The goal of this study is to seek for the method of effective DB conversion and related system development for the integrated KORMARC Format on the basis of the case of Sogang University Library. Since the integrated KORMARC bibliographic format was established, libraries have been converting bibliographic DB according to the new format. Loyola Library of Sogang University internally proceeded DB conversion using bibliographic DB convertor, which was developed and customized with a system vendor for Sogang University Library. The internal conversion enabled to correct or supplement bibliographic data errors. Besides, it enhanced stability of conversion and shortened the project time by adopting sampling conversion method. It was effective to reduce the additional work for DB quality maintenance, so this kind of conversion is recommendable to the library that has limited manpower for manual data correction.
2005년12월 국립중앙도서관은 새로운 KORMARC 표준인 ‘한국문헌자동화목록형식-통합서지용’ 즉, 통합서지용 KORMARC을 발표하였다. 통합서지용 KORMARC은 기존의 KORMARC 특성을 일부 승계하고 있으나, 국제적표준으로 인정되고 있는 MARC21과 같이 하나의 입력 원칙으로 여러자료 유형에 통용할 수 있도록 하였다. 따라서 기존의 여러 자료유형별로 규칙이 분리되어 조기성과 필드 사용의 자유로움이 부족했던 면을 극복한 통합형표준이 완성되었다고 할 수 있다.
이를 제정한 국립중앙도서관이 최초로 통합서지용 KORMARC을 적용하여 서지 DB를 구축하였고, 2007년 12월에는 대학도서관 중심 종합목록의 통합서지용 KORMARC 적용을 위하여 한국교육학술정보원(이하, KERIS)에서 ‘KERIS 종합목록 입력지침-한국문헌자동화목록형식 통합서지용’을 발표하였다. 이후 대학도서관으로서는 처음으로 중앙대학교 도서관에서 2009년 3월 KERIS 변환기를 통하여 통합서지용 KORMARC으로 서지 DB를 변환하고, 목록에 이를 적용하였다. 이어 2009년 6월 KERIS에서는 ‘KERIS 종합목록 데이터 통합서지용 KOMRARC 형식 적용’을 공표
이로써 많은 대학도서관이 국가표준의 변경이라는 이유와 더불어 통합서지용 KORMARC이 기존 자료유형별 KORMARC 보다 현시적으로 적합한 포맷이라는 판단에 의해 자관의 서지 DB구축에 새로운 표준을 적용하려는 준비를 시작하였다. 따라서 자료유형별로 필드 사용이 상이하여 자료의 매체에 따라 편목에 불편함이 있었던 점이 해소되었고, 최근의 자료 매체 경향인 전자자료에 대한 수용과 현시적인 용어 사용 등으로 최신성이 확보되었다. 또한 국외서 편목에서 사용되는 MARC21과 유사하여 편목상 혼란을 줄인 점(조상호 2010, 74-75) 등으로 많은 도서관이 통합서지용 KORMARC으로 전환하기 시작하였다.
이러한 가운데 서강대학교 로욜라도서관(이하, 서강대학교 도서관)도 2010년에 새로운 국가표준인 통합서지용 KORMARC을 자관에 적용하기로 결정하여, 특히 타기관의 공용 변환기
아울러 이러한 서강대 도서관의 사례 연구를 통하여 현재의 통합서지용 KORMARC의 변환 뿐 아니라, 이어지는 다른 목록형식 및 기술규칙의 개정을 도서관 목록에 적용할 시에도 그 과정에 대한 유사한 관점과 원리를 적용함으로써 목록의 새로운 내용과 형식으로의 전환과정에 필요한 이론적이고 실무적인 정보를 제공할 수 있을 것으로 기대해 본다.
현재 진행되고 있는 변화 중 하나는 MARC21에 반영된 RDA에 관한 것이다. 우리나라 대학도서관 중 국외서 편목 기술규칙으로 AACR2를 사용하는 곳이 다수이나, LC에서 이미 적용되고 있는 RDA는 우리 목록에도 전체적 적용이 머지 않았다.(신규 데이터 등 부분적으로는 적용중임.) 이때 MARC21 데이터에 대해 소급 데이터를 포함한 전체 데이터를 RDA로 변환하고자 한다면 기구축된 서지 DB의 변환이 필요하다. 일부 필드와 기술 내용의 매핑이 필요하고 변환기를 통한 DB 레코드의 재정비가 사업으로 진행될 것이다.
그리고 2014년 5월, RDA 적용을 고려한 통합서지용 KORMARC의 개정이 고시
아울러 이 사례 연구는 자체 변환이라는 특수성을 감안할 때, 변환 주체인 사서가 과정 전체를 책임질 수 있는 전반적 지식을 갖출 것, 필드 개개 항목을 정확하게 파악할 것, 자관 데이터의 단점을 보완할 기회로 삼기 위해 자관 서지 데이터의 특성을 분석해 낼 것 등을 전제로 하고 있으므로, 이를 위한 효율적인 방법과 정보에 대하여 공유하고자 한다.
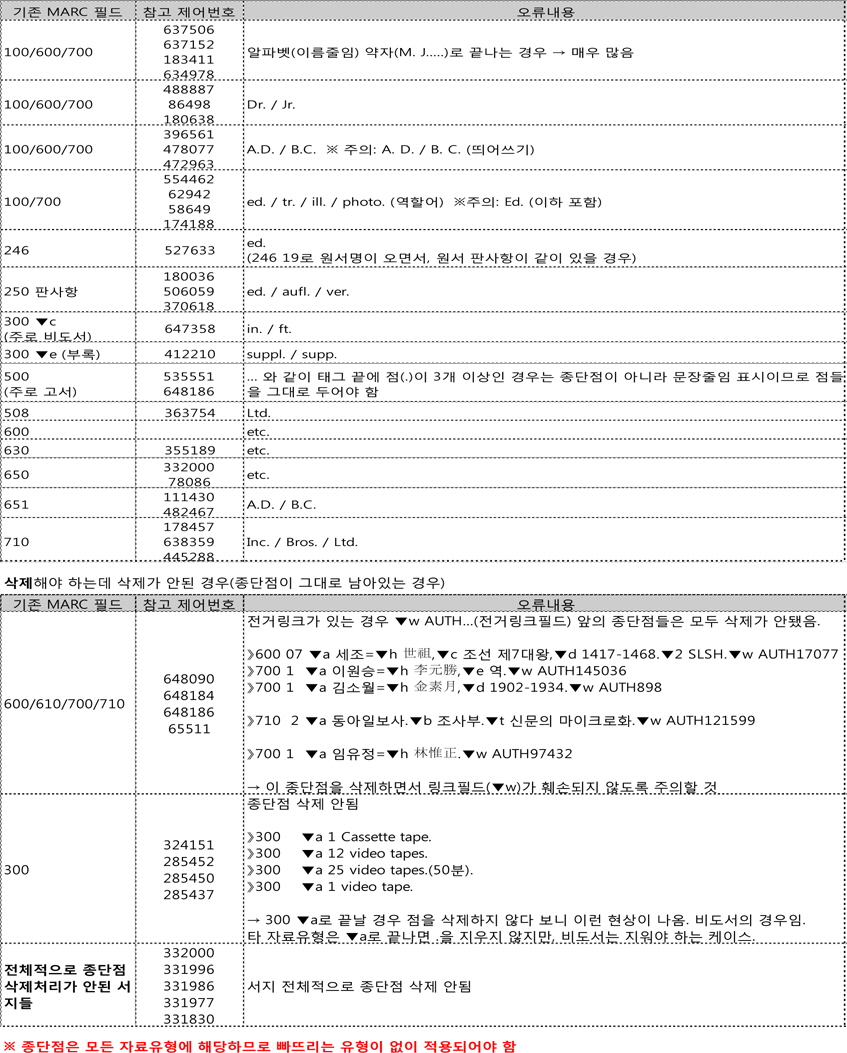
통합서지용 KORMARC의 탄생과 함께 KORMARC 형식 사용과 보완에 대한 연구의 요구가 증가하였다. 그 시기를 전후로 하여 발표된 연구는 주로 통합서지용 KORMARC 자체의 형식적인 특성을 주지시키며 보완점을 지적한 함으로써 MARC의 주 이용층인 사서가 통합서지용 KORMARC을 이해할 수 있게 하고, 향후 개정의 시점에서 해결하여야 할 문제점에 대해 함께 고민하게 하였다. 이러한 유형에 해당하는 대표적인 연구로서 이경호, 김정현의 연구(2006)가 있다. 이들 연구에서는 KORMARC 포맷의 통합 경위와 통합 내용을 서지형식의 통합, KCR4의 수용, 신설 필드를 들어 설명하고, KORMARC 형식의 구조적 문제점과 더불어 입력원칙의 미비함, 필드 반복 여부 등의 보완 사항을 개진하였다.
