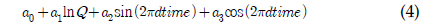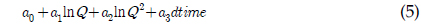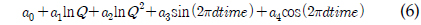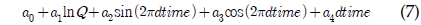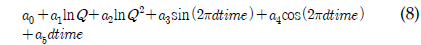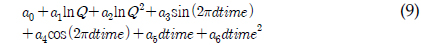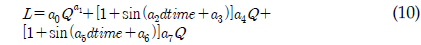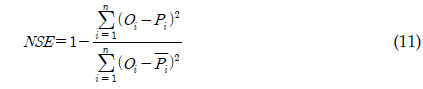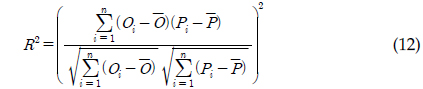Water quality data are collected less frequently than flow data because of the cost to collect and analyze, while water quality data corresponding to flow data are required to compute pollutant loads or to calibrate other hydrology models. Regression models are applicable to interpolate water quality data corresponding to flow data.
A regression model was suggested which is capable to consider flow and time variance, and the regression model coefficients were calibrated using various measured water quality data with genetic-algorithm. Both LOADEST and the regression using genetic-algorithm were evaluated by 19 water quality data sets through calibration and validation. The regression model using genetic-algorithm displayed the similar model behaviors to LOADEST. The load estimates by both LOADEST and the regression model using genetic-algorithm indicated that use of a large proportion of water quality data does not necessarily lead to the load estimates with smaller error to measured load.
Regression models need to be calibrated and validated before they are used to interpolate pollutant loads, as separating water quality data into two data sets for calibration and validation.
강우시 하천이나 강으로 유입되는 비점원오염원은 부영양화나 수생태계의 파괴 등의 원인 중 하나며, 이러한 현상은 자연적인 현상일 수도 있으나 농경지나 도시화와 같은 인위적인 요소도 적지 않은 영향을 끼친다(Carey
Load Estimator (LOADEST; USGS Report, 2004)는 유량자료와 측정된 수질자료를 이용하여 회귀식을 보정하여, 수질자료가 측정되지 않은 지점에 대한 오염부하량을 산정할 수 있는 프로그램이다. Carey 등(2011)은 1992년에서 2006년 동안의 아질산염질소, 질산염, 총인의 실측자료를 통해 LOADEST를 보정 및 검정한 결과 실측치에 가까운 예측치를 모의하였다. 또한 LOADEST는 부유유사(Dornblaser and Striegl, 2009; Das
LOADEST 는 11개의 회귀식을 가지고 있으며, 이 중 2개는 특정 기간에 대한 오염 부하량을 산정하기 위한 것이며, 그 외 9개의 회귀식이 주어진 유량과 수질 자료에 대해 모형의 보정 및 오염 부하량을 예측하기 위한 것이다. 이 9개의 회귀식은 유량만을 이용해 오염 부하량을 산정하는 회귀식부터 유량과 측정시간을 이용하는 회귀식까지 다양하다. LOADEST의 회귀식은 로그로 치환된 오염부하량을 산정하기 위한 것이다. LOADEST 의 회귀식들은 다양한 형태의 유량과 측정 시간을 고려하도록 되어 있으나, 유량에 대해서는 로그로 치환하는 데에 비해, 측정 시간에 대해서는 로그로 치환되지 않은 값을 사용하고 있다. 비점오염원은 강우시 많은 양이 유출이 되기 때문에 유량과 높은 상관관계를 가질 확률이 크지만, 비점오염원은 계절과 같은 시간에 따라 변동할 수 있기 때문에, 오염 부하량을 산정하는 데에 있어 유량과 측정시간은 모두 중요하다(Robertson, 2003).
따라서 본 연구에서는 유량과 측정시점을 대등하게 고려하여 오염부하량을 예측하는 회귀식과 LOADEST에 의한 예측치과 실측치를 비교하여, 회귀식을 이용한 일부하량 산정 방법을 분석하는 데에 있다.
