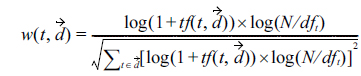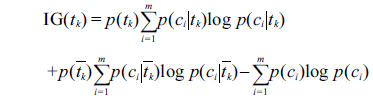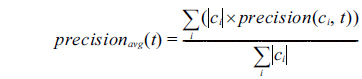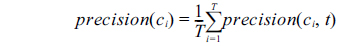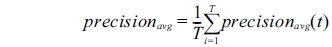Named entity classification of Wikipedia articles is a fundamental research area that can be used to automatically build large-scale corpora of named entity recognition or to support other entity processing, such as entity linking, as auxiliary tasks. This paper describes a method of classifying named entities in Chinese Wikipedia with fine-grained types. We considered multi-faceted information in Chinese Wikipedia to construct four feature sets, designed different feature selection methods for each feature, and fused different features with a vector space using different strategies. Experimental results show that the explored feature sets and their combination can effectively improve the performance of named entity classification.
As the largest online collaborative multilingual encyclopedia, Wikipedia contains millions of available articles in 285 languages. Although written collaboratively by volunteers, Wikipedia has been found to have similar coverage and accuracy to Encyclopedia Britannica, in which articles were contributed by experts [1].
With the development of the Knowledge Base Population track at Text Analysis Conference (TAC), an increasing number of scholars have recently focused on the combination of Wikipedia and named entities (NEs). Compared with other resources, Wikipedia contains a large amount of NEs that have a normalized structure and many types of information. These characteristics make Wikipedia an excellent resource for numerous NE applications, such as named entity recognition (NER) [2], entity linking [3], and entity knowledge base [4].
For pre-defined NE types, the manual process of collecting and annotating NEs is a time-consuming task, and requires significant skill. To address this problem, a number of researches have presented methods to classify articles in Wikipedia with NE types, which is usually considered an NE classification problem of Wikipedia articles. By using the result of NE classification, NE gazetteers can automatically be constructed to improve the performance of NER [5], or increase NE type information for a disambiguation system [6]. Another important application is automatic NER corpora generation from Wikipedia [7, 8], which can be used to annotate the NE types of outgoing links, in sentences within Wikipedia articles.
Different languages have different conventions and resources. For the task of English NER, one of the most effective orthographic features is capitalization in English, which aids in generalization to new text of different genres in an NER system. The capitalization feature of aliases in incoming links is also utilized, to identify large portions of non-entity articles in English Wikipedia [9]. However, this feature is nonexistent in some languages, such as Chinese and Arabic, and the diversity of nonentity articles will undoubtedly lead to greater difficulty in NE classification. To improve the performance of NE classification in special languages, some language-dependent features can be utilized. For example, in the Chinese NER system, the NEs of person (PER) type usually start with the common Chinese family names [10] (e.g., ‘
This paper attempts to classify articles in Chinese Wikipedia with fine-grained NE types. The contribution of this paper lies in considering multi-faceted information in Wikipedia, such as some traditional features and novel features (e.g., co-occurrence relation and article title feature), to construct feature sets; in analyzing the characteristics of each feature and designing different feature selection methods; and in fusing different features with a vector space through different strategies, such as increasing weight, or adding new feature terms. To the best of our knowledge, this study is the first to perform such NE classification in Chinese Wikipedia.
This paper is organized as follows: Section II introduces the related work. Section III describes the NE types used in our experiments. Section IV discusses the feature sets extracted from articles in Chinese Wikipedia. Section V describes the datasets and presents the results of the experiments. Section VI concludes the paper.
The works to classify Wikipedia articles with NE types mainly fall into two categories:
Methods based on heuristic rules usually achieve high precision. Heuristic rules can be established more easily than those of other natural language processing (NLP) applications, such as NER. However, the problem with this method is limited coverage. Moreover, a large number of Wikipedia articles cannot match any rule. Thus, the methods based on machine learning are generally applicable to all articles in Wikipedia and can be applied independently [14] or combined with heuristic rules [8].
Researches on machine learning mainly focused on the features extracted from Wikipedia articles, and the classifiers adopted to classify the articles. This method is represented by the works of Watanabe et al. [15], who utilized conditional random fields over a graph constructed from the outgoing links in the articles, and classified Wikipedia outgoing links with NE types. Dakka and Cucerzan [14] trained SVM and Naïve Bayes classifiers by using page-based and context features, and their experimental results showed that structural features (such as the data in the tables) are distinctive in identifying the NE type of Wikipedia articles. Saleh et al. [16] extracted features from abstracts, infobox, category, and persondata structure, and improved the recall of different NE types, by using beta-gamma threshold adjustment. Tkatchenko et al. [17] adopted similar features to Tardif et al. [18]. They added a ‘List of’ feature to the bag-of-words (BOW) representation, and added a boolean feature, which is the result of a binary rule, to increase separability between the articles of NEs and non-entities.
Most previous researches have focused on the English language, which is characterized by a distinction in the capitalization of common and proper nouns. However, for some other languages (e.g., Chinese, Arabic), the number of potential NEs is significantly larger than that for English, because no distinction can be utilized to remove non-entity articles. To make the most of the distinction in the English language, a reasonable assumption is usually adopted that the article in non-English Wikipedia can be classified into the same NE type as the corresponding English article that is associated with cross-language links [7, 13]. However, this method suffers from limited coverage.
Some language-dependent features have also been introduced to improve performance for special languages. Higashinaka et al. [19] devised some features (e.g., article title features) that are related to the Japanese language, and created an extended gazetteer of 200 NE types. Alotaibi and Lee [20] defined language-dependent and independent features in Arabic Wikipedia.
