The Web is rich with various sources of information that go beyond the contents of documents, such as hyperlinks and manually classified directories of Web documents such as Yahoo. This research extends past fusion IR studies, which have repeatedly shown that combining multiple sources of evidence (i.e. fusion) can improve retrieval performance, by investigating the effects of combining three distinct retrieval approaches for Web IR: the text-based approach that leverages document texts, the link-based approach that leverages hyperlinks, and the classification-based approach that leverages Yahoo categories. Retrieval results of text-, link-, and classification-based methods were combined using variations of the linear combination formula to produce fusion results, which were compared to individual retrieval results using traditional retrieval evaluation metrics. Fusion results were also examined to ascertain the significance of overlap (i.e. the number of systems that retrieve a document) in fusion. The analysis of results suggests that the solution spaces of text-, link-, and classification-based retrieval methods are diverse enough for fusion to be beneficial while revealing important characteristics of the fusion environment, such as effects of system parameters and relationship between overlap, document ranking and relevance.
웹은 하이퍼링크 및 야후와 같이 수동으로 분류된 웹 디렉토리 처럼 문서의 콘텐츠를 넘어선 다양한 정보의 소스가 풍부하다. 이 연구는 웹문서 내용을 활용한 텍스트기반의 검색 방식, 하이퍼 링크를 활용한 링크 기반의 검색 방식, 그리고 야후의 카테고리를 활용한 분류 기반의 검색 방식을 융합하므로서 여러 정보소스를 결합하면 검색 성능을 향상시킬 수 있다는 기존 융합검색연구들을 확장시켰다. 텍스트, 링크, 분류 기반 검색 결과를 여러가지 선형조합식으로 생성한 융합결과를 기존의 검색 평가 지표를 사용하여 각각의 검색 결과와 비교 한 후, 검색결과 오버랩의 중요성 또한 조사 하였다. 본 연구는 텍스트, 링크, 분류 기반 검색의 솔루션 스패이스들의 다양성이 융합검색의 적합성을 제시한다는 결론과 더불어 시스템 파라미터의 영향, 그리고 오버랩, 문서순위, 관련성들의 상호 관계 같은 융합 환경의 중요한 특성들을 분석하였다.
The Web document collection is rich in sources of evidence(e.g., text, hyperlinks, Web directories) and thus offers an opportunity to employ a diverse set of retrieval approaches that can leverage a wide range of information. Furthermore, findings from fusion information retrieval (IR) research suggest that multiple sources of evidence(MSE) and multiple methods that leverage them could be combined to enrich the retrieval process on the Web. The nature of the Web search environment is such that retrieval approaches based on single sources of evidence suffer from weaknesses that can diminish the retrieval performance in certain situations. For example, text-based IR approaches have difficulty dealing with the diversity in vocabulary and quality of web documents, while link-based approaches can suffer from incomplete or noisy link topology. The inadequacies of singular Web IR approaches coupled with the fusion hypothesis of “fusion is good for IR” make a strong argument for combining MSE as a potentially advantageous retrieval strategy for Web search.
The first step in fusion IR is to identify and examine the sources of evidence to combine. MSE on the Web that can be leveraged for IR are: contents of Web documents, characteristics of Web documents, hyperlinks, Web directories such as Yahoo, and user statistics. The main hypothesis of the study, namely that combining text-, link-, and classification-based
Text-based approaches have difficulties dealing with the vocabulary problem(e.g., different expressions of the same concept in Web documents and queries), the diversity of document quality and content, fragmented documents, and documents with little textual contents, such as “hubs”, index pages, and bookmarks. Link-based approaches do not fare well when faced with a variety of link types(e.g., citation links, navigational links, commercial links, spam links), and “emerging” communities with incomplete link topologies. Web directories, in addition to classification and vocabulary problems(e.g., different categorizations of the same Web document and different labeling of the same category), contain only a fraction of the documents on the Web.
The most obvious of the complementary strengths is found in the combination of text- and link-based approaches. Ranking text-based retrieval results by a measure “link importance” can help differentiate documents with similar textual contents but varying degrees of importance, popularity, or quality. Pruning documents based on their textual contents before applying link analysis techniques can help alleviate the problems introduced by spurious links. On an abstract level, web directories, which embody explicit human judgments about the quality and topicality of documents, can augment ranking algorithms based on counting of words or links. Specifically, Web directories can be used to train document classifiers, to find related documents, and to help refine queries by finding subcategories, searching within a category, and suggesting related categories, all of which employ text- and/or link-based methods to exploit the information contained in Web directories.
Combining text-, link-, and classification-based methods can be viewed as attempting to maximize the combined strengths of leveraging author’s knowledge, peer’s knowledge, and cataloger’s knowledge about Web documents while minimizing their individual weaknesses. Although the idea of fusion is intuitively appealing, there is a shortage of techniques that utilize the considerable body of explicit human judgment(e.g. Web directories
Two best-known link analysis methods, which are based on the notion that hyperlinks contain implicit recommendations about the documents to which they point, are Page Rank and HITS (Yang 2005).
Page Rank is a method for assigning a universal rank to Web pages based on a recursive weight-propagation algorithm(Page et al. 1998). Page et al. start with the notion of counting backlinks(i.e., indegree) to assess the importance of a Web page, but point out that simple indegree does not always correspond to importance; thus they arrive at propagation of importance through links, where a page is important if the sum of the importance of its backlinks is high.
Kleinberg’s(1999) HITS(Hyperlink Induced Topic Search) algorithm considers both inlinks and outlinks to identify mutually reinforcing communities of “authority” and “hub” pages. Though HITS embraces the link analysis maxim that says a hyperlink is an annotation of human judgment conferring authority to pointed pages, it differs from other link-based approaches in several regards. Instead of simply counting the number of links, HITS calculates the value of page
The bulk of IR fusion research, which investigates the various ways of combining different retrieval strategies, have found fusion to have a positive effect on retrieval performance regardless of what strategies were combined. The potential of fusion to leverage the strengths of its components while minimizing their weaknesses is not only promising in its own right, but offers a novel perspective of IR that relaxes the research goal of discovering the one best retrieval strategy.