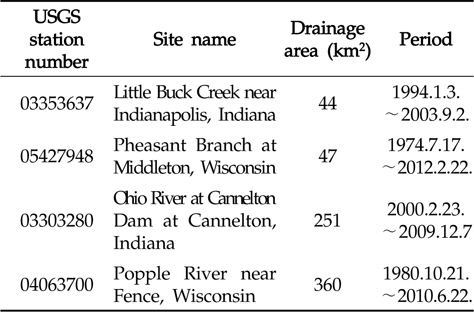
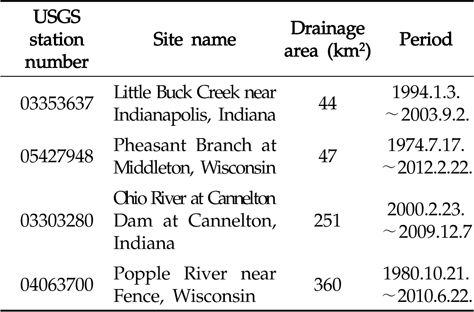
본 연구에서 개발된 회귀식의 검정을 위해, United States Geological Survey (USGS, http://water.usgs.gov/owq/data.html)의 수질 자료가 사용되었다. 유역의 비점오염원 발생은 유역내 특성뿐만 아니라, 유역내 인위적인 요소 또한 영향을 줄 것으로 판단된다. 오염부하 산정을 위한 회귀식은 유역의 강우나 지형, 인위적인 요소 등과 같은 특성은 고려할 수 없다. 따라서 이러한 영향을 최소화하기 위하여, USGS의 수질 자료 중, 장기간에 걸쳐 측정되고, 비교적 유역 면적이 작은 지점에 대해 측정된 수질 자료가 사용되었다. 총 4개 지점(Table 1)에서 측정된 수질 자료가 사용되었으며, 각 지점은 44 km2에서 360 km2의 유역면적을 가졌으며, 약 10년에서 20년에 걸쳐 각 수질 자료에 대해 135개에서 1,437개의 수질 자료가 측정되었다. 각 지점에 대해서 수질 자료의 유무에 따라 4-5개의 질소와 인에 관련된 수질 자료가 사용되었다(Table 2).
[Table 1.] United States Geological Survey stations for water quality data
United States Geological Survey stations for water quality data
[Table 2.] United States Geological Survey water quality data code and description

United States Geological Survey water quality data code and description
수문 모형이나 회귀식 등에 대해 적용성을 판단할 때에는 보정뿐만 아니라 검정 결과도 함께 분석이 되어야 하기 때문에 본 연구의 회귀식 역시 보정 및 검정 과정을 거쳤다. 보정과 검정 과정을 위해서는 실측치를 분할해야 하며, 일반적으로는 자료의 기간에 의해 분할하여 보정과 검정 과정을 거치나, 회귀식의 경우 보정 시 사용된 자료의 범위를 벗어나 예측하게 될 경우, 도시화 등과 같은 유역의 장기간에 걸친 변화 등에 의해 회귀식에 의한 예측치에 대한 불확실성이 커질 것으로 예상되었다. 따라서 본 연구에서는 실측 자료를 분할하는 데에 있어, 보정자료와 검정 자료의 기간이 같도록 할 필요가 있었으며, 이에 실측 자료의 측정된 날짜와 무관하게, 각 자료의 홀수 번째 자료를 보정자료로, 각 자료의 짝수 번째 자료를 검정 자료로 사용하였다. 따라서 각 실측 수질자료는 회귀식에 대한 보정과정과 검정과정에서 거의 같은 기간과 같은 개수의 수질 자료가 사용이 되었다.