두 번째 유형은 본격적으로 통합서지용 KORMARC 형식을 적용하기 위한 논의로서, 이지원의 연구(2009)에서는 기존 KORMARC 형식에서 통합서지용 KORMARC으로의 사용 전환이 필요한 이유와 이 작업에 필요한 일반적인 절차를 매핑정의서, 변환기 개발, 프로그램 수정, 공동목록에서의 변화 등을 들어 제시하였고, 아울러 초기 KERIS 변환기를 사용하여 변환한 대학도서관 2 개관(중앙대, 연세대)을 언급하였다.
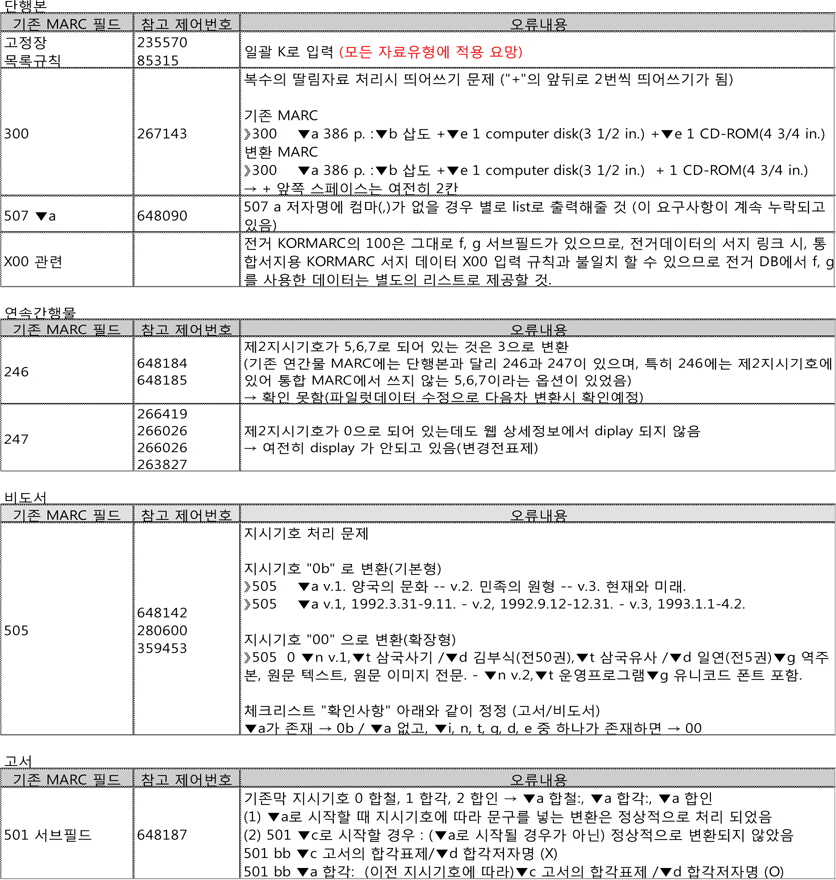
세 번째 유형은 본격적으로 대학도서관에서 통합서지용 KORMARC으로의 사용 전환을 하였던 사례 발표 연구로서, 대학도서관 최초로 통합서지용 KORMARC을 적용한 중앙대학교 도서관의 시스템 구축에 관한 것이다. 임현의 사례 보고(2009)와 조상호의 논문(2010)에서는 중앙대학교 도서관이 KERIS의 변환기를 이용하여 변환 작업을 수행하였던 내용과 함께 향후 통합서지용 KORMARC의 확대 및 향후과제에 관하여 제안하였다. 중앙대에서 KERIS 변환기를 선택한 이유는 변환 프로그램이 이미 개발 완성되어 있으므로 프로그램의 안정성이 확보되어 있고, 시스템벤더에 별도의 신규 프로그램 개발을 의뢰해야 하는부담을 덜 수 있다는 점을 들었다. DB 변환의 과정에 있어서는 KERIS 샘플 변환 1회 이후, 실제 데이터 40만건을 3회 전체 변환하는 방식을 택하였다. 사후 데이터 정규화 과정에서는 1,000여건의 오류 데이터 리스트를 변환 기관으로부터 받아 수작업 또는 일괄 시스템처리 하였다.(조상호 2010, 78-81)
본 연구의 특징은 변환 수단과 변환 방법의 상이함에 따라, KERIS와 같은 외부 공공 기관의 변환기를 통하지 않고 자관에 최적화된 변환기를 별도 개발하여 개별 도서관의 자체 변환을 시도한 사례 연구로 볼 수 있다. 내용적으로는 자관 데이터의 특성이 최대한 반영된 변환기를 개발하여 사용하므로 최소한의 샘플 변환과 최종 1회의 전체 DB 변환으로 변환 과정을 간략화하고, 최종 오류 데이터 또한 소수화할 수 있도록 한 방법에 대한 것이다.
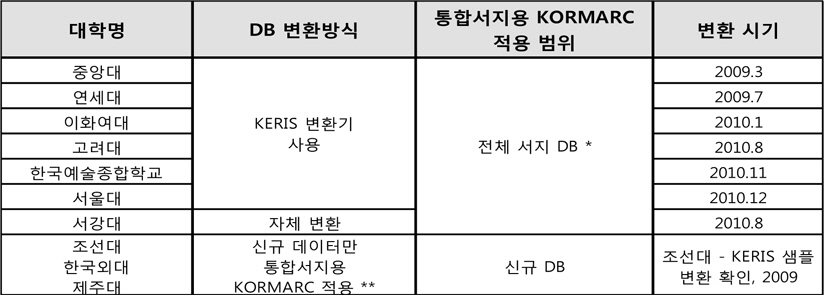
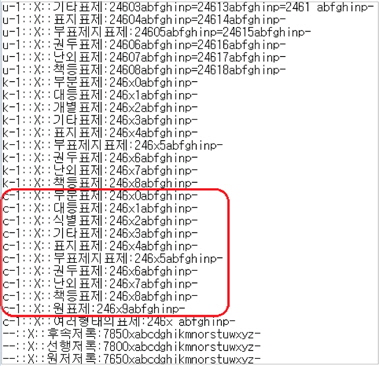
서강대학교 도서관에서 변환사업을진행할 2010년 당시에는 <표 1>과 같이총 10개 대학도서관이 통합서지용 KORMARC으로 데이터 변환을 한 것으로 집계되었다.(KERIS 종합목록 운영위원회 회의자료(2011. 4. 13) 2011, 5)
[<표 1>] 대학도서관 통합서지용 KORMARC 적용 현황 (2011. 4. 당시)
대학도서관 통합서지용 KORMARC 적용 현황 (2011. 4. 당시)
즉 7개 대학도서관이 데이터 전체를 변환하였고, 3개의 대학은 신규자료만 통합서지용 KORMARC을 적용하였다. 전체변환 7개 대학중 6개의 대학은KERIS 변환기를 통하여 전체 데이터를 변환하였고, 당시 자체적으로 대상 데이터를 전량 변환한 대학도서관은 서강대학교 도서관이 유일한 상황이었다.
2014년 현재는 전국 대학도서관 중 총 38개 대학이 통합서지용 KORMARC으로 사용 전환을 한 상태
가. 자체 변환 선택
KERIS의 변환기를 통한 데이터 변환은 공공 기관의 변환기를 이용하여 무료로 DB를 변환할 수 있고, 종합목록의 기준에 맞추어진 변환기를 통한 변환이라는 점에서 장점이 있다. 서강대 도서관과 같이 자체적으로 변환기 요구조건서를 발부하고 이에 맞춰 변환사업을 할 때는 경우에 따라 공임이 발생할 수 있다.
통합서지용 KORMARC으로의 변환을 위해서는 다음과 같은 기본 작업이 필요하다.
