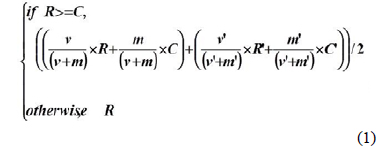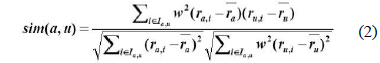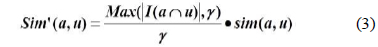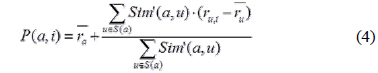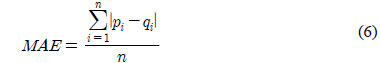As the use of mobile device is increasing rapidly, the number of users is also increasing. However, most of the app stores are using recommendation of simple ranking method, so the accuracy of recommendation is lower. To recommend an item that is more appropriate to the user, this paper proposes a technique that reflects the weight of user information and recent preference degree of item. The proposed technique classifies the data set by categories and then derives a predicted value by applying the user’s information weight to the collaborative filtering technique. To reflect the recent preference degree of item by categories, the average of items’ rating values in the designated period is computed. An item is recommended by combining the two result values. The experiment result indicated that the proposed method has been more enhanced the accuracy, appropriacy, compared to item-based, user-based method.
최근 몇 년간 전 세계적으로 스마트 폰과 태블릿 PC와 같은 모바일 기기의 사용이 급속도로 증가되고 있다. 국내에서도 2011년 스마트폰 사용자 수가 2,000만 명을 넘어섰으며[1] 태블릿 PC도 180만대 이상 판매되었다[2]. 이러한 모바일 기기의 확산은 전자상거래의 형태에도 변화를 가져오고 있다. Forrester Research의 2011년 6월 발표에 의하면 2016년까지 전세계 m-commerce 시장은 연평균 39% 이상 성장할 것으로 예상하고 있다[3].
모바일 애플리케이션을 통한 콘텐츠 이용 또한 증가하고 있다. 2011년 전 세계 모바일 애플리케이션 다운로드 수는 180억 건으로 전년 대비 144% 증가했을 것으로 추산되며, 스마트폰 애플리케이션 시장은 2010년 68억 달러에서 2013년 925억 달러로 4배 이상 확대될 전망이다[4]. 또한 2014년까지 모바일 폰 이용자들은 18억 5천만건의 애플리케이션을 다운받을 것으로 예측했다[5]. 모바일 기기들은 사용의 간편성으로 거의 모든 연령대의 사용자들이 쉽고 다양하게 사용하고 있다. 이러한 현상으로 앱 스토어가 웹과 같은 영향력 있는 서비스로 성장할 것이라는 전망에 따라 콘텐츠 업계들은 애플리케이션 개발에 힘을 쓰고, 기업들은 앱 스토어를 통해 비즈니스 확장, 차별화된 서비스 제공, 마케팅 등 다양한 관점에서 기업 성과 제고 방안을 모색하고 있다[6].
현재 모바일 앱 스토어에는 이미 수십만 개의 애플리케이션이 등록되어 있으며 그 수가 빠르게 증가하고 있다. 그러나 대부분의 앱 스토어들은 초기 웹(web)과 같이 단순한 랭킹 방식을 사용하고 있다. 따라서 사용자들의 대부분은 다른 사람들의 후기나 주변 사람의 추천, 또는 높은 순위에 올라 있는 애플리케이션이나 콘텐츠들을 구매하거나 다운로드 받는 경우가 많다[4]. 이러한 방식은 사용자가 원하는 아이템(애플리케이션 이나 콘텐츠)을 찾는데 많은 시간과 노력을 기울여야 하거나 사용자가 원하는 기능이 미비한 아이템을 다운로드할 수 있다는 단점이 있다.
따라서 본 논문에서는 사용자들이 원하는 아이템을 좀 더 빠르고 정확하게 찾을 수 있도록 아이템에 대해 기간 정보를 적용한 평가값과 카테고리별로 사용자 정보 가중치를 사용한 협업필터링 기법을 제안한다.
제안하는 기법은 아이템들을 카테고리별로 분류한 후 최근의 선호도를 반영하기 위해 특정 기간 정보를 적용한 아이템 평가값을 구한다. 아이템 평가값을 계산한 후 사용자 정보 가중치를 적용하여 사용자 기반 예측값을 구하고 앞서 계산된 기간 정보를 적용한 아이템 평가값을 결합하여 최종 예측값을 계산한다. 앱 스토어들이 사용자에게 많은 정보를 요구하지 않기 때문에 사용자 정보는 연령과 성별만을 사용한다. 마지막으로 최종 예측값들 중 Top-N개의 아이템을 추출하여 사용자에게 추천한다. 제안하는 기법은 사용자 정보를 추천에 사용함으로써 단순한 아이템 순위별 추천이 아닌 사용자 특성을 반영한 추천이 가능하고 아이템에 대한 기간 정보를 사용하여 계산된 아이템 평가값을 예측에 사용함으로써 최근의 선호 경향을 적용한 추천도 가능하다.
