In the field of noise processing, background noise is one of the important research problems. In particular, it has been noted that system reliability, and especially the speech recognition ratio, can be significantly decreased by background noise [1, 2]. Background noise includes various non-stationary noises existing in the real environment such as street noise and babble noise. Thus, typical background noises cannot be simply eliminated with a Wiener filter or spectral subtraction, but require more skillful techniques. Therefore, to solve the above-mentioned problems, this paper proposes a speech processing system using an auditory system and noise reduction neural network that is effective in various noisy environments.
Several noise suppression and speech processing methods have been proposed, such as spectral subtraction [3-5], neural networks [6, 7], minimum mean-square error estimators [1, 8, 9], and a time-delay neural network [10]. The spectral subtraction method is used in signal processing to process speech adaptively according to the noise intensity, thereby enhancing the performance. For instance, in a study by Lim et al. [4], speech intelligibility was improved when choosing four different lengths of filter for the pitch period according to four different input signal-to-noise ratios (SNRs). In this paper, the parameters of lateral inhibition function are adjusted frame by frame. For details, the parameters are used to adjust the width and amplitude of the lateral inhibition filter at each frame, respectively [10, 11].
Recently, developments of auditory processing systems have been reported in various studies imitating functions of signal processing in auditory processing systems [10-12], and one of these auditory mechanisms, called lateral inhibition, is used as the speech processing system in this paper. In the area of speech signal processing, a neural network (NN) is applied to speech recognition area, while in the area of speech enhancement and noise reduction, the major application of NNs is the extraction of speech sections from a noisy speech signal. Moreover, amplitude spectrums contain more information than phase spectrums when speech signals are generated by fast Fourier transform (FFT).
In this paper, the proposed system reduces the noise of a speech signal by using the proposed NN based on FFT amplitude spectrums and phase spectrums, and implements auditory processing frame by frame according to the detected results after detected voiced sections and transitional sections for each frame. Thereafter, the proposed system restores the FFT amplitude and phase spectrums using an inverse fast Fourier transform (IFFT).
To evaluate the proposed speech processing system, the SNR is measured as an indication of the speech intelligibility, and the results confirm the effectiveness of our solution in the case of white, car, restaurant, subway, and street noise.
>
A. Speech and Noise Database
The speech data used in the experiment are included in the Aurora-2 database (DB) that consists of English-connected digits, recorded in clean environments with a sampling frequency of 8 kHz [13]. The Aurora-2 DB offers two different training modes, i.e., clean training and multi-conditional training modes. The clean training mode includes 8,440 utterances, which contains the voices of 55 male and 55 female adult recordings. The same 8,440 utterances are also used in the multi-conditional training mode. For each training mode, three test sets (sets A, B, and C) are provided. These clean utterances are artificially contaminated by adding different types of noise (subway, babble, car, etc.) to the clean utterances at different SNR levels. In test set A, four types of noise (subway, car, exhibition hall, and babble) are added to the clean utterances at SNR levels of -5, 0, 5, 10, 15, and 20 dB, while in test set B, another set of four different types of noise (restaurant, street, airport, and train station) are added to the clean utterances at the same SNR levels. In test set C, two types of noise (subway and street) used in sets A and B are added. The three test sets are composed of 4,004 utterances from 52 male and 52 female speakers [10, 11].
In this paper, a weighted spectral average filter is adopted to reduce unexpected peaks at each frame, as shown in Eq. (1) [10, 11].