①소급데이터에 대한 분석 : 변환할 기존 자관 서지데이터를 통합서지용 KORMARC 포맷과 비교 분석하여 정확한 매핑룰을 도출하고, 표준 원칙 이외의 변수(예: 로컬규칙 등)에 대한 적절한 처리 방식을 완성 ② 위 작업을 바탕으로 한 변환기(Converter) 완성 ③ 소급데이터의 반출(Exporting) ④ 변환 처리(Converting) ⑤ 변환 완료된 데이터의 반입(Importing) ⑥ 변환 데이터의 검증 ⑦ 홈페이지에서의 데이터 출력(상세정보)과 검색을 위한 세부 설정 ⑧ 신규 데이터 입력을 위한 통합서지용 KORMARC 에디터(Editor) 구비 및 환경설정 ⑨ 신규 데이터 작성 처리(DB Insert/Update/Delete) 검증
KERIS의 변환기를 사용하는 경우에는 ④만을 KERIS에서 처리해주고, 개별 도서관이 유지보수 계약을 맺고 있는시스템벤더가 약간의 데이터 보정 프로그램처리, 반입·반출, 웹설정 정상화를 담당한다. 그러나 변환 작업 전체를 도서관의 주도하에 자체 변환으로 진행할 경우, 도서관 관리하에 선정된 해당 시스템 벤더를 ①~⑨ 전 과정 전 기간에 걸쳐 필요 시 마다 투입할 수 있으며, 특히 ①에 대해서는 타기관 공용 변환 프로그램에서 처리할 수 없는 자관의 데이터 변수를 자체 변환기에 신규로 프로그래밍 함으로써, 자관 인력이 수작업으로 일일히 보정작업을 해야 하는 영역을 보완할 수 있다. 특히 KORMARC에 정의되지 않은 자관의 규칙과, 표준 기술방식과는 다르게 일상적으로 기술한 내용을 통합서지용 KORMARC 방식에 맞추어 일괄 변환하는 것은 타기관 변환기를 통해서는 할 수 없는 부분으로서, 이를 기계적으로 일괄처리해 줌으로써 자관의 인력적 부담을 최소화할 수 있다.
또한 도서관의 소수 인력을 통한 작업시간 장기화를 막기 위해, 자관의 검증(데이터 검증/웹설정 검증/프로그램 검증) 전에 시스템 벤더 내부적으로 사전 테스트를 하여 보고하도록 하는 단계를 마련할 수 있다는 점도 장점이다. 즉 수작업으로 오류 데이터를 일일히 바로 잡을 인력적 시간적 여력이 없을 경우, 되도록 변환 프로그램(변환기 로직)에 수작업의 영역에 있는 데이터 보정 작업 내용을 최대한 포함시켜 일괄변환 하도록 하고 변환 후의 데이터 검증작업에서는 시스템 벤더 내부의 사전 검증 과정을 설치함으로써, 사서는1차 검증된 내용으로 데이터의 교정 작업에 투입될 수 있기 때문에 인력과 시간을 절약할 수 있다. 이것은 검증에 필요한 까다로운 과정과 시간은 단축하고 도서관이 데이터 내용 자체의 정확성 검증에 집중할 수 있도록 해준다.
다음으로 타기관 공용 변환기에 의한 DB 변환 시에는 반출한 전체 데이터를 해당 기관(예를 들면, KERIS)에 보낸 후 변환이 완료될 때까지 대기하였다가 변환 데이터가 도착하면 그 시점부터 변환결과를 분석하고 검증할 수 있다. 이로 인해 대기시간이 발생하고 이 변환 검증 결과를 보정 프로그램에 적용하는 시기도 자체적으로 정할 수 없으므로 사업진행 면에서 도서관이 일정을 주도하는 데 다소 어려운 면이 있다. 이런 점으로 볼 때 결과적으로 시스템 벤더를 선정한 후 도서관 주도하에 자체 변환 하는 것이 시간과 효율의 입장에서 합리적인 선택이 될 수 있다.
아울러 변환 시 MARC 입력 규칙에 따른 고정장과 가변장의 변환 이 외, ‘필드(태그) 끝의 구두점’인 종단점(이하, 종단점) 제거와 같은 추가적인 데이터 일괄 갱신을 병행할 수 있다. 특히 자관에서 종단점을 사용하는 방향에 맞춰 프로그램을 제안함으로써 소급 데이터에도 일관성 있게 종단점 규칙을 적용할 수 있다. 이러한 부가적인 프로그램을 사업에 포함하여 병행 처리할 수 있는 것 등도 추가적인 이점으로 볼 수 있다.
그러므로 관내에서 사업에 투입할 수 있는 인력, 사업 진행에 있어 시간적 여유, 사업 전체의 원활한 통제와 진행 등의 도서관측 상황대비, 사업에 투자할 예산 등을 고려하여 무리함이 없다면 이러한 방식이 효율적이라고 판단된다. 특히 수작업의 인력이 절대 부족한 기관과 도서관의 일정 및 업무 방식 위주로 변환 사업을 추진하려는 기관에 적합하다. 단 변환 사업의 진행 주체인 사서가 새로운 MARC 포맷의 내용과 변환 사업의 전체적 특성에 대해 충분히 인지하고 있어야 한다.
나. 자체 변환의 의의
이러한 자체 변환의 가장 큰 의의 중 하나는 해당 도서관의 사서가 주도권을 가지고 변환 작업을 추진할 수 있다는 점이다. 기존의 많은 전산 관련 사업은 시스템 벤더 및 관련 공공 기관의 의도와 일정에 맞추어 진행되는 경우가 많았다. 그러나 전산에 대한 해박함이 없어도 MARC과 같은 도서관 표준은 누구보다 매일의 일상에서 이를 사용하는 편목 사서가 내용적으로 가장 잘 파악하고 있다는 점을 간과하여서는 안될 것이다. 따라서 서지 DB를 새로운 표준 포맷에 맞춰 변환하는 사업이야 말로 표준 및 자관 DB에 대한 이해도를 바탕으로 사서와 도서관이 주도적으로 실제적 밑그림을 그릴 수 있는 사업이다.
실제적으로 대학도서관이 종합목록과 같은 최후 데이터 업로드 대상 기관의 포맷에 적합한 데이터를 구축해 가는 것도 중요하지만, 이러한 DB 변환 사업은 해당 도서관이 주체적으로 국가표준에 맞는 표준적 데이터를 구축하고 적극적으로 새 표준을 적용하는 시도의 일환이 될수있기 때문에, 변환 작업에 있어 그것이 공용 변환기를 통한 것이든 자체 변환 사업을 통한 것이든 개별도서관이 변환 작업의 중심이 되어야 한다는 것은 당연한 논리일 것이다. 다만 자체 변환은 도서관이 변환의 일정과 세부적인 상황에 전체적으로 개입하여 주도하여야 하므로 이러한 자발적이고 적극적인 자세가 더욱 요구되는 작업 방식이라 할 수 있다.
또한 자체 변환 진행 과정을 통해 해당 도서관의 전체 서지 DB에 대해 통찰하여 문제점을 발견, 수정 보완해 나갈 수 있고 기존의 잘못된 편목 방식이나 습관을 조정하거나 바로잡을 수 있다. 즉 서지 DB를 재정비하는 충분한 기회가 될 수 있다.
이와 함께 전 필드에 걸친 매핑 테이블이나 변환기 체크리스트 등을 구성하는 과정을 통하여 개별도서관의 향후 목록 원칙을 확정하고 스탭매뉴얼을 완성할 수 있다는 점에서도 의의가 있다고 판단된다.
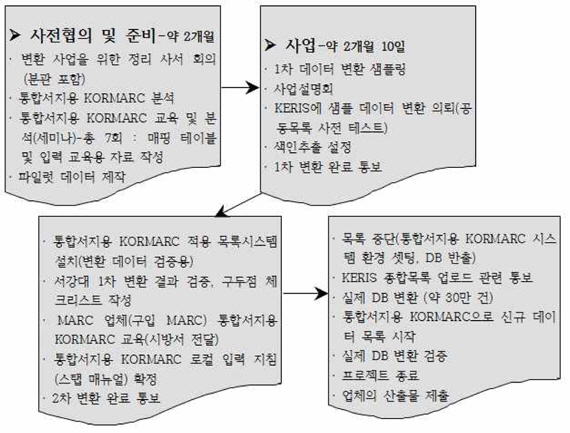
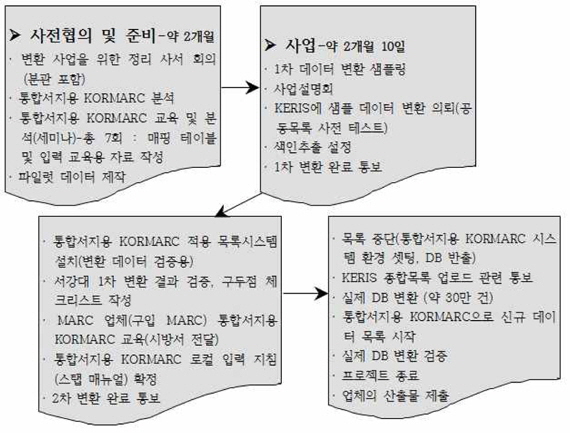
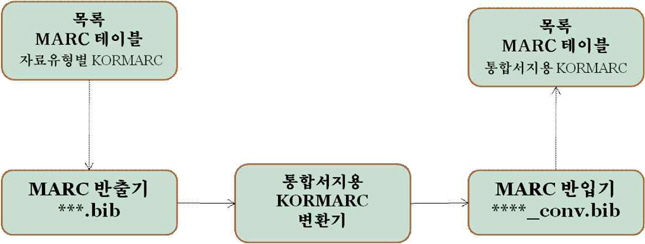
통합서지용 KORMARC으로의 변환을 위한 준비사항과 전체적인 작업 진행은 <그림 1>과 같다.
