Speech recognition technology has made great progress in recent decades, and automatic speech recognition (ASR) systems have become increasingly widespread. Since an ASR system is vulnerable to speech noise, and since almost all voice signals contain noise, ASR identification performance using only audio information cannot meet the need. Therefore, developing a robust speech recognition system in a noisy environment is an urgent problem. Developing an integration strategy for audio and visual information is one of the many challenges facing an audio-visual (bimodal) ASR system. From the point of view of perception, video information corresponding to audio information can improve a person’s understanding of a speaker’s voice. In a noisy environment or for hearing-impaired listeners, video information is a useful complement.
Generally, the audio-visual ASR (AVSR) systems work by the following procedures. First, the acoustic and the visual signals of speech are recorded by a microphone and a camera, respectively. Then, each signal is converted into an appropriate form of compact features. Finally, the two modalities are integrated for recognition of the given speech. Integration of acoustic and visual information aims at obtaining as good recognition results as possible in noisy circumstances. It can take place either before the two information sources are processed by a recognizer early integration (EI) or after they are classified independently late integration (LI). LI has been shown to be preferable because of its better performance and robustness than EI [1], and psychological supports [2].
Considering the asynchronous nature of speech signal and video signal, we put forward an improved product hidden Markov model (HMM) in this paper, used for implementing the bimodal voice recognition of Chinese words, which formulate an improved HMM as a multi-stream HMM. Moreover, we control the stream weights of the audio-visual HMM by the generalized Pareto distribution (GPD) algorithm [1,3], in order to adaptively optimize the audio-visual ASR. According to the corresponding relation between the weight coefficient and instantaneous signal-to-noise ratio (SNR), it can adjust the weight ratio of audio stream and video stream adaptively.
Experimental results demonstrate that the importance of audio features is far higher than that of video features in a quiet environment, while in the presence of noise, video features make an important contribution to speech recognition [4-6].
In Section 2, we introduce some related research works about speech recognition technology. In Section 3, we introduce the classical speech feature parameter extraction approach. In Section 4, we put forward our improved HMM, and, in Section 5, we present our weight optimization approach based on the GDP algorithm. In Section 6, we implement our improved bimodal product HMM system, and, show some experiment results between other ASR systems and the improved HMM. Section 7 is conclusion and our future work.
In speaker recognition, features are extracted from speech signals to form feature vectors, and statistical patter n recognition methods are applied to model the distribution of the feature vectors in the feature space. Speakers are recognized by pattern matching of the statistical distribution of their feature vectors with target models. Speaker verification (SVR) is the task of deciding, upon receiving tested feature vectors, whether to accept or reject a speaker hypothesis, according to the speaker’s model. Mel-frequency cepstral coefficients (MFCC) [7] are a popular feature-extraction method for speech signal processing, and Gaussian mixture models (GMM) have become a dominant approach for statistical modeling of speech feature vectors for text-independent SVR [8].
A recently developed method for overcoming model mismatch is to use a reverberant speech database for training target models [9]. This method was tested on an adaptive-GMM (AGMM)-based SVR system [10] with reverberant speech, with various values of reverberation time (RT). Matching of RT between training and testing data was reported to reduce the equalerror rate (EER) from 16.44% to 9.9%, on average, when using both Z-norm and T-norm score normalizations. However, the study in [9] did not investigate the effect of GMM order on SVR performance under reverberation conditions. In fact, it may be difficult to find such research studies on this effect in the literature.
The audio and visual fusion techniques investigated in previous work include feature fusion, model fusion, or decision fusion. In feature fusion, the combined audio-visual feature vectors are obtained by the concatenation of the audio and visual features, followed by a dimensionality reduction transform [11]. The resulting observation sequences are then modeled using one HMM [12]. A model fusion system based on multi-stream HMM was proposed in [13]. The multi-stream HMM assumes that audio and video sequences are state synchronous but allows the audio and video components to have different contribution to the overall observation likelihood. However, it is well known that the acoustic features of speech are delayed from the visual features of speech, and assuming state synchronous models can be inaccurate. We proposed an audio visual bimodal that uses a product HMM. The audio visual product HMM can be seen as an extension of the multi-stream HMM that allows for audio-video state asynchrony. Decision fusion systems model independently the audio and video sequences using two HMMs, and combine the likelihood of each observation sequence based on the reliability of each modality [11].
