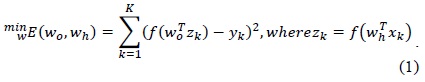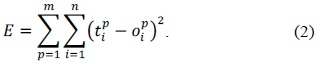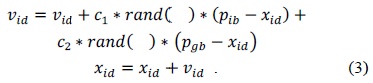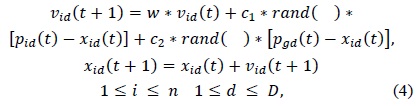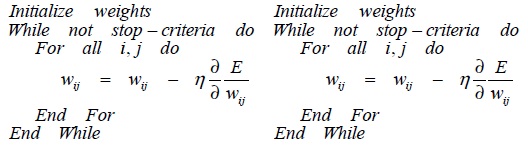Artificial neural networks (ANNs) are nonlinear mapping structures based on the function of the human brain. They are powerful tools for modeling, particularly because the underlying data relationship is unknown. The key element of this paradigm is the novel structure of the information processing system. It is composed of a large number of highly interconnected processing elements (neurons) working in unison to solve specific problems. An ANN is configured for a specific application, through a learning process. Learning in a biological system involves adjustment to the synaptic connections that exist between the neurons. ANNs can identify and learn the correlated patterns between input datasets and the corresponding target values. After training, ANNs can be used to predict the input data. ANNs imitate the learning process of the human brain and can process problems involving nonlinear and complex data even if the data are imprecise and noisy. Thus, they are ideal for the modeling of complex and often nonlinear data. ANNs have great capacity for predictive modeling; i.e., all the characters describing the unknown situation can be presented to the trained ANNs, and then, the prediction of systems is guaranteed. ANNs are capable of performing many classification, learning, and function approximation tasks, yet in practice, they sometimes deliver only marginal performance. Inappropriate topology selection and weight training are frequently blamed for this. Neural networks are adjusted, or trained, such that a particular input leads to a specific target output. The ANN weights are adjusted on the basis of a comparison of the output and the target, until the network output matches the target. Typically, many such input/target pairs are needed to train a network. Increasing the number of hidden layer neurons helps to improve the network performance, yet many problems can be solved with very few neurons if only the network takes its optimal configuration. Unfortunately, the inherent nonlinearity of an ANN [1] results in the existence of many suboptimal networks, and a considerable majority of training algorithms converge to these suboptimal configurations. The problem of multiple local minima in neural networks has been widely addressed. The proposed solutions include multiple starts from randomly chosen initial points, simulated annealing, random perturbation, diffusion techniques, and evolutionary computing. Most of these methods are probabilistic in nature: They can find the globally optimal solution with a certain probability, which depends on the number of iterations of the algorithm. In this study, an ANN is trained using the proposed hybrid approach. The rest of this paper is organized as follows: Section II presents a brief introduction to different existing ANN learning algorithms with their pros and cons. The proposed hybrid DPSO-BP approach is introduced in Section III. Simulation results and comparisons are provided in Section IV to demonstrate the effectiveness and potential of the proposed hybrid algorithm. Finally, several conclusions are presented in Section V.
II. NEURAL NETWORK LEARNING ALGORITHMS
Training neural networks is a complex task of great importance in the field of supervised learning. ANNs have been shown to have the potential to perform well for classification problems in many different environments, including business, science, and engineering. A majority of the studies on this topic rely on a gradient algorithm, typically a variation of backpropagation (BP), to obtain the weights of the model. Various learning techniques are introduced to optimize the weights of an ANN. Although the limitations of gradient search techniques applied to complex nonlinear optimization problems, such as the ANN, are well known, many researchers still choose to use these methods for network optimization. ANNs can identify and learn the correlated patterns between input datasets and the corresponding target values. After training, ANNs can be used to predict input data. ANNs imitate the learning process of the human brain and can process problems involving nonlinear and complex data even if the data are imprecise and noisy. Different learning algorithms are described below.
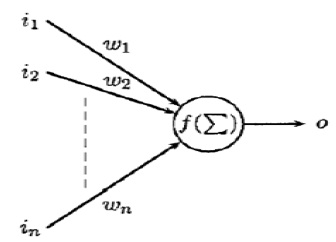
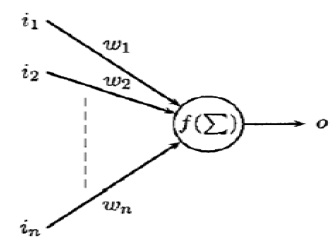
In an ANN, activation functions of the output units become differentiable functions of the input variables and of the weights and biases, as shown in Fig. 1. If we define an error function (
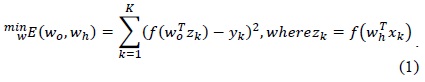
Here,
The BP algorithm is a classical domain-dependent technique for supervised training. It works by measuring the output error, calculating the gradient of this error, and adjusting the ANN weights [4] (and biases) in the descending gradient direction.