<그림 1>의 작업 진행 개요를 통해 알 수 있는 것과 같이 서강대학교 도서관에서는 서지 DB의 변환에 들어가기에 앞서 변환 사업의 주체로서의 도서관 즉, 정리사서의 입장에서 준비할 것과 전산적 변환을 시행할 시스템 벤더가 진행상 준비할 사항에 대해 명확히 구분하는 일을 선행하였다.
도서관은 첫째, 변환기에 포함될 MARC 필드의 매핑 테이블을 작성하고 몇 차례에 걸친 샘플링 변환이 거듭됨에 따라 이를 도서관 측 테스트를 위한 체크리스트로 활용하면서, 변환기 보완 내용을 갱신할 때 마다체크리스트도 함께 갱신하였다. 이 과정에서 수작업의 최소화를 위해 기계적으로 일괄 변경이 가능한 내용이 있는지에 대한 추가적인 확인 작업을 반복하였다.
둘째, 통합서지용 KORMARC에 대한 로컬 입력 지침을 확정하기 위하여 작업 일정 중에 편목 스탭 매뉴얼을 완성하였다.
셋째, 파일럿 데이터를 자료유형별로 준비하였다. 이는 각 유형별로 변경된 입력지침의 사례를 최대한 포함한 테스트 데이터로서, 변환 후 파일럿 데이터를 우선 점검함으로써 변환의 누락을 하나의 서지 데이터 내에서 최대한 확인할 수 있도록 도서관이 직접 준비하여 서지 DB 내에 포함시켰다.
넷째, 종합목록 참여기관은 사후 종합목록 업로드를 고려하여 KERIS 변환기에 자관 데이터를 샘플링 변환해 보도록 의뢰
다섯째, 변환 사업의 전체적 일정은 도서관이 주도하여 관리하였다. 일정이 늦어지지 않도록 점검하며, 사업 종료 후 시스템 벤더의 산출물 등 관련 기록물을 확인하였다. 특히 실제 DB 변환과 검증 기간 내 주의하여야 할 재정리 및 소장분리
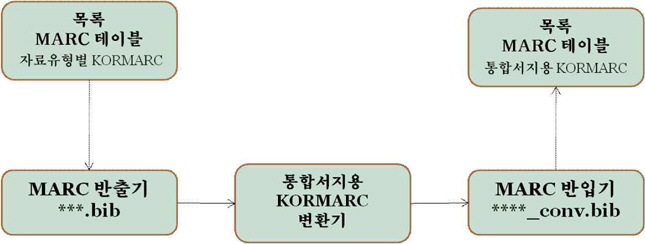
변환기를 만들고 DB 변환을 시행하였던 시스템 벤더의 작업 진행은 다음 <그림 2>와 같다.
즉, 시스템 벤더는 자관 서지데이터를 반출하여 변환기(종단점 정리 프로그램 포함)를 통해 변환한 후 다시 DB에 반입하는 과정에 있어 샘플링 변환과 실제 DB 변환으로 구분하여 반복하였다. 변환기 로직은 표준을 바탕으로 하되 해당 도서관 DB의 서지통정 상태에 따라 오류 또는 보완의 필요성에 의해 내용적으로 커스터마이징될 수 있어야 한다.
매핑 테이블은 MARC 변환기(Converter)에 필요한 주요 요건사항을 정리한 것으로서, 시스템 벤더에 요청하는 RFP(제안요청) 내용 중 가장 중요한 부분이다. 시스템 벤더는 도서관의 요구사항이 담긴 매핑 테이블을 중심으로 변환기를 구성하고, 향후 이 매핑 테이블은 변환 결과를 도서관이 점검할 때 체크리스트로 활용할 수 있어야 한다.
이러한 매핑 테이블은 먼저 ‘국립중앙도서관 매핑표’
특히 자체 변환 시에는 자관의 데이터 특성을 파악하여 기본 매핑 테이블 위에 많은 부분을 추가할 수 있으므로, 서강대학교 도서관의 경우에도 장기간 습관적으로 오입력한 코드와 표준에 어긋난 기술 등을 찾아내어 일괄 변환함으로써 좀 더 표준에 근접한 DB가 될 수 있도록 하였다. 이는 개개의 도서관 마다 특성이 다르므로 자관 데이터에 대한 분석이 선행되어야 한다.
가. 변환기간 단축을 위한 합리적 변환 방법 채택
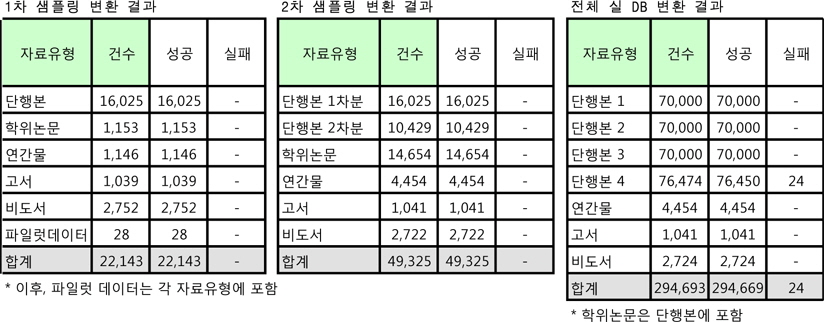
기존의 변환 사례에서는 여러 차례 실제 DB를 전량 직접 변환하는 방식이 많았다. 즉, 3~4차례 실제 DB를 변환하여 이로 인해 변환에 약 2~3개월이 소요되는 경우도 있었다. 그러나 이번 변환 작업은 변환 데이터 군을 점진적으로 늘려가는 방식을 채택하여 1~2차 샘플링 변환을 거쳐 3차 최종 약식 점검 후 실제 DB를 1회에 전량 변환하도록 하였다.
샘플 데이터군의 추출방식은 각 자료유형별 DB 구성률을 분석한 후 가장 많은 부분을 차지하는 단행본과 연간물에 대하여는 랜덤 추출기를 통하여 MARC 작성 기간범위가 충분히 섞이도록 샘플링하고, 데이터 수가 상대적으로 적은 나머지 유형은 데이터 전체를 샘플군으로 확정하였다.
1차 샘플링 변환 후 2차 샘플링 변환 시 단행본과 연간물 샘플군을 변경하여 재구성함과 동시에 단행본의 샘플수를 추가로 구성하였다.
이러한 방식은 30만건의 실제 DB 전체 변환 횟수를 최소화하면서도 최종 변환 이전 샘플군 변환 시 충분히 변환기를 수정 보완함으로써 변환을 할 때 오류 범위를 축소할 수 있으며, 결과적으로 변환 시간과 수동으로 검증할 데이터의 양을 줄일 수 있다는 장점이 있다.
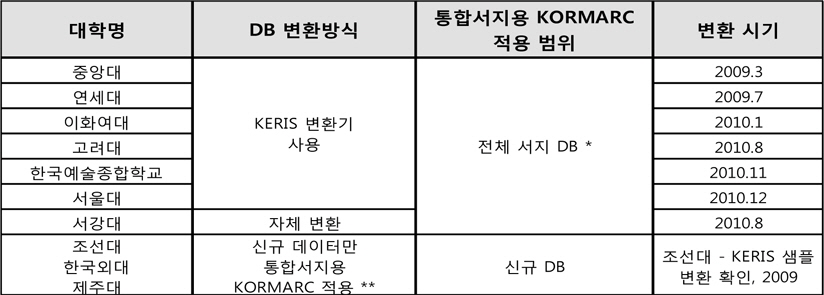
DB 변환 결과는 다음 <표 2>와 같다. 총 3회의 변환 작업 중 1, 2회는 약 2만, 5만 건의 데이터로 샘플링 변환하고 최종 전체 DB 변환에서 약 30만건을 처리하였으며, 변환 실패 데이터는 24건에 불과하였다.
DB 변환 결과
위와 같이 오류 데이터의 양을 최소화하여 단기간 제한된 인력이 수작업 가능한 범위로 결과를 도출하는 것이 관건이라 할 수 있다. 기계 보정이 되지 않는 소수의 최종 변환 오류데이터는 별도의 리스트로 제공되었으며, 수작업으로 수정 보완하기에 충분히 용이한 수량이었다.
