Maintaining connectivity is essential in multi-hop wireless networks since the network topology cannot be pre-determined due to mobility and environmental effects. To maintain the connectivity, a critical point in the network topology should be identified where the critical point is the link or node that partitions the network when it fails. In this paper, we propose a new critical point identification algorithm and also present numerical results that compare the critical points of the network and H-hop sub-network illustrating how effectively sub-network information can detect the network-wide critical points. Then, we propose two localized topological control resilient schemes that can be applied to both global and local H-hop sub-network critical points to improve the network connectivity and the network resilience. Numerical studies to evaluate the proposed schemes under node and link failure network conditions show that our proposed resilient schemes increase the probability of the network being connected in variety of link and node failure conditions.
Recent innovations in wireless technology have contributed to the rapid growth of wireless communication such as cellular and multi-hop wireless networks. Multihop wireless networks are considered to play an especially important role in communications due to their mobility and flexibility. Examples are wireless mesh networks being considered for the replacement of the backbone network [1], vehicular ad-hoc networks creating the connectivity between moving cars [2], wireless sensor networks monitoring and tracking the environment or the target remotely [3], and mobile ad-hoc networks that selforganize without infrastructure aid [4]. One considerably attractive network is the mobile ad-hoc network (MANET), which creates dynamical arbitrary topologies due to node mobility. Since multi-hop wireless networks create conectivity without a pre-existing infrastructure, they have been considered in the deployment of many applications involved in difficult or dangerous tasks where the network infrastructure may not be available. For example, network infrastructure may not be available on the military battlefield, during disasters, or in a rescue environment. A MANET can also be used to provide extended connectivity for the coverage increments in a cellular network or wireless health monitoring system. Such a network requires cooperative nodes willing to act as a router because the wireless link is determined by the receiving signal strength, which is affected by node mobility and interference.
The topology changes with dynamical link changes and adaptive route establishment is required in a multi-hop wireless network. Therefore, connectivity is essential.
In a multi-hop wireless network, connectivity should be maintained to maintain communication because of dynamical topology changes. The network is known to be connected if all pairs of nodes have at least one path, while the network is not connected or partitioned if at least one pair of nodes does not have a path. Note that pre-determined network design is not possible where a wireless link is susceptible to node mobility and interference. Therefore, maintaining connectivity in a multi-hop wireless network is challenging because of its unstructured topology, link and node failure, unreliable wireless channel properties, and limited battery life [1-4].
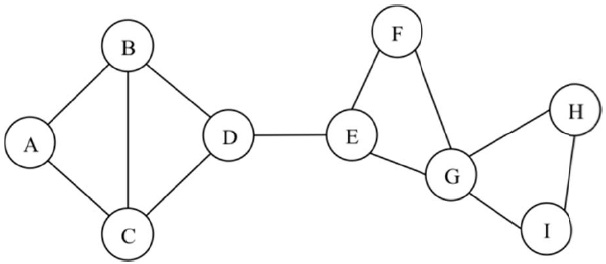
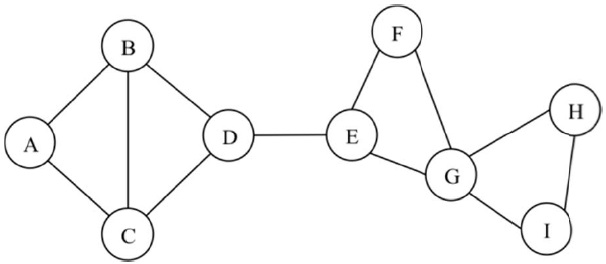
Here we provide an approach to improving the network connectivity to increase the reliability of a given multi-hop wireless network. For a given connected network, we identify the weak or critical points of the network and strengthen those critical points to improve the network survivability. In a multi-hop wireless network, a critical point can be a link, node, or combination of them that partitions the network topology into two or more due to its failure. A link whose failure partitions the network is defined as a critical link, and it is also called a bridge link in a network graph. A node that partitions the network when it fails is defined here as a critical node and is also known as an articulation node. In Fig. 1, for example, link D-E and node G are critical points. The link D-E is a critical link because the network partitions into two network clusters (i.e., A-B-C-D and E-F-G-H-I). Similarly, when node G fails, the network is broken into two clusters, A-B-C-D-E-F and H-I.
In a traditional wired network, a backup route is utilized for the network survivability where the backup route can be link or node disjoint. The backup route allows the network to remain connected in any circumstance of link or node failure. For the network that is still connected from simultaneous failure of (
In a
In this paper, we propose a novel algorithm for identification of critical points in a network. The approach is based on examining the connectivity between neighbor nodes without global connectivity information. In many cases, obtaining network topology may not be easy while obtaining limited sub-network information may be relatively easy. Therefore, we also introduce how each node makes its decision on critical points based on
In this section, we provide the notation used in the paper. Then, we present the proposed heuristic critical point identification algorithm.
We consider an arbitrary multi-hop wireless network of

Notation used
>
B. Critical Point Identification
In wired networks, the concept of identifying critical network nodes has recently been investigated from an infrastructure protection standpoint [15,16]. This literature focuses on which nodes will have the most impact on the network (in terms of connectivity or traffic loss) and a variety of heuristics have been proposed to identify the critical nodes, such as maximum degree nodes and maximum traffic nodes. In this section, some simple heuristics in identifying critical nodes are examined for their effectiveness; specifically, we consider the maximum node degree (Max ND), minimum node degree (Min ND), most heavily utilized (HU) nodes (i.e., nodes on the greatest number of shortest primary path routes), and nodes having the greatest backup path (GB) routes passing through them. The backup path routes are node disjoint with the shortest path primary route for each pair of nodes.
In evaluating the heuristics in the literature, we tested 100 connected random topologies that contained at least one critical node. The topologies were created by randomly placing 50 nodes each with 250 m of communication range in an area of 1,000 m × 1,000 m. Table 2 shows the average percentage of correct detection in the 100 topologies using the metrics Max ND, Min ND, HU, and GB. For each metric, three nodes, as selected by the metric, were evaluated for node criticality. For example, with Max ND, the three nodes with highest node degree were evaluated.
[Table 2.] Percentage (%) of correct critical node detection

Percentage (%) of correct critical node detection
[Table 3.] Critical point identification algorithm

Critical point identification algorithm
The results in Table 2 show that the HU heuristic has the highest critical node detection rate. However, its detection rate is still very low at 32% and one can infer that none of the heuristics are a reliable critical node identification method.
Here, we propose a new heuristic algorithm to identify topological critical points. Our proposed algorithm utilizes the network layer routing protocol to examine the alternate connectivity between neighbor nodes to identify critical points. The algorithm can be executed locally at a node as a self-test. The basic idea is to test a link or node for criticality by deleting all routes through the test point and seeing if alternate routes exist between neighbor nodes of the test point. If the test point is a link, alternate routes between the two end nodes are considered. Our proposed algorithm is shown below in Table 3.
