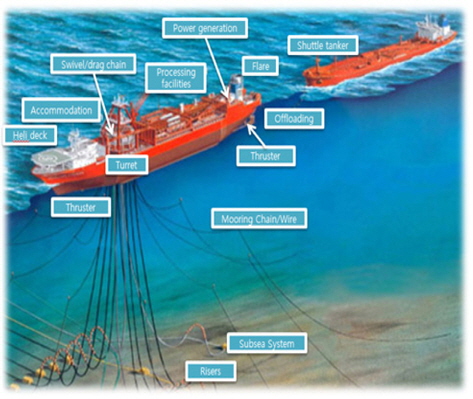
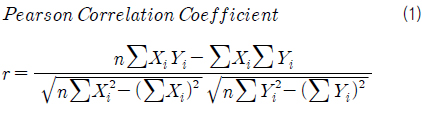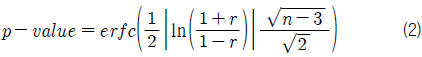세계적인 고유가로 인해 심해 자원에 대한 경제성이 높아지고 산업의 팽창으로 인해 석유 수요가 증가함에 따라 해양 산업이 새로운 유망 산업으로 주목 받고 있다. 또한 기존 심해에서의 석유시추 및 가공과 같은 해양 화석 연료 분야에만 주를 이루는 해양산업에서 점차 망간, 메탄 하이드레이트 등과 같은 해양 광물 자원 분야, 동물성 단백질을 공급하는 해양 생물 자원 분야, 그리고 조력과 파력 등 다양한 해양 에너지 분야로 확산되고 있다.
Fig. 1의 자료에 따르면 전세계 해양 구조물의 시장 규모가 2010년 1,400억 달러에서 2030년 5,000억 달러로 급속히 성장할 것으로 전망되고 있어, 해양 구조물 산업이 국가 성장 동력으로 주목 받고 있다.
해양 구조물의 설계 방법은 기존의 유사 데이터를 이용하여 수정 설계하는 유사 설계 방법과 기존 유사 데이터가 없는 경우 단계적인 반복 설계 과정을 거쳐 점차 개선된 결과를 얻어내는 신규 설계 방법으로 구분할 수 있다. 두 가지 방법 모두 중량 추정 방법은 매우 중요하다고 할 수 있다. 중량은 건조 비용, 생산일정 계획, 구조 강도, 복원성 등 다양한 측면에 영향을 미칠 뿐만 아니라 나아가 해당 구조물의 생산 비용 및 완료 기간에 막대한 영향을 미치기 때문이다.
그러나 초기 설계 단계에서는 모든 설계 요소를 고려할 수 없기 때문에 실제 중량을 정확히 추정하기는 어렵다. 따라서 많은 경우, 실제 중량은 상세 설계 및 건조 과정을 거치면서 초기 설계 단계에서 추정한 중량보다 증가 또는 감소하게 된다. 이에 따라 이러한 중량 증가는 초기 중량 추정 단계에서 중량 마진이라는 항목으로 고려하게 된다.
초기 설계 단계의 적절한 중량 마진은 설계 및 건조 과정을 거치며 나타나는 설계 상의 변경 사항이나 장비 변경 등에 적절히 대응하는 도구가 될 수 있다. 하지만 과도한 중량 마진이나 잘못된 중량 추정은 건조 비용과 운용 비용의 증가뿐만 아니라 자칫인도 지연을 초래할 수 있다. 따라서 초기 설계 단계에서 신뢰도가 높게 중량을 추정하고 후속 단계에서 이를 관리하고 통제하는 기술이 매우 중요하다 (Cho, 2011).
따라서 본 연구는 기존에 건조된 FPSO(Floating, Production, Storage, and Offloading unit)같은 해양 구조물의 실적 자료를 이용하여 새로이 건조할 해양 구조물의 중량 추정에 활용할 수 있는 모델을 개발함으로써 초기 설계 단계에서의 중량 추정의 정확성을 높이는 것에 그 목적이 있다.
해양 구조물의 중량 추정과 관련된 연구 현황으로서, 중량 추정 방법 자체에 대한 연구와 유전적 프로그래밍에 대한 연구로 구분하여 소개하기로 한다.
