For real-time wireless sensor network applications, it is essential to provide different levels of quality of service (QoS) such as reliability, low latency, and fault-tolerant traffic control. To meet these requirements, an (m,k)-firm based real-time routing protocol has been proposed in our prior work, including a novel local transmission status indicator called local DBP (L_DBP). In this paper, a fault recovery scheme for (m,k)-firm real-time streams is proposed to improve the performance of our prior work, by contributing a delay-aware forwarding candidates selection algorithm for providing restricted redundancy of packets on multipath with bounded delay in case of transmission failure. Each node can utilize the evaluated stream DBP (G_DBP) and L_DBP values as well as the deadline information of packets to dynamically define the forwarding candidate set. Simulation results show that for real-time service, it is possible to achieve both reliability and timeliness in the fault recovery process, which consequently avoids dynamic failure and guarantees meeting the end-to-end QoS requirement.
A wireless sensor network (WSN) is comprised of small devices, known as sensor nodes, with computation, communication, and sensing capabilities as well as various resource constraints [1]. In recent years, the application of the complementary metaloxide semiconductor (CMOS) camera and small microphones in WSNs allows them to gather not only data information but also background multimedia information [2]. However, given the limited resources of nodes, such as memory, energy consumption, CPU performance, and unstable factors of wireless communication, it is much more difficult for WSNs to meet the requirements of such real-time applications than traditional sensing applications, since it must handle the special quality of service (QoS) requirements of real-time multimedia applications as well, such like high reliability and low latency of packet transmission [3]. Therefore, the fault tolerance characteristic is highly necessary for maintaining the robustness of the network, either through hardware or software. In this paper, we focus on the fault tolerance scheme in realtime routing protocols.
Most existing fault tolerance schemes for WSNs implement redundancy to recover packet loss and increase the probability of data delivery. This concept is established based on multiple copies of the same packet that travels through a multipath to the sink. In [1], a multipath-based reliable information forwarding protocol called ReInForM was used to deliver the data at desired levels of reliability to recover failures caused by channel errors. It controls the number of paths required for the desired reliability using only local knowledge of channel error rates and does not require any maintenance of the multipath. However, the forwarding node selection mechanism of ReInForM considers only the required reliability so that it cannot be applied to meet the timeliness requirement of real-time services. In [4], a dynamic jumping real-time fault-tolerant routing protocol (DMRF) was proposed to handle the potential faults of the network such as failure, congestion, and void regions. Each node could use the remaining transmission time of the data packets and the state of the forwarding candidate node set to determine the next hop. It is designed to guarantee the performance of real-time services, although only soft real-time can be satisfied due to its hop-by-hop transmission mode. For some specific applications such as multimedia transmission in WSNs, which requires a firm real-time guarantee, it is not enough to meet the requirements. Moreover, without an end-to-end QoS guarantee, the intermediate nodes cannot adjust the delivery to the real-time performance effectively. SPEED [5] introduced a real-time communication routing protocol which can provide desired delivery speed across the sensor networks through a combination of feedback control and non-deterministic geographic forwarding. However, it also supports only soft real-time transmission since it does not take into account the packet deadline of a real-time stream, which may consequently lead to end-to-end dynamic failure of transmissions.
In our prior work [6], a firm real-time routing protocol was presented to guarantee end-to-end QoS of real-time services, which becomes an issue for [5], using a scheduling policy called distance-based priority (DBP) [7]. This scheduling policy is used to evaluate the QoS performance of real-time streams and to better service them according to their (
The rest of this paper is organized as follows. The proposed scheme is described in Section II. Simulation results are shown in Section III. Section IV concludes the proposed scheme.
The key components of the proposed failure recovery scheme are discussed in this section. Taking advantage of the (
The first metric for end-to-end QoS performance evaluation is G_DBP, which shows the quality of one real-time stream. It is measured at the sink, using the equation in [6].
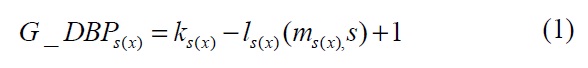
where
The sink periodically sends back the value of
For local transmission status evaluation on the intermediate nodes, we continue using the value of L_DBP, which was proposed in our prior work [5]. Different from G_DBP, the calculation of L_DBP is as follows:
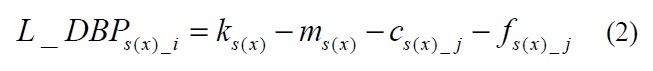
where
By Eq. (2) each node on the transmission path could obtain the information of the real-time status of all traffic passed through it, and also distinguish the causes of network faults as congestion or link failure at the same time. Based on the feedback from the downstream node, the results of
In this paper, using the value of L_DBP, intermediate nodes could calculate the required number of forwarding nodes and then make decisions for the multipath. Details are discussed in the following part.
