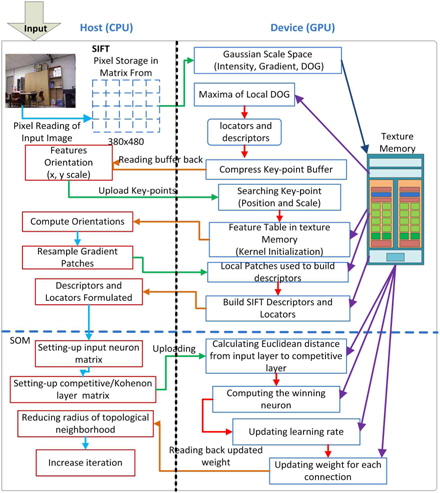
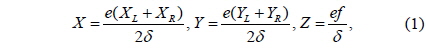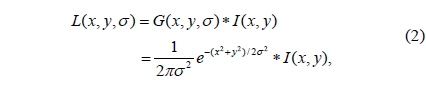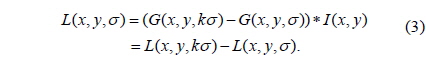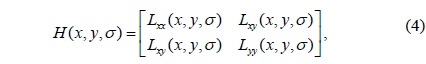Feature selection and matching is a key component in many computer vision tasks, such as path finding, obstacle detection, navigation, and stereo vision [1-4]. Several strategies have been already proposed for keypoint detection [5, 6]. Schmid and Mohr [7] used Harris corners as interest points in image recognition problems to match features against a large database of images. This method allows features to be matched under arbitrary orientation changes, but it is sensitive to image scaling. Lowe [8] proposed a scale-invariant feature transform (SIFT) descriptor for the extraction of interest points from an image that is invariant to both scale and rotation. The SIFT technique, however, uses a 128-dimensional vector to describe the SIFT feature that is computationally intensive. In a recent research [9], we have implemented an efficient feature matching technique, which is faster than Lowe’s SIFT, with a selforganizing map (SOM) that can be used for real-time stereo matching applications. In this paper, we extended our research and implement the proposed method with graphics processing units (GPUs) to further optimize the execution time.
Due to the advancements of parallel processing techniques, multi-core CPU methods are widely used to accelerate computationally intensive tasks [10]. Modern programmable graphics hardware contains powerful co-processing GPUs with a peak performance of hundreds of GigaFLOPS, which is an order of magnitude higher than that of the CPUs [11]. For accelerating computer vision applications, many researchers are now exploiting parallelism supported by modern programmable graphics hardware that provides a great scope for acceleration to run computations in parallel [12, 13]. Some researchers also use specialized and reconfigurable hardware to speed up these algorithms [14-16]. One example is discovering concurrency in parallel computing, where coloring is used to identify subtasks that can be carried out or data elements that can be updated simultaneously [17]. Yet another example of coloring is the efficient computation of sparse derivative matrices [18]. With the increasing programmability and computational power of GPUs, the recent work by Sinha et al. [10] accelerates some parts of the SIFT algorithm by using the hardware capacities of the GPU. A 10× speedup was obtained, which makes this technique feasible for video applications [10]. A variety of computer vision algorithms have been parallelized, providing significant acceleration to the computation [10, 12, 13].
In this paper, we present a technique that is designed to achieve fast feature matching in images with the use of neural networks and GPUs. Our contribution is the proposal of a GPU-optimized matching technique based on Kohonen’s SOM [19]. The presented method provides a significant reduction of computation time as compared to Lowe’s SIFT. In our approach, the scale space for keypoint extraction is configured in parallel for detecting the candidate points among which the number of keypoints is reduced with the SOM neural network. The descriptor vector generation is accelerated by the GPU, and matching is accomplished on the basis of competitive learning. The key idea is to optimize keypoint extraction with a GPU and to reduce the descriptor size with the winning calculation method. Similar winning pixels in the images are found and associated to accomplish feature matching. The proposed method using a GPU is faster as multi-processing is used.
The rest of this paper is organized as follows: Section II gives a brief overview of stereo vision. The procedure of feature matching with the GPU-optimized method is presented in Section III. Experimental results are shown in Section IV, while Section V presents the conclusions.
