




Nearest neighbor search is a fundamental operation in data processing that determines a specified number of data objects nearest to an object specified in a query from a collection of data objects. As the amount and dimensionality of data increase, this simple operation places a considerable burden on search time and space. A related problem to which nearest neighbor search techniques are applicable is the similar pair identification problem, where all pairs of data objects similar to each other need to be found. Conventional tree-based indexing techniques, such as
As an enabling technique for nearest neighbor search and similar pair identification for large amounts of high-dimensional data, locality-sensitive hashing (LSH) techniques use hashing to conduct rapid searches at the cost of the exactness of the results. LSH techniques create indexing structures, for which they extract short signatures for data objects using hashing functions and maintain the data objects in buckets according to their signatures. Since there is no guarantee that all similar objects are mapped to the same bucket, LSH techniques are approximate. For nearest neighbor search or similar pair identification, LSH techniques first extract the signature for a given query, and find the candidates to be exampled by calling out data objects with the same signature as the query. The volume of the resulting candidates is much smaller than that of the original data set.
When measurements are recorded from different perspectives, the corresponding data comes to have as many attributes as measurements. Some attributes are numerical and others can be categorical. Attributes are sometimes specified by a set, e.g., text values in addresses, memos, and messages. Most LSH techniques have been developed for numerical data, and a few LSH techniques have been attempted for categorical data and set-valued data [1]. Nevertheless, much data in real life contain numerical and categorical attributes together. Little attention has been paid to LSH techniques to deal with data containing such mixed attributes.
This paper is concerned with an LSH technique applicable to large collections of data with both numerical and categorical attributes. The remainder of the paper is organized as follows: Section 2 contains a description of LSH and existing techniques for numerical and categorical data, respectively. Section 3 details the proposed LSH technique to incorporate dual hash functions to handle both numerical and categorical attributes. Some experimental results of the proposed method are presented in Section 4, and conclusions are offered in Section 5.
2.1 Locality-Sensitive Hashing
To efficiently locate a specific data item in a collection of data, a number of indexing structures have been developed in the literature [2–8]. Most of these adopt either tree-based or hashingbased approaches. Tree-based indexing methods encode the space partitioning information into a tree structure in which the data of interest can be found by scanning down the tree. Examples of tree-based indexing methods are
In nearest neighbor search and similar pair identification, it is desirable to find data similar to the given data rather than to locate it. LSH is an approximate search technique for data items similar to the one being queried. The query uses special hash functions that map similar data objects to the same bucket with a high probability, whereas conventional hash functions do not make any assumptions about the similarity or homogeneity in buckets.
The notion of locality-sensitive hashing was first introduced by Gionis et al. [10], Indyk et al. [11], who defined localitysensitive hash functions as follows:
A family of functions = {
if d(p, q) r1, then (h(p) = h(q)) P1.if d(p, q) r2, then (h(p) = h(q)) P2.
Here,
Most LSH techniques encode data objects into short binary strings that play the role of signatures. Data objects with the same binary strings are maintained in the same buckets. When a query is made, it is also encoded into a binary string using the same LSH technique. Following this, data objects from the bucket with the binary string are examined according to a nearest neighbor search because the bucket might contain data objects similar to the one being queried.
Most LSH techniques make use of multiple binary hash functions, each of which produces a bit value such that all bit values are subsequently concatenated into a binary string. The binary strings play the role of bucket identifiers for corresponding data objects. Many LSH techniques have been developed for data with only numerical attributes [12–18]. The following describes a few of them.
LSH hashing for binary codes by Andoni and Indyk [12], Datar et al [13] is a method that uses several hyperplanes specified randomly selected projection vectors to define hyperplanes. Each hyperplane plays the role of a hash function that produces a single bit: 1 for one side of the hyperplane and 0 for the other side.
Boost similarity-sensitive hashing [19] uses a supervised method that first samples a subset of data to determine similar and dissimilar pairs among them, and regards similar pairs as positive examples and dissimilar pairs as negative ones. Following this, it learns weak classifiers to separate positives from negatives using the AdaBoost algorithm [20].
The restricted Boltzmann machine (RBM) is a kind of Markov random field that has a layered network to allow connections only between the visible layer and the hidden layer, where the nodes of the network are stochastic binary units. RBM can learn to maximize the probability of reconstructing the original input at the visible layer by activating the hidden layer using a contrastive divergence sampling-based update rule. The RBMbased LSH method [16] uses a stacked RBM with multiple layers, where the upper layers have a gradually decreasing number of nodes. The outputs of the topmost layer are the binary hash codes for the data fed into the bottom-most layer as input.
The spectral hashing method [18, 21] first finds the principal axes of the data set and adjusts the data along these axes. It then chooses the k smallest one-dimensional eigenfunctions to produce binary codes for data by thresholding the eigenfunction values for data at level zero.
In semi-supervised hashing [17, 22], both labeled and unlabeled data pairs are used to determine projection vectors to minimize the empirical error in the labeled data while maximizing the entropy of the generated hash bits over the unlabeled data. The projection vectors are obtained by eigendecomposing a
In unsupervised sequential projection learning for hashing [17], hash functions are sequentially learned as pseudo-labels are generated at each iteration. Subsequent hash functions are determined so that they correct errors made by the preceding hash functions. The pseudo-labels are assigned to pairs of closed data points residing on the opposite side of the hyperplane and pairs of far data points on the same side of the hyperplane. Once pseudo-labels are assigned, the method works in a similar manner to semi-supervised hashing [22].
In density-sensitive hashing [15], hash functions are determined by taking into account the distribution of the data set. The LSH method first applies a k-means algorithm to the data set to generate small groups and determines pairs of adjacent groups. It then finds median planes to separate adjacent groups and evaluates them according to their entropy. It chooses as hash functions the top-ranked median planes in order of descending entropy score.
In LSH for categorical data [1], the similarity matrix for categorical values is first determined for each categorical attribute using a data-driven distance [23]. A hierarchical clustering is then carried out for categorical values with respect to the similarity matrix for them. Following this, clusters for categorical values are selected at an appropriate level of the dendrogram of the hierarchical cluster. Each cluster now contains a set of categorical values and is assigned a binary code. A hash function is defined for each categorical attribute that produces a binary code corresponding to the value of the categorical attribute. When there are multiple attributes in data, an LSH function is defined by combining the hash functions for the categorical attributes. The LHS function produces a binary string for categorical values and associates a bucket with a binary string in the domain of the LSH function.
3. Locality-sensitive Hashing for Data with Numerical and Categorical Attributes
There is no method of assigning data with categorical attributes in a coordinate system because there is no inherent ordering relationship among categorical values. When numerical attributes occur together with categorical attributes, data objects cannot be projected into a coordinate system. LSH techniques for numerical data basically partition the (Euclidean) data space into subspaces, each of which corresponds to a bucket of a hash function. It is not easy to have available a distance measure for data having both numerical and categorical attributes. Hence, it is better to consider numerical attributes and categorical attributes separately. The similarity between a query and data object is regarded as high when both the similarity of numerical attributes and that of categorical attributes are simultaneously high. When we collect the candidate data into a query, it is effective to take the intersection of the data objects with numerical attributes similar those of the query, as well as that of data objects with categorical attributes similar to those of the query. We thus propose an LSH technique that takes this approach.
3.1 The Proposed Dual Hashing Structure
To support LSH for data with numerical and categorical attributes, our proposed method uses two ways of hashing: one for numerical attributes and the other for categorical attributes. For convenience of description, we use the following notations:
Figure 1 shows the proposed dual hashing structure for data with both numerical and categorical attributes. For the given data set
When a query


