A headword finding system is defined as an information retrieval system using a word gloss as a query. We use the gloss as a document in order to implement such a system. Generally the gloss is very short in length and then makes very difficult to find the most proper headword for a given query. To alleviate this problem, we expand the document using the concept of query expansion in information retrieval. In this paper, we use 2 document expansion methods : gloss expansion and similar word expansion. The former is the process of inserting glosses of words,which include in the document, into a seed document. The latter is also the process of inserting similar words into a seed document. We use a featureless clustering algorithm for getting the similar words. The performance (r-inclusion rate) amounts to almost 100% when the queries are word glosses and r is 16, and to 66.9% when the queries are written in person by users.Through several experiments, we have observed that the document expansions are very useful for the headword finding system. In the future, new measures including the r-inclusion rate of our proposed measure are required for performance evaluation of headword finding systems and new evaluation sets are also needed for objective assessment.
표제어 검색시스템은 뜻풀이를 질의로 간주하는 정보검색 시스템이다. 이러한 시스템을 구축하기 위한 가장 간단한 방법으로 사전의 표제어 뜻풀이(사전 뜻풀이)를 문서로 간주하는 정보검색 시스템을 구축하는 것이다. 이 문서의 길이가 너무 짧아 사용자 질의(사용자 뜻풀이)에 대한 적절한 표제어를 검색하기 어렵다. 이 문제를 완화하기 위해서 본 논문에서는 정보검색에서 사용되는 질의 확장 개념을 문서 확장에 적용한다. 본 논문에서는 문서 확장 방법으로는 뜻풀이 확장과 유의어 확장을 사용한다. 뜻풀이 확장은 주어진 단어의 사전 뜻풀이에 속하는 단어의 뜻풀이를 문서에 포함시키는 방법이고, 유의어 확장은 무자질 군집화 알고리즘을 통해서 유의어를 찾고, 찾아진 유의어를 문서에 포함시키는 방법이다. 제안된 표제어 검색시스템은 사전 뜻풀이 그 자체를 입력으로 할 때, 16-포함률이 거의 100%에 달하였다. 또한 사용자 뜻풀이를 입력으로 할 때, 20-포함률이 66.9%였다. 사용자 뜻풀이가 단어의 의미를 충분히 전달할 수 없는 것으로 관찰되었으며 앞으로 정확하고 객관적인 평가를 위해서 평가 집합에 대한 연구가 추가적으로 필요한 실정이다.
단어 검색(word retrieval or word finding) 이라는 용어는 의학 분야에서 기억언어상실증(dysnomia)이나 실어증(aphasia) 등의 연구에 널리 사용되어 왔으며 생각의 표현하거나 물체의 이름을 말하는 데 필요한 단어를 찾아내는 과정으로 정의하고 있다(German 2000;Wise et al. 1991). 그러나 정보기술 분야에서는 다소 생소한 용어이나 최근 정보검색 등의 기술이 발전하면서 정보검색 분야에서도 그 필요성이 대두되고 있다. 예를 들어 ‘낱말 맞추기놀이’(crosswords puzzle)를 생각해보자. 이놀이는 단어에 대한 설명을 통해서 원하는 단어를 찾아 지정된 칸을 채우는 놀이이다. 이 밖에도 여러 가지 형태의 창작 활동에 매우 다양한 형식으로 사용될 수 있을 것이다. 본 논문에서는 이와 같이 단어의 뜻이 주어졌을 때, 그뜻에 해당하는 사전 표제어를 찾는 시스템을 제안하고자 한다. 즉, “자기의 잘못을 인정하고 용서를 빎”이라는 질의어를 입력하면 ‘사과’라는 표제어를 찾아주는 시스템이다. 본 논문에서는 다른 영역에서 사용되는 단어 검색(word retrieval)이라는 용어와 혼란을 피하기 위해 표제어 검색(headword retrieval)이라고 한다.
단어의 뜻풀이를 문서(document)로 간주하면 표제어 검색시스템(headword retrieval system)은 문서검색시스템(document retrieval system)이다. 이와 같은 문서검색시스템은 몇가지 문제를 가지고 있다. 첫째, 뜻풀이(문서)의 길이가 너무 짧다(박은진, 김재훈, 옥철영2005). 사전의 뜻풀이는 일반적으로 10어절을넘지 않을 정도로 매우 짧게 기술되어 있다. 둘째, 뜻풀이는 매우 함축적이다. 예를 들면 ‘개’(dog)에 대한 뜻풀이는 “<동물>갯과의 포유류”이며, ‘포유류’는 젖을 먹이는 동물이라는 의미를 내포하고 있다. 셋째, 모든 문서가 서로 독립이 아니다. 예를 들면 ‘여가수’의 뜻풀이는 “여자 가수”이고 ‘가수’의 뜻풀이는 “노래 부르는 것이 직업인 사람”이며, ‘사람’의 뜻풀이는 “생각을 하고 언어를 사용하며, 도구를 만들어쓰고, 사회를 이루어 사는 동물”이다. 이처럼 ‘여가수’ < ‘가수’ < ‘사람’ < ‘동물’과 같은 계층을 가지고 있어 어떤 단어의 완전한 의미를 파악하기 위해서는 이 계층의 의미를 충분히 파악되어야 한다. 이는 일반적인 문서검색시스템에서 문서 간에는 서로 독립이라는 가정을 그대로 적용할 수 없다. 이와 같은 뜻풀이 문서의 특성은 사용자(일반인)의 단어 뜻풀이와는 아주 다르다. 예를 들면 ‘개’(dog)라는 단어에 대해서 사전의 뜻풀이는 ‘갯과의 포유류’인데 일반 사용자는 거의 이와 같은 질의를 하지 않을것이다. 본 논문에서는 이와 같은 문제를 완화하기 위해서 정보검색에서 사용되는 질의 확장개념(query expansion)(Baeza-Yates and Ribeiro-Neto 1999)을 이용한다. 문서 확장 방법을 이용하면 위에서 제기한 첫 번째 문제인문서 길이 문제를 해결할 수 있다.