먼저 조선 및 해양 분야의 중량 추정 관련 연구에 관해 살펴보면, 선박의 중량 추정의 경우 많은 학자들로 인해 재화중량계수, 주요치수 등으로 추정하는 식이 선종 별로 개발되었다. 국내에서는 Kim (1966)은 3,000마력 이하의 중소형선에 대하여 중량/마력 비와 마력/축 비를 이용하여 중량을 추정하는 연구를 수행한바 있다. 또한 Cho (2011)는 통계적 방법으로 컨테이너선의 중량 추정 식을 개발하고자 하였다. 해양 구조물의 중량 추정 연구로는 Bolding (2001)의 경우 FPSO의 각 모듈 별 중량에 대하여 Bulk Factor(부피에 대한 중량 비, 즉 밀도에 대응)를 생성하여 FPSO의 중량을 추정하였다.
1950년대부터 Nils (1954)를 필두로 유전적 알고리즘에 대한 연구가 시작되었으나, 본격적인 유전적 프로그래밍에 대한 연구는 1980년대 후반에 시작되었다. Koza (1990)는 유전적 알고리즘의 유전자형을 구조적으로 표현할 수 있도록 확장하였고, 이것이 유전적 프로그래밍에 대한 연구의 시작이었다.
국내에서는 Yeon (1998)이 가중 선형 연상 기억을 유전적 프로그래밍에 접목하여 공학적으로 응용하는 연구를 수행하였고, 이후 Yeon and Lee (2001)는 유전적 프로그래밍 방법을 이용한 응답면의 모델링을 분석하였다. 또한 Lee and Yeon (2004)은 유전적 프로그래밍 방법을 이용하여 노이즈가 많은 데이터의 정확도를 높이고자 하였으며 이를 검증하기 위해 살물선의 재화 중량 추정 과정에 적용하였다. 이후 Lee, et al. (2009)은 유전적프로그래밍에 SOM(Self Organizing Map)을 접목시켜 독립 변수들의 영향력을 분석한 후 영향력이 낮은 독립 변수들을 제거함으로써 추정 방법의 신뢰성을 높였다.
Um, et al. (2013)은 유전적 프로그래밍 방법을 이용하여 부유식 해양 구조물의 중량 추정을 위한 근사 모델의 개발 방법에 대해 연구하였다. 이 방법은 자료 조사로부터 얻어진, 중량에 기여하는 모든 변수들을 유전적 프로그래밍 방법의 터미널 집합으로 사용했기 때문에, 생성된 중량 추정 모델에 다소 많은 독립변수들이 포함될 수 있다는 단점을 가지고 있다.
본 연구에서는 본 저자들의 기존 연구 (Um, et al., 2013)를 보다 확장하여 개선된 유전적 프로그래밍 방법을 이용한 중량 추정 모델을 개발하고자 하였다. 이를 위해, 상관 분석(correlation analysis)을 이용하여 중량에 영향을 미치는 독립 변수를 선정하였고, 이 독립 변수들을 터미널 함수로 구성한 뒤, 최종적으로 유전적 프로그래밍 방법을 적용함으로써 중량 추정 모델을 개발하였다. 유전적 프로그래밍 마지막으로 개발된 추정 모델의 효용성을 검증하기 위해 FPSO의 중량 데이터를 적용, 이를 추정 중량과 비교, 분석하였다. 특히, 유전적 프로그래밍을 이용해 중량 모델을 생성할 때, 독립 변수의 개수가 많을 경우 계산 시간이 증대되고, over-fitting이 발생하는 경우가 많다. 따라서 본 연구에서는 상관 분석을 통해 독립 변수의 개수를 줄이는 방법을 적용하여 기존의 유전적 프로그래밍 방법이 가진 한계를 극복하고자 하였다.
진화 연산 또는 진화 알고리즘은 적자 생존과 같은 자연 생태계의 진화 현상과 유전학에 근거한 계산 모델이다. 해(solution)를 나타내는 개체(individual)들로 개체군(population)을 형성한 후 그 개체군에 대하여 각 개체의 적합도(fitness)에 따라 선택(selection), 교배(crossover), 돌연 변이(mutation), 재생산(reproduction) 등의 유전 연산자(genetic operator)를 적용하여 다음 세대의 개체군을 형성하는 과정을 반복함으로써 전체적으로 우수한 해들로 진화시키는 최적화 알고리즘이다. 지면 관계상이에 대한 보다 상세한 내용은 참고 문헌 (Koza, 1992; Um, et al., 2013)을 참조하기 바란다.
상관 분석이란 두 변수 간에 서로 상관이 있는지 없는지를 알아보기 위한 분석 방법으로 얼마나 밀접한 선형 관계를 가지고 있는가를 분석하는 통계 기법이다. 이러한 척도를 나타내기 위해 두 변수간의 연관된 강도를 나타내는 상관 계수가 사용된다. 즉, 상관 계수가 클수록 두 변수는 밀접한 관계에 있다고 볼 수 있다.