Earlier studies on combining different document representations discovered that combined representations achieved better retrieval outcome than single representations(e.g., title and keyword vs. title or keyword) despite the fact that the difference in retrieval performance among single representations were small(Keen 1973; Spark Jones 1974). To explain this phenomenon, subsequent studies examined the overlap between different document representations(i.e., common terms) and found overlap to be small(Williams 1977; Smith 1979). A more systematic study of different document representations' relative effectiveness was later conducted by Katzer et al.(1982), who executed 84 queries on seven representations of 12,000 INSPEC documents and found but higher overlap among relevant documents than nonrelevant documents. The relationship between overlap and relevance was further studied from the perspective of the searcher by Saracevic and Kantor(1988), who found that the odds of a document being relevant increased monotonically with the number of retrieved sets in which it appeared. Fox and Shaw(1994; 1995), in combining different retrieval methods as well as query representations, discovered that combining dissimilar sources of evidence was better than combining similar ones.
Lee(1996) experimented with the fusion of multiple relevance feedback methods and found that different relevance feedback methods retrieve different sets of documents even though they achieve a similar level of retrieval effectiveness. By examining the overlap of relevant and non relevant documents retrieved by different retrieval systems separately, Lee(1997) observed what he calls the “unequal overlap property”, which is the phenomenon that different systems tend to retrieve similar relevant documents but dissimilar nonrelevant documents. The unequal overlap property challenges the fusion assumption by Belkin et al.(1993), which suggests that retrieval performance improvement by fusion may be partially due to combining of different relevant documents retrieved by different sources of evidence. In fact, Lee hypothesized that fusion is warranted when systems retrieve similar sets of relevant documents but different sets of nonrelevant documents. Lee’s hypothesis about the condition for effective fusion was more formally validated by Vogt and Cottrell(1998). Based on the performance estimation of a linearly combined system based on measurable characteristics of the component systems, they concluded that to achieve effective fusion by linear combination, one should maximize both the individual system’s performance and the overlap of relevant documents between systems, while minimizing the overlap of nonrelevant documents. They also suggested that component systems should distribute scores similarly but not rank relevant documents similarly.
We should note at this point that the art of fusion lies in discovering how different experts or sources of evidence can be combined to exploit their strengths while at the same time remaining unaffected by their weaknesses. As the study by Bartell et al.(1994) demonstrates, the fusion solution space is defined not only by the fusion algorithm but also by how that fusion algorithm is applied. In other words, the optimal fusion approach should consider the context of fusion in determining its overall fusion strategy.
This study combines methods that leverage text, hyperlink, and Web directory information to improve retrieval performance. Retrieval results of methods that leverage Web page text, hyperlink, and Yahoo Web directory information, both combined and individual, were examined to determine whether such fusion approaches are beneficial for Web search. The following sections describe the experiment in more detail.
The data used for the study is the WT10g test collection from Text REtreival Conference (http://trec.nist.gov/), which consists of 1.7 million Web documents, 100 queries(topics 451-550), and relevance judgments. The WT10g collection also includes the connectivity data, which provides lists of inlinks and outlinks of all documents in the collection. The connectivity data, however, is restricted to the WT10g universe, meaning that inlinks and outlinks that are not part of the collection themselves are omitted, which is likely to make the link topology of the collection incomplete. The document set of WT10g is comprised of 1,692,096 html pages, arrived at by sampling the original Internet Archive data in such a way to include a balanced representation of the real Web characteristics such as hyperlink structure and content types. Duplicates, non-English, and binary documents were excluded from the collection. Queries, or topics as they are called in TREC, consist of a title field, containing actual queries as they were submitted to Web search engines, a description field, which is typically a one sentence description of the topic area, and a narrative field, containing descriptions of what makes documents relevant. The description and narrative fields were created by TREC assessors to fit the intent of the real Web search queries represented in the title.
The characteristics of a Web directory, such as breadth of coverage, consistency of classification, and granularity of categories, are important factors to consider in determining the data source for classification-based retrieval methods. An ideal Web directory would be one that has classified all the documents of the test collection into fine-grained categories in a consistent manner. Lacking the ideal Web directory, Yahoo(http://yahoo.com) was used to leverage Web directory information for its size and popularity. Instead of using the actual Web documents associated with Yahoo categories, the classification-based method uses document titles and Yahoo’s descriptions of the categorized pages to represent each categorized document. This not only speeds up processing but also reduces noise in representation, which is a preferred practice in text categorization. In addition, the annotated description of a Yahoo site, along with the category to which it belongs, represent the cataloger’s knowledge about the classified document, which complements the author’s knowledge embodied in the document text and peers’ knowledge embodied in hyperlinks that point to the document.
2.1 Text-based Retrieval Method
The text-based retrieval component is based on a Vector Space Model(VSM) using the SMART length-normalized term weights (Singhal et al. 1996). Documents are processed by first removing markup tags and punctuation and then excluding stopwords, low frequency terms, non-alphabetical words(exception: embedded hyphen), words consisting of more than 25 or less than 3 characters, and words that contain 3 or more repeated characters. After punctuation and stopword removal, each word was conflated by applying the simple plural remover(Frakesand Baeza-Yates 1992). The simple plural remover was chosen to speed up indexing time and to minimize the overstemming effect of more aggressive stemmers. TREC topics were stopped and stemmed in the same manner as the document texts.
In addition to body text terms(i.e. terms between < BODY> and < /BODY> tags), header text terms were extracted from document titles, meta-keyword and description texts, and heading texts (i.e. texts between
The VSM method used SMART