3. Speech Feature Parameter Extraction
The normalized energy, MFCC and linear predictive cepstrum coefficients (LPCC) of speech describe the prosodic features, timbre features and perceived features, respectively, so they are selected as audio feature parameters in this paper.
The MFCC computation formula is as follows:
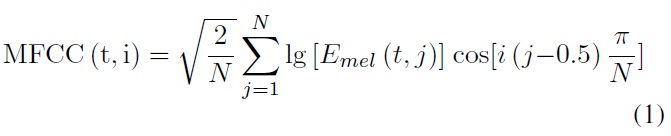
where N is the number of triangular filters; Emel(t,j) is the output energy for the j?
The LPCC computation formula is as follows:
LPCC(t; i) =LPC(t; i)
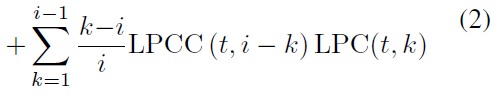
where LPC (t, k) is the k?thlinear prediction coefficient at time t, {LPCC(t,i)}
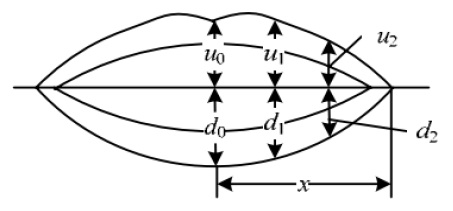
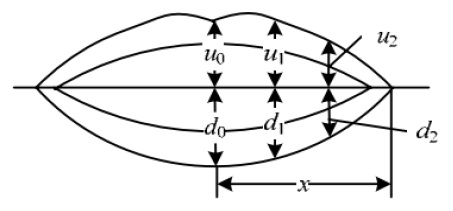
We select lip parameters as video features, a segment video image using a two-dimensional fast thresholding segmentation algorithm, and lip feature extraction parameters [14], as shown in Figure 1, where x is the distance from the labial center line to the edge, u0 and d0 are the heights of the upper and lower halves, respectively, of the mouth centerline, and u1,d1,u2,d2 are the respective heights of the corresponding x-third point. The original lip parameter is v
