The past few years have witnessed the emergence of applications that monitor streams of data items, such as sensor readings, network measurements, stock exchanges, online auctions, and telecommunication call logs [1-4]. In these applications, fast, approximated results are more meaningful than delayed, accurate results. For example, consider a medical center where biosensors are used to monitor the body status of patients. In this example, a life-threatening event should be detected on time, and notified to the medical staff immediately, even if it proves to be a false alarm. Delayed detection of critical events is unacceptable. Similar examples can be found in network intrusion detection, plant monitoring, and so on.
Stream monitoring applications do not fit the traditional database model. Data streams are potentially unbounded. Therefore, it is not feasible to store an entire stream in a local database. Also, queries posed to a database system may not be answered, because an input stream can be infinite. Instead, stream applications adopt the notion of
For example, consider a query that asks for the maximum value of sensor readings over the latest 30 seconds. This can be specified as a structured query language (SQL)-like query
Q1. SELECT MAX(value) FROM Sensors [RANGE 30 seconds]
During run time, the query is evaluated for each tuple arrival. Whenever a new tuple arrives at time
As shown in the example, continuous queries generally use
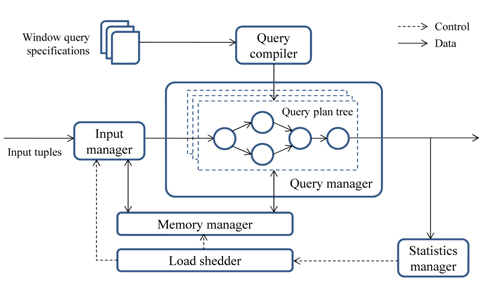
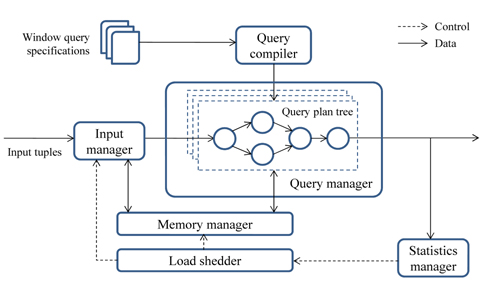
Fig. 1 shows a system structure to process window queries. The query processing engine is also called a
● Query compiler translates user-specified window queries into a query plan tree. The plan tree can be viewed as a filter, through which input streams pass. As mentioned above, queries specified for stream applications can be characterized as window queries (Section Ⅱ).● Query manager runs the generated plan trees over input data streams. Some parts of the trees can be shared to reduce execution time (Section Ⅲ-A). The behavior of stateful operators, such as aggregates and joins, can differ from those in the traditional DBMSs (Section Ⅲ-B). The operators in the plan trees can be scheduled dynamically, according to changing system status (Section Ⅲ-C).● Memory manager provides storage for input tuples and intermediate results generated from the operators in plan trees. It is organized to maximize the sharing of tuples, to avoid disk accesses by reducing memory size (Section Ⅲ-A).● Load shedder monitors system status including arrival rates of input tuples and memory growth during query execution. If the system is overloaded, it prompts the memory manager or the input manager to discard some portion of the tuples (Section Ⅲ-D).● Input manager synchronizes multiple data streams (for a join) and resolves disorder of the streams. Disorder control is necessary to clearly determine the boundaries of sliding windows and to avoid tuple discards that can occur from windowing tuples (Section Ⅲ-E).
In this paper, we provide an overview of data stream processing. In what follows, we consider the specifications and processing of stream queries. We also review related work in this area.
So far, many query languages have been proposed to specify stream queries, including
In Aurora [1], users construct query plans via a graphical interface by arranging boxes corresponding to query operators, such as selections, joins, and aggregates. The boxes are connected with directed arcs to specify data flows. The boxes can be rearranged in the optimization phase. On the other hand, most other systems including STREAM support SQL-like languages for query specification. The query languages have syntax to specify sliding windows to deal with unbounded data streams. This section focuses on the specification of window queries.
A real-time data stream is a sequence of data items that arrive in some order (e.g., timestamp order). In the STREAM project [2, 4, 5], assuming a discrete time domain
DEFINITION 1 (Stream).
