Nowadays, there is a trend of migrating from two-dimensional (2D) display systems to 3D ones. This migration, however, is not happening due to the fact that commercially available 3D display technologies are not able to stimulate all the mechanisms involved in the real observation of 3D scenes. The human visual system needs a set of physical and psychophysical clues to perceive the world as 3D. Among the psychophysical clues, we can list the linear perspective rule (two parallel lines converge at a far point), occlusions (occluded objects are further away than occluding ones), movement parallax (when the observer is moving, close objects displace faster than far objects), shadows, and textures.
Among the physical clues are accommodation (capacity of eye lens to tune its optical power), convergence (rotation of the visual axes to converge at the object point), and binocular disparity (horizontal shift between retinal images of the same object). It is remarkable that the closer the object is to the observer, the stronger are the accommodation, convergence, and binocular disparity. The brain makes use of these physical clues to obtain information about the depth position of different parts of a 3D scene.
Note that while psychophysical clues can be easily simulated in a 2D display, physical clues are difficult to simulate and indeed are not generated in currently commercially available 3D displays.
The aim of this review is to analyze a 3D imaging and display architecture that at present is still far from the stage of commercial implementation but has the potential of successfully simulating all physiological and physical 3D clues.
II. STEREOSCOPIC AND AUTOSTEREOSCOPIC TECHNIQUES
At present, there are many techniques for the display of 3D images. Usually, the term 3D display is used for referring to two different visualization situations: the stereoscopic display and the real 3D display. Stereoscopic systems provide the user with two different images of the 3D scene, obtained from different but close perspectives. The images are shown independently to the eyes of the observer so that they produce binocular disparity, which provides the brain with the information that allows it to estimate the depth contents of the scene. Stereoscopy has been conventionally implemented by the use of special glasses that transmit for each eye its corresponding image and block the other one. This effect has been produced by the use of anaglyph glasses [1], polarizing glasses [2], and more recently, shutter glasses based on polarization [3, 4]. It is also possible to implement stereoscopy without the use of special glasses. The systems that perform this are known as auto-stereoscopic systems. Autostereoscopy can be imple- mented by means of lenticular sheets [5] or by parallax barriers [6, 7]. However, the main drawback of stereoscopy is that it produces ocular fatigue due to the conflict between convergence and accommodation. This conflict occurs due to the fact that the accommodation is fixed at the screen where the two perspectives are projected, whereas the visual axes intersect at the distance where the scene is recon- structed.
The main difference between the stereoscopic and the real 3D displays is that the latter present different perspectives when the observer displaces parallel to the display. Among the real 3D displays, we can find multi-view systems based on lenticular sheets or on parallax barriers [8-10], volumetric systems [11], holographic systems [12], and integral photography systems [13-15]. From a conceptual point of view, holography, which can render the wave field reflected by an object, is the technique that provides a better 3D experience and does not produce visual fatigue. However, since holography is based on the interference of coherent wavefronts, it is still far from been efficiently applicable to massive 3D display media.
Multi-view systems either based on parallax barriers or in lenticular sheets, provide the observer with multiple stereoscopic views of a 3D scene. These systems can provide different stereoscopic views to different observers, but have the drawback of flipping or double image, when the observer displaces parallel to the system. Multi-view systems do not provide images with vertical parallax, and more importantly, the users still suffer from the consequences of the convergence accommodation conflict.
Integral imaging is, together with holography, the only technique that can stimulate both the physical and the psychophysical mechanisms of 3D vision. Integral imaging systems reconstruct any point of the 3D scene through the intersection of many rays, providing the observer with fullparallax images and avoiding the conflict between the mechanisms of convergence and accommodation [16, 17]. The main advantage of integral imaging nowadays is that it can be implemented with the available 2D imaging and display technology, such as charge-coupled device (CCD) or CMOS sensors and LED or LCD displays. In any case, there are still some physical limitations, such as the poor viewing angle, or technological limitations, such as the need for a higher resolution of pixelated monitors and a wider bandwidth for the transmission of integral images, that still prevent this technique from a rapid commercial spread. However, note that it is reasonably expected that these limitations will be overcome in the next few years.
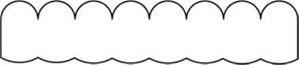
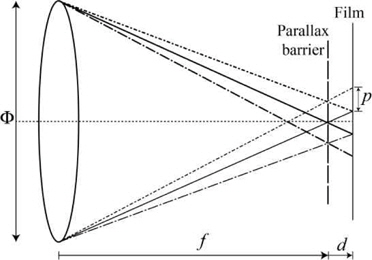
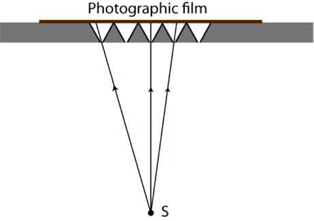
On March 2, 1908, Lippmann presented to the French Academy of Sciences his work ‘Epreuves réversibles photographies integrals’ [13], which postulated the possibility of capturing 3D information of an object on a photographic film. He proposed the use of a transparent sheet of celluloid to record on one surface a large number of small notches with circular relief intended to serve as lenses. On the other side of the sheet, he proposed to mold a series of diopters but coated with a photographic emulsion. Each of these spherical diopters should be adapted to receive the image provided by each of the lenses of the opposite face (see Fig. 1). Henceforth, we will refer to each of these images as elemental images.