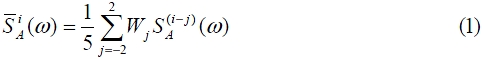
In Eq. (1), the weighted values for the parameters of
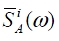
is the FFT spectral average of the
The parameters for

In this paper, the parameters of
>
C. Proposed Noise Reduction NN
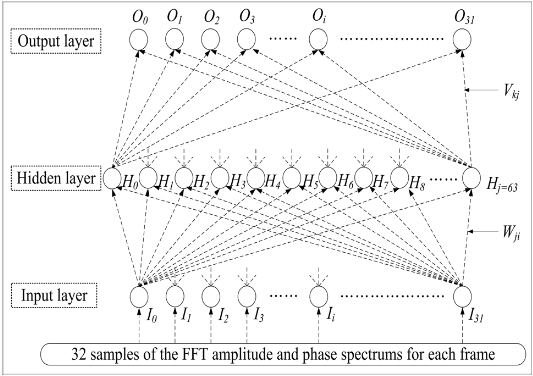
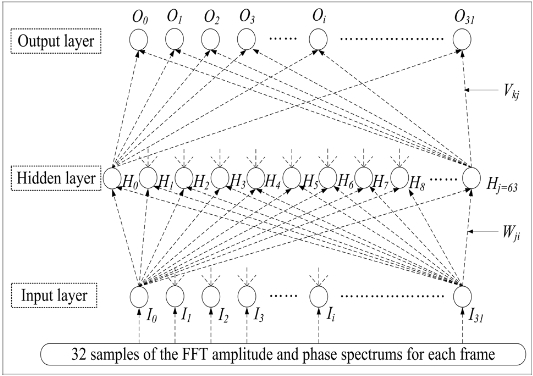
This paper proposes an algorithm using a noise reduction neural network (NRNN) that is constructed for the FFT amplitude and phase spectrum areas, allowing more effective correlation of the added information. In this experiment, a perceptron type NN is used and trained by a back-propagation (BP) algorithm, as shown in Fig. 2. The input and output for each unit approximates a sigmoid function, whose output range is from ?1.0 to 1.0, as given by Eq. (3) [10, 11].
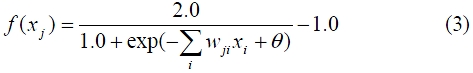
In this equation,
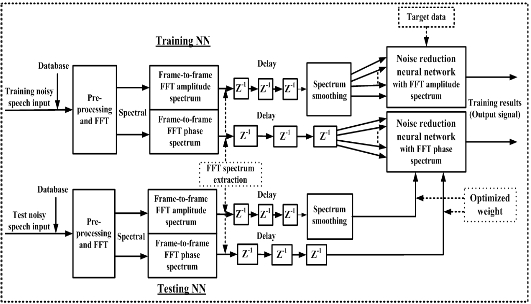
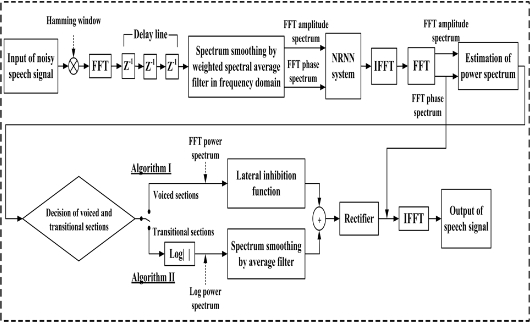
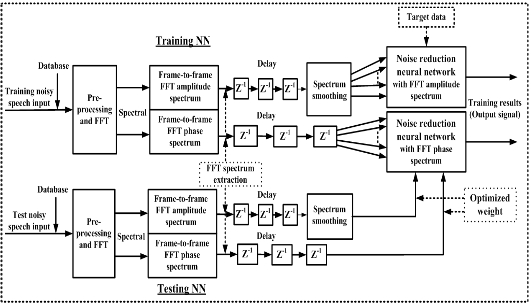
In order to essentially reduce the background noise, this paper proposes a noise processing algorithm using the BP training method of the NRNN system, which is composed of an NN based on amplitude and phase spectrums, as shown in Fig. 3.
