Achieving situation awareness is especially challenging for real-time data stream applications because they i) operate on continuous unbounded streams of data, and ii) have inherent realtime requirements. In this paper we showed how formal data stream modeling and analysis can be used to better understand stream behavior, evaluate query costs, and improve application performance. We used MEDAL, a formal specification language based on Petri nets, to model the data stream queries and the quality-of-service management mechanisms of RT-STREAM, a prototype system for data stream management. MEDAL’s ability to combine query logic and data admission control in one model allows us to design a single comprehensive model of the system. This model can be used to perform a large set of analyses to help improve the application’s performance and quality of service.
Situation awareness (SA) has been recognized as a critical foundation for successful decision-making across a broad range of complex real-time applications, including aviation and air traffic control [Nullmeyer et al. 2005], emergency response [Blandford and Wong, 2004], and military command and control operations [Gorman et al. 2006]. SA is especially important for applications where the information flow can be high and poor decisions may lead to serious consequences (e.g., piloting a plane or treating critically injured patients). These applications need to operate on continuous unbounded streams of data to understand how incoming information and events could impact the system, both now and in the near future. The streaming data may come from various sources such as sensor readings, router traffic traces, or telephone records. Therefore, the capability to manage data streams has become an essential application requirement.
These applications also have inherent real-time requirements, and queries on the streaming data should be finished within their respective deadlines. Consider a surveillance system as an example. The system is expected to detect if a target enters the monitored area and alert the controlling party (e.g., human operators). If the detection does not occur within a certain deadline, the target may be missed. However, due to the dynamic nature of the input data streams, the stream queries may have unpredictable execution costs. First, the arrival rate of the data streams can be volatile, which leads to variable input volumes to the queries. Second, the content of the data streams may vary with time, which causes the selectivity of the query operators to change over time. The variable stream behavior and the irregular workload pattern make maintaining the desired level of quality-of-service (QoS) a challenging task.
Formal data stream analysis can help tremendously in achieving the desired levels of QoS for real-time data stream applications. Such analysis can provide query designers with a better understanding of the behavior of the real-time data streams they are working with. It could also be used to more accurately predict changes in the data arrival patterns and the query workloads. In addition, analysis of the data admission controller, responsible for determining the amount of input stream data to the queries, could aid the design of better controllers that can adapt faster to workload fluctuations. To perform such an analysis, we needed a specification language that would allow us to formally model real-time data streams, stream queries, and data admission control mechanisms. Such a language, however, was missing. To address this, we proposed to use MEDAL - a formal specification language, which in its nature is an enhanced Petri net. MEDAL can capture the structural, spatial, and temporal characteristics of a complex distributed real-time system, which makes it suitable for modeling and analysis of data streams.
In this paper we describe how MEDAL was used to model and analyze real-time data stream applications. First, each query plan could be specified with a MEDAL model. Second, MEDAL is also capable of modeling the data admission controller. MEDAL’s ability to model both the queries and the data admission control enabled us to combine the two main components of data stream applications - query logic and control - into a single comprehensive system model. Third, using the MEDAL query models to analyze different system properties such as the behavior of the data streams, the cost and selectivity of different query operators, and the real-time properties of the queries, can significantly improve the QoS of the applications. Further, MEDALaided analysis could also help admission control designers build better and more accurate prediction-based controllers.
There are three main contributions of this paper: 1) adapting MEDAL to model realtime data stream queries and stream management mechanisms, 2) integrating query logic and data control models into a comprehensive data stream application model, 3) introducing how MEDAL can be used for various types of analyses, such as query plan optimization and application timeliness.
The rest of this paper is organized as follows: We discuss related work in Section 2. Section 3 gives a short overview of MEDAL and some of its properties. Section 4 briefly introduces the components of our system model, namely, periodic query model, query plans, and the data admission controller. Section 5 describes how operator cost and selectivity predictions are used to improve the QoS of the system. Section 6 describes how MEDAL is applied to model stream queries and data admission. We demonstrate some of the types of analyses that MEDAL is used for in Section 7. Section 8 shows the MEDAL models of different data stream management configurations. We also evaluated how these configurations affect the QoS of a prototype data stream management system, RT-STREAM. Section 9 concludes the paper.
There have been significant research efforts devoted to the query optimization problem in distributed Data Stream Management Systems (DSMSs) [Olston et al. 2003; Liu et al. 2005]. Adaptive filters have been proposed to regulate the data stream rate while still guaranteeing adequate answer precisions [Olston et al. 2003]. Liu et al. [2005] discuss the challenges for distributed DSMSs and propose dynamic adaptation techniques to alleviate the uneven workloads in distributed environments. Tu et al. [2006] use system identification and rigorous controller analysis to improve the benefits of input load shedding. Wei et al. [2007] apply
Selectivity estimation has been a fundamental problem in the database community since query optimizers use the estimation results to determine the most efficient query plans. Sampling [Haas et al. 1994], histograms [Poosala and Ioannidis, 1997], index trees [Comer, 1979], and discrete wavelet transforms [Press et al. 1992] are the most widely used selectivity estimation methods. Sampling has been used extensively in traditional database management systems (DBMSs) [Haas et al. 1994; Barbara et al. 1997; Chaudhuri et al. 2001]. It gives a more accurate estimation than parametric and curve fitting methods used in DBMSs and provides a good estimation for a wide range of data types [Barbara et al. 1997]. In addition, since sampling-based approaches, as opposed to histogram-based approaches, do not require the maintenance of an auxiliary data structure, they do not incur the overhead of constantly updating and maintaining that data structure. This is especially important in the context of data streams as the input rate of the streams is constantly changing. Wei et al. were the first to consider a sampling-based approach to evaluate the data stream query workloads and use the results to manage the query QoS [Wei et al. 2007]. In this paper we employed this sampling technique and used it as part of our prediction-based QoS management mechanism.
The majority of work on data streams uses SQL or SQL-like semantics to define stream queries [Wei et al. 2006; Babcock et al. 2002]. Babcock et al. use standard SQL to model stream queries and extend the expressiveness of the language to allow the specification of sliding windows [Babcock et al. 2002]. However, SQL fails to express a number of essential characteristics specific to processing data streams, such as:
1) Data dependency and correlation among different streams in heterogeneous systems;
2) Collaborative decision making: Data stream systems are distributed, concurrent, and asynchronous. Therefore, detecting events usually requires spatial and temporal composition of ad-hoc readings;
3) Modeling probabilities: Individual data readings are often unreliable which results in non-deterministic decision making. In order to tolerate such non-determinism, queries might need to be defined using a probabilistic model. SQL has no explicit support in this regard;
4) Graphical model: SQL does not have natural graphical support.
Another method for modeling stream queries was proposed for the Aurora system [Abadi et al. 2003]. Aurora uses a graphical boxes-and-arrows interface for specifying data flow through the system. Compared to a declarative query language, this interface is more intuitive and gives the user more control over the exact series of steps by which the query answer is obtained. However, this approach lacks the ability to model probabilities, data dependencies and correlation, and collaborative decisions.
In this paper we used a formal specification language, called MEDAL [Kapitanova and Son, 2009], to model stream queries and data admission control. MEDAL combines features from Stochastic, Timed, and Colored Petri nets, which allows it to model system properties such as collaborative decision-making, temporal and spatial dependencies, heterogeneity, and non-determinism. These modeling capabilities render MEDAL very suitable for modeling stream query plans.
In this section we give a short overview of the specification language MEDAL and some of its properties. The MEDAL description of a real-time application is a 7-tuple structure
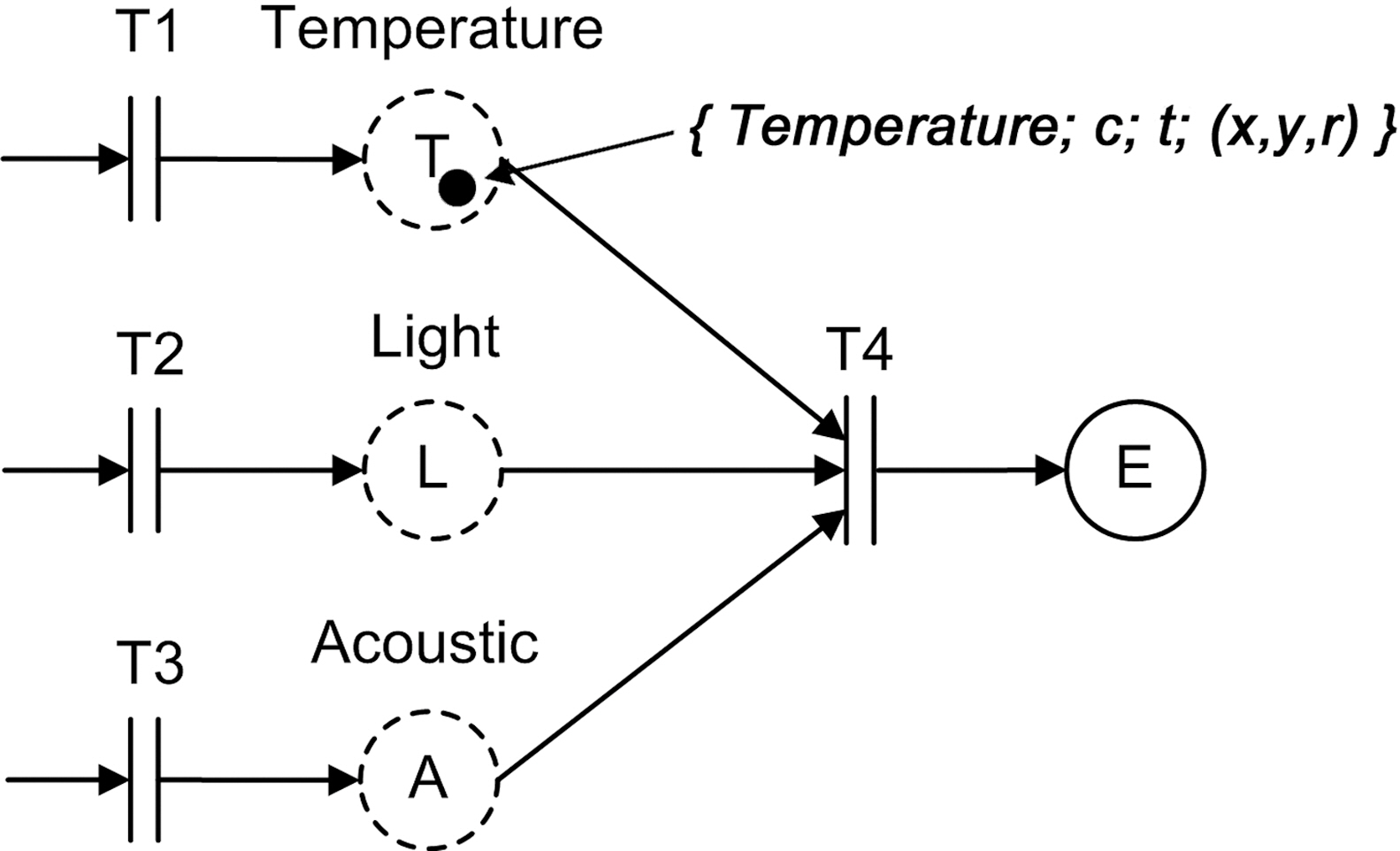
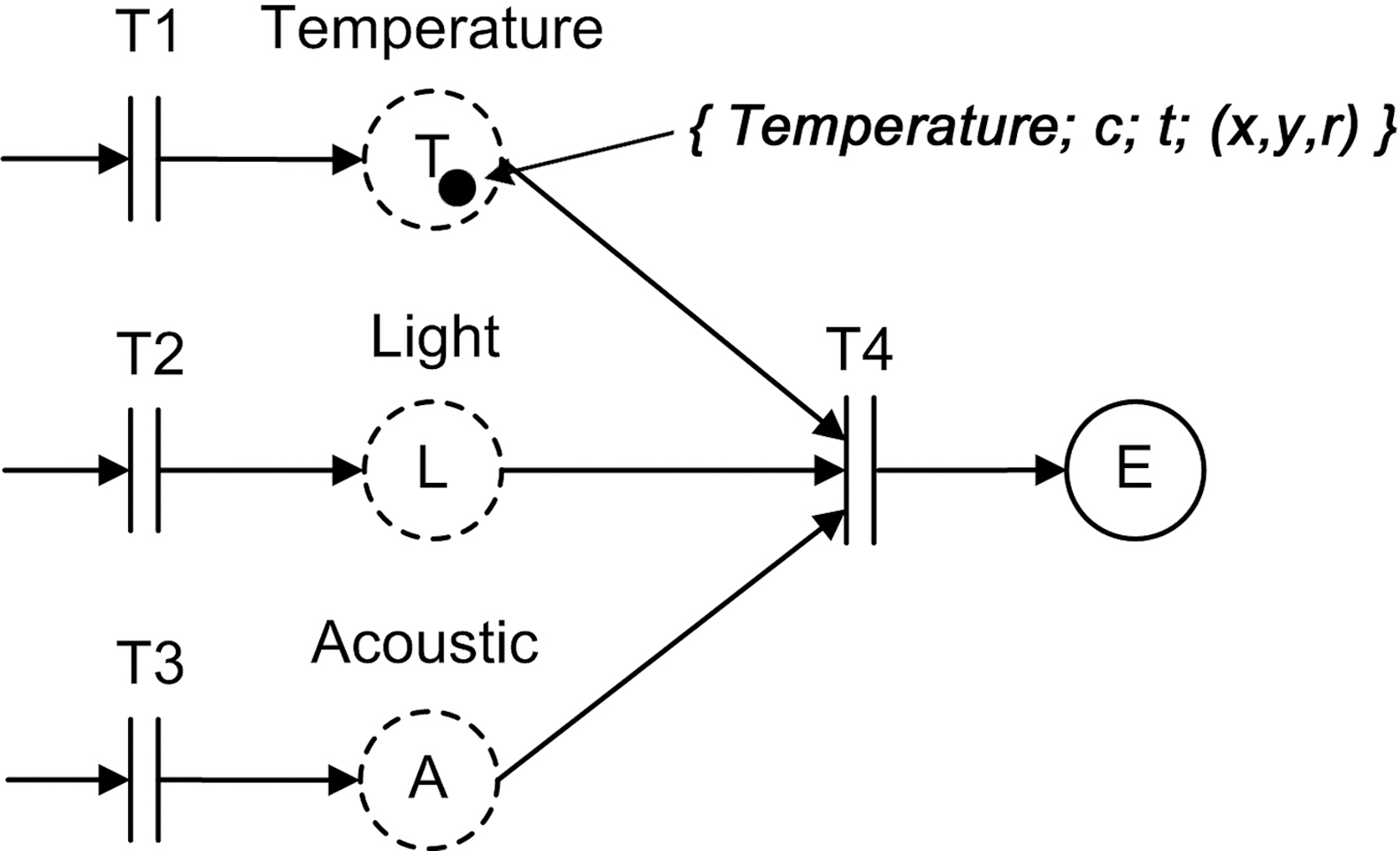
1) P is the set of all places. Places can represent application state or data, and are depicted as circles in a MEDAL model. P =S∪E, where S represents the data input places (T, L, and A in Figure 1), and E represents the places for higher level events (place E in Figure 1).
2) T is the set of all transitions. Transitions model various types of actions or operators and are represented by rectangle bars (transitions T1, T2, T3, and T4 in Figure 1).
3) A is the set of arcs. Arcs in MEDAL represent the flow of logic/control and are depicted as directed arrows.
4) λ is the probability/weight function for the arcs and λ : A→[0, 1]. With λ,MEDAL adopts features from Timed and Stochastic Petri nets which allow it to model probabilistic problems.
5) β is the time guard function, β : T→* (r1, r2), where r1 ≤ r2 . For a transition T, β(T) = (α1, α2) (α3, α4) indicates that this transition can only fire during the union closure of the given ranges. β also acts as a persistency guard, i.e. we can use it to specify the amount of time a place can hold a token before this token becomes invalid.
