사화 EGML 알고리듬의 MOD 성능
검증 영상은 IEEE CDW-2012 데이터 세트의 highway, park 영상이며, 두 영상 모두 오차가 약 1% 이내로 측정되어 동일한 성능을 갖는 것으로 간주할 수 있다. 그림 1은 highway, park (thermal) 영상에 대한 EGML 및 근사화 EGML 알고리듬의 MOD 결과 영상이다. 일부 영역에서 미세한 차이가 발생하였으나, 거의 유사한 결과가 얻어졌으며, 따라서 본 논문의 근사화 EGML 알고리듬이 MOD에 효과적으로 적용될 수 있음을 확인하였다. recall은 참 영상(ground truth)의 이동 객체 화소에 대한 검지율을 나타내며, precision은 이동 객체 화소로 판단된 화소 중에 올바르게 검지된 정확도를 나타낸다. F-measure는 recall 및 precision이 포함된 지표이며, 우수한 성능을 가질수록 세 가지 모두 ‘1’로 가까워진다.
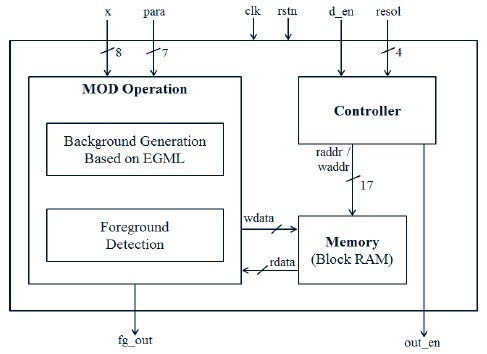
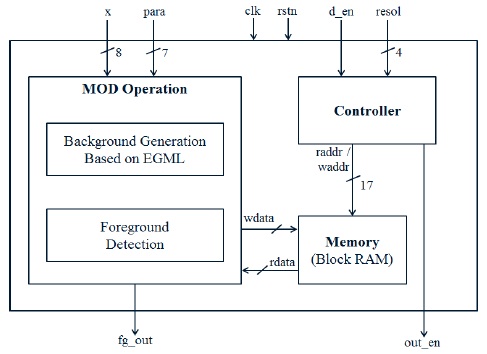
설계된 MOD 프로세서는 그림 2와 같이 MOD 연산부, 제어부, 메모리로 구성된다. MOD 연산 모듈은 8-비트 그레이 스케일(gray-scale)의 영상 데이터와 설정될 파라미터의 정보를 입력받으며, 해당 화소의 MOD 결과를 출력한다. 제어부는 파이프라이닝 적용에 따른 메모리 읽기/쓰기 타이밍을 제어하며, MOD 결과 출력 타이밍에 맞도록 출력 인에이블 신호를 생성한다. 또한 해상도 정보를 입력받아 각 프레임의 동일 위치 화소별 연산이 올바르게 되도록 제어한다. 가우시안 파라미터 저장을 위해 FPGA 내부의 Block RAM을 사용하였다.
Virtex-5 XC5VSX95T FPGA에서 최대 240x180 해상도 영상을 지원할 수 있으며, Virtex-6 XC6VSX475T 디바이스에서는480x320의 영상을 지원할 수 있다.
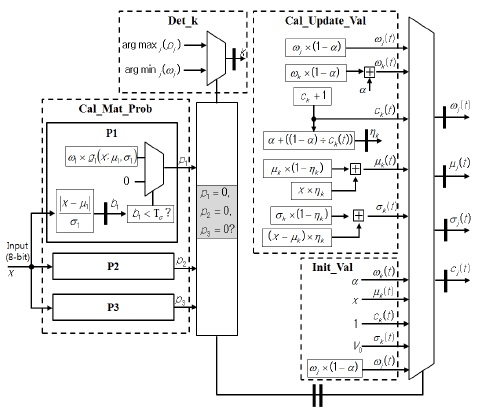
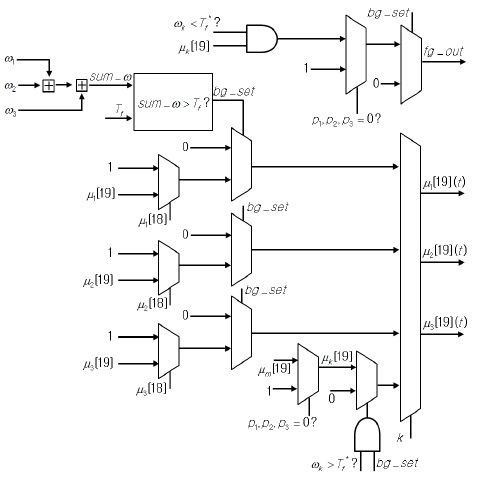
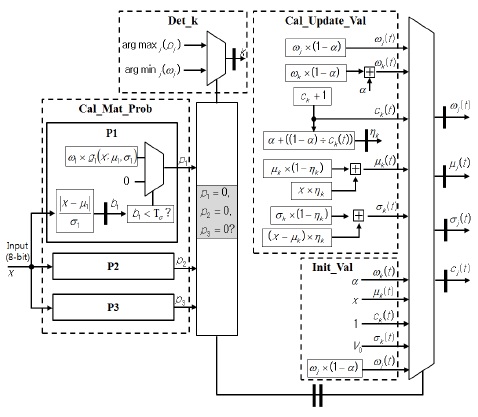
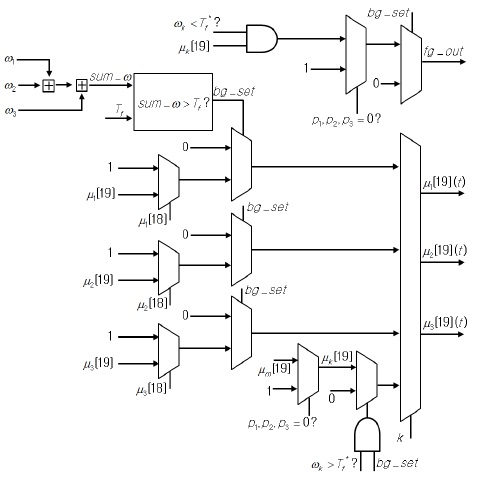
