Categorization and classification are methods used by humans to organize entities, thoughts, objects, and phenomena. These processes are related to the organization of knowledge and the way people learn, remember, and know about the world. There is a basic human drive to categorize as it allows people to make useful assumptions about new things by making comparisons with well-known things. In common language, the terms classification and categorization are not clearly distinguished, as for instance, dictionaries use both terms indistinctly. However, in Library and Information Science (LIS) some make the distinction (e.g. Taylor & Joudrey, 2009, p. 376): “Categorization can be seen as amorphous or less well-defined grouping; whereas classification can be viewed as a comprehensive hierarchical structure for organizing information resources on linear shelves.” In this context, classifications or modern bibliographic classifications emerged in the late 1800s and early 1900s to handle early stages of the print revolution, i.e., to organize, store, and retrieve bibliographic materials. In light of the proliferation and use of simple categorization systems and classifications in physical and electronic environments, such as the use of BISAC (Book Industry Standards and Communications) and other verbal categories in libraries and websites such as Amazon and Google Books, we are reviewing and systematizing the features, functions, and components of library classification systems, according to the LIS literature and tradition of authors such as Ranganathan, that should be considered or at least known in the design and choice of classifications for these new environments.
2. LIBRARY CLASSIFICATION SYSTEMS
A classification is a tool for the organization of the phenomena of the universe or any of its parts or constituents. It groups objects into categories/classes based on shared properties with the purpose of bringing like items together. A modern library classification is a classification of knowledge as it is contained in documents of all sorts. It came into being for the purpose of arranging and retrieving information resources. In libraries, later, it was used for arranging classified catalogs and other information retrieval tools such as bibliographies. A modern library classification is more than knowledge classification, and beyond grouping it has many intellectual and mechanical functions to perform. Since their modern origin in the 1870s, many library classification systems have been designed to organize and access knowledge in libraries.
2.1. General and Special Classifications
A library classification may be general or special in coverage of subject areas. A general classification covers all subjects in the universe of knowledge. A special classification concentrates on a narrower range of topics, or the goods manufactured or services provided by the organization for which the classification has been developed. A special classification also refers to a classification of documents by form such as government reports, fiction, maps, or music. Such a classification is for micro-documents and in-depth subjects.
The taxonomy of the different types of classification has been expanded and systematized by Koch et al. (1997) as follows: universal schemes, national general schemes, subject specific schemes, and home-grown schemes. Universal schemes are intended to classify the entire universe of human knowledge for use by anyone, anywhere. Examples are the Universal Decimal Classification (UDC), the Colon Classification (CC), the Bliss bibliographic classification (BC), the Dewey Decimal Classification (DDC), and the Library of Congress Classification (LCC). National general schemes are universal in subject coverage, but intended for use in a single country. Examples are the Nederlandse Basisclassificatie (BC), the Sveriges Allmáma Biblioteksfórening (SAB), and the Nippon Dewey. This category may also include translated versions of the DDC in various languages incorporating provisions for the classification of local material. Subject specific schemes are designed for use by a particular subject community or domain. Examples are the National Library of Medicine (NLM) scheme for medicine, Iconclass for art resources, Moy’s Law Classification, and the London Education Classification, among many others. Home-grown schemes are those devised for use in a particular service or retrieval system or in a library. Examples are Yahoo!’s categories and reader-interest classifications. There is an abundance of homemade library classifications, but these do not survive long in the era of standardized systems.
On the other hand, although the idea of special or subject specific classifications presupposes a greater level of detail, some general classifications, notably the UDC, LCC, and BC-2 (Bliss bibliographic classification, second edition) have been developed in sufficient depth of details to enable them to be adapted to moderately special collections. Thus, the debate between special and general classification is inconclusive. Ranganathan visualized his Colon Classification as a trunk of an elephant: nimble enough to pick up a small twig and strong enough to carry a heavy log of wood (Ranganathan, 1964). The Library of Congress Classification, with its 21 main classes in 29 parts bound in 50 volumes, is
Some of the main general classification systems are:
• Dewey Decimal Classification (1876+) / by Melvil Dewey • Universal Decimal Classification (1905+) / FID (International Federation for Information and Documentation), now UDCC (Universal Decimal Classification Consortium) • Expansive Classification (EC, 1892) / by C.A. Cutter • Library of Congress Classification (1904-) • Subject Classification (SC, 1906-1939) / by J.D. Brown • Bibliographic Classification (BC, 1940-1953) / by H.E. Bliss • Colon Classification (1933-1987) / by S.R. Ranganathan • Bibliothecal Bibliographical Klassification (BBK, 1960-1970) / by VINITI (All-Russian Institute for Scientific and Technical Information), Russia • Rider’s International Classification (RIC, 1961) / by Fremont A. Rider • Information Coding Classification (ICC, 1970) / by I. Dahlberg • Bibliographic Classification second edition (BC-2, 1977-) / by J. Mills and V. Broughton • Broad System of Ordering (BSO, 1978) / by Eric Coates
Of these, the DDC, UDC, and LCC are considered the big three systems. The CC and BC-2 are ideal and scientifically sound systems, arguably more complex and grounded than the previous three (see for instance Ranganathan, 1967). However, they have not been implemented and used as widely as the DDC and UDC due to lack of editorial support or a more aggressive marketing of institutions such as OCLC (Online Computer Library Center). The BSO and ICC are not shelf classifications, whereas the fate of the Russian BBK is not known. The rest, namely EC, SC, BC, and RIC, are now only of historical interest.