6) H is the threshold function for places and is defined as H : P→ . For example,H(p) = c means that a token can enter a specific place p only if its capacity is equal or higher than c.
7) L is the spatial guard function for transitions, L : T→+. It is used to guarantee that the incoming data has been generated within the radius of interest.
Figure 1 shows the MEDAL model of an example explosion detection application.An explosion is characterized by specific temperature, light, and sound values.Therefore, our detection application takes input data streams from three types of sensors - temperature, light, and acoustic - and uses the readings to determine if an explosion has occurred. In Figure 1,the temperature, light, and sound input data streams are represented with places
Tokens are abstract representations of data or occurrences of events. In MEDAL, a token is defined as:
Token = {Type tp; Capacity c; Time t; Location l},
where the type of a token indicates the type of data or event represented by the token.The
A data stream is defined as a real-time, continuous, ordered (implicitly by arrival time or explicitly by timestamps) sequence of data [Golab and Ozsu, 2003]. A DSMS is a system especially constructed to process persistent queries on dynamic data streams.DSMSs are different from traditional DBMSs in that DBMSs expect the data to be persistent in the system and the queries to be dynamic, whereas DSMSs expect dynamic unbounded data streams and persistent queries. Emerging applications such as sensor networks, emergency response systems, and intelligent traffic management,have brought research related to data streams into focus. These applications inherently generate data streams, and DSMSs are well suited for managing the produced data.
So far, DSMS research has mainly been focused on using a continuous query model[Carney et al. 2002; Abadi et al. 2003; Abadi et al. 2005; Girod et al. 2007]. In a continuous query model, long-running continuous queries are present in the system and new data tuples trigger the query instances. These incoming data tuples are then processed and the corresponding query results are updated. The continuous model performs well when the system workload is stable and the system has sufficient resources to finish all triggered query instances. However, since the number of query instances and the system workload depend directly on the input, which could be extremely volatile, this continuous query model is not appropriate for real-time applications that need predictable responses. Another drawback of this model is that,since the query execution is driven by the data rate of the system, the application does not have control over the frequency and the deadlines of the queries. For applications where some queries are more important than others, it might be desirable to have the ability to execute the important queries more often. This, however, is hard to accomplish in a continuous query model.
To address this, we have developed a periodic query model (PQuery) for data stream queries with timing constraints [Wei et al. 2006]. In this periodic query model, every query has an associated period. Upon initialization, a query instance takes a snapshot of the data streams at its inputs. The query input does not change throughout the course of the query instance execution, even when there are new data tuples arriving over the data streams. Instead, the newly arrived data tuples are processed by the next query instance. In this way, query execution is not interrupted or aborted by new incoming data. When an application receives the results of a periodic query instance,it is with the understanding that these results reflect the state of the system when the query instance was initiated. In the periodic query model, the application can specify the query periods and deadlines. These parameters can be used to calculate the number of queries in the system at any given time, which allows us to estimate the query workloads much easier than with the continuous query model.
4.2 Query Plan and Query Execution
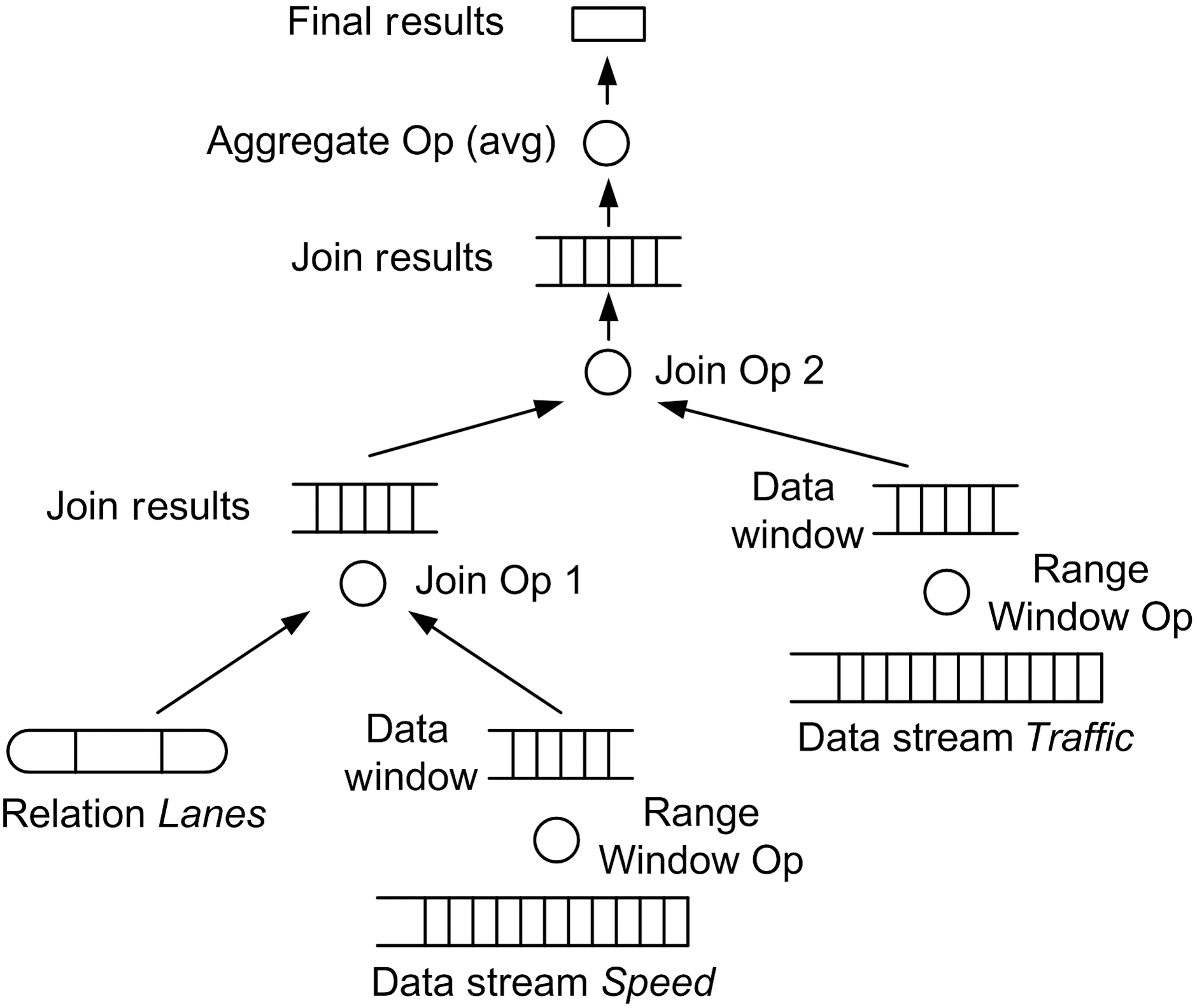
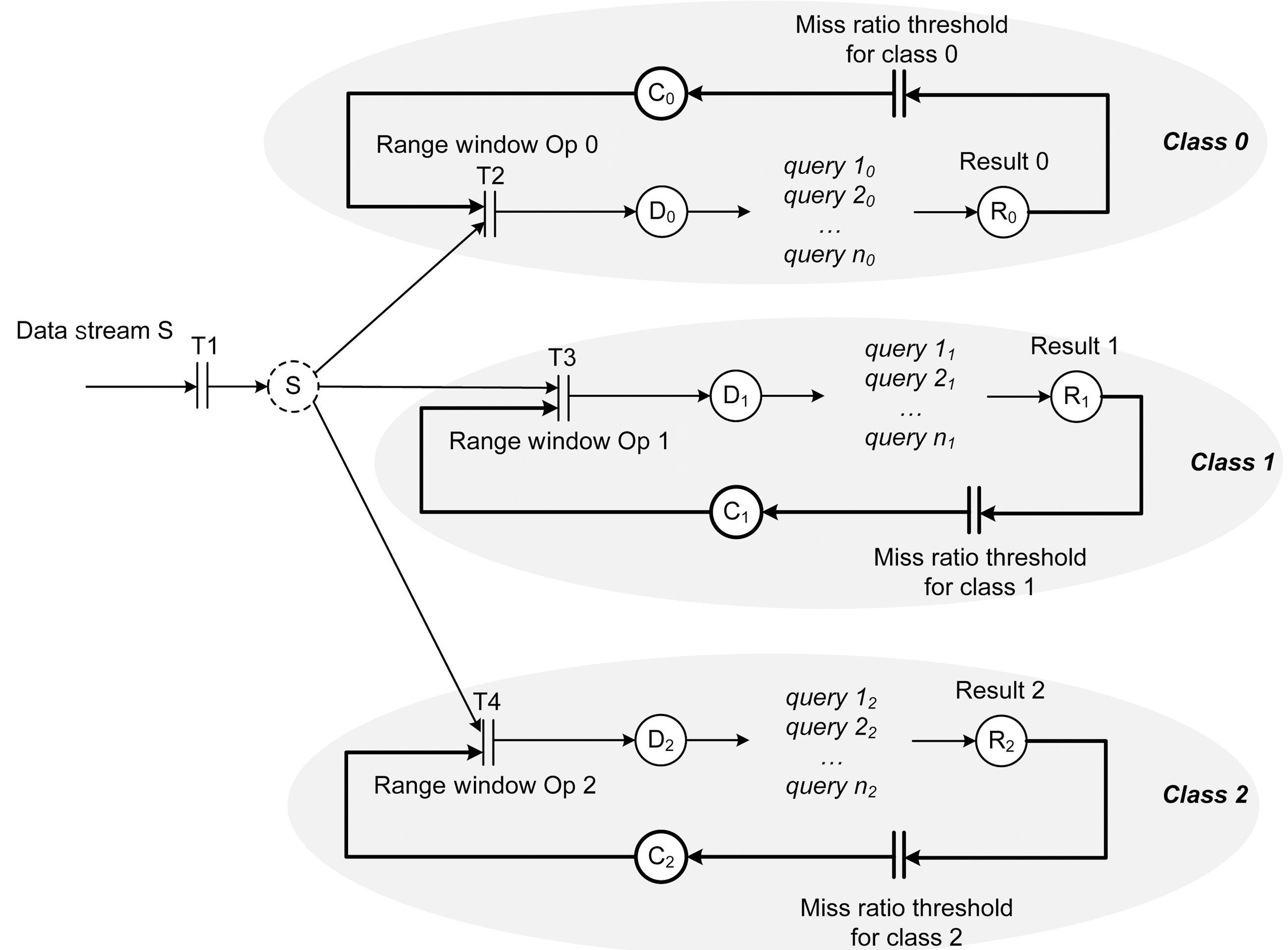
A DSMS contains long-running and persistent queries. When a query arrives in the system, it is registered and is triggered periodically based on its specified period. All queries are converted to query plans (containing operators, queues, and synopses)statically before execution. Queues in a query plan store the incoming data streams and the intermediate results between the operators. A synopsis is associated with a specific operator in a query plan, and stores the accessory data structures needed for the evaluation of the operator. For example, a JOIN operator may have a synopsis that contains a HASH JOIN index for each of its inputs. When the JOIN operator is executed,these hash indices are probed to generate the JOIN results.