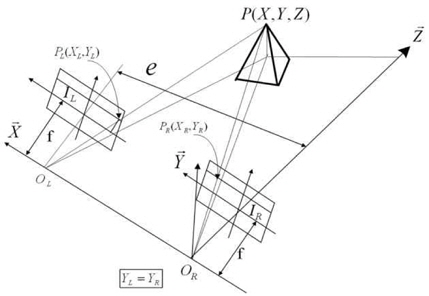
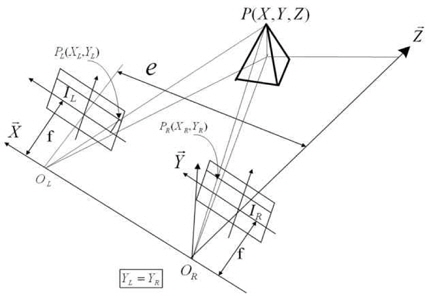
Stereo vision is based on acquisition of three-dimensional (3D) data from different views obtained by a single moving camera or a fixed arrangement of several cameras. The 3D position of an object is determined by triangulating the optical rays from at least two views of the same object point. Optical axes of two camera-lens units are configured in parallel, and the straight line joining the two optical centers is parallel to each image’s horizontal line in order to meet the epipolar constraint (Fig. 1). The 3D image data are obtained on the basis of the position of the points in the left and the right images [20].
The coordinates of a 3D point P of the object (
where
III. PROPOSED GPU-OPTIMIZED MATCHING TECHNIQUE
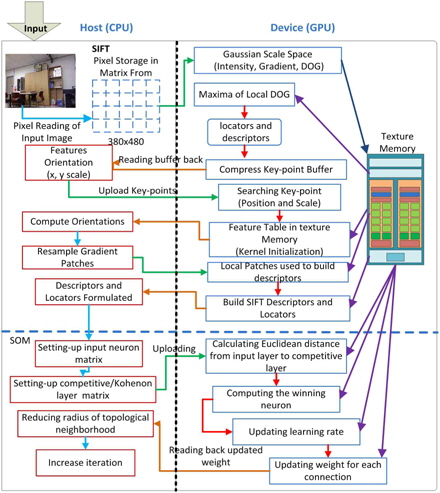
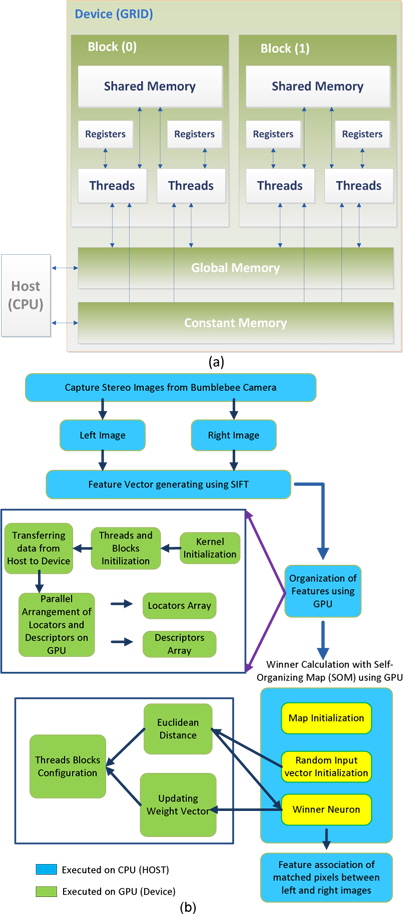
In this section, we explain the proposed GPU-based method to optimize image matching along with the SOM methodology. The GPU is a special-purpose processing unit with a single instruction multiple thread parallel architecture. With the advent of multi-core CPUs and many-core GPUs, mainstream processor chips are now parallel systems. Moreover, their parallelization continues to scale with Moore‘s law. Compute unified device architecture (CUDA) considers GPU hardware as an independent platform that can provide a programming environment and minimize the need for understanding the graphics pipeline. A GPU hardware chip has
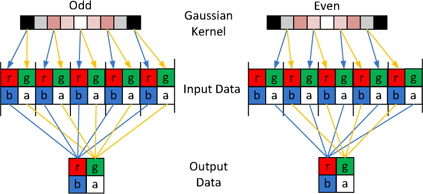
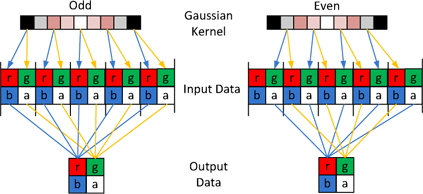
The parts executing on the GPU that would mainly reduce the computation time are described in subsections III-A and III-B. The streams of instructions and fragments (pixels) are designed to be processed in parallel on the GPU with a peak performance of GFLOPS (GigaFLOPS). Fragment processors perform the role of computational kernels, and different computational steps are often mapped to different fragment programs [10]. Texture mapping on the GPU is analogous to the CPU’s random read-only memory interface; the fragment processors apply a fragment program (a pixel shader) to each fragment in the stream in order to compute the final color of each pixel. The GPU processes the pixels with parallel processing by the fragment processors and calculates the four color values at once as a vector. The image data are rearranged into a four-channel RGBA image where one color value in the RGBA image represents a 2 × 2 block of the gray-level image, thereby reducing the image size by 4. The RGBA image is processed on the GPU, and the fragment shader arranges them into one RGBA image format (Fig. 3). The Gaussian convolution is directly applied to the RGBA image format where the Gaussian kernel consists of even and odd values to perform semi-convolutions, which are added further to form the final result. The calculations are performed in the fragment shader, and the computational overhead is low because of the rearrangement of the image in the RGBA image format.