LOADEST는 11개의 회귀식을 가지고 있으며 회귀식 번호를 지정할 경우 지정된 회귀식에 의해 회귀식 계수들을 보정하고, 이렇게 보정된 계수를 이용하여 미계측 지점에 대한 오염부하량을 산정한다. 하지만 회귀식 번호를 0으로 지정할 경우, 회귀식 번호 1-9번 중 주어진 수질자료를 통한 회귀식의 보정 결과가 Akaike Information Criterion에 의해, 예측치가 실측치에 가장 가까운 회귀식에 의해 미계측지점에 대한 오염부하량을 예측한다. 식 (1)에서 식 (9)에서 보이는 바와 같이, 식 (1)과 식 (2)의 경우 오염부하량을 유량에 의해서만 산정하는데, 이는 수질자료가 유량자료와 매우 큰 상관관계를 보일 경우 사용될 수 있으며, 식 (3)부터 식(9)의 경우는 유량과 함께 측정시간(계절적 변화)이 함께 수질자료가 상관관계가 있을 때 사용될 수 있다. 앞서 언급한 바와 같이, LOADEST의 회귀식들은 유량과 측정시간을 모두 고려할 수 있으나, 회귀식에 의해 로그로 치환된 오염부하량을 예측하는 것이다. 다시 말해, 회귀식의 계수 보정에서 회귀식에 의해 산정된 값들은 지수함수에 의해 다시 오염부하량으로 산정이 된다(USGS Report, 2004). 하지만, 로그로 치환된 오염부하량을 산정하는 데에 있어, 유량은 로그로 치환하여 고려하는 반면, 측정시간에 관한 항은 로그로 치환되지 않고 보정과정을 거치기 때문에 이 과정에서 유량과 측정시간은 대등한 위치에 있다고 보기 어렵다. 이러한 유량과 측정시간에 대한 고려가 실측치에 가까운 예측치를 위한 회귀식 계수 보정을 가능하게 할 수도 있지만, 수질자료는 수질 자료의 종류와 측정지점에 따라 달라질 수 있기 때문에, 유량과 측정시간을 대등하게 고려하는 회귀식 역시 필요할 것으로 판단되었다.
일부하량(kg):



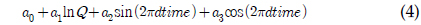
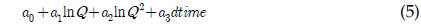
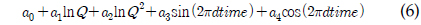
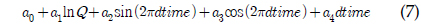
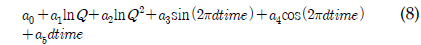
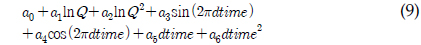
a0 - a6 = 회귀식 계수 Q = 유량dtime = 연중 시간을 0∼1의 소수로 환산한 값
따라서 본 연구에서는, 오염부하량을 산정하는 회귀식의 기본 형식에 로그로 치환하지 않고, 유량과 시간을 고려할 수 있도록 하였다(식. 10). 본 연구에서 제안되고 사용된 회귀식의 첫 번째 항은 유량에 관련된 오염부하를 고려하기 위함이며, 두 번째 및 세 번째 항은 시간에 따라 변동하는 오염부하를 고려하기 위함이다. 다시 말해, 본 연구의 회귀식은 유량과 시간을 동등하게 고려할 수 있도록 하였다.
일부하량(kg/d):
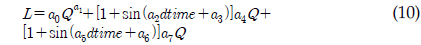
L = 일부하량(kg/d) Q = 유량 dtime = 연중 시간을 0∼1의 소수로 환산한 값 a0 - a7 = 회귀식 계수
LOADEST는 모형내 회귀식을 보정하기 위해 최우추정법(Maximum Likelihood Estimation; MLE)과 개선된 최우추정법(Adjusted Maximum Likelihood Estimation; AMLE)그리고 오차절대값최소화추정법(Least Absolute Deviation; LAD)에 의해 회귀식을 보정하며, 회귀식에 의한 예측치와 실측치의 차이가 표준정규분포를 따를 때에는 AMLE나 MLE에 의한 오염부하량을 사용하고 그렇지 않을 시에는 LAD에 의한 오염부하량을 사용하도록 제안하고 있다(USGS Report, 2004). 이러한 AMLE, MLE, 그리고 LAD 는 회귀식을 보정하는 데에 있어 최적화 기법 중 하나이며, 본 연구에서는 식 (10)의 회귀식 계수들을 보정하기 위해 유전자 알고리즘을 사용하였다. 유전자 알고리즘은 크게 선택, 교차, 변이의 과정을 가진다. 유전자 알고리즘은 복잡한 문제를 효과적으로 해결하기 위해서, 여러 분야에 걸쳐 사용되어 왔다(Togan and Daloglu, 2008). 따라서 본 연구에서는 유전자 알고리즘을 이용하여 회귀식의 계수들을 보정하였다.