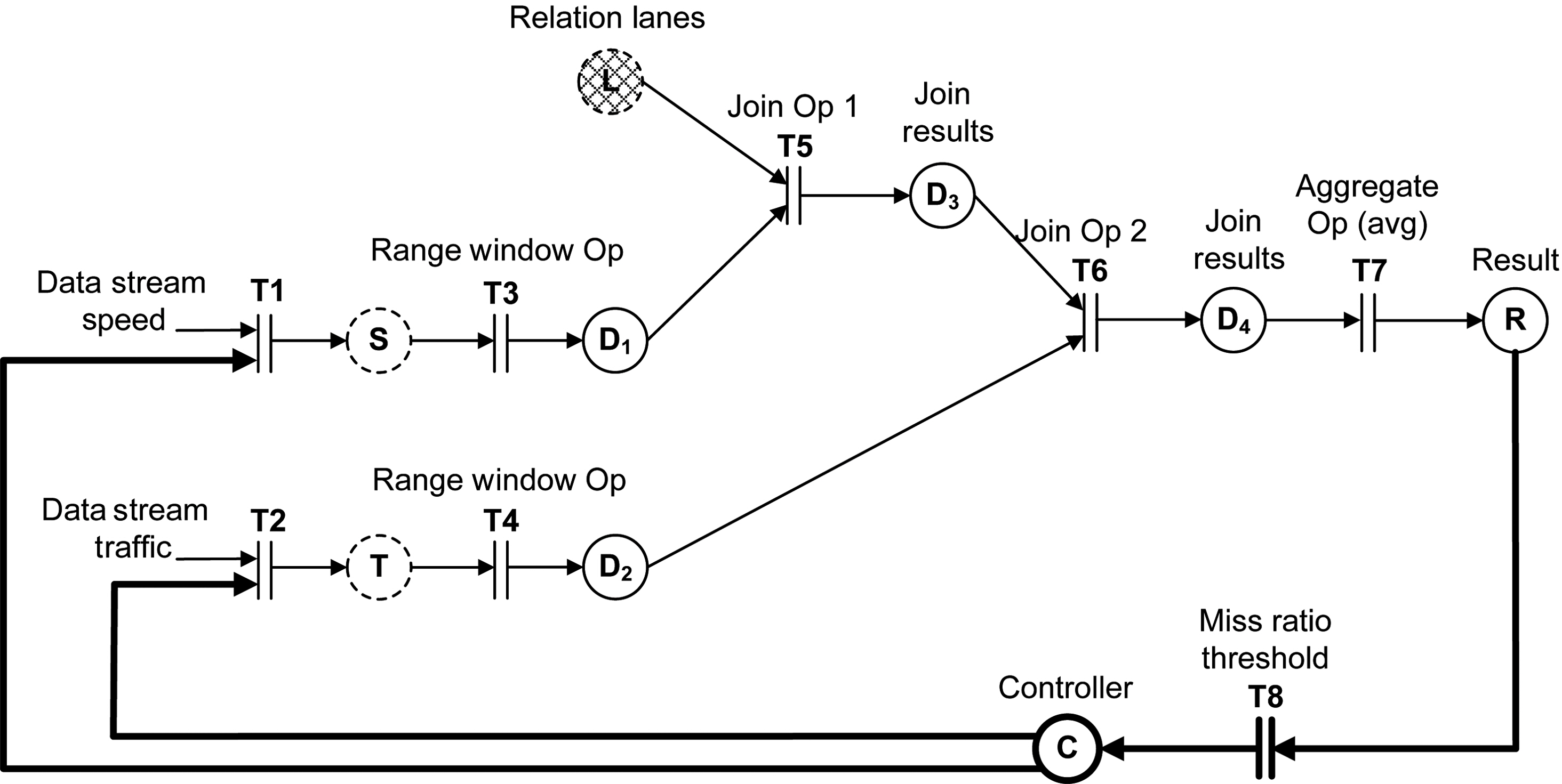
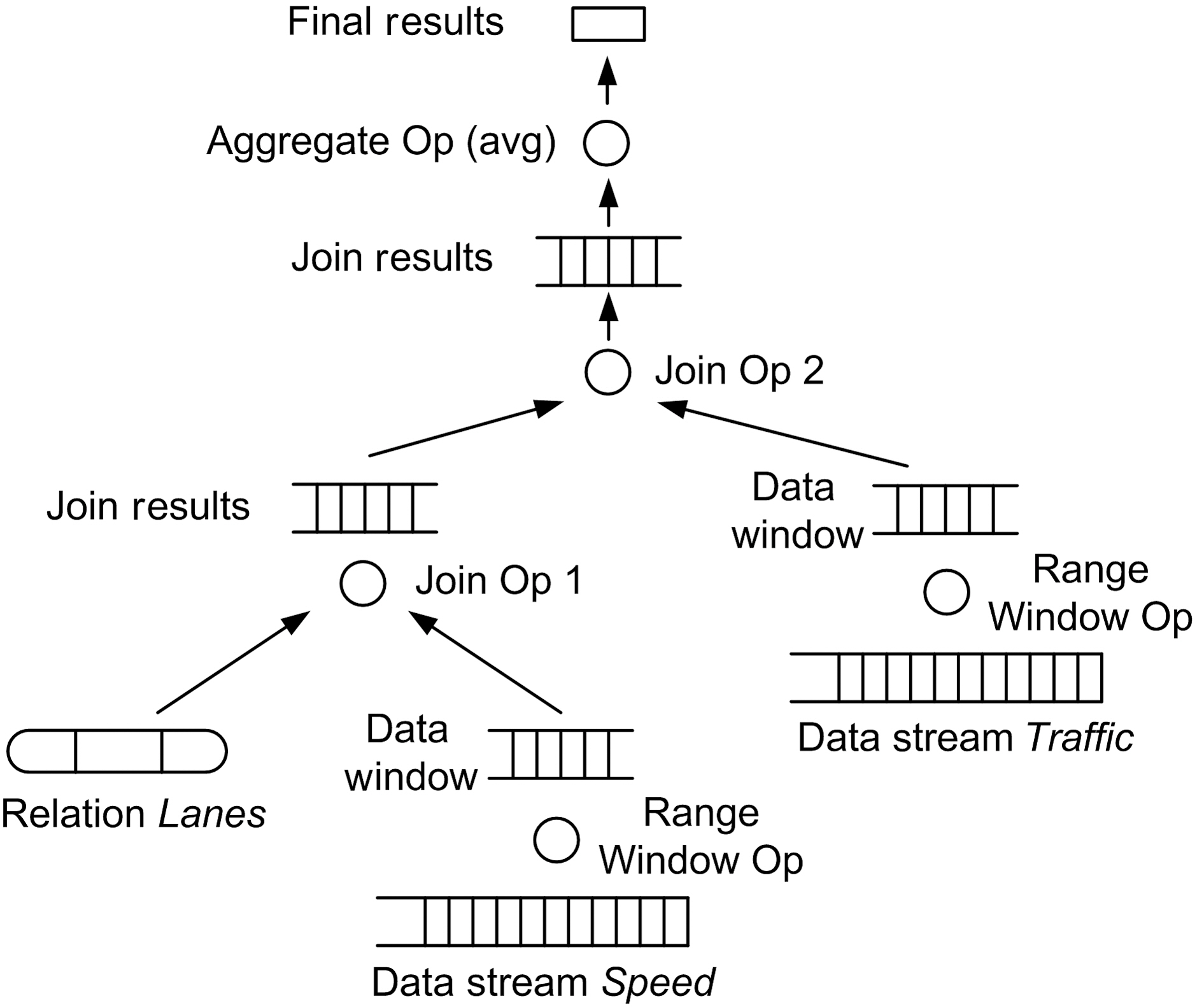
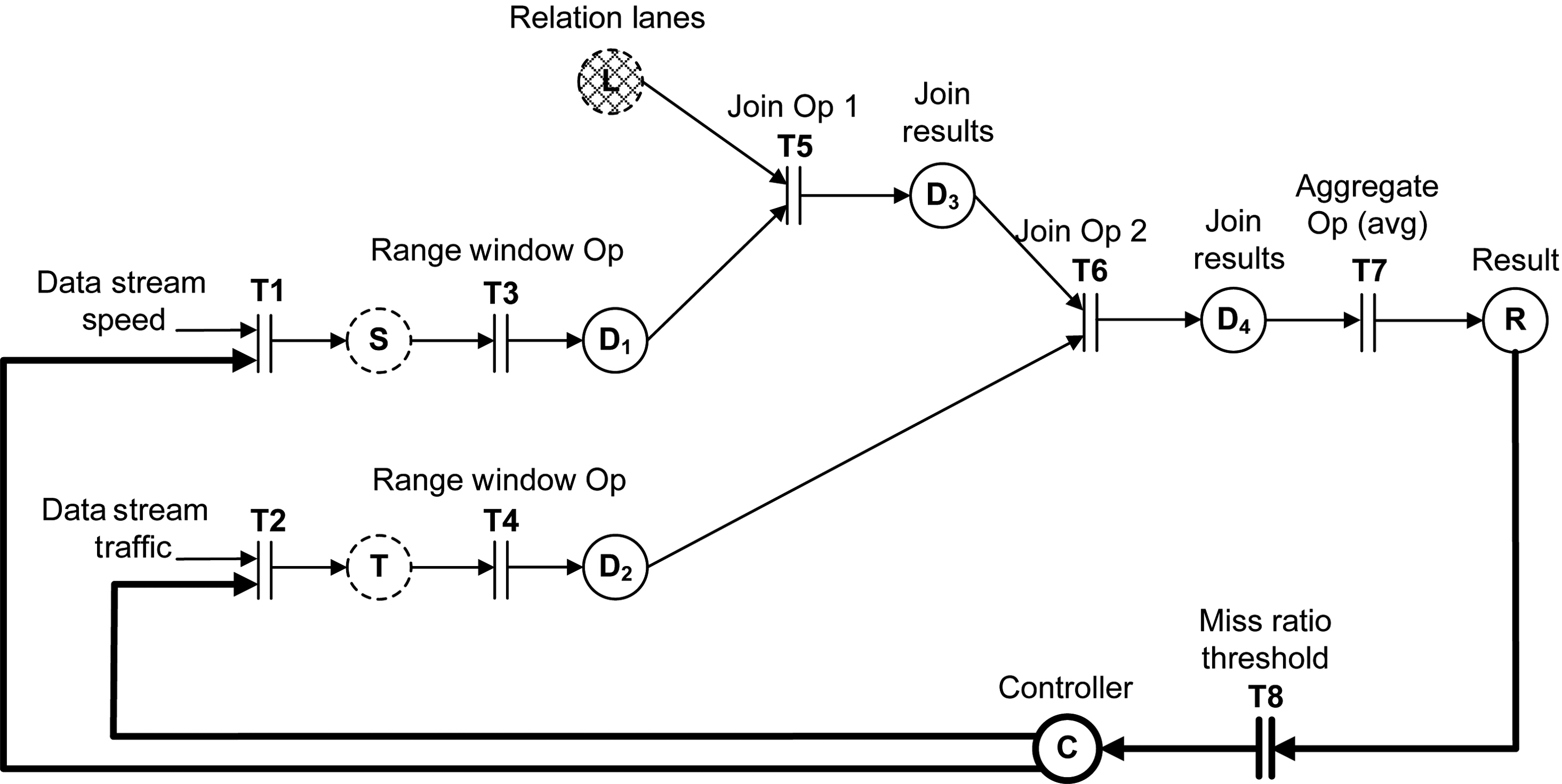
Consider the following example scenario where a traffic monitoring system has been deployed to constantly analyze the traffic in a particular city and determine the most suitable times for delivering supplies to grocery stores. To achieve the desired situation awareness, the system analyzes data streams from speed and traffic sensors.We perceive events as the fundamental building blocks of a situation. Therefore,achieving situation awareness requires that we identify a particular set of events and perform our situation assessment and analysis based on their occurrence. One type of event that our traffic monitoring application is interested in is trucks that travel during light traffic in specific lanes, such as non-HOV lanes. For its consequent traffic analysis, the application calculates the average speed of these trucks. The SQL data stream and query specifications are given as follows:
Stream : Speed (int lane, float value, char[8] type);
Stream : Traffic (int lane, char[10] type);
Relation : Lanes (int ID, char[10] type, char[20] road);
Query : SELECT avg (Speed.value)
FROM Speed [range 10 minutes], Lanes,
Traffic [range 10 minutes]
WHERE Speed.lane = Lanes.ID AND
Lanes.ID = Traffic.lane AND
Speed.type = Truck AND
Traffic.type = Light
Period 10 seconds
Deadline 5 seconds
The query above operates on data streams generated by speed and traffic sensors and calculates the average speed of trucks in particular lanes during light traffic over a 10-minute window. The query needs to be executed every 10 seconds and the deadline is 5 seconds after the release time of every periodic query instance. The query plan that is generated based on this query is shown in Figure .2 It contains three types of
query operators (RANGE WINDOW operator, JOIN operator, and AGGREGATE operator)and two types of queues (one for storing the output of the RANGE WINDOW operators and one for storing the output of the JOIN operators).
After the query plan is generated, the operators are sent to the scheduler to be executed. Depending on the query model (e.g., continuous or periodic), a scheduling algorithm such as round-robin or earliest deadline first could be chosen so that the system requirements are met.
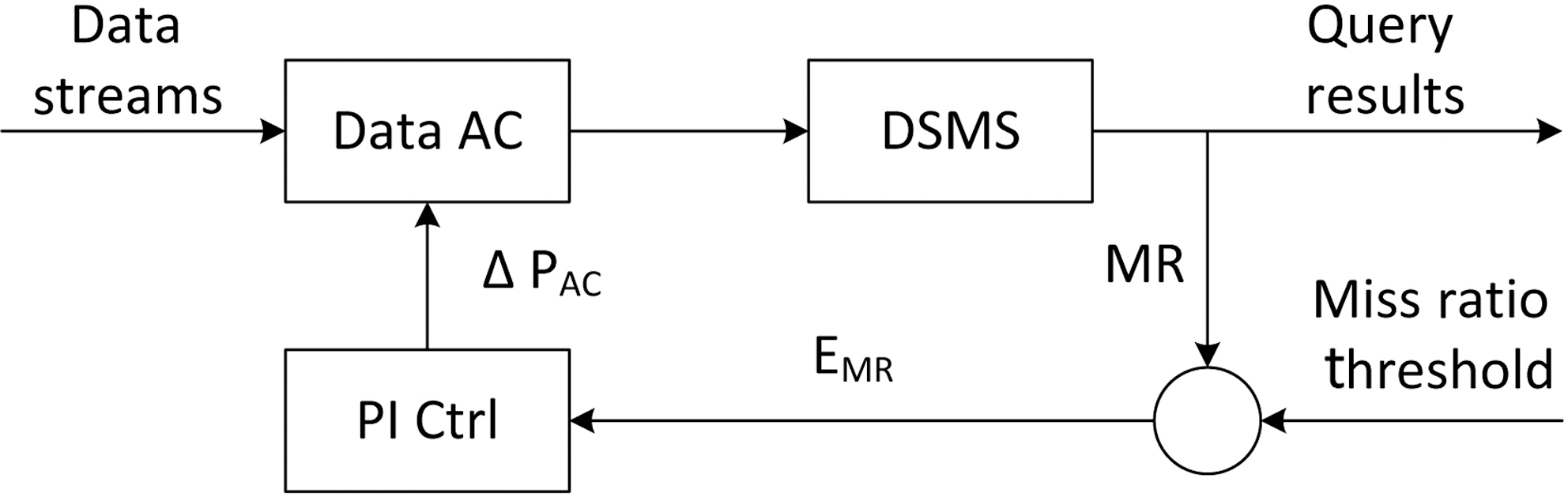
In many real-time applications, partial results are more desirable than queries missing their deadlines. Therefore, the system might trade off data completeness for better query miss ratios at run time. We have designed an overload protection mechanism called a
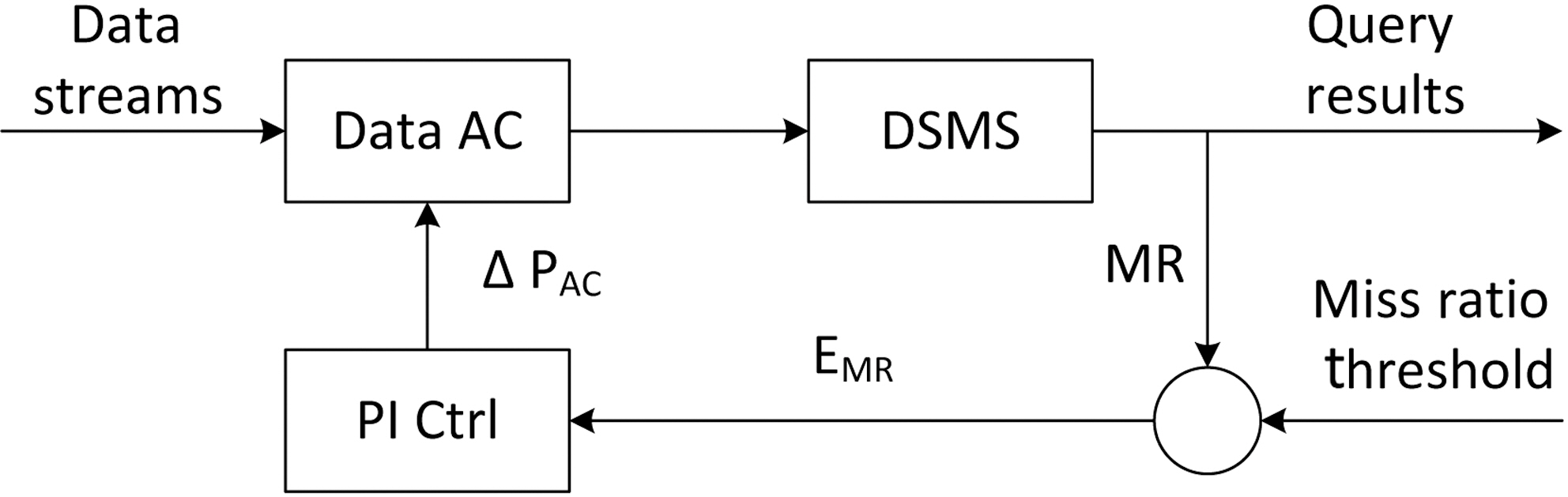
The data admission process is controlled with a proportional-integral (PI) controller as it is simple to use and provides an acceptable response time to workload fluctuations.A proportional-integral-derivative (PID) controller is not suitable in this situation because of the dramatic changes that might occur in the workloads of query systems
from one sampling period to another. Adding a derivative control signal amplifies the random fluctuations in the system workloads [Hellerstein et al. 2004].
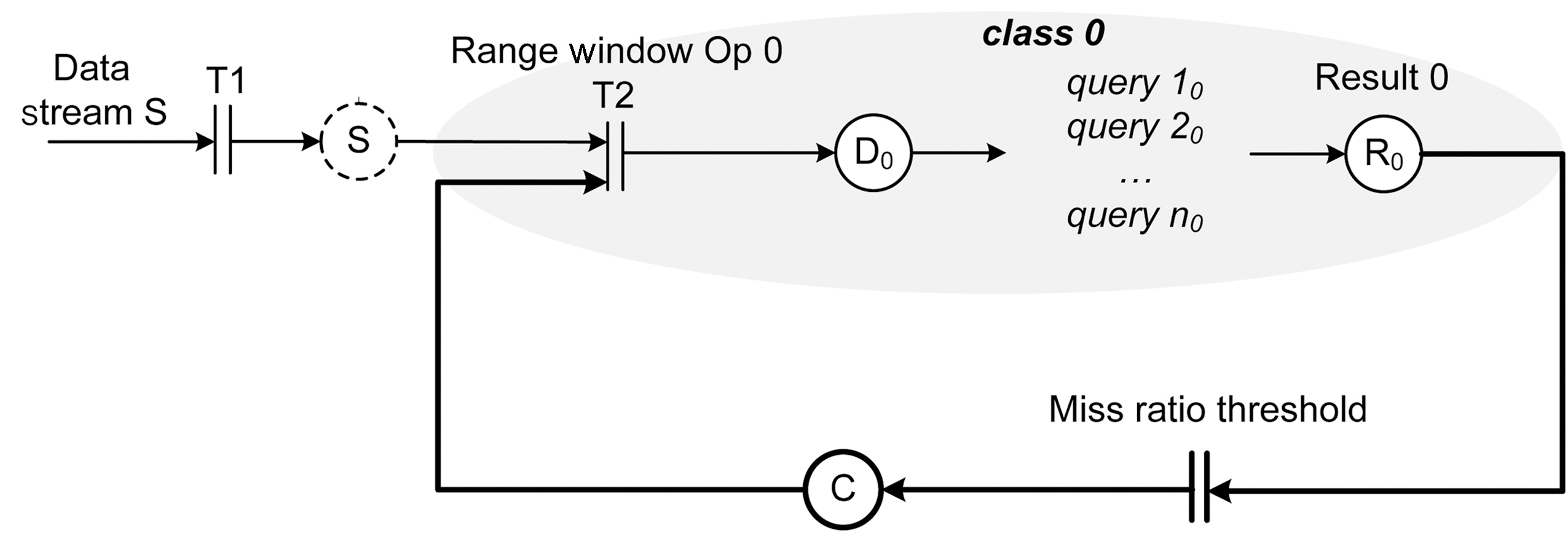
The data admission control architecture is shown in Figure 3. The query miss ratio(MR) is sampled periodically and compared against the miss ratio threshold specified by the application. The result is used by the PI controller to calculate the data admission control signal ΔPAC. The control signal is derived with the equation
ΔPAC = PMR× (MRST ? MRt) + IMR× (MRLT? MRt),
where
In order to provide service differentiation, the system uses multiple data admission controllers. Each service class is associated with a designated data admission controller whose parameters have been specifically tuned for that particular service class. The use of multiple controllers is further discussed and evaluated in Section 8.