Auditory and visual features have some synchronicity, with some asynchrony within a certain range. When people talk, mouth movement has already begun before the voice, and it takes time to close the mouth and return to the natural state after the voice, so visual information is usually ahead of auditory information by about 120 ms [15], which is close to the average duration of a phoneme.
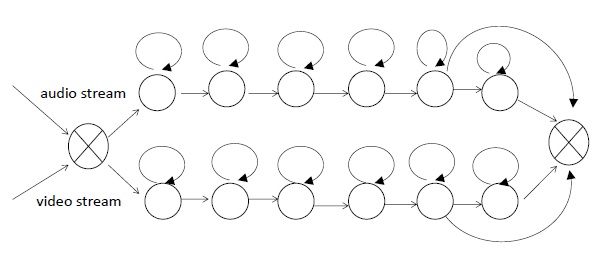
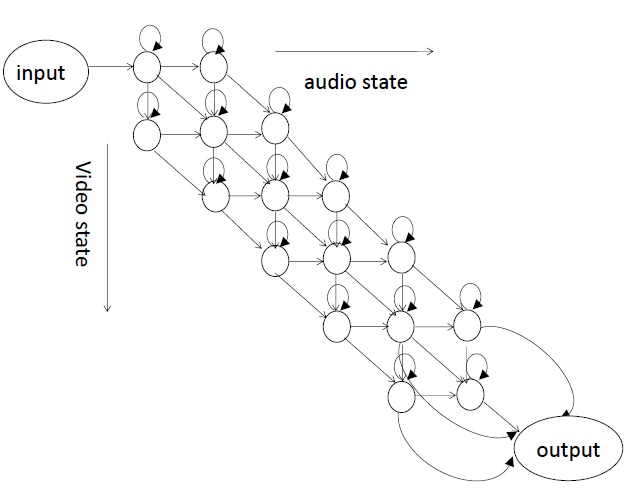
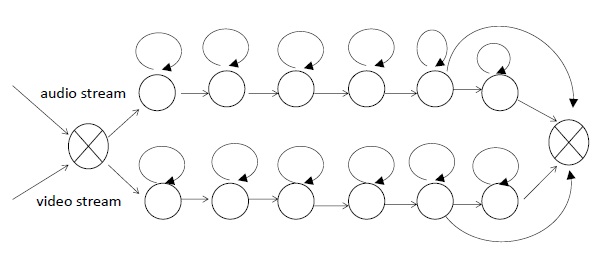
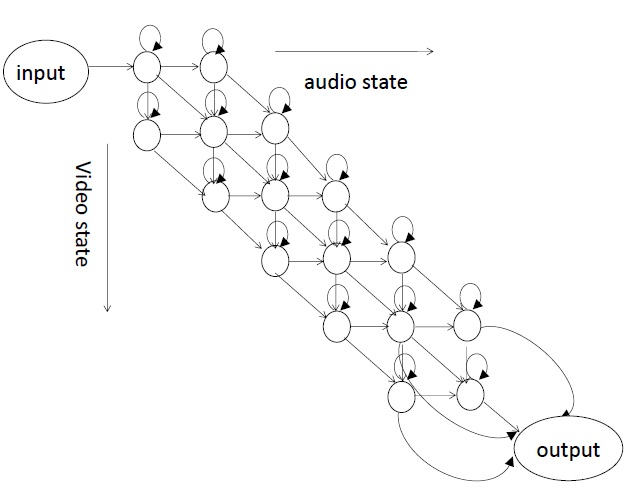
Therefore, asynchrony can be permitted in the auditory and visual training model. This paper proposes an improved product HMM model based on the product HMM method. For Chinese words recognition, which usually corresponds to five or six states, only one state migration is allowed between the audio and video streams as a result of the presence of asynchrony. Figure 2 shows theHMMmodel for the audio and video streams, and Figure 3 shows the topology of the corresponding product
HMM model.
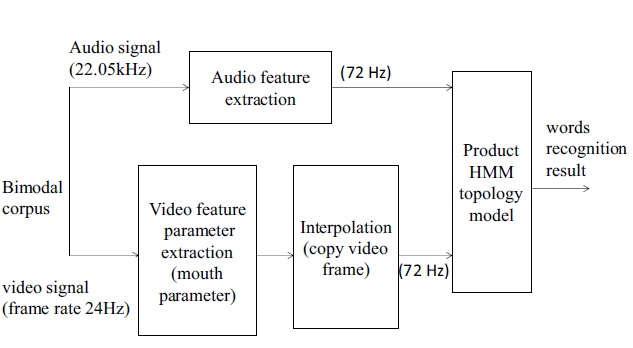
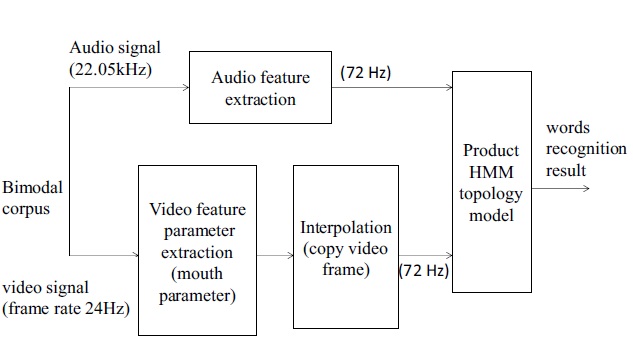
We extract the video features and audio features during the training stage. Generally speaking, the frame rate of the phonetic features is higher than the frame rate of the video features, so we use interpolation for them after video-feature extraction in order to ensure training synchronicity in the data flow.