상관 계수를 구하는 방법은 두 변수가 어떤 특정한 분포(정규 분포, t-분포 등)를 따르는가 아닌가에 따라 그 방법이 나뉜다. 두 변수가 연속형 변수이며 정규성을 띈다고 가정하며 비율 척도를 사용하는 모수적 상관 계수인 Pearson 방법과 특정한 분포를 따르지 않아 명명척도나 서열척도를 통해 변수를 분석하는 비모수적 상관 계수인 Spearman 방법, Kendall 방법으로 구할 수 있다.
본 연구에서는 변수에 대하여 명명척도나 서열척도가 아닌 비율척도로 분석하기 위해 Pearson 방법을 이용하여 상관 계수를 계산하였다. 식 (1)은 Pearson 방법을 이용하여 상관 계수를 구하는 수식을 나타낸다 (Bluman, 2004).
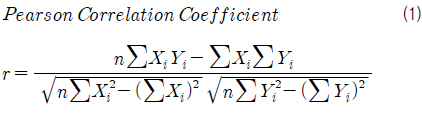
여기서, r은 Pearson 방법에 따라 계산한 상관 계수, X는 독립 변수, Y는 종속 변수, n은 표본의 개수이다.
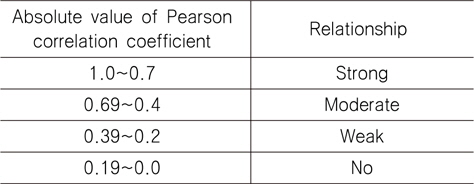
상관 계수를 이용하여 두 변수의 연관 정도를 해석할 때, 연관강도는 절대값으로 표현되는 수치를 보면 되고, 연관 방향(비례 또는 반비례)은 수치의 부호(+, -)를 보면 된다. 상관 계수의 부호가 양수인 경우 한 변수가 증가함에 따라서 다른 변수도 함께 증가함을 뜻하고, 상관 계수의 부호가 음수인 경우 이와는 반대로 한 변수가 증가함에 따라서 다른 변수는 감소하는 경향을 보인다는 것이다. 상관 계수에 의한 두 변수의 연관 강도는 Table 1에 따라 해석할 수 있다 (Kang, 2011).
[Table 1] The relationship between variables according to Pearson correlation coefficient
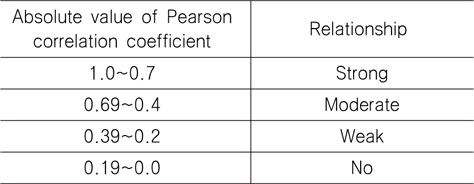
The relationship between variables according to Pearson correlation coefficient
한편, 상관 계수가 통계적으로 얼마나 의미가 있는지를 나타내는 수치를 유의 확률(p-value)이라고 한다. 유의 확률은 0~1사이의 값을 가지며 작을수록 의미가 있다는 것이며, 본 연구에서는 식 (2)에 따라 계산하였다.
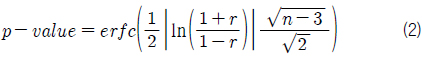
여기서, erfc(x)는 보상 오차 함수(complimentary error function)를 나타낸다.
상관 계수가 0.5 이상이면 변수 사이에 어느 정도 선형 관계가 있고, 0.7 이상이면 변수 사이에 아주 밀접한 선형 관계가 있다. 따라서 본 연구에서는 상관 분석을 통해 상관 계수 0.5 이상, 유의 확률 0.15 이하의 값을 가지는 독립 변수들을 유전적 프로그래밍 방법의 터미널 집합에 포함될 수 있는 후보들로 선정하였다.