5. PREDICTION BASED QOS MANAGEMENT
When a system becomes overloaded, more queries start missing their deadlines. If the query miss ratio increases above the application threshold, the application can no longer satisfy its QoS requirements. When this happens, in order to decrease the deadline miss ratio, the data admission controller should adjust the amount of input data sent to the queries. To perform a correct adjustment, the data admission controller needs information about the future workload and the corresponding query execution times. We predicted the query workload using execution time
5.1 Operator Selectivity Estimation
5.1.1 Operator selectivity.
The operator selectivity measures the ratio between the size of the input that is passed to an operator and the size of output data remaining after the operator has been applied. The selectivity of an operator is defined as:
Selectivity = Sizeoutput / Sizeinput
As the operator selectivity varies, the size of the output changes even when the input volume stays the same. Thus, the query execution cost could change significantly when the data stream content changes. While possible to design the system based on the maximum system workloads, this is not practical nor efficient, because the transient system overload does not persist for long periods of time. Therefore, we dynamically estimated and updated the operator selectivity based on changes in the workload.
5.1.2 Selectivity estimation using sampling.
We used
5.2 Operator Overhead Prediction
5.2.1 Operator cost estimation.
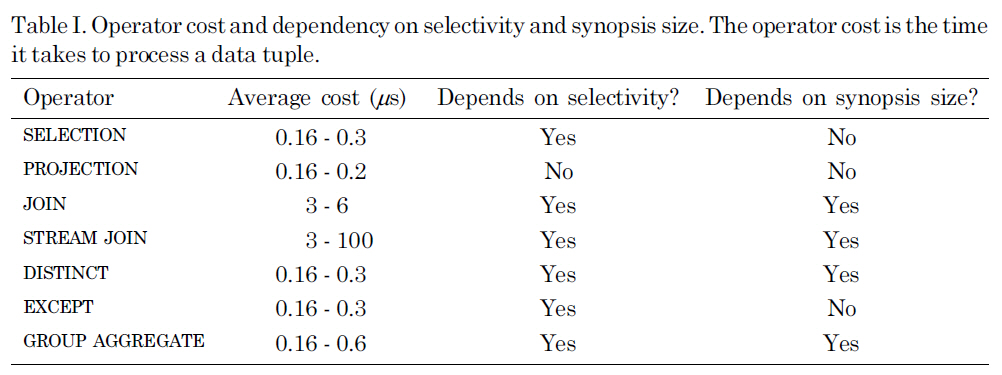
We made the assumption that all data, including incoming data streams and intermediate results, was stored in memory. Therefore, we could estimate the time it took for an operator to process a data tuple, excluding any additional delays caused by fetching data from the disk. Table I shows the average execution time per tuple for different types of operators. The experiments were performed on our real-time data stream management prototype system RT-STREAM. We could see that, with the exception of JOIN operators, the execution cost of most operators was relatively small and fairly predictable. The cost of a STREAM JOIN (a JOIN operator on two streams) varied from 3
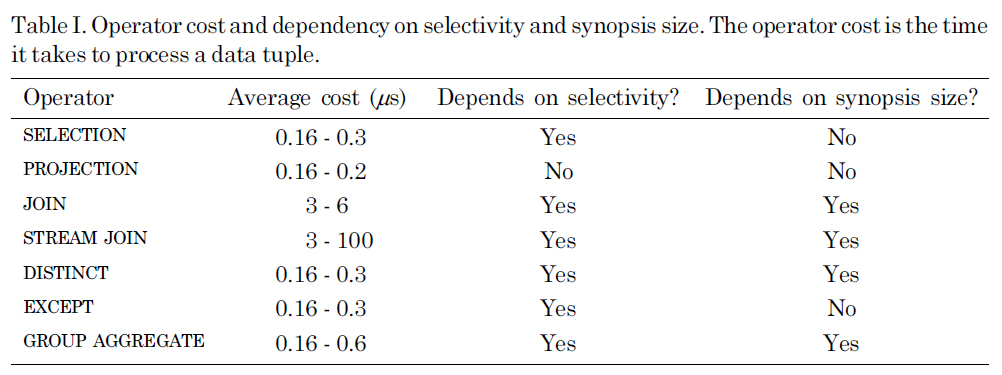
Operator cost and dependency on selectivity and synopsis size. The operator cost is the time it takes to process a data tuple.
tuples selected from the data streams could vary significantly. Joining one data tuple with thousands of data tuples from another data stream resulted in the high stream join cost we see in the table. Our experimental results showed that the cost of each operator can be estimated since it closely follows the formula obtained from cost analyses. Here, we presented our analyses for SELECTION and JOIN operators. The analyses for other operators are similar.
The following notations are used for the SELECTION operator
?n : input tuple volume,
?s : the selectivity of the operator,
?Cp : execution time to evaluate the predicates,
?Ci : execution time to insert the output tuple to buffer.
For the selection operator
Number of output tuples = n × s
Time to evaluate all input tuples = n × Cp
Time to insert the output tuples = n × s × Ci
Total time = n × Cp + n × s × Ci
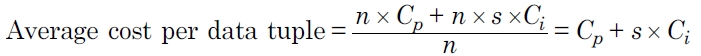
The costs
For JOIN operators, our system used SYMMETRIC HASH JOIN [Wilschut and Apers 1991; Hong and Stonebraker 1993]. The symmetric hash join keeps a hash table for each input in memory. When a tuple arrives, it is inserted in the hash table for its input. It is also used to probe the hash table of the other input. This probing may generate JOIN results which are then inserted in the output buffer. The following notations are used for a JOIN operator
?nL : left input volume,
?nR : right input volume,
?s : operator selectivity,
?CLProbe : execution time to probe the left hash index,
?CRProbe : execution time to probe the right hash index,
?nLHash : execution time to hash the left input,
?nRHash : execution time to hash the right input,
?Ci : execution time to insert the output tuple to the buffer.
For the join operator
Number of output tuples = nL × nR × s
Time to process the left input tuples = nL × CRProbe + nL × CLHash
Time to process the right input tuples = nR × CLProbe + nR × CRHash
Time to insert the output tuples = nL × nR × s × Ci
Total time = nL × (CRProbe + CLHash) + nR × (CRProbe + CLHash) + nL × nR × s × Ci
Of the three types of cost factors, hashing cost (
5.2.2 Maintaining cost constants using profiling.
There are a number of constants that participate in the cost analysis of query operators. For example, when estimating the cost of a SELECTION operator, one of the necessary inputs is the execution time to evaluate the predicates. The system needs to know the precise values of such cost parameters in order to accurately estimate the execution time of the operators. The approach we used was to keep track of the execution time of each operator and compute these cost parameters periodically. Suppose that after a query instance, the execution time for an operators is
Cnew = Cold × (1 ? α) + Texec × α,
where
6. MODELING QUERIES AND CONTROL
An advantage of MEDAL is that it can be used to specify a comprehensive application model by combining the admission controller and the query plan models into a single MEDAL model. This was very beneficial for two main reasons. First, it allowed us to model the direct relationship between the data admission controller and the query inputs. Second, integrating the query plan models and the data admission control logic gave us a better understanding of the correlation between the query results and the stream input volume.
MEDAL can seamlessly be applied to modeling real-time query plans. The same
query plan from Figure 2 is specified in Figure 4 using MEDAL. The different types of query operators are modeled with the help of transitions (transitions
There is an array of real-time data stream applications that use feedback control to adjust to the constantly changing environment and improve system performance [He et al. 2003; Lin et al. 2006]. To model feedback control, MEDAL employs a theoretical control approach which adopts the controller synthesis paradigm from control theory. Given a model of the system’s dynamics and a specification of the desired closed-loop behavior, the objective is to synthesize a controller to achieve the specified behavior. This approach relies on the clear distinction between the system and the controller and requires that the information flow between them is explicitly modeled. We met this requirement by designing two separate MEDAL models - one for the query plan and one for the data admission controller. The two models were then composed into a single application MEDAL model which allowed us to analyze the interactions between the system and the data admission controller.