총 19개의 유량과 수질자료가 본 연구의 유전자 알고리즘에 의한 회귀식과 LOADEST 보정 및 검정에 이용되었었다. 회귀식과 LOADEST의 보정 및 검정 결과를 판단하기 위해 Nash-Stucliffe Efficiency (NSE; 식 11)과 결정계수(Coefficient of Determination; R2; 식 12)가 사용되었다. Santhi 등(2001)은 NSE와 R2가 각각 0.5와 0.6일 때를 기준으로 모형에 의한 예측치를 판단한 바 있다. 따라서 본 연구의 회귀식와 회귀식의 계수들을 보정하기 위한 유전자 알고리즘에 의한 예측지의 정확도를 판단하기 위해서 NSE와 R2가 함께 고려되었다. NSE와 R2는 실측치(
Nash-Stucliff Efficiency:
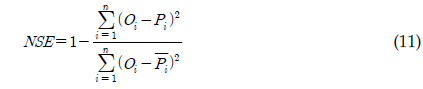
Coefficient of Determination:
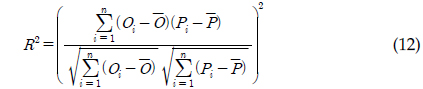
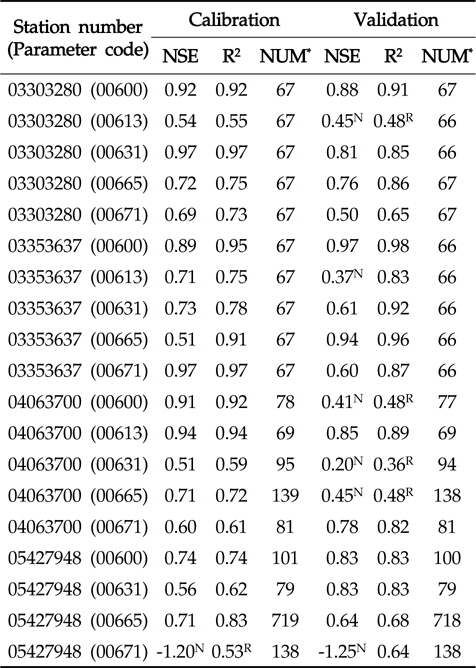
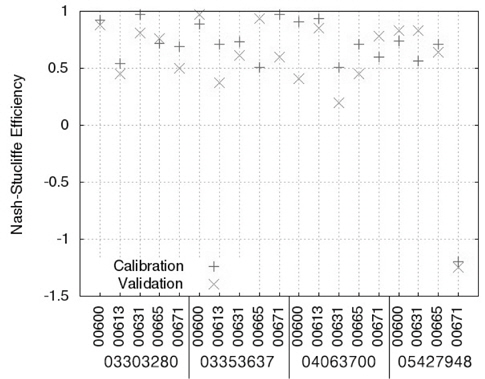
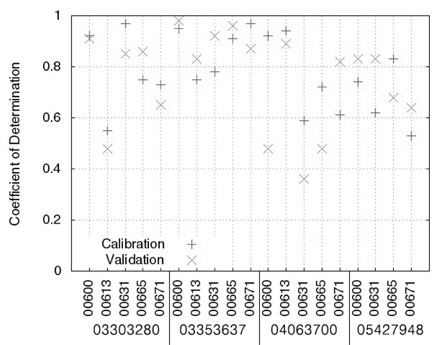
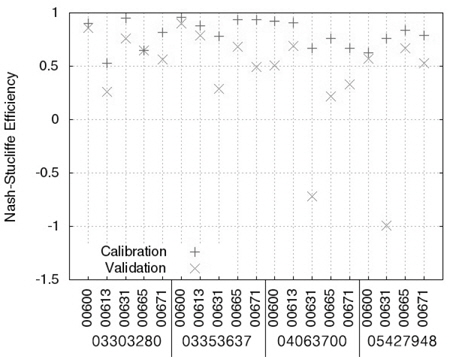
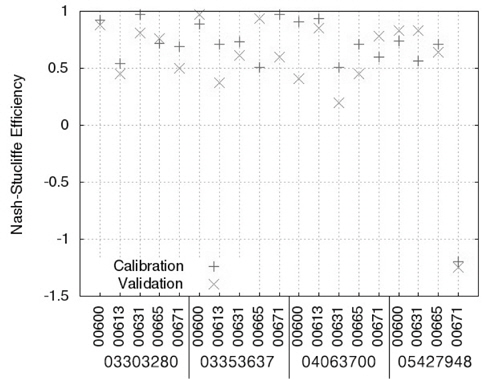
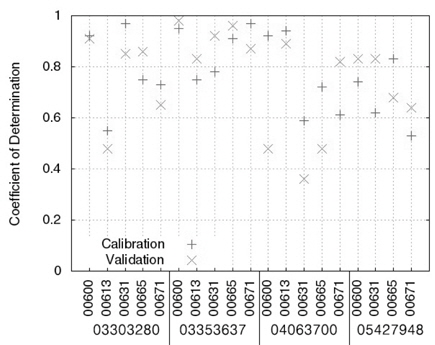