본 논문에서 문서 확장 방법으로 뜻풀이 확장(gloss expansion)과 유의어 확장(synonym expansion)을 이용한다. 뜻풀이 확장은 단어의 뜻풀이에 속하는 단어의 뜻풀이를 다시 문서에 포함시키는 방법이며 이를 통해서 위에서제기한 의미 함축성과 뜻풀이 의존성 문제를 다소 완화할 수 있을 것으로 생각한다. 유의어 확장은 무자질 군집화(featureless clustering) 알고리즘(Wong, Liu, and Bennamoun 2009)을 이용한다. 이와 같은 방법으로 확장된 문서와 특정 단어에 대해서 길게 풀어서 설명한 정의나 의미로 주어지는 사용자의 질의와의 유사도를 계산하여 표제어를 검색한다.
본 논문의 구성은 다음과 같다. 2장에서는 관련연구에 대해 간략히 기술하고, 3장에서는 시스템의 전체 구조와 문서 확장 방법을 자세히 설명하고 4장에서 제안된 표제어 검색시스템에 대한 성능을 평가하고 분석한다. 마지막으로 6장에서는 결론을 맺고 향후 연구 방향에 대해서 기술한다.
질의 확장은 검색 모델에 따라 다소 차이가 있지만 일반적으로 사용자 질의에 검색 성능을 개선하기 위해 질의 용어를 추가하는 방법이다(Baeza-Yates and Ribeiro-Neto 1999). 구체적인 방법으로는 시소러스와 같은 정보를 이용해서 확장하는 전역적 질의 확장 방법과 적합성 피드백과 같은 기술을 이용하는 지역적 질의 확장 방법이 있다. 전역적 질의 확장 방법은 초기 사용자 질의의 검색 결과와는 관계없이 시소러스와 같은 범용 지식을 이용해서 유의어나 상위어 등과 같은 용어를 질의에 포함시키는 방법이다. 본 논문에서는 유의어 확장이 이 방법에 속한다고 볼 수 있다. 지역적질의 확장 방법은 초기 검색 결과를 이용해서 적합성 피드백을 이용하는 방법이 주로 사용되며, 본 논문에서는 뜻풀이 확장이 이 개념을이용한 것이다.
군집화(clustering)는 유사한 성향이나 패턴을 가지는 자료를 한 곳으로 모으는 것이다 (Jain, Murty and Flynn 1999). 군집화를 위해서는 먼저 각 자료들 간의 유사도를 계산하여 유사도가 가까운 자료들을 하나의 군집으로 간주하는 것이다. 군집화에는 그 대상에 따라문서 군집화(Andrews and Fox 2007), 단어군집화(박은진, 김재훈, 옥철영 2005; Hodgel and Austin 2002) 등 다양한 방법들이 있다. 문서의 경우 일반적으로 각 문서를 구성하고있는 단어들이 비슷하다면 문서가 유사하다고 말할 수 있으며 이 단어를 자질(feature)라고한다. 단어의 경우에는 문서의 경우와 많은 차이를 보인다. 왜냐 하면 단어 그 자체에는 문자이외에는 특별한 자질이 없으며 문자 그 자체만으로 어떤 두 단어의 의미 유사도를 측정할수 없다. 본 절에서는 단어와 같이 그 자체에서 자질을 찾을 수 없어서 어떤 형식으로 자질을 수집하여 그 유사도를 측정하는 군집화를 무자질 군집화(featureless clustering)라고 한다(Wong, Liu and Bennamoun 2007; Wong,Liu and Bennamoun 2009).
2.2.1 무자질 군집화를 위한 유사도 측정
단어의 무자질 군집화를 위한 유사도 측정 방법에는 여러 가지가 있지만 이 절에서는 NGD(Normalised Google Distance)(Cilibrasi and Vitanyi 2007)와 noW(no of Wikipedia) (Wong, Liu and Bennamoun 2007)에 대해서 간략히 기술한다.
NGD는 구글에서 검색되는 페이지의 수를 이용해서 두 단어 사이의 유사도를 계산하며, 식 (1)과 같이 정의된다(Cilibrasi and Vitanyi 2007).
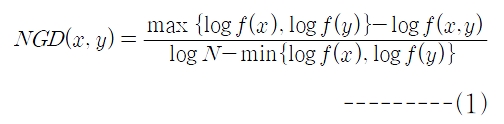
여기서
noW은 그래프 구조를 가진 위키피디아를 이용하는 방법이다. 위키피디아는 사전과 비슷하게 각 단어를 설명하는 하나의 문서가 있다. 이 문서는 개념 구조에 해단하는 “Categories”를 포함하고 있으며 이를 통해서 각 단어는 서로 연결되어 있다. 따라서 위키피디아는 마치 Categories를 통해서 서로 연결된 거대한 그래프(graph)와 같다. 유사한 문서일수록 같은 Categories에 있을 가능성이 높다. 이러한 점을 이용하여 두 단어 사이의 유사도를 계산하며 식 (2)와 같이 정의된다(Wong, Liu and Bennamoun 2007).