The feedback control loop in Figure 4 is shown in bold. Transition
MEDAL can be used to model different levels of abstraction. For example, analogously to using Place
Another requirement introduced by the control theoretic approach is that changes in the system are observable [Lee and Markus 1967]. MEDAL achieves
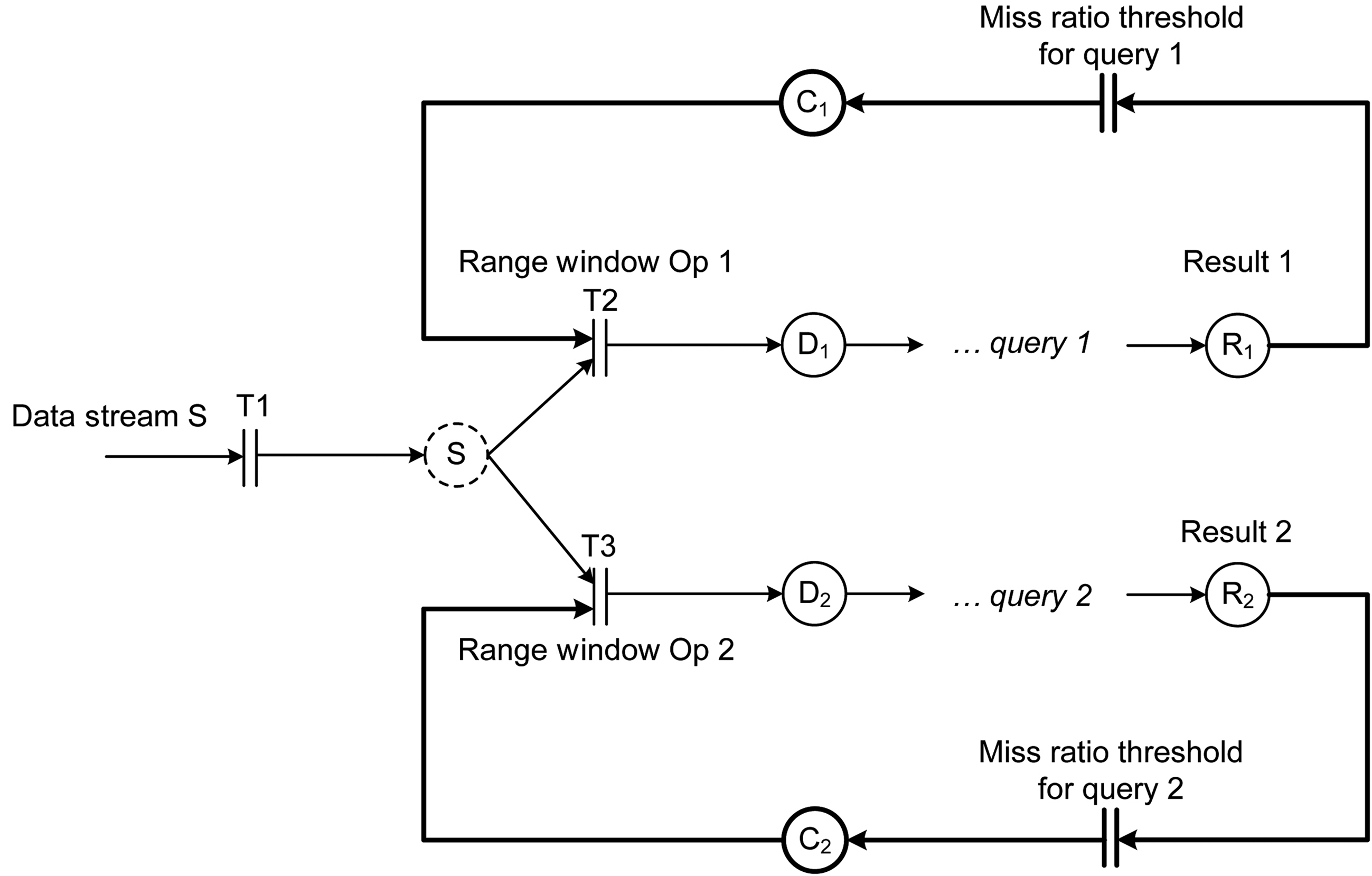
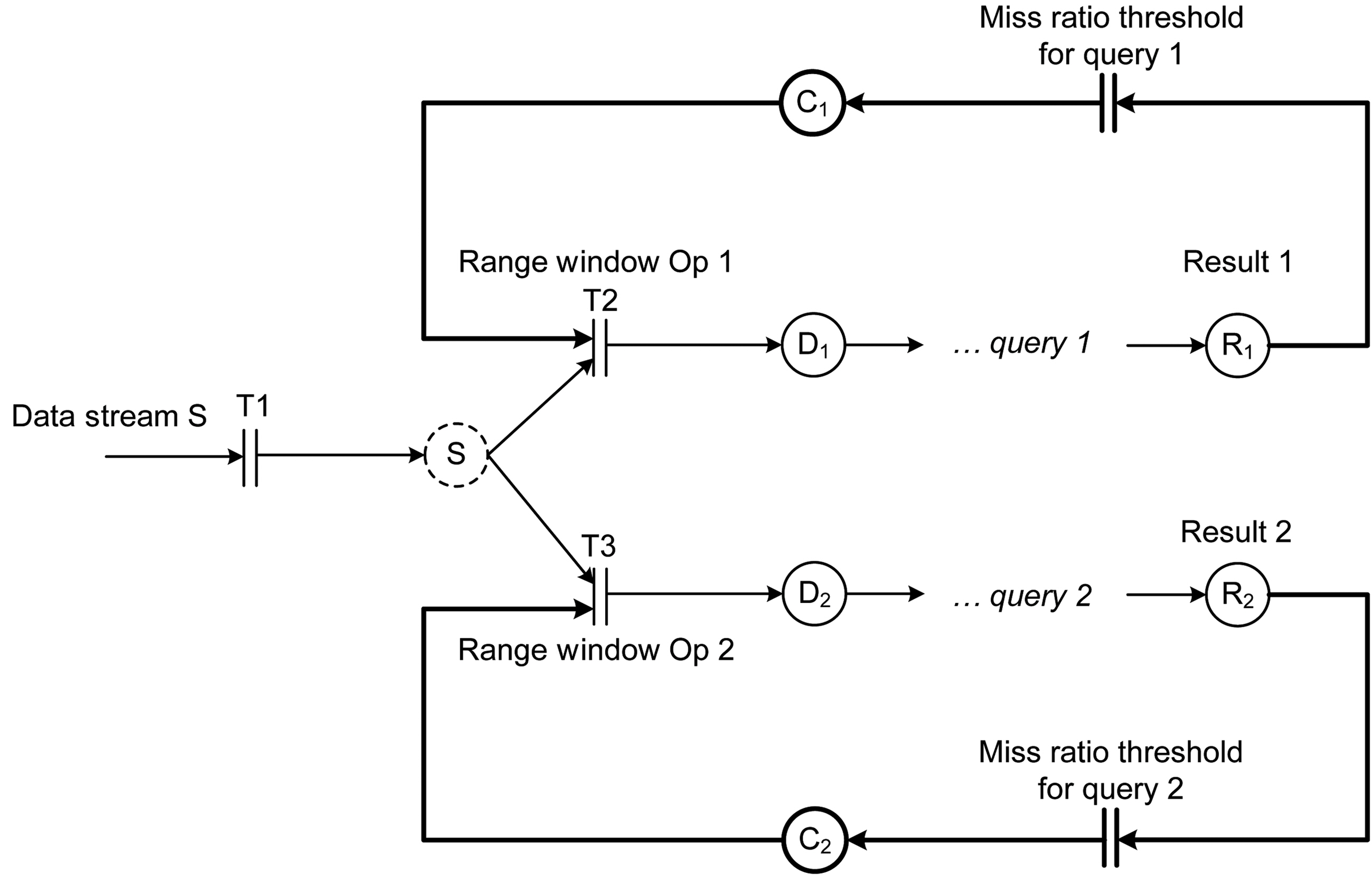
The data admission control needs to be implemented at the query level so that different queries can have different data admission ratios even if they share the same data stream source. The two queries in Figure 5 share the same data stream input
7.1 Query Optimization Analysis
The MEDAL model of a data stream system could be used to analyze query plans, controller logic, and the interactions between them. This analysis could help designers identify possible query plan optimizations and design more suitable data admission mechanisms. Consider, for example, the following scenario: For the query model in Figure 4 we have estimated the cost of each of the query operators. In addition, based on historical workload information, we have also estimated the average selectivity of the operators. The data admission controller has been designed to decrease the data admission rate by x%, where
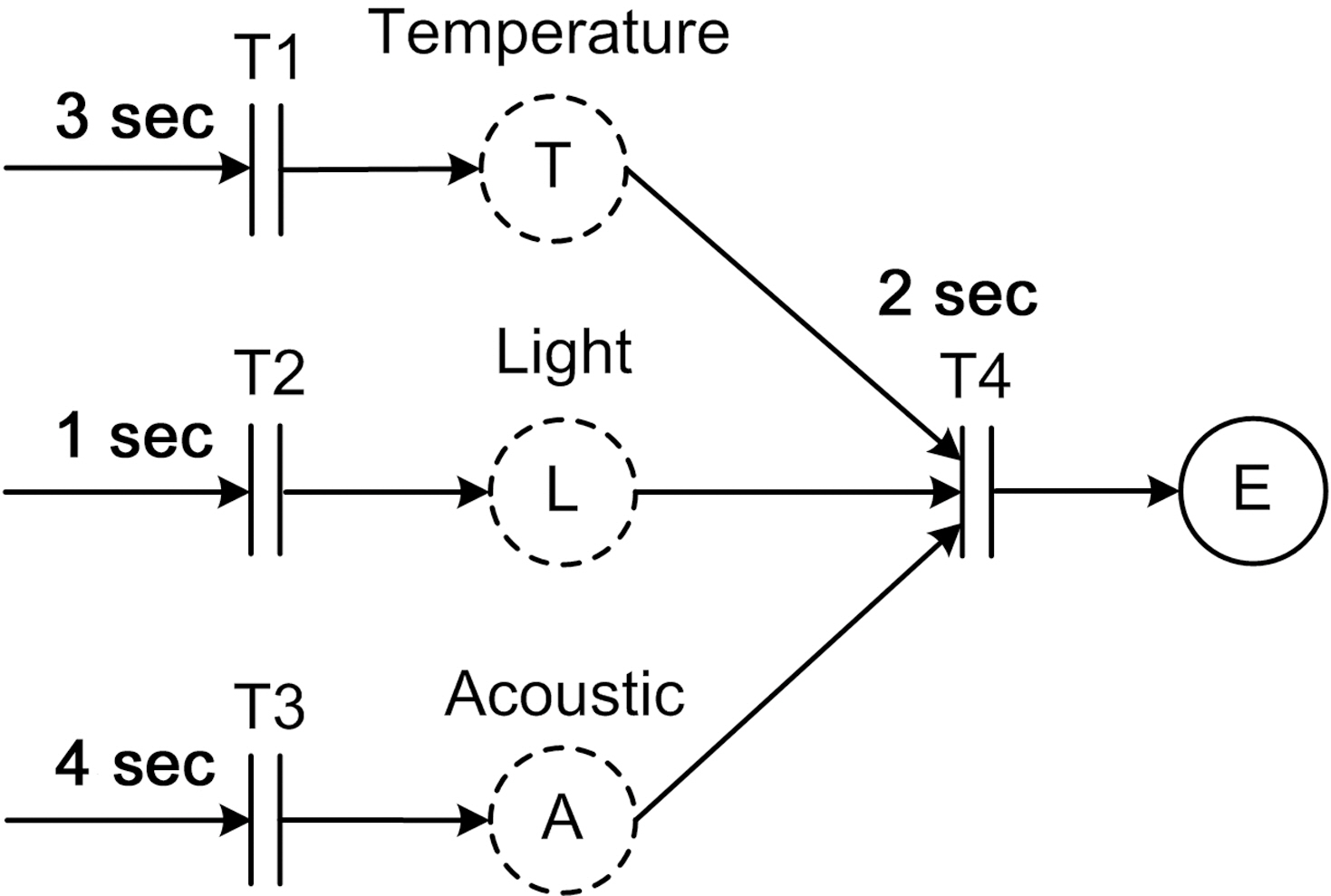
MEDAL can also be used for real-time analysis of data stream network applications. For example, a safety requirement for the explosion detection application could be that explosions are detected within 5 seconds of their occurrence. If the application takes longer to detect an explosion and send an alert, there might not be enough time to evacuate. The MEDAL model of the explosion application could be used to help determine if the application is able to meet this requirement. During the design of the
application, the sampling periods for the temperature, light, and acoustic sensors have been set to 3, 1, and 4 seconds, respectively. In addition, based on knowledge about the system and the environment, the designers have determined that it takes 2 seconds, in the worst case, to process the data, run the explosion detection algorithms, and calculate the result. Since the rest of the transitions in the model represent simple computations, the execution times associated with them could be neglected for this particular application analysis.
Figure 6 shows the time information associated with each transition. Analyzing this model reveals that detecting an explosion could take 6 seconds in the worst case: 4 seconds for sound detection and 2 more seconds for data processing. This, however, means that the application may not be able to meet its real-time requirements. Therefore, either the acoustic sensor sampling period has to be changed, or the system should be altered such that analyzing the incoming data does not take more than 1 second. Similar real-time analysis could be performed for much more complex systems.
In this section we show how MEDAL is used to model different data stream management configurations. We created MEDAL models for the following scenarios:
(1) All queries belong to the same query service class.
(2) There are three query service classes in the system and no data admission control is applied.
(3) There are three query service classes in the system and they share a single data admission controller.
(4) There are three query service classes in the system and each service class has its own designated data admission controller.
We also show the effect of these four configurations on the QoS of the system. We implemented the configurations in RT-STREAM, which is a real-time prototype system for data stream management developed at the University of Virginia [Wei et al. 2006]. RT-STREAM supports the periodic query model and utilizes the prediction based QoS management techniques described in Section 5.
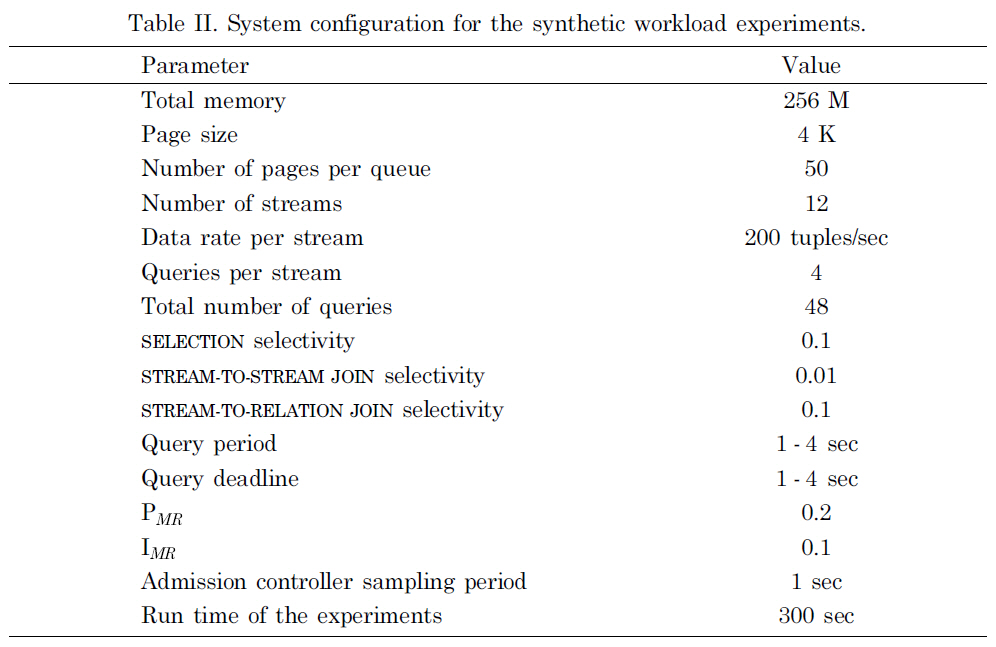
We conducted the performance evaluation using a synthetic workload. The settings for the synthetic workload experiments are shown in Table II. We tested the system performance with both short and long workload bursts. The experiments were carried out on a single machine running Redhat Linux 8.0. The machine was equipped with a 2.8 GHz Pentium 4 hyperthreading processor and 1 Gigabyte DDR 3200 SDRAM memory.
There were 12 streams registered in the system and four queries associated with each of the data streams. The data streams used in the experiments are variable-rate data streams and the average data tuple arrival rate of one data stream is 200 tuples/sec. The arrival of the data tuples conforms to Poisson distribution and the data rate shown is the average arrival rate. The data tuples in the streams are assigned with special values so that the selectivity values are configurable. In the experiments, we
[Table 2.] System configuration for the synthetic workload experiments.
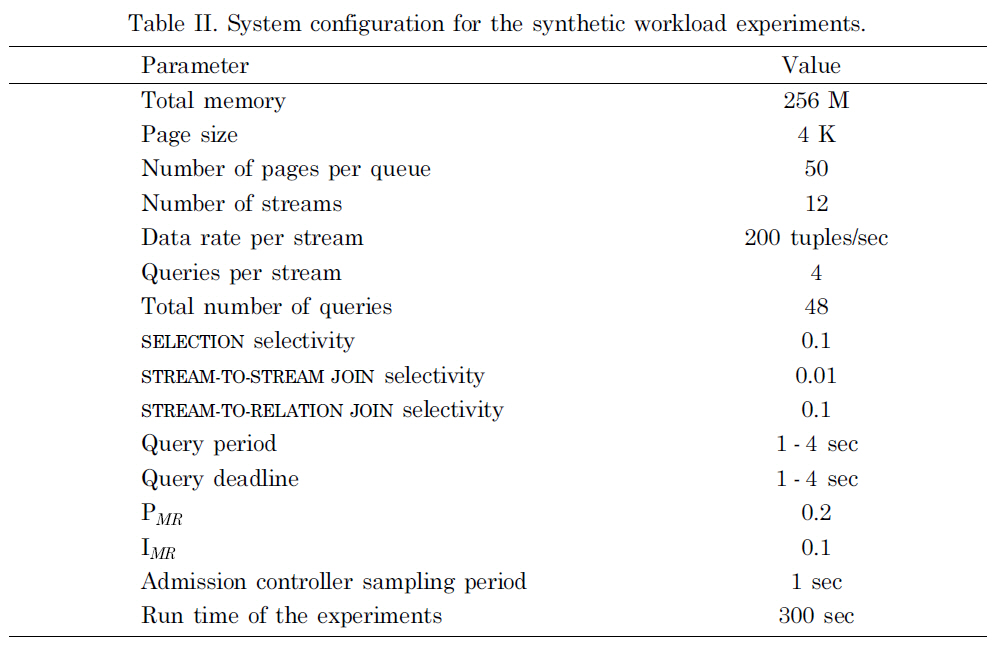
System configuration for the synthetic workload experiments.
set the SELECTION query selectivity to 0.1, the STREAM-TO-STREAM JOIN selectivity to 0.01, and STREAM-TO-RELATION JOIN selectivity to 0.1. The sampling period of the data admission controller was set to 1 second to give fast response to workload fluctuations. The total run time of one experiment was 300 seconds.
The data streams and relations used in the experiments had the following schema:
Stream S (ID : integer, value: float, type: char(8));
Relation R (ID : integer);
We conduct experiments on the following four systems:
(1) STREAM: STREAM is a data stream management system developed at Stanford University [Motwani et al. 2003]. STREAM uses a round-robin scheduler and supports continuous queries. The same set of queries without real-time query specifications were executed on the STREAM prototype in order to compare its system performance to that of RT-STREAM.
(2) RT-STREAM: Data admission control is not used in this system.
(3) RT-STREAM-DACS: RT-STREAM with a single data admission controller for the whole system.
(4) RT-STREAM-DACM: RT-STREAM with multiple data admission controllers -one for each query service class.