MOD 연산부는 근사화 EGML 알고리듬 기반의 배경 생성 블록 그리고 전경과 배경을 분류하는 객체 검출 블록으로 구성된다. 배경 생성 블록은 그림 3과 같은 구조로 구현되었으며, 식 (1)에 의해 가우시안 매칭 확률
그림 3의 Cal_Mat_Prob 블록에서 세 개의 가우시안의 매칭 확률
배경 생성 블록의 입력부터 최종 출력까지 곱셈기, 나눗셈기, 가산기 등을 거치며 매우 큰 지연을 갖게 되어 파이프라이닝을 적용하지 않을 경우에 동작 주파수는 10 MHz 이하가 될 것으로 예측되었다. 본 논문에서는 회로의 동작 주파수를 높이기 위해 배경 생성 블록이 총 13 단계의 파이프라이닝으로 동작하도록 회로를 설계하였다. 특별히 내부 연산회로들 중 critical path를 갖는 16-비트 나눗셈기 내부에는 3단계 파이프라인을 삽입하여 전체적인 동작 속도를 최적화하였다.
객체 검출 블록은 입력 화소에 대해 전경 및 배경으로 분류하는 기능과 함께 각 가우시안이 배경 모델에 속하는지 판단한다. 최초의 배경 생성 모델과 추가로 생성되는 배경 모델을 결정하기 위해 식 (11)과 식 (12)가 적용되며, 입력 화소가 특정 가우시안에 매칭되면 해당 화소는 배경으로 분류되고, 그렇지 않으면 전경으로 분류된다. 입력 화소가 어느 가우시안에도 매칭되지 않을 경우에도 전경으로 분류된다. 이와 같은 기능을 수행하는 객체 검출 블록의 구조는 그림 4와 같다.
가우시안의 평균 값
그 후, 입력 화소가 매칭된 가우시안이
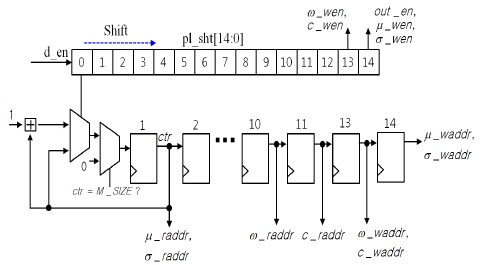
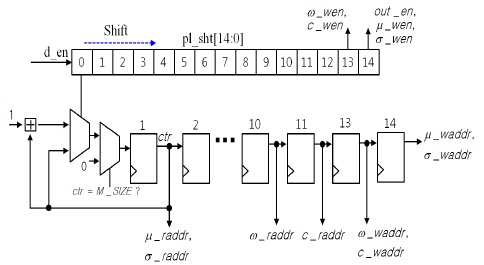
제어부는 메모리의 읽기/쓰기 그리고 출력 인에이블 신호의 타이밍을 제어하며, 설정된 해상도에 맞추어 메모리 주소 값을 연산한다. 4가지 가우시안 파라미터의 읽기/쓰기를 위해 8가지 주소 값이 존재하며, 모든 주소값을 개별적으로 계산할 경우 8개의 카운터 회로가 필요하다. 그러나 설계된 알고리듬의 특성상 모든 주소값들이 일정한 클록 수 간격 차이로 동일한 값을 가지므로 하나의 계수기와 13개의 레지스터로 모든 주소 값을 얻을 수 있다. 이와 같은 동작 특성을 고려하여 설계된 제어부의 구조는 그림 5와 같다.