A bimodal speech feature vector consists of the observation vectors of audio features and video features. According to Bayes’ theorem, the classification result for the maximum posterior probability is
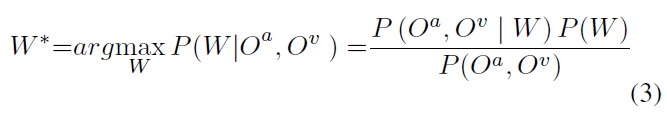
where W denotes some word and O
A multiple-model method needs to combine the audio and video streams in terms of formulas. For the improved product HMM method, we assume that the audio and video streams are conditionally independent, so observation vector and transition probabilities at t time are

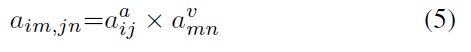
where aaij is the transition probability from state i to state j among the audio HMM and aυmn is the transition probability from state m to state n in the video HMM. The output probability of state ij is
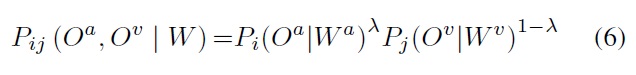
The weight coefficient ? (0 < ? < 1) reflects the different weights of the two modes, which depend on the recognition performance of each mode under the different noise conditions. Zhao et al.’s experiments [16] showed the following linear relationship.
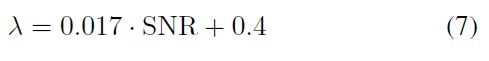
The weight coefficient is greater (? > 0:825) when the speech signal noise is smaller (SNR>25 dB), illustrating that audio information plays a larger role in the decision-making. The weight coefficient decreases with an increase of noise, illustrating that the proportion of video information increases gradually in the decision-making. When SNR = 5 dB, ? ? 0.5, illustrating that they have the same importance at that moment.
5. Weight Optimization Based on the GPD Algorithm
Using the existing training data, based on formula (7), and calculating the weight coefficient according to the GDP algorithm [17], this training algorithm defines a misclassification distance that provides the correct distance between the class information and other information. The misclassification distance is computed using a smooth loss function and is minimized.
For a well-trained product HMM model, according to the Nbest recognized hypotheses, supposing x as the unknown word vector,
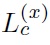
(?) as the logarithmic likelihood values of correctly identifying the x in the model,
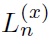
(?) as the logarithmic likelihood values of the N-best candidate vector of misrecognized words, the misclassification distance is
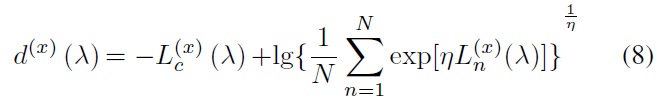
Where η is a smoothing parameter and N is the total candidate number. The total loss function of x after smoothing is
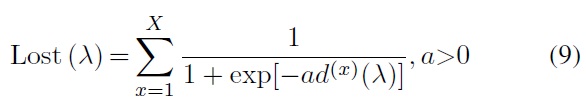
The purpose of training is to minimize Lost(?) so as to minimize the error. The recursive formula of weight is
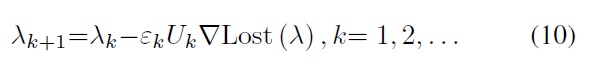
The condition is
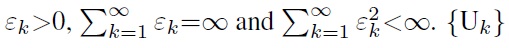
is a finite positive matrix sequence. The algorithm converges as k→ ∞. The recursion stops, and the final weight is obtained when the difference of the recursive value is smaller than a given threshold.
6. Experiment Results and Analysis
We constructed a bimodal corpus and selected from seven people (five for male and two for female). The corpus contains 50 Chinese words, totaling 750 words for the seven people, including 550 words for training and the others for recognition. As needed, we added some noises of different intensity for recognition speech words. The sampling rate of the speech signal is 22.05 kHz. The quantitative value is 16 bits. The frame length of the speech frame is 28 ms. The frame shift is 14 ms, using a Hamming window as the window function. In order to ensure the synchronization of the video and audio streams after the extraction of video and audio features, we interpolated the video features and input these feature parameters into the improved product HMM, shown as in Figure 4. The video features were the lip parameter v
(1) MFCC feature: MFCC (14 dimensions) + ΔMFCC (14 dimensions) + normalized audio energy, totaling 29 dimensions;
(2) LPCC feature: LPCC (14 dimensions) + ΔLPCC (14 dimensions) + normalized audio energy, totaling 29 dimensions;
(3) MFCC-LPCC joint feature: MFCC (14 dimensions) + ΔMFCC (14 dimensions) + LPCC (14 dimensions) + ΔLPCC (14 dimensions) + normalized audio energy, totaling 57 dimensions.