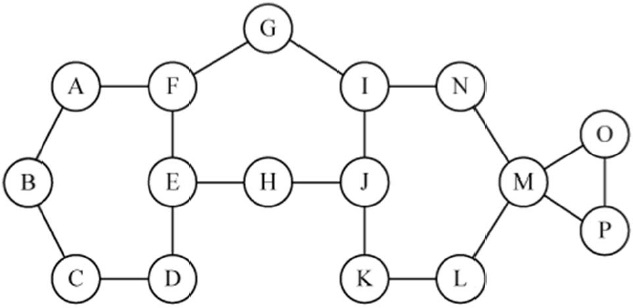
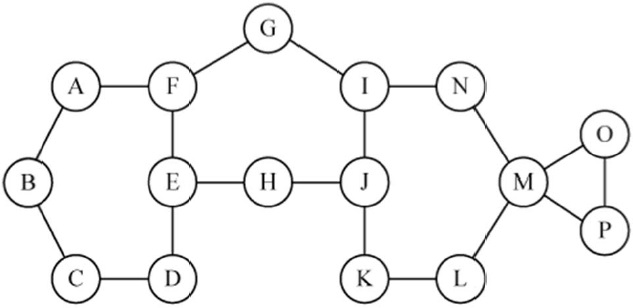
The concept of the critical point identification algorithm is illustrated by example for the network of Fig. 2. Consider the test point node E, which has three neighbor nodes,
Note, that the neighbor node pairs (N, L) and (O, P) have an alternate path between them (i.e., N-I-J-K-L for N and L, O-P for O and P). However, nodes (O, N), ((O, L), (P, N), and (P, L) do not have an alternate path; thus node M is a critical node.
The time complexity of the proposed algorithm is largely determined by computational time to determine the routes between neighbor nodes. In fact, the proposed algorithm takes the same time as the routing algorithms adopted in the network.
Multiple critical points are a combination of nodes and/or links whose simultaneous failure partitions the network. For example, double critical nodes are a combination of two nodes/links whose failure causes the network to partition. Multiple critical points can be found by our proposed algorithm with modification of the test points. Consider the double critical node case, in which all combinations of two neighbor nodes, one neighbor node from one test point node and one neighbor node from another test point node, should be tested for alternate paths that do not include the test point nodes. If any combination of two neighbor nodes does nott have an alternate path, then the e test point nodes are double critical nodes. In determining double critical nodes, single critical nodes are excluded because the failure of any combination with a single critical node partitions the network. In Fig. 2, for example, the failure of any combination of nodes with node M partitions the network because node M is already a s single critical node. Node F and J are not single critical nodes and could be tested for double critical node status. the neighbor pairs of F and J, which are (A, H), (A, I), (A, K), (G, I), (G, H), (G, K), (E, I)), (E, H), and (E, K)), are considered for alternate paths with F and J removed. In this case, the node pairs (A, H), (G, I), (G, K), and (E, H) have alternate paths while other pairs off nodes do not. Thus, the combination of F and J form a double critical node pair.
>
D. Local H-hop Critical Points
Our proposed critical point test algorithm can also be used for local
Once a test point node collects
Each nodes checks the connectivity between all pairs off nodes from its neighbor nodes set
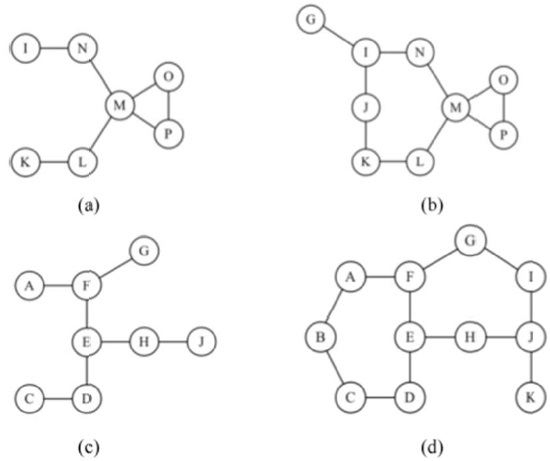
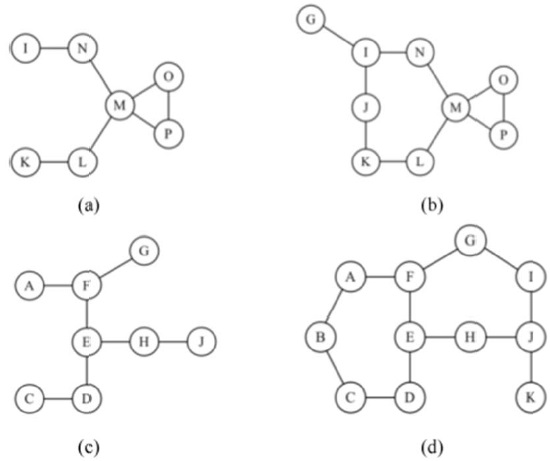
Consider the critical point identification problem using H-hop local connectivity regarding node M or E in the network topology of Fig. 2. The 2-hop and 3-hop connectivity sub-networks of node M are in Fig. 3(a) and (b), respectively. Similarly, Fig. 3(c) and (d) show 2-hop and 3-hop sub-networks of node E, respectively. In order to apply the critical point test algorithm, each test point M or E should examine all hello messages with a TTL value of 2. For example, node M in Fig. 3(a) will receive
[Table 4.] H-hop critical node identification algorithm

H-hop critical node identification algorithm
We also observe that the set of global critical nodes will be contained in the set of all local critic al nodes identified by the algorithm with
In this section, we present two topology modification schemes to improve the resilience of the network by strengthening the connectivity around the critical node. The first scheme adds additional links to provide full connectivity around the critical node while the other scheme creates the minimum number of additional links in the
1) Local Mesh Connectivity Scheme
The local mesh connectivity (LMC) scheme creates a fully connected 1-hop local network around a critical node. An additional link between each pair of 1-hop nodes can be established by adjusting transmission power. All 1-hop nodes of the critical node check for direct link connectivity with all the rest of the 1-hop nodes or neighbor nodes set
[Table 5.] Local mesh connectivity (LMC) algorithm

Local mesh connectivity (LMC) algorithm
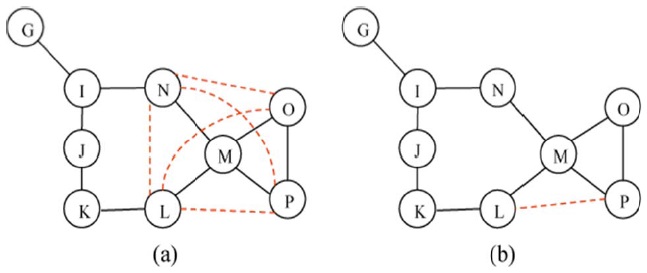
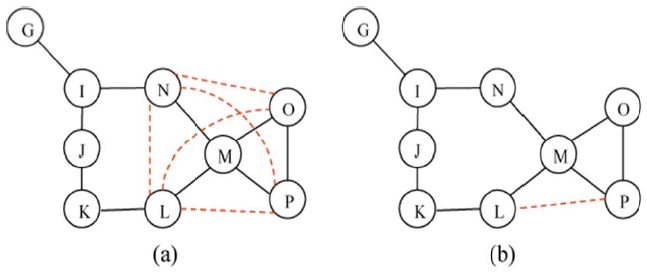
Adding additional links between 1-hop nodes of the critical node creates an alternate path for each pair of 1-hop nodes so that the network is still connected even when the critical node fails. For example, node M is a critical node off the 3-hop sub-network in Fig. 3(b). Node MM, whose node degree is 4 (i.e.,
In the LMC scheme, all pairs s of neighbor nodes are to be examined for direct link connectivity (i.e.,
2) Local Least Connectivity Scheme
Similarly, the local least connectivity (LLC) scheme also creates additional links around a critical node. LLC finds fewer additional links than does LMC. Since LLC utilizes
[Table 6.] Local least connectivity (LLC) algorithm

Local least connectivity (LLC) algorithm
The example of LLC is shown in Fig. 4(b). Node M is a critical node and the sub-network breaks into two clusters when node M fails. 1-hop nodes L and N are connected via an alternate route (i.e., L-K-J-I-N) and they are in the same cluster, while the other 1-hop nodes O and P are directly connected. Then, LLC recognizes connectivity within the 3- hop sub-network and creates one additional link between L and P to create an alternate route between the two clusters assuming the distance L-P is shortest (i.e.,
3) Implementation of the Schemes
The critical node initiates LMC and 1-hop neighbor nodes execute it. First, the critical node sends an initiation message including the set of 1-hop neighbor nodes to all other 1-hop nodes. As soon as this message arrives at each neighbor node, each 1-hop neighbor node sends a message to all of the other 1-hop neighbor nodes by setting the time-to-live (TTL) value of 1 to check for direct link connectivity. Only directly connected 1-hop nodes receive this message. Then, each 1-hop neighbor node learns which other nodes with which it should create an additional link.
