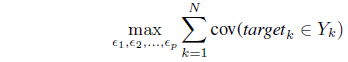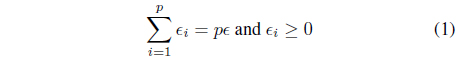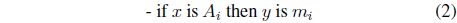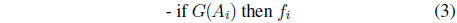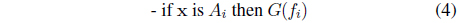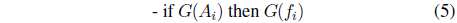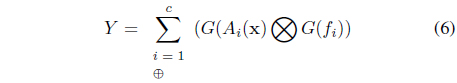In this study, we pursue a new direction for system modeling by introducing the concept of granular models, which produce results in the form of information granules (such as intervals, fuzzy sets, and rough sets). We present a rationale and several key motivating arguments behind the use of granular models and discuss their underlying design processes. The development of the granular model includes optimal allocation of information granularity through optimizing the criteria of coverage and specificity. The emergence and construction of granular models of type-2 and type-n (in general) is discussed. It is shown that achieving a suitable coverage-specificity tradeoff (compromise) is essential for developing granular models.
It is apparent that there are no ideal models. Numerical data are not ideally captured (i.e., captured without any error) by any model, irrespective of the model’s complexity. Informed by the principle of Ockahm’s razor, we strive to build simple models and establish a balance between the requirements of accuracy and simplicity. In spite of the diversity of the architecture of models (especially those emerging in the realm of computational intelligence), many challenges remain. An interesting, innovative, and promising direction is to conceptualize and build models at a higher level of abstraction; in this manner, the models become capable of better coping with the system to be modeled. These models can be constructed in terms of information granules; in what follows, these are referred to as granular models. Information granules are formalized in various settings such as sets (intervals), fuzzy sets, and rough sets. Depending on the nature of the model, we can talk about granular neural networks, granular regression models, etc.
The objective of this study is to conceptualize information granularity as an essential design asset in system modeling, which, when used properly, can make the model match the complexity of the problem (system) and gives rise to a hierarchy of granular models (models of type-1, type-2, etc.) to cope with the complexity of the system under discussion.
The remainder of this paper is organized as follows. To make the material self-contained, we start with a brief summary of granular computing (Section 2). In Sections 3 and 4, we develop a characterization of information granules, discussing their two important characterizations, namely, coverage abilities (related to the generalization facet of information granules) and specificity description. We also identify their complementary nature, which must be dealt with at the modeling level. The concept of granular models is studied in Section 5; here, we consider the idea of creating granular parameters of the original numeric model, demonstrating how they give rise to granular results. The detailed protocols for determining the granular parameters of the models are covered in Section 6. Then, a detailed example of rule-based architectures is considered to demonstrate how the parameters of the model are realized in the form of information granules (Section 7). Section 8 is devoted to the realization of the hierarchy of granular models, resulting in type-2 granular models and (in general) type-
2. Selected prerequisites: Granular computing
To provide a better idea of this study and to make it self-contained, we present a concise introduction to granular computing, which is a formal conceptual framework for data analysis and modeling tasks.
Information granules are intuitively appealing constructs that play a pivotal role in human cognition and decision-making. We perceive complex phenomena by reconciling existing knowledge with available experimental evidence and structuring them in the form of meaningful, semantically sound entities; these entities are central to all ensuing processes for describing the world, reasoning about the environment, and supporting decision-making. The term information granularity has emerged in different contexts and has numerous areas of application, and therefore, carries various meanings. In artificial intelligence, information granularity is central to problem solving through problem decomposition, in which various subtasks are formed and solved individually. In general, an information granule is a collection of elements drawn together by their closeness (resemblance, proximity, functionality, etc.), articulated in terms of some useful spatial, temporal, or functional relationship. Granular computing considers representing, constructing, and processing such information granules.
We can refer here to some areas that offer compelling evidence as to the nature of underlying processing and interpretation in which information granules play a pivotal role:
image processing, processing and interpretation of time series, granulation of time, and design of software systems. Information granules are abstractions. As such, they naturally give rise to hierarchical structures: the same problem or system can be examined at different levels of specificity (detail) depending on the complexity of the problem, available computing resources, and particular goals to be addressed. The hierarchy of information granules is inherently visible when processing information granules. The level of detail (which is represented by the size of information granules) becomes an essential part of the hierarchical processing of information, where different levels of the hierarchy are indexed by the size of information granules.