본 논문의 구성은 다음과 같다. 2장에서는 관련 연구에 대해 기술하고, 3장에서는 제안 기법에 대해 살펴본다. 4장에서는 실제 데이터를 대상으로 제안하는 기법의 성능 평가를 하고 마지막 5장에서는 결론을 기술한다.
추천 시스템은 새로이 등장한 개인화 시스템으로 사용자의 취향에 적합한 상품이나 아이템을 찾아 사용자에게 추천하는 시스템이다[7]. 추천 시스템은 사용자가 본인이 원하는 아이템이나 서비스를 보다 빠르게 이용할 수 있어 원하는 것을 찾기 위한 시간과 노력을 줄일수 있는 이점이 있다. 그리고 기업은 이전까지의 단순방문자를 구매자로의 전환을 유도할 수 있으며 교차 판매의 효과와 사용자 충성도를 증진시킬 수 있는 이점을 얻을 수 있다[8].
추천 시스템은 이미 Amazon.com, CDnow 등과 같은 전자상거래 기업들에 성공적으로 적용되어 사용자의 구매를 촉진시켰으며, 많은 전자상거래 사이트에서의 직접적인 판매 향상을 확인할 수 있다[9]. 추천 시스템이 데이터를 처리하여 추천목록을 생성하는 기법으로는 내용 기반 추천 기법, 규칙 기반 추론 기법, 사례 기반 추론 기법, 협업 필터링 등 다양한 방법이 있지만 그 중에서 협업 필터링이 가장 성공적으로 적용된다[10].
협업 필터링(collaborative filtering)기법은 사용자가 선호하는 패턴과 유사한 다른 사용자들의 선호도를 이용하여 사용자에게 관련된 아이템이나 서비스를 추천하는 기법이다. 이 기법은 추천 시스템 분야에서 가장 성공적인 추천 기법으로 전자상거래 기업이 가장 널리 이용하고 있다[11]. 협업 필터링은 사용자와 아이템의 관계에서 무엇을 중심으로 선호도를 예측하느냐에 따라 사용자 기반(user-based) 알고리즘[12]과 아이 템 기반(item-based) 알고리즘으로 분류된다[13].
사용자 기반 알고리즘은 사용자간의 유사성을 측정하여 선호도가 비슷한 다른 사용자들이 평가한 아이템을 기반으로 목표 사용자가 선호할 만한 아이템을 추천하는 방식이다[14]. 사용자 기반 알고리즘은 두 사용자가 공통으로 평가한 아이템만을 이용하여 유사도를 구하고 예측을 수행하므로 사용자간에 공통으로 평가한 아이템이 적을 경우 두 사용자가 성향이 비슷하더라도 정확한 유사도를 구하기 어려우며, 사용자의 평가 자료가 부족하여 예측의 정확성을 떨어뜨리는 희소성의 문제가 발생할 가능성이 높다[15].
아이템 기반 알고리즘은 사용자가 이미 구매했던 과거 아이템과 비슷한 아이템을 구매할 가능성이 높다는 개념에서 출발한 것으로[15] 아이템 간의 유사성을 측정하여 어떤 특정 사용자가 어떤 아이템을 선호하는지 예측하는 방식이다[16]. 아이템 기반 알고리즘은 사용자간의 유사도를 고려하지 않고 아이템 간의 유사도만을 고려하므로 선호도가 비슷하지 않은 사용자들의 평가를 기반으로 예측을 수행할 경우 예측의 성능이 저하될 수 있다[17].
최근에는 모바일 추천을 위해 다른 지역의 사람들은 문화적 성향이 다르므로 다른 모바일 애플리케이션을 선호한다는 지역기반 애플리케이션 추천 기법[18], 유사 성향을 가진 사용자들의 애플리케이션 설치 빈도를 분석한 애플리케이션 추천기법[19] 등 다양한 협업필터링 적용 기법들이 연구되고 있다.
본 장에서는 기간 정보를 적용한 아이템 평가값과 사용자 정보 가중치를 적용하여 예측값을 생성하는 제안기법에 대하여 설명한다.