Over the years, the features of these classifications have evolved and with experience been standardized. A library classification is a system having mutually related components or subsystems with the objective of organizing knowledge in libraries. It has its anatomy (hardware) showing its visible and invisible components, each of which has its supporting functions (physiology).
2.2. Functional Requirements of Bibliographic Classifications
It has been claimed that modern bibliographical work demands a standard classification which:
1. brings together related classes and subjects; 2. is sufficiently subdivided to index everything of its class under the sun, though the level of specificity varies; 3. is capable of further extension and subdivision, as our knowledge grows; 4. is recognized widely so that the users may easily find their way in it and with it; 5. has an extensive index of its classes in alphabetical sequence in order to navigate schedules; 6. has moderately mixed notation which shows hierarchy, is easy for arranging and finding the classified arrangement, is hospitable to new subjects, and allows interdisciplinary combinations; 7. is not subjected to too frequent revision or any drastic reorganization, and is not under experimentation; 8. has a body to market and maintain it with adequate resources and expertise; and 9. is available as a web based online database.
Practically, a library classification performs three functions:
1. Linking an information item on the shelves with its catalog entry. An item’s class number forms part of its call number, and the latter is unique for every item in the library. The library classification thus enables items in a library catalogue to be located from the shelves. 2. It is a tool for information retrieval; hierarchy easily allows the broadening and narrowing of search by truncating a class number from the right; all the alphabetical subject access tools such as subject headings lists, thesauri, and ontologies inherently involve classification of one kind or the other. A thesauro- facet is more than a classification. Use of classification for retrieving information on the web is increasing (Satija & Martínez-Ávila, 2014). Ranganathan’s chain indexing is an eminent example of the use of classification for information retrieval (Vickery, 1972). The Classification Research Group (CRG, London) established in 1952 in its manifesto has declared facet classification as the basis of all information retrieval both in manual and machine environments (Maltby, 1978, p. 225). 3. Facilitates browsing the collection, which results in serendipitous discoveries. This is called unknown item approach. In addition, by browsing, users can expect to find related subjects nearby. However, due to the limitations of linear order and division by discipline, not all related subjects can be collocated. The mode of classification is to group together by discipline the topics that the library users are most likely to see together (both on library shelves and in digital collections). This is done by arranging documents in a filiatory sequence, or helpful order. Arrangement of documents or their surrogates is an attempt to suit as many of the users as possible as much of the time as possible (Curwen, 1978).
2.3. Ideal Functions of Library Classification Systems
An ideal library classification system is supposed to have the following broader functions in the order of their generic importance:
1. Cognitive function (Mapping of knowledge) 2. Bibliographic function (Information retrieval) 3. Shelf arrangement function (Locating and browsing documents)
A classification system which performs an upper function also performs lower functions equally well. This means that a cognitively sound classification is equally good at information retrieval and shelf arrangement of documents. A bibliographic classification will also be good at shelf arrangement, but may not be good as a cognitive system. The systematic arrangement of knowledge or of the documents in a collection translates into the following functions:
1. Gives us an overview of the structure of the subject field covered; 2. Helps in the locating of documents, either directly or through the catalog. In this age, the document is no more the unit; one can retrieve a chapter or a paragraph on the one hand, and a group of documents on the other; and 3. Allows meaningful browsing of documents in stacks or their surrogates in a bibliographic database.
The features that a bibliographic classification requires in order to achieve these ends are: a helpful order of subjects at all levels, a brief memorable notation, and a host of techniques and devices for number synthesis.
2.4. What is Necessary for a Library Classification System?
A library classification system should be:
• explicit, recorded, and unambiguous with clear notes and instructions with examples • available to both classifiers and users • designed to comprehensively mirror the cognitive structure of subjects to potential users • designed to cover the literature, information, or knowledge base which it is supposed to organize. In other words, it should be based on literary warrant • preferably made available in varied but interoperable versions of details to suit libraries of different sizes
2.5. Print and Machine-Readable Formats of Classification Systems
Since the last decade of the previous century, most of the living classification systems have converted their print format into machine readable databases. The DDC, UDC, and the LCC are available both in print and machine readable format. Now the machine readable database is the main source file while the other versions, including the print edition, are its byproducts. In the beginning, the electronic version was used only to help the editors in the editing and publishing of the system. But now the electronic versions have been made available to the users mostly on the web and have many additional valued features apart from being easily kept updated by the publishers. Classification systems in a machine readable database, which these days are in MARC-21 Concise Format for Classification Data, have the following functions (Slavic, 2008):
• searching and browsing of classification by notation; the hierarchy allows to broaden or deepen the search to any point from the right end • searching notation through an associated verbal expression, that is index and synonymous terms • sorting and displaying of schedules in various layouts • automatic tracing of hierarchical and associative linking • tracing of system rules to the area of their application • navigation between tables, facets, and subject areas • tracing historical data through a scheme’s lifespan (‘replaces/replaced by’) • various outputs and exports • identification of classes independently of notation
On the other hand, an online classification system does not logically or intellectually differ from its print version, though it has many add-on functions.
2.5.1. Electronic Dewey
The Electronic Dewey, which is a highly value added online version of the DDC, can be searched by words or phrases, numbers, index terms, and Boolean operations. Captions can be browsed and hierarchies can be displayed. An entry also shows frequently used LC subject headings associated with a Dewey number, along with a sample bibliographic record. The Electronic Dewey enables users to classify materials quickly and efficiently. Its latest manifestation is called WebDewey 2.0.