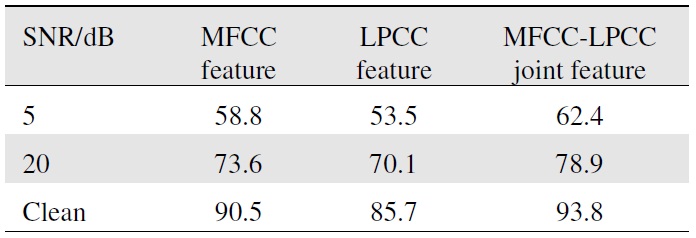
[Table 1.] Bimodal speech recognition rate of audio feature parameters for different SNR
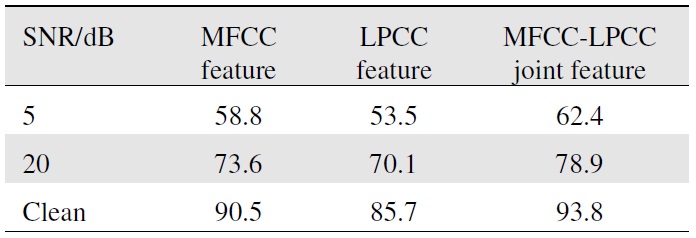
Bimodal speech recognition rate of audio feature parameters for different SNR
Under different SNR conditions, according to the recognition result (Table 1), we selected the MFCC-LPCC joint feature to train modal and recognize speech.
The convergence performance of the GPD algorithm depends on the choice of the feature parameters. After many experiments, we set N = 2 in formula (8), α = 0:1 in formula (9), ?k = 50=k in formula (10), and convergence threshold T
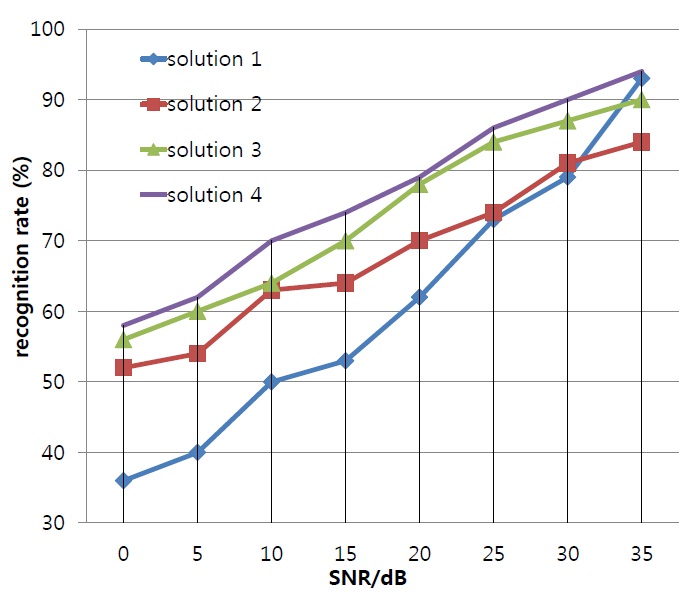
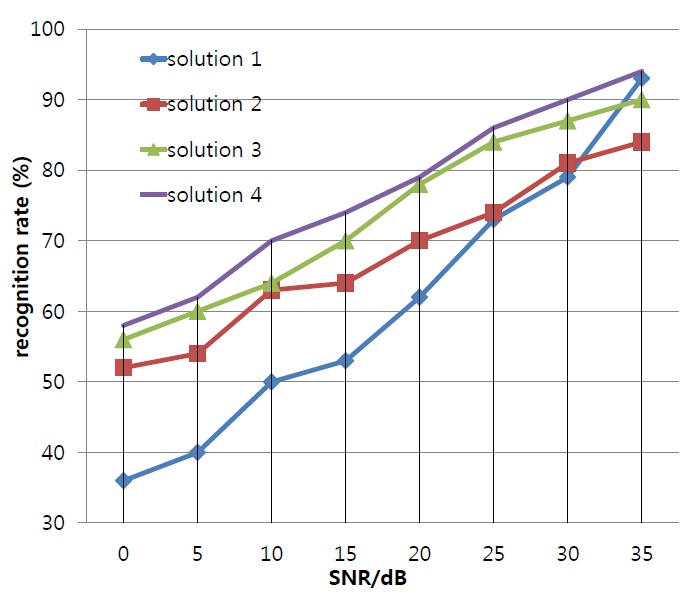
Four speech recognition schemes were proposed for comparing the bimodal speech recognition performance of the different methods.