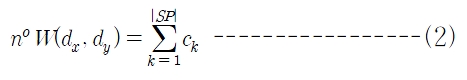
여기서
2.2.2 무자질 군집화 알고리즘: TTA(Tree-Traversing Ants)
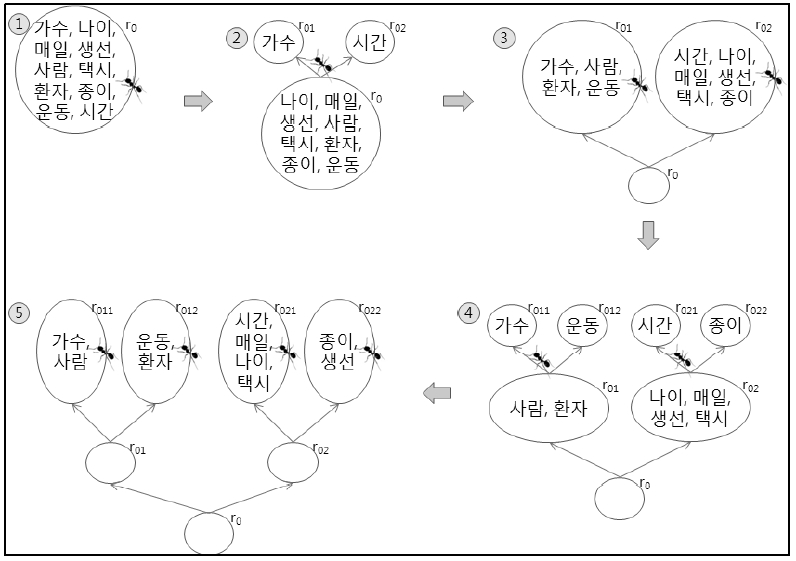
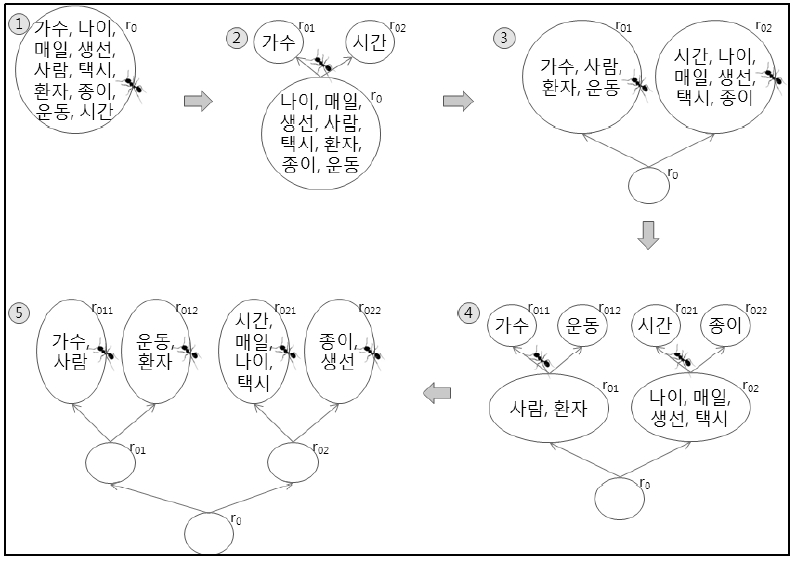
본 논문에서는 무자질 군집화 알고리즘으로 3-Pass-TTA 알고리즘(Wong, Liu and Bennamoun 2007)을 수정하여 이용한다. 3-Pass-TTA 알고리즘은 TTA(Tree-Traversing Ants) 알고리즘(Handl, Knowles and Dorigo 2003)을 개선한 것이다. 먼저 TTA(Tree-Traversing Ants) 알고리즘에 대해서 살펴보자. TTA 알고리즘은 격자형태의 그래프 위에 군집하고자 하는 대상들을 임의로 올려놓고, 개미들이 지나다니며 유사한 것들끼리 모아가는 개념이다. 개미는 크게 세 종류의 일(pick-up, move, drop)을 수행한다. <그림 1>은 TTA 알고리즘의 동작 원리를 보여주고 있다.
<그림 1>은 10개의 단어에 대한 군집화 과정으로 보이고 있으며, 여기서 사용된 유사도는 모두 임의로 가정된 것이다. 처음에 정점
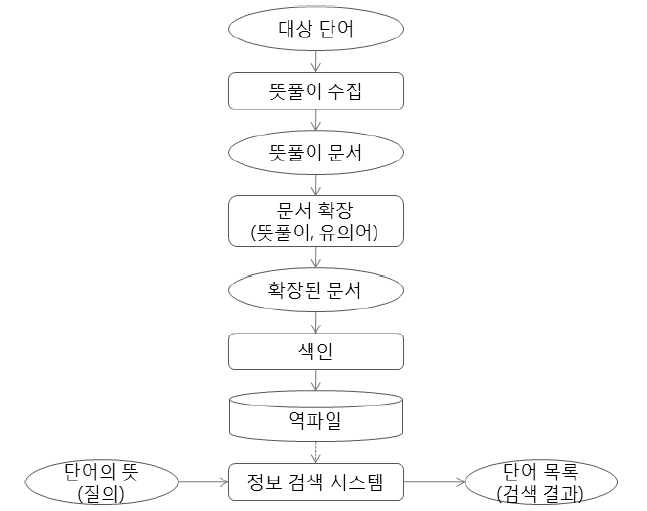
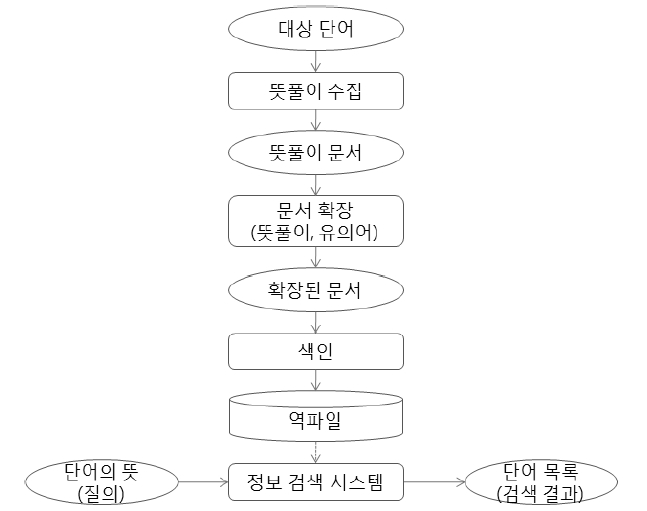
본 논문에서 제안된 표제어 검색시스템은 기본적으로 정보검색 시스템을 기초하고 있다. 문서는 일반 사전에 있는 단어 뜻풀이이며, 질의는 사용자 단어 뜻풀이이다. 앞에서 언급했듯이 사전 뜻풀이는 그 길이가 너무 짧고 함축적이어서 그대로 사용할 수 없다. 본 논문에서 질의 확장 개념을 문서에 적용하여 이 문제를 완화시키고자 한다. 본 논문에서 사용하는 문서 확장 방법으로 사전을 이용한 뜻풀이 확장(gloss expansion)과 단어 군집화를 이용한 유의어 확장(synonym expansion)을 사용한다. 뜻풀이 확장은 단어의 뜻풀이에 속하는 단어의 뜻풀이를 다시 문서에 포함시키는 방법이며 이를 통해서 앞에서 언급한 의미 함축성과 뜻풀이 의존성 문제를 다소 완화할 수 있을 것으로 판단한다. 유의어 확장은 무자질 군집화(featureless clustering) 알고리즘(Wong, Liu,and Bennamoun 2009)을 이용한다. 이와 같은 방법으로 확장된 문서와 특정 단어에 대해서 길게 풀어서 설명한 정의나 의미로 주어지는 사용자 질의와의 유사도를 계산하여 표제어를 검색한다. <그림 2>는 전체 시스템 구조이다. <그림 2>에서 대상 단어는 Naver와 Daum의 사전에 포함된 519,109개 단어를 선정하여 이들 단어의 뜻풀이를 기본 문서로 간주한다. 기본 문서는 여러 가지 문서 확장 방법을 통해서 문서를 확장하여 역파일(inverted file)을 구축하여 정보검색 시스템을 구축한다.