Unlike in LMC, the critical node initiates and executes the LLC scheme. LLC uses the
In this section, we present results from sets of simulations. We first present the numerical study of
>
A. Critical Node Detection by H-hop
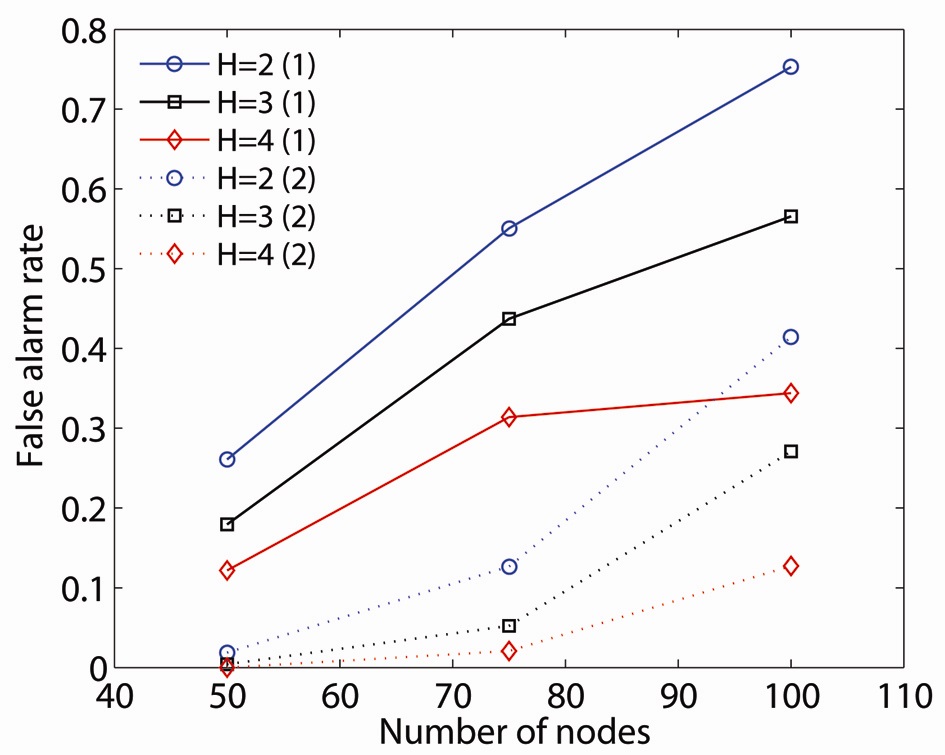
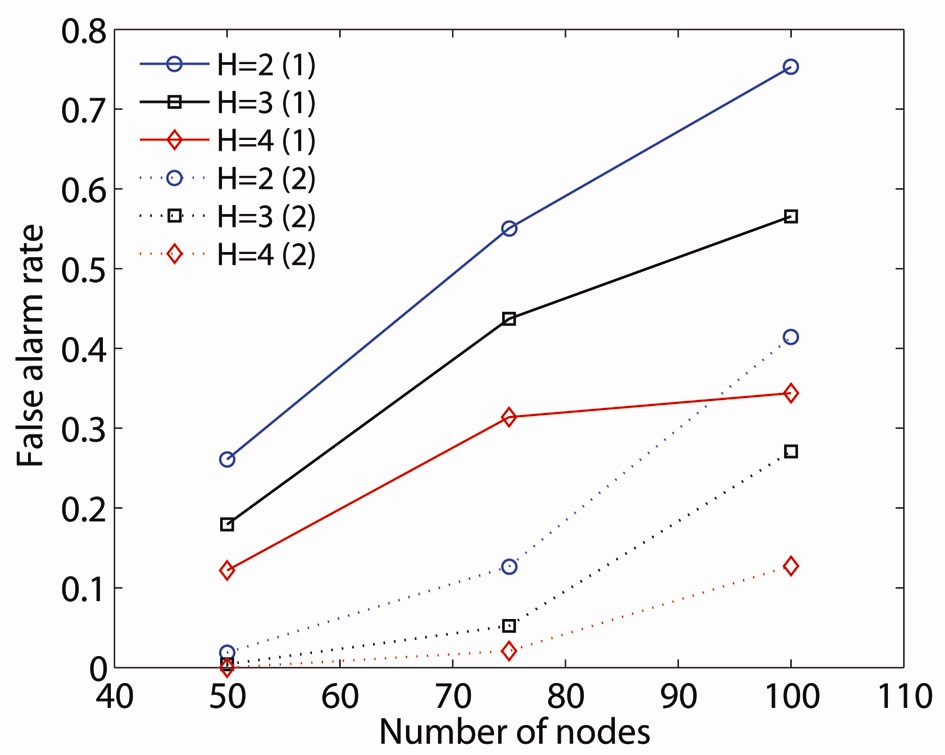
We use our proposed critical point identification algorithm to illustrate the effects of limited information (i.e.,
Comparing FR1 and FR2, critical node detection by an
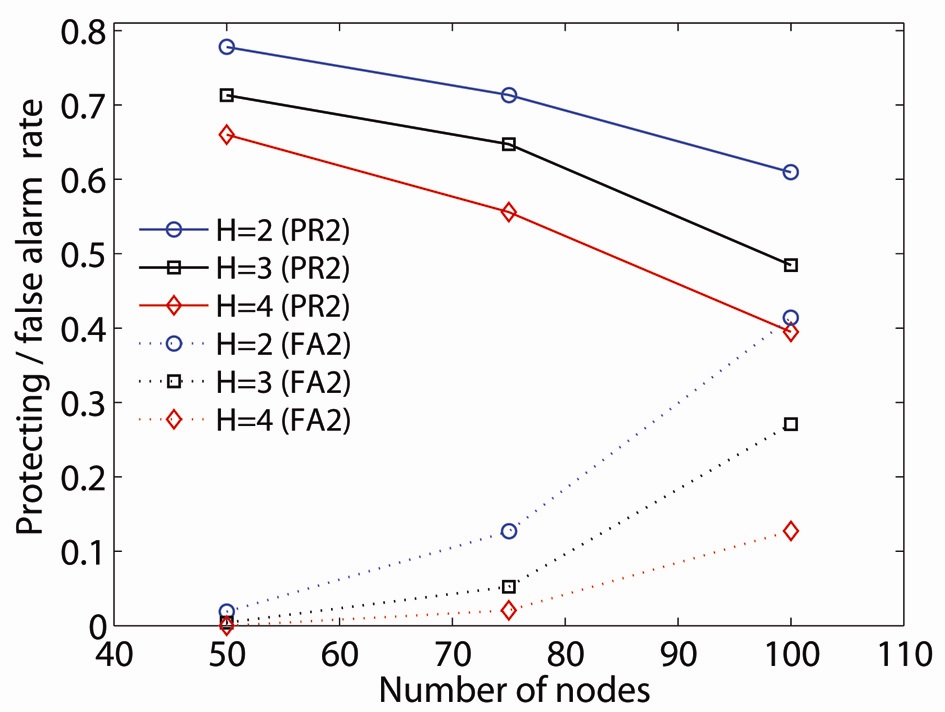
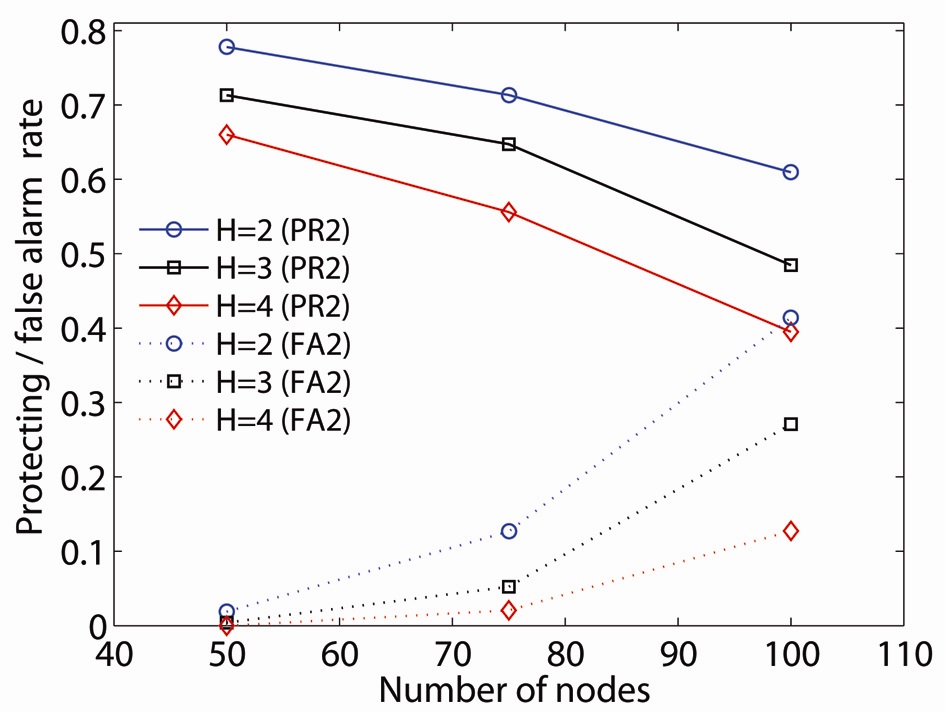
To illustrate the effect on double critical node detection, we introduce the protection rate of double