>
A. Parallel Scale Space Configuration and Construction of the Descriptor
In our approach, the construction of a Gaussian scale space is accelerated by the GPU by using fragment programs. In order to extract the candidate keypoint, the scale space
where * denotes the convolution operation in
The intensity image, gradients, and the DOG values are stored in the RGBA packed format and computed in parallel in the same passage by using vector operations in the fragment programs. The Hessian matrix
where
>
B. Winner-Based Image Matching and Acceleration Using GPU
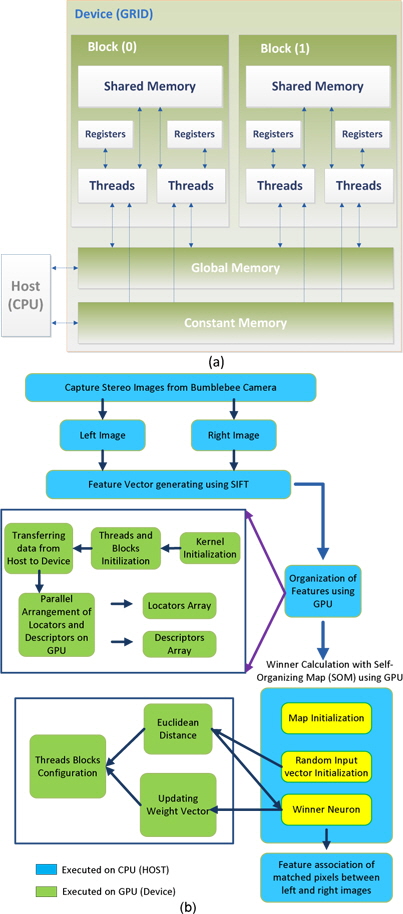
We use the SOM algorithm to map high-dimensional keypoints to a lower dimensional space by using competitive learning [8]. The pseudo-code of the proposed algorithm is shown in Fig. 4. Fig. 5 summarizes the complete algorithm.
To optimize the algorithm, the descriptor and the locator section are implemented on the GPU in order to solve the complexity of feature matching that consumes a considerable amount of time to obtain the descriptor vector. To this end, keypoints are scanned to obtain the descriptor and locator vector that can run in parallel on the GPU. In the initial stage, a function reads an image that returns the SIFT keypoints, which consist of locators and descriptors of an image that are stored in a temporary file. The temporary file is then processed separately for the scanning and organization of the locators and descriptors. The scanning and organization of the locators and descriptors is carried out in a parallel manner on the GPU. The processors consist of a front-end that reads/decodes the data, which is responsible for allocating memory on the GPU and transferring data from the CPU to the GPU, and initializes the kernel instructions. A backend is made up of a group of eight calculating units and two super-function units where instructions are executed in the SIMD mode; the same instruction is sent to all threads in the warp. NVIDIA calls this mode of execution ‘single instruction multiple threads (SIMT)’. The streaming multiprocessors’ operating mode is as follows:
1) At each cycle, a warp ready for execution is selected by the front-end, which starts execution of an instruction. 2) To send the instruction to all 32 threads in the warp, the backend will take four cycles, but since it operates at double the frequency of the front-end, from its point of view, only two cycles will be executed
The presented approach uses scale invariant feature vectors instead of an image database as an input to the SOM network. A topological map is obtained with the use of the SOM network, and we obtain a 2D neuron grid where each neuron is associated with a weight vector containing 128 element descriptors. The 128-dimensional descriptor generation is accelerated using the GPU in order to increase the execution speed of the algorithm. The descriptor vector is read, and its value is recorded individually in an array; further, the total value is recorded using built-in libraries. The value is later used as a limit for declaring threads and blocks for the GPU. As per the limit of each block, only 512 threads can be accommodated in each block and there can be a total of 65535 blocks in the grid. Each value is assigned to each thread in the block, and the number of blocks depends on the total value divided by 512 (number of threads). An inspection of the temporary file containing the keypoints of each image indicates that the first four values are the locator values followed by the 128 descriptor values. The GPU threads are employed to arrange these locator and descriptor values accordingly.