Unlike the print editions, the WebDewey is not constrained by physical size and space. The database includes all built numbers from the relative index of the print version and thousands more added to the electronic version. It also includes the segmentation (prime) marks used by the Library of Congress to show either the end of an abridged number or the beginning of a standard subdivision. A convenient work area displays and stores the parts of the Dewey number being built as one moves among the schedules and tables for instructions (Satija, 2013, pp. 21-23).
LC subject headings and BISAC headings have been added to each class number by statistical matching. These headings provide additional terms for searching. In WebDewey movement of upward and downward hierarchies is possible by highlighting and clicking. If a number or term is dragged and dropped into a search window, the search for number or the term will begin. Dragging and dropping a Dewey number will show the full record display of the number including caption notes, relative index entries, and associated Library of Congress Subject Headings (LCSH). If the term is dragged and dropped into an index window then the relevant part of the Relative index will be displayed, looking like that of the printed relative index.
There are standard as well as customizable on screen views for the user to set. The standard views are:
a) Search view—search window and DDC number window b) Browse view—search window, DDC pages window, and DDC number window c) Scan view—Index window, Search window, and DDC number window d) Summary view—DDC summary window, Search window, DDC pages window, and DDC number window
In any view users can:
• maximize any window to see a larger display • choose display to see appropriate LCSH • choose bibliographic record to see a sample record using the number selected • change LCSH to review the frequency of headings used with the number • print contents of a window may by choosing Print; choose Notes to make a permanent record of a DDC number and its specific use • choose Past to review the searches made during the current session • use Help to understand a term or procedure
WebDewey has an augmented index with natural language terms from other thesauri to provide an enhanced access. Some of the important advantages of WebDewey over the traditional print version are:
a) Keyword access to the entire print DDC-23 b) Additional terms and subject headings for search c) Hierarchic display d) Standard and formulable view e) Dragging and dropping of numbers and terms f) Automatic cuttering for book numbers with two options for constructing four-figure or three figure cutter numbers
However, the basic principles and number building techniques are the same. Future electronic versions may provide some built-in expert system for automatic synthesis of numbers wherever required. Many more surprising features may be in store in the near future, including the one Dewey without notation.
2.5.2. Other online classifications
Other important online classifications are the LC (Classification Plus) and the UDC (UDC-MRF, Master Reference File). During an International Federation of Library Associations and Institutions (IFLA) sponsored international seminar on UDC in June 2007 (www.ulec.org/seminar2007.htm) at the UDCC headquarters, a Dutch software company Magnaview (www.magnaview.nl) presented an innovative visual application of the UDC. It makes possible viewing the UDC MRF in twenty novel ways and interacting with it visually. The software is commercially available from the company for MRF license holders.
3. PARTS OF A LIBRARY CLASSIFICATION SYSTEM
A classification, in essence, is simply a systematically arranged list of subjects and their subdivisions in the universe of knowledge. To be of practical use in libraries, a classification needs additional features, and these are what make it into a system. A library classification scheme has three broader components (Rowley & Hartley, 2008, pp. 171-192):
1. The schedules: in which subjects are listed systematically in arrays and chains showing their inter and intra relationships. The order of subjects in these schedules is not self-evident, and therefore requires: 2. Notation, which is a sort of a code using numbers and/or letters that have a readily understood order, and which guides the arrangement of subjects in the schedules and documents on shelves; and 3. An alphabetical index to locate terms within lengthy and mazy schedules.
It is often stated that a classification requires a fourth component: a governing body to keep it innovative, current, and for its marketing. Finally, the introduction of the system, usually including instructions and editorial information reflecting the views of the author or the governing body, can constitute another essential part of the system.
A schedule is a systematic list of classes and their subdivisions arranged in a logical way. It is the core or the
• Main classes • The division and subdivisions of main classes hierarchically or in faceted mode • Facets, generated by facet analysis • Sub-facets (arrays), formed by the subdivision of the facets by a single characteristic at a time • Above all, in the beginning, a summary of main classes and their further division is given, serving as a broader map of the knowledge covered. For example: the DDC and UDC have three summaries called Main classes, Divisions, and Sections, respectively. Apart from providing an overview of the subject, summaries save the time of the classifiers in locating the desired subdivision.
3.1.1. Example
Aida Slavic (2008, p. 5) explains an entry from the online UDC schedules having the following components:
“004.421.2 Basic mathematical algorithms
Examples of combination(s): 004.421.2:517.443 Fast Fourier transform 004.421.2:517.535 Algorithms for rational expression 004.421.2:519.17 Graph algorithms =>519.16 =>519.178
When stored in a database, information implicit in the class information showed above will have to be made explicit using following 7 blocks of data elements:
1. Notation (classification number): tables from which notation is taken type of notation (simple or composed) notation structural elements/components relationships between elements: span, phase relationships 2. Broader class 3. Caption 4. Notes: Scope note Application (instruction) note Notation building notes and rules Rules for parallel division (derived from; divide) Rules for combination and expansion (add, specify by) Examples of combination Notation history note (replaces, replaced by) General content note Editorial note 5. References (See also) 6. Class ID (unique identifier of a class) 7. Index (search) terms (keywords)
We can think of these blocks of data as a standard container that we have available to record more detailed information from a specific system.”