본 논문에서 정보검색 모델은 벡터 모델
(vector model)을 사용하며, 질의-문서 간 유사도(query-document similarity)는 가장 일반적으로 사용하는 코사인 유사도(cosine similarity)를 사용한다. 가중치는 TF-IDF 모형을 사용하며 TF(term frequency)는 일반적인 정보검색과 달리 경험적인 방법으로 결정되며 IDF(inverse document frequency)는 일반적인 정보검색에 사용하는 방법으로 그대로 사용한다. 색인 방법은 형태소 분석기를 이용하며 이 형태소 분석기는 세종 말뭉치(국립국어원 2007)와 CRF(Con-ditional Random Field)(CRFPP 2011)를 이용해서 구현되었다. 이 형태소 분석기는 동사의복원이나 준말의 복원을 실행하지 않으며 실험말뭉치에 대해서 98.1%의 성능을 보였다.
앞에서 언급했듯이 표제어 검색시스템의 기본 문서(basic document)는 사전 뜻풀이이다. 대상 단어의 뜻풀이는 인터넷에 공개된 사전(Naver와 Daum)을 이용하여 수집한다. 본 논문에서는 Naver와 Daum의 사전 openAPI를 이용하여 대상 단어의 뜻풀이를 수집하였다.
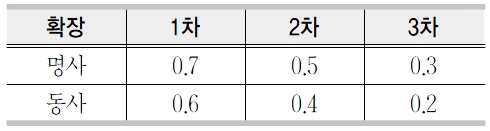
이 절에서는 3.1절에서 수집된 기본 문서(뜻풀이)를 재귀적으로 확장하는 방법에 대해서 기술한다. 재귀적 확장은 3회로 제한한다. 예를 들면 대상 표제어 ‘사과’의 기본 문서는 “자기의 잘못을 인정하고 용서를 빎”이며 형태소분석을 통해서 문서를 확장한다. 여기서 확장된 표제어와 가중치는 {(자기, 0.7), (잘못, 0.7), (인정하다, 0.6), (용서, 0.7), (빌다, 0.6)}이며 이를 1차 확장이라고 한다. 가중치 부여 방법은 <표 1>과 같다. 확장 차수가 높을수록 원문서와는 거리가 멀어지므로 가중치를 낮게 설정하였고 동사보다는 명사가 정보검색에서 더중요한 역할을 하므로(강현규, 박세영 1998)높은 가중치를 부여하였다. 그러나 이 가중치들은 경험적으로 주어진 것이며 최적화를 위해서는 더 많은 연구가 필요한 실정이다.
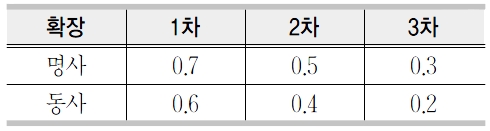
색인어의 가중치 부여 방법
2차 확장은 1차 확장으로 기본 문서에 포함된 각 단어의 뜻풀이를 기본 문서에 다시 추가한다. 예를 들면 ‘자기’의 뜻풀이 문서는 “그 사람 자신”이므로 기본 문서에 {‘사람’, ‘자신’}이 추가되고, ‘잘못’의 뜻풀이 문서가 “잘하지 못하여 그릇되게 한 일”이므로 기본 문서에 {‘잘하다’, ‘못하다’, ‘그릇되다’, ‘하다’, ‘일’}이 다시 추가된다. 이와 같은 과정으로 ‘인정하다’, ‘용서’, ‘빌다’에 대해서 적용하면 <그림 3>과 같은확장 문서를 얻을 수 있다.