where

where
In addition to initial retrieval results, top ten positive and top two negative weighted terms from the feedback vector, created by the adaptive linear model using the top three ranked documents of the initial retrieval result as “pseudo-relevant”, were used as a query to generate the pseudo-feedback retrieval results. The basic approach of the adaptive linear model, which is based on the concept of preference relations from decision theory(Fishburn 1970), is to find a

wherea is a constant, and b is the
Table 1 enumerates the text-based method parameters for VSM systems, which are query length, term source, use of phrase terms, and use of pseudo-feedback. Query length ranges from short(topic title) and medium(topic title and description) to long(topic title, description, and narrative). Term sources are body text, header text, and body plus header text. The use of noun phrase indicates whether the term index for each term source contains both single and phrase terms or single terms only. The combination of parameters(3 query lengths, 3 term sources, 2 for phrase use, 2 for feedback use) resulted in 36 VSM systems.

VSM system* parameters
2.2 Link-based Retrieval Method
For the study, the authority score of documents computed by the HITS algorithm (Kleinberg 1999) is used to generate a ranked list of documents with respect to a given query. HITS was chosen over PageRank scores, whose effective computation requires a link propagation over much larger set of linked documents than the WT10g corpus(Brinand Page 1998), and the Clever algorithm(Chakrabarti et al. 1998), which makes it difficult to isolate the contributions and behaviors of individual methods by implicitly combining link- and text-based methods to extend HITS.
HITS defines “authority” as a page that is pointed to by many good hubs and defines “hub” as a page that points to many good authorities. Mathematically, these circular definitions can be expressed as follows:

The above equations define the authority weight
The original HITS algorithm was modified by adopting a couple of improvements from other HITS-based approaches. As implemented in the ARC algorithm (Chakrabarti et al. 1998), the root set was expanded by 2 links instead of 1 link(i.e. expand
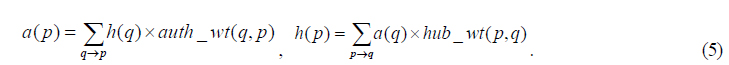
In above equations,
Among the 36 text-based system results, we chose the best performing system with all variations of query lengths as the seed sets. The combination of host definition and seed set parameters, as seen in Table 2, resulted in 6 HITS systems.

HITS system* parameters
2.3 Classification-based Retrieval Method
The first step of the classification-based method is to find the categories that best match the query, which can be thought of as a query-category matching problem. Since Web directories classify only a fraction of the Web and do not rank documents that are classified, a second step that classifies and ranks documents with respect to the best matching category is needed, which can be thought of as a category-document matching problem.
To leverage the classification information, we employed the

where
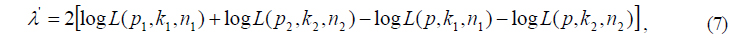
where:
logL(p,k,n) = k log p + (n − k)log(1 − p),, , , k1 = AB, n1 = AB+-AB, k2 = A-B, andn2 = A-B+-A-B.
The TM method finds the best category for a query based on the number of matching query terms, and expands the original query with selected category terms that are weighted by term association weights to rank documents. The way the TM method leverages the classification information is twofold. First, it uses manually assigned category terms(i.e., category labels, site titles and descriptions) to find the best matching categories and to expand the query. Second, it uses term association weights, which are based on term-category co-occurrence, to compute the term weights of the expanded query vector. In other words, the importance of category labels as well as multi-term concepts are underscored in ranking categories by the number of unique query terms in category labels, while the importance of term and category co-occurrence in the classification hierarchy is emphasized in the term weights of the expanded query vector.
The parameters tested for the TM systems are number of top (i.e., best matching) categories used, WT10g term index, and use of pseudo-feedback. The combination of the parameters (3 top categories, 4 WT10g term index, 2 for feedback use) resulted in 24TM systems (Table 3).