critical nodes (PR2): the ratio of the number of double critical nodes in which at least one node is detected by an
The value of the
>
B. Local Resilient Schemes in H-hop Subnetwork
We evaluate the effectiveness of our critical node management schemes using simulation. In this study, we implement our proposed resilient schemes for
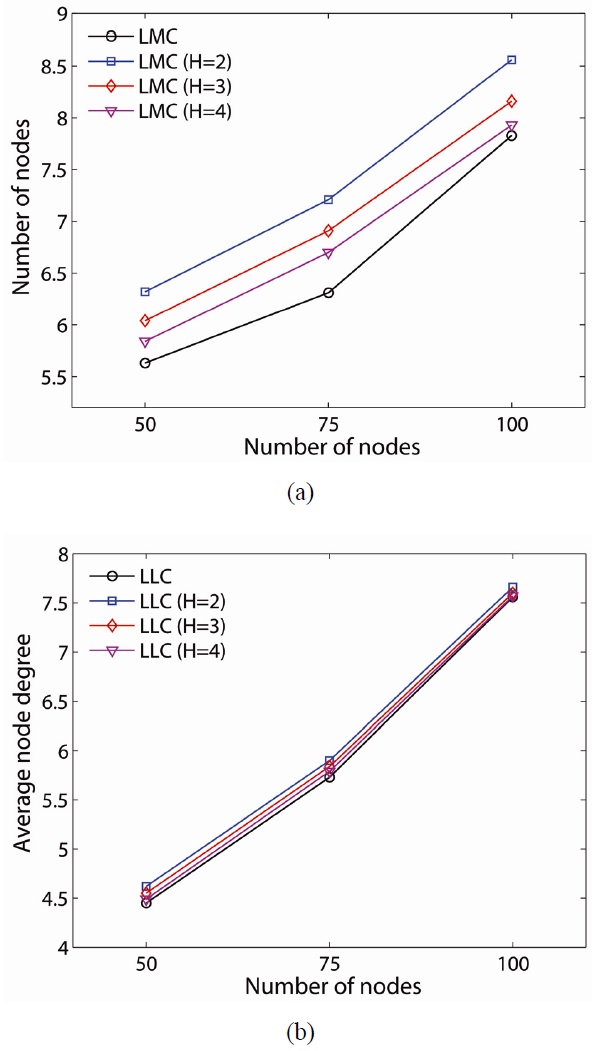
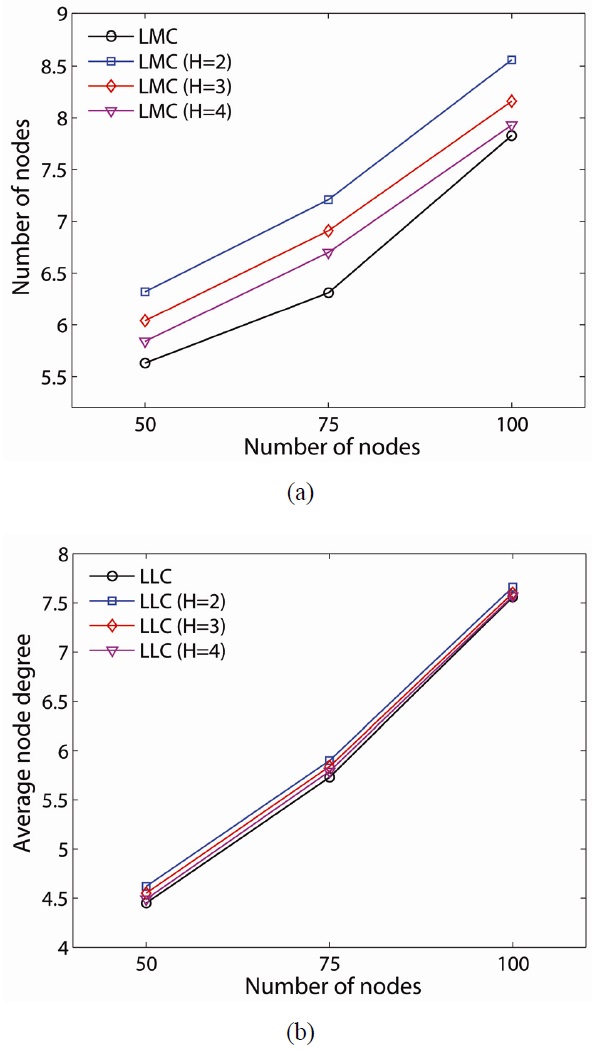
Although our proposed schemes can effectively provide a 2-connected network, there are some tradeoffs between LMC and LLC. We consider the average node degree and average number of added links as the tradeoffs, and they are shown in Figs. 7 