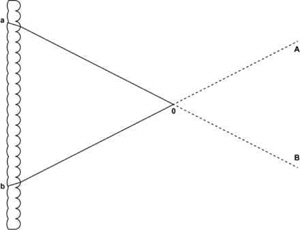
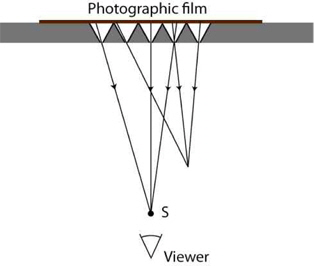
During the capturing process, each lens forms the image of a slightly different perspective of the 3D scene on the photographic emulsion. In the display process, the positive of the developed image is pasted on the face where the photographic emulsion is applied and illuminated through a diffuser. Then, any point on the positive can generate a beam of parallel rays. As a result, a 3D scene is reconstructed by the intersection of these beams and can be observed within a range of angles (see Fig. 2).
Despite the simplicity of Lippmann’s concept, its experimental implementation faced numerous technical difficulties. Experimental tests performed with a thermally molded film produced poor results. In 1912, Lippmann [15] conducted a new experiment with 12 sticks of glass mounted in a rectangular matrix. In this experiment, he proved the existence of a 3D image that can be seen from different perspectives and whose angular size can be changed to zoom in or out.
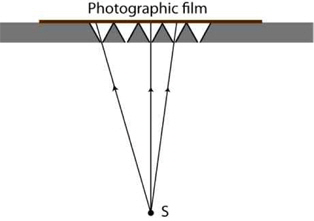
Unfortunately, the technology for creating an array of small lenses was complex, and therefore, instead of using microlens arrays (MLAs), the experiments and investigations conducted during that time and in the following few years used pinhole arrays. However, pinholes have an important problem, in order to have sharp images, they need to have a small aperture, and thus, the light that goes through them is not sufficient to achieve an acceptable exposure time. In 1911, Sokolov [18] described and validated experimentally the integral photography method proposed by Lippmann. He built a pinhole array by piercing equidistant little cone-shaped holes in a sheet surface and applied a photographic emulsion (Fig. 3).
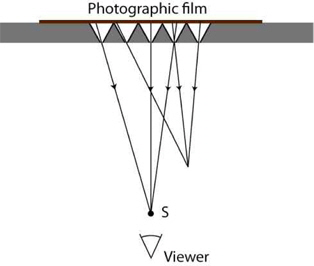
In the reconstruction process (see Fig. 4), the recorded image replaced the photographic film. Another drawback of the pinhole array arises during reconstruction: instead of a continuous image, the viewer sees a series of discrete points [19].
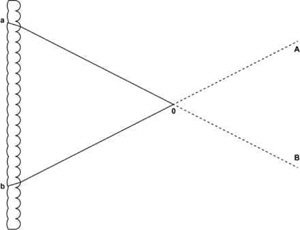
One of the main problems of integral imaging is pseudoscopy: the projected images are reversed in depth. Sokolov [18] showed this problem in one of his figures, which is similar to Fig. 4.
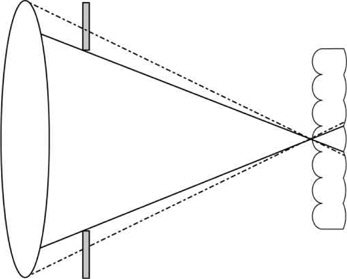
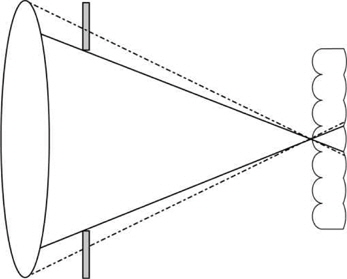
In addition, Ives [21] was the first to propose the use of a field lens of a large diameter to form the image of an object through a parallax-barrier plate in order to obtain multi- perspective images (see Fig. 5). Later, in 1936, Coffey [22] proposed to combine the systems developed by Ives and Lippmann. He used a molded sheet with photographic emulsion, similar to the one designed by Lippmann. To avoid an overlap between the elemental images, Coffey [22] proposed the adjustment of the effective apertures of the field lens and the microlenses (see Fig. 6).
The first commercial integral imaging camera was patented by Gruetzner [23] in 1955 In the patent, he reported a new method for recording a spherical lens pattern in a photographic film that was covered on one side by a light-sensitive emulsion.