나. 파일럿 데이터의 작성
자료유형별로 준비되는 파일럿 데이터는 수많은 데이터를 통해 검증할 수 있는 변환 내용을 한 서지 데이터에서 일목요연하게 일괄 확인할 수 있으므로 이를 변환 대상 샘플군에 추가적으로 포함하도록 하였다. 변환 대상이 되는 필드들의 내용을 한 서지 내에서 최대한 나열하고, 변환 결과 점검 시 1차적으로 확인하였다. 자료유형별 KORMARC은 필드의 사용이 자료유형별로 상이한 부분이 있으므로 한 자료유형에서 변환이 확인된 내용이라 할지라도 각 자료유형별로 다시 변환 여부를 확인하여야 한다.
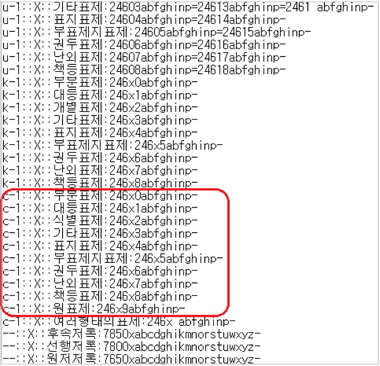
다. 종단점 정리 프로그램 구축
통합서지용 KORMARC으로의 변환 작업을 통하여 MARC 목록 작업에 있어 종단점에 대한 개념을 재고하였을 때, 종단점을 일괄 제거하는 것으로 결정함에 따라 이에 대한 프로그램을 추가로 구축하여 MARC 데이터 변환 후 별도로 실행하였다.
현재의 기계가독형 목록은 과거 카드 목록과 달리 MARC 포맷 특성상 데이터 종단 지점 표시 역할이 약화되었고, KERIS 종합목록 입력 지침 등의 기술 제안사항 권고를 참조하여 따른 것이다. 또한 신규 데이터 편목 시 종단점을 사용하지 않기로 하였을 때 필드별 종단점 입력 여부를 매번 확인하지 않아도 되므로 목록의 편의성을 도모할 수 있다.
단 종단점 정리 프로그램 구성 시 필드 종단점이 아닌 약자나 단위에 쓰이는 축약점이 아닌지 반드시 구별하여야 한다.
실제적으로 종단점을 입력하지 않는 것을 향후의 신규 서지 데이터 작성 지침으로만 적용할 수도 있으나 소급 데이터와의 전체적 일관성을 고려하여 이러한 별도의 종단점 정리 프로그램을 구축하였다.
가. 최초의 체크리스트(Checklist)
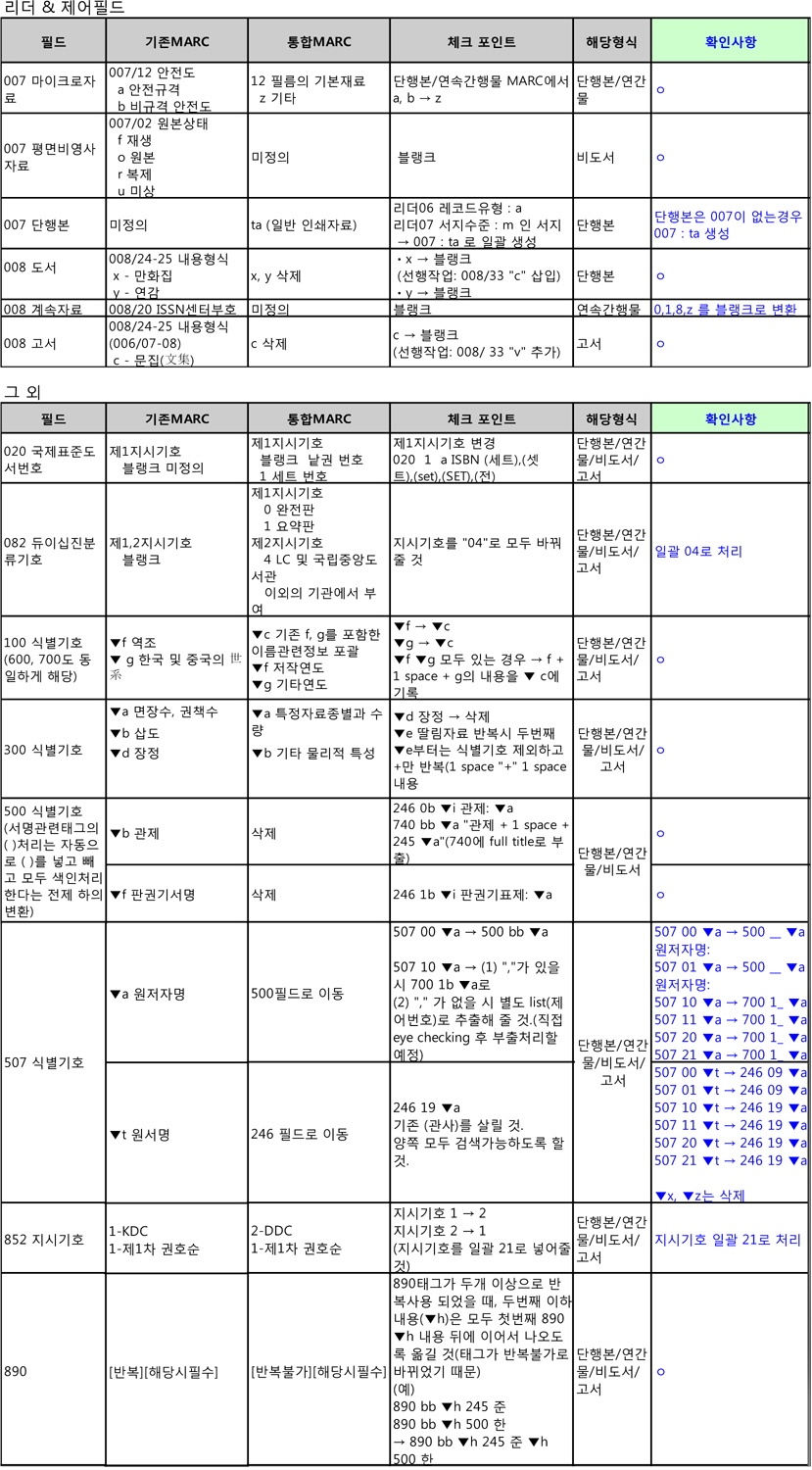
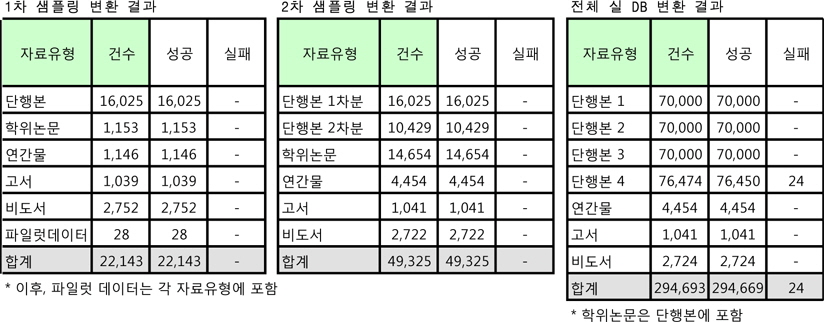
앞서 언급한 바와 같이 변환기 구성을 위한 초안에 해당하는 매핑 테이블은 도서관이 변환의 결과를 점검하는 체크리스트로 활용할 수 있다. 그러므로 최초의 체크리스트는 기본 매핑 테이블 과 형식이 거의 유사하고, 1차 변환 이후의 체크리스트는 오류 내용이 중심이 되므로 매핑 테이블과는 다른 형식으로 진행되었다. 최초의 체크리스트는 필드명을 기준으로 나열하고 해당 필드의 변환 사항을 기술한 후 이에 해당하는 자료유형을 기재하였다.
서강대학교 도서관의 매핑 테이블 즉, 최초의 체크리스트의 주요 내용은 표 3과 같다.