Wikipedia contains a wealth of multi-faceted information, but only part of the available information is used in related researches. More attempts need be made to exploit the information in Wikipedia as intensively as possible. Moreover, the morphological and orthographic features in special languages can also be used to significantly improve performance.
Wikipedia provides a categorization hierarchy called folksonomy, which refers to dynamic knowledge organization systems created by communities of distributed volunteers. However, its complicated hierarchies and largescale categories make it unsuitable for many semantic applications. With the closer combination of Wikipedia and NE technologies, more researches have focused on NE types for their exact definition and wide application.
Different sets of NE types can be adopted for different applications. To determine the set of NE types in this paper, we extend three universal NE types (PER, ORG, and LOC) into fine-grained types. As in the ACE (Automatic Content Extraction) evaluation (cf. ACE 2005), geo-political entity (GPE) includes inhabited locations with a government, such as cities and countries. Facility refers to a functional, primarily man-made structure. For the definition of the three universal NE types, we also principally refer to the ACE evaluation, and give some examples in Wikipedia.
Person Entities (PER): Person entities are not limited to specific persons in real life (e.g., ‘
Organization Entities (ORG): Organization entities are usually corporations, agencies, and other groups of people defined by an established organizational structure. Generally, such entities are classified with the following subtypes: government (e.g., ‘
Location Entities (LOC): Location entities are usually geographical entities, such as geographical areas and landmasses, bodies of water, and geological formations. These entities include water-body (e.g., ‘
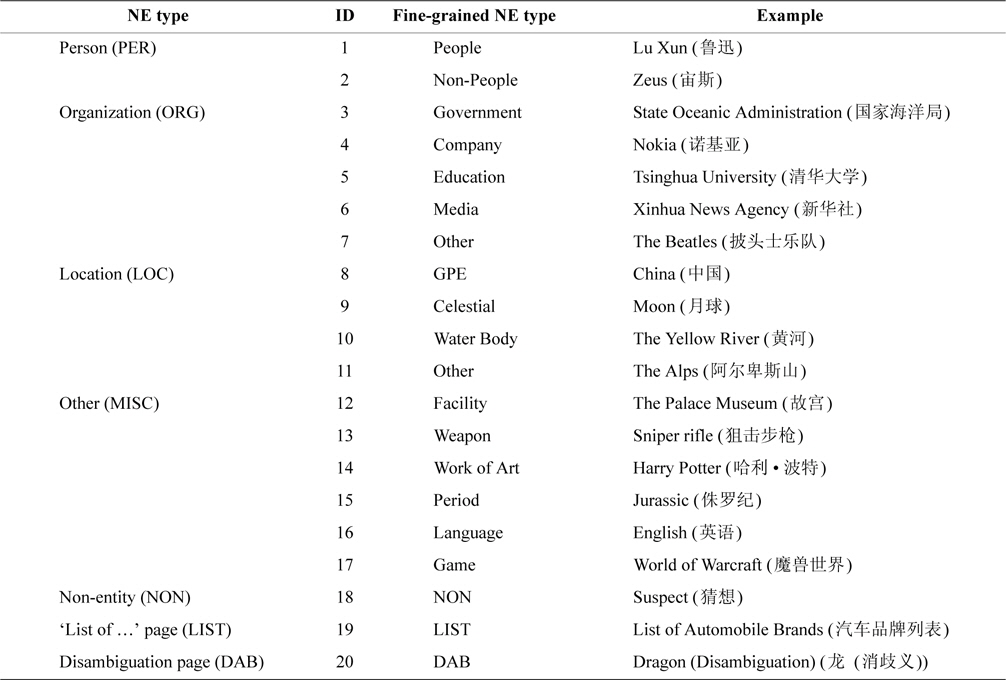
The coverage of each NE type in Chinese Wikipedia is also considered in the process of designing fine-grained types. Finally, we select five coarse-grained types (PER, ORG, LOC, other miscellaneous entity [MISC], and nonentity [NON]), and 18 fine-grained types. Two auxiliary types (‘List of ’ page and Disambiguation page) are identified by simple heuristic rules. All fine-grained types and their examples are listed in Table 1.
[Table 1.] Fine-grained NE types and the examples
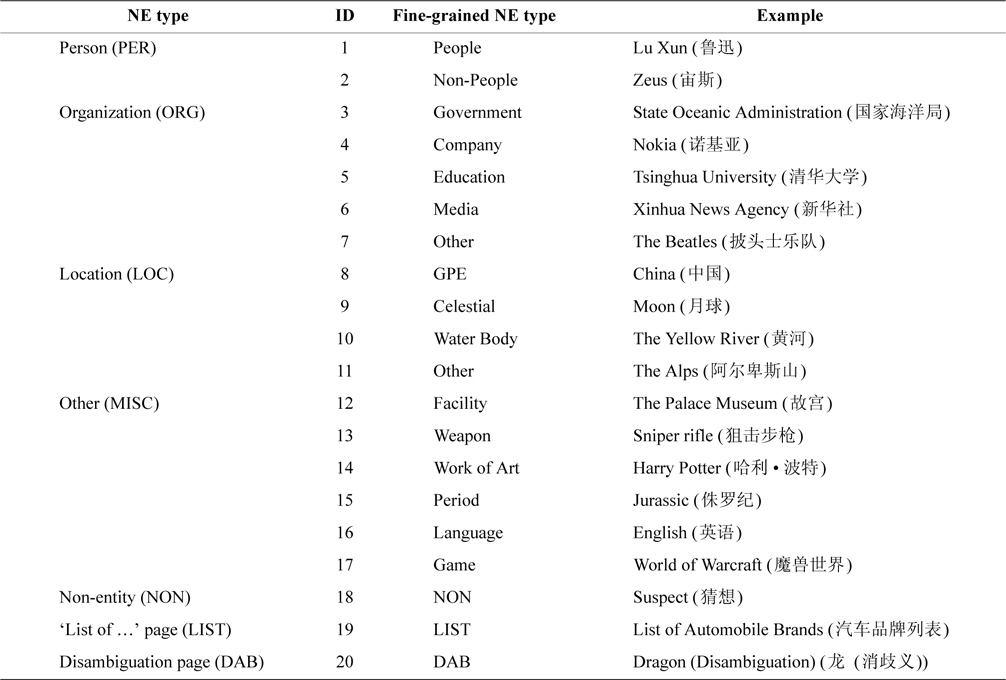
Fine-grained NE types and the examples
For the articles in Wikipedia, we prioritize the extraction of features with great discrimination for NE types. Wikipedia editors tend to use the same structure, such as similar section title, infobox, and category, as similar existing articles. However, a large number of articles do not possess any structure information, or possess only some items. For these articles, we should utilize some common features, such as article content and article title, to identify the NE types.