For image matching, we use a learning algorithm based on the concept of the nearest neighbor learning. One image is considered the reference and the next image as the matching image. Both images are represented in terms of the winning neurons in the SOM network as explained in the pseudo-code. After the network is trained, input data are distributed throughout the grid of neurons. The feature vectors are arranged according to their internal similarity with the SOM, thereby forming a topological map of the input vectors. The winning neuron is found for each pixel of the next image, and the pixel value is associated to it once the winner is found. Feature matching is performed by associating the similar winning pixels between the pixels of the reference image and its neighbor image. By iteratively repeating these steps, winning pixels are obtained with the SOM and the matching between the pixels of the different image pairs is accomplished.
In this section, we present some experimental results to show the performance of the proposed method. Experiments were performed using images captured with a Kinect camera designed by Microsoft; the experimental details and results of two test image sets are as follows: each image set contained 15 different images, and the performance of the proposed GPU-based method was compared with that of Lowe’s method and that of the SOM-based feature matching method [9]. For a comparative analysis of the execution performance, the algorithm was run on a CPU and a GPU independently. Experiments were conducted on an Intel Core i3 processor endowed with an NVIDIA GPU, GeForce 310 with a global memory of 512 MB. The CUDA, proposed by NVIDIA for its graphics processors, exposes a programming model that integrates the host (CPU) and the GPU codes in the same code source files. The main programming introduced by the programming model is an explicitly parallel function invocation (kernel), which is executed by a user-specified number of threads.
Every CUDA kernel is explicitly invoked by the host code and executed by the device, while the host side code continues the execution asynchronously after instantiating the kernel. The image size for the two test image sets is 480 × 380 pixels. Experiments were conducted under varying situations, such as rotation, scaling, and blurring conditions. Figs. 6 and 7 show the matching results for two image sets obtained using Lowe’s method and with the SOM-based feature matching method [9]. The proposed method achieves the same matching results as those described in [9] with much less computation time. It is found that the average matching time is 0.13953 s for Lowe’s SIFT, while for the SOM-based feature matching method [9], it is 0.01447 seconds, which is reduced to 0.00165 seconds by using the proposed GPU-based method.
Using the SOM-based feature matching [9] method, we can accelerate Lowe’s algorithm by nine times on average, and yet another nine times by using the proposed GPU-based method. Thus, the presented GPU-based method yields a performance improvement of approximately 90 times. Tables 1 and 2 show the comparison results of the computation time on two image sets for different images, in the cases of the Lowe’s method, SOM-based feature matching method [9], and the proposed GPU-based method. Experimental results show that the SOM-based feature matching method [9] performs more efficient matching than Lowe’s SIFT. A significant reduction in the computation time is obtained by using the proposed GPU-based method.
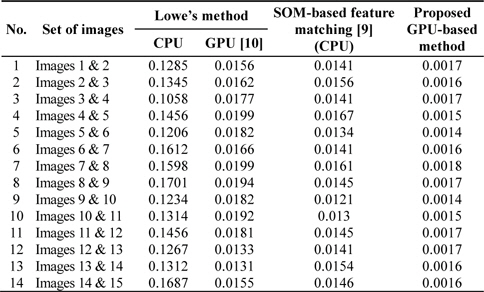
Comparison results for test image set 1 with Lowe’s method, SOM-based feature matching method [9], and the proposed GPU-based method
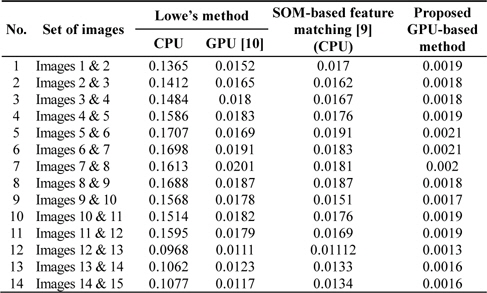
Comparison results for test image set 2 with Lowe’s method, SOM-based feature matching method [9], and the proposed GPU-based method
This paper presents a matching method to obtain the features under varying conditions with reduced processing time. The computation time of the proposed method is reduced as compared to Lowe’s method and further optimized by using a GPU. Experiments on various test images have been carried out to evaluate how well the presented method performs on the matching problem as compared to Lowe’s method. Experimental results show that the proposed method produces better matching results with a significant reduction in computation times.




![Comparison results for test image set 1 with Lowe’s method, SOM-based feature matching method [9], and the proposed GPU-based method](http://oak.go.kr/repository/journal/13310/E1ICAW_2014_v12n2_128_t001.jpg)
![Comparison results for test image set 2 with Lowe’s method, SOM-based feature matching method [9], and the proposed GPU-based method](http://oak.go.kr/repository/journal/13310/E1ICAW_2014_v12n2_128_t002.jpg)