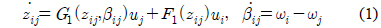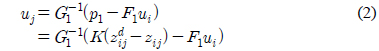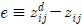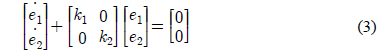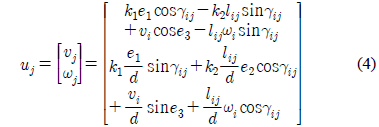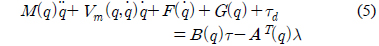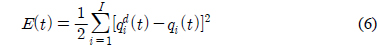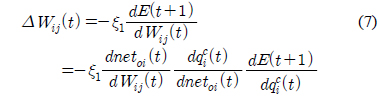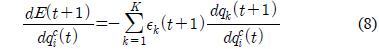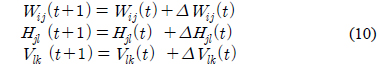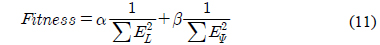In this paper, a PID controller with adaptive neural network compensator is proposed to control the formations of mobile robot. The control system is composed of a kinematic controller based on the leader-following robot and dynamic controller for considering the dynamics of the mobile robot. The dynamic controller is constituted by a PID controller and the adaptive neural network compensator for improving the performance and compensating the change in dynamic characteristics. Simulation results show the performance of the PID controller and the neural network compensator for the circular trajectory and linear trajectory. And it is verified that by improving the performance of a PID controller via the adaptive neural network compensator, the following robot's tracking performance is improved.
오늘날 로봇 산업의 발달로 산업 현장뿐만 아니라 다양한 분야에서 로봇이 많이 활용되고 있다. 특히 한대의 로봇으로 해결하기 어려운 문제를 여러 개체의 로봇을 사용하여 해결하려 협력 제어에 대한 연구가 활발히 연구되었으며, 이동 로봇의 경우 군집 제어에 대한 연구가 널리 연구되어 왔다[1]. 이동 로봇의 군집 제어는 행동 기반(behavior-based) 방식, 선도 로봇 추종(leader-follower) 방식, 가상 구조(virtual structure) 방식 등 다양한 형태가 연구되었으며, 이중에서 추종로봇이 선도 로봇을 추종하는 방식이 개념이 간단하고 여러대의 로봇으로 확장성이 용이하여 많은 연구가 이루어졌다[2-5].
일반적인 군집제어와 관련된 연구는 선도 로봇과 추종 로봇의 기구학적 관계만을 고려한 기구학적 제어기 설계가 주를 이루었으나[2-4], 실제 추종 로봇의 질량 및 관성 등의 동적 특성에 의해 추종 로봇의 선속도와 각속도를 완벽히 추종할 수 없다. 따라서 추종 로봇의 동역학적 특성이 고려된 제어기 설계에 관한 연구가 필요하다[6].
일반적인 선형 PID 제어기는 구조가 단순하고 구현이 용이하여 각종 산업 현장에서 많이 사용되고 있으나, 부하 및 제어 동작 범위가 변화하거나 비선형 제어 시스템일 경우, 적절한 이득과 성능을 얻기가 어렵다. 따라서 추종 로봇의 동역학을 고려한 제어기를 단순한 PID 제어기로 설계 시 제어의 성능을 보장할 수 없다.
본 논문에서는 군집제어와 관련된 연구로 추종 로봇이 선도 로봇과 일정 거리와 각도를 유지하며 추종하고자 한다. 추종 로봇이 선도 로봇을 정밀하게 추종하기 위하여 선도 로봇과 추종 로봇의 기구학적 관계로부터 기구학적 제어기를 설계하고 추종 로봇의 동역학을 고려한 동역학 제어기를 설계하고자 한다. 추종 로봇의 동역학 제어기는 적응적인 신경 회로망 보상기를 갖는 PID 제어기로 구성하였다[7]. 선형 PID 제어기의 이득은 인공 면역망 알고리즘에 의해 최적의 PID 제어기 이득을 설계하고, 설계된 최적 PID 제어기에 의해서도 발생하는 추종 오차는 비선형 시스템에 적합한 신경 회로망을 사용하여 보상하고자 한다. 모의실험을 통하여 실시간 학습 기능을 가진 신경 회로망 보상기를 갖는 PID 제어기가 일반적인 PID 제어기에 비하여 군집 제어에서 추종 로봇의 추종 성능을 향상시키는 것을 확인하였다.