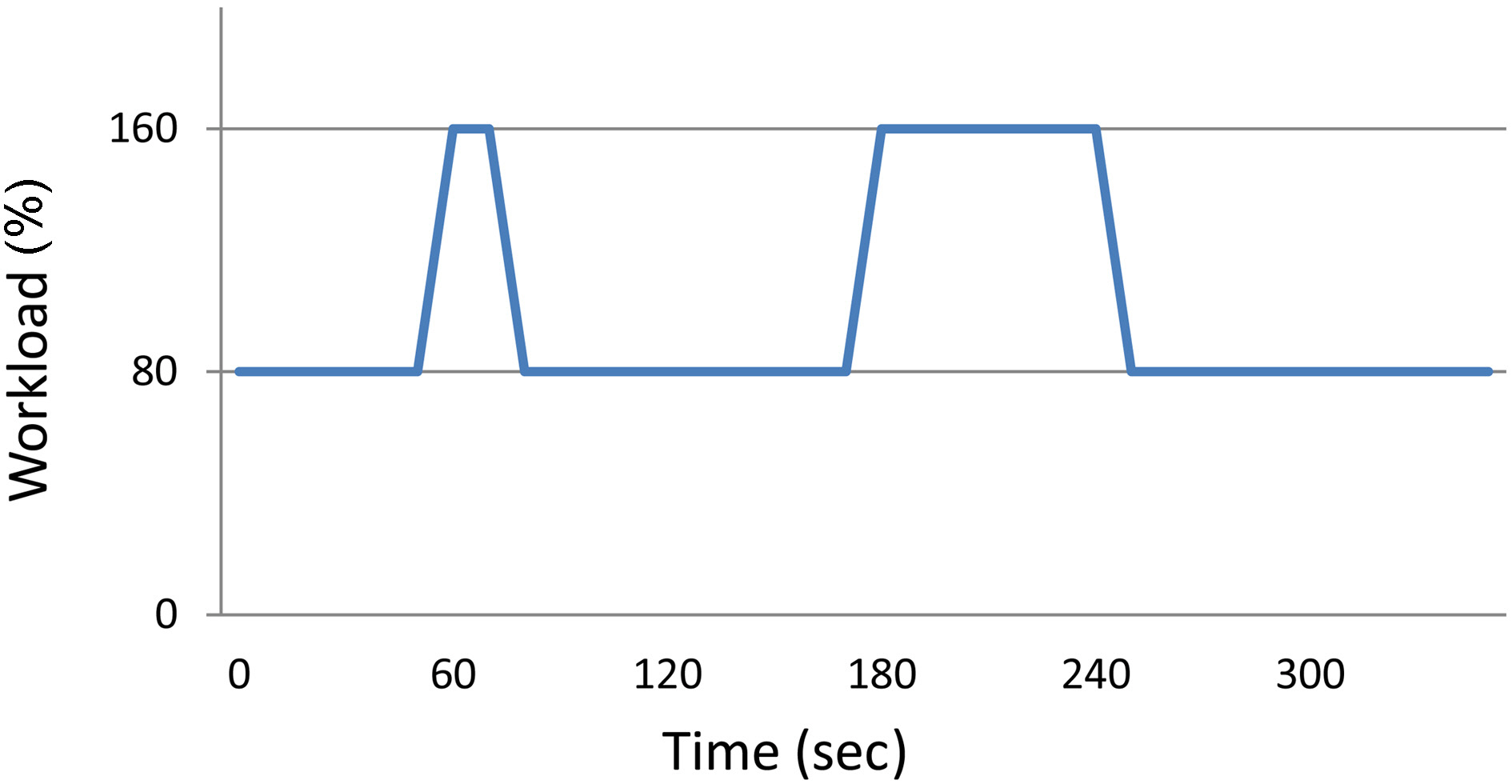
To evaluate the system, we studied the system performance under normal and extreme workload. As shown in Figure 7, the system workload was configured in such a way that under a normal workload, the system CPU utilization was 80%. To evaluate the system performance under a heavy workload, we created two workload bursts during the experiment. These workload bursts were twice as large as the
normal workload and needed 160% of the CPU processing capacity. As shown in Figure 7, the first workload burst was short. It began at the 60
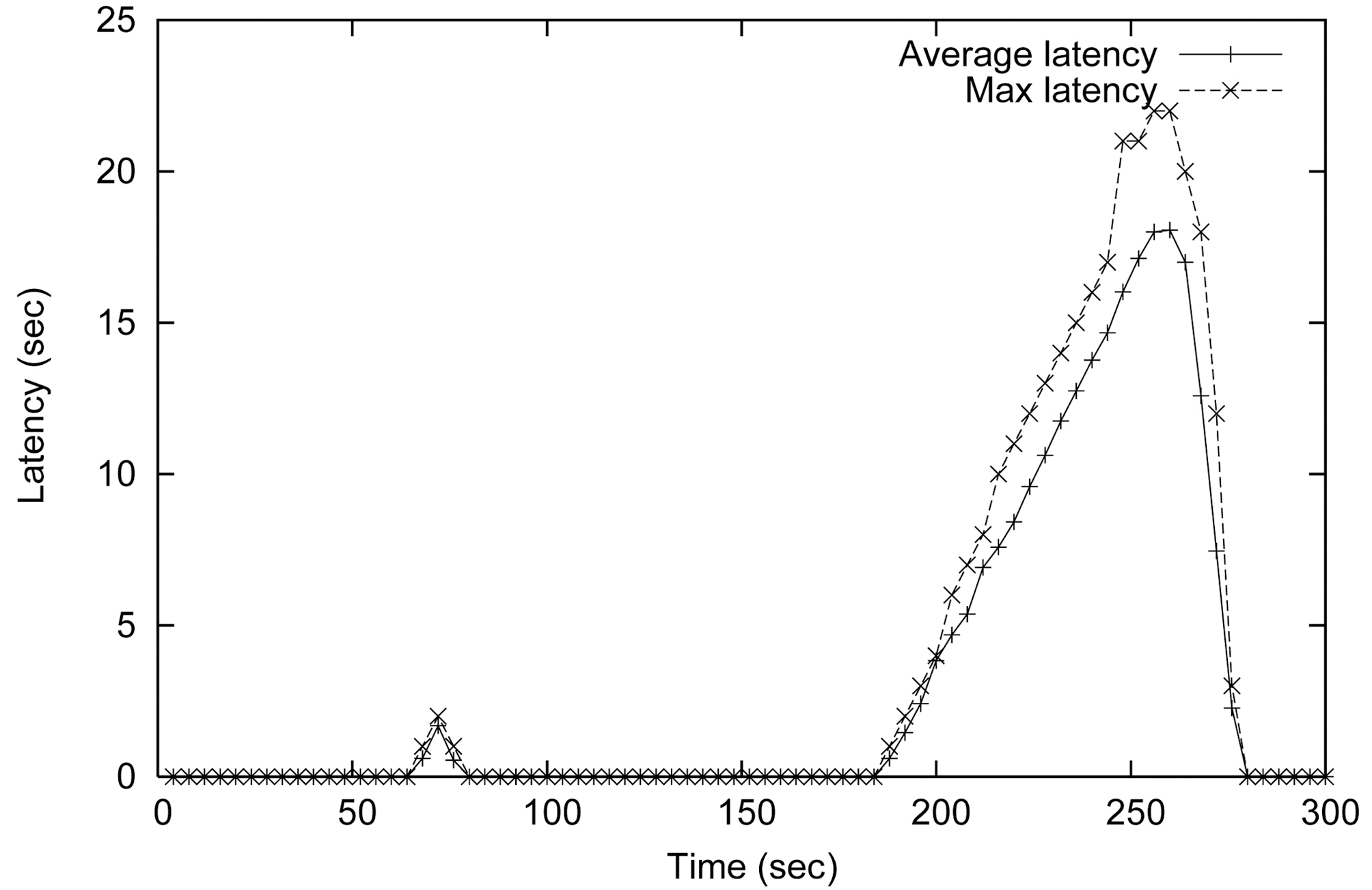
The first set of experiments evaluated the system performance when all queries belonged to the same service class. The experiment results are shown in Figure 8 and Figure 9. As we can see in Figure 8, when the system was overloaded, the latencies of continuous queries increase monotonically with time. The maximum latency reaches as high as 23 seconds. The latency of the system continues to grow even after the
burst ends at the 240
In the periodic query model, the latencies of the queries were bound by the specified query deadlines. As shown in Figure 9, similarly to the latency of the continuous queries, the short-term miss ratio of the periodic query continued to increase until the burst went away at the 240
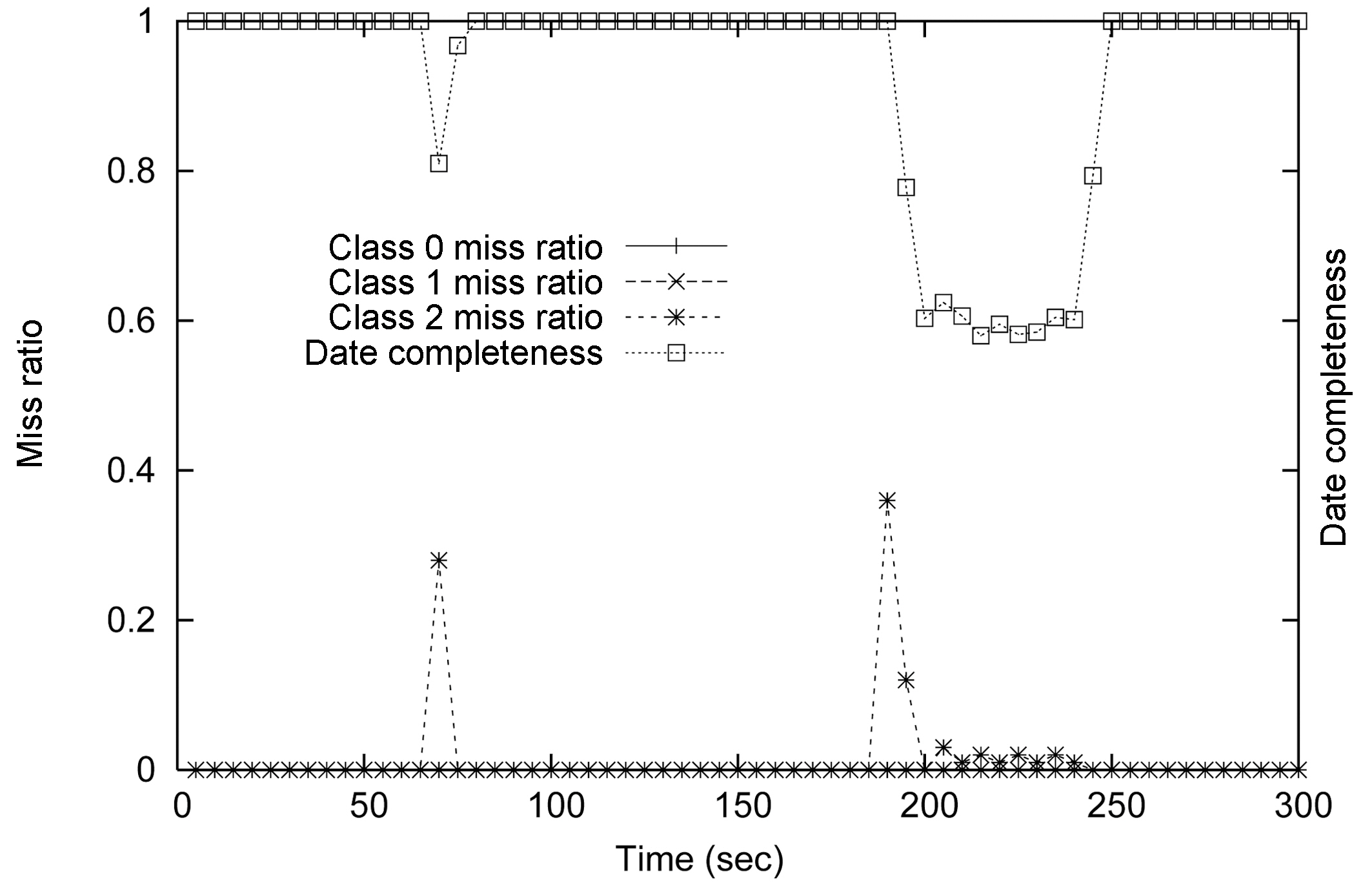
The MEDAL model for the RT-STREAM-DACs configuration with one query service class is shown in Figure 10. There is one data admission controller,
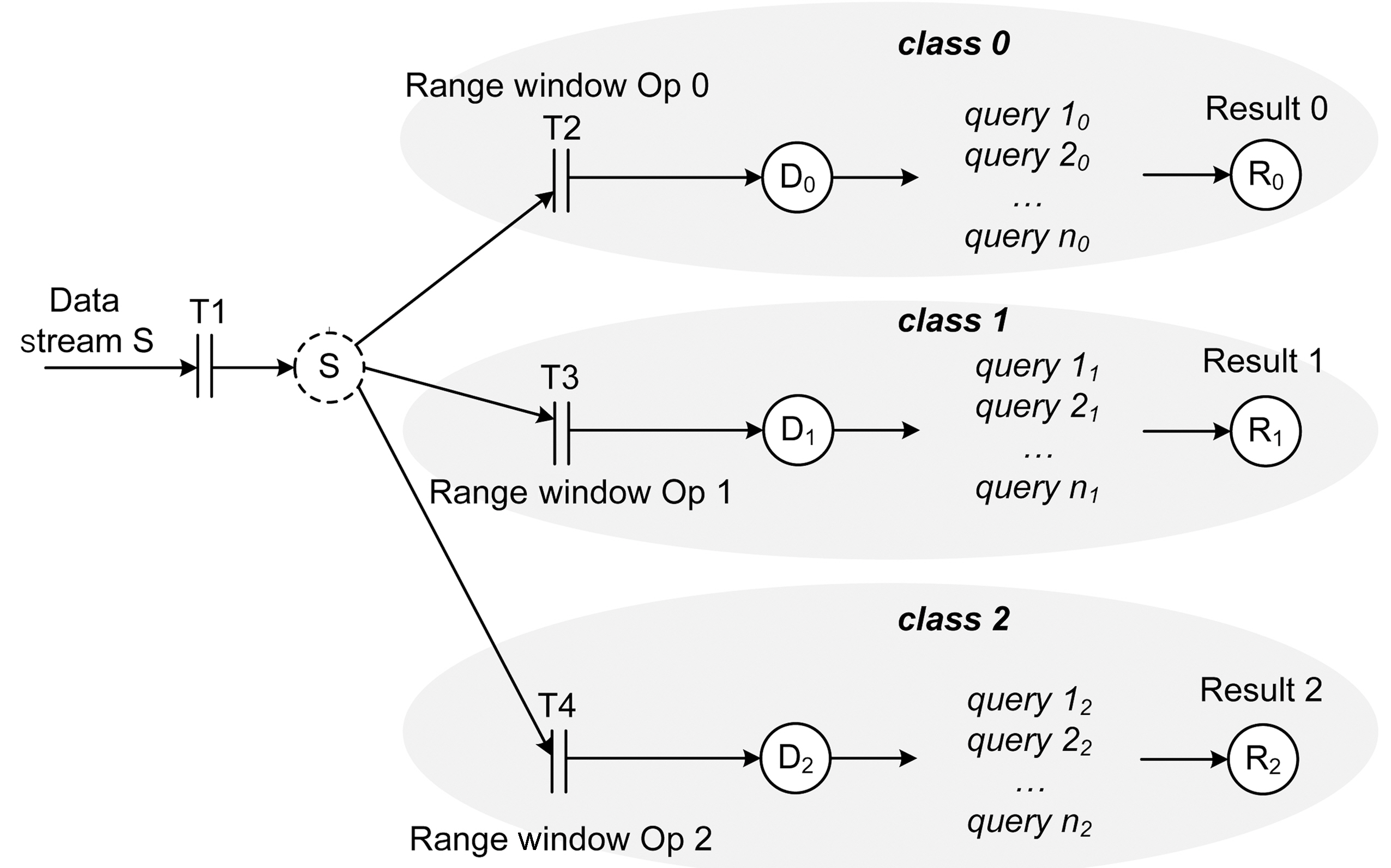
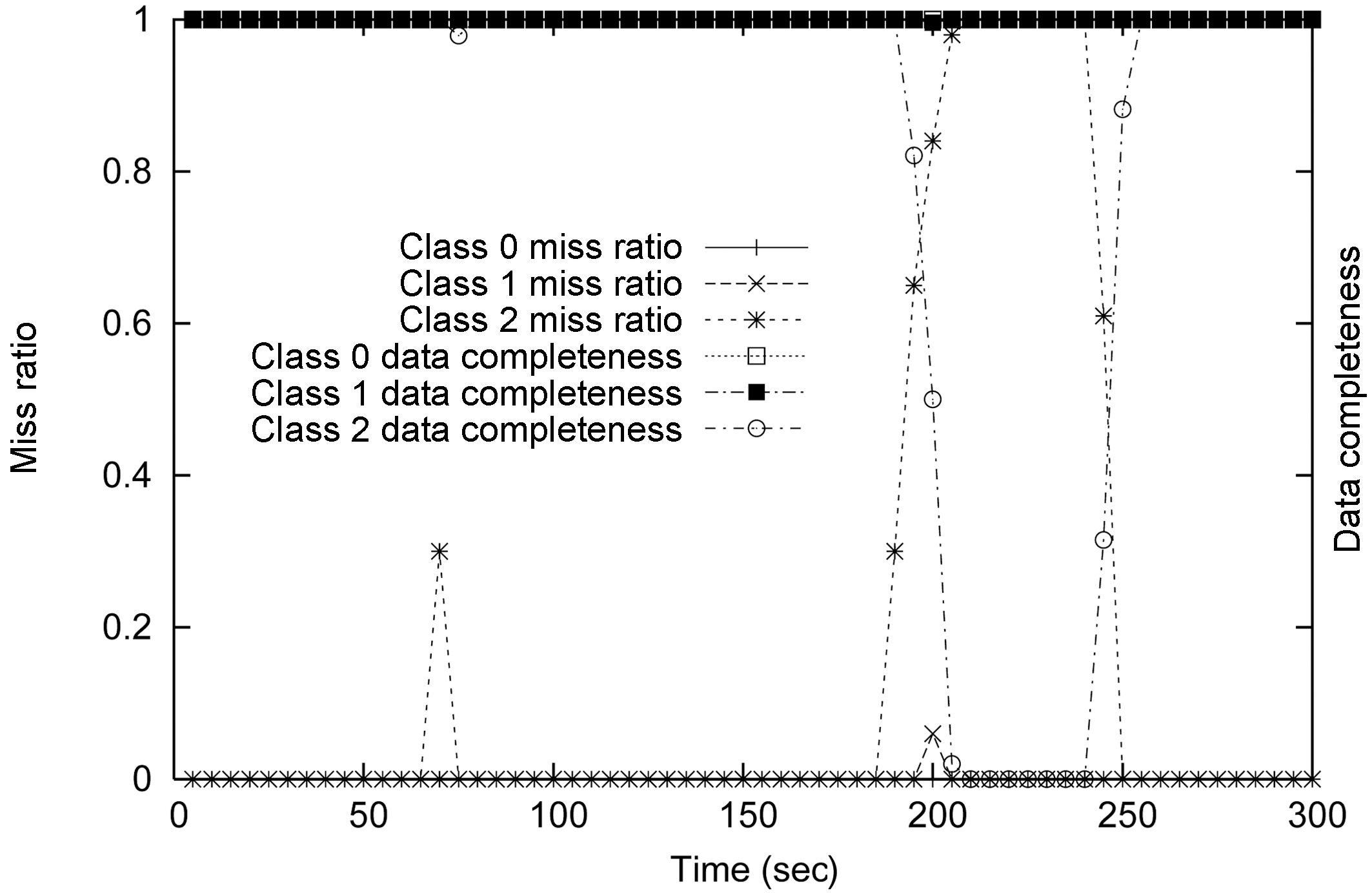
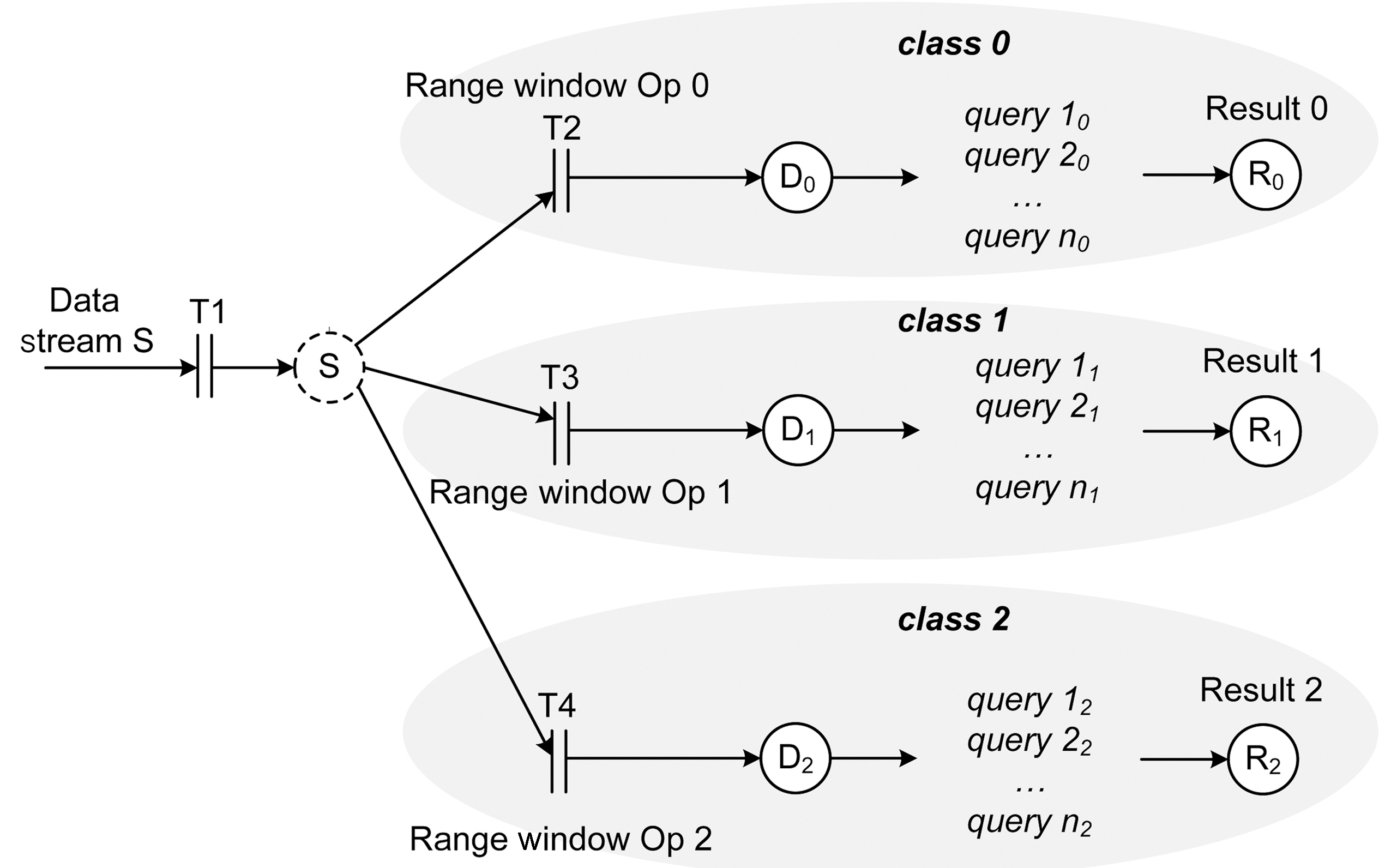
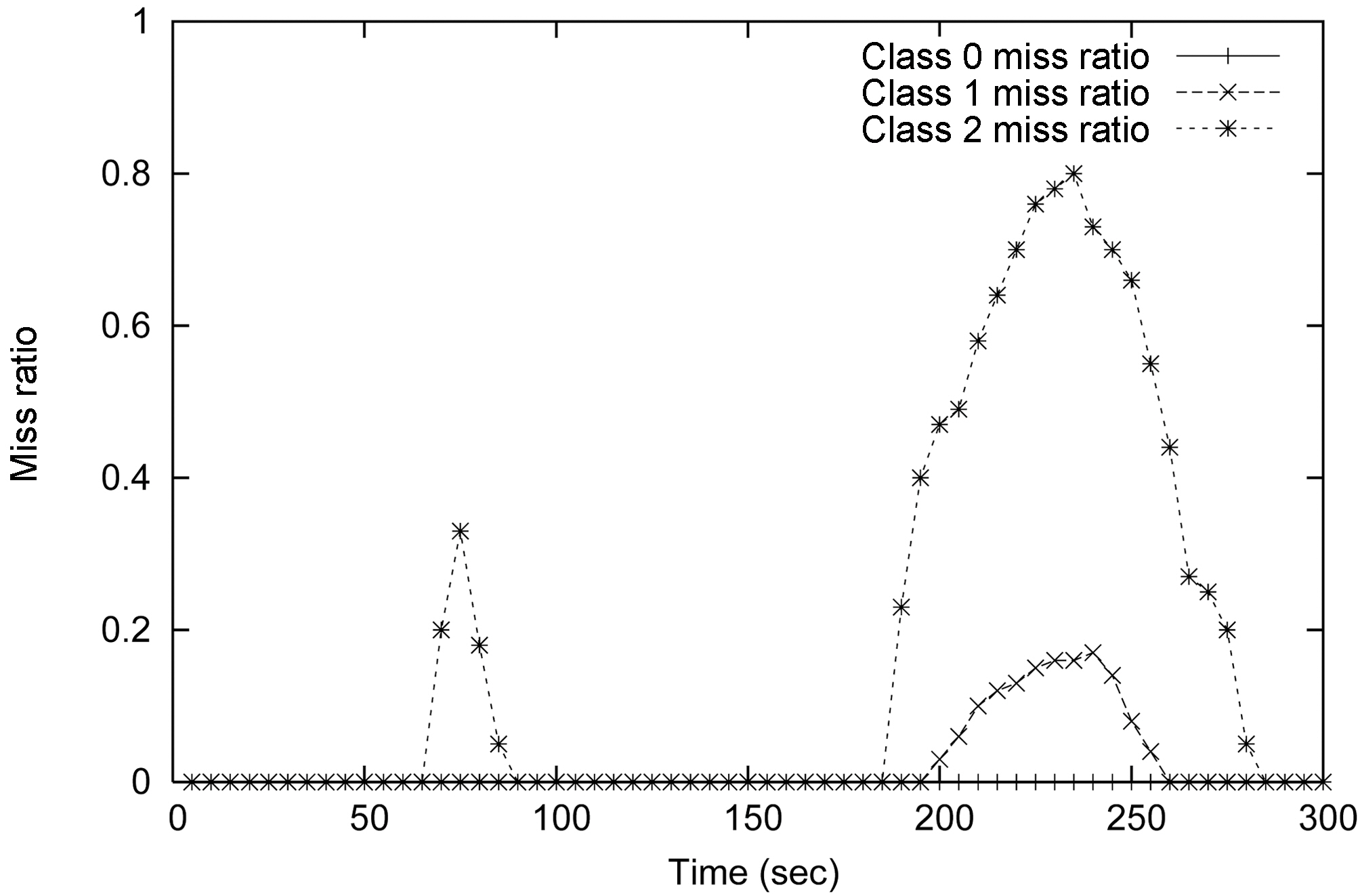
Differentiated services are required by many applications. In case of overload, the system has to guarantee that the most important set of queries get processed. The second set of our experiments tests the service differentiation capability of the system. In this set of experiments, 12 streams and the associated queries are divided into three service classes -