The proposed NN was trained using twenty types of noisy speech data selected randomly from test set A, and artificially added at five different SNRs (20 dB, 15 dB, 10 dB, 5 dB, and 0 dB) for four different noises (i.e., white, car, restaurant, and subway noise). Therefore, the proposed NN was trained using five kinds of networks: 1) input signal-to-noise ratio (
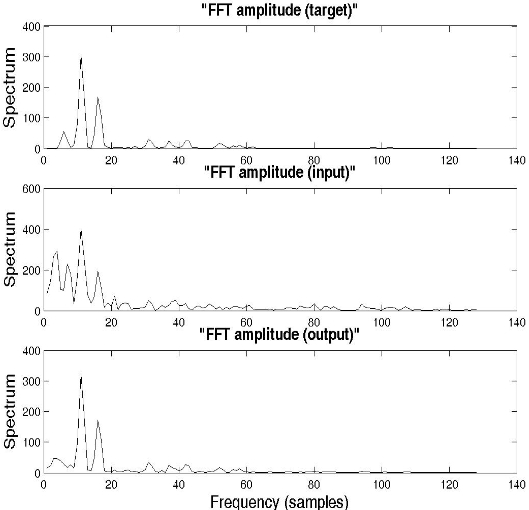
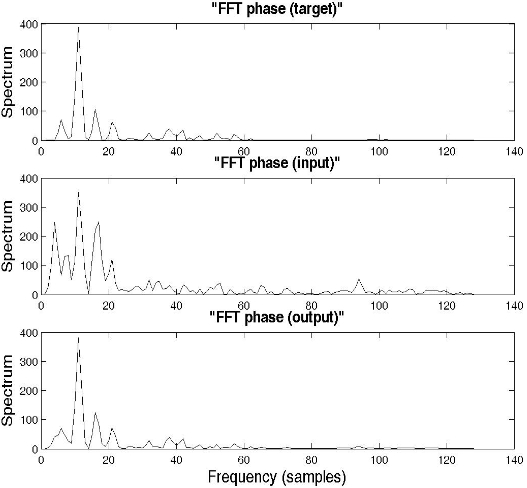
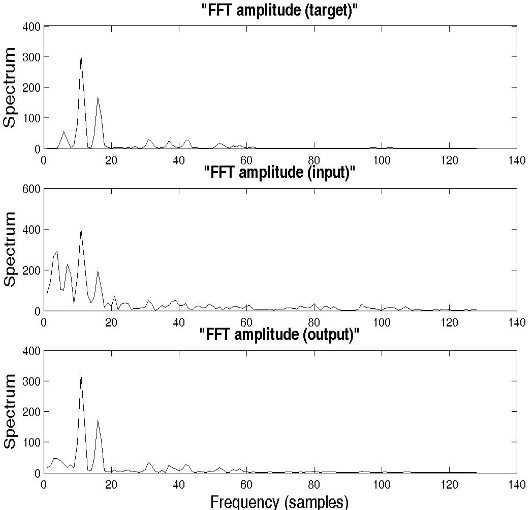
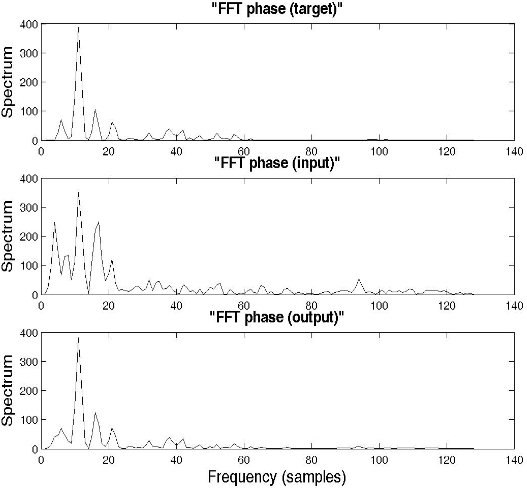
In order to highlight the noise elimination performance by the NRNN system, car noise was added to the original clean signal "MAT_32O2A.08", which was spoken by a male speaker, for the tenth frame. Fig. 4 shows examples of the FFT amplitude spectrums for the target (clean speech), input (noisy speech), and output signal, while Fig. 5 shows the FFT phase spectrums for the target, input, and output signal, in the case of
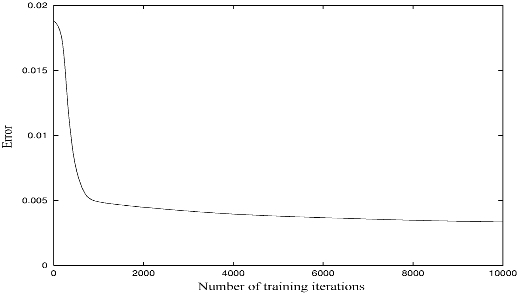
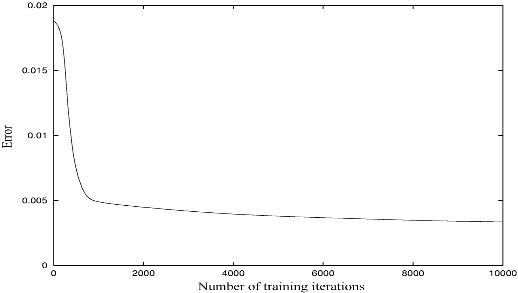
The training coefficient was set at 0.1 and the inertia coefficient set at 0.03 because these training coefficients produced the best convergence of the NN. The maximum number of training iterations was discontinued after 10,000 times because there was almost no decrease in the training error curves at the minimum error points. The error in Fig. 6 is an average value among ten trials for one network. Fig. 6 shows the training error curves for the NN based on the amplitude spectrums in the case of
>
III. DESIGN OF PROPOSED SPEECH PROCESSING SYSTEM
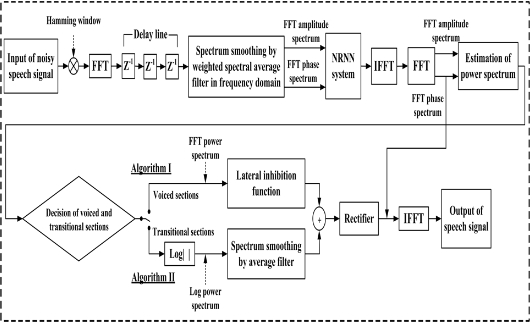
In order to consider the practical applications for noise reduction, we adopted the speech processing system as shown in Fig. 7. The proposed system mainly consists of the weighted spectral average filter for reducing unexpected peaks at frames, the NN for training two kinds of different patterns with the FFT amplitude and phase spectrums, and the lateral inhibition function for obtaining a significant auditory spectral representation. In Fig. 7, first, the noisy speech signal