본 논문에서는 추천의 정확성과 아이템에 대한 사용자들의 최근 선호도를 반영하기 위해 카테고리별로 아이템의 전체 평가값 평균과 기간 정보를 적용한 아이템 평가값을 구하여 예측값 계산에 적용한다. 아이템들에 대한 가중치 평가값은 다음 식(1)을 이용하여 계산한다.
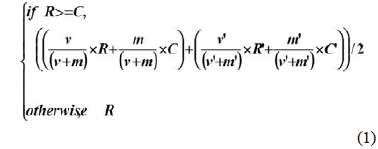
아이템의 평가값 평균이 전체 아이템에 대한 평가값 평균보다 작으면 선호도가 낮으므로 기간 정보를 적용한 평가값을 사용하지 않고 아이템 평가값을 그대로 사용한다. 또한 아이템에 대한 평가 수가 적음에도 평균이 높아 선호도가 높게 평가되는 것을 방지하기 위해 최소 평가 개수를 지정한다. 기간 정보를 사용하여 아이템 평가값을 추출함으로써 누적 다운로드 횟수와 최근의 선호 경향을 함께 반영한 아이템을 사용자에게 추천할 수 있다. 그림 1은 기간 정보를 적용한 평가값을 계산하는 알고리즘이다.
사용자 정보 가중치를 적용한 예측값 생성 및 추천은 다음과 같은 단계로 이루어진다.
3.2.1. 카테고리별 User-Item matrix 생성
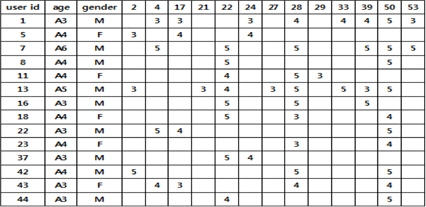
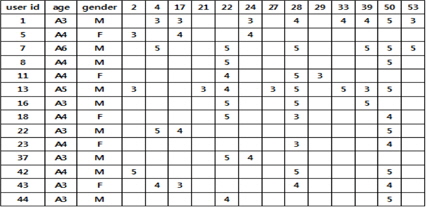
카테고리별로 사용자 정보를 가중치로 사용한 useritem matrix를 생성한다. 앱 스토어들은 가입 시 사용자에게 많은 정보를 요구하지 않으므로 본 논문에서는 사용자 정보로 나이와 성별 정보만을 사용한다. 같은 연령대의 소비자들은 유사한 소비 성향을 갖는 경향이 있으므로 나이 정보는 연령별로 7개의 그룹(A1~A7)으로 나누어 사용한다.
그림 2는 사용자 정보를 사용한 user-item matrix의 예를 나타낸다.
user-item matrix를 생성한 후 목표 사용자의 근접 이웃을 추출하기 위해 유사도를 계산한다. 유사도는 두 사용자가 공통으로 평가한 아이템의 개수가 소수인데도 유사도가 높게 나오는 경우 정확성이 떨어지므로 공통평가 아이템 개수에 임계값을 적용하여 피어슨 상관계수와 사용자 정보 가중치를 적용하여 계산한다. 식(2)는 피어슨 상관계수에 가중치를 적용한 유사도 계산식이다.
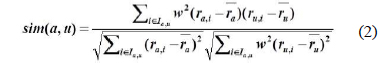
식(3)은 식(2)에 공통평가 아이템 임계값을 적용한 최종 유사도 계산식이다.
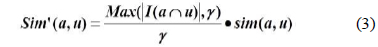
그림 3은 사용자 특성 가중치를 적용하여 유사도를 구하는 알고리즘이다.
가중치와 임계값을 지정하여 유사도를 계산한 후 모든 사용자를 목표 사용자의 이웃으로 지정하는 것이 아니라 유사도 임계값을 지정하여 그 이상의 유사도 값을 가진 사용자들만을 목표 사용자의 이웃으로 지정한다. 근접 이웃 사용자들의 평가값과 유사도만을 사용하여 목표 사용자의 평가되지 않은 아이템의 예측값을 계산한다.
식(4)는 예측값을 계산하는 식이다. , 는 사용자 a와 u의 평가값 평균을 나타내고
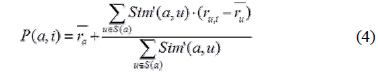
목표 사용자의 평가하지 않은 아이템들에 대한 예측값을 식(4)를 사용하여 계산한 후 예측값중 Top-N개의 아이템들을 선택한다. 선택한 아이템들의 예측값과 식(1)을 이용하여 구한 아이템 평가값의 평균을 구하여 그 값을 아이템의 최종 예측값으로 지정하고 사용자에게 해당 아이템들을 추천한다.

