Human action recognition is a new but highly researched field in computer vision owing to the vast applications it attracts. The applications include but are not limited to intelligent human-computer interactions and entertainment, automatic annotation of video data, surveillance, and medical diagnosis and training. We can reiterate the fact that there are thousands of variants of activities and gestures that can be inferred from a video clip or on still pictures. Describing and recognizing these actions involve image processing methods that are not trivial. Most of the action recognition machines are application-specific and have predefined tasks to execute. Widely researched and modeled human actions with publicly available databases include walking, running, jumping, jogging, waving (one and/or two hands), bending, handshaking, boxing, kissing in movies, and many others. Like that of many other research works, our task in this paper is to locate, extract, describe, and recognize (classify) several predefined human actions into proper classification categories.
Recognition or categorization of these actions refers to classification of the action in a motion picture into one of the many predefined classes. Action detection not only classifies the action but also identifies the spatial and temporal aspects of the action that occurred in the video. These two very important tasks have been dealt with through various methods, all in the effort to improve their performance. These approaches have developed from silhouette-based methods [1], and pose estimation [2], which are considered to be traditional methods of human action recognition, to more dynamic spatiotemporal domain methods [3]. The latter methods are closely related to our work in general, as actions are considered to exhibit spatiotemporal patterns that can be modeled based on local features extracted [4], optical flow [5], and gradient based descriptors [6].
In this paper we describe and model human actions from human silhouette edges based on spatiotemporal features extracted from the video. Information entropy measurement [7] is used to aid in the selection of important key posture frames from the input video. Shape context [8] is used in many studies as a local feature selection method to avoid redundancy of similar frames selected. Summing up the finely extracted edge features forms the vital descriptors for various action classes in our gallery database. Similarity measurement is performed based on rigid Hausdorff distance measure [9] to validate the query template into an appropriate grouping. Most of the image preprocessing procedures are outside the scope of this paper and are just mentioned. Section II of the paper explains in brief the theory of information entropy. We describe both the formation of our descriptor and the Hausdorff distance in Section III. Section IV contains experimental results with the conclusion of the paper in the final part, Section V.
II. EXTRACTION OF KEY POSTURES