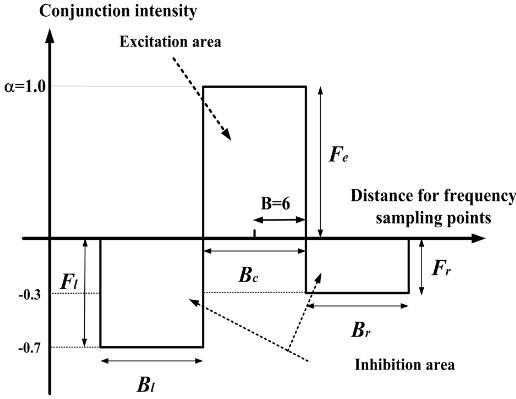
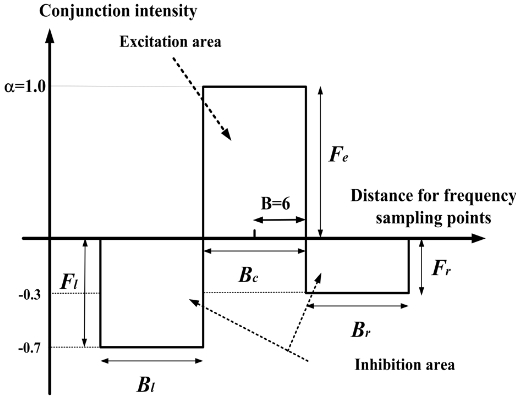
At the output of the decision of the voiced and transitional sections block, there is a switch to send the FFT or log power spectrums in Fig. 7. When the detected results for each frame are voiced sections, we use FFT power spectrums to convolve with the lateral inhibition function, called algorithm I. When the detected results for each frame are transitional sections, we use log power spectrums and a spectrum smoothing method by using the average filter, that is, algorithm II. Some negative values after convolution do not contain any useful information in the present situation, and therefore are set at zero. In this experiment, the coefficients for the lateral inhibition function were "
IV. EXPERIMENTAL RESULTS AND CONSIDERATIONS
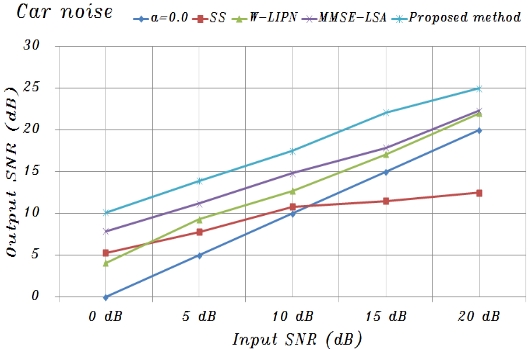
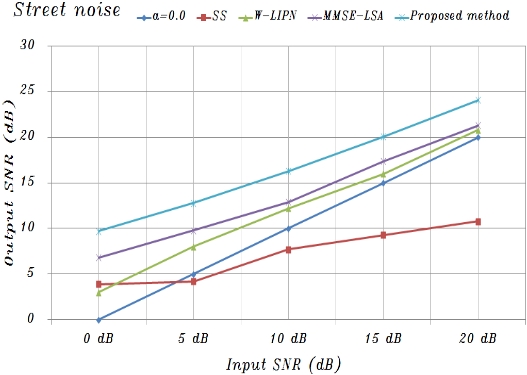
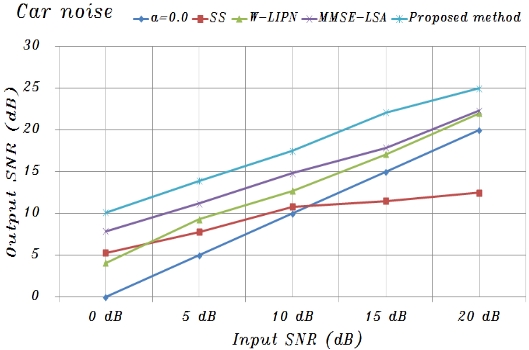
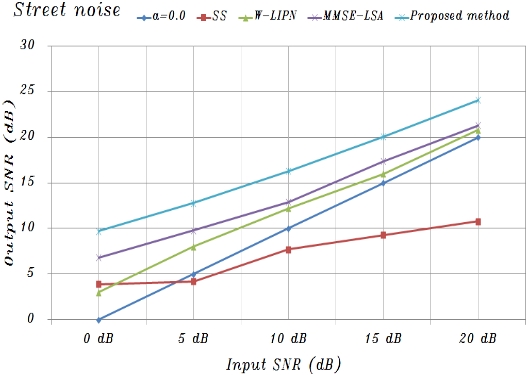
Using the basic composition conditions described above, experiments confirmed that the proposed system was effective for speech degraded by additive car and street noise based on measuring the SNR. To evaluate the performance, noisy speech data for twenty different test utterances were randomly selected from test sets A, B, and C [10, 11].
The proposed system was compared with a conventional spectral subtraction (SS) method [3] and the minimum mean-square error log-spectral amplitude (MMSE-LSA) [8] estimator method for car and street noise. The SS method is the classic algorithm that is used in speech enhancement and noise suppression. This method estimates the noise power spectrums from the magnitude spectrums of the noisy speech measured