Between the late 1960s and the 1980s, interest in integral imaging increased. During this period, various theoretical analyses and experimental systems were implemented. The most notable researchers of this time were De Montebello [24-27], Burckhardt [28-30], Dudley [31, 32], Okoshi [33-35], and Dudnikov [36-41]. ‘MDH Products’, Montebello’s company, was the first to commercialize integral photographs for the general public. The first virtual integral images were produced by Chutjian and Collier [42] in 1968 while they worked for Bells Laboratory. These virtual images were obtained by calculating an integral image of computer-generated objects. The objects were calculated with inverted relief in order to produce a double depth inversion to obtain orthoscopic images.
From 1988 to the last decade, the Davis and McCormick [43-50] group had been the most active in the integral imaging area; they published numerous studies and filed a number of patents. In 1991, Adelson and Bergen [51] introduced the concept of plenoptic function, which describes the radiance of each luminous light ray in space as a function of angle, wavelength, time, and position. This function contains any parameter that is susceptible to being captured by an optic device, and it is closely related with what Gibson [52] called ‘the ambient light structure’.
The plenoptic function is a 5D function that in an environment free of occlusions and light absorption can be reduced to a 4D function. The first plenoptic camera was proposed in 1992 by Adelson and Wang [53]. In fact, they used the design proposed by Coffey [22] but added their plenoptic function for the formulation.
Because of the possibility of capturing and reproducing integral images using digital media, the computer graphics community became interested in the concept of integral imaging. In 1996, Levoy and Hanrahan [54] renamed the 4D plenoptic function as ‘Light Field’ and Gortler et al. [55] used the term ‘The Lumigraph’ to describe the same function. In both cases, the researchers proposed the use of just one digital camera moved to different positions for capturing different perspectives of the object.
In 1997, Okano et al. [56] captured, for the first time, integral images in real-time video frequency. Instead of using the habitual configuration, they used a high-resolution television camera to capture the different images formed behind an MLA. In 2002, Javidi and Okano [57] included transmission and real-time visualization. In particular, they proposed the use of a multicamera system organized in a matrix form for the capture, and an MLA placed in front of a high-resolution screen for the visualization.
The information recorded with an integral imaging system has more uses than just optics reconstruction of 3D scenes, and it is possible to achieve computational reconstruction with different applications. One such application was proposed by Levoy and Hanrahan [54] and Gortler et al. [55]. They synthetized new views of a 3D scene from a discrete set of digital pictures captured from different perspectives. These views can be orthographic or with perspective. By using the different perspectives captured with an integral imaging system, we can simulate an image captured by a camera with the main lens with a superior diameter than the microlenses or cameras that sampled the plenoptic function. The depth of field of these images is smaller than that of each of the elemental images. It is also possible to obtain images of the scene focused to different depths, in planes perpendicular to the optics axis of the synthetic aperture [58] or in planes with arbitrary inclinations with respect to this axis [59].
In 2005, the first portable plenoptic camera was built by Ng et al. [60], on the basis of that proposed by Adelson and Wang [53]. The key feature of this camera was to refocus computationally the photographs captured with a digital camera after they were taken. In order to overcome the low resolution of this system, Lumsdaine and Georgiev [61] implemented a new design named ‘Focused Plenoptic Camera’. They proposed to place the MLA in front of, or behind, the image plane. In such a case, the spatial resolution is increased at the expense of the angular resolution. Anyways, independently of the configuration used, a higher number of microlenses and a higher number of pixels behind each microlens will produce a higher spatial and angular resolution.
Miniaturization and integration of chips in the MLA and in the light sensor is the future of integral imaging. In 2008, Fife et al. [62] designed the first integrated plenoptic sensor. Instead of taking the usual approach of using a sensor and a microlenses array, they designed and built a 166 × 76 sensor with small groups of 16 × 16 pixels. Over any of these groups and separated by a dielectric film, a small lens was placed for focalizing the light onto the group of pixels placed behind it.
The interest in and the number of publications on the topic of integral imaging have increased exponentially during the last decade. The two main research topics have been to overcome the physical limitations and to search for new applications of integral imaging systems. For solving the physical limitations, several researchers have proposed solutions to the pseudoscopic problem [63-66], to the uncertainty in the position and angle of the microlenses and the elemental images with respect to the sensor [67-70], and to the limitation of the viewing angle [71-74]. Solutions to the limited depth of field [75-77] or to the detrimental effect of the facet braiding have also been proposed [78, 79].
On the other hand, new applications of integral imaging have arisen. Some examples of these are the visualization of 3D content and TV systems based on integral imaging [80-82], and the automatic recognition of 3D objects [83-86]. Other interesting applications are the 3D image and processing systems of poorly illuminated 3D scenes based on multi-perspective photon counting [87-91], the 3D imaging and pattern recognition of scenes that present partial occlusions or immersed in dispersive environments [92, 93], and the 3D microscopy after a single shot [94-99].
We have reported a review of the advances in the integral imaging technique. We have gone over more than one century of history of 3D imaging and found that this technique constitutes the most promising approach to the problem of showing 3D images in color to massive audiences. Besides, we have shown that this technique has many technological applications other than the 3D display.