The principal contribution of this paper is the algorithm used for nodes to choose the optimal forwarding nodes for redundancy on a multipath. Compared with previous fault tolerant schemes or realtime routing protocols, the proposed scheme makes it possible to establish multiple transmission paths with a bounded latency during transmissions. It is guaranteed that all selected nodes for forwarding multiple copies of packets can relay the packets in a timely manner. Due to the features of real-time services, packets loss would lead to not only end-to-end dynamic failures but also the timeout of a certain number of packets. The potential high latency which is involved in the use of a multipath may severely influence the quality of packets received by the sink. Thus, we present a new delay-aware algorithm for dynamically choosing the optimal forwarding nodes, which can guarantee both required reliability and bounded delay, to improve the performance of prior work, and make it more adaptable for real-time services than others. The algorithm can be described in Table 1 as follows.
This algorithm shows how upstream node
This algorithm makes it possible for nodes to establish a multipath in the link failure recovery for real-time services. However, not all nodes in that set are needed in the case of densely employed network such that there may be many candidates available from which to choose. Consequently, a calculation for the forwarding path selection should be done according to the actual situation. Two subsystems in Section II are introduced here for sink-source node and intermediate nodes to make decisions for choosing the optimal number of alternative paths needed for redundancy, from their candidate node set, respectively.
[Table 1.] Algorithm: candidate node selection

Algorithm: candidate node selection
For the source node, the most useful information is the G_DBP value of the stream it generated, as feedback from the sink. Therefore, the adapted number of alternative paths could be calculated using the following equation:
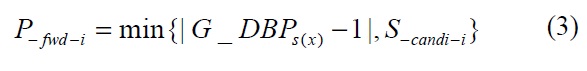
where
This equation can be also used when the source node receives backpressure from its downstream node, which indicates the failures of some links on the primary path and the intermediate nodes have no candidate to choose, so that it is necessary to start using multipath at the source node.
The local system includes all intermediate nodes and the links between them. Since the L_DBP value is the most useful information for the intermediate nodes to evaluate the transmission status, it is used in Eq. (4) for the selection of the optimal number of alternative paths. The equation is as follows:
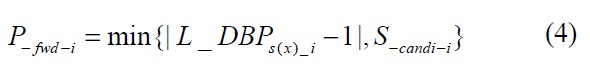
Similar to Eq. (3), the number of forwarding paths is calculated adaptively with respect to the candidate node set and the actual situation.
In case of severe channel errors, or a sparsely employed network, it is possible that once an intermediate node detects link failure on a primary path, it finds no candidates for a multipath itself, so it sends backpressure to its upstream node. Therefore, the backpressure may finally reach the source node, and Eq. (3) would be executed for recovery as mentioned in Section II-A.