4. 개선된 유전적 프로그래밍 방법을 기반으로 한 중량 추정 모델 생성 프로그램 개발
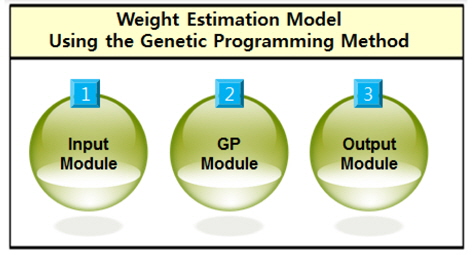
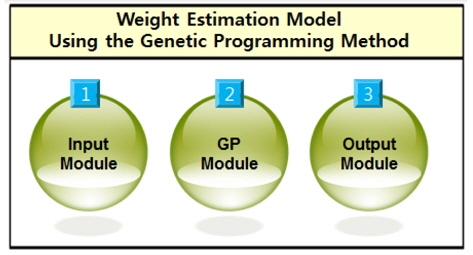
본 연구에서는 Fig. 2와 같이 유전적 프로그래밍 방법을 기반으로 한 중량 추정 모델 생성 프로그램을 개발하였다. 본 프로그램은 최종 중량 추정 모델에 포함될, 상관 분석을 통해 선정된 독립 변수들을 터미널 집합으로 선정하고, 최종 중량 추정 모델의 형태를 결정할, 사용자가 정의한 함수를 함수 집합으로 선정하였다. 이후 생성된 터미널 집합과 함수 집합을 기본으로 하여, 유전적 프로그래밍 방법에 의해 적합도 함수를 최대화하는 최적의 중량 추정 모델을 생성한다. 이 과정은 유전자 연산을 통해 종료 조건을 만족할 때까지 개선된 개체군을 반복적으로 생성함으로써 수행이 가능하다. 끝으로, 도출된 최적의 중량 추정 모델의 결과를 수식화한다. 본 프로그램은 상용 프로그램인 Matlab의 일부 내장 함수를 활용하여 개발하였다.
본 연구에서는 유전적 프로그래밍 방법을 이용하여 FPSO 상부의 중량 추정 모델을 개발하였으며, 아래에서 그 결과를 간략히 소개하였다.
FPSO는 크게 선체(hull)와 상부(topsides)의 두 부분으로 나뉜다. 특히 상부의 설계에 있어서 중량은 제작해야 하는 장비와 조달되어야 하는 재료의 양을 측정하는 기초가 되며, 제한된 공간인 상부에 많은 장비들이 배치되어야 하므로 중량 조절(weight control) 역시 중요하다.
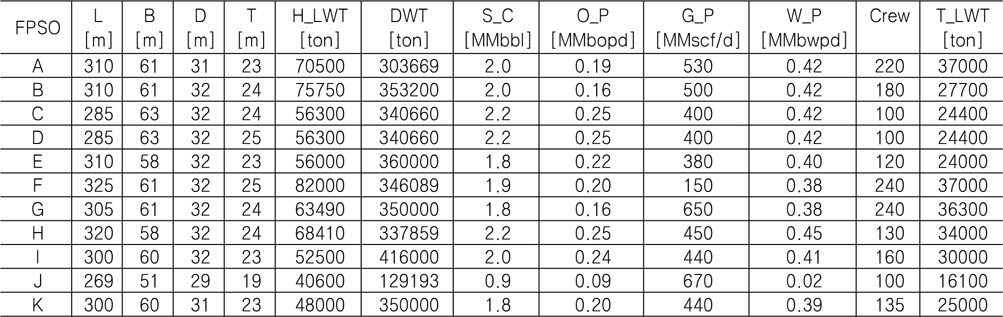
본 연구에서는 중량 추정 모델을 개발하기에 앞서 실적 자료를 수집하였다. 조선소로부터 정확한 데이터를 얻는 것이 보다 정도 높은 모델 개발에 필요하나 보안 등의 이유로 어려웠기 때문에 본 연구에서는 인터넷 또는 각종 문헌 조사를 통해 Table 2와 같이 총 11척의 FPSO 실적 자료를 확보하였다. 이들 중 10척의 자료는 중량 추정 모델을 만들기 위한 학습 자료로서 활용하였고, 1척의 자료는 개발된 중량 추정 모델의 검증을 위한 검증 자료로서 활용하였다.