The division of classes must be step by step, that is, by one characteristic at a time. There are two approaches to the division of classes, namely enumerative and faceted. Historically bibliographic classifications have followed enumerative systems in which classes and subclasses have been deduced top down, moving hierarchically from general to specific; this may be called gradation by specialty. This gradual division takes the shape of a funnel. Today, faceted approach prevails.
3.2.1. Enumerative Approach
Enumerative classifications typically start out with a hierarchical structure and list or enumerate concepts within it. Enumerative classifications list or enumerate all possible topics of interest (subclasses) of a particular class in top-down manner. The enumerative method has the following problems (Buchannan, 1979, pp. 105-118):
1. Successive divisions can only properly cover one type of relationship, i.e., hierarchical. 2. Successive subdivisions of classes may be carried unnecessarily, ignoring the literary warrant. Some topics may get repeated under different arrays. That may lead to cross classification.
Enumerative systems today are almost out of fashion, giving way to the faceted approach. It has been said that enumerative systems such as the LCC are not culturally hospitable, since their main goal is to find a place, rather a pigeonhole, for each subject, rather than to build a coherent structure (Kwasnik & Rubin, 2010, p. 42).
On the other hand, the faceted approach may not be clear in representing the structure of knowledge in a specific area. Rather, the enumerative structure might be better in representing the structure of knowledge (e.g., DDC and LCC).
Rowley and Farrow (2000) summarize some of the advantages of enumerative classifications as follow:
• “[Although] there is a temptation to dismiss enumerative classification as antiquated and inflexible, [...] Dewey Decimal Classification and LCC go back a long way and have solid institutional support” (pp. 199-200). • “Perhaps the strongest inherent advantage of enumerative classification is that it is constructed and displayed in a way that can be intuitively understood” (p. 200).
Indeed, enumerative systems are easy to operate, and for a static universe of knowledge these are the best choice. Alas, there is no such universe of knowledge which is static.
3.2.2. Faceted Approach
However, the impossibility of enumerating all compound and complex subjects and the awareness of the inefficiently enumerative nature of the DDC led Ranganathan to invent the faceted approach for his Colon Classification (Ranganathan, 1989, p. 3). As Vickery put it (1966): “A faceted classification differs from the traditional in that the facets so distinguished are not locked into rigid, enumerative schedules, but are left to combine with each other in the fullest freedom, so that every type of relation between terms and between subjects may be expressed” (p. 13). Faceted classifications are constructed in what can be considered an inductive, bottom-up manner in which the basic concepts are assigned to a few preordained categories or facets (although we also acknowledge that Ranganathan’s facet-analytic approach has been argued to be rationalist, e.g., Hjørland, 2014, and thus deductive). In a faceted approach:
• Only isolated concepts assigned to a few ordained categories are listed in arrays and chains. • Compound and complex classes are formed by synthesis only. • Classification is easily hospitable to new subjects. This hospitality is multidimensional. • Class numbers are customized to be co-extensive with the subject of the document. • Structure of subject is transparent. • Schedules of subjects are short and slim, but their class number turning capacity is almost infinite.
According to Broughton (2006) some of the advantages of faceted classifications over enumerative classifications include:
• If the structure has a specified order of combination, or citation order, it can be populated with combinations of attributes to generate a more complex structure very similar to an enumerative classification, but with a more rigorous and logical pattern to it (p. 52). • With an accurate analysis, the members of an array in a faceted classification are all mutually exclusive classes, while enumerative systems on the other hand often produce groupings of classes that are not mutually exclusive (p. 54). • Where a faceted classification differs most significantly from an enumerative classification is in its potential to combine terms from different facets: the relationships between facets, and between terms from different facets – the inter-facet relationships (pp. 54-55). • Faceted classification provides a source of vocabulary for the thesaurus; the very structure of the classification helps the identification of the relationships between terms that is essential to the thesaurus. On the other hand, the enumerative classification and its “top-down” [approach] might not be ideal for clearly identifying relationships (pp. 59-60).
As for the Web, it is said that the logical and predictable structure of the faceted system undoubtedly makes it compatible with the requirements of mechanization in a way that enumerative and pre-coordinated systems are not (p. 61). In the Web environment classification is passing through its second golden age.
3.3. Relations in Library Classification
Classification is all about relations. The classification process is essentially correlating or discovering relations between two entities. There are two types of relations, both displayed or inherent, in the classification schedules.
3.3.1. Semantic Relations
Semantic relations are hierarchical, cognate, collocative, and filial. The arrangement of the main classes and their subdivisions into arrays and chains are semantic relations which are deemed helpful to the users. For the arrangement of subclasses in an array, Ranganathan prescribes eight principles of helpful sequence such as chronological arrangement, geographical arrangement, evolutionary arrangement, conventional arrangement, and so on. Hierarchy arranges entities from general to specific, or from whole to parts.