Performance of the proposed scheme is proven by simulation. We chose NS-2 as the simulator and a uniform topology that includes 100 nodes in an area of 200 × 200 m. The propagation model is set to be two-ray ground, and the protocols for the physical and medium access control (MAC) layer are set to be wireless-Phy and 802.11, respectively. The radio range is set to be 30 m for nodes to transmit 1,000 bytes packets on the bandwidth of 2 Mb/s.
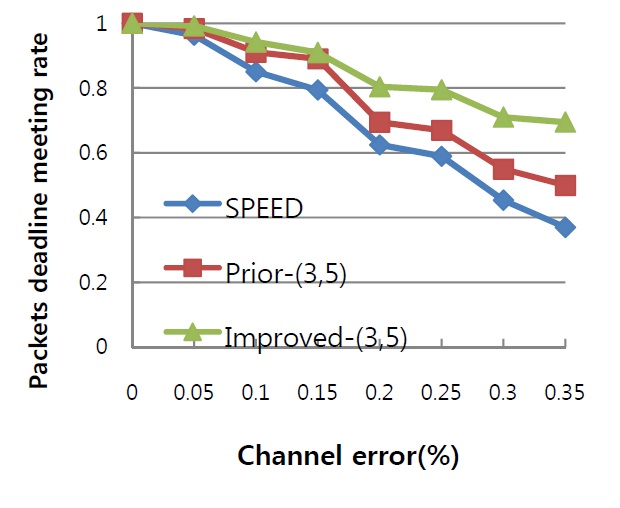
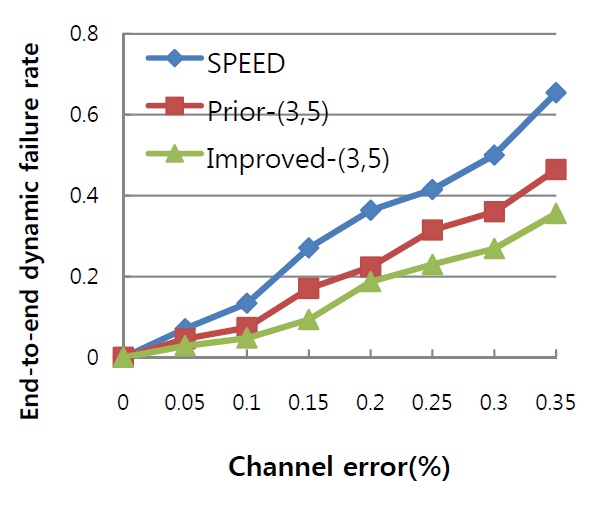
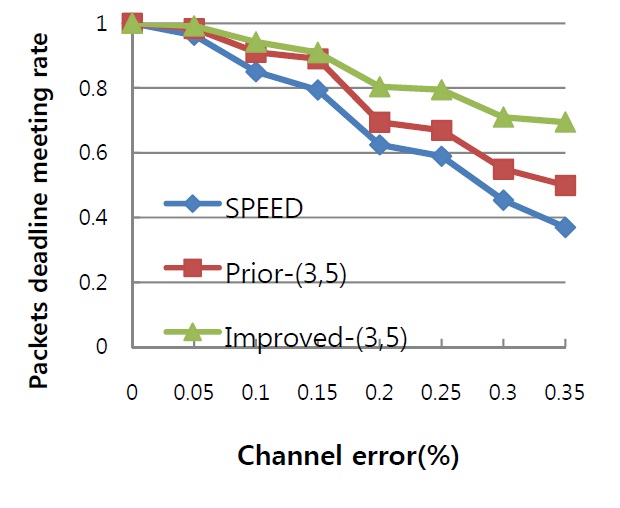
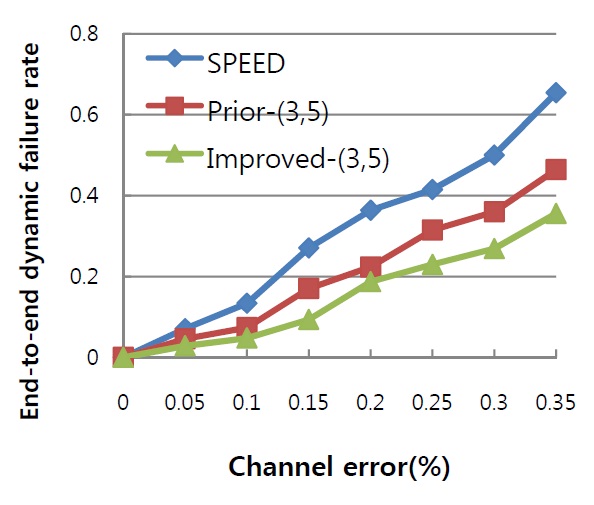
The proposed failure recovery scheme is used to improve the performance of our prior work, so the comparison was carried out with SPEED, our prior algorithm, and improved one. In order that the performance of failure recovery can be shown clearly and distinctly, we did not involve much cross-traffic so that most nodes in network would not suffer from heavy traffic load and its introduced packet loss. Channel error, as the principal cause of link failure in WSNs, is normally distributed across the network and increasing at a proportional speed from 0% to 35%. Simulations show the influence of various channel error rates on both the rate of meeting the packet deadline and the end-to-end dynamic failure rate.
In Fig. 1, as a critical metric for real-time services, the packet deadline meeting rate is measured for all three algorithms. The reason for missing the deadline is considered to be the introduced high latency of failure recovery methods. When link failure has occurred, each algorithm starts up a recovery scheme to handle the problem. For SPEED, backpressure-based feedback is used to inform the upstream node to switch the next hop when the downstream finds no next hop is available; however, there is no method to guarantee the switched node could not choose a path that would not increase the end-to-end delay of transmissions. Fig. 1 shows an obvious decline of the deadline meeting rate of SPEED after the mean channel error rate reached 10%. In the case of our prior work, with the same (
The second simulation (Fig. 2) shows the impact of an increasing channel error to the end-to-end dynamic failure, which includes the verification of both reliability and timeliness, and is considered to be the most important QoS metric. Packet loss caused by link failure would lead to stream dynamic failures as well as packet deadline missing. For SPEED, when packet loss occurs due to link failure, no recovery scheme such as retransmission or redundancy is used to handle it, and the feedback process may not be timely. Our prior work has the same problem as mentioned in the last simulation, that it cannot guarantee the multipath generated for redundancy could meet the timeliness requirement of the stream. Both algorithms lead to a rapidly increasing rate of dynamic failures from the channel error rate of 10%. The curve of the improved algorithm is much smoother than others and indicates a better capability of fault tolerance.
In this paper, a new link failure recovery scheme is proposed for (