식(5)는 최종 예측값 계산식이고
본 논문에서 제안한 추천기법의 성능을 평가하기 위해 실험 데이터는 GroupLens Research Project에 의해 수집된 MovieLens 데이터셋을 사용하였다. MovieLens 데이터셋은 943명의 사용자가 1682개의 영화에 대하여 평가한 100,000개의 평가값을 갖는 데이터셋으로 사용자들은 최소 20개의 아이템에 대해 선호도를 1~5의 값으로 평가하였다[15].
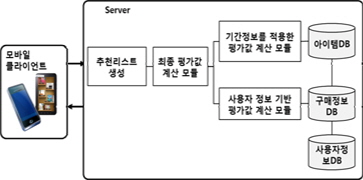
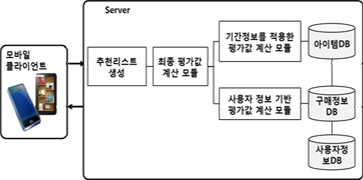
제안하는 기법의 성능 평가를 위해 training dataset과 test dataset의 아이템들을 각각 영화 장르를 기준으로 18개(action, adventure, animation, children’s, comedy, crime, documentary, drama, fantasy, film-noir, horror, musical, mystery, romance, sci-fi, thriller, war, western)의 카테고리로 분류하여 실험하였다. 제안 시스템의 구조도는 그림 5와 같으며 실험은 Eclipse, JDK SE 7, MySQL5.5, Android SDK Tools, Android Platform 환경에서 진행하였다.
실험은 예측의 정확성을 평가하기 위해 MAE (Mean Absolute Error) 값 측정과 사용자에게 양질의 아이템을 추천하는지를 평가하기 위해 F1척도(F-measure)기법을 사용하였다.
MAE(Mean Absolute Error)는 아이템에 대한 사용자의 실제 평가값과 추천시스템의 예측값의 차이에 대한 절대 평균으로 추천의 성능을 평가하는 방식이다. MAE의 값이 작을수록 예측의 정확성이 높고 더 좋은 추천을 한다[20]. 식 (6)은 MAE의 계산식이다.
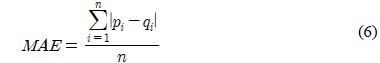
F1척도는 정보검색 시스템의 성능 평가를 위해 사용되는 평가법으로 추천시스템의 성능 평가를 위해서도 많이 사용되고 있다. F1척도는 정확율과 재현율을 사용하는데 추천의 개수를 증가시키면 재현율은 증가하지만 정확율은 감소한다는 상호 상충관계에 있으므로 두방식을 동일한 가중치로 결합하여 보완한 방식이다. F1값이 클수록 추천의 적합성이 좋다고 할 수 있다[21].

식(7)은 F1의 계산식이고 R1은 재현율, P1은 정확율을 나타낸다.
실험은 협업 필터링 기법의 아이템 기반 추천기법과 사용자 기반 추천기법, 제안하는 추천기법에 대하여 MovieLens 데이터셋에서 예측의 정확성과 추천의 적합성 비교로 이루어졌다.
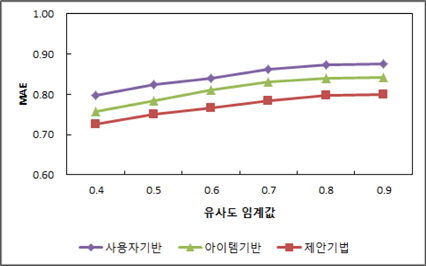
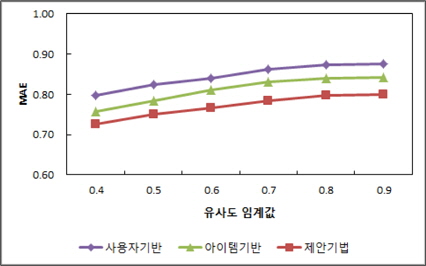
예측의 정확성 실험에서는 유사도 임계값을 0.4에서 0.1씩 증가시켜 0.9까지 변화를 주어 세 기법의 MAE값을 측정하여 정확성을 비교하였다. 그림 6은 유사도 임계값 변화에 따른 MAE 값을 측정한 결과를 나타낸것이다.