TM system* parameters
2.4 Fusion Method
How to combine or integrate fusion components is the key question in fusion IR. One of the most common fusion methods is the
To compensate for the differences among fusion component systems, the

where:
Although the WRS formula aims to weight the contributions of individual fusion components to the retrieval outcome by their relative strength, it does not explicitly differentiate between overlapped and non-overlapped instances. In other words, the absolute contribution of a document retrieved by a system remains the same whether the document in question is retrieved by other systems or not. What WRS formula neglects is the possibility that the contribution of a document by a system to the retrieval outcome could be different across overlap partitions(e.g., documents retrieved by system 1 only, by system 1 and 2 only, etc.).
To leverage the retrieval overlap and rank information, we devised two additional fusion formulas.

where:

where:
In all the formulas of Weighted Sum variation, topics 451 to 500 were used as training data to determine the weights. Overall average precision, which is a single-value measure that reflects the overall performance over all relevant documents, was used to determine the weight in the WRS formula. In the OWRS formula, overall average precision was multiplied by overlap average precision, which is the average precision computed for each overlap partition. In a 3-system fusion, for example, average precision is computed for each of the 4 overlap partitions for each system. In other words, the result set of a system is partitioned into overlap partitions (e.g., for system A: documents retrieved by system A, by system A and B, by system A and C, by system A, B, and C), and average precision is computed in each partition of each system.
For the ROWRS, which needs a performance estimate at a given rank, overall average precision is not appropriate. Instead, three rank-based measures, namely
Whereas
For both WRS and OWRS formulas, three variations that amplify the contribution of the top performing system were investigated. These variations, in an increasing order of emphasis for the top system, are

where:
Equation 12, 13, and 14 describe the weighting functions of
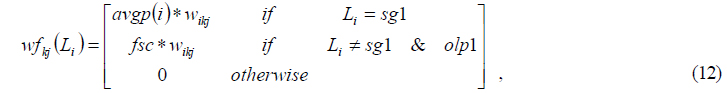