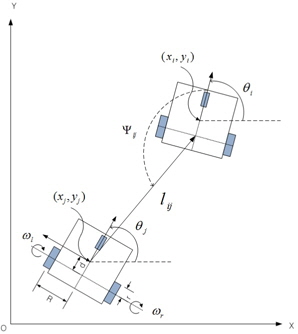
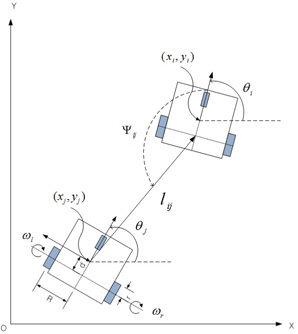
그림 1은 선도 로봇과 추종 로봇 사이의 기구학적 관계를 표현하였다. 선도 로봇은 선속도
상대거리와 추종 각도에 대한 기구학 방정식은 식 (1)과 같이 표현할 수 있다[3].
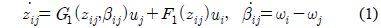
여기서,
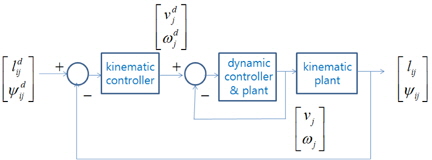
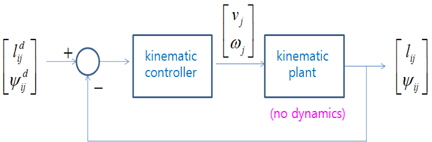
그림 2는 선도 로봇과 추종 로봇의 기구학적 관계만을 고려한 군집 로봇의 제어 블록선도를 나타낸다. 추종 로봇이 선도 로봇과 일정 거리 와 추종 각도 를 유지하며 추종하고자 한다. 추종 로봇의 동역학은 포함되지 않으며, 선도 로봇은 이상적인 기구학에 의해 동작한다고 가정하였다.
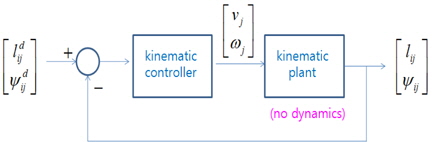
추종 로봇의 속도 제어 입력 값 [
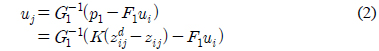
여기서, ,
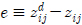
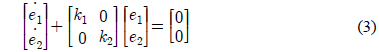
따라서
식 (2)를 구체적으로 표현하면 추종 로봇의 속도 제어 입력은 식 (4)과 같이 구할 수 있다.
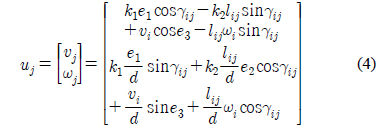
여기서 이다.
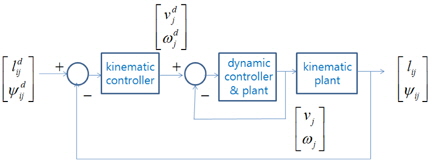
군집제어는 선도 로봇과 추종 로봇이 일정 거리 와 일정 각도 를 유지하는 것을 목적으로 하고 있다. 2.1절과 같이 두 로봇 사이의 기구학적 관계만을 고려하여 제어기를 설계할 경우, 정밀한 제어 성능을 보장할 수 없다. 이는 추종 로봇의 동역학으로 인해 식 (4)의 기구학 제어기에 의해 구한 선속도와 각속도
본 논문에서 고려하는 비 홀로노믹(nonholonomic) 이동 로봇의 동역학 모델로 식 (5)와 같이 구성되어 있다[6].