[<표 3>] 매핑 테이블 및 최초의 체크리스트 일부(예시)
매핑 테이블 및 최초의 체크리스트 일부(예시)
나. 1차 변환 이후의 체크리스트
변환기에 적용한 초기 매핑 테이블을 1차 변환 후 데이터 점검을 위한 체크리스트로 사용하여 다시 미결 사항을 추출하였다. 이를 중심으로 차기 변환에 대한 체크리스트를 작성하되 데이터 검증 시에는 자료유형별 담당자가 전담하여 미결 및 보완사항을 도출하였다. 그 후 교차 체크를 통하여 자료유형별 체크리스트가 나올 수 있도록 준비하되, 1차 검증 체크리스트가 필드 중심의 나열이었다면 2차 이후부터의 기본적 기준점은 자료유형이 되므로 유형 내의 필드별 주안점을 구체적으로 기술하도록 하였다. 이 때 변환의 진행에 따라 검증결과를 표시하고 변환기에 추가 보완할 사항을 정확하게 지적하였다. 결과적으로 이러한 과정은 샘플링 변환의 진행에 따라 내용의 양적인 면은 감소되는 경향을 보였다. 중요한 것은 자관데이터의 문제적 기술내용을 발견하는 대로 이에 반영함으로써 소급 데이터의 문제점 중 기계적으로 수정 가능한 최대 범위를 도출하고 변환 과정 중 일괄해결하여 수작업 보완 범위를 최소화하는 것이다. 1차 변환 이후의 체크리스트의 예시는 다음 <표 4>와 같다.
[<표 4>] 1차 변환 이후의 체크리스트 일부(예시)
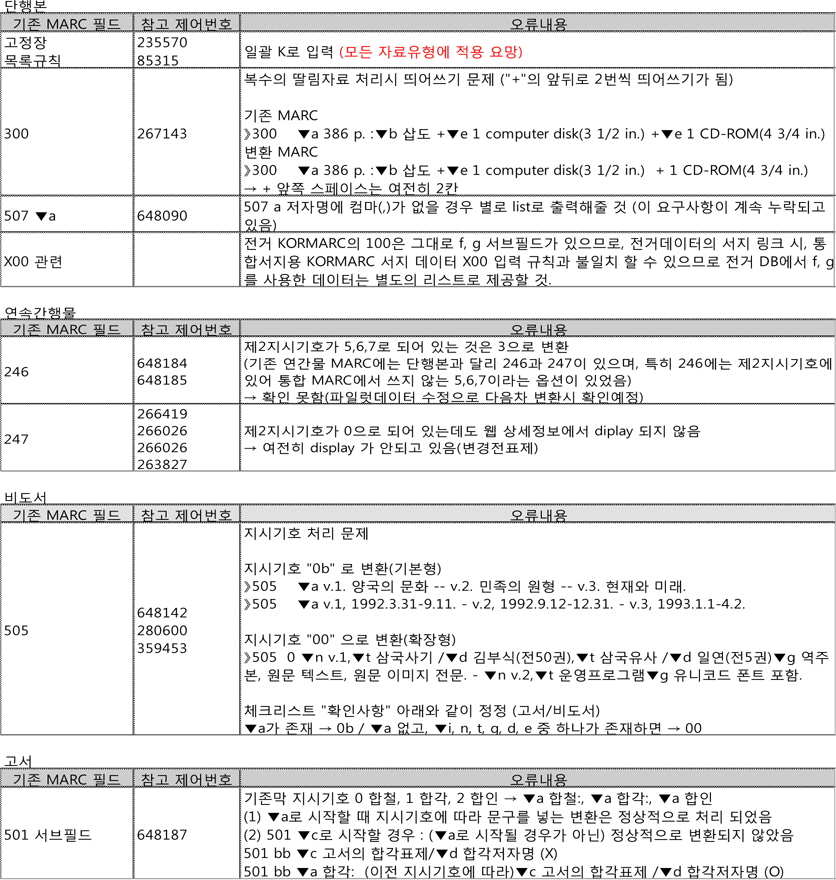
1차 변환 이후의 체크리스트 일부(예시)
다. 종단점 정리 프로그램 체크리스트
필드(태그) 끝의 구두점인 종단점을 일괄 제거할 때, 그것이 종단점인지 약자 및 단위 표현 상의 점(.)에 해당하는지 등을 구분해야 하므로 1차 변환시 종단점 정리 프로그램을 테스트하고 서지 데이터를 직접 확인하여 종단점 정리 프로그램에 보완되어야 할 사항을 추가적으로 제안하였다. 해당 필드별로 종단점이 아니면서 점의 형태로 끝나는 경우를 도출하고, 반대로 삭제되어야할 종단점이 삭제되지 않은 경우를 찾도록 하였다. 종단점 정리 프로그램 체크리스트의 주요 내용은 <표 5>와 같다.
[<표 5>] 종단점 정리 프로그램 체크리스트의 주요 내용(예시)
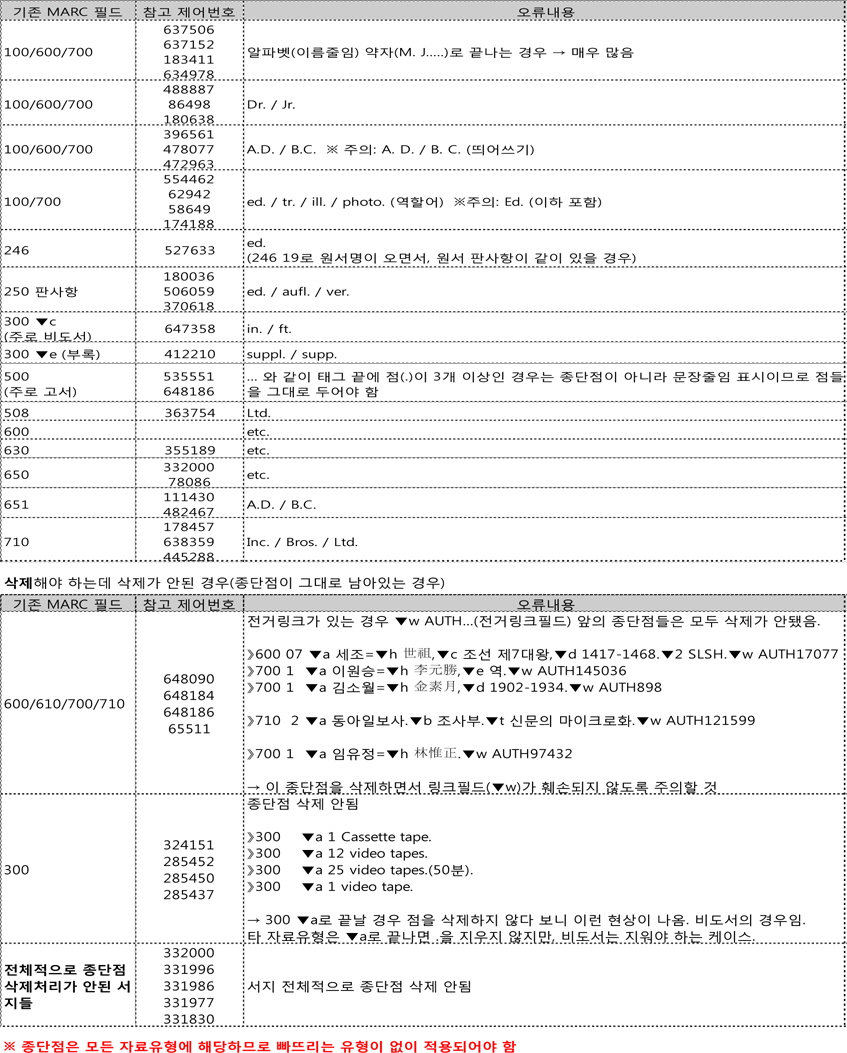
종단점 정리 프로그램 체크리스트의 주요 내용(예시)
2차 샘플링 변환 시 서지 데이터의 변환 작업 완료 후 보완된 종단점 정리 프로그램을 실행하였다.
종단점은 서지의 내용과는 직접적인 관련이 없으므로 기관에 따라 기존의 구두점 표기 방식을 유지하여 계속 사용할 수도 있다. 소급 DB는 입력된 종단점을 유지하고 통합서지용 KORMARC 적용 이후의 신규 서지 데이터부터 종단점을 사용하지 않는 기관도 있다.
서지 데이터를 통합서지용 KORMARC으로 변환하는 것과 별도로 전산 시스템상 고려할 사항은 향후 사용할 목록시스템과 도서관 홈페이지에서의 검색 및 서지 상세정보의 출력 등이다. 이들에 대하여 도서관은 표준 변경에 따른 여러가지 환경설정과 시스템 테스트의 과정이 필요하다.