and 8, respectively. The average node degree provides a metric of connectivity and interference. In the sparse network case (i.e., 50-node network), LMC has a higher average node degree (i.e., LLC 4.45, LMC 5.63). When the network is denser, the average node degrees of the proposed resilient schemes are closer. A different value for H in LLC does not make much difference in the average node degrees in all network density while LMC makes a difference. LLC on a global critical node shows a lesser average node degree than that on
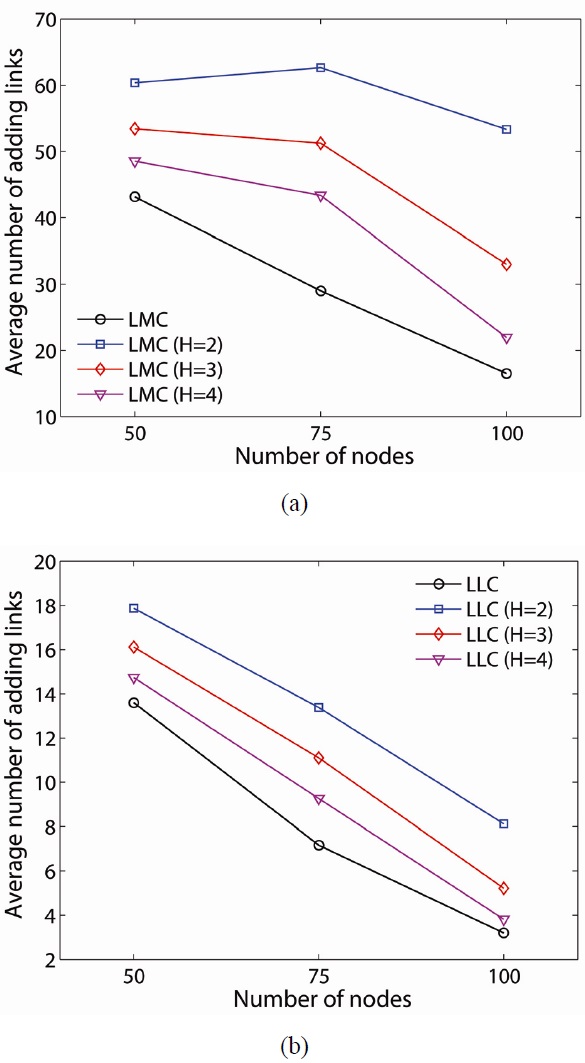
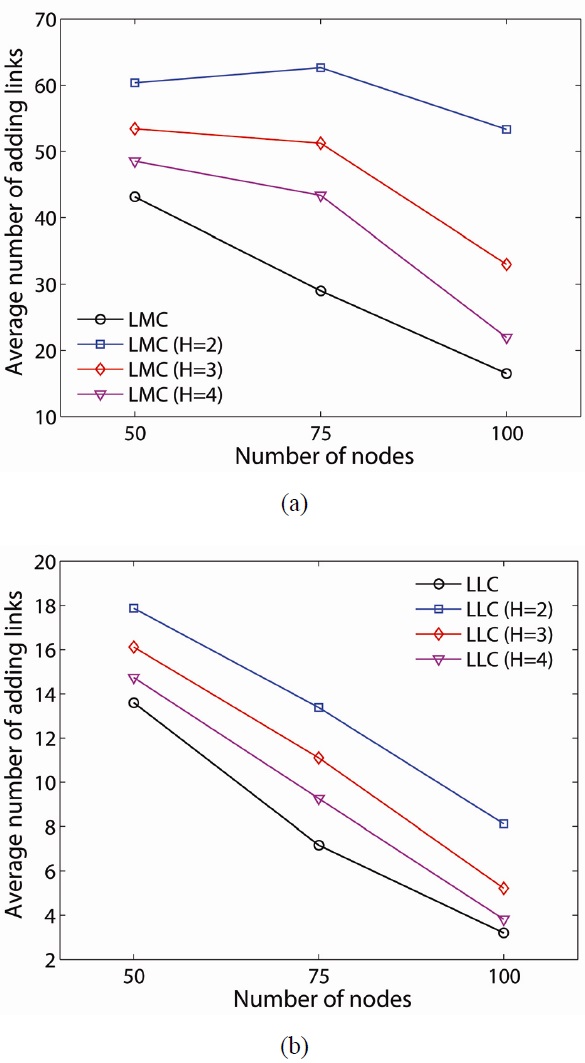