[Table 2] Principal particulars of 11 FPSOs used in this study
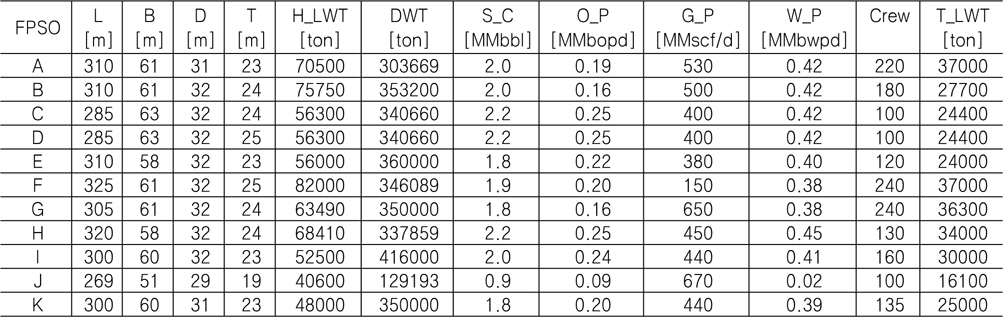
Principal particulars of 11 FPSOs used in this study
여기서, FPSO의 주요 제원과 관련된 변수로서 선체 길이 L, 폭 B, 깊이 D, 흘수 T, 선체 중량 H_LWT, 재화 중량 DWT 등이 선정되었으며. 구조물의 용량 및 규모를 고려하기 위한 변수로서 저장 용량 S_C, 오일 생산량 O_P, 가스 생산량 G_P, 물 주입량 W_P이 선정되었다. 끝으로 Crew는 해양 구조물의 작업 인원을 나타낸다.
[Table 3] Independent variables for the estimation model for topsides weight of FPSO

Independent variables for the estimation model for topsides weight of FPSO
5.2 상관 분석을 통한 독립 변수(터미널 집합) 선정
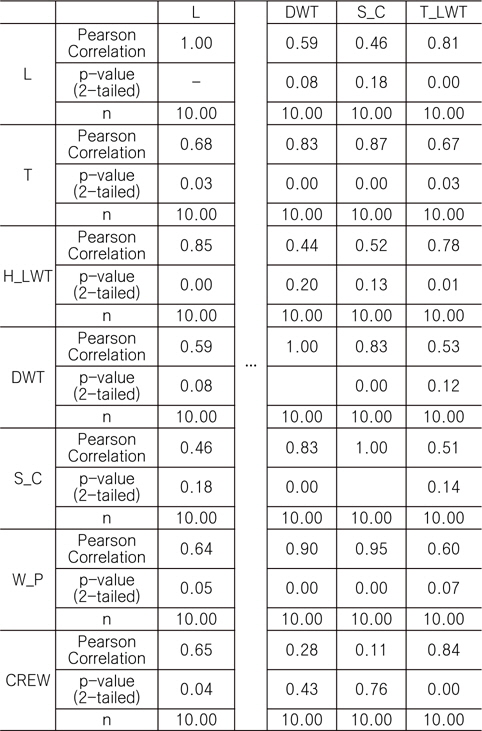
본 연구에서는 Pearson 방법으로 독립 변수간 상관도를 검토하였으며, 상관 계수가 0.5 이상이면 변수 사이에 어느 정도 선형 관계가 있고, 0.7 이상이면 변수 사이에 아주 밀접한 선형 관계가 있는 것으로 판단하였다. 본 연구에서는 자체 개발 프로그램을 이용하여 FPSO 상부 중량에 영향을 미치는 독립 변수들의 상관 분석을 수행하였으며, 그 결과 상관 계수가 높은 상위 7개의 변수를 선정하였다. Table 4는 상관 분석 결과의 일부를 나타낸 것이다.
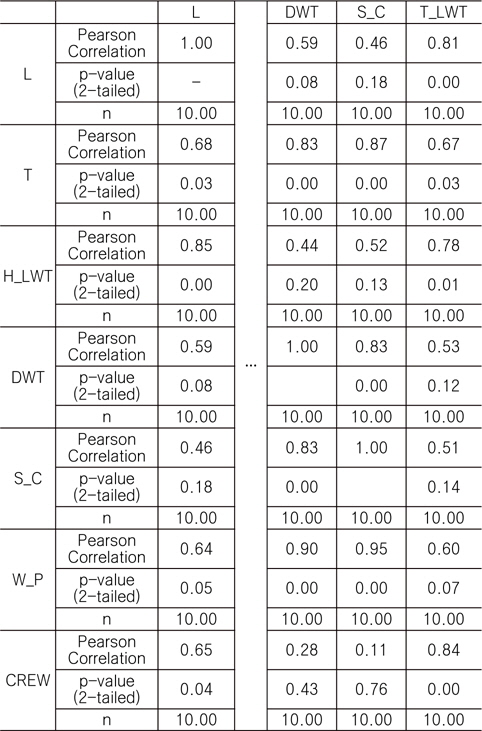
Correlation analysis between independent variables and topsides weight (7 variables were partially represented)
Table 4에서 Pearson Correlation, p-value, N은 각각 상관 계수, 유의 확률, 데이터의 수를 나타낸다.