Hence, BPP is a gradient descent local search procedure (expected to stagnate in the local optima in complex landscapes). The squared error of the ANN [5] for a sset of patterns is calculated using Eq. (2).
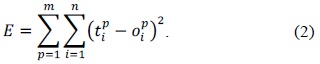
The actual value of the previous expression depends on the weights of the network. The basic BP algorithm calculates the gradient of
>
B. Particle Swarm Optimization Algorithm
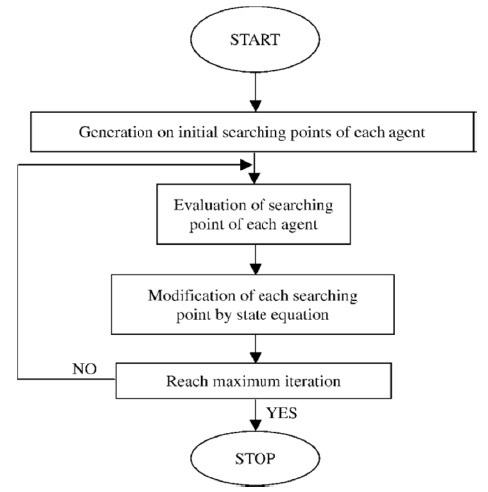
The particle swarm optimization (PSO) algorithm was first introduced by Kennedy and Eberhart [6]. Instead of using evolutionary operators to manipulate the individuals, as in the case of other evolutionary computational algorithms, each individual in the PSO flies in the search space with a velocity that is dynamically adjusted according to its own flying experience and its companions' flying experience. Each individua is treated as a volume-less particle (a point) in the D-dimensional search space. The
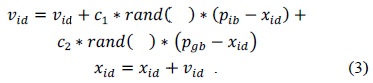
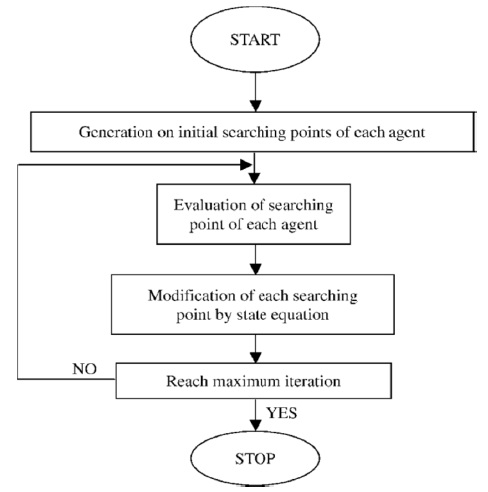
The algorithm can be summarized as follows (in Fig. 3):
PSO-BP is an optimization algorithm combining PSO with BP [7,8].The PSO algorithm [9] is a global algorithm that has a strong ability to find the global optimistic result. However, this algorithm has a disadvantage that the search around the global optimum is very slow. In contrast, the BP algorithm has a strong ability to find the local optimistic result, but its ability to find the global optimistic result is weak. The fundamental idea for this hybrid algorithm is that at the beginning stage of searching for the optimum, PSO [10] is employed to accelerate the training speed. When the fitness function value has not changed for some generations, or the change in value is smaller than a predefined number, the search process is switched to the gradient descent search according to this heuristic knowledge. The PSO-BP [11] algorithm’s search process also starts by initializing a group of random particles. First, all the particles are updated according to Eq. (4).
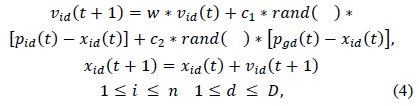
where
The procedure for this PSO-BP algorithm can be summarized as follows:
This algorithm has a parameter called the learning rate [13] that controls the convergence of the algorithm to an optimal local solution; however, obtaining a good value for this parameter is difficult.