세 기법 모두 유사도 임계값이 커지면 예측값 계산에 사용되는 이웃의 크기가 줄어들어 MAE 값이 커지지만 제안하는 추천 기법이 사용자 기반 추천 기법과 아이템 기반 추천 기법보다 MAE값이 낮은 것을 볼 수 있다. 이러한 결과는 제안하는 기법의 예측 성능이 두 비교 기법들보다 우수하다는 것을 나타낸다. 제안하는 기법은 유사도 임계값이 0.7일 때 비교 기법들과 조금 더 차이를 보이며 평균적으로 아이템 기반 기법보다 4.9%, 사용자 기반 기법보다 8.8% 정도 예측 성능의 향상을 보인다.
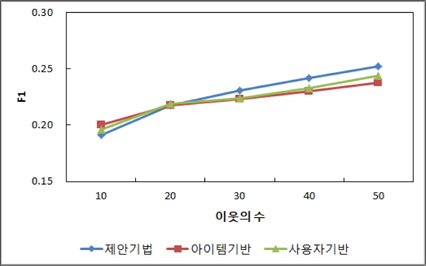
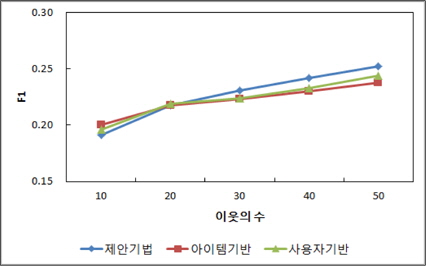
추천의 적합성 실험에서는 이웃의 크기에 변화를 주고 이에 따른 세 기법의 추천의 적합성을 F1척도로 비교하였다. 이웃의 크기는 10에서 50까지 10씩 증가시키고 그 변화에 따른 결과를 추출하였다.
그림 7은 이웃의 크기 변화에 따른 세 추천기법의 추천의 적합성을 측정한 결과이다. 결과를 통해 제안하는 기법이 비교 기법들보다 추천의 적합성이 높음을 알 수 있다. 세 기법 모두 이웃의 수가 증가하면 F1값이 증가하지만 제안하는 추천기법이 아이템 기반 기법보다는 평균 3.8%, 사용자 기반 기법보다는 2.6% 정도 추천의 적합성이 높게 나타났다.
최근 모바일 기기의 사용이 급속도로 증가하면서 사용자들의 모바일 애플리케이션 이용 또한 급격히 증가하고 있다. 그러나 대부분의 앱 스토어들은 초기 웹과 같이 단순한 랭킹방식을 사용하고 있으며 대부분의 사용자들은 다른 사람들의 후기나 주변 사람의 추천 등을 통해 애플리케이션이나 콘텐츠를 다운로드하는 경우가 많다. 이러한 방식은 사용자가 본인이 원하는 아이템들을 찾기 위해 많은 시간과 노력을 기울여야 하는 문제점을 가지고 있다.
이에 본 논문에서는 모바일 추천의 성능을 향상시키기 위해 아이템에 대한 기간 정보와 협업필터링 기법을 결합한 추천 기법을 제안하였다. 제안된 기법은 단순한 누적 다운로드 수를 이용한 추천이 아닌 사용자들의 최근 선호 경향을 반영하기 위해 카테고리별로 전체 아이템에 기간 정보를 적용한 아이템 평가값을 구하고 사용자의 정보 가중치를 적용한 예측값을 생성하여 두 값의 평균을 실제 예측값으로 사용하였다.
실험 결과 제안하는 추천 기법이 예측의 정확성에서 아이템 기반 추천 기법과 사용자 기반 추천 기법보다 각각 평균 4.9%, 8.8% 정도 정확성이 향상되었음을 알 수 있었고, 이웃의 크기 변화에 따른 적합성 비교에서도 제안하는 기법이 아이템 기반 추천 기법과 사용자 기반 추천 기법보다 평균 3.8%와 2.6% 정도 적합성이 향상되었음을 알 수 있었다. 이를 통해 사용자 정보 가중치와 아이템의 최근 선호 정도를 결합한 제안 기법이 사용자에게 좀 더 정확하고 적합한 아이템을 추천함을 확인할 수 있었다.
제안하는 기법은 사용자 정보를 기반으로 예측값을 추출하기 때문에 사용자의 수가 너무 많을 경우 확장성의 문제가 있을 수 있다. 그러나 이러한 문제는 최근 활발히 연구, 적용되고 있는 빅데이터의 분석기법을 활용하면 해결될 수 있는 문제이다. 따라서 향후 연구과제는 앱 스토어를 이용하는 사용자들과 등록되는 애플리케이션, 콘텐츠 등의 급증으로 인해 늘어나는 데이터들을 좀 더 정확하게 분석하여 사용자에게 빠르고 정확하게 아이템을 추천할 수 있도록 빅데이터 분석을 활용한 예측방법을 연구하는 것이다.