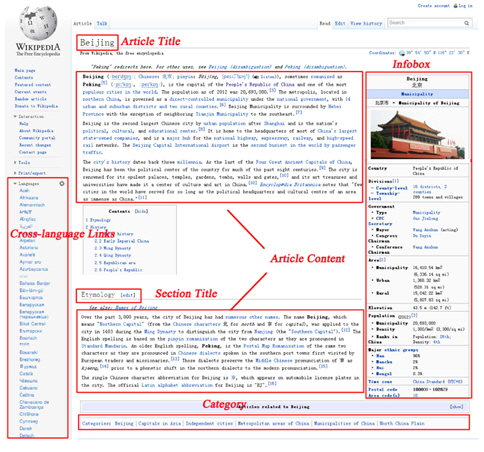
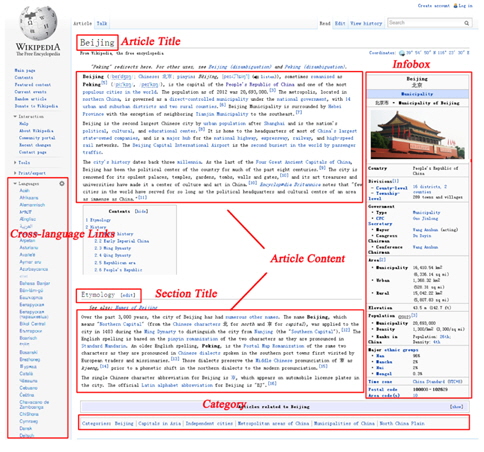
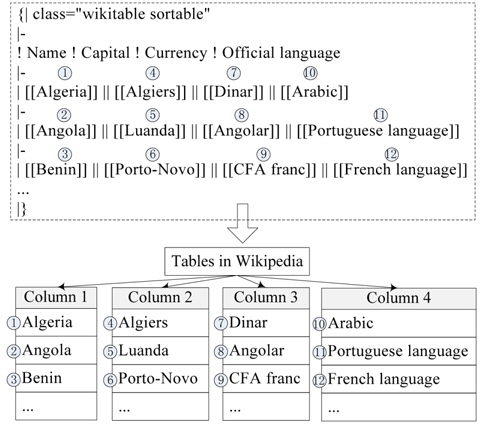
We explore four feature sets, of article content feature, structured feature, category feature, and article title feature. As a common feature set, the BOW representation based on article content is used to build a basic feature vector. Other features can be utilized to optimize the weight of terms, or to build a new feature vector that can be combined with a basic feature vector to classify Wikipedia articles. We consider multi-faceted information in Wikipedia to build our feature sets. Fig. 1 shows an example of information areas in the Wikipedia article ‘
Article content refers to a detailed description of a Wikipedia article that introduces the related knowledge in textual format. The BOW representation based on article content has been adopted in many researches [14, 19], and is considered a stable feature, because almost all Wikipedia articles contain such information.
Unlike English text, no marked word boundaries exist in Chinese text. We use toolkit NLPIR (http://ictclas. nlpir.org) to realize Chinese word segmentation and part-of-speech tagging, and only keep the terms of the most representative parts-of-speech (noun, verb, and adjective). The feature vector that contains the BOW representation of reserved terms is then built, and the feature weight is computed using the TF-IDF method, as follows:
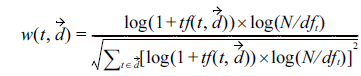
where is the number of times that term
Although the feature space is effectively limited by part-of-speech selection, the dimensional space remains large, and the data could be plagued by a substantial amount of noise terms. To reduce feature dimensions, the feature selection method of information gain (IG) is introduced. IG is defined as follows:
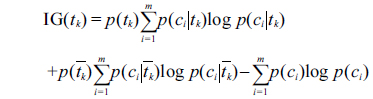
where
The articles in Wikipedia are edited by using wiki markup language, and these semi-structured texts are converted into HTML pages by wiki tool. With wiki markup, some important information can be tagged (e.g., section title and infobox template). We discarded outgoing links, because they are more inclined to explain the topics of related articles. Finally, three representative structured features were chosen, namely, section title, infobox, and co-occurrence relation in the lists and tables.