The candidate data set

3.2 LSH for Numerical Attributes
To get the specified number
3.3 LSH for Categorical Attributes
A typical distance measure

Hence, the measure cannot have any distance information when the compared categorical values are different. To handle this problem, data-driven distance measures have been studied for data with categorical attributes [23]. They make use of attribute value distributions in a given data set and determine the distances between attribute values, i.e., between categorical values. Boriah et al. [23] have surveyed data-driven similarity measures on categorical values. Three measures among them are presented in the following, where
(IOF measure)
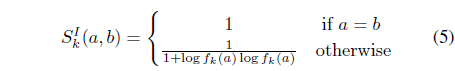
(OF measure)

(Goodall measure)

When there are multiple attributes

The similarities are combined into a single value

To test the performance of the proposed method, we conducted a few experiments under the following conditions: for LSH with numerical attributes, we used density-sensitive hashing, which explores the geometric structure of data to generate hash codes. For LSH with categorical attributes, we used data-driven categorical LSH [1], which makes use of the data-driven similarity measure for categorical values.
We conducted experiments for two synthetically generated data sets. Each synthetic data set consists of 1,000,000 data objects with 10 numerical attributes and five categorical attributes, each of which has 10 categorical values. The first data set
For numerical attributes, 10-bit LSH codes were generated using density-sensitive hashing. For categorical attributes, the categorical values were encoded into three disjoint groups, and 35 indices were created altogether. For both data sets
[Table 1.] Experimental results of the proposed method

Experimental results of the proposed method
For big data applications, nearest neighbor search and similar pair identification can be burdensome tasks even though they are rather fundamental operations. Various LSH techniques have been developed to handle such tasks in an efficient but approximate manner. Most LSH techniques are applicable to only numerical data, and little attention has thus far been paid to how LSH can be engineered for data sets containing numerical and categorical attributes together. We proposed in this paper a method to combine numerical and categorical LSH techniques to handle this problem. From the experiments, we concluded that the proposed approach provides improved performance, as we had expected.
