가. 목록시스템
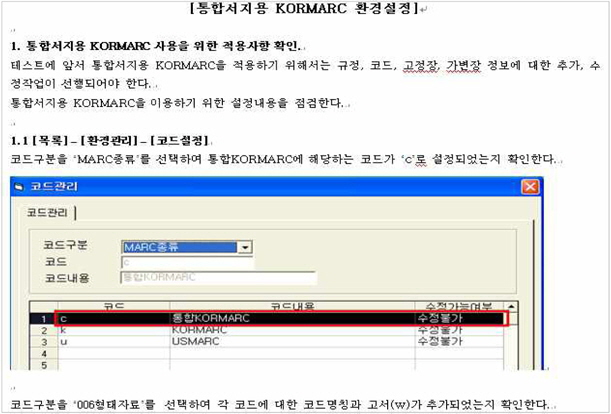
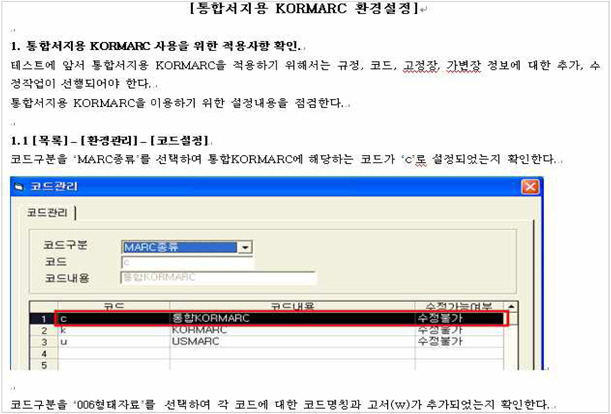
향후 목록작업에 사용될 시스템은 통합서지용 KORMARC으로 데이터 구축이 가능한 형태여야 한다. 최근 개발된 도서관 업무 상용 시스템(LAS)의 대부분은 기존 자료유형별 KORMARC과 통합서지용 KORMARC을 병행하여 사용할 수 있으나 기존에 사용하던 시스템을 통합서지용 KORMARC의 입력이 가능하도록 업그레이드 하는 경우, 여러 가지 편목 환경설정과 MARC 에디터의 제기능에 문제가 없는지 점검하는 것이 필요하다.
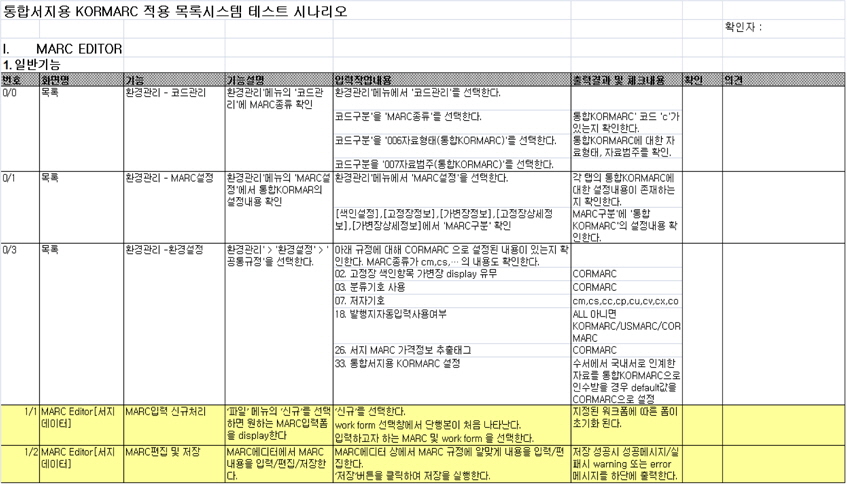
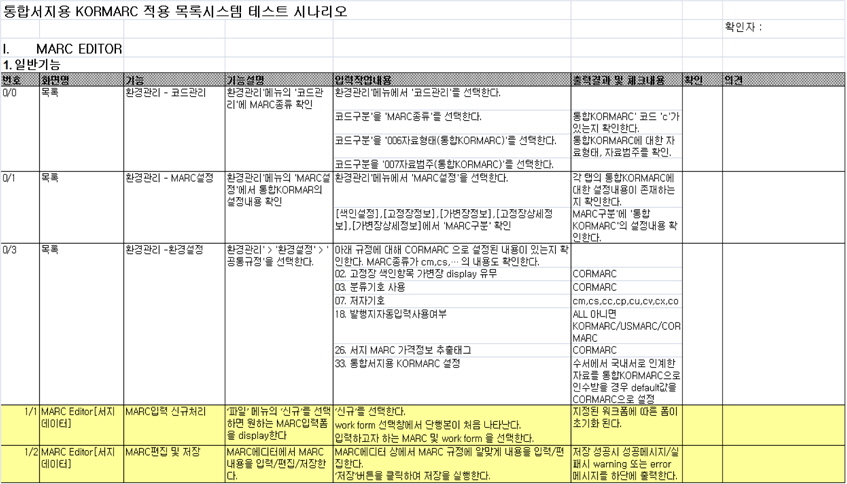
이 때 새로운 시스템에 대한환경설정 매뉴얼(<그림 3>)과 목록시스템 테스트 시나리오
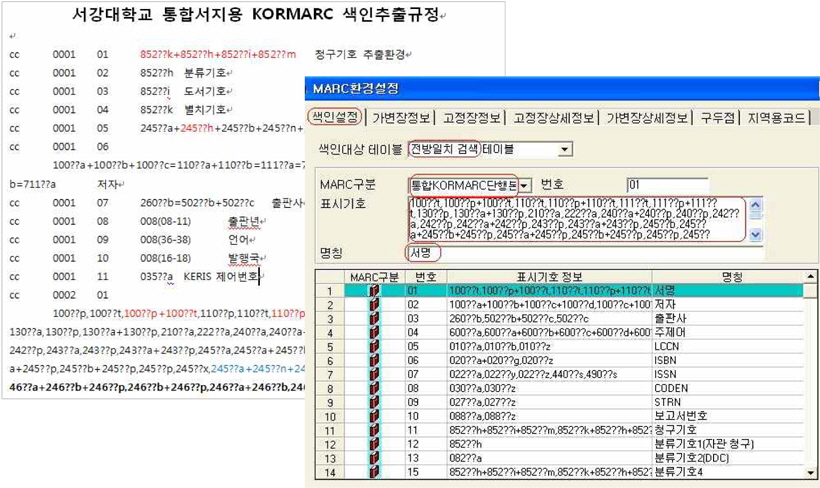
나. 검색을 위한 색인설정 작업
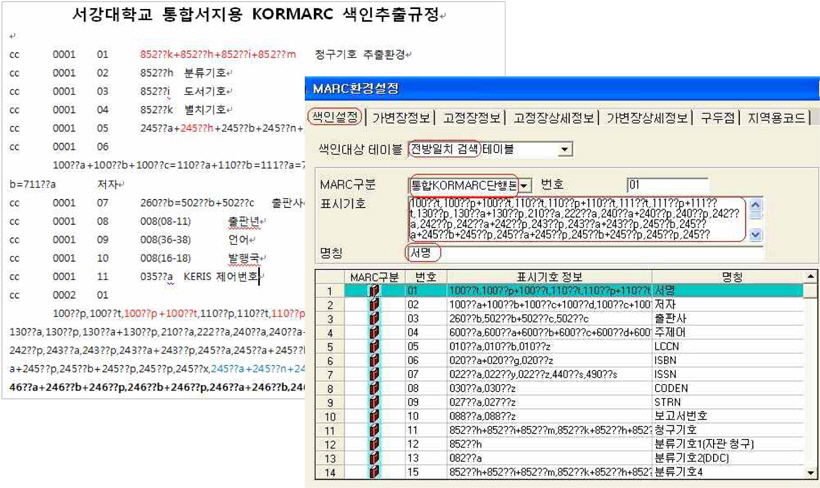
통합서지용 KORMARC으로의 전환에 따라 검색을 위한 색인의 설정이 달라지게 된다. 새로운 필드가 생기고 필드의 이동 등 필드 사용에 변화가 생겼으므로 MARC 색인설정을 총체적으로 점검하고 재구성하여야 한다.(<그림 5>) 목록시스템에서의 색인설정은 도서관 홈페이지의 이용자 검색에 직접적 영향을 미치므로 각 필드별로 신중하게 확인할 필요가 있다.
다. 도서관 홈페이지 서지 상세정보 설정
표준 변경에 따른 필드 사용이 달라짐으로써 검색에 관련된 색인설정과 더불어 도서관 홈페이지의 서지 상세정보 출력에도 조정이 필요하다. 모든 변환 작업이 완료되면 도서관 홈페이지에서 검색 테스트와 함께 서지 상세정보가 필드별로 정확하게 출력 가능한 지 웹 설정을 점검(<그림 6>)하고 필요 시 설정 상태를 조정한다.