For proper classification, information from the motion pictures should be collected in a proper manner. The extracted features will influence the outcome of the categorization or classification of the task at hand. Evaluation of information entropy is a step towards extraction of the key postures that will be later applied in the formation of human action descriptors. Image sequences from the motion pictures reveal that human actions contain a few important postures and gestures that are significantly different from each other. These need to be properly extracted so that they can be used in the discrimination process. Motion analysis is performed in the original video to extract the moving object (human body). This can be achieved through methods like background subtraction, temporal differencing between frames, and optical flow [10]. For salient extraction of the features of the moving object, our paper used the background subtraction method. Successive thresholding and binarization accomplished this vital process.
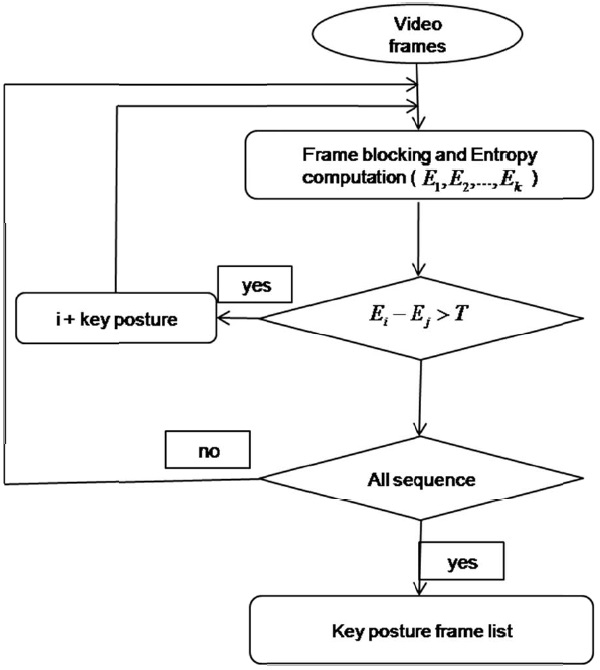
Information entropy is a statistical measure of uncertainty used to collect all possible key postures frame-by-frame based on their information measurements. We applied information entropy [7] as a criterion in designing an optimal feature selection process. The formation states that given a discrete set of pattern classes of {
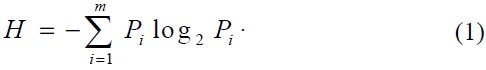
The entropy is computed per frame in sequential order. This is to say that the entropy values of two frames are compared to determine the similarity between the postures. For every frame, the information entropy is computed by first dividing the frame into blocks of

with
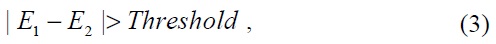
where
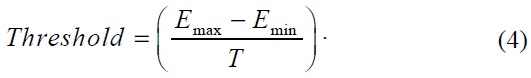
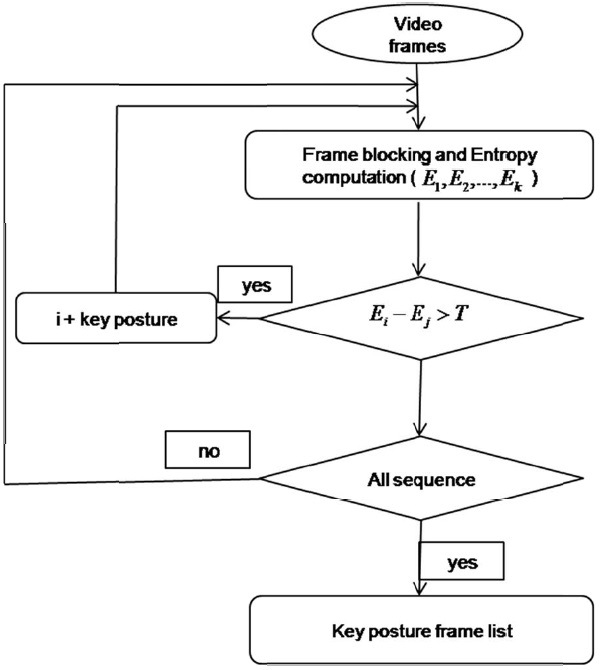
The key posture frame list is formed using information entropy. Fig. 2 shows the flow chart for key frame selection.
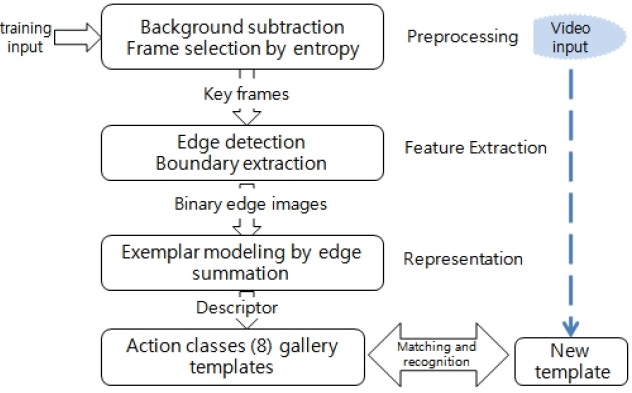
This part is the main contribution of this paper. We have chosen to represent the human body in terms of its external characteristics: the boundary. Morphological operations [11] on the edge images form clear double-boundaries, which in turn are superimposed to exhibit a good silhouetteedge shape used as a descriptor to the action classes. The boundary has been chosen fundamentally because the task we are faced with is dependent on the shape of the human body rather than the regional properties like color or texture.
The vital key postures from the entropy section are operated on further to form the salient features for an excellent description of the action classes. The exemplar images formed from the edge descriptors are stored as templates for the gallery images in our database for comparisons with the query templates presented for classification.
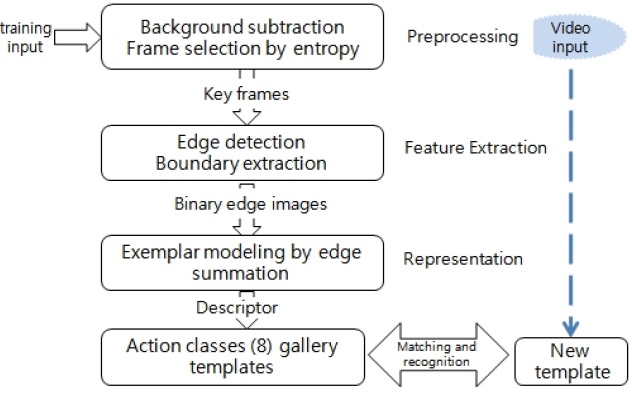
1) Motion analysis is performed to extract the object (human body) in the frame sequences from the original video stream. Background subtraction is done simultaneously.