Section Title: Section titles are usually the framework of an article. Words in section titles can indicate NE types more clearly. For example, section titles ‘
Infobox: Infobox templates are a set of subjectattributes-values triples that often contain a condensed set of important facts relating to the article. The attributes of infobox are predefined by the infobox template. For example, the infobox ‘
An analysis of distribution of infobox subjects reveals two main problems. First, many Wikipedia articles do not use infobox templates. Fig. 2 shows the percentage of articles that contain an infobox template in the annotated articles of each NE type. Different percentages are found for each NE type. Second, the overlapping subjects of infoboxes could limit the performance. For example, the template ‘
Following the analysis above, we build another feature vector based on infobox subject, and add the label ‘Infobox’ for all features, such as ‘
Co-occurrence Relation: The co-occurrence articles, which are tagged with special wiki markup, usually have strong semantic correlation, and the same NE type. Nadeau et al. [21] showed the possibility of creating a list of entities from HTML lists and tables on the Web. Watanabe et al. [15] introduced a graph structure based on the co-occurrence of elements to improve the classification performance of NE types.
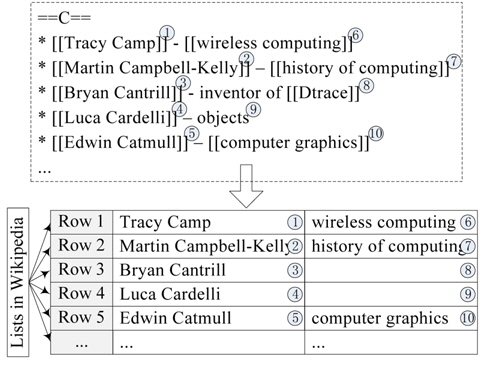
Considering that a large amount of noisy results could be identified by complicated structures, we only extracted the co-occurrence relation from the lists and tables in the ‘List of ’ pages. These hierarchical layouts, especially list items, are usually used to extract hyponymy-relation candidates and to then realize large-scale hyponymy-relation acquisition [22, 23]. Tkatchenko et al. [17] added the ‘List of’ feature, which is constructed by tokenizing and stemming the titles of all ‘List of ’ articles containing the current article, to the BOW representation. In this paper, the co-occurrence articles are utilized to extract representative words and increase their weights because only a small number of articles tagged with co-occurrence relation can be found in Chinese Wikipedia. Fig. 3 shows the transformation of a list tagged with wiki markup into a co-occurrence relation of articles in the same NE type. Some lists sometimes have more than one article in each row (Fig. 3). To resolve this issue, we choose only the same hierarchical articles with the same pattern, such as articles ①, ⑥ and ②, ⑦ in Fig. 3. Similar to Fig. 3, Fig. 4 shows the transformation of a table into a co-occurrence relation. We extract the co-occurrence relation from the same column in the table.
Compared with the total number of Wikipedia articles, the number of articles tagged with the co-occurrence relation remains small (approximately 7%), and the percentage will decrease rapidly, if the article pair is limited to the training and test dataset, respectively. To highlight the commonness expressed by these articles, we extract common words and increase their weights. The detailed process is as follows:
1) For the test article
2) Only the words that occur in at least half of the cooccurrence articles are reserved;
3) The reserved words and their frequency are added to the feature vector based on the article content of the test article
Categories usually express a relation that is common to all articles in the category, and one article can simultaneously belong to multiple categories that describe the article from different perspectives. For example, the article ‘
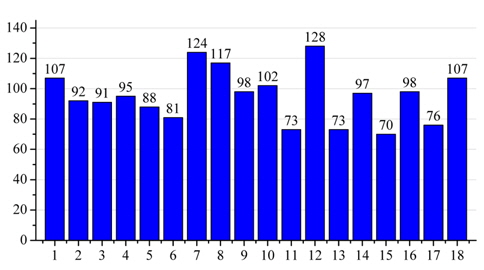
Wikipedia categories are usually used in the method based on heuristic rules by defining category patterns [8, 24, 25]. Tardif et al. [18] directly tokenized the names of all categories applied to each article, and added each token to the BOW representation of the article. Consider that there are a large number of categories (approximately 140,000) in Chinese Wikipedia, but volunteers use only a few. Fig. 5 shows the percentage of categories that contain fewer than the specified number of articles. Approximately 21% of categories are empty and nearly 80% of categories contain fewer than 12 articles.
Based on the analysis above, several constraints are designed for category selection. For a set of categories
Universality Constraint: A large number of categories are rarely used in Wikipedia. To filter less-used categories, we reserve the categories that contain more than two articles (Σ
Centrality Constraint: The articles in the categories need to be annotated with a few NE types, such that the number that satisfies the condition
Superiority Constraint: The NE type can be considered as superior, if it has a more prominent number than others in the category. We use the variance of vector (
After category selection, a number of representative categories are selected. We build another feature vector based on the reserved categories, and add label ‘Category’ for all features, similar to the process employed for infobox subjects.
The article titles in Chinese Wikipedia provide internal evidence of NE type. For example, the article title that ends with ‘
Many NER methods utilize the surface form of article titles and their context to extract and classify NEs. We design several NER features based on the structural characteristics of Chinese NEs.
1) NER Feature
Related researches on NER mainly focus on three universal NE types (PER, ORG, and LOC), for which some special features are usually designed. We give several special features that are based on Chinese NER.
Family Names: Some common Chinese family names, such as ‘
Number of Characters: Chinese names usually have two to four Chinese characters, including family name and given name.