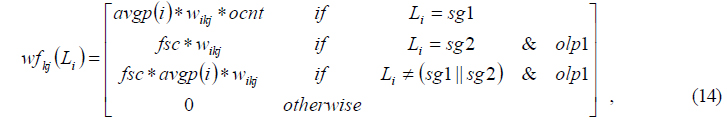
where:
The study generated a massive amount of data that consisted of 66 single system results(36 VSM, 6 HITS, 24 TM) and numerous sets of fusion results. Since the focus of the study is on fusion methods, the discussion of results will center on fusion results preceded by a summary analysis of single system results.
The best performing single systems by average precision were:
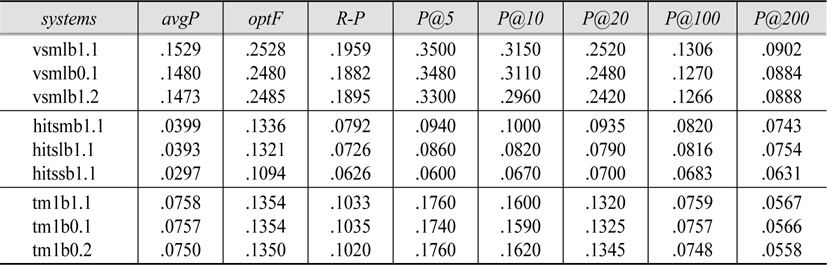
Single System results
1.1 Text-based Retrieval Results
Among the VSM system parameters tested, which are query length, term source, use of phrase terms, and use of pseudo-feedback, query length and term source were found to be most influential to the retrieval outcome. The influence of query length, which may be related to the amount of information, seems intuitive. Regardless of other parameter combinations, longer queries performed better than shorter queries in all cases except when system performances were degraded by the adverse effect of header text terms. The use of noun phrases, although helpful in 16 out of 18 system pairs, resulted in only a marginal increase in performance. Similarly, the use of pseudo-feedback resulted in a slight decrease in performance in most cases. Incidentally, the average precision of the best VSM system is roughly twice that of the top TM system, and four times the top HITS.
1.2 Link-based Retrieval Results
The results indicated the influence of host definition on retrieval performance for HITS systems. The shorter host definition is obviously far superior to longer definition(over 10 times better in average precision). As for the effect of the seed system on performance, one would expect better seed sets to produce better HITS results, since the quality of a seed set is amplified by link expansion much like the way the quality of “seed” documents is amplified by pseudo-feedback. The results, however, appear not to be totally consistent with such a supposition. The HITS tendency to degrade rather than enhance the seed system performance, even with the optimum seed set, may be due to incomplete relevance judgments and truncated link structure with heavy concentration of spurious links in the WT10g collection (Gurrinand Smeaton 2001).
1.3 Classification-based Retrieval Results
TM results showed only small performance variations across TM systems. TM parameter influences were quite orderly. All body text systems were ranked above body and header text systems. Within a given term source(e.g., body text, body and header text), systems using fewer number of top categories were always ranked higher than systems using more categories. Within a given number of top categories and term sources, systems without pseudo-feedback always ranked above ones with feedback. Only the phrase use parameter show edin consistent results. Systems without phrase use ranked above ones with phrase use in five of the six body text system pairs, but only twice in six body and header text pairs.
Since parametric combinations in each of VSM, HITS, and TM methods spawned a large number of systems(36 VSM, 6 HITS, and 24 TM systems), a brute force investigation of all possible fusion combinations was neither feasible nor desirable. Therefore, selective combinations of systems were conducted in a progressive fashion in an attempt to tease out the major factors that influence fusion.
The results of the systems within each method(e.g., VSM, HITS, or TM) were combined first to see the effect of fusion without cross-method interplay of systems. Henceforth, combining systems within a given method will be referred to as
2.1 Intra-Method Fusion
In both VSM and TM fusion, WRS fusion performance closely shadowed the baseline system. In HITS fusion, however, WRS surpassed the baseline performance at lower ranks. WRS and baseline results were almost identical in TM fusion. It is interesting to note that combining HITS results improved the retrieval performance, while little was gained by combining VSM or TM results. One possible explanation for this phenomenon may be that the combined solution space of HITS systems is much larger than that of the best individual HITS system, while the best system dominates the combined solutions space in VSM and TM methods.