<그림 3>에서 기울임체(italic font)는 1차 확장에서 포함된 단어이고 밑줄(underline)로 표시된 단어는 2번 혹은 그 이상 출현되어 그 가중치를 합한 단어들이다. 이와 같은 방법으로 3차 확장을 통해서 최종 확장 문서가 결정된다.
이 절에서는 검색 대상 단어에 대한 단어 군집화를 유의어 단어를 추출하고 추출된 유의어를 이용해서 기본 문서의 확장 방법을 기술한다. 본 논문에서는 기본적으로는 2.3절에서 설명한 3-Pass-TTA 알고리즘을 개선한 (Wong, Liu and Bennamoun 2007)을 그대로 사용하였다. 그러나 본 논문에서 많은 단어를 대상으로 군집화하므로 이 알고리즘을 그대로 구현할 수 없었다. 많은 단어를 대상으로 알고리즘으로 수행할 수 있도록 알고리즘을 일부 개선하였으며 그 결과는 <알고리즘 1>과 같다.
<알고리즘 1>의 알고리즘 antClustering( )는 먼저 3-Pass-TTA 알고리즘에서와 같이 antTraverse(<알고리즘 2>)를 호출하여 기본적인 단어 군집
[알고리즘 1] <알고리즘 1> 개선된 3-Pass-TTA 알고리즘: antClustering

<알고리즘 1> 개선된 3-Pass-TTA 알고리즘: antClustering
[알고리즘 2] <알고리즘 2> 개선된 3Path-TTA 알고리즘의 antTraverse( )

<알고리즘 2> 개선된 3Path-TTA 알고리즘의 antTraverse( )
<알고리즘 2>의 antTraverse( )는 하향식 방법(top-down approach)으로 하나의 군집을 두 군집으로 재귀적으로 분리하며 군집 내유사도(intra-cluster similarity)가 ?보다 클때까지 재귀적으로 반복해서 분리한다. 단어를 각 군집에 분배하는 방법은
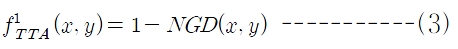
여기서
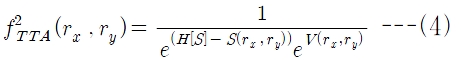
여기서
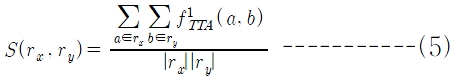
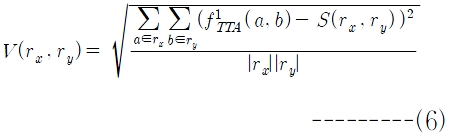
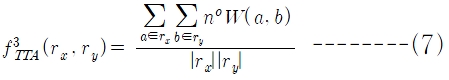
정보검색 시스템을 위한 성능 평가 방법으로는 정확률(precision)과 재현율(recall)이 널리 사용되나(Baeza-Yates and Riberio-Neto 1999), 표제어 검색시스템에 대한 연구는 거의 이루어지지 않았으며 성능 평가 방법도 특별히 제안되지 않았다. 본 논문에서 표제어 검색 시스템의 성능을 평가하기 위해 새로운 평가측도로
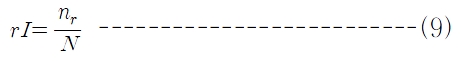
여기서
제안된 표제어 검색시스템을 평가하기 위해 두 가지 실험을 수행한다. 첫 번째 실험은 각표제어에 대해서 사전의 뜻풀이를 표제어 검색시스템의 질의로 사용한 경우이고, 또 다른 실험은 사용자 5명에 의해서 직접 작성된 표제어의 뜻풀이를 질의로 사용한 경우이다.