A relation is also defined with the notion of time, which is different from the conventional relation.
DEFINITION 2 (Relation).
To denote a relation at any time instant
The relation
● Movement of the window's endpoints: Two fixed endpoints define a fixed window, while two sliding endpoints define a sliding window. One fixed endpoint and one moving endpoint define a landmark window.● Physical vs. logical: Physical or time-based windows are defined in terms of a time interval, while logical or count-based windows are defined in terms of the number of tuples. The latter windows are also called tuple-based windows.● Update interval: Eager re-evaluation updates the window whenever a new tuple arrives on a stream, while lazy re-evaluation induces a jumping window. If the update interval is larger than or equal to the window size, the window is called a tumbling window.
If sliding windows are used in a query, the query becomes
On the other hand, if landmark windows are used, the query will be non-monotonic. It will be recomputed from scratch during every query re-evaluation. The answer set of
To specify a sliding window, the syntax proposed in [6] can be used. In the syntax, a window can be defined with three parameters: 1) RANGE, to denote a window size; 2) SLIDE, to denote a slide interval of the window; and 3) WATTR, to denote a windowing attribute—the attribute over which RANGE and SLIDE are specified.
In general, time-based sliding windows are most commonly used in stream applications [13, 14]. The previous query
Q2. SELECT MAX(value) FROM Sensors [RANGE 100 rows]
To define an update interval for the window, the SLIDE parameter can be used. The following query updates the max value every 30 seconds, which is calculated over tuples arriving for the latest 30 seconds. The query is an example of the tumbling window.
Q3. SELECT MAX(value) FROM Sensors [RANGE 30 seconds, SLIDE 30 seconds]
Note that, with time-based windows, the window interval is determined based on the arrival timestamp of the last input tuple. On the other hand, windowing can also be performed based on different attribute values, not only arrival timestamps. For instance, a user may want to perform the windowing based on the tuples' generation timestamps. Let the attribute denoting a tuple's generation timestamp be
Q4. SELECT MAX(value) FROM Sensors [RANGE 30 seconds, SLIDE 30 seconds WATTR sourceTS]
The following query shows another example of using the WATTR parameter. The query will be posed to identify the list of product names of the latest 10 orders issued from customers.
Q5. SELECT productName FROM Orders [RANGE 10 rows, WATTR orderId]
When a windowing attribute is explicitly specified, as in
To chain a number of relevant queries, the concept of
To calculate the number of vehicles in each segment, the position of a vehicle should first be converted to its corresponding segment number. Assume that segments are exactly 1 mile long. Then, the segment number can be computed by dividing
Q6. SegSpeedStr SELECT vid, speed, pos/1760 as segno FROM PosSpeedStr
From
Q7. CongestedSegRel SELECT segno FROM SegSpeedStr [RANGE 5 minutes] GROUP BY segno HAVING AVG(speed) < 40
As shown in this example, the outputs of a query
This section discusses the issues in processing of window queries over continuous data streams. The discussion consists of query plan structure, blocking operators, operator scheduling, load shedding, and disorder control.
A user-specified window query is translated into a plan tree from the
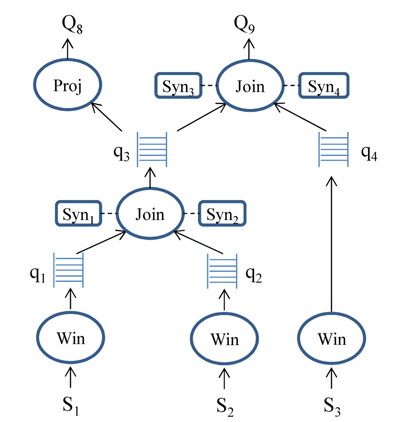
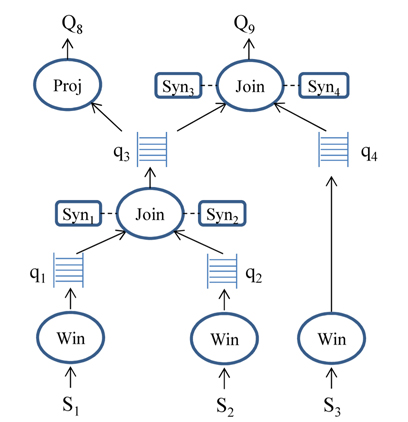
● Query operators: Each operator reads a stream of tuples from one or more input queues, processes the tuples based on its semantics, and writes the results to a single output queue.● Inter-operator queues: A queue connects two different operators and defines the path along which tuples flow, as they are being processed.● Synopses: An operator may have one or more synopses to maintain states associated with operators. For example, a join operator can have one hash table for each input stream as a synopsis.