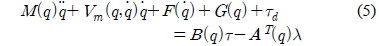
여기서
본 논문에서 이동 로봇의 운동은 수평면에 제한되어 있으므로 중력
PID 제어기는 구조가 단순하고 이득 동조 과정이 비교적 간단하기 때문에 산업 현장에서 널리 사용되고 있으나 부하 및 제어 동작 범위가 변화하거나 비선형 제어 시스템일 경우 적절한 이득과 성능을 얻기가 어렵다.
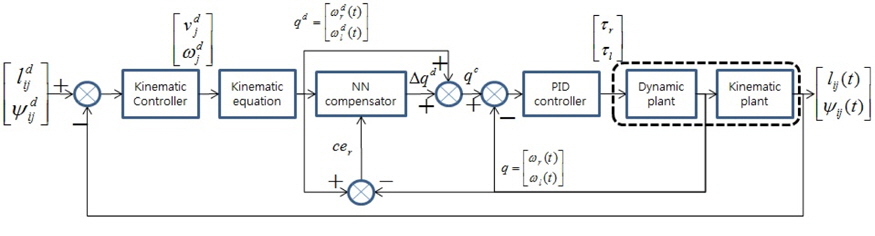
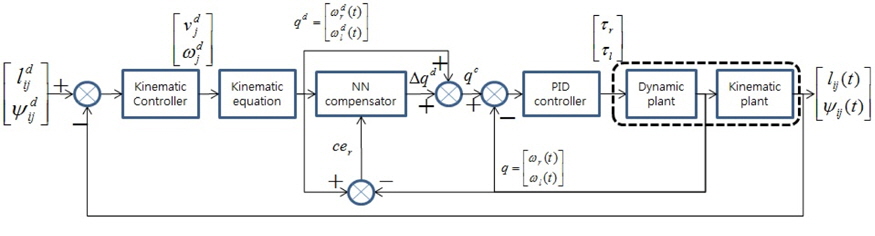
그림 4는 추종 로봇의 동역학 제어기로써 적응적인 신경 회로망 보상기를 갖는 PID 제어기의 구조를 나타내었다[7]. 선형 PID 제어기에 의해서도 발생하는 추종 로봇의 오차를 비선형 시스템에 적합한 신경 회로망 보상기가 줄이고자 한다.
적응적 신경 회로망 보상기는 2개의 은닉층과 1개의 출력층으로 구성되어 있으며 2개의 입력과 2개의 출력으로 구성하였다.
기준 입력과 플랜트 출력의 에러를 줄이기 위한 적응적 신경 회로망 보상기는 식 (6)의 에러를 최소화하기 위한 오류 역전파(error back propagation) 알고리즘을 적용하여 신경 회로망의 가중치를 학습한다.
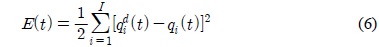
여기서 는 오른쪽 바퀴와 왼쪽 바퀴의 각속도 목표 값이고,
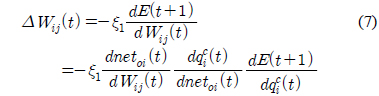
여기서
위 식 (7)에서 시스템의 응답 특성을 반영하기 위해서
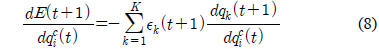
여기서, 이다.