Table 3에서 보이는 바와 같이, LOADEST의 보정 과정에서 실측치와 예측치의 NSE는 -1.20 (USGS 지점 05427948, 수질자료 00671)에서 0.97 (USGS 지점 03303280, 수질자료 00631)으로 한 개의 수질자료를 제외한 예측치에서 0.5보다 큰 값을 보였으며(Fig. 1), R2는 0.53 (USGS 지점 05427948, 수질자료 00671)에서 0.97 (USGS 지점 03303280, 수질자료 00631)으로 한 개의 수질자료를 제외한 예측치에서 0.6보다 큰 값을 보였기 때문에(Fig. 2) LOADEST의 보정이 잘 된것으로 판단되었다. LOADEST의 검정 과정에서 실측치와 예측치의 NSE는 -1.25 (USGS 지점 05427948, 수질자료 00671)에서 0.94 (USGS 지점 03353637, 수질자료 00665)로 19개의 수질자료에 대해 13개의 수질자료에 대해서 0.5보다 큰 값을 보였다(Fig. 1). R2는 0.36 (USGS 지점 04063700, 수질자료 00631)에서 0.98 (USGS 지점 03353637, 수질자료 00600)으로 19개의 수질자료에 대해 15개의 수질자료에 대해서 0.6보다 큰 값을 보였다(Fig. 2). 19번의 LOADEST의 보정 및 검정 결과 중에서 NSE가 0.5보다 크고 R2가 0.6보다 큰 예측치는 총 13개(68%)였으며, 따라서 LOADEST의 보정과 회귀식에 의한 오염부하량 예측은 비교적 잘 이루어진 것으로 판단되었다.