The average number of added links can be related to the average energy consumption of the network since adding additional links is achieved by increasing the transmission power of the node. As shown in Fig. 8, LMC requires significantly more energy than LLC for the 50-node network (i.e., 60.36 at
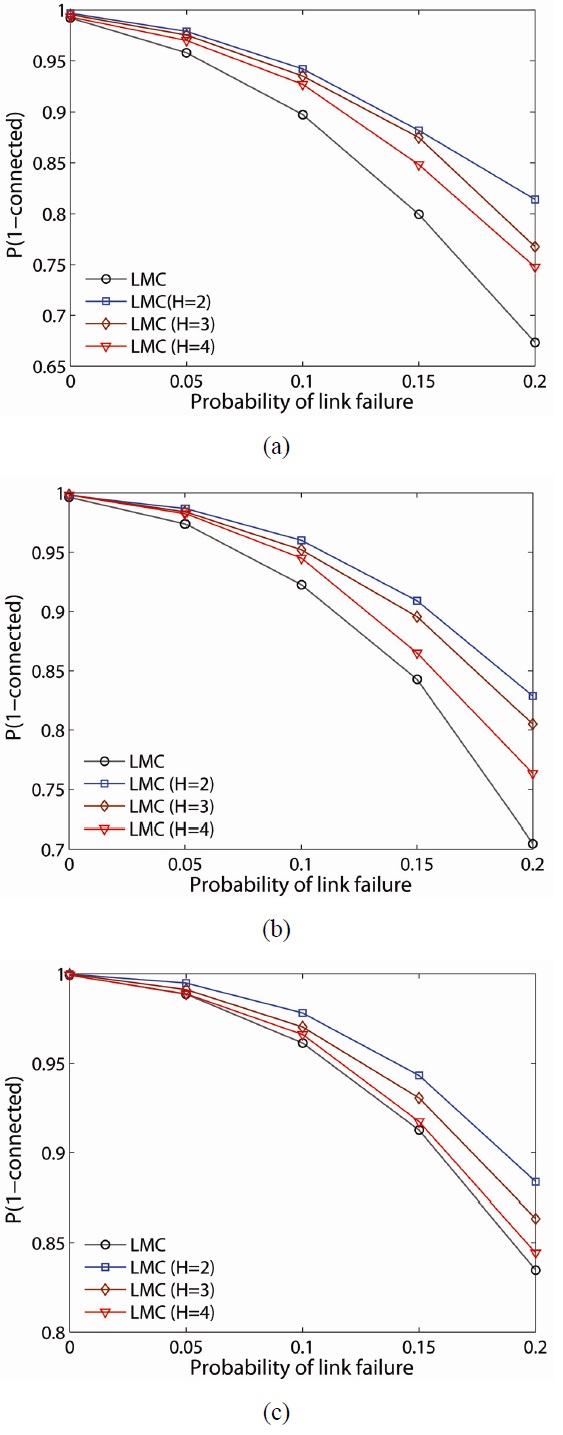
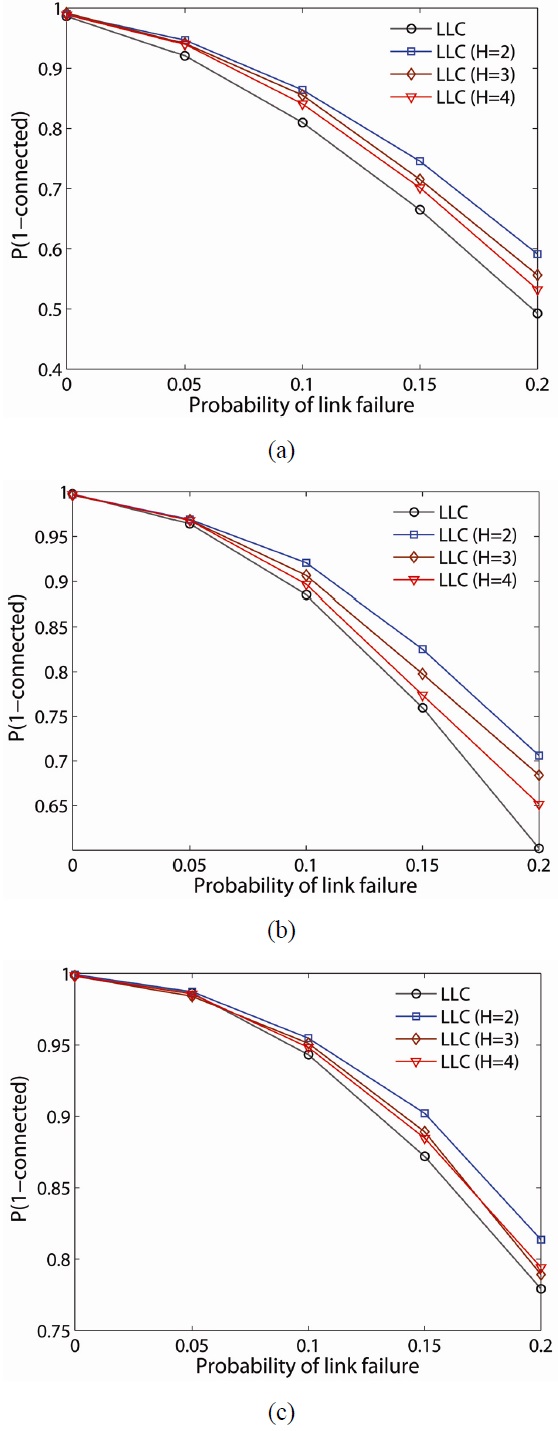
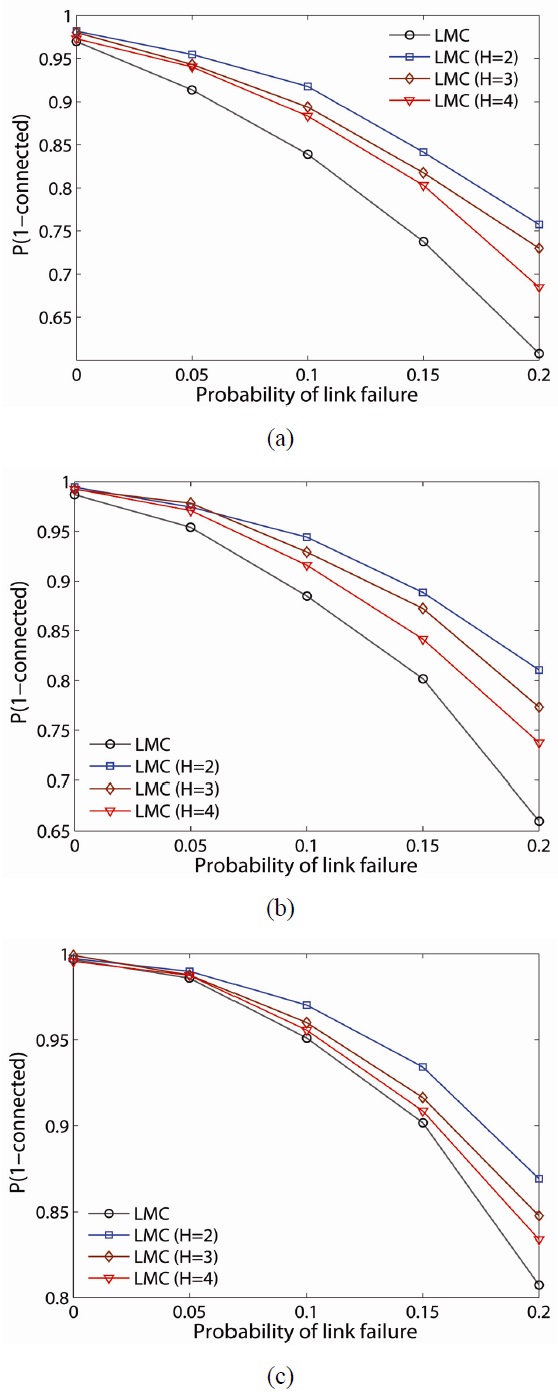
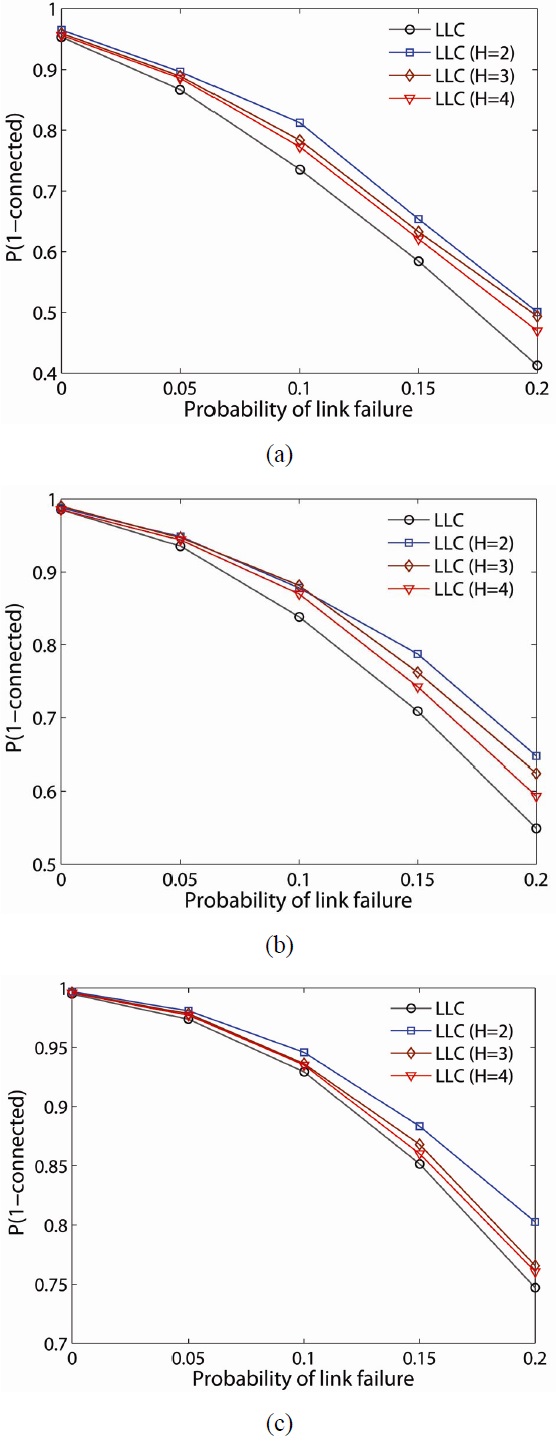
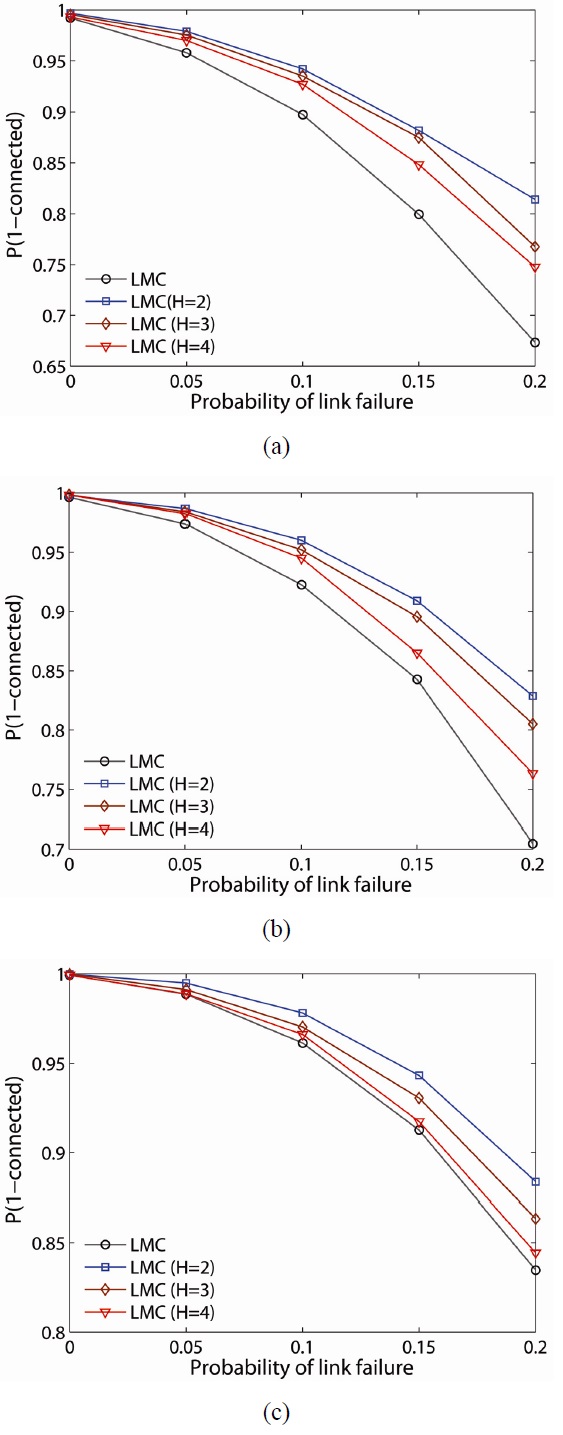
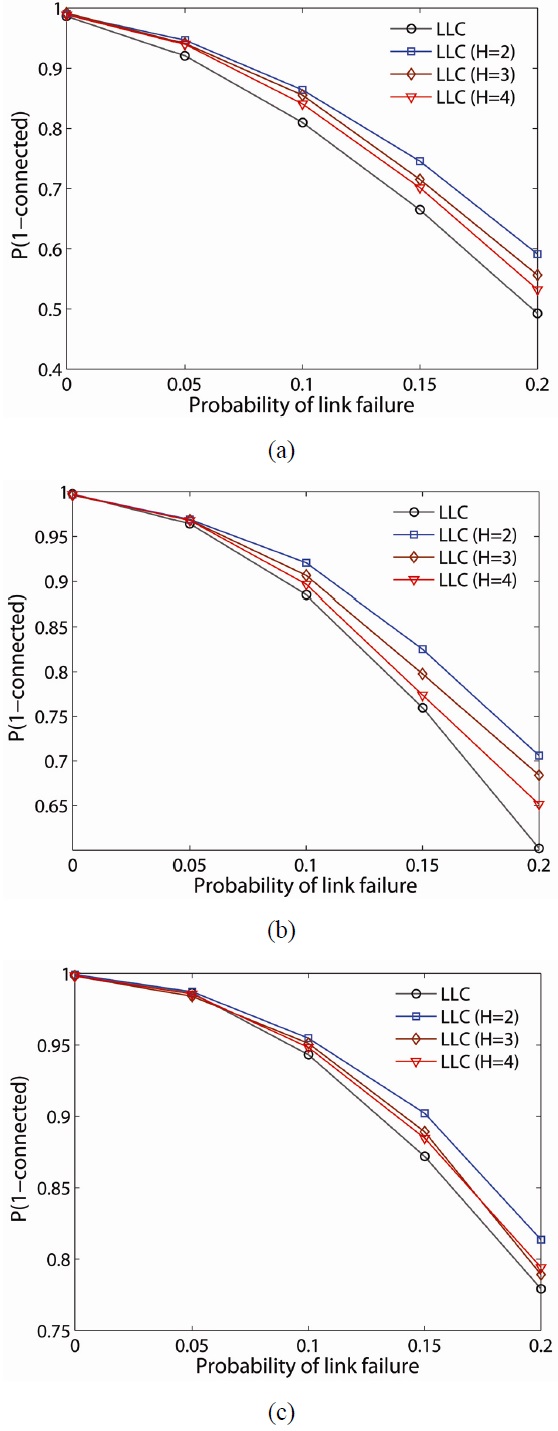
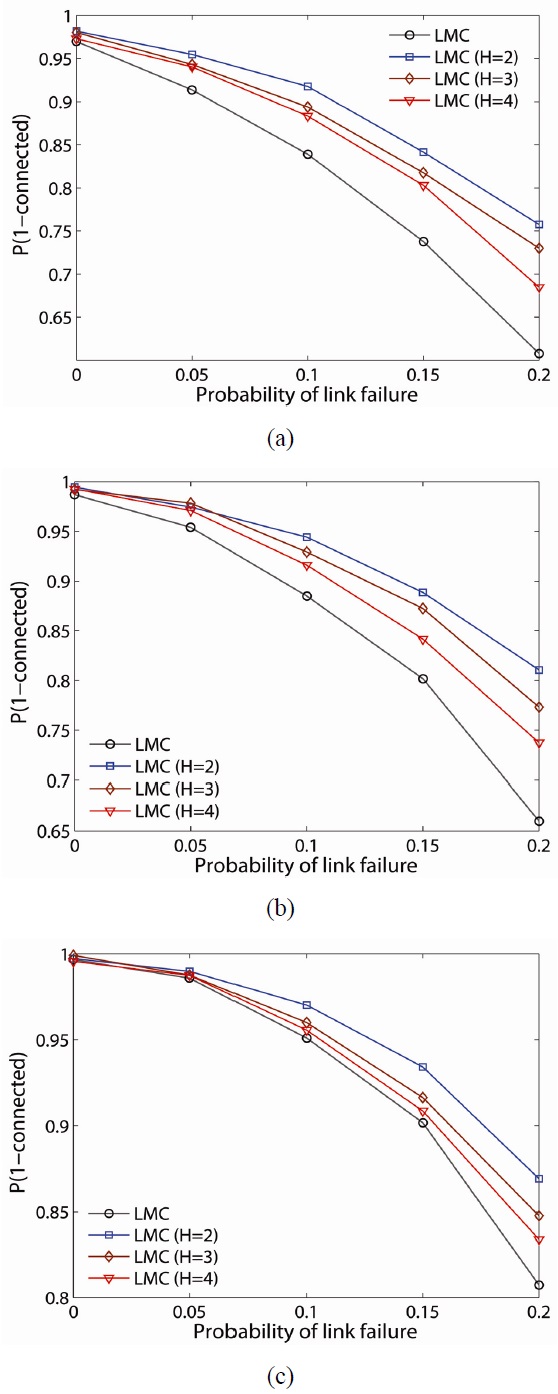
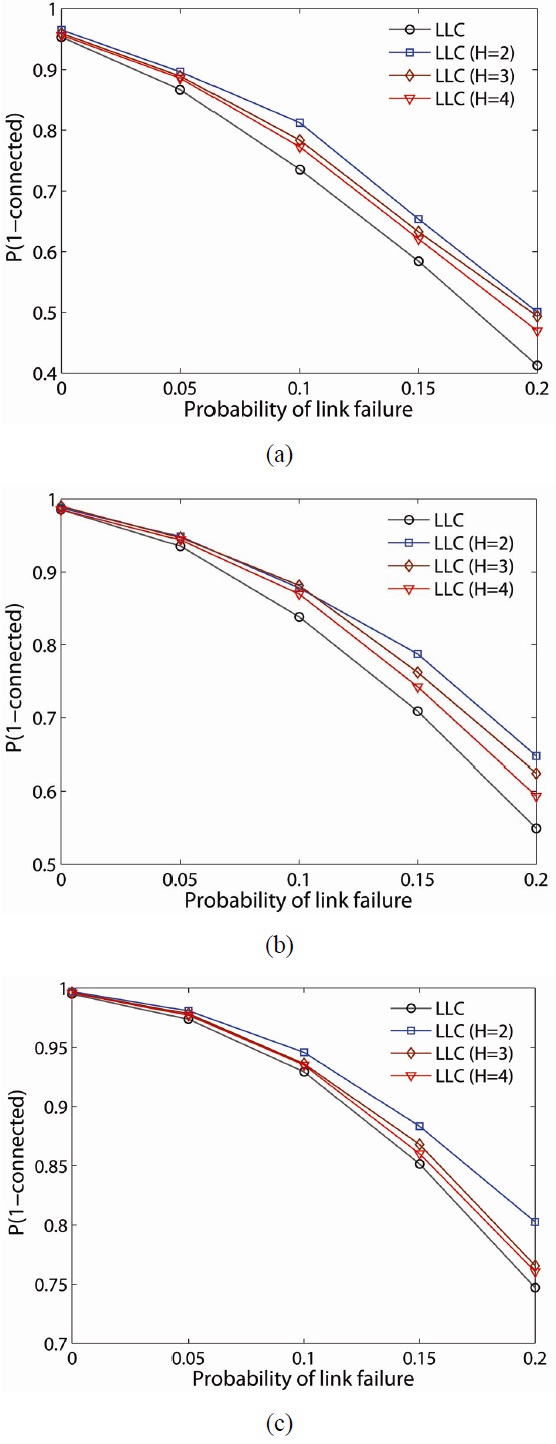
To further examine the resilience of the proposed schemes, we randomly fail nodes and links in the network and determine the probability the network remains connected (i.e.,
The probability of the network being connected on the estimate of LMC is computed and plotted for 50-, 75-, and 100-node networks, as shown in Fig. 9(a)?(c), respectively. As one would expect, the lower
For example, for a 100-node network with link failure of 0.2,
The probability,
When LLC is compared with LMC, LMC improves the probability of network connectivity more than LLC at any network density. Another observation is that
Figs. 11 and 12 illustrate
Note that while the LMC scheme has a higher
We have proposed a new algorithm to identify the critical connectivity points of a multi-hop wireless network topology utilizing the connectivity between local neighbor nodes. Unlike the existing algorithms, the proposed technique can be tested locally at the node and has a simple implementation using only local information at the expense of false positives in the results. Local sub-network critical nodes can be used to predict multiple failure critical points and can reduce the number of broadcasting messages by limiting the TTL value. We have also proposed two resilient schemes that strengthen the critical nodes by utilizing transmission power control. Our proposed schemes can be applied to global and local