Fig. 2 illustrates plans for two queries,
Q8. SELECT id, value FROM S1 [RANGE 30 seconds], S2 [RANGE 30 seconds] WHERE S1.id = S2.id
Q9. SELECT * FROM S1 [RANGE 30 seconds], S2 [RANGE 30 seconds], S3 [RANGE 30 seconds] WHERE S1.id = S2.id and S2.id = S3.id
S2 [RANGE 30 seconds], S3 [RANGE 30 seconds] WHERE S1.id = S2.id and S2.id = S3.id
Synopses are maintained for stateful operators, such as joins or aggregates. Simple filter operators, such as selections and duplicate-preserving projections, do not require a synopsis, because they need not maintain state. For synopses, various summarization techniques can be used, including
Queues are generally organized to have pointers to tuples stored in the
As mentioned earlier, query operators can be stateless or stateful. The behavior of stateless operators is the same as in a traditional DBMS. On the other hand, the behavior of stateful operators can differ. When stateful operators are involved in stream queries, sliding windows are needed to decompose infinite streams into finite subsets and produce outputs over the subsets. In this section, we focus on aggregates and joins with sliding windows.
To compute window aggregates, many existing algorithms use the
f(x) =
For any possible sub-aggregate function g(·), if there is no constant bound on the size of storage needed to store the result of
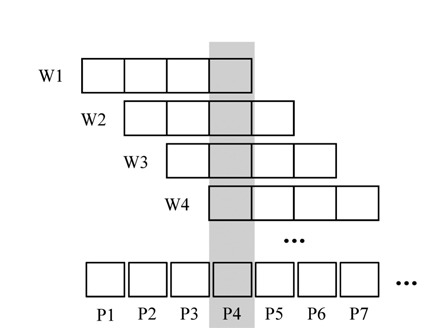
Li et al. [22] proposed an approach for evaluating aggregate queries when sliding windows are overlapping. When adjacent windows overlap, a stream is divided into disjoint subsets called
Q10. SELECT MAX(bid-price) FROM Bids [RANGE 4 minutes, SLIDE 1 minute]
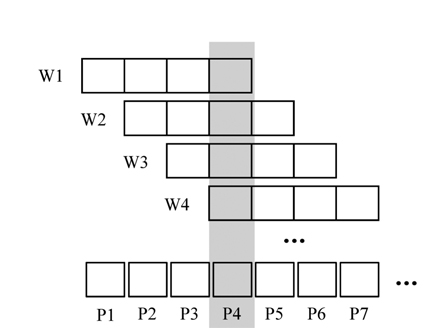
Given
Arasu and Widom [23] proposed resource sharing techniques, when a number of window queries are posed over the same data. In their method, a time interval is divided into a number of predefined smaller intervals called
When discussing join algorithms, sliding window equijoins are most commonly considered [24, 25]. Suppose we want to join m input data streams over a common attribute
Consider
Algorithm 1. Sliding window equijoinWhenever a new tuple s arrives on Sk (1 ≤ k ≤ m), 1. Update all Si[Wi] (1 ≤ i ≤ m) by discarding expired tuples 2. Join s with all Si[Wi] (i ≠ k) 3. Add s to Sk[Wk]
The algorithm consists of three steps: windowing streams (step 1), producing join results over window extents (step 2), and adding the new tuple to its window extent (step 3). Assuming a symmetric hash join, step 2 can be described in more detail:
2.1. Hash: calculate a hash value v for s2.2. Probe: scan all hash tables of Si (i ≠ k), to see if matching tuples with value v exist in the tables2.3. Output: generate results, if matching tuples exist in all hash tables
Previous work [24-26] showed that a symmetric hash join is faster than any tree of binary join operators, emphasizing that its symmetric structure can reduce the need for query plan reorganization. From this, an
There has been substantial research in joining data streams. Early studies in this area focused on a binary join. Kang et al. [27] showed that when one stream is faster than the other, an asymmetric combination of hash join and nested loop join can outperform both the symmetric hash join, and the symmetric nested loop join. Golab and Ozsu [24] showed that hash joins are faster than nested loop joins, when performing equijoins. Assuming that the query response can be delayed up to a certain time, they discussed eager and lazy evaluation techniques for a window join.