이 절에서는 표제어의 사전 뜻풀이를 입력하여 그 표제어가 얼마나 정확하게 검색되는지를 평가한다. 실험 대상 표제어는 수집된 모
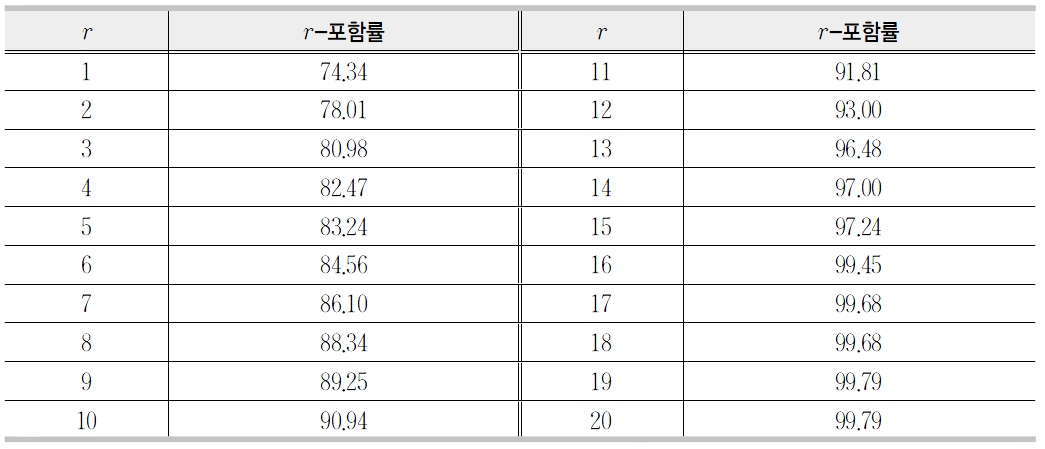
사전 뜻풀이를 이용한 시스템 성능 평가
든 표제어를 그대로 사용하였으며 총 표제어수
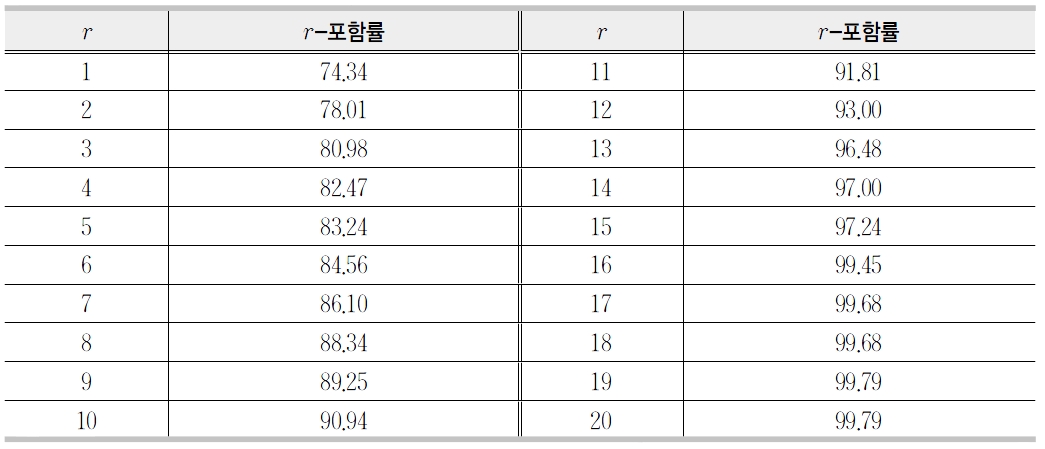
<표 2>에서 보는 바와 같이 1-포함률은 약74%이다. 이는 단어의 뜻풀이를 질의로 사용할 경우에 약 74%가 1위로 검색됨을 의미한다.
4.2.1 실험 대상 단어 선정 및 사용자 뜻풀이 구축
실험 대상 단어는 국립국어원이 2004년에 발표한 외국인을 위한 한국어 학습용 기본 어휘 6,000단어 중 A등급의 명사류 단어 200개
사용자 뜻풀이에 선정된 200개의 단어
를 무작위로 추출하여 단어를 선정하였다(<표3> 참조). 선정된 200개의 단어에 대해서 5명의 연구원(대학생)에게 각 단어의 뜻풀이를 작성하여 1000개의 사용자 뜻풀이를 수집하였다. <표 4>는 사용자 1이 작성한 200개 단어 중에서 40개의 사용자 뜻풀이를 보여주고 있다.

사용자 뜻풀이에 선정된 200개의 단어
4.2.2 문서 확장 방법에 대한 성능평가: r-포함률
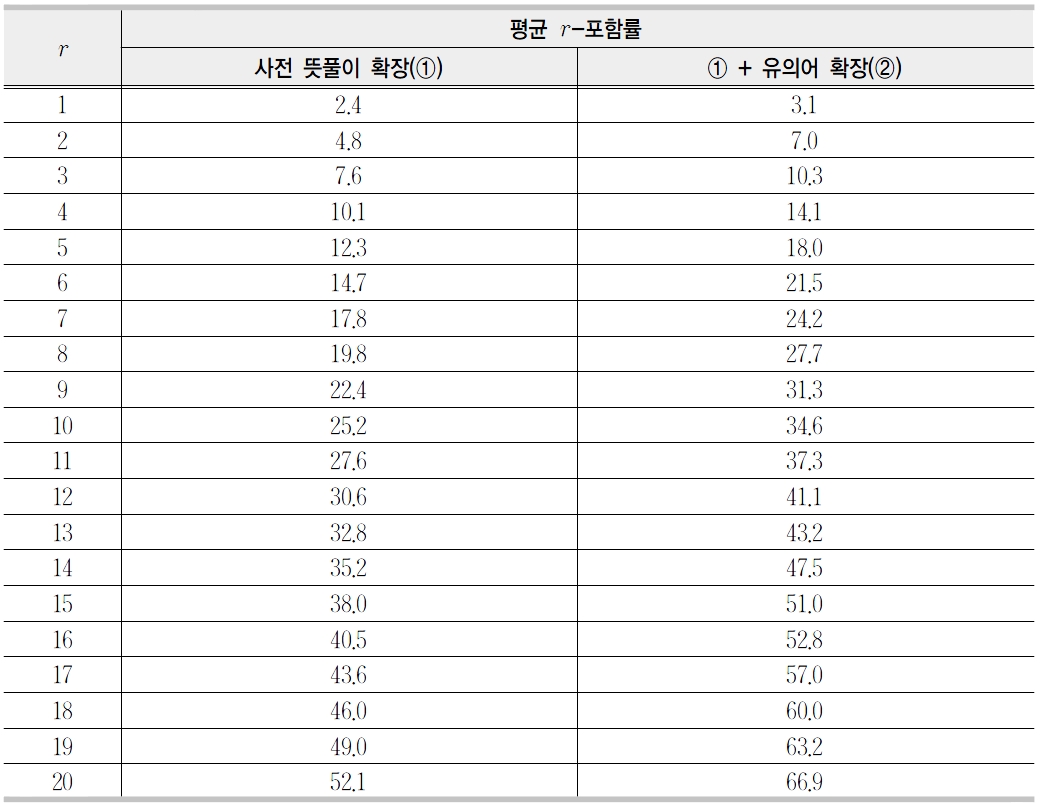