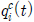

여기서
샘플링 타임이 작다면
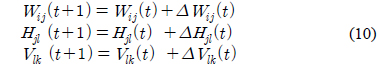
여기서,
본 논문에서 제안한 적응 신경 회로망 보상기를 갖는 PID 제어기의 성능 검증을 위하여 선도 로봇이 원형 궤적과 직선 궤적으로 주행할 경우를 모의실험 하였다. 또한 제안된 제어기의 성능 비교 평가를 위해 PID 제어기를 사용하였다. PID 제어기는 이득 값에 따라 제어 성능에 크게 영향을 미치므로, 실험적으로 구한 적절한 이득 값과 인공 면역망 알고리즘(Artificial Immune Algorithm)을 이용하여 구한 최적의 이득 값을 사용한 경우에 대하여 비교 실험을 수행하였다.
최적의 PID 제어기 이득 값을 찾기 위하여 인공 면역망 알고리즘을 사용하였으며, 평가함수는 식 (11)과 같이 정의하였다.
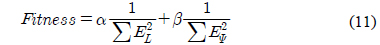
여기서, 은 상대 거리 오차, 는 상대 각도 오차이며,
인공 면역망의 학습 조건은 세대수 50, 개체 수 10, 돌연변이 비율 0.1, 복제 비율은 0.5로 설정하여 PID 제어기의 최적 이득 값을 구하였다.
인공 면역망에 의해 학습된 최적의 PID 이득 값은
비교 실험을 위해 다음의 4가지 경우에 대해 모의실험을 진행하였다.
case 1: 적절한 이득을 가진 PID 제어기 case 2: 최적의 이득을 가진 PID 제어기 case 3: 적절한 이득을 가진 PID+신경 회로망 보상기 case 4: 최적의 이득을 가진 PID+신경 회로망 보상기
군집 제어 모의실험을 위하여 선도 로봇과 추종 로봇들의 제원은 바퀴 사이 거리 2
추종 로봇의 추종 성능 평가를 위한 선도 로봇의 궤적을 두 가지로 설정하였다.
원형 궤적 : υr =0.5m/sec와 wr=0.1rad/sec 직선 궤적 : υr =0.5m/sec와 wr=0.1rad/sec
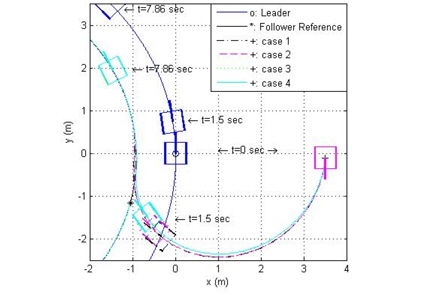
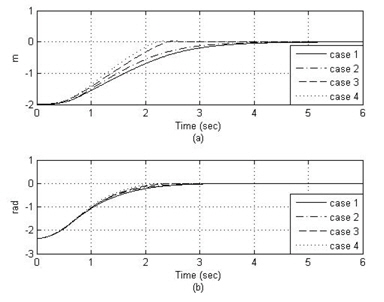
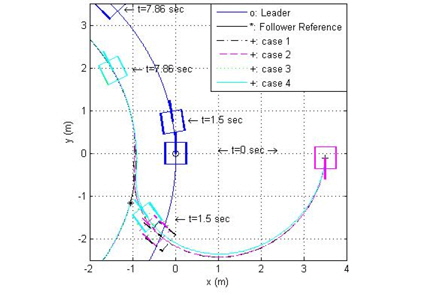
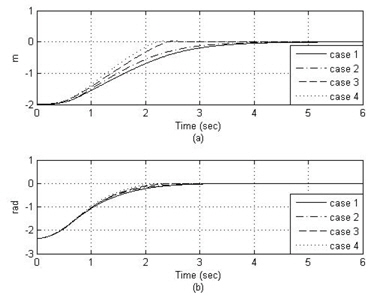
그림 5는 선도 로봇의 원형 궤적에 대해 4가지 제어 방법을 적용한 추종 로봇의 추종 결과이며, 그림 6은 각각의 거리 오차와 각도 오차를 표시하였다. 모의실험 결과 case 4, case 3, case 2, case 1의 순서로 성능이 좋음을 알 수 있다. 이는 신경 회로망 보상기를 갖는 PID 제어기가 최적의 이득을 갖는 PID 제어기에 비해서도 뛰어나며, 특히 case 3이 case 2보다 뛰어난 성능을 나타냄은 적절한 이득 값을 갖는 PID 제어기에 신경망 보상기를 첨가할 경우에도 성능이 향상됨을 알 수 있다.