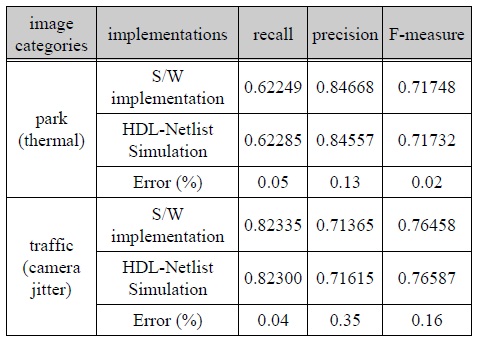
Verilog-HDL로 설계된 MOD 프로세서는 Xilinx ISE 시뮬레이터와, MATLAB/Simulink의 HDL-Netlist 시뮬레이션을 통해 설계된 회로의 기능 검증과 MOD성능을 분석하였다. 하드웨어의 올바른 설계 유무를 판단하기 위해 하드웨어 구현의 MOD 결과와 소프트웨어 모델링의 MOD 결과를 비교하였으며, 분석 결과는 표 3과 같다. park 영상은 열 감지 카메라의 영상으로 thermal 범주에 속하며, traffic 영상은 카메라의 흔들림이 있는 camera jitter 범주에 속한다. 두 영상에 대한 MOD 결과를 recall, precision, F-measure 대하여 비교한 결과 약 99.6% 이상의 일치율을 보이므로, 거의 완전히 동일한 성능을 갖는 것으로 측정되어 하드웨어가 정상적으로 설계되었음을 확인하였다.
[표 3.] 하드웨어 구현과 소프트웨어 구현의 MOD 성능 비교
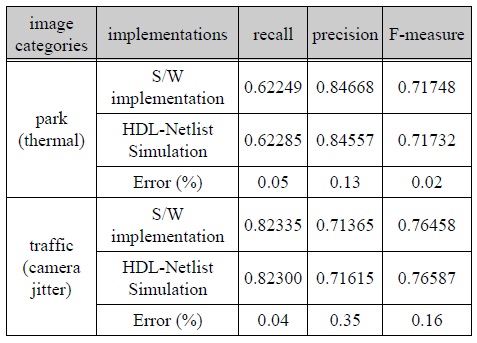
하드웨어 구현과 소프트웨어 구현의 MOD 성능 비교
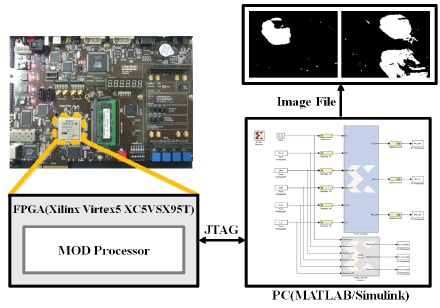
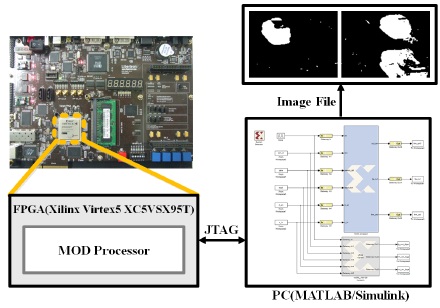
설계된 MOD 프로세서의 하드웨어 동작 검증을 위해 그림 6과 같이 USB JTAG 통신으로 PC와 FPGA가 연결된 FPGA-in-the-loop 환경을 구성하였으며, 사용된 FPGA 디바이스는 Virtex-5 XC5VSX95T 이다. FPGA에서 출력된 MOD 결과와 HDL-Netlist 시뮬레이션에 대한 기능 검증의 MOD 결과와 비교하여 FPGA 구현 결과의 이상 유무를 판단하였다. 기능 검증 결과, 단 하나의 데이터도 어긋나지 않고 100% 일치함으로써 FPGA 환경에서 하드웨어가 정상으로 동작함을 확인하였다. 그림 7은 PETS2006 영상에 대한 FPGA 검증과 기능 검증의 MOD 결과를 비교한 것이며, 두 결과가 완전히 일치함을 확인할 수 있다.