Special Separator: The separator ‘•’ is commonly used in Chinese names translated from foreign names, such as ‘
Common GPEs: Article title of ORG type is most likely to contain common GPEs, such as ‘
Last Chinese Character: The last Chinese character, such as ‘
2) Parenthesized Text
In addition to NER feature, another noticeable feature is the head nouns of parenthesized text in the article title. Approximately 10% of articles in Chinese Wikipedia are tagged with parenthesized text, which is mainly used to provide an explanation for a Wikipedia article. For example, ‘
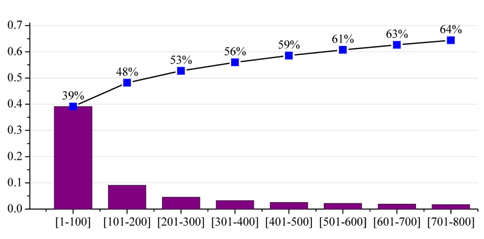
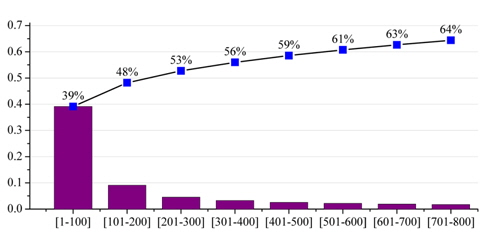
For all head nouns (terms) in parenthesized texts of article titles, we compute the frequency of each term and rank all terms by this frequency. Every 100 terms are grouped together from ranked terms, and the frequency sum of each group is computed. The bar-chart in Fig. 6 gives the percentage of the frequency sum of each group in the total frequency of all terms, whereas the line-chart in Fig. 6 shows the percentage of the cumulative frequency of top groups. Through statistical analysis for parenthesized text, we found that a significant coverage scale can be obtained by using only a small number of frequent terms. A large percentage of GPE terms can be found in parenthesized text (approximately 29% in total frequency for the top 100 terms), such as ‘
In this paper, we constructed several common gazetteers that could easily be collected on the Internet. These gazetteers include Chinese family names gazetteer, common GPE gazetteer, and indicative last Chinese character gazetteer. Then we built a new feature vector based on article title. This vector contains four special features (including family names, number of characters, special separator, and common GPEs), a BOW representation of the feature ‘last Chinese character’, and a BOW representation of the feature ‘head nouns in parenthesized text’. The weights of the related feature are set to 1, if the current article title satisfies corresponding criteria; otherwise, the weights are set to 0.
The Chinese version of Wikipedia (http://download. wikipedia.com/zhwiki/) in March 2013 is used in our experiments. This version contains 735,000 Wikipedia articles, and each article corresponds to a single Web page.
To create the dataset of Wikipedia articles with finegrained NE types, two different sampling methods can be used: random sampling and popular sampling. Random sampling produces many Wikipedia articles that rarely occur in text, and only have small potential in NE applications. Moreover, these articles are more challenging, because they are rarely edited and some types of information are absent in Wikipedia. Popular sampling tends to choose Wikipedia articles targeted by the most frequent outgoing links. However, these articles usually refer to some common locations or concepts, such as ‘
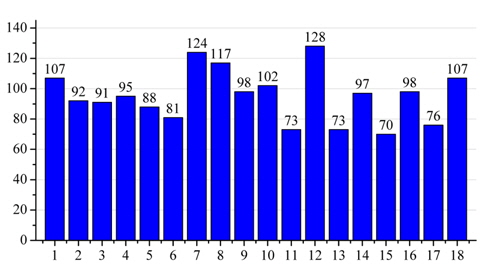
We adopted a compromise method that balances randomness and popularity in our experiments. Beginning from several seed articles, we randomly selected some articles occurring in the page of seed articles and then continued this process with selected articles. By using this method, we developed a dataset of 1,717 Chinese Wikipedia articles to evaluate the performance of NE classification. Fig. 7 shows the distribution of NE types. Two independent annotators were involved in the annotation process. For each article, the URL that points to the Web page of the Wikipedia article is generated. The annotators can more easily make their judgment about NE types of articles by using the richer information shown on the Web page.
Previous researches have mostly focused on English Wikipedia, and an important heuristic rule such that article titles are capitalized if they are proper nouns can be used to determine whether the articles are NEs [9]. However, this heuristic rule cannot be applied to Chinese Wikipedia. To distinguish NE type of non-entity (including common concepts and NE types not in our list) from other NE types, it must be added to the classifier.
The experiments adopted the strategy of two-layer classification. First, the types of LIST and DAB were easily identified, using some heuristic rules. The article titles of “List of
” pages usually end with the word ‘
We evaluated the models by using 5-fold cross-validation and adopted the widely used Precision, Recall, and F1 to measure classification performance. The weighted average of each measure was adopted to evaluate the overall performance of all NE types. The weighted average of precision in t-th cross-validation (
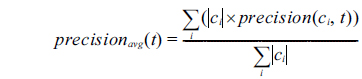
where |
The global measurements of each NE type evaluated by 5-fold cross-validation were computed by:
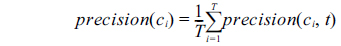
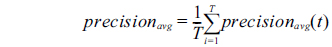
where
In the experiments, the first-layer classification easily achieved outstanding performance by using the defined heuristic rules. Thus we emphasized the classification of other fine-grained NE types. As a common feature set, article content feature can effectively overcome the problem of zero-vector caused by other missing feature sets. We thus took the model applying only the article content feature as the baseline.
We performed several experiments as follows: 1) we observed the influence of feature dimension using the feature selection method of IG; 2) we verified the effectiveness of each feature set; and 3) we tested the performance of mixed feature sets.