The discussion was extended to a multi-way hash join, in a study by Viglas et al. [25]. They proposed MJoin, a multi-way symmetric hash join operator and showed that the
The window join was also used to track the motion of moving objects, or detect the propagation of hazardous materials in a sensor network. This idea was captured by Hammad et al. [30]. The same authors also proposed scheduling methods for query operators, when a window join is shared by more than two branches of operators in a query plan tree [31]. Hong et al. [32] discussed techniques for processing a large number of extensible markup language (XML) stream queries involving joins over multiple XML streams. The method focused on the sharing of representations of inputs to multiple joins, and the sharing of join computation.
Query plans are executed via a
In many stream management systems, more intelligent scheduling techniques have been proposed and used, including
In Aurora, the contents of inter-operator queues can be written to disk, which is different from STREAM. Therefore, to improve performance of query execution, context- switching between operators should be minimized. For this purpose, their scheduling algorithm (called
In TelegraphCQ, query scheduling is conducted by
The
● Round-robin scheduling: Tuples are processed to completion in the order they arrive at q1. Each batch of n tuples in q1 is processed by O1 and then O2, requiring two time units overall.● Selectivity-based scheduling: If there are n tuples in q1, then O1 operates on them using one time unit, producing n/5 new tuples in q2. Otherwise, if there are any tuples in q2, then up to n/5 of these tuples are operated on by O2, requiring one time unit.
Suppose we have the following arrival pattern: n tuples arrive at every time instant from
Due to the high arrival rate of tuples, memory may not be enough to run queries. In this case, some portion of input or intermediate tuples can be moved out to a disk or can simply be discarded from memory to shed system load. In data stream management systems, the latter approach is generally adopted, because in many stream applications, fast, approximate results are considered more meaningful than delayed, exact answers.
The
There has also been substantial research in
● Frequency-based model [26, 39-42]: The priority of a tuple s is determined in proportion to the number of tuples in windows, whose value is the same as that of s.● Age-based model [43]: The priority of a tuple is determined based on the time since its arrival, rather than its join attribute values.● Pattern-based model [29]: The priority of a tuple is determined based on its arrival pattern in data streams (e.g., the order of streams in which the tuple appears).
Das et al. [26] proposed the concept of
On the other hand, Srivastava and Widom [43] showed that the frequency-based model (e.g., PROB) is not appropriate in many applications and proposed an agebased model for them. In their model, the expected join multiplicity of a tuple depends on the time since arrival, rather than its join-attribute value. Their method focused on the memory-limited situation. Many other studies including [26, 40-42] also assumed the memory-limited situation, and then discussed their load shedding algorithms. On the other hand, Gedik et al. [39, 44] emphasized a situation where the CPU becomes a bottleneck (i.e., when an input arrival rate exceeds CPU processing speed), and then proposed load shedding techniques to shed the CPU load.
Kwon et al. [29] considered the load shedding problem for applications where join attribute values are unique, and each join attribute value occurs at most once in each data stream. For these applications, the frequency-based model cannot be used. To resolve this issue, they proposed a new load shedding model, in which the priority of a tuple is determined based on its arrival pattern in data streams (e.g., the order of streams in which the tuple appears).
A data stream is an ordered sequence of data items. The order is important in windowing data streams. In general, window operators assume that tuples arrive in an increasing order of their WATTR values. Out-of-order tuple arrivals are ignored to facilitate the identification of window boundaries [1, 6]. However, tuples may not arrive in the WATTR order, since they often experience different network transmission delays. These out-of-order tuples are discarded in the windowing phase, and such tuple drops can lead to inaccurate results in aggregate queries.