<표 3>은 앞에서 구축된 1,000개의 사용자 뜻풀이에 대해서 평균
[표 5] 문서 확장에 따른 성능 평가(평균 r-포함률)
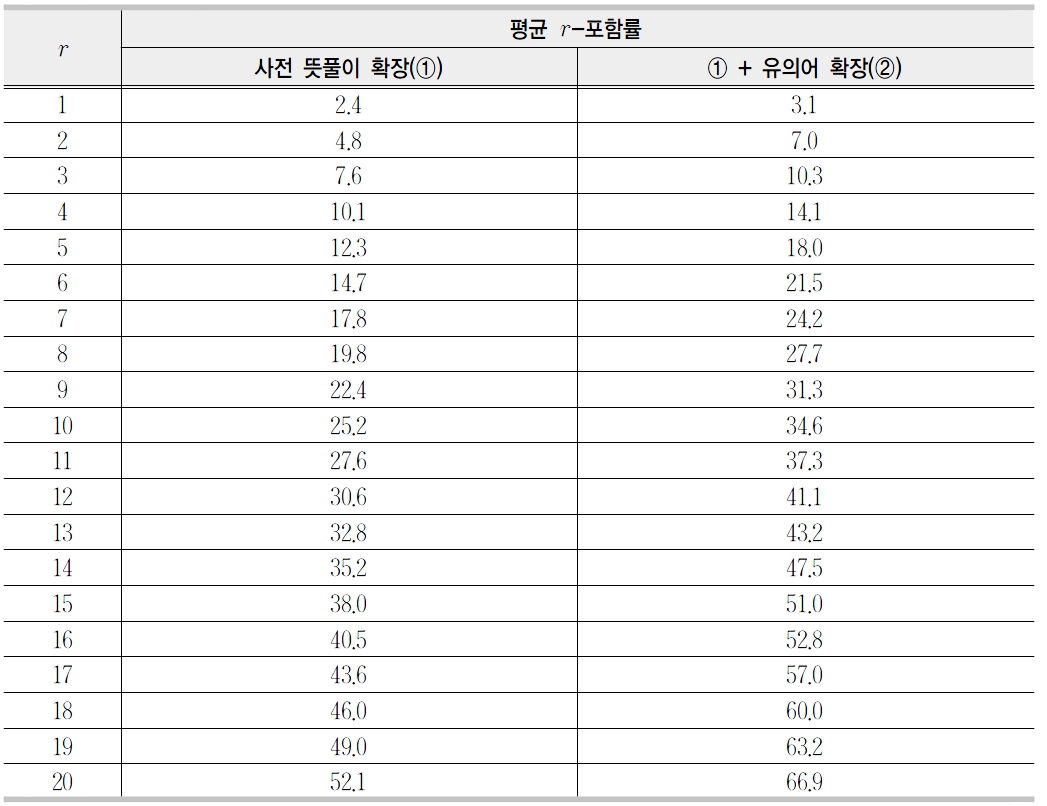
문서 확장에 따른 성능 평가(평균 r-포함률)
이용한 유의어 확장(②)을 추가했을 경우, 20-포함률이 14.8% 증가한 66.9%를 보였다. 이는 사전 뜻풀이의 성능에 비하면 매우 낮은 결과이고 사전 뜻풀이의 1
제안된 표제어 검색시스템의 성능은 20-포함률이 약 67%이다. 이는 아직도 더 많은 연구가 진행되어야 함을 암시하고 있다. 먼저 객관적인 평가를 위한 평가 집합(evaluation set)이 절실히 필요하다. 본 연구에서 사용한 평가 집합은 많은 경우에 제3자는 이해할 수 없는 뜻풀이들이 종종 보인다. 예를 들면 <표 4>에서 ‘건물’을 “높게 지어 올리는 것. 빌딩”이라는 뜻풀이를 사용한다. 이 뜻풀이로 표제어 ‘건물’을 바로 찾기는 쉽지 않다. 또한 초기 문서로 사전의단어 뜻풀이를 사용하는 것이 올바른 방법인지도 한번쯤 생각해보아야 할 것이다.
4.2.3 문서 확장 방법에 대한 성능평가: MRR
만약 사용자 뜻풀이를 질의/응답 시스템의 사용자 질의로 간주하면 질의/응답 시스템어서 가장 일반적으로 사용되는 평균역순위(mean reciprocal rank)(Voorhees 1999)를 사용할수도 있을 것이다(식 (8)).