Even the commonly encountered simple examples presented above indicate that (a) information granules are a key component of knowledge representation and processing; (b) the level of granularity of information granules (their size) becomes crucial to the problem description and the overall problem-solving strategy; (c) the hierarchy of information granules is an important aspect of the perception of phenomena and offers a tangible method of dealing with complexity, namely, by focusing on the most essential facets of the problem; and (d) there is no universal level of granularity for information; essentially, the size of granules becomes problem-oriented and user-dependent.
There are several well-known formal settings in which information granules can be defined and processed.
3. Information granules: coverage and specificity characterization
From the perspective of this study, there are two important and directly applicable characterizations of information granules, namely coverage and specificity [9-11].
The realizations of the definitions can be augmented by some parameters that contributes to their flexibility. It is also intuitively apparent that these two characteristics are associated: the increase in one of then implies a decrease in another: an information granule that “covers” a lot of data cannot be overly specific and vice versa.
4. Information granules of higher type
By information granules of
5. An emergence of granular models: structural developments
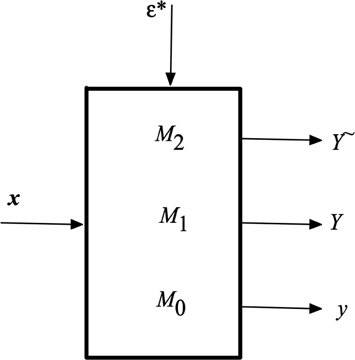
The concept of the granular models form a generalization of numeric models no matter what their architecture and a way of their construction are. In this sense, the conceptualization offered here are of general nature. They also hold for any formalism of information granules. A numeric model
- granulation of parameters of the model A = G(a) where G stands for the mechanisms of forming information granules, viz. building an information granule around the numeric parameter - result of the granular model for any x producing the corresponding information granule Y, Y= M1(x, A) = G(M0(x))= M0(x, G(a)).
Information granulation is regarded as an essential design asset. By making the results of the model granular (and more abstract in this manner), we realize a better alignment of
The design asset is supplied in the form of a certain allowable level of information granularity e which is a certain non-negative parameter being provided in advance. We allocate (distribute) the design asset across the parameters of the model so that the coverage measure is maximized while the overall level of information granularity serves as a constraint to be satisfied when allocating information granularity across the model, namely . The constraint-based optimization problem reads as follows
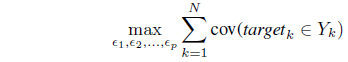
subject to
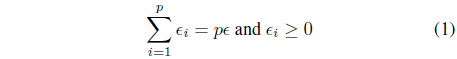
The solution to the problem can be produced by invoking one of the protocols outlined in Section 6.
The monotonicity property of the coverage measure is apparent: the higher the values of e, the higher the resulting coverage. Hence the coverage is a non-decreasing function of e.
Along with the coverage criterion, one can also consider the specificity of the produced information granules. It is a non-increasing function of e. The more general form of the optimization problem can be established by engaging the two criteria leading to the two-objective optimization problem
- determine optimal allocation of information granularity [ϵ1, ϵ2, . . . , ϵp]so that the coverage and specificity criteria become maximized.