III. PROPOSED ALGORITHM (DYNAMIC PSO-BP)
PSO combined with BP gives good result in learning but due to some cons of basic PSO, we modified it with some dynamic constraints where during the learning process of the ANN objective space can be compressed or expanded. In PSO, each particle should be kept in a confined space corresponding to the parameter limitations. This decreases the diversity of the particle. If the global best particle does not change its
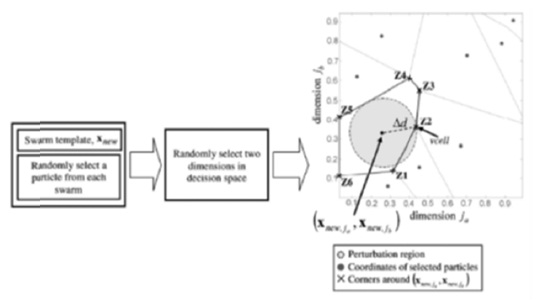
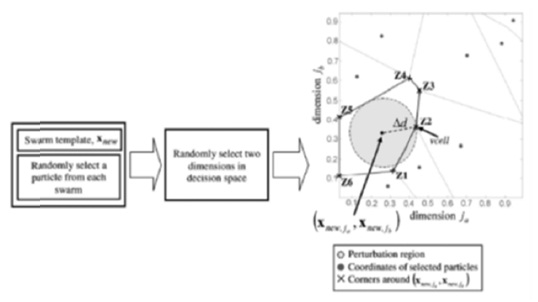
To overcome such limitations, a multiple-swarm PSO algorithm called dynamic multiple swarms in PSO is proposed in which the number of swarms is adaptively adjusted throughout the search process via d dynamic swarm strategy. The strategy allocates an appropriate number of swarms required to support the convergence and diversity criteria among the swarms. The main objective of this is to develop a multiple-swarm PSO that eliminates the need to estimate an initial number of swarms to improve the computational efficiency without compromising the performance of the algorithm. Once the swarm template (
In DPSO adding and removing the swarms throughout the search process will directly affect the swarm population distribution. Instead of applying the Pareto ranking method to update the Pareto rank of the particles and applying a niching strategy to estimate the density of the particles when the swarm population progresses at every iteration.
In the DPSO-BP algorithm, to know when the search process is transited from the particle swarm search to the gradient descent search, a heuristic way was introduced.
That is, when the best fitness value in the history of all particles does not change for some generations (i.e., ten generations), the search process is transferred to the gradient descent search. When the best fitness does not change for some generations, all the particles may lose the ability to find a better solution; at this time, a gradient descent search can be used to obtain better results. If the rank values of a current swarm and its recorded swarm leader have the same rank value, then the pure Pareto ranking method is applied to both the swarm leaders. If the current swarm dominates the recorded swarm leader, then the current one will replace the recorded one. If both do not dominate each other, one of them is randomly chosen to update the local best archive of swarms. The new velocity and position are given in Eq. (5).
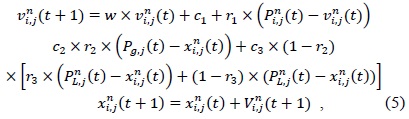
where is the
IV. EXPERIMENTAL RESULT AND DISCUSSION
We choose two different datasets of small and large dimensions for the experiment. It is assumed that the proposed hybrid learning algorithm works in both these environments. The datasets are the e-learning dataset (number of patterns = 90) and the thyroid dataset (number of patterns = 7,200).
>
B. Results and Algorithm Settings
In the following experiments, two datasets are chosen for comparing the performances of the BP, PSO, PSO-BP, and DPSO-BP algorithms in evolving the weights of the ANN. Suppose that every weight in the network was initially set in the range of [-50,50], and all thresholds in the network were 0 s. Further, suppose that every initial particle was a set of weights generated at random in the range of [0,1]. Let the initial inertial weight w be 1.8, the acceleration constants, both
Algorithms for training ANNs were compared. Tests were conducted on gradient descent algorithms such as BP, and population-based heuristics such as PSO. Experimental results showed that DPSO–BP outperformed all other algorithms in training neural networks. In this study, the DPSO–BP algorithm, which is a new, simple, and robust optimization algorithm, was used to train the standard and e-learning datasets for classification purposes. Training procedures involved the selection of the optimal values of the parameters, such as the weights between the hidden layer and the output layer, spread parameters of the hidden layer base function, center vectors of the hidden layer, and bias parameters of the neurons of the output layer.
PSO and PSO-BP algorithms showed better performance than derivative-based methods; however, these algorithms had the disadvantage of a slow convergence rate. Trapping a local minimum was a disadvantage for these algorithms. When the learning performances were compared, experimental results showed that the performance of the proposed algorithm was better than that of the others.
The success of the classification results of the test problems was superior and correlated with the results of many research [9,10,12]. In real-time applications, the number of neurons might affect the time complexity of the system. The results of the e-learning classification problem were reasonable and might help training algorithms in other e-learning applications.