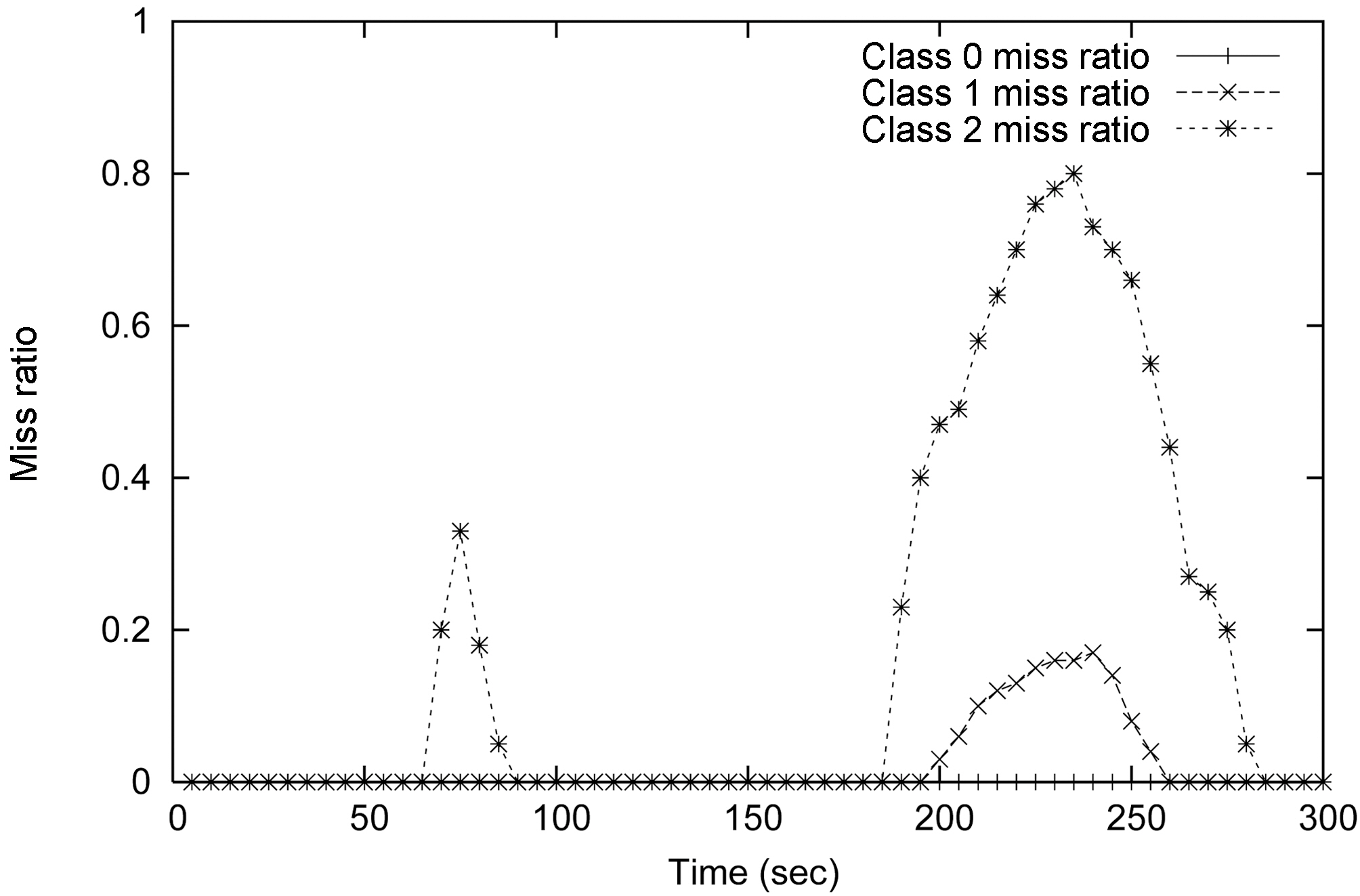
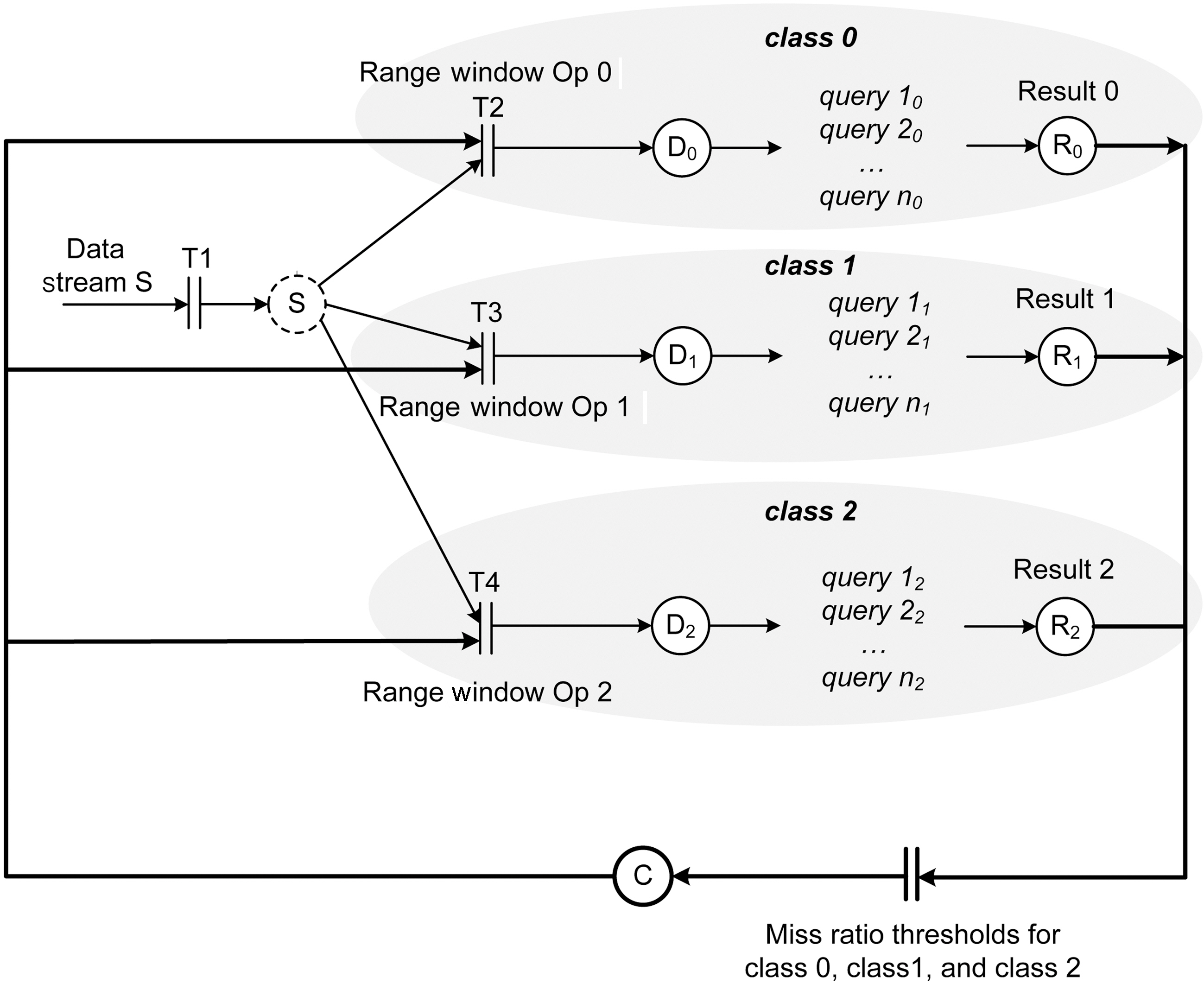
The results from this experiment are shown in Figure 12, Figure 14, and Figure 16. Figure 11 shows the MEDAL model of RT-STREAM without data admission control. The three query service classes share data stream
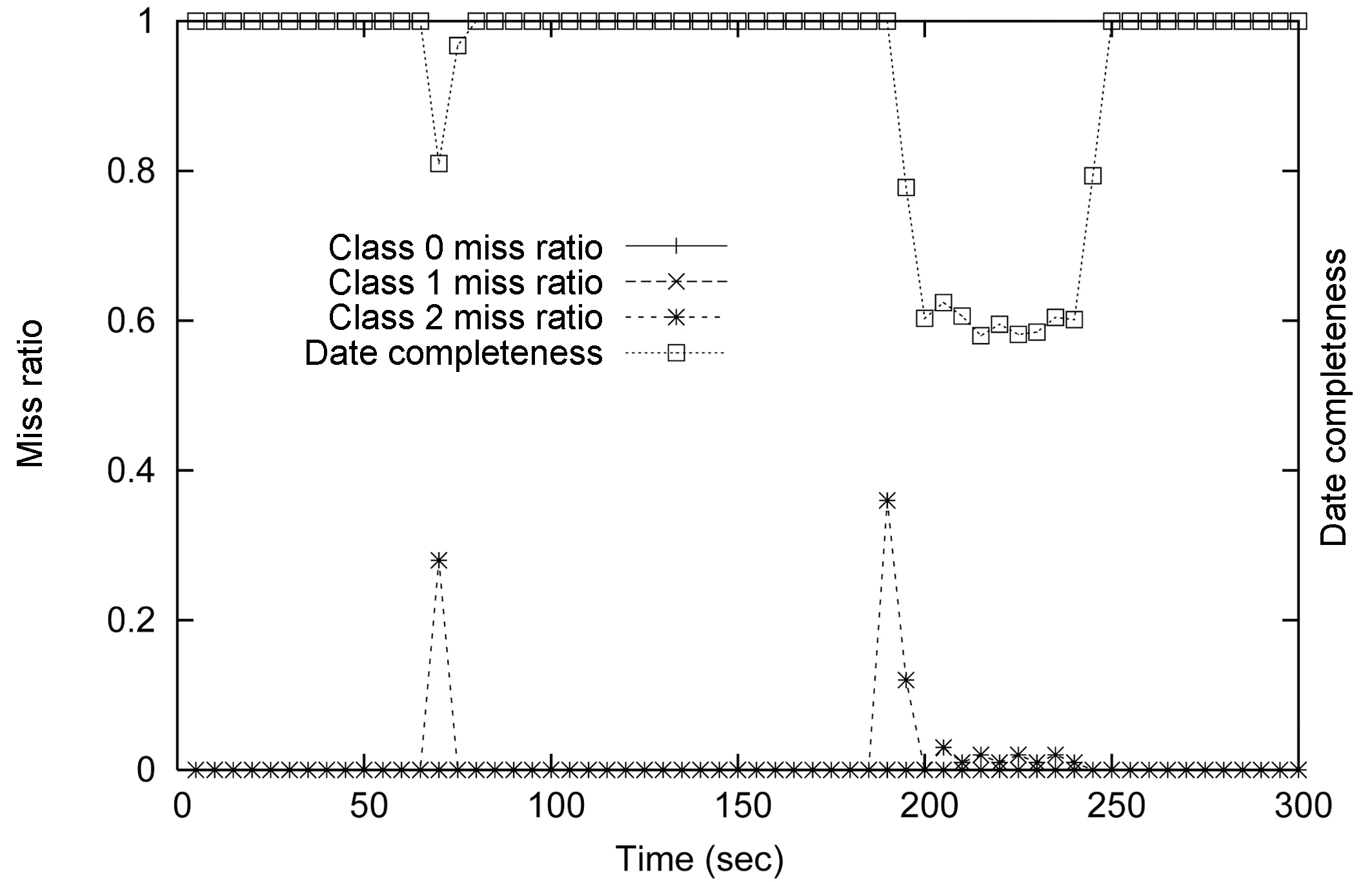
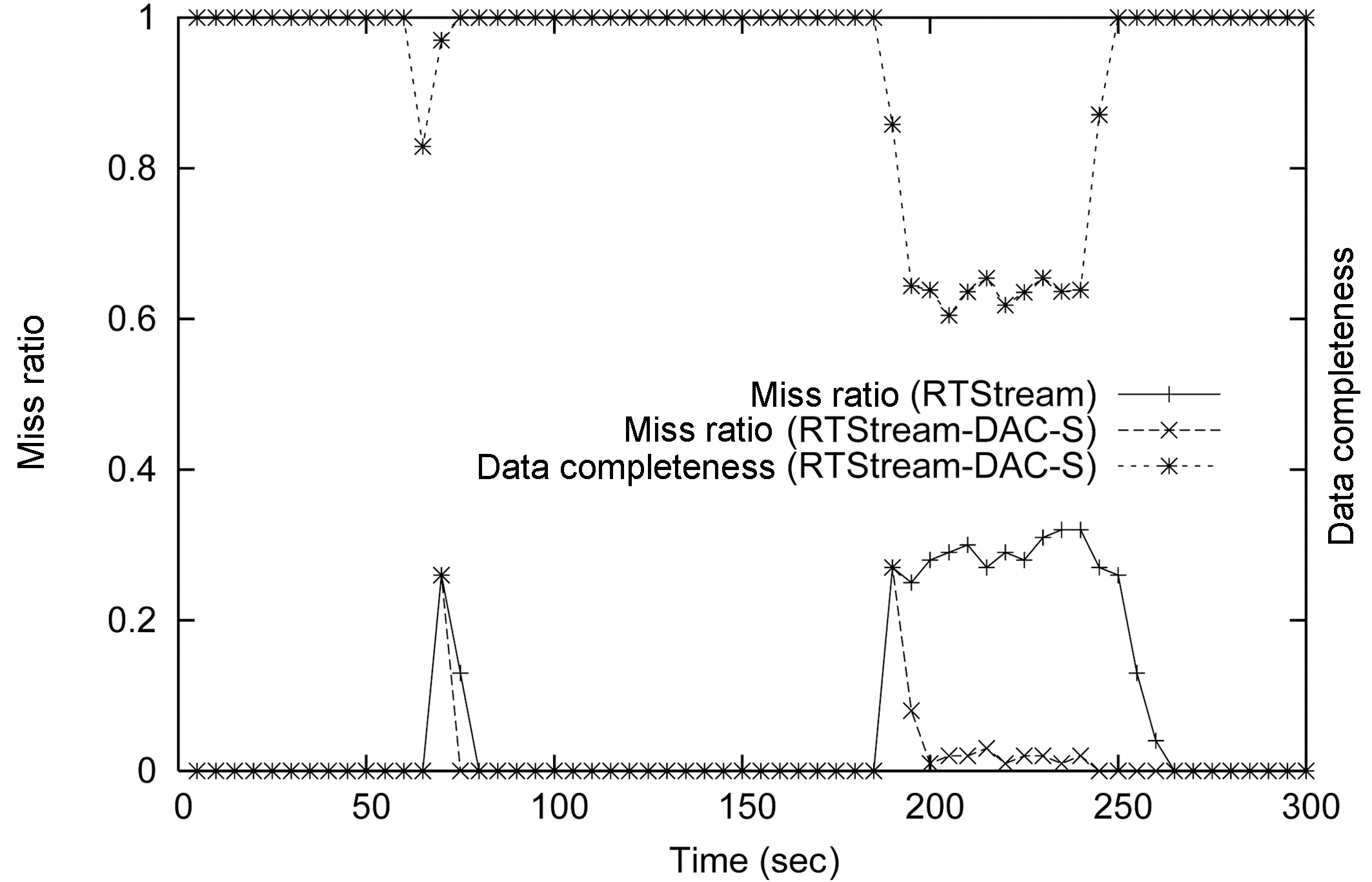
Figure 14 and Figure 16 show the miss ratio and data completeness of our two data admission schemes. The first one is called RT-STREAM-DAC
class has its own set of queries. As the queries are executed, the controller receives information about the missed deadline ratios for the three classes and determines whether more or less data tuples should be admitted into the system. The decision of the controller is then propagated to the three service classes.
The results for RT-STREAM-DAC
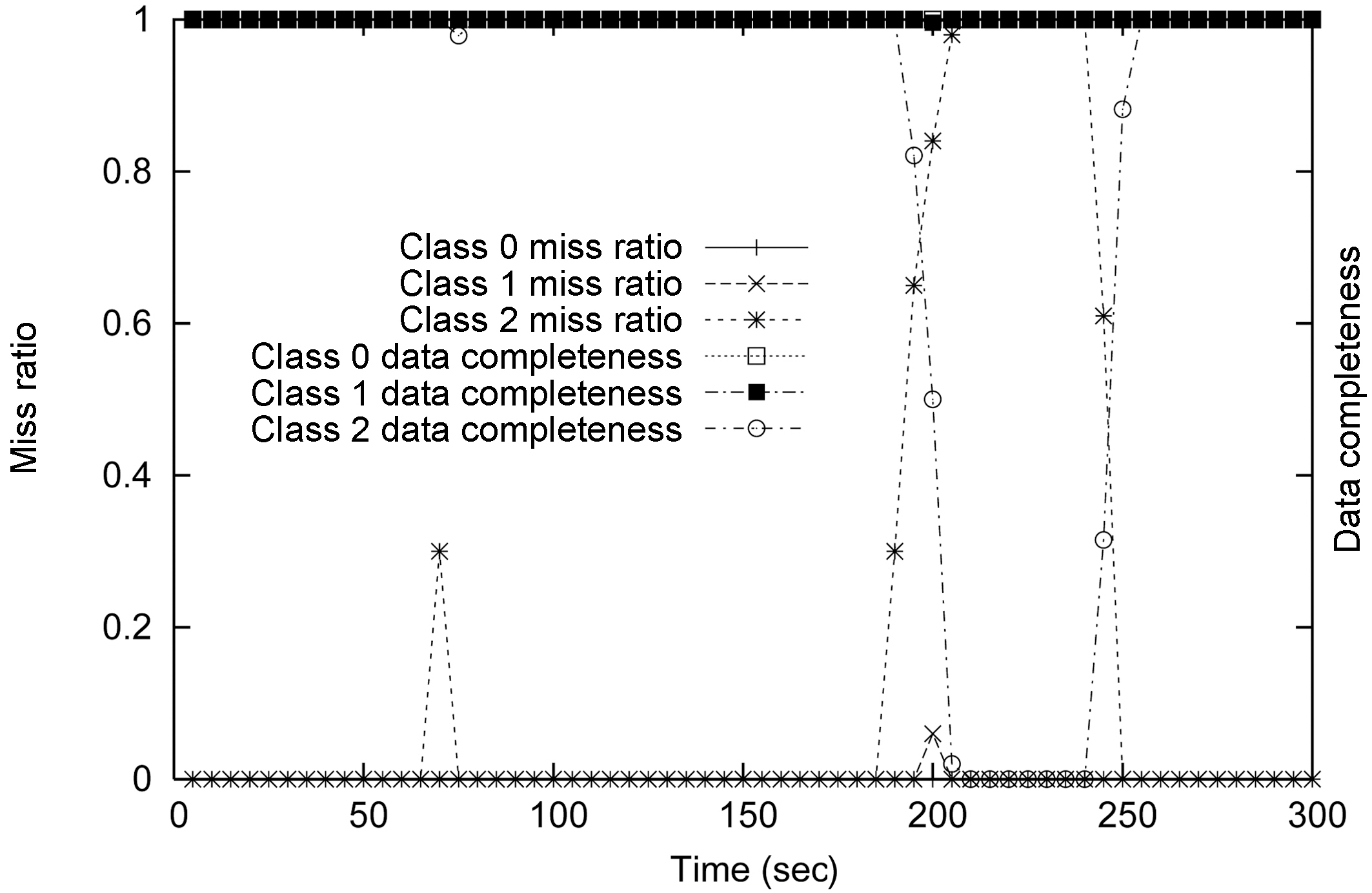
The second data admission scheme is RT-STREAM-DACM. Each of the service
classes in this scheme has its own designated data admission controller. Figure 15 shows the MEDAL model for this data admission scheme. Although all three of the service classes receive data from the same data stream
The results for the RT-STREAM-DAC
Comparing Figure 14 with Figure 16, we can clearly see the QoS tradeoffs in the system. If the application is willing to tolerate low data completeness ratios, the query miss ratios of different service classes can be substantially improved. If the miss ratios of the lower service class queries can be sacrificed, the service quality of the higher class queries can be preserved.
9. CONCLUSIONS AND FUTURE WORK