2) The information entropy measurement (Section II) is used for key frame selection.
3) Edge detection is performed and extraction of boundaries executed.
4) Finally, selected binarized boundaries are super-imposed to form a feature descriptor for each action class.
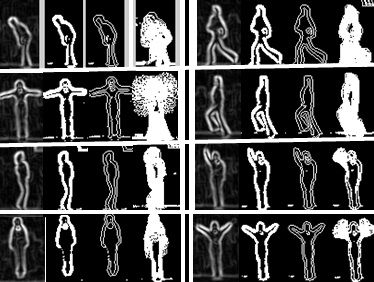
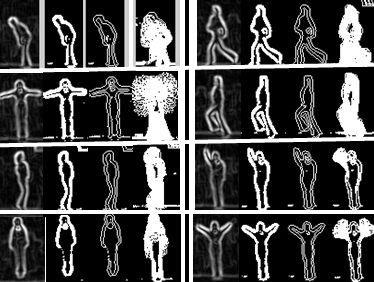
The result of the feature descriptors formed from the procedure in Fig. 3 above is shown below in Fig. 5.
Snapshots of video captures of typical actions are shown from the Weizmann human action database in Fig. 4.
>
B. Matching and Classification
The Hausdorff distance measure [9] is a distance measure that computes the maximum distance of a set to the nearest point in the other set. In other words, it measures the extent to which each point of a model pattern set lies near some point of the probe image set. With this value computed, we can use it to determine the similarity between the two objects/images in question. This is done by superimposing the images on one another. This is the characteristic that we need for the comparison between the action-trained descriptor models and the input image for classification.
The Hausdorff distance method has been widely used and is lauded for many advantages with the two main ones enhancing the effectiveness of our proposed descriptor.
1) The Hausdorff distance is simple to implement and has a fast computation time. The log polar transforms of our descriptor are of the same size and superimposing makes comparison easy, even visually.
2) Our work involves stacking of frames to form a sum of the edges for description. The Hausdorff distance is relatively insensitive to small perturbations of the image such as those that occur with edge detectors and other feature extraction methods.
Hausdorff distance can be extended to cater for occlusion and help identify portions of a shape that are hidden from view but need to be identified. Occluded images are not included in our work, but Hausdorff distance could help solve that problem when it presents itself.
We formulate the Hausdorff distance method of recognition as in Eq. (5). Given two finite point sets of
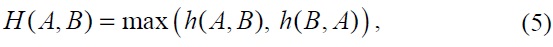
where
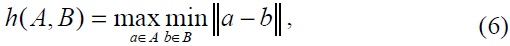
and ||?|| is some underlying distance on the points of
The Hausdorff distance is asymmetric, which means that the condition
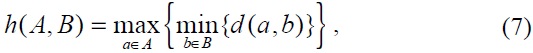
where
By computing the maximum distance between two sets of images, the Hausdorff distance measures the mismatch between two sets that are at fixed positions with respect to each other. This is true in our case, as the images that we intend to compare are fixed without translation. If translations were to be considered, Hausdorff distance obeys metric properties, as can be seen in [12,13]. This means that the function is everywhere positive and has the properties of identity, symmetry, and triangle inequality. We hold the view that a pattern formed from modeling a particular action could only resemble the same pattern executed by the same action. On the same note, the order of comparison of the formed patterns does not matter and two different patterns cannot both be similar to a third one. All these notions are in line with the three properties of identity, symmetry, and triangle inequality mentioned above.
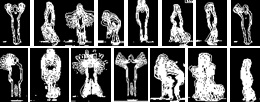
The fourth image in each group shown in Fig. 5 above represents the descriptor for that particular action and is modeled by an individual’s action. The Weizmann database constitutes 9 subjects. An action of one subject is enough to produce a model descriptor that can be used to identify similar actions from the remaining 8 subjects, which are taken to be the test data. Below in Fig. 6 is the extracted descriptor for each of the 8 trained activities.
The descriptors above are stored as templates in the gallery. A new action to be recognized is modeled using the procedure explained above. Classification is done based on the distance as in part B above between the gallery images and the query template presented.