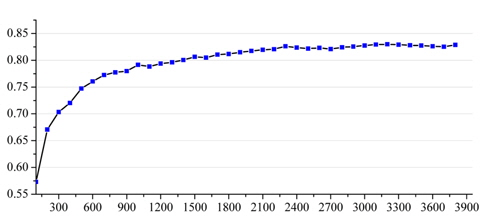
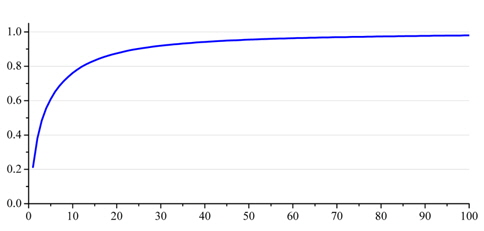
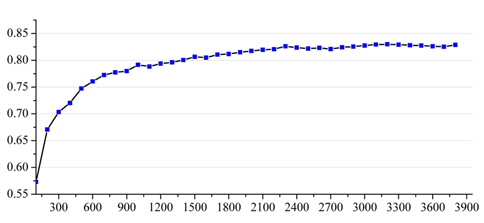
Influence of Feature Dimension: High feature dimension consumes more computational resources with only a negligible improvement in classification performance. Fig. 8 shows the F1-measure for the article content feature set (baseline) of different feature dimensions, and we can see that sufficient representative features are covered, when the feature dimension reaches a particular value. In this work, we set the value of feature dimension to 3,000 and applied this parameter to the following experiments.
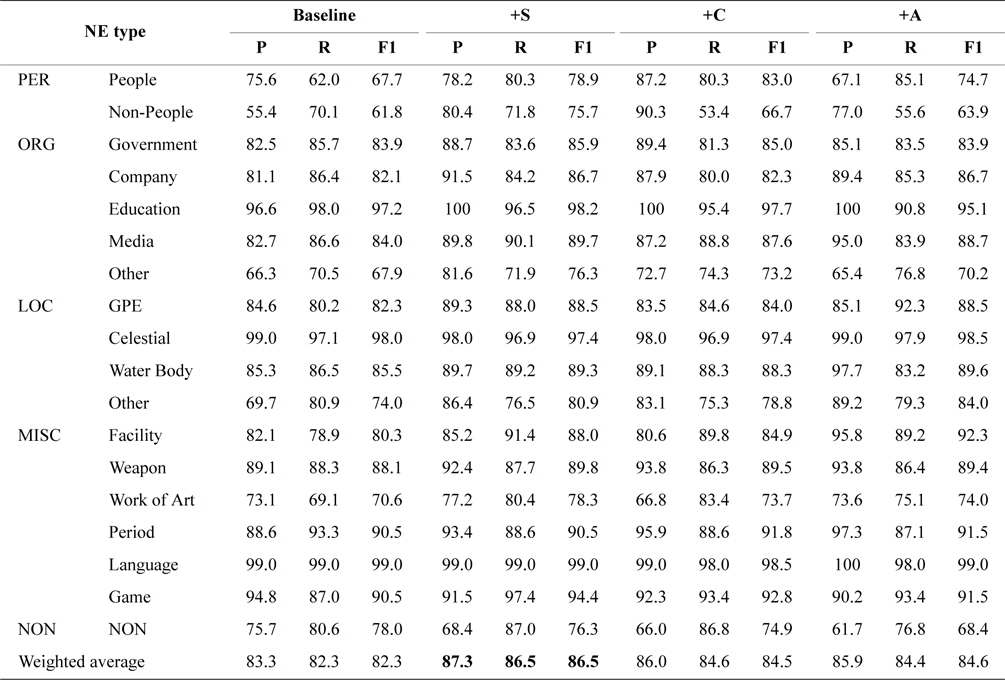
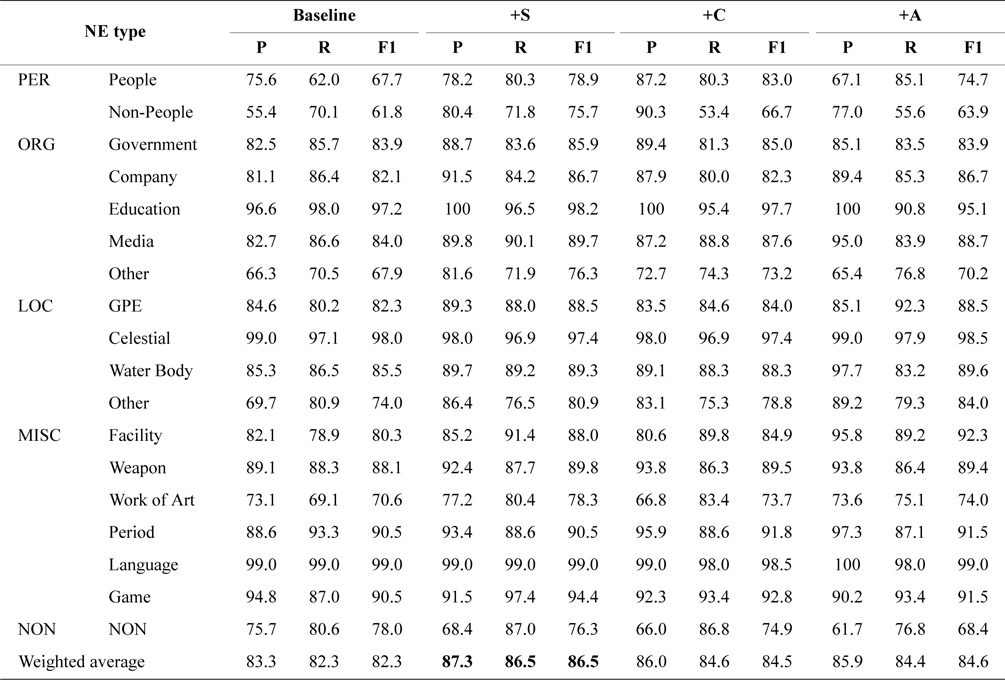
Effectiveness of Each Feature Set: To verify the effectiveness of each feature set, we trained classifiers by using the combination of each feature set and article content feature set (baseline), respectively, which are expressed as ‘+S’ (structured feature set), ‘+C’ (category feature set), and ‘+A’ (article title feature set). Table 2 shows the experimental results. By analyzing the results, we can find some valuable conclusions as follows:
[Table 2.] Precision (P), recall (R) and F1-measure for each feature set
Precision (P), recall (R) and F1-measure for each feature set
1) The addition of the feature set can improve performance at different levels. The combined feature set ‘+S’ achieved better improvement of the F1-measure than the ‘+C’ and ‘+A’ feature sets.