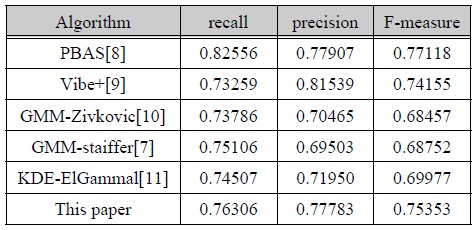
본 논문에 적용된 EGML 알고리듬 기반의 MOD 결과와 타 알고리듬의 MOD 결과에 대해 상대적인 성능을 비교하였다. 비교 대상의 알고리듬은 IEEE CDW-2012에서 평가된 5가지 알고리듬이다. 5가지 알고리듬 가운데 PBAS[8], Vibe+[9]는 성능이 상대적으로 우수하게 평가된 알고리듬이며, GMM-Stauffer[7], GMMZivkovic[10]는 EGML 알고리듬과 유사한 GMM 기반의 MOD 알고리듬에 해당된다. 그리고 또 다른 하나는 커널 분포 추정[11] 기반의 MOD 알고리듬이다. CDW-2012 데이터 세트의 각 범주별 2가지, 총 12가지 검증영상에 대한 성능 비교 결과는 표 4와 같으며, 12가지 영상에 대한 평균을 나타낸다.
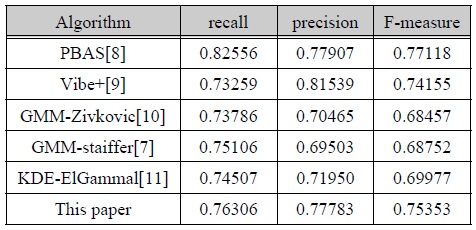
MOD 알고리듬의 성능 비교
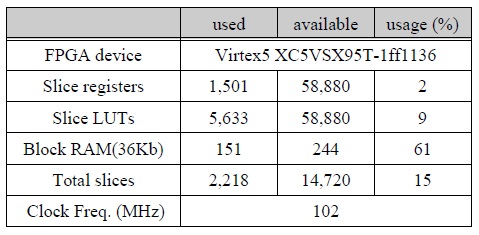
recall의 측면에서는 PBAS 알고리듬이 가장 우수한 성능을 가지며, precision 측면에서는 Vibe+ 알고리듬이 가장 우수한 성능을 갖는다. 본 논문의 근사화 EGML MOD 결과는 GMM 기반의 MOD 알고리듬 보다 전반적으로 높은 recall, precision, F-measure 값을 갖는 것으로 평가되었으며, F-measure 값은 6개의 알고리듬 중 2번째로 높게 평가되었다. 표 4의 MOD 성능은 IEEE CDW-2012의 12가지 영상에 대한 결과로서 모든 영상을 검증한 것은 아니지만 IEEE CDW-2012에서 확인되는 평가 결과와 비슷한 양상을 보이기 때문에 의미있는 결과로 간주할 수 있다. 그림 8은 dining room 영상에 대해 MOD 알고리듬 종류에 따른 MOD 결과 영상을 비교한 것이다. 설계된 MOD 프로세서의 FPGA 합성 결과는 표 5와 같이 XC5VSX95T FPGA디바이스에서 2,218 슬라이스로 구현되었으며, 동작 속도는 102 MHz로 측정되어 102 MS/s의 처리율을 갖는 것으로 평가되었다. 외부 메모리를 사용할 경우 HD 해상도의 입력을 약 100 fps 까지 처리할 수 있는 성능을 갖는다.
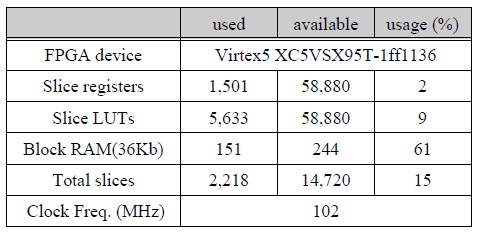
FPGA 합성 결과
본 논문에서는 입력 영상에서 이동 객체 영역을 검출하기 위한 MOD 프로세서를 Verilog-HDL을 사용하여 설계하였다. 설계된 회로는 Xilinx ISE 및 MATLAB 환경에서 기능 검증이 이루어졌으며, MATLAB/Simulink와 FPGA가 연동된 FPGA-in-the-loop 방식을 이용하여 하드웨어 동작을 검증하였다. XC5VSX95T FPGA로 합성한 결과 2,218 슬라이스가 사용되었고 102 MHz의 최대 동작주파수를 갖도록 구현되었다. 설계된 MOD 프로세서는 실시간 감시시스템을 포함한 다양한 움직인 추정 응용 시스템에 사용할 수 있을 것이다.