상관 분석 결과를 활용하여, Table 5에서와 같이 상관 계수 0.5 이상, 유의 확률 0.15 이하인 7개의 독립 변수들을 유전적 프로그래밍 방법에서의 터미널 집합으로 사용하였다.

Independent variables for the estimation model for topsides weight of FPSO generated from the correlation analysis
5.3 유전적 프로그래밍 방법을 이용한 중량 추정 모델 생성
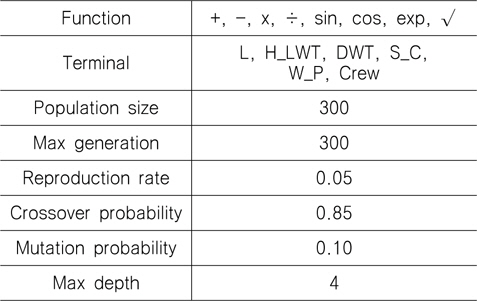
본 연구에서 유전적 프로그래밍 방법을 이용하여 FPSO의 중량 추정 모델을 생성할 때, 터미널 집합은 상관 분석의 결과를 활용하였고, 기타 함수 집합과 파라미터는 Table 6의 값을 활용하였다.
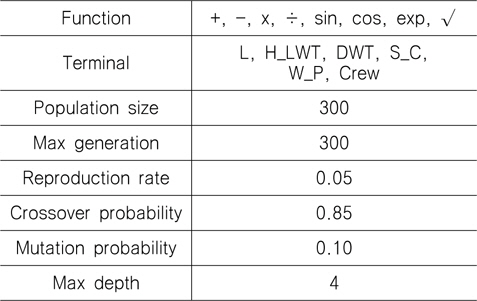
Parameters of genetic programming for developing the estimation model for topsides weight of FPSO
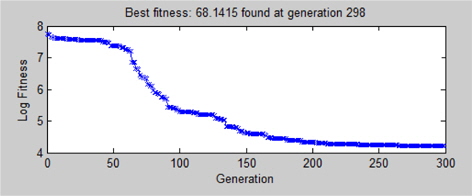
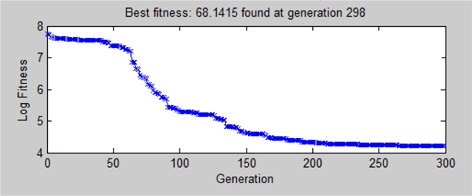
유전적 프로그래밍 방법을 이용하여 중량 추정 모델을 생성할때 각 세대에 따른 적합도는 Fig. 4와 같다. 여기서 적합도는 해당 중량 추정 모델이 종속 변수(FPSO 상부의 중량, T_LWT)를 얼마나 잘 추정하느냐를 나타내는 정도를 나타내며 본 연구에서는 보간법(interpolation)의 정확도를 판단하는데 가장 널리 사용되고 있는 RMSE(Root Mean Square Error)를 최소가 되도록 하였고 식 (3)과 같다.

이상과 같은 유전적 프로그래밍 방법의 수행을 통해 FPSO 상부에 대한 중량 추정 모델을 얻었으며, 이를 수식화하면 식 (4)와 같다.
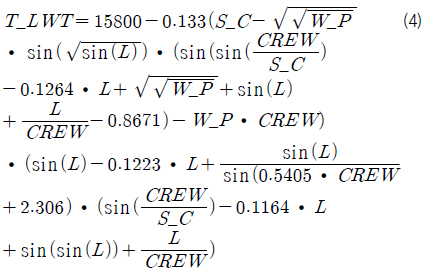
여기서, 좌변의 T_LWT는 FPSO 상부의 추정 중량을 나타낸다.
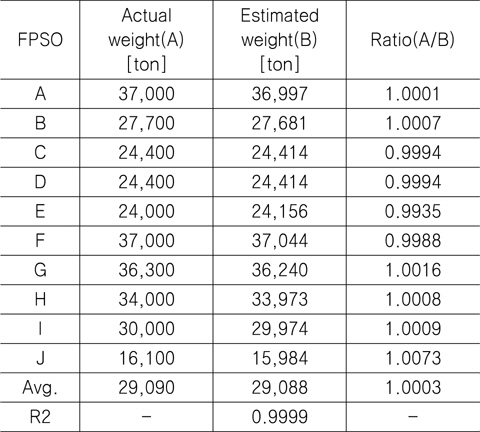
앞서 생성한 중량 추정 모델의 효용성을 검증하기 위해, FPSO에 대한 총 10척의 학습 자료(유전적 프로그래밍 방법을 이용하여 중량 추정 모델을 만들기 위해 활용된 자료. 물론, Table 7에서 검증용으로도 활용하였음)와 1척의 검증 자료(생성 된 중량 추정 모델의 유효성을 평가하기 위해 활용된 자료. 중량 추정 모델을 생성하는 데에는 활용되지 않은 것임)를 활용하여 중량 추정 모델을 개발하였다. 먼저, 각 FPSO 상부의 실제 중량을 추정 모델로부터 구한 추정 중량과 비교하여 그 차이를 분석하였으며, Table 7에 그 결과를 나타내었다.