2) For two fine-grained NE types in PER type (People and Non-People), the classifier performed worse while only using the article content feature set. The possible reason is that various descriptions exist in Wikipedia to introduce different people. The classification performance achieved great improvement while each feature set, especially structured feature set, was combined with article content feature set (+S, +11.2% for People and +13.9% for Non-People; +C, +15.3% for People and +4.9% for Non-People).
3) A certain feature set is a great indicator of some NE types. For example, the combined feature set ‘+A’ could achieve great improvement for MISC:Facility (+12.0% F1-measure), LOC:Other (+10.0% F1-measure), and LOC:GPE (+6.2% F1-measure). After analyzing the evaluation data of these NE types above, we find that a lot of article titles have the same last Chinese characters, such as ‘
4) For part of NE types, such as MISC:Language and LOC:Celestial, outstanding performance could be achieved by the baseline system, because there are greater differences between the terms in article contents of these NE types. Furthermore, the NE type ORG:Other and LOC:Other achieved poor performance because they are composed of multiple fine-grained NE types.
5) For most fine-grained NE types, the systems trained by combined feature sets outperformed the baseline system by F1-measure. However, F1-measure of NON:NON type decreased because of poor precision (more articles belonging to each NE type are identified as non-entity type). The performance of combined feature set ‘+A’ seriously decreased (-9.6% F1-measure), which resulted in minor improvement of overall performance by using this feature set ‘+A’.
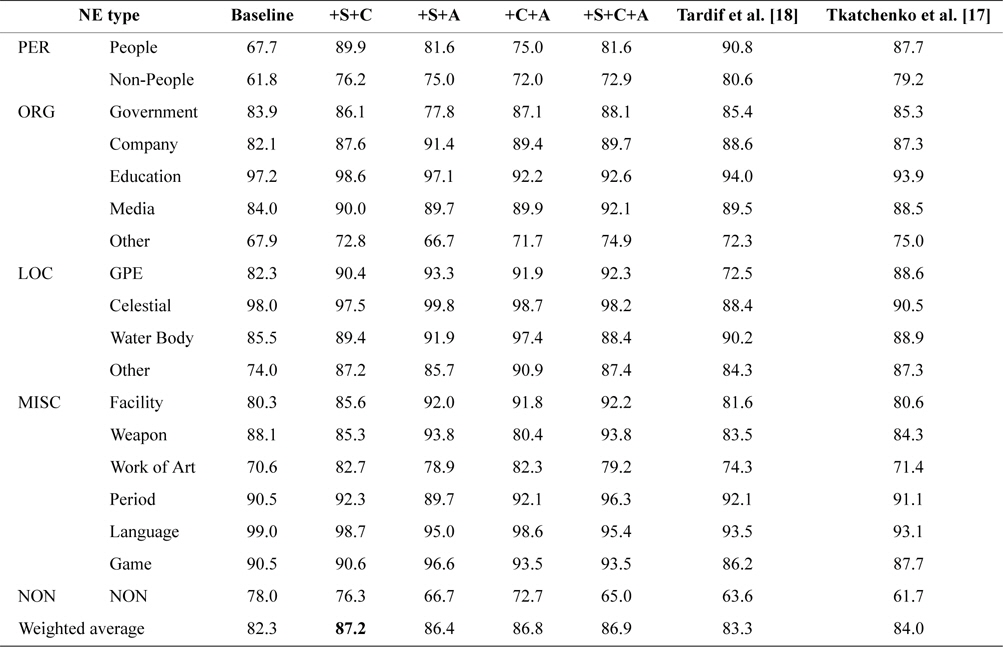
Performance of Mixed Feature Sets: The mixed feature sets were used to identify the best combination of feature sets. We combined structured feature set (S), category feature set (C), and article title feature set (A) based on the baseline, and Table 3 reports the results of these mixed feature sets.