(1) For the single-modal speech recognition of the audio, the single audio model adopts the classical left-to-right no-cross HMM modal [18]. Considering that the training objects are Chinese words, five or six states are selected and the output probability density function is a four-dimension mixed Gaussian density distribution. The audio parameters are the aforementioned 57 dimension MFCC-LPCC joint feature parameters.
(2) Based on the EI model [19], the joint feature vector is composed of the audio feature vector and video feature vectors, which are inputted to the single HMM model for training, with the same modal architecture as in solution (1).
(3) The multiple HMM model, mixing audio and video features on the state layer, assigning different weights to the audio and video streams according to the principle of formula (6) [5,6], requires special restrictions so as to maintain synchronization between the video and voice stream.
(4) This solution achieves word recognition through the improved product HMM model (Figure 3) proposed here. Based on the assumption that the audio and video streams are independent of each other, it allows for a step-state deviation between them.
To facilitate the performance comparison, the audio and video feature parameters of solutions (2) and (3) are the same as that of solution (4), and the recognition results are as shown in Figure 5.
6.3 Result Comparison and Analysis
In a low-noise environment, the difference in the recognition rate between the single-mode audio recognition method (solution 1) and the bimodal recognition method (solution 2-solution 4) is not large. When noise increases, the gap in recognition rate between single-mode and double-mode recognition will increase. This shows that in high-noise environments, the video information contributes more to the speech recognition rate.
For the bimodal recognition method, the EI model-based method did not assign the weights of video and audio information dynamically, leading to the lowest recognition rate for this method among all the bimodal recognition methods. The solution 3 in [5] only considered the speech recognition of isolated words, while we consider recognizing Chinese phrases, increasing the recognition length. In contrast to our method, [5] used a neural network model, which was slower in actual speech recognition. Furthermore, [5] did not consider the asynchronous nature of the video and audio signals, but simply used the weighted fusion of the speech and video streams. Different from other methods, the method proposed in this paper considered the asynchrony, as shown in Figure 5, the speech recognition rate was slightly higher than in solution 3.
In this paper, with the aim of achieving effective speech recognition in noisy environments, a product HMM-based bimodal speech model allowing a one-step state offset to adapt to the asynchronous nature of the video signal and audio signal is proposed.
According to the corresponding relation between the weight coefficient and instantaneous SNR, the model can adjust the weight ratio of the audio and video streams adaptively. We selected a 50 Chinese 2-digit word corpuses as training and identification data, in contrast to other types of programs. The result showed that our proposed model can ensure the accuracy and robustness of speech recognition in a noisy environment.
Although we have shown effectiveness of the proposed bimodal HMM method on the Chinese 2-digit word recognition tasks, this scheme can be extended for multiword or continuous speech recognition tasks. In such cases, it would be a problem that, from the two modalities, we have unmanageably many possible word or phoneme sequence hypotheses to be considered for weighted integration. Also, more complicated interactions between the modalities can be modeled by using cross-modal associations and influences, where we still can use the proposed integration method for adaptive robustness. With these considerations, further investigation of applying the proposed system to complex tasks such as multiword or continuous speech recognition is in progress.
No potential conflict of interest relevant to this article was reported.