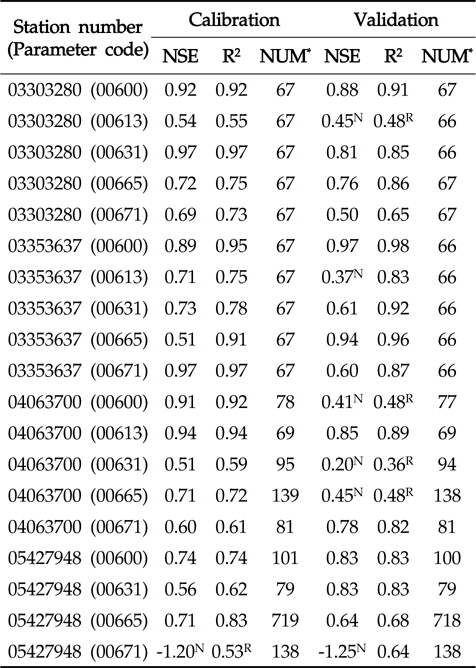
Nash-Stucliffe Efficiency and coefficient of determination of LOADEST in calibration and validation
USGS의 4개 지점들은 각기 다른 유역 면적과 각기 다른 실측치의 개수를 가지고 있다. 같은 종류의 수질자료(00665)에 대해 USGS 지점 04063700과 USGS 지점 03303280에 대한 보정 및 검정 결과를 비교해볼 때, 역시 많은 양의 실측치를 통한 검보정이 반드시 실측치에 유사한 예측치를 얻을 수 있다고 판단하기는 힘든 것으로 보인다. 또한, USGS 지점05427948의 수질자료 00665의 경우 719개의 수질자료(보정시)와 718개의 수질자료(검정시)를 이용하여 보정과정에서는 NSE와 R2가 모두 0.7보다 크고, 검정과정에서는 NSE와 R2 가 모두 0.6보타 컸기 때문에 보정 및 검정 과정에서 예측치가 실측치에 매우 근사하였다. 하지만 더 적은 양의 수질 자료가 이용된 USGS 지점 03303280의 수질자료 00665의 경우 67개의 수질자료를 통한 보정 및 검정 과정에서 모두 NSE와 R2가 모두 0.7보다 컸기 때문에 이 역시 많은 양의 수질자료가 반드시 실측치와 가까운 예측치를 의미한다고 보기는 힘든 것으로 판단된다. Robertson (2003)는 수질 자료 측정 빈도에 따른 23 종류의 수질 자료와 회귀식을 이용해 오염부하량 평가를 한 바 있으며, 많은 양의 수질 자료가 반드시 실측치에 더 가까운 예측치를 의미하지 않는다고 제안한 바와 일치한다.
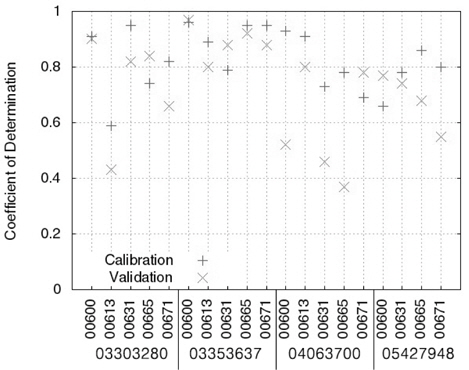
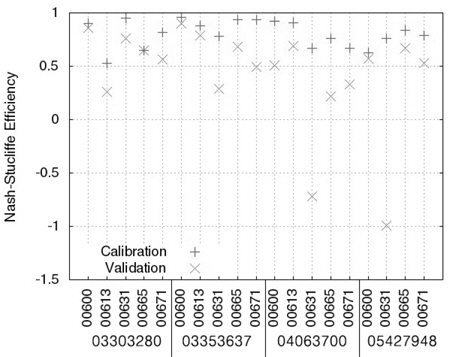
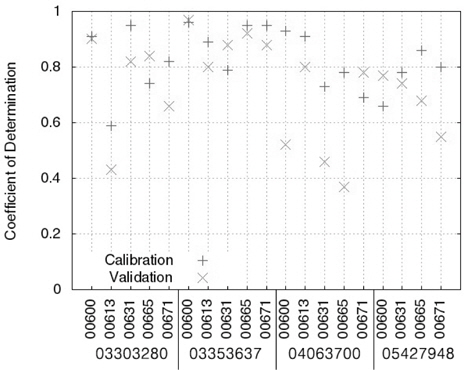
Table 4에서 보이는 바와 같이, 회귀식의 보정 과정에서 실측치와 예측치의 NSE는 0.53 (USGS 지점 03303280, 수질자료 00613)에서 0.96 (USGS 지점 03353637, 수질자료 00600)으로 모두 0.5보다 큰 값을 보였으며(Fig. 3), R2는 0.59 (USGS 지점 03303280, 수질자료 00613)에서 0.96(USGS 지점 03353637, 수질자료 00600)으로 대부분 0.6보다 큰 값을 보였기 때문에(Fig. 4) 유전자 알고리즘에 의한 회귀식은 보정이 잘 된 것으로 판단되었다. 