2.2 Inter-Method Fusion
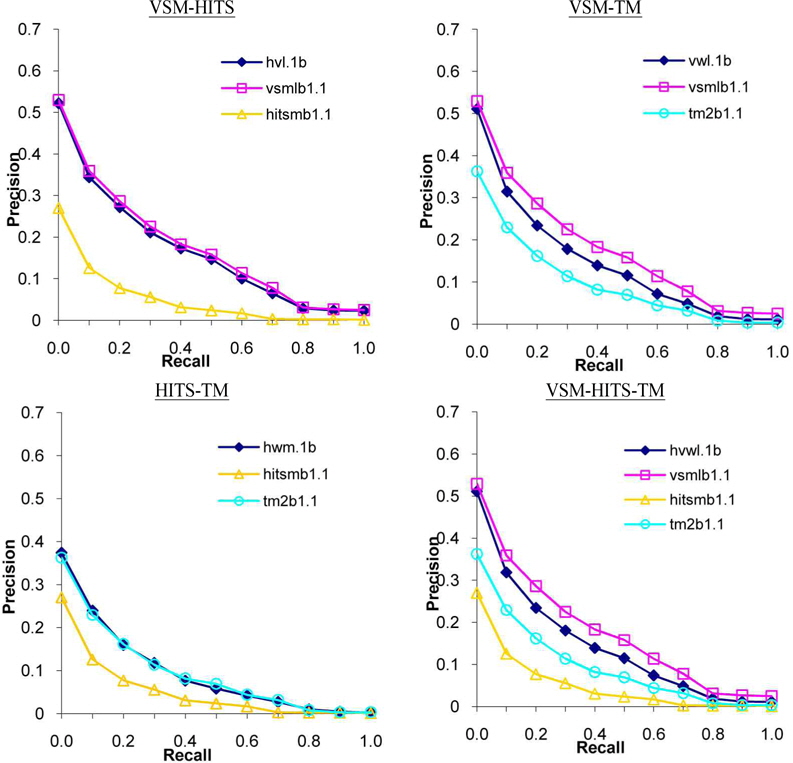
In each of the four possible combinations of the three methods, fusion was conducted in a similar manner as the intra-method fusion to investigate the general fusion tendencies of cross-method fusion rather than to focus specifically on potentially advantageous system combinations. Observations from intra-method fusion mostly held true in inter-method fusion, although fusion seemed to degrade the best single system performance more in inter-method fusion than in intra-method fusion. In all but the HITS-TM method combination, the baseline systems acted as upper and lower bound performance thresholds and fusion results fell nicely between them. There was, however, a distinct difference in the level of fusion results. As can be seen in Figure 1
Examination of overlap offers a possible explanation for this fusion outcome. High overlap counts for VSM and TM but low overlap count for HITS (Table 5) suggest that documents retrieved by VSM, which get boosted by the fusion formula, are much more likely to dominate the higher ranks of the VSM-HITS combined results than documents retrieved by the HITS systems. When VSM and TM system results are combined, however, documents retrieved by either system will get the overlap boost. Unfortunately, the performance level of VSM system may be degraded since documents of high ranks by the TM system are less likely to be relevant than those by VSM systems as implied by the lower performance levels of TM systems. In fact, the proportion and the size of non-relevant documents with high overlap were much larger in TM than in VSM systems, which may very well account for the adverse effect of TM systems on fusion results.
[
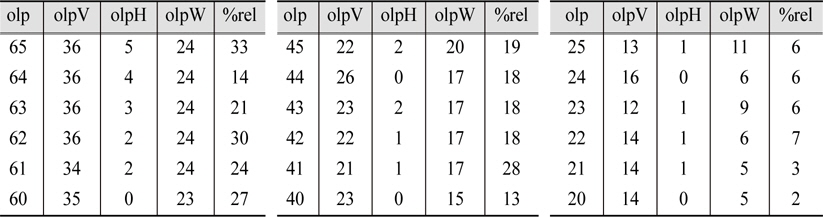
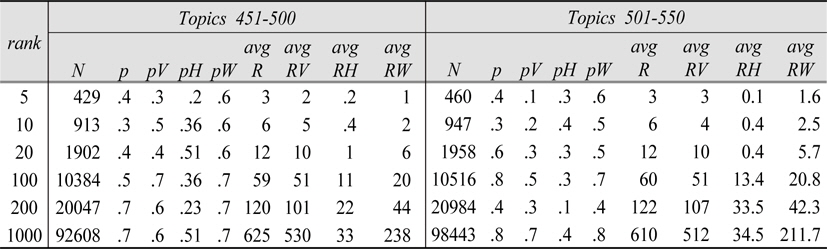
Overlap Statistics for all systems at rank 100
OLP = number of systems that retrieved a document OLPV = number of VSM systems that retrieved a document OLPH = number of HITS systems that retrieved a document OLPW = number of WD (TM) systems that retrieved a document %REL = percentage of relevant document in a partition defined by OLP
2.3 Top System Fusion
While intra- and inter-fusion experiments study the general effect of comprehensive fusion,
The fusion formulas tested in top system fusion are enumerated below. In the first column are the suffixes attached to system names to indicate the fusion formula used.
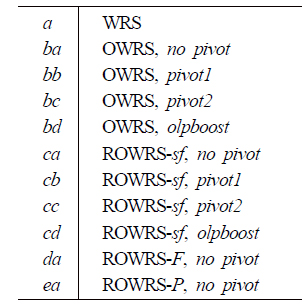
Three different rank-based system performance measures were tested for the ROWRS formula. ROWRS-
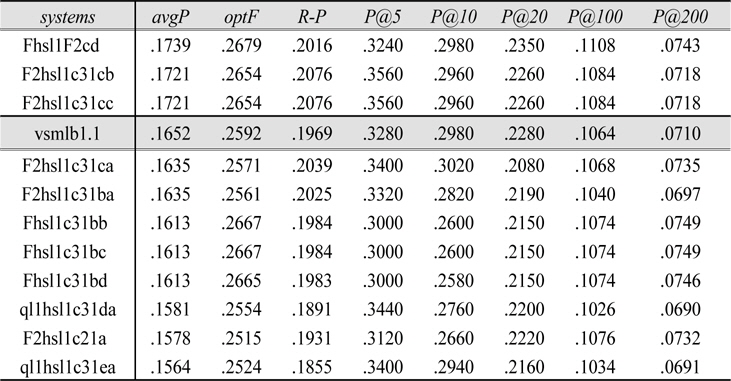
Table 6, which lists the best results from each fusion formula along with the baseline of the best single system result
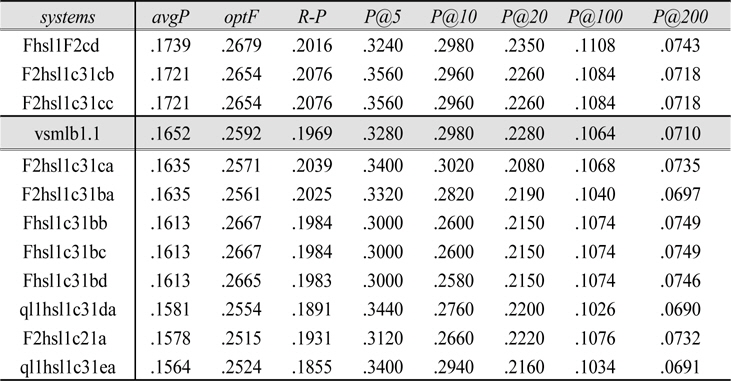
Top System Fusion results
Comparison of rank-based measures shows the success/failure measure to be superior to precision- or effectiveness-based measures for ROWRS. As for top-system pivot variations, the ROWRS formula seems to work best with the heaviest emphasis on the top system contribution (
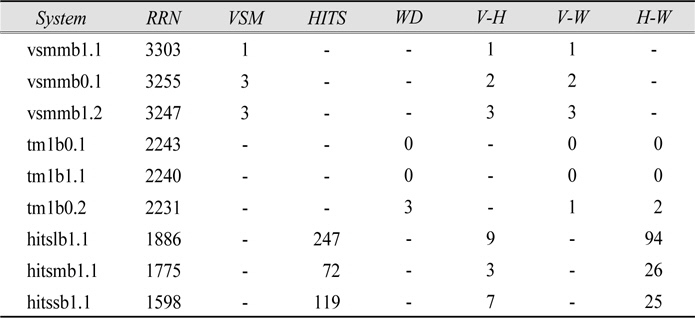
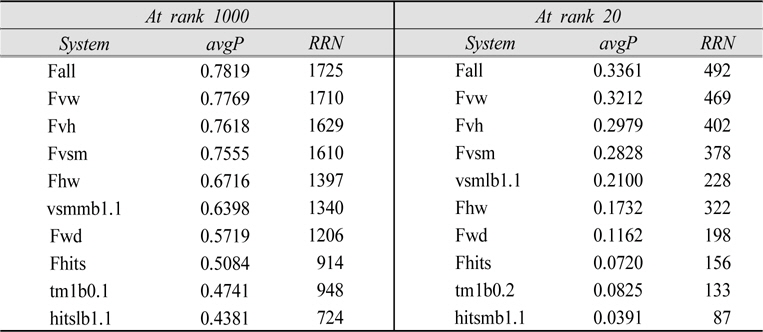
In section 4.2.1 where intra-fusion results were discussed, it was suggested that HITS systems had the most to gain by fusion due to their diverse solution spaces. One way to confirm such a hypothesis is to examine the degree of overlap in relevant documents retrieved by HITS systems. Table 7 lists the total number of relevant documents retrieved(RRN) as well as the number of relevant documents uniquely retrieved by a system within a given method(e.g. VSM, HITS, TM), and thus describe the degree of overlap in relevant documents retrieved. The VSM, HITS, and TM columns indicate that the solution spaces for HITS systems overlap much less than those of VSM or TM systems. More specifically, the unique contributions of the top 3 HITS systems, which are considerably larger than those of the top 3 VSM or TM systems, imply that the HITS method has the most to gain by fusion.Examination of the inter-method fusion results in section 4.2.2 also merited overlap analysis. Larger numbers in the H-W column of Table 7 indicate the greater potential gain for HITS-TM fusion, which we saw in section 4.2.2.
[