To resolve this issue, input tuples are buffered in the
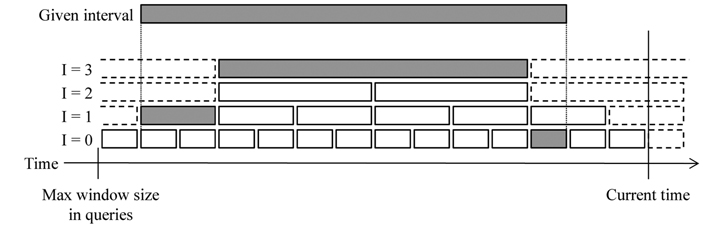
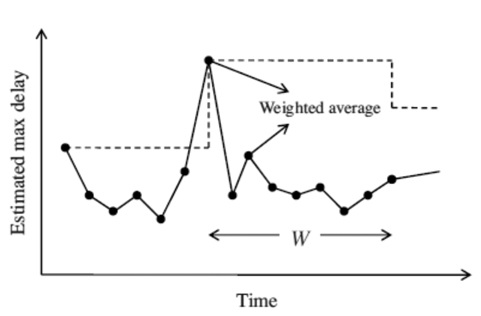
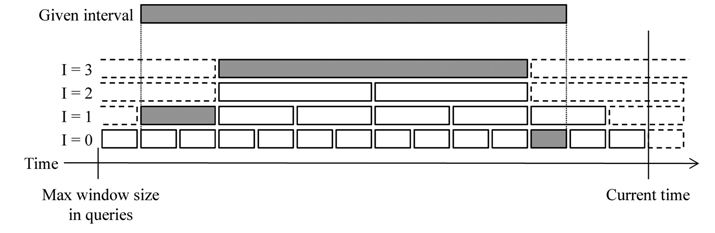
When estimating heartbeats internally, existing approaches generally use the maximum network delay seen in the streams. Let the max delay until time
The heartbeat estimation algorithms focus on saving as many discarded tuples as possible. Consequently, they tend to keep the buffer size larger than necessary. For example, the
To resolve this issue, Kim et al. [46] proposed a method to estimate the buffer size based on stream distribution parameters monitored during query execution, such as tuples' interarrival times and their network delays. In particular, their method supports an optional window parameter DRATIO (an abbreviation for a
Q11. SELECT MAX(value) FROM Sensors [RANGE 30 seconds, DRATIO 1%]
The query above specifies that the percentage of tuple discards permissible during query execution should be less than or equal to 1%. By specifying DRATIO, a user can control the quality of query results according to application requirements; a small value for the drop ratio provides more accurate query results at the expense of high latency (due to a large buffer), whereas a large value gives faster results with less accuracy (from a smaller buffer).
In this survey, we have tried to coherently present the major technical concepts for data stream processing. To keep the task manageable, we restricted the scope of this paper to the specification and processing of window queries. This is meaningful, because most major stream processing engines, such as Borealis [49] (the successor of Aurora), STREAM, TelegraphCQ, and StreamMill, support an SQL interface, to receive application requirements in the form of window queries [50]. The discussions in this paper included synopses structures, plan sharing, blocking operators, operator scheduling, load shedding, and disorder control.
Many interesting issues related to data stream processing could not be included in this survey, for example:
● Classification and clustering● Frequent pattern mining● Synopsis structures, such as reservoir samples, sketches, wavelets, and histograms● Indexing streams● Multi-dimensional analysis of data streams
Some of the issues were discussed in other papers. For example, Gaber et al. [51] presented a survey related to mining data streams. Aggarwal and Yu [52] provided a survey on synopsis construction in data streams. Mahdiraji [53] provided a survey on the algorithms for clustering data streams. These surveys can augment the discussions given in this paper.


![Estimation of the max delay proposed by Srivastava and Widom [14].](http://oak.go.kr/repository/journal/13276/E1EIKI_2013_v7n4_220_f006.jpg)