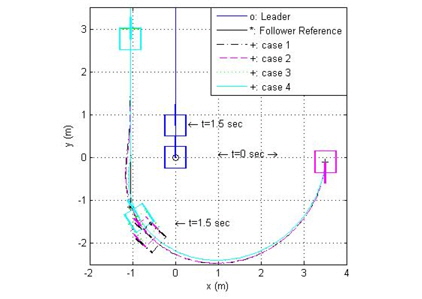
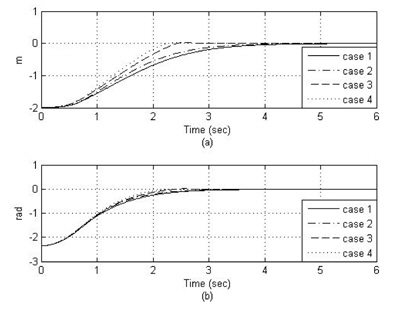
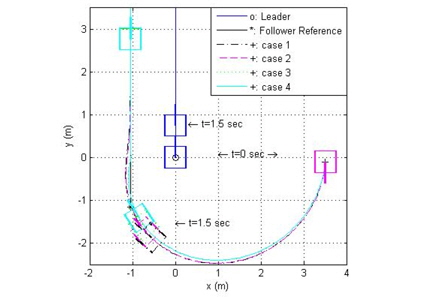
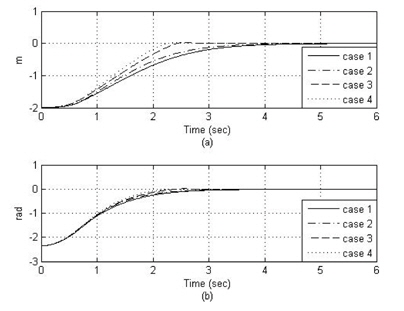
그림 7, 8은 선도 로봇의 직선 궤적에 대한 추종 로봇의 궤적과 추종 오차를 표시하였다. 직선 궤적 추종에 대한 성능 역시 신경 회로망 보상기를 갖는 제어방법인 case4, case3이 가장 뛰어난 성능을 보였다.
본 논문에서 제안한 신경 회로망 보상기를 갖는 PID 제어기가 PID 제어기에 비해 최적의 PID 이득 값이 아니더라도 신경 회로망 보상기를 통해 최적의 성능을 발휘함을 알 수 있다.
본 논문에서 이동 로봇의 군집 제어를 위해 선도 로봇과 추종 로봇의 기구학적 관계로부터 기구학적 제어기를 설계하고 추종 로봇의 동역학을 고려한 동역학 제어기를 설계하였다. 추종 로봇의 동역학 제어기는 적응적인 신경 회로망 보상기를 갖는 PID 제어기로 구성하였다.
또한 제안된 실시간 학습 기능을 가진 신경 회로망 보상기를 갖는 PID 제어기와 인공면역망 알고리즘을 통해 설계된 최적의 이득을 가진 PID 제어기를 모의실험을 통해 비교하였다. 고정 이득을 가지는 일반적인 선형 PID 제어기에 비해 실시간 학습을 통해 에러에 대해 추가적인 보상 기능을 가진 PID 제어기가 군집 제어에서 추종 로봇의 추종 성능을 향상시키는 것을 확인하였다. 향후 실제 이동로봇의 추종 제어에 적용하여 센서 노이즈, 외란 및 모델 불확실성에 대해 강인한 제어기에 대한 타당성 검증이 필요하다.