[Table 7] Comparison between the actual and estimated weight for FPSO topsides using 10 FPSO data
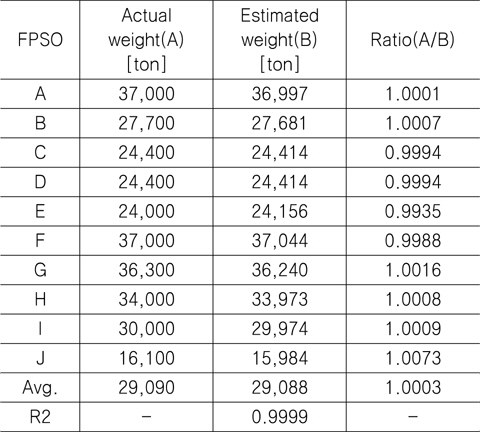
Comparison between the actual and estimated weight for FPSO topsides using 10 FPSO data
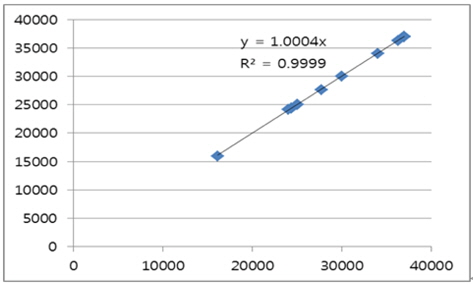
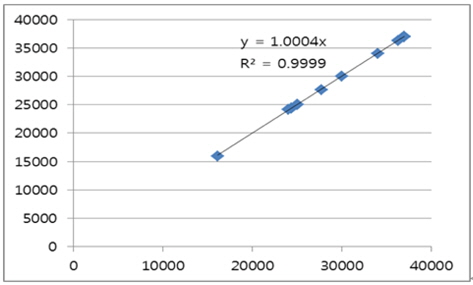
Table 7에서 볼 수 있듯이, 실제 중량과 추정 중량의 비의 평균은 1.0003이었으며, 결정 계수(R2)는 0.9999였다. 그리고 Fig. 5는 실적선 중량과 추정 중량의 차이를 그림으로 나타낸 것이다.
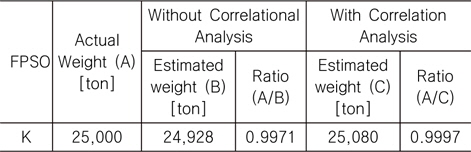
그리고 중량 추정 모델을 개발하기 위하여 활용한 10척의 FPSO 자료 외에 1척의 자료를 앞서 개발된 추정 모델의 유효성 검증에 활용하였다. 그 결과는 Table 8과 같다.

Comparison between the actual and estimated weight for FPSO topsides using additional FPSO data
본 절에서는 선행 연구 되었던 유전적 프로그래밍을 이용한 중량 추정 모델 결과 (Um et. al, 2013)과 상관 분석을 적용한 개선된 중량 추정 모델의 결과를 비교하고자 한다.
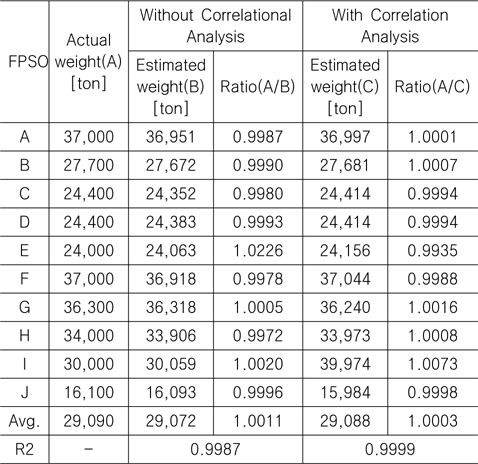
Table 9에서 볼 수 있듯이, 상관 분석의 적용을 통해 최종 중량 추정 모델에 포함되는 변수의 수를 줄임으로써 더 신뢰도가 높은, 즉 결정 계수(R2)의 값이 더 높은, 결과를 얻을 수 있었다. 또한 Table 10에 나타나 있듯이, 추가 1척(K FPSO)에 대한 비교 결과 역시, 상관 분석을 적용한 것이 더 우수한 결과를 도출하였음을 알 수 있다.