Apart from our own generated data for human actions, we have used the publicly available Weizmann Institute of Science’s human action database [14] to validate our claims. The Weizmann database contains actions from 9 different actors performing 9 actions, among which we have applied our method to most of them. Actions experimented on include bend, jack, jump forward on two legs, jump up in one spot, running, skip forward, one-hand wave, and twohand wave. The video resolution is given and is taken at the speed of 25 fps. Our own generated video dataset (OGD) contains five subjects performing eight different actions of bending, walking, jumping jacks, jumping in place, onehand wave, two-hand wave, jumping in place wave, and running. The videos are taken at 15 frames per second. Each frame is of the size 320 × 240, with images of 24 bit RGB. The videos are also available in binary form as we have applied binarization for background removal.
We have extracted the silhouettes based on the background subtraction method. The number of key frames used was limited to 20, which was enough to describe a full cycle of an event, considering the speed of the video. The performance was comparable to other methods that used different descriptors for action representation. One such method is our own [15], which used additional shape context for fine selection of key postures. [16] used a global histogram to describe the extracted rectangles from the human silhouette with a claim of a 100% recognition rate [17]. Two main assumptions apply in both databases used: the viewing direction is fixed and the background static. The restrictions contributed to the efficient extraction of the human body silhouette-edges, thereby enhancing the recognition. The Hausdorff distance performed better with the normalization of images to equal sizes. Actions with varied rotation, translation, and transformation problems were fixed for matching purposes. For example, in the case where running directions were different, the activity was trained independently for exact and fast recognition.
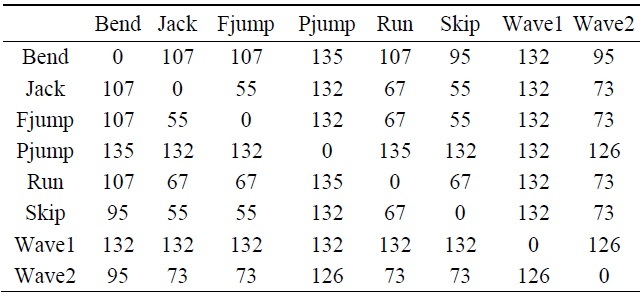
[Table 1.] Hausdorff distances between different models
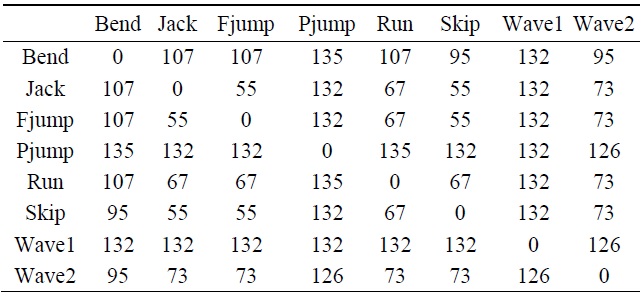
Hausdorff distances between different models
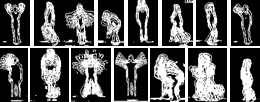
In Fig. 7, we extracted the descriptor for each of the various activities. The descriptor is representative of an action model that can be differentiated one from another.
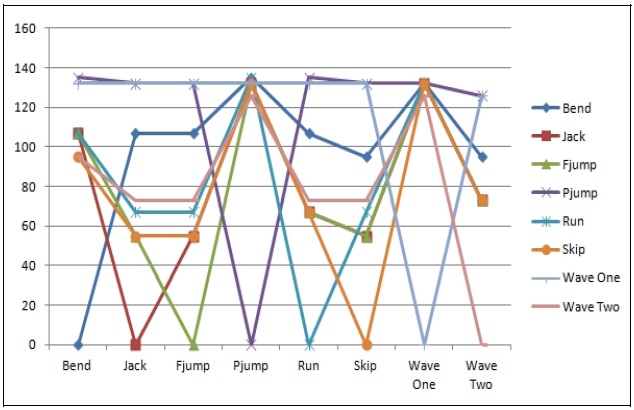
Table 1 shows some of the results of dissimilarity among various action model images by using the Hausdorff distance measure. The Hausdorff distance measure compared the action models by measuring how much difference existed within an action itself and even among other actions. We can check for the explanation of the Hausdorff distance as a dissimilarity measure in Section IIIB. The experiment was done on the Weizmann human action database.