Number of Relevant Documents Retrieved at rank 1000
The fact that VSM-HITS fusion results were closer to the upper bound(defined by the best VSM system) while VSM-TM fusion results fell more towards the middle of the upper and lower bound(defined by the best VSM and TM systems) requires different kind of overlap analysis to explain. The overlap statistics table(Table 5) shows fairly even number of overlap counts for VSM and TM(OLPV and OLPW columns) but hardly any overlap count for HITS(OLPH column) at high ranks. Even at lower ranks, documents retrieved by many HITS systems are small in numbers compared to VSM and TM. Since fusion formulas reward the overlapped documents, documents retrieved by VSM systems are much more likely to influence the VSM-HITS combined results than documents retrieved by HITS systems. Thus, the VSM-HITS fusion results are closer to the VSM baseline than the HITS baseline. When VSM and TM system results are combined, however, documents retrieved by either system get the overlap boost and the results of VSM systems get degraded by the large number of non-relevant documents with high overlap in TM systems.
Table 8, which describes the maximum potential for fusion, shows that combining all VSM systems(
Optimum Performance Levels
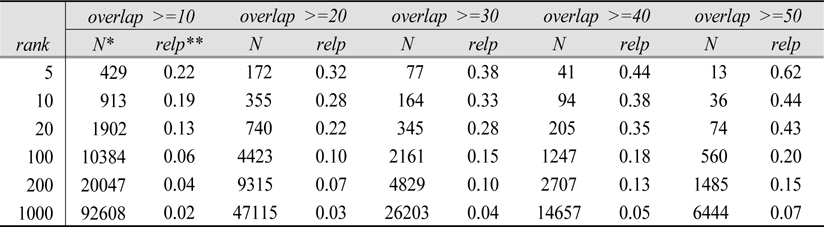
Table 9, which summarizes the overlap statistics tables to display the density of relevant documents at various ranks and overlap, show the higher relevance density(i.e. proportion of relevant documents in a given overlap) for not only higher overlap but also higher ranks. Unfortunately, the relevance density is below 50%, which suggests that overlap without the consideration of document ranking and systems that retrieved the overlapped document may not always be a good indicator of relevance. In fact, more documents are apt to be non-relevant than relevant for a given overlap in the current experiment, although more overlapped documents are more likely to be relevant than less overlapped documents.
[
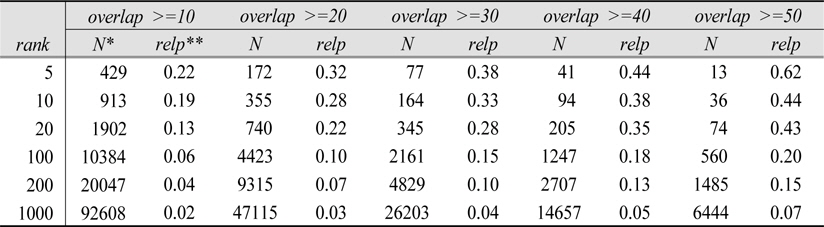
Relevance Density in Overlapped Documents for all systems, Topics 451-500
Table 10, which relates overlap with not only relevance but also document ranks, shows that in general, non-relevant documents are ranked lower than relevant documents with the same overlap in VSM and TM systems but the reverse is true for HITS systems. This peculiar pattern of overlap in HITS systems may explain why the rank-based fusion formula did not do well in HITS fusion.
[