during non-speech activity and then subtracts the noise power spectrums from the speech power spectrums for each frame. The enhanced speech is reconstructed, through an inverse Fourier transform, from both the enhanced magnitude spectrums and the original phase spectrums [3]. When implementing the SS method in this experiment, Hamming-windowed frames that overlapped by 50% were used to reduce edge effects. Moreover, the MMSE-LSA estimator method is based on a minimum mean-square error short-time spectral amplitude (MMSE-STSA) estimator [9], which can be derived by modeling speech and noise spectrums as statistically independent Gaussian random variables. This MMSE-LSA amplitude estimator method is obtained by means of minimizing the mean-squared error of the log-power spectrums, and the gain function derived in Ephraim and Malah [8] is constructed to minimize the mean-square error estimates of log spectrums. When implementing these conventional methods, the frame length was 64 samples (8 ms) and the overlap was 32 samples (4 ms). At each frame, a Hamming window was used [10, 11].
Figs. 8 and 9 show the averages of the approximate
A speech processing system was proposed that uses a lateral inhibition mechanism model and noise reduction neural network based on amplitude and phase spectrums to reduce background noise. In summary, the experimental results were as follows: 1) The noise reduction with the function of lateral inhibition was different for car and street noise, and was especially remarkable for car noise; and 2)The noise reduction was significant under serious
The proposed system using the function of lateral inhibition was experimentally demonstrated as an effective noise suppression system for white, car, restaurant, subway, and street noise. Therefore, it is believed that the present research results will be useful for noise suppression and speech enhancement under noisy conditions.