3.3.2. Syntactic Relations
These are grammatical relations among the components/facets of a compound subject. In other words, these relations are governed by citation order. Ranganathan postulated a grand but broader formula in the form of PMEST (Personality, Matter, Energy, Space, Time) in which the facets are arranged in the order of their decreasing concreteness. To arrange facets within Rounds and Levels, Ranganathan formulated an over-arching Wall-Picture principle, which is an analogical name for a dependency principle. Other such picturesque principles that he formulated are the Cow-Calf, and the Whole-Organ principles to arrange facets in a logical order (Ranganathan & Gopinath, 1989, pp. 97-102). The BC-2/CRG also formulated a detailed itemized citation formula which is comprehensive of possible facets in abstract and is free of the confusing concept of Rounds and Levels. This is: Thing-Kind-Part-Property-Material-Process-Operation-Patient-Product-Byproduct-Agent-Space-Time (Hunter, 2009, pp. 89-93). This formula bypasses the mazy and confusing act of arrangement of entities in Rounds and Levels and it is much simpler. In the 1960s S. R. Ranganathan (1967, pp. 579-582) tried in vain to establish an Absolute Syntax of facets.
3.3.3. Principle of Inversion
The citation order prescribes an arrangement of facets from specific to general, or concrete to abstract. But the arrangement of documents on the shelves or entries in a catalog is in a pedagogical order of general to specific, i.e., in the reverse order of the citation of facets. This general to special order on the shelves is achieved by manipulating the ordinal value of notational digits and indicator digits. In the UDC, the auxiliary facets are arranged in tables 1c-1k, which are in general to specific order, but these are applied in the 1k-1c order. So is the case with the PMEST order of Colon Classification, and hence the inversion (Mills, 1962, pp. 54-64). The inversion principle is embedded in the retroactive notation of the BC-2. Within the overall general to specific order there are four sub-orders:
General treated generally General treated specially Special treated generally Special treated specially
In both systems the first division is by broad classes called main classes. All current classifications base their main classes on divisions by discipline. Barbara Kyle experimented in vain to design a classification system for social sciences without the notion of main classes. Although arbitrary, there seems no alternative to them. A discipline is a broader division of the universe of knowledge which gives context to the phenomena. Main classes form the first order array of the division of universe of knowledge. These, being conventional, are postulated a bit arbitrarily by the designer of the system (Palmer, 1962, pp. 25-35). The number of main classes and boundaries vary from system to system and from time to time. There are ten main classes in the DDC, 21 in the LCC, and more than 700 in the CC-7.
3.4.1. Generalia Class
As its name implies, this is the general works class provided to accommodate such books as general encyclopedias, newspapers, magazines, and other poly-topical books, or form classes such as serials, manuscripts, museums, anthologies which cover knowledge in general, or such a portion of it that is impossible to place under any other main class in the schedules. This holdall class is an essential feature of book classifications. Its place precedes the disciplinary divided subjects.
In providing places for works which on account of their form do not specifically belong to any other main class, the Generalia class may be considered a form class. In its practical form, however, those subjects dealing with varied knowledge cannot be considered as a rigid form class. Thus a Generalia class is more than a form class.
The outline of the Generalia class in the Dewey Decimal Classification is:
000 Knowledge & Systems 010 Bibliographies 020 Library & Information Science 030 Encyclopedias and Books of Facts 050 Magazines, Journals, & Serials 060 Associations, Organizations, & Museums 070 Newspapers, Journalism, & Publishing 080 Quotations, Anthologies 090 Manuscripts and Rare Books
3.4.2. Form Divisions
A book on any particular subject may deal with that subject in various ways, from different viewpoints or in different forms. This may be an encyclopedia, a dictionary, a periodical, an advanced or elementary treatise, or it may be written as history, philosophy, in essay, or another literary form of the subject covered. Books on almost every subject frequently fall into one of these categories. Many schemes recognize their generality of application by converting them into common subdivisions, i.e., a constant set (by name and notation) of divisions which can be used to qualify any subject listed in the schedules. All bibliographical classifications make provisions for such aspects of books by the addition of the so-called (auxiliary) form divisions, or common divisions. In the DDC, such form divisions are now termed as standard subdivisions as given in Table 1 of Volume 1, e.g.,
-01 Theory & Philosophy -02 Handbooks, etc. -03 Alphabetical Reference Works -05 Serial Publications -06 Conference Proceedings -07 Study, Teaching, & Research -08 Anthologies -09 History, Biography, etc.
These divisions can be added to specify any class number in the schedules. Similar provisions exist in all other library classifications.
3.4.3. Form vs. Subject
Many of the terms representing these forms also correspond to terms used in the main schedules for specific subjects. There is, however, a distinct difference in their meaning and implication. In the main schedules, the terms are used to represent recognized subjects from the field of knowledge, e.g., the Encyclopedia Britannica has the class number 032 in DDC. Similar terms used in the form divisions represent either a special way in which a book is written and produced, or an aspect from which the subject is viewed. In other words, it is not the subject but a subject qualifier. Hence these cannot be used alone. Form divisions are exclusive to a library classification; they form the generalia divisions of a specific class. In practice, these divisions enable a further, more detailed, and convenient grouping of books by format or form to be made on the shelves (Philips, 1961, p. 38). All the dictionaries of science will come together, as do all the histories of science.