Average Ranks in Overlapped Documents for all systems with Overlap >= 10*
In this study, we explored the question of whether combining text-, link- and classification-based retrieval methods can improve the Web search performance by examining the effects of combining retrieval results of text-, link-, and classification-based retrieval systems using the WT10g test collection and Yahoo directory information. The retrieval results of text-based systems based on the Vector Space Model, link-based systems using the HITS algorithm, and classification-based systems using Yahoo categories were combined using a rank-based fusion formula. In addition, a handful of the best performing systems from each method were combined with variations of the rank-based fusion formulas to explore the optimization of fusion parameters.
The differences in retrieval methods that affected different retrieval outcomes appeared to influence both intra- and inter-method fusion, where the system results were combined within and across retrieval methods. Interestingly, the only intra-method fusion that enhanced the baseline performance of the best fusion component results occurred with the worse performing HITS systems. Intra-method fusion of VSM and TM systems behaved similarly in that fusion detracted from the baseline performance although combining TM system results degraded baseline results much more severely than VSM fusion when using the SM formula.
To investigate the possible reasons why combining HITS system results enhanced retrieval performance while combining VSM or TM system results degraded the baseline performance, we examined the degree of overlap in relevant documents in HITS systems in comparisons with VSM and TM systems and found that HITS systems retrieved much more diverse sets of relevant documents than VSM or TM systems and thus had the most to gain by fusion.
In top system fusion, where variations of WRS formulas were used to combine the results of a few top systems from each method in an attempt to improve the retrieval performance of the top system results while minimizing both the computational overhead and the adverse contributions from the poor performing systems, the fusion succeeded in enhancing the best single system result. Top system pivot with the overlap boost, which emphasized progressively the contributions of overlapped top system documents showed the best results, which suggests that leveraging overlap in conjunction with the rankings of the best performing systems is an advantageous fusion approach.
Perhaps the most significant findings of the study came from the overlap analysis, which revealed that the total number of relevant documents in the combined result sets of VSM, HITS, and TM systems were much more than the largest number of relevant documents retrieved by any single system. This observation disputes the implicit null hypothesis against fusion(i.e., there is nothing to be gained by combining single system results) and thus strongly suggests that the solution spaces of text-, link-, and classification-based retrieval methods are diverse enough for fusion to be beneficial. It is important to note that HITS runs, despite their lower performance levels than VSM and TM runs, appeared to have the most unique contributions to the fusion pool. The high degree of unique contributions by HITS systems could be a reflection of its retrieval approach, which is distinct from VSM and TM systems with heavy reliance on text-based retrieval techniques.
One of the most important issues for fusion is the optimization of the fusion formula. Given less than the optimum results by individual systems, how can we combine them to bring up the ranking of the relevant documents? We have seen in the overlap analysis that, although the documents retrieved by more systems are more likely to be relevant, the simple number of systems that retrieve a document is not a good indicator for relevance since highly overlapped documents were often more likely to be non-relevant than relevant. One way to compensate for this is to rely on top performing systems as was done in top system fusion. Top system fusion, however, tends to ignore the unique contributions with its heavy emphasis on overlap. One of the most difficult challenges of top system fusion, as well as fusion in general, is devising a method that rewards both the overlapped and unique contributions to the combined solution space.
The study selected retrieval methods that leverage three distinct sources of evidence on the Web and implemented a variety of ordinary systems and combined their retrieval results using ad-hoc variations of common fusion formulas. Although the performance of the best fusion result was only marginally better than the best individual result, the analysis of overlap strongly suggested that the solution spaces of text-, link-, and classification-based retrieval methods were diverse enough for fusion to be beneficial. Furthermore, analysis of the results revealed much insight concerning the effects of system parameters, the relationship between overlap, document ranking and relevance, and important characteristics of the fusion environment. In addition to establishing the existence of the fusion potential for Web IR, this study has provided a rich foundation on which to continue the exploration of fusion in future research.
There are almost as many possibilities for future research in fusion as there are fusion combinations and fusion formulas. The main contributions of this study are twofold. First, it confirms the viability of fusion for Web IR by not only determining the existence of the fusion potential in the combined solution spaces of text-, link-, and classification-based retrieval methods but also by demonstrating that relatively simple implementation of fusion does improve the retrieval performance. Furthermore, the study lays the groundwork for future research, where the current research framework can be extended in many dimensions to explore various aspects of fusion.