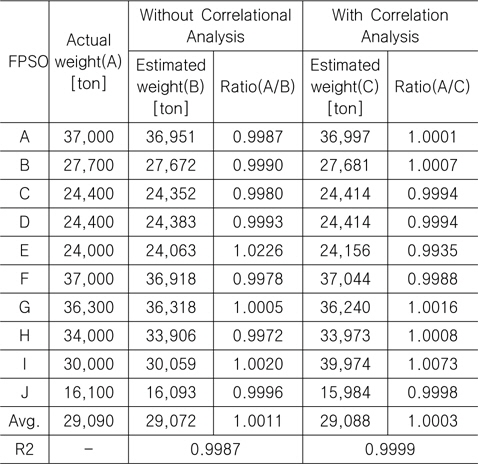
Comparison between the actual and estimated weight (without and with correlation analysis) for FPSO topsides using 10 FPSO data
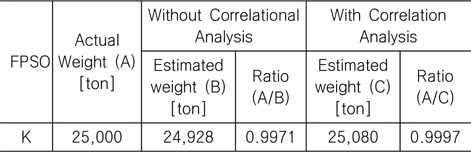
Comparison between the actual and estimated weight (without and with correlation analysis) for FPSO topsides using additional FPSO data
이와 같은 비교 분석 과정을 통해 다음과 같은 사실을 알 수 있다. 상관 분석을 적용한 경우, 학습 데이터가 부족할 때 독립 변수와 종속 변수간의 선형 관계를 분석함으로써 상관도가 낮은 변수를 제거하여 추정 모델의 신뢰도를 높일 수 있다. 즉, 유전적 프로그래밍 방법을 이용한 중량 추정 모델 생성 방법에 상관 분석을 적용할 경우, 변수들간의 상관도 및 영향도를 평가하여 이를 추정 모델 생성 과정에 반영함으로써, 유전적 프로그래밍방법(상관 분석 미적용)에서 학습 데이터가 부족할 경우 발생할 수 있는 over-fitting 문제를 해결할 수 있으리라 생각된다.
본 연구에서는 설계의 초기 단계에서 부유식 해양 구조물의 중량 추정 모델을 구현하기 위해 개선된 유전적 프로그래밍을 이용하였다. 특히, 독립 변수간 상관 분석을 통해 상호 영향도를 평가함으로써 변수의 개수를 줄였으며, 이를 통해 데이터의 수에 비해 독립 변수의 개수가 많을 때 나타날 수 있는 유전적 프로그래밍 방법에서의 over-fitting 문제를 어느 정도 해결할 수 있고, 또한 유전적 프로그래밍 방법을 통해 중량 추정 모델을 도출해내는데 소요되는 시간을 줄일 수 있었다.
본 연구에서는 독립 변수와 종속 변수간 상관도를 계산하여 상호 의존성을 평가하는 상관 분석 과정을 통해 유전적 프로그래밍 방법에서의 터미널 집합(독립 변수의 집합)을 결정하였고, 함수 집합 및 기타 파라미터를 선정한 후 종속 변수를 가장 잘 표현할 수 있는 중량 추정 모델을 다수의 세대 반복을 통해 도출하였다. 그 결과 적합도가 가장 높은, 즉 종속 변수를 가장 잘 근사화할 수 있는 중량 추정 모델을 최종 모델로서 선정하였다. 끝으로, 이러한 과정은 FPSO 상부의 중량 추정 모델을 개발하는 데에 적용하였고, 검증 결과 효과적으로 해당 중량을 추정할 수 있음을 확인하였다.
다만, 이러한 추정 결과는 얼마나 많고 정확한 자료를 활용하였는가에 따라 달라질 수 있다. 따라서 향후, 보다 많고 정확한 실적선 자료를 활용하여 본 연구에서 제안한 방법을 적용하고 그 효용성을 보다 심도 있게 평가하고자 한다.
향후에는 Semi-submersible (반잠수식 구조물), TLP(인장식각 플랫폼), Floating offshore wind turbine (해상풍력발전기) 등 다양한 해양구조물에 대한 보다 많은 실적선 확보를 통해 보다 정교한 중량 추정 모델을 개발하고, 그 유효성을 검증할 예정이다.