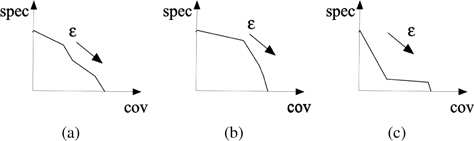
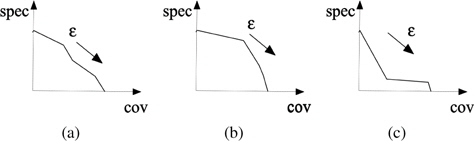
Plotting these two characteristics in the coverage –specificity coordinates offers a useful visual display of the nature of the granular model and possible behavior of the behavior of the granular model as well as the original model. Several illustrative plots shown in Figure 1 illustrate typical changes in the specificity/coverage when changing the values of information granularity e. One can consider those coming as a result of the maximization of coverage while reporting also the obtained values of the specificity. There are different patterns of the changes between coverage and specificity. The curve may exhibit a monotonic change with regard to the changes in e and could be approximated by some linear function. There might be some regions of some slow changes of the specificity with the increase of coverage with some points at which there is a substantial drop of the specificity values. A careful inspection of these characteristics helps determine a suitable value of e – any further increase beyond this limit might not be beneficial as no significant gain of coverage is observed however the drop in the specificity compromises the quality of the granular model. Furthermore Figure 1 highlights an identification of suitable values of the level of information granularity. The global behavior of the granular model can be assessed in a global fashion by computing an area under curve (AUC) of the coverage-specificity curve present in Figure 1. Obviously, the higher the AUC value, the better the granular model. The AUC value can be treated as an indicator of the global performance of the original numeric model produced when assessing granular constructs built on their basis. For instance, the quality of the original numeric models
As to the allocation of information granularity, the maximized coverage can be realized with regard to various alternatives as far as the data are concerned: (a) the use of the same training data as originally used in the construction of the model, (b) use the testing data, and (c) usage of some auxiliary data.
6. Protocols of optimal allocation of information granularity
The numeric parameters of the model are to be made granular. In what follows, to illustrate the idea, we consider interval information granules spanned over the numeric values. The allocation of information granularity can be realized in many different ways by engaging various levels of sophistication. The series of protocols presented below is organized with the increasing level of flexibility each of them supporting a better usage of information granularity:
P1: uniform allocation of information granularity. This protocol is the simplest one. It does not invoke any optimization mechanism. All numeric values of the parameters are treated in the same way and become replaced by intervals of the same length. Furthermore the intervals are distributed symmetrically around the original values of the parameters.
P2: uniform allocation of information granularity with asymmetric position of intervals around the numeric parameter. Here we encounter some level of flexibility: even though the intervals are of the same length, their asymmetric localization brings a certain level of flexibility, which could be taken advantage of during the optimization process. More specifically, we allocate the intervals of lengths
P3: non-uniform allocation of information granularity with symmetrically distributed intervals of information granules. Each parameter of the model is endowed with the individual level of information granularity
P4: non-uniform allocation of information granularity with asymmetrically distributed intervals of information granules. Among all the protocols discussed so far, this one exhibits the highest level of flexibility.
P5: An interesting point of reference, which is helpful in assessing a relative performance of the above methods, is to consider a random allocation of granularity. By doing this, one can quantify how the optimized and carefully thought out process of granularity allocation is superior over a purely random allocation process.
While the allocation of information granularity realized above through a collection of protocols offers several main strategies, some of the implementation details are dependent on the nature of the model. For instance if all parameters of the model are in the same range, say [0,1] (as encountered in fuzzy neural networks operating logic operators) then the intervals around the numeric parameter
P1 [
P2 [
P3 [
In case the parameters of the model are localized in different ranges, the realization of the intervals involves the magnitude of the parameters, say for P1
[
7. Rule-based models ? schemes of allocation of information granularity
These functional rules (Takagi-Sugeno format of the conditional statements) link any input space with the corresponding local model whose relevance is confided to the region of the input space determined by the fuzzy set standing in the input space (
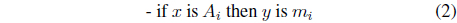
These models are then equivalent to those produced by the Mamdani-like rules with a weighted scheme of decoding (defuzzification). There hs been a plethora of design approaches to the construction of rule-based models, cf. [1-3, 6-8, 18, 19].
Information granularity emerges in fuzzy models in several ways by being present in the condition parts of the rules, their conclusion parts and both. In a concise way, we can describe this in the following way (below the symbol
(i)
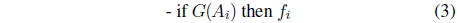
where
(ii)
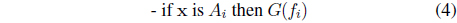
with
(iii)
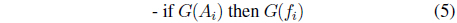
The augmented expression for the computations of the output of the model generalizes the expression used in the description of the fuzzy models (3). We have
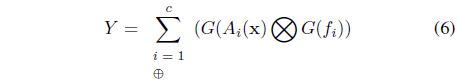
where the algebraic operations shown in circles ⨂ and ⊕ reflect that the arguments are information granules instead of numbers (say, fuzzy numbers). The detailed calculations depend upon the formalism of information granules being considered. Let us stress that
8. A hierarchy of granular models: towards type-2 and type-n granular models
The construction of the granular model can be expanded to form additional layer of the granular constructs and granular models. In essence, we develop a models whose granular parameters are made information granules of higher type, say those of type-2.