3.5. Devices for Synthesis and Phase Relations
A schedule, always equipped with many notes, instructions, devices, and techniques, is more than a systematic list of subjects. These notes and such are for the uniformity of application of these entries, for what is called inter-indexer consistency. These instructions and devices make the system a mint for forging new class numbers for unforeseen subjects of the future. To a classifier, it is a joy and a feeling of accomplishment to synthesize numbers. In a system like the DDC or the UDC, the minted or synthesized numbers may be much more than the explicitly listed numbers. The UDC uses + / : : [ ] : for combination of subjects, e.g.,
3+5 Social Sciences and Natural Sciences 5/6 Science and Technology 2:5 Religion and Science (Relation) [5+6](05) Journal of Science and Technology
These are devices for classifying interdisciplinary or composite subjects which are in
A classification notation is a series of codes or symbols which denotes the names of a class or any division or subdivision of a class. Notation forms a convenient means of reference to the arrangement of a classification. Although notation is an important addition to a classification schedule, in no way does it determine its logic, its scope, or its sequence of development. It just furnishes a convenient reference to the arrangement of a classification. The notation is not assigned until the schedule has been worked out in the idea and verbal planes. Ranganathan harshly terms notation as a servant of the Idea Plane to implement the decision taken by the latter. In fact, it is the executive authority of the Idea Plane. Notation is the engine of library classification, far from being any menial servant. Notation itself is not the classification but an essential adjunct for a library classification. Without notation it would be impossible to apply classification to documents. As classification is the “foundation of librarianship,” it can be said that notation is the visible structure of practical classification.
Summarizing its usefulness, a notation:
1. is a guide to the sequence of subjects. It places a term in the hierarchy of the schedules. A notation serves to denote the classes, their subdivisions, and the order in which these are arranged without in any way naming or defining them explicitly. It mechanizes the shelf arrangement when documents are replaced at their proper shelves after their use. 2. makes the mapping of knowledge quite visible. 3. helps to construct class numbers for compound and complex classes. 4. makes possible the use of the index. The symbol attached to an index entry is the only means of quick reference to the place of the topic in the schedules. 5. is used as a short sign to be written in various parts of the book—on the spine, back of title-page, ownership label, charging cards, etc.—to facilitate the arrangement of books on the shelves, the recording of issues, and other statistical information. 6. is the basis of chain indexing to derive standardized subject headings for the subject catalog.
The notation is that piece of apparatus without which a book classification cannot function.
4.1. The Qualities of an Ideal Notation
Some are essential and some only desirable. A notational system:
1. should convey order clearly and automatically; 2. should desirably be as brief, simple, and mnemonic as possible without compromising its efficacy; and 3. should be hospitable to new subjects, i.e., allowing insertions at any point without dislocating the existing subjects, and allowing a class to expand its boundaries without drastic reorganization. This is particularly true for the schedules of a book classification, which must be of a semi-permanent nature. Knowledge is growing turbulently since the mid-20th century. In the information and communications technology era, its speed of growth has become tremendous. All this knowledge must be assimilated, mapped, organized, and even reorganized. It is here that the hospitality of the notation is of paramount importance. Notation is the most essential quality for survival of a classification system. Among existing general classification the notation of BC-2 is an ideal.
There are two types of notation by pedigree: pure and mixed. Pure notation is comprised of single species of digits, usually either numerals or alphabets. The DDC, which uses Indo-Arabic numerals, is the best example of a pure notation. RIC, which uses only A/Z, is another example of a pure notation. Pure notations, in the face of the growing knowledge and complexity of subjects, are no more possible to employ; their time is long gone by. Mixed notation is obviously comprised of two or more species of digits. Mixed notations can again be divided into two categories, of moderately or highly mixed. The LCC and BC-2, which use only alphabets and numerals together, are considered ideal models of a library classification notation. The CC and UDC use highly mixed notations which are comprised of alphabets, numerals, punctuation marks, and so on. Moderately mixed notations are elegant and work effectively. The Library of Congress uses an alphabetical notation A-Z for the main classes; the subdivisions are denoted by a second sequence A-Z, and within these divisions a numerical span from 1 to 9999 is used. Gaps are left in between for expansion, e.g.,
U Military Science UB Administration 200 Commanders. Generals 210 Command of Troops. Leadership 220-225 Staffs of Armies 230-235 Headquarters, Aides, etc. 240-245 Inspection. Inspectors 250 Intelligence 260 Attaches 270 Spies
Choice of a notational system can benefit or be detrimental to a classification. The DDC has thrived mostly due to its simple notation, while the CC is smarting under the weight of its highly mixed notation. In the present time, the alphanumeric notation of the BC-2 with all its synthetic devices is the most theoretically advanced system (Hjørland, 2013, p. 546).
In a library classification, the class number alone is not able to provide a unique place to a document on the shelves (Satija, 2008, p. 1). For example, there may be many books on the History of Mughal India bearing exactly the same class number. If not further subdivided, there would be pockets of chaos on the shelves within the same group of subjects. For a proper and effective organization and location, those books having the same class number must be further divided granularly. The device to do this is called book number or author number. In the LCC and to some extent in the CC, the book number is a part of the class number. Book numbers usually employ two opposing techniques for sub arrangements: alphabetical by author/title or chronological by the year of publication. The Library of Congress uses simplified Cutter author numbers as an integral part of the notation to provide a complete call number. DDC classified libraries usually use the Cutter-Sanborn author table to sub arrange books having the same class number by author. The CC further sub-arranges books having the same specific class numbers chronologically by the year of publication. There are numerous locally or home devised book numbering systems.
The index is an alphabetical list of the terms that are mentioned in the schedules and tables referring to their notations. The index usually includes, as far as possible, all the synonyms of these terms, together with some synthesized subjects even when they are not included in the schedules. The index is a labor-saving device assisting in the navigation across topics in the lengthy and mazy schedules. The index should be used only as an aid to, and not as a means of, classification. The principal virtue of the index is that it ensures that a subject will always be classified in the same place in the schedules. The index to the classification schedules has two purposes:
• to locate topics within the classification • to bring together related aspects of a subject that appear in more than one place in the schedules, that is to collocate the distributed relatives of a subject. The index brings together what the schedules scatter.