도서관의 서지 DB에 새로운 MARC 표준을 적용한다는 것은 단순히 바뀐 규칙으로 목록을 한다는 것 이상의 의미가 있다. 즉, 도서관은 대상이 되는 전체 서지에 대해 재정비할 수 있고 해당도서관의 자관 목록 원칙을 확정하여 편목 스탭 매뉴얼을 완성할 기회를 갖게 된다. 이번 과정에서도 새로운 표준의 적용을 위해 관련 사서가 모두 모여 통합서지용 KORMARC을 분석 및 숙지하고 자관에 가장 적합한 매뉴얼을 도출하기 위하여 수 차례 논의를 거듭하였으며, 이 논의는 기존 소급 DB를 새 표준 포맷으로 변환하는 것을 포함하여 향후의 도서관 목록 방향 설정에 큰 바탕이 되었다. 또한 개별 사서들의 편목 작업 중 혼란이 있었던 기술 내용을 내부적으로 정돈할 수 있고 이런 공동 논의를 통해 미래편목작업의 일관성을 확보하는 등, 변환 사업을 통하여 도서관은 단순한 DB 변환 이상의 성과를 이룰 수 있다. 그러나 이번 통합서지용 KORMARC으로의 변환 작업을 통해 다음과 같은 향후 고려해야 할 문제점들도 발견되었다.
첫째, 서지데이터용 표준인 통합서지용 KORMARC은 완성이 되었으나, 전거통제용과 소장정보용 KORMARC의 갱신은 이루어지지 않은 점이다. 서강대학교 도서관은 전거데이터를 구축하고 있는 기관으로서, 전거는 1999년에 발간된 기존의 전거통제용 KORMARC에 의해 데이터를 구축하고 있다.
$f – 역조(歷朝) $g – 한국 및 중국의 세계(世系)
그런데 변경된 통합서지용 KORMARC은 $f와 $g가 사라지고 ‘$c 이름 관련 정보(직위, 칭호 및 기타 명칭, 역조(歷朝), 국명(國名), 한국 및 중국의 세계(世系))’로 통합되었다. 이런 경우, 전거데이터용 표준이 갱신되지 않은 상태에서 전거데이터는 기존의 표준에 따라 $f, $g로 표현되고, 이 전거데이터를 서지데이터와 연동할 경우 불일치되는 현상이 발생한다.
아울러 서강대학교 도서관의 경우 전거데이터와 더불어 소장데이터도 구축하고 있으므로 국내서 소장 MARC DB 구축 시 1999년에 발행된 소장정보용 KORMARC 규칙에 준거하여 소장필드를 입력하고 있다. 따라서 전거통제용 표준과 더불어 소장정보용 표준도 함께 개정할 필요가 있다. MARC21은 기존 USMARC Bibliographic 편과 함께 Authority 및 Holdings 편도 동반적으로 갱신함
둘째, 통합서지용 KORMARC 기술의 KCR4 기반에 따른 기본표목의 혼란이다.
통합서지용 KORMARC에 대한 연구 논문들을 살펴 보면 통합서지용 KORMARC이 KCR4의 기술원칙 및 내용을 수용하여 제정됨에 따라 기본표목과 통일표제의 사용에 있어 논란이 많은 것이 사실이다.(이경호, 김정현 2006, 205-206) 특히 대학도서관의 경우 통합서지용 KORMARC으로 변환하려는 많은 도서관에서 통합서지용 KORMARC 규칙으로 입력하되 기본표목의 문제를 KCR4에 준거할 것인지 기존의 1XX 사용을 유지할 것인지에 대한 고민이 있는 것으로 나타났다. 대학도서관은 많은 기관들이 KORMARC을 USMARC과 함께 사용하여 왔고, 기본표목으로서 1XX를 보유하고 있어 통합서지용 KORMARC이 KCR4를 수용하였다는 면에 부담을 느끼고 있는 것이 사실이다. 사업을 완료한 후 변환에 대한 문의를 해오는 타 도서관들의 사례에서도 이러한 고민의 흔적을 충분히 찾을 수 있었다.
실제 MARC21이 AACR2에 기반한 것과 마찬가지로 통합서지용 KORMARC이 KCR4를 수용한 것은 표면상으로 문제가 없으나, 통합서지용 KORMARC이 KCR4 기반이지만 1XX 필드에 대한 규정이 사라진 것이 아니라 새로운 표준 내에서 정확하게 제시되어 있고 이에 대한 사용 여부는 사용하는 기관의 결정에 맡기고 있어 통합서지용 KORMARC 변환에 대한 대학도서관 간의 논의에서는 항상 이 문제가 대두될 수밖에 없는 실정이다. 서강대학교 도서관의 경우도 실용적 측면에서 기존 1XX 기본표목 사용을 포기할 수 없었고 실제적으로 새로운 표준에 1XX 규칙이 존재할 뿐만 아니라, 국외서 편목에 사용되는 MARC21과의 일관성 등을 고려하여 1XX는 향후에도 유지하는 것으로 하였다. 그러나 표준으로 제정된 것을 사용함에 있어 그것도 기본저록방식이라는 중대한 내용에 관하여 계속적인 혼란과 논란이 있는 현상에 대해서는 실제 편목 작업을 하는 입장에서 큰 문제점으로 판단된다.
또한 현재의 이와 같은 표목의 사용에 대한 입장 정리를 위해 편목의 국제적 경향을 파악하고 적용할 필요가 있다. MARC21은 AACR2에 기반하여 제정되었고, 이후 FRBR 및 FARD를 기저로 만든 목록규칙 RDA는 디지털 환경에 맞춤과 동시에, MARC21과의 연계성을 고려(유영준 2011, 112-115)하여 연구되었다. 따라서 현재 RDA가 적용된 MARC21의 사용에 있어서는 통합서지용 KORMARC과 달리 기본표목과 통일표제의 사용에 전혀 혼란이나 거리낌이 없고 오히려 저작 간의 관계성 표현이 강화됨에 따라 240이나 130 필드의 사용이 증대될 것으로 보인다.
편목 현장의 입장에서 통합서지용 KORMARC을 제대로 적용하는 것과 더불어 향후의 표준제정 시에는 이러한 국제적 편목 경향이 합리적으로 반영된 포맷과 기술규칙을 완성함으로써 실제 적용하는 도서관에서 편목의 통일감
본 연구는 통합서지용 KORMARC으로의 DB 변환에 대해 서강대학교 도서관의 사례를 중심으로 효과적인 변환 방안을 모색하는 데 목적이 있다. 서강대학교 도서관은 변환 시 공용 변환기 대신 자체 변환기를 개발함으로써 적은 인력으로 효율적인 DB 변환을 할 수 있는 방법을 찾고 기존 자관 DB의 오류와 단점을 일괄 개선하도록 하였다. 이를 위해 자관에 최적화된 매핑 테이블을 구성하여 변환기에 탑재하고 체크리스트로 변환 과정을 추적 검증하도록 하였다. 그 과정에서 샘플링 변환을 기본으로 파일럿 데이터의 작성, 종단점 정리 프로그램 별도 구축 등의 작업을 포함하였으며, 목록시스템과 색인 및 웹 상세정보의 설정 등의 변환 관련 처리를 진행하였다.
이러한 전과정에 있어 의식해야 할 지향점이 있다면 그것은 이와 같은 서지 DB의 변환 작업의 주체가 도서관 즉 사서이어야 한다는 것이다. 이를 단순 포맷변경으로만 인식하여 시스템벤더에 일임하거나 방관하여서는 안될 것이다. 표준이 변경되었을 때 해당 표준의 적용이 자관의 편목작업에 직간접적으로 미칠 영향에 대해 파악할 수 있어야 정확한 적용 또한 가능할 것이다. 필요에 따라 자관의 입력 세칙을 정하거나 불가피하게 변용할 경우 사용상의 혼란을 방지할 명확한 기준을 확정하여야 한다. 아울러 편목에 임하는 도서관의 전 인원이 동일하게 이를 공유하고 있어야 하므로 표준 변경에 따른 도서관의 대처 과정은 결과에 앞서 중요한 행위임을 인식하여야 할 것이다. MARC의 이용원리와 자관 서지데이터에 대해 가장 잘 알고 있는 편목 사서가 서지 DB변환의 주체가 되어 적극적으로 임할 때 변환의 결과는 물론 향후의 편목 작업 현장 역시 흔들림이 없을 것이다. 이 과정에서 사서는 기본적인 사업 진행 능력 및 동반하는 시스템 벤더의 태스크 수행 내역을 잘 파악할 필요가 있다.
통합서지용 KORMARC 변환의 과정을 통해 도서관은 자관 서지 DB에 대한 이해 뿐만 아니라 나아가 현재의 표준에 대한 사용자적 진단이 가능할 것이다. 따라서 개정에 필요한 요소들이 도서관현장을 통해 나옴으로써 우리가 쓰는 표준의 유효성과 적합성을 높이며 그 표준이 더욱 온전한 형태로 발전하는 데 기여할 수 있기를 희망하여 본다.