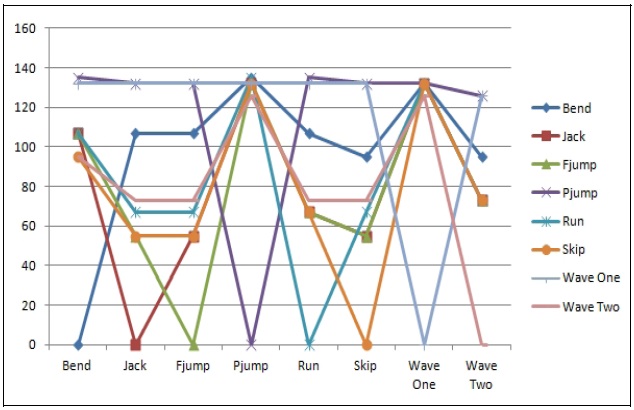
Fig. 8 is an expression of Table 1, which shows a sample experiment on eight actions compared against the rest of the models, where the zero values of the line on the graph indicate that the action was compared against itself and express absolute similarity. Just like with all distance measurement techniques, the smaller the value in between actions, the more similar the images.
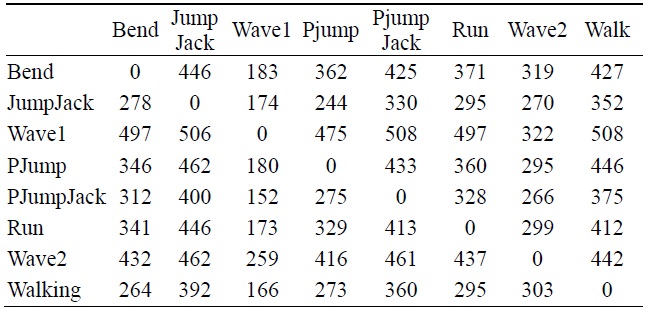
[Table 2.] Hausdorff distance values of OGD
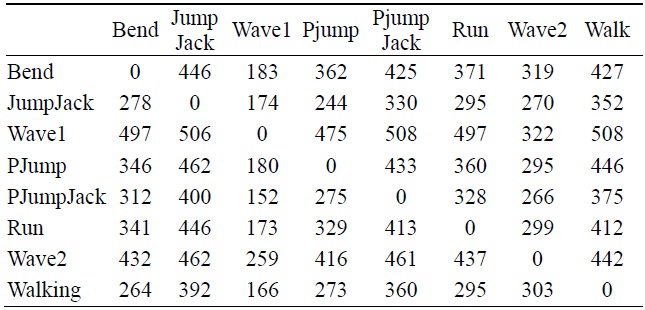
Hausdorff distance values of OGD
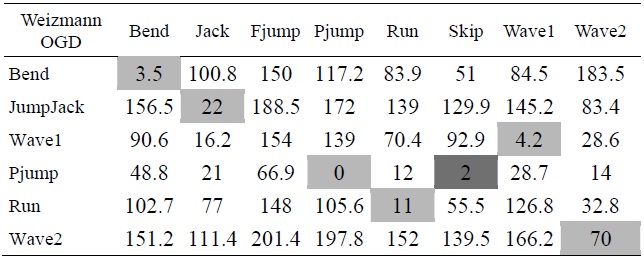
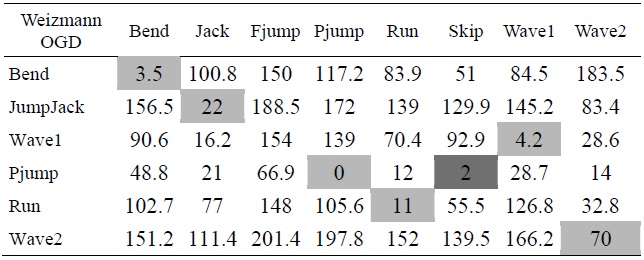
The comparison of trained data between OGD and the Weizmann database using Hausdorff distance
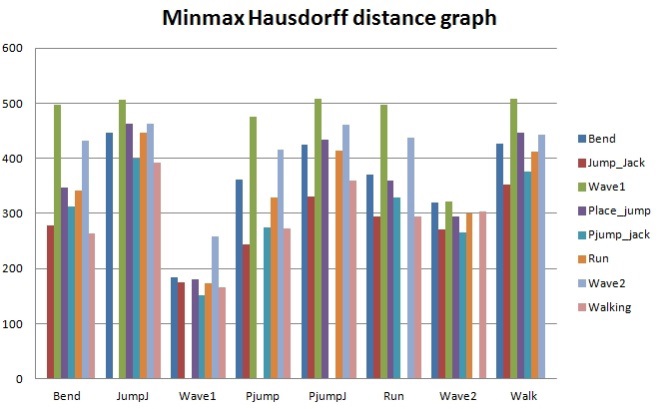
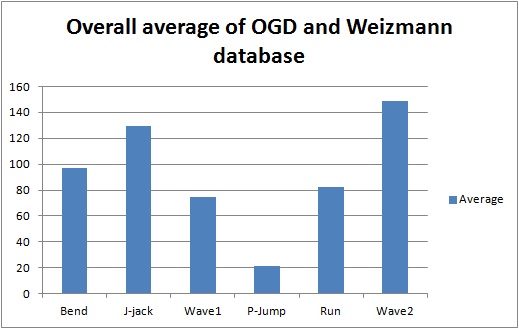
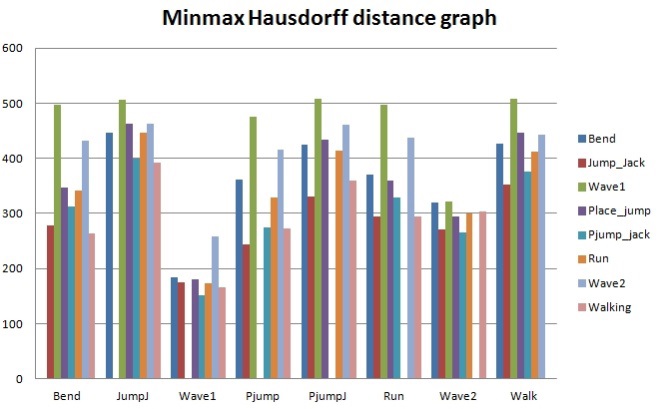
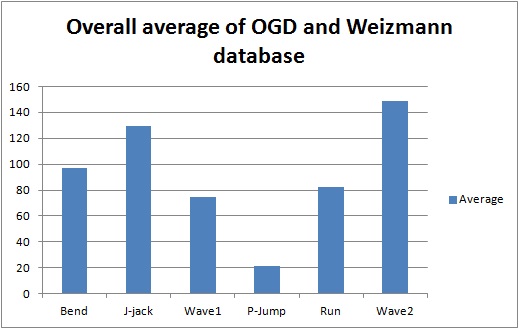
Table 2 indicates the Hausdorff distance value computed between each pair of action as indicated. From these values we have tabulated a general bar graph. Fig. 9 graphs the expressions of the values in Table 2, comparing each labeled action with the other remaining actions. It can be further generalized to produce the following graph in Fig. 10 for clarity. Table 3 is a comparison of some of the actions we took from our own recorded video data (OGD) and one of the benchmark databases, the Weizmann database. The recognition via Hausdorff distance performed fairly well with the distances, as shown in the table. The lower the value, the closer the actions are to each other. The distance values between two inter-databases did not yield zero frequently, except for with the ‘point-jump’ action. The recognition process followed the criteria explained in the proposed algorithm, starting from object identification in videos, to the template modeling. The results exhibited some closeness in particular actions but the smallest distance was still clear. Some actions still presented a similarity challenge, as can be witnessed in the experiment among the ‘point-jump’, ‘skip’, and ‘run’ actions. The Hausdorff distance measure provided a value just significant enough to separate the actions and to let us claim the effectiveness of our proposed method. High classification performance was achieved, empirically.
A graph is shown in Fig. 10 for the cases in which clear differences existed among several actions. In the graph, it is obvious that the difference between the ‘two-hand wave’ and ‘jumping jack’ actions compared to the ‘point-jump’ action revealed the greatest dissimilarity on average. From this particular experiment, ‘run’ and ‘one-hand wave’ actions can be seen to be quite similar to each other.
A simple but powerful image descriptor based on the silhouette boundary extraction is proposed. Fast and efficient representation was achieved through the two steps of information entropy and summed boundary shapes. We managed to model well and represent most of the actions in Weizmann database and from our self-generated human action database. Future work includes more tests on various databases containing complex action-videos with assorted backgrounds. A dynamic matching method and an improved boundary descriptor will improve the classification performance and contribute to this particular research field.