회귀식의 검정 과정에서 실측치와 예측치의 NSE는 -0.99 (USGS 지점 05427948, 수질자료 00631)에서 0.90 (USGS 지점 03353637, 수질자료00600)으로 19개의 수질자료에 대해 LOADEST와 비슷한 12개의 수질자료에 대해서 0.5보다 큰 값을 보였다(Fig. 3). R2는 0.37 (USGS 지점 04063700, 수질자료 00665)에서 0.97 (USGS 지점 03353637, 수질자료 00600)으로 19개의 수질자료에 대해 LOADEST와 비슷한 14개의 수질자료에 대해서 0.6보다 큰 값을 보였다(Fig. 4). 19번의 유전자 알고리즘에 의한 회귀식의 보정 및 검정 결과 중에서 NSE가 0.5보다 크고 R2가 0.6보다 큰 예측치는 총 10개(53%)로, LOADEST 보다 3개 적은 수질 자료에 대해 예측치의 보정 및 검정 과정에서 실측치에 가까운 일별 오염부하량을 보였다.
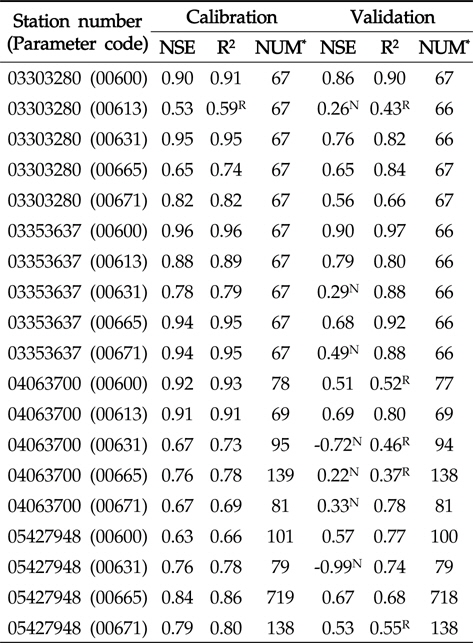
Nash-Stucliffe Efficiency and coefficient of determination of the regression model using geneticalgorithm in calibration and validation
회귀식을 이용한 일별 오염부하량 예측 역시, LOADEST와 비슷한 결과 및 결론을 도출할 수 있었다. 같은 종류의 수질자료(00671)에 대해 USGS 지점 05427948과 USGS 지점03303280에 대한 보정 및 검정 결과를 비교해볼 때, 많은 양의 실측치를 통한 검보정이 반드시 실측치에 유사한 예측치를 얻을 수 있다고 판단하기는 힘든 것으로 보인다. 특히, USGS 지점 05427948의 수질자료 00665의 경우 719개의 수질자료(보정시)와 718개의 수질자료(검정시)를 이용하여 보정과정에서는 NSE와 R2가 모두 0.8보다 크고, 검정과정에서는 NSE와 R2가 모두 0.7에 가까웠기 때문에 보정 및 검정 과정에서 예측치가 실측치에 매우 근사하였다. 하지만 USGS 지 점 03353637의 수질자료 00600의 경우 67개의 수질자료(보정시)와 66개의 수질자료(검정시)를 이용하여 보정 및 검정과정에서 모두 NSE와 R2가 모두 0.9보다 컸기 때문에 이 역시 많은 양의 수질자료가 반드시 실측치와 가까운 예측치를 의미한다고 보기는 힘든 것으로 판단된다.