There are two types of indexes:
1. Specific, which gives one entry only for each topic mentioned in the schedules in an alphabetically linear way. 2. Relative, which enumerates mentioned topics, all synonyms, and, to a great extent, shows the relation of each subject to other subjects. Perhaps the best example of a full relative index is that appended to the Encyclopedia Britannica, and to the DDC. The relative index of the DDC shows relations between subjects. The index of the Web-Dewey is even much more augmented. In fact, the relative index is a supplementary approach to knowledge organization by discipline. In the present era, all classifications divide knowledge by discipline.
The index of the DDC also includes a selection of synthesized subjects and provides their ready-made full class numbers. This tempts some classifiers to classify by the index alone –which is something that every classification teacher advises against in the classroom. In the LCC, each class has its own separate index. Faceted classifications only need to index the simple concepts that appear in the schedules.
Bibliographic classifications are born already out of date. Earlier, it took almost two years between the final editing and publication of a classification. Now, the use of computers has considerably reduced this turnabout time, yet lag is there. Classification systems are necessarily closed rather than open systems. Inserting a new topic at its proper place is not automatic, as it is with a list of subject headings: only a controlling body with technical expertise can determine the correct place of a new topic within the schedules and tables. This revision, update, and maintenance committee is a part of a larger governing body of the system. It has been experienced that classification systems such as Ranganathan’s Colon Classification, J.D. Brown’s Subject Classification, and C.A. Cutter’s Expansive Classification have not survived mostly due to the absence of a body to keep the system current and relevant. There cannot be a self-perpetuating classification as Ranganathan (1949) vaunted of his CC. Most of the credit for the popularity of not-so scientific schemes such as the LCC and the DDC goes to their respective institutional support. These systems are revised regularly and have an assured backing of big institutions. Psychologically, it is also taken by the users as an assurance for the lifelong sustainability of the system. Patronizing libraries have a feeling that there is at least somebody to count on in case of need. It is a sort of after-sale service which every customer needs. This is what the editors of the DDC do under the guidance of the DC Editorial Policy Committee (DCEPC) and OCLC. The DDC/OCLC has gone on further to establish the European Dewey Users Group (EDUG), which discusses the problems of European Dewey users, especially for translation. The DDC has a worldclass revision and promotion machinery. That is one of the open secrets of the ever increasing popularity of the DDC. The LCC has a similar assurance, although its revision body is domestic. The value of such an active body can be clearly known from the history of the UDC. The revision of the system was slow paced in the 1960s and 1970s as its parent body, the erstwhile FID, did not have sufficient resources for its progress and promotion. Since the 1980s, the establishment of the UDC Consortium (UDCC) and the appointment of the first full time editor in the person of Professor Ia C. McIlwaine gave it an impetus to the path of progress by leaps and bounds. With many new innovations, products, and services from a somewhat dormant entity, it has become a vibrant system in many ways. Hence, revision machinery is vital to the survival of a classification system (Curwen, 1978). Indeed the institutions are lengthening shadows of strong individuals.
An appurtenance to such bodies is the need of communicating with the users. The UDC had P-notes and the DDC had its irregularly regular DC&, that is, DDC Additions, Notes, and Decisions (AND). These devices communicated changes, conveyed news, and took questions from users. Now, this print media has been replaced by websites and the use of social media. The DDC has its regular blog. Regular communication with users is now easy and a must for its popularity.
Though peripheral, the ‘introduction’ to the system is an integral part of it. It combines the preface, editorial, and instructions to operate the system. Of course it is written last of all like the preface to a book. The introduction outlines in brief the history of the system, its objectives, and purpose. Essentially, it is an operational manual of the system explaining its intricacies and giving tips on how-to-use. It should be simple, clear, and sufficiently illustrated. The DDC introduction has also a glossary of used terms and its separate index to refer back to the terms and concepts used therein and throughout. However, the introduction and notes given under the entries may not be sufficient to interpret and make the intended use of the system. It is not uncommon to see different classifiers interpreting a schedule entry in different ways –many notes appended to an entry notwithstanding. This affects the uniform use of the system, termed as inter-indexer inconsistency. This problem cannot be eliminated altogether but can be minimized with an additional manual for the system. The DDC published such a manual (Comaromi, 1982) which is considered a landmark for a consistent application of the DDC in practice. Since the 20th edition of the DDC (1989), this manual has been included in the introduction, though in a separate section. Today, the introduction to the latest edition of the DDC can be consulted and downloaded at the OCLC website for free (https://www.oclc.org/content/dam/oclc/dewey/versions/print/intro.pdf). In the Colon Classification, the rules portion covers half of the core of the CC. This introduction is also well-illustrated with typical and exceptional rules. The introduction to the UDC that accompanies the tables in the first volume is also a key part of the system. It includes the complete auxiliary tables, instructions, and a summary of the classification. The introduction to the LCC also includes a preface and an outline of the different tables, or texts, that are grouped together. This information is available at the Library of Congress website.
8. SUMMING UP: FEATURES OF A LIBRARY CLASSIFICATION
1. A library classification should be comprehensive, covering the whole field of knowledge as represented in the books.
2. A library classification should be formulated with due regard to the literary warrant, aiming to provide a place for every type of subject and document.