[Table 3.] F1-measure for mixed feature set
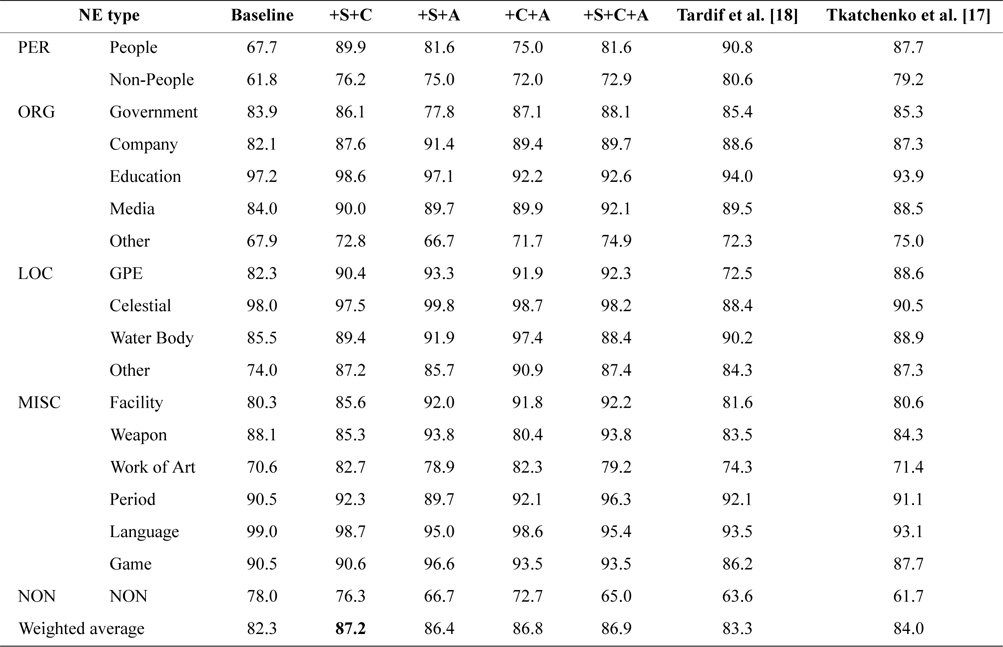
F1-measure for mixed feature set
For different languages, it is difficult to perfectly implement the previous works because language-dependent features and heuristic rules are usually adopted to achieve better classification performance, such as in Japanese [19] and Arabic [20]. In order to evaluate the resulting training set in classification, we re-implemented the state-of-the-art method presented by Tkatchenko et al. [17], and their baseline method that is similar to Tardif’s classifier [18]. Their baseline method used the text of the first paragraph as a basic feature space, and a range of additional ones, namely, Title, Infobox, Sidebar, and Taxobox tokens, stemmed and tokenized categories, and template names. Category, Template, and Infobox features are extended with different prefixes (e.g., ‘cat:’) to distinguish them from the same tokens found in article text. Tkatchenko et al. [17] extended the features presented by Tardif et al. [18]. They added the ‘List of’ feature, which is constructed by tokenizing and stemming the titles of all ‘List of ’ articles containing the current article to the BOW representation. We neglected the boolean feature, which is used to increase the separability between articles about NEs and non-entities, because some English heuristic rules (such as Wikipedia naming conventions) were utilized to compute this feature, and pre-defined category patterns and template patterns could not be obtained.
In Table 3, we can see that the best performance was achieved by the mixed feature set ‘+S+C’ (approximately 4.9% F1-measure higher than the baseline system). In all fine-grained NE types, significant improvements were achieved by People and Non-People in PER type, such as +22.2% F1-measure for People and +14.4% F1-measure for Non-People, by using mixed feature set ‘+S+C’. Moreover, the methods of Tardif et al. [18] and Tkatchenko et al. [17] outperformed the baseline system by 1%–2% F1-measure, but the overall performance of their methods in Chinese Wikipedia was far worse than the results of corresponding experiments in English Wikipedia.
From the results of Tables 2 and 3, we also find that the article title feature set can improve the classification performance, but the improvement is less significant than that of other feature sets. The reason is that this feature set mainly focuses on coarse-grained NE types and lacks discriminatory capability between fine-grained NE types. However, these coarse-grained NE types, especially three universal NE types (PER, ORG, and LOC), are important in many NLP applications. We also constructed training and test datasets with coarse-grained NE types, and the results in Table 4 show that a significant improvement could be achieved while adding the article title feature set (+S+C+A, +6.6% F1-measure; +C+A, +5.8% F1-measure; +S+A, +5.2% F1-measure).
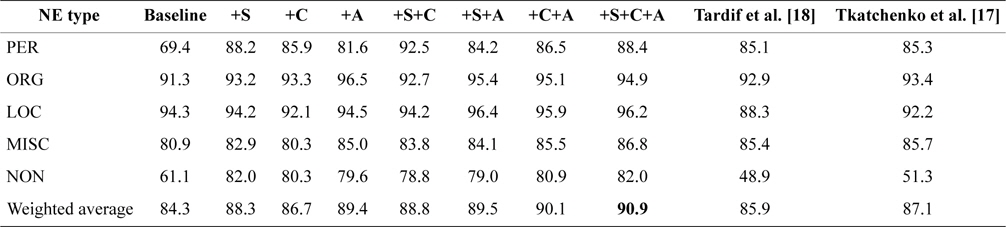
[Table 4.] F1-measure for coarse-grained NE types
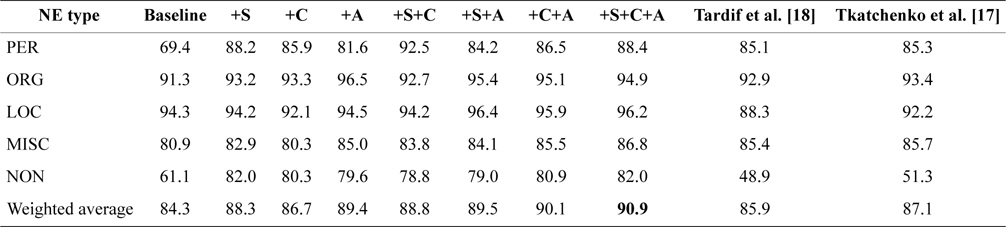
F1-measure for coarse-grained NE types
This paper presented a study on the NE classification of the articles in Chinese Wikipedia with fine-grained NE types. We explored four feature sets, namely, article content feature, structured feature, category feature, and article title feature. For each feature set, different strategies were designed to realize feature fusion. Experimental results showed that the combination of feature sets could effectively improve classification performance.
In future works, we will conduct experiments with hierarchical NE types using the method of hierarchical classification. Furthermore, the strategy of model fusion will combine the virtues of different models, such as the classifier and graph model. For application, the proposed method in this paper will be used to automatically generate Chinese NER corpora with the domain characteristics.