We proceed with a construction of the granular model of type-2 by forming their granular parameters on a basis of the initially available parameters of the numeric model
Proceeding with the specific realization of information granules, in case of interval-valued parameters, we observe an emergence of the visible hierarchy of information granules of higher type (granular intervals). Originally, the model
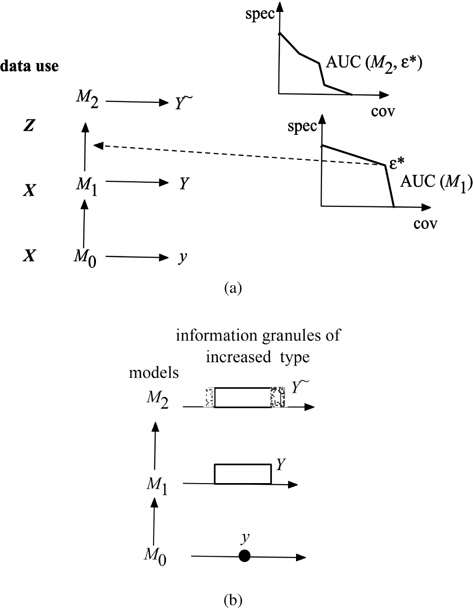
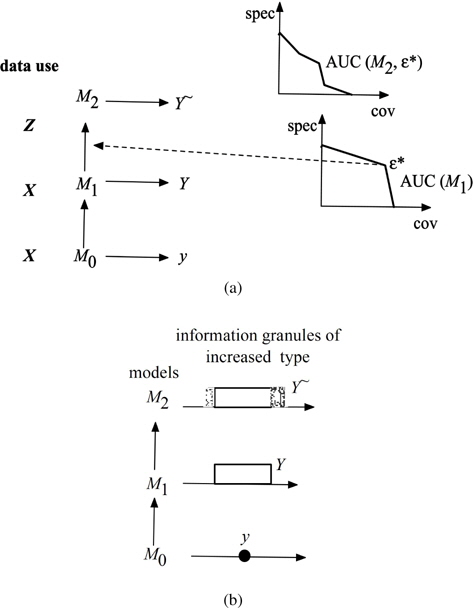
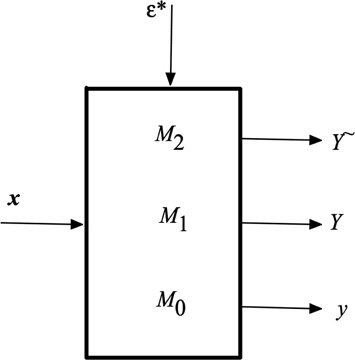
In parallel, we show a series of hierarchically structured models, Figure 2 (b) where the successive layers of the model are invoked depending upon the predefined levels of information granularity e and e*. For any input x they produce a numeric output, granular output (
There are two boundary situations worth emphasizing:
(a) selecting the values of e* for which the highest coverage is attained. In this situation, we are left with a small set of data
(b) selecting e* such that the highest specificity is attained. Now the data to be processed by
One could solve a certain optimization problem formulated as follows. We choose such
If the information granules are realized as fuzzy sets, following this scheme, we produce type-2 or interval –valued fuzzy sets of results, see Figure 3. Again as before, in the optimal allocation of information granularity we engage methods of evolutionary optimization in the realization of the protocols outlined in Section 6.
The above construction can carried out at the higher levels of hierarchy leading to granular models of type-3, 4, etc. In this case the successive data being used in the resulting constructions could be sought as outliers of type-1, type-2, etc.
With regard to the hierarchy outlined above, we may draw a certain analogy with some well known linear regression models. It is obvious that in the models of this class, for any
This study proposed a new direction for granular modeling of constructs of higher types. Successive granular system modeling can lead to the formation of granular parameters of type-1, type-2, etc. and to the production of models of type