3. A library classification should be systematic, proceeding from the general to the specific.
4. The arrangement of the classes and subdivisions should be made with constant regard for the main purpose of the library classification-the securing of a helpful order convenient to the majority of users.
5. The terms used must be clear and currently accompanied, where necessary, by full definitions. They must refer to the scope of the headings and be equipped with notes and instructions for the guidance of the classifier.
6. The notation of the library classification should be equitably apportioned and capable of allowing alternative locations for certain subjects or classes. It should make a genuine provision for local variations.
7. The library classification should be equipped with:
a) generalia and form classes.
b) form and geographical common subdivisions.
c) an effective notation. The notation should fit the scheme (not the scheme to the notation) and may include mnemonic, and also synthetic and combinatory devices.
d) a detailed alphabetical index.
1. A library classification should be structurally expansive both in breadth and depth.
2. A library classification should be displayed in a form that is easy to handle and consult, so it can assist users grasping the hierarchy and the layout of the classes.
3. A library classification may have its own system of book numbers.
4. A library classification should be revised regularly, but not too frequently, by an editorial committee working under a governing body.
5. A library classification should have an introduction which explains the aim and purpose of the system, and also works as a concise manual for using the system.
6. A library classification should be maintained (and also made web accessible) as a machine readable database.
7. A library classification must have its website, a newsletter, and someone to answer the problems and questions of its users.
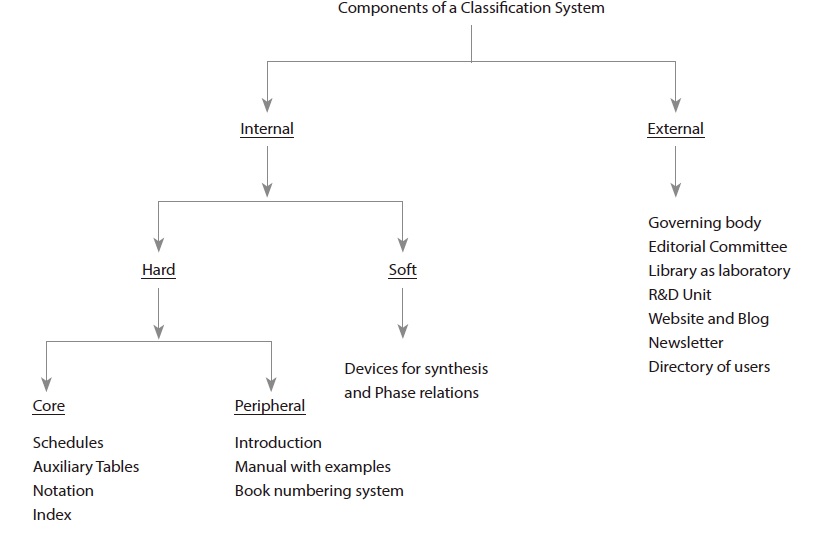
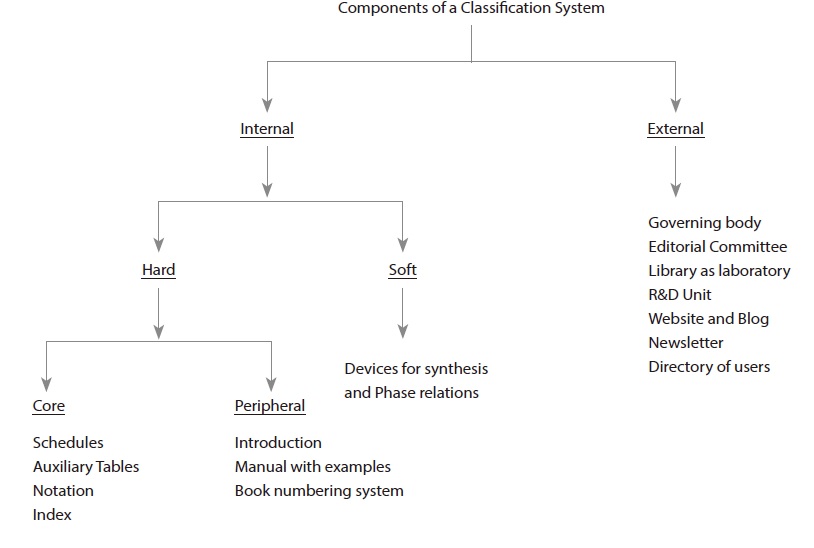
The components of a library classification are summarized in Fig. 1, including those that are external to the system and mainly related to its development, maintenance, and marketing (such as a governing body, an editorial committee, a Research & Development unit, the website and blog of the system, newsletters, and a directory of users); and the components that form the system itself (such as the schedules, auxiliary tables, notation, index, introduction to the system including a manual with example, devices for synthesis and phase relations, and so on).
In this paper, we have presented and systematized some features, functions, and components of a library classification system that are commonly discussed in the LIS traditional practices and published literature. However, these are not always considered for the new e-environments. Although we acknowledge the possibility of other competing approaches to classification (that by the way are also rarely considered in the e-environment), we have based our study on the description of those practices and features that have been commonly used and discussed in the most widely used library classification systems, such as the DDC, UDC, CC, BC-2, etc. Additional questions and possibilities for future studies might include the analysis of possible and practical scenarios in which different features might be applied to classifications such as the DDC and UDC, and the conditions of the practical viability of classifications such as CC and BC-2 to survive and adapt to the new environments.