여기서
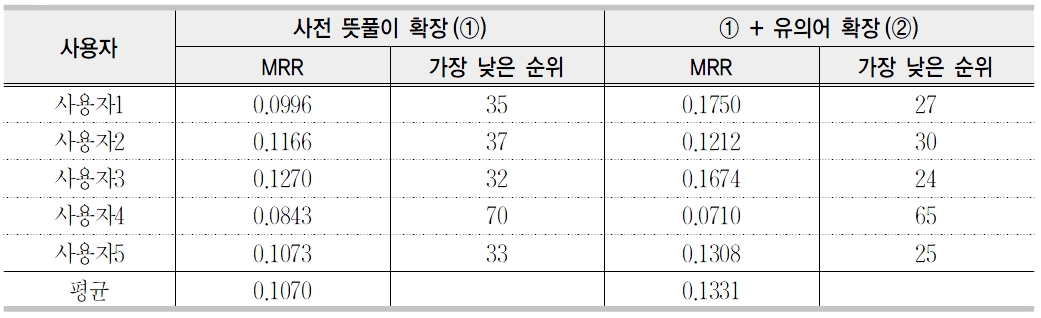
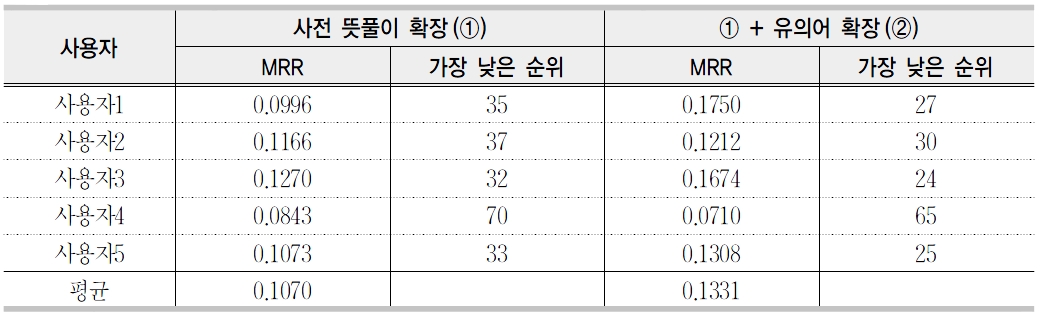
문서 확장에 따른 성능 평가(MRR)
는 의미하며 1위에 가까우면 가까울수록 좋은 시스템이다. <표 6>은 사용자 뜻풀이에 대한 MRR의 성능을 보이고 있다. 사용자 뜻풀이 확장의 경우 MRR이 0.11이고, 유의어 확장을 포함하면 0.13이다. 이 성능은 객관적으로 얼마나 좋은 결과인지를 비교하기 매우 어렵다. 왜냐하면 공개된 평가 집합을 찾을 수 없어서 객관적인 평가를 수행할 수 없었고 또 다른 표제어 검색시스템이 존재하지 않기 때문이다.
유의어 확장을 포함할 경우 대부분의 경우 성능이 개선되었으나 사용자4의 경우 MRR이 오히려 떨어지는 현상이 나타났다. 이는 사용자 뜻풀이가 사전 뜻풀이와 너무 큰 차이를 보이므로 이와 같은 현상이 나타났다. <표 4>에서 ‘갈비’에 대한 사용자 뜻풀이가 “고기 중에가장 비싼 것”이나 사전 뜻풀이는 “소나 돼지, 닭 따위의 가슴통을 이루는 좌우 열두 개의 굽은 뼈와 살을 식용으로 이르는 말”이다. 이 두뜻풀이가 너무나 큰 차이를 보이고 있다. 그 밖에도 많은 단어에 대한 사용자 뜻풀이를 살펴보면 개인적이고 일반적이지 못한 문제가 있다. 향후에 이점을 개선하기 위해 좀 더 질 좋은 사용자 뜻풀이를 수집하여 할 것이며 표제어 검색시스템으로 보다 객관적인 평가를 위한 평가 집합을 구축하는 연구도 아울러 진행되어야 할 것으로 생각된다.
본 논문은 정보검색 기술을 이용한 표제어 검색시스템을 제안하였다. 제안된 표제어 검색 시스템은 일반적인 사전 시스템과는 정반대의 개념으로 단어의 정의나 의미가 입력으로 주어질 때, 그 정의나 의미에 가장 적절한 단어를 검색하는 시스템이다. 이러한 시스템을 구축하기 위한 가장 간단한 방법으로 사전의 뜻풀이를 문서로 간주하는 정보검색 시스템을 생각할수 있다. 이 경우 문서(사전 뜻풀이)의 길이가너무 짧아 사용자 질의에 대해 적절한 단어를 검색할 수 없다. 이 문제를 해결하기 위해서 본 논문에서는 정보검색에서 사용되는 질의 확장(query expansion) 개념을 이용한다. 즉 정보검색에서 질의 확장 개념을 표제어 검색시스템에서 문서 확장에 적용하였다. 본 논문에서는 문서 확장 방법으로는 사전을 이용한 뜻풀이 확장(glossary expansion)과 단어 군집화를 이용한 유의어 확장(similar word expansion)을 사용했다. 뜻풀이 확장은 주어진 단어의 뜻풀이에 속하는 단어의 뜻을 문서에 포함시키는 방법이며 본 논문에서는 3단계까지만 확장했다. 유의어 확장은 무자질 군집화 알고리즘을 통해서 유의어를 찾고, 찾아진 유의어를 문서에포함시키는 방법이다. 이와 같이 다양한 방법으로 확장된 문서와 사용자의 질의(특정 단어에대해서 길게 풀어서 설명한 정의나 의미)의 유사도를 계산하여 단어를 검색한다. 이와 같은방법으로 구현된 시스템은 단어의 뜻풀이 그 자체를 입력으로 할 때, 16-포함률이 거의 100%에 달하였다. 또한 사용자들이 직접 작성한 뜻풀이에 대해서는 20-포함률이 71.4%였으나 사용자 본인들의 정말로 필요에 의해서 뜻풀이를 작성한다면 더 좋은 성능을 보일 수 있을 것으로 생각된다.
본 논문에서 제안된 표제어 검색시스템의 검색 시간은 매우 빠르다. 그러나 새로운 단어가 새로 추가하기 위해서는 많은 노력이 필요하다는 단점이 있다. 앞으로 이러한 문제를 개선하기 위한 연구가 더 필요할 것으로 생각되며 정확한 성능 평가를 위한 평가 측도와 객관적인 평가를 위한 평가 집합(evaluation set)에 대한 연구도 필요할 것이다. 또한 문서를 확장할 때 의미 분석을 통해서 유의어 외에 반의어도 확장된다면 조금 더 높은 성능을 보일 수 있을 것이다.