본 연구에서 사용된 수질자료는 장기간에 걸쳐 총 4개 지점에서 측정된 5종류였으며, LOADEST와 유전자 알고리즘을 이용한 회귀식의 보정 및 검정을 위해, 실측자료는 모두 두 개의 자료로 분할되어 사용되었다. 일반적으로 많은 양의 수질자료를 통해 회귀식을 보정해야 실측치에 가까운 예측치를 구할 수 있다고 여겨지는 반면, 본 연구에서 사용된 수질자료에 대해 LOADEST와 유전자 알고리즘을 이용한 회귀식 모두 많은 양의 수질 자료가 반드시 실측치와 가까운 예측치를 보이지는 않았다. 또한, LOADEST와 유전자 알고리즘을 이용한 회귀식 모두, 보정과정에서 실측치와 작은 차이를 보였다고 해서 반드시 검정과정에서 실측치와 작은 차이를 보이지 않았다. 이는 유량 자료에 비해 측정 빈도가 낮은 수질자료를 회귀식에 의해 일부하량이나 연부하량을 산정할 때, 회귀식의 보정과정에서 사용된 실측치와 예측치가 작은 오차를 보인다고 할지라도 미계측지점에 대해서는 오차가 클 수도 있으며 따라서 일부하량이나 연부하량 역시 실제 발생된 오염부하량과는 적지 않은 오차를 보일 수 있다는 것을 가리킨다. 따라서 다른 수문모형과 마찬가지로, 미계측지점에 대해 오염부하량 산정을 위한 회귀식 사용은 보정과정뿐만 아니라 검정과정을 통해 평가가 된 후 사용되어야 할 것으로 판단된다.
또한, LOADSET 와 유전자 알고리즘을 이용하는 회귀식에 의한 보정 및 검정 결과를 볼 때, 두 회귀식에 대해 모두 실측치와 큰 오차를 보이는 수질자료가 있는 반면, 선택적으로 실측치와 예측치가 높은 상관관계를 보인 수질자료가 있었다. 그러므로 측정된 수질자료를 이용하여 미계측지점에 대해 보간할 때, 어느 하나의 모형을 일괄적으로 사용하기 보다는, 실측치를 분할하여 보정과 검정 과정을 통해 보다 실측치에 가까운 예측치를 보인 회귀식을 사용하는 것이 미계측 지점에 대한 수질 자료 예측이 효과적일 것으로 보인다.
회귀식은 일반적으로 유량과 수질자료만을 요구하기 때문에, 수문 모형에 비해 적은 노력과 시간을 요구한다. 본 연구에 사용되었던 LOADEST와 유전자 알고리즘을 이용한 회귀식 역시 유량과 수질자료만을 이용하여 보정과 검정과정이 이루어졌으며, 적지 않은 예측치가 실측치와 가까운 것으로 나타났다. 그러므로 회귀식의 사용은 다른 수문 모형의 사용보다 효율적인 것으로 보인다. 하지만 이와 동시에, 수문모형은 모형 자체의 여러 변수를 통해 실측치에 보다 가까운 예측치를 이끌어 낼 수 있는 기회가 주어지는 반면, 회귀식은 이에 대한 방법이 제한적이다. 이와 같은 점을 고려할 때, 회귀식에 의한 예측치의 사용에 있어 충분한 검정이 주어져야 하며, 이러한 보정 및 검정 과정이 충분히 이루어진다면 오염부하량을 산정하는 데에 있어 보다 효율적으로 이용될 수 있을 것으로 판단된다.