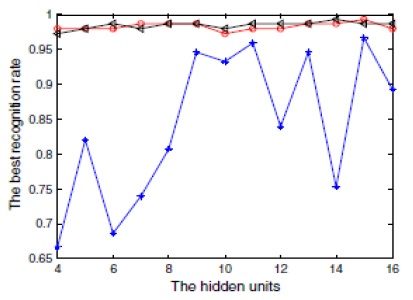
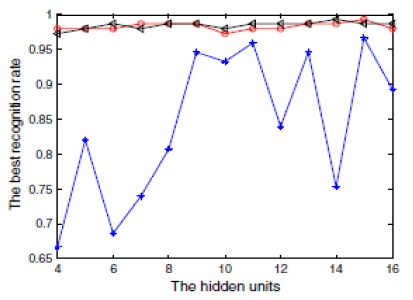
Fig. 5 shows the recognition rate of different algorithms while training an ANN in the thyroid dataset. Here, the red line denotes the proposed algorithm, while the blue and black lines denote the results of PSO and PSO-BP, respectively. It can be inferred from Fig. 5 that PSO-BP has a better recognition rate than PSO. Apparently, the PSO algorithm has a very low recognition rate while learning the ANN, but when it is combined with the BP algorithm, the mean recognition rate increases, as shown in Fig. 5. However, the proposed algorithm again increases the rate of recognition due to its dynamic nature. This shows that the DPSO-BP algorithm is more stable, while in the training process, the DPSO-BP algorithm uses less CPU time than the PSO-BP algorithm and the PSO algorithm.
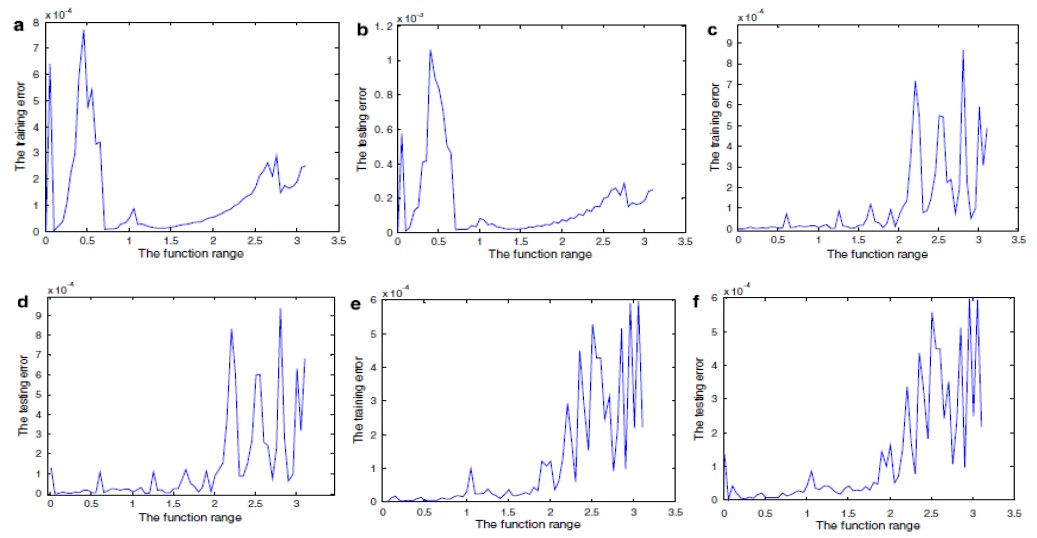
Fig. 6 illustrates the curves of the training errors and the testing errors for the three training algorithms using the elearning dataset. Fig. 6(a), (c), and (e) show the training error curves of the PSO, PSO-BP, and DPSO-BPA algorithms, respectively. Fig. 6(b), (d), and (f) illustrate the testing error curves of the PSO, PSO-BP, and DPSO-BPA algorithms, respectively. When the value of
In this paper, a hybrid DPSO-BP algorithm is proposed, which combines the PSO algorithm’s strong ability of global learning and the BP algorithm’s strong ability of local learning. Hence, we can obtain better training results by using this hybrid algorithm. Some heuristic knowledge is adapted to transit from the DPSO algorithm search to the BP algorithm search. That is, when the best fitness value in the history of all particles does not change for some generations (i.e., ten generations), the search process is transferred to the gradient descent search. The heuristic way is used to avoid wasting too much CPU time on a vain search (as used in the other compared algorithms); therefore, the training efficiency of the DPSO-BP algorithm is improved considerably. A different selection strategy is introduced for updating the inertial weight w. In the initial searching stage, the searching inertial weight is reduced rapidly in order to rapidly achieve the global optima. Then, around the global optimum, we reduce the inertial weight more smoothly by using BP so that a higher accuracy can be achieved.
From the conducted experiments, we conclude that for the same goal, the DPSO-BP algorithm uses less CPU time and provides higher training accuracy than the PSO algorithm and the BP algorithm. A comparative study shows that the performance of the variant is competitive in comparison with the selected algorithms on standard benchmark problems. It is concluded that the DPSO-BP algorithm is more stable than the BP algorithm and the PSO algorithm. In future research works, we shall focus on how to apply this hybrid PSO algorithm to solve more practical problems.