In this paper we showed how MEDAL can be used to model and analyze real-time data stream queries, QoS management mechanisms, and the relationships between them. Unlike previous work, where query models and system control logic are designed and analyzed separately, MEDAL allowed us to merge these two components into a single comprehensive system model. The advantage of this combined model is that it can be used not only to predict the workload and estimate the query cost, but also to model and analyze the interactions between the input and output of the query plans and the data control mechanism, which gives us a much better understanding of the system.
In our performance evaluation we used a synthetic workload to test the system’s behavior under heavy workload and workload fluctuations. Our results revealed the benefit of using a periodic query model as an alternative to the continuous query model for real-time applications. We also designed and implemented data admission as an overload protection mechanism to reduce the system workload in case of an overload and study the QoS tradeoffs presented by the admission controller. Our results showed that when there was a dedicated controller for each query service class, if the application is willing to sacrifice the miss ratios of the queries from the lower service classes, the higher service class queries can benefit significantly.
For future work we plan to design an automated data admission controller that can preemptively alter the data admission rates and thus maintain high data completeness while ensuring low deadline miss ratio. This data admission controller will take advantage of context information such as spatial and temporal data characteristics, and stream behavior patterns extracted from historical data. We will also implement a MEDAL tool which will allow system designers to conveniently build and analyze data stream applications. This tool could be used to perform operator cost analysis and selectivity estimation. It will also help model dependencies between the data stream system and the surrounding environment, which could be extremely useful for context-aware workload predictions.