A thesis central to the field of metaphor research since Lakoff & Johnson (1980) has been that metaphor, while deeply important to cognition and highly worthy of study, isn’t special. Metaphor isn’t anomalous, operating outside of the rules and principles which govern ‘normal’ speech, but is rather at the core of the conceptual systems which govern thought and (accordingly) language, inextricably tied up with language at the lexical, phrasal, syntactic, and discourse levels. As many times as this assertion has been made, however, it’s unclear that it has been fully implemented. If it is the case that metaphor is an essential structuring feature of language, then it ought to be demonstrably true not only that metaphor has an effect on linguistic structure (as has been repeatedly and convincingly demonstrated), but that metaphors will themselves be subject to principles that govern language more generally.
One such principle is that repetition plays a major role in the storage, use, expression and overall structure of language. “The frequency with which certain items and strings of items are used,” write Bybee & Hopper (2001: 3), “has a profound influence on the way language is broken up into chunks in memory storage, the way such chunks are related to other stored material and the ease with which they are accessed.” The greatest strength of the frequency-based approach to language lies in the fact that it grounds accounts of linguistic structure in factors that are not specific to language, but operate on cognition more generally. The phonological reduction of a frequent word has the same underlying causes as, for example, the streamlining, for experienced drivers, of the process of putting a key into the ignition of a vehicle. Metaphors are cognitive entities, their psychological reality repeatedly attested in three decades of research, and as such should be subject to frequency effects. Linguistic metaphors, moreover, should be in particular operated on by those frequency effects to which language is especially subject. At the levels, then, of both linguistic expressions (e.g.
It has been repeatedly demonstrated that metaphorical idioms (such as
Building on findings such as these that suggest an important role for a speaker’s previous exposure to metaphor in processing subsequent metaphorical utterances, both at the level of individual words and utterances and at level of conceptual metaphors as outlined by Lakoff & Johnson (1980), Emergent Metaphor Theory (Sanford 2012) asserts that metaphor is operated upon by frequency effects in a manner analogous to that which has been repeatedly observed to take place in phonological, morphological, syntactic and lexical phenomena. Representations of patterns to which speakers are frequently exposed are ‘strong’—easily accessed & productive—in proportion to their frequency. Specific instantiations of such patterns, as a result of the high frequency of the instantiation relative to the pattern overall, can themselves gain in strength, independently of the overall pattern.
This article, following a review of the relevant literature on experimental approaches to frequency and schematic strength (§1.1), presents a series of three experiments that directly assesses specific claims relating to how frequency affects metaphor. For all three experiments, the variable manipulated is the overall frequency of the cross-domain mappings instantiated in the stimuli. A survey method, in which participants rate the acceptability of metaphorically predicated stimuli, is used to assess the relationship between the frequency of an underlying mapping and the acceptability of utterances that instantiate the metaphor (§3.1). A computer-based reaction time experiment is used to gauge how the accessibility of metaphorical utterances follows from metaphorical frequency (§3.2). A sentence completion task analyzes how the frequency of a metaphorical mapping bears on the productivity of the mapping (§3.3). A corpus study (§2) provides frequency data for metaphorical mappings which is used to inform the experiments; the study also directly supports the claim that metaphors differ from one another in their frequency and that within a given source domain the frequency with which different terms are used to invoke the mapping varies greatly as well. The corpus and experimental results support a model for understanding metaphors as schemas that emerge over tokens of use.
1.1 Literature Review: Experimental Approaches to Frequency
Various experimental approaches have borne out several of the key claims of the frequency-based approach to linguistic structure—namely, that grammatical knowledge is probabilistic, that frequency increases accessibility, and that type frequency influences productivity. The great majority of such studies have focused on phonotactics, morphology, and (less commonly) constructions. The first such prediction is that grammatical judgments aren’t absolute, but probabilistic, based on a speakers’ previous experience with the language. In Pierrehumbert (1994), subjects were presented with pairs of nonsense words and asked questions assessing their acceptability to a native speaker. Each pair contained one word with a low-frequency and another with a high-frequency tri-syllabic sequence. The author’s hypothesis was that the more probable a consonant cluster was, the more likely it would be to be judged as acceptable by a native speaker. This hypothesis was supported, indicating that speakers have statistical knowledge of phonological structure which is based on their previous experience, and that they use this knowledge to evaluate novel forms, indicating that such knowledge has a place in their mental grammars. Vitevich et al. (1997) uses, in an initial experiment, a method similar to that used in Pierrehumbert (1994), but incorporating stress placement as well as phonotactic probability and asking subjects to rate items on a scale from 1 to 10 with respect to their acceptability rather than having them pick one item out of a pair. This experiment was followed up by a second one in which processing times (as measured by recognition time, the time from the presentation of the stimuli to subjects’ pressing of a button indicating that they understood it) were measured for the same stimuli. Acceptability was demonstrated to increase, and processing time to decrease, as phonotactic probability increased. In addition, then, to indicating that a word’s phonotactic probability, which for any individual speaker is a function of their previous language experience, has a clear effect on their intuitions about language, the study also indicated a direct effect on processing.
The claim that frequency has a direct effect on processing speed (accessibility) is more directly assessed in Hare et al. (2001), which builds on earlier studies such as Morton (1969) and Rubenstein et al. (1970), which have indicated that access is faster for frequent than for infrequent words. Hare et al. extend these relatively uncontroversial findings to morphologically complex words in two experiments which assess processing time by having subjects write sentences in which particular verbs occur, and then by having subjects perform a lexical decision task on a past-tense verb after it has been primed by its base form. They show that not only are irregular verbs subject to frequency effects which ease their access, but regular verbs are as well, corroborating the usage-based account’s assertion that the units of use in language are also the units of storage: morphemes which co-occur regularly come to be stored together, regardless of whether or not their cooccurrence can be predicted a by a regular rule (Bybee 1985, 1995).
The third of the three key claims regarding frequency with which this study will be primarily concerned is that the frequency of a pattern has a direct effect on its productivity. Studies such as Dabrowska & Szczerbinski (2006), which examined the effect of several variables on the productivity of genitive, dative, and accusative inflections of varying stages of diachronic development, Wang & Derwing (1994), which examined how speakers of English formed the past tense of nonce ablaut verbs, and others (Baayen & Lieber 1991, Moder 1992) have all lent support to the prediction that type frequency has the effect of strengthening a pattern/schema, a major factor in causing the pattern to be more likely to be applied to new items.
The experiments reported in §3 are based directly on experimental methods that have demonstrated the role of frequency in affecting how language is stored and processed, indicating that, at the level of metaphor as at other levels of linguistic structure, the frequency of a schema causes instantiating tokens to be more acceptable and accessible to speakers, and the schema itself more productive.
Bybee (2001: 6) writes that:
Emergent Metaphor Theory asserts that metaphors are such patterns, and as such are subject to frequency effects. These effects operate on metaphor both at a conceptual level, pertaining to the source-target mapping itself, and at the level of linguistic realization, pertaining to individual metaphorically predicated utterances. As claims relating to source-target mappings are stronger and have less precedence in the literature, this study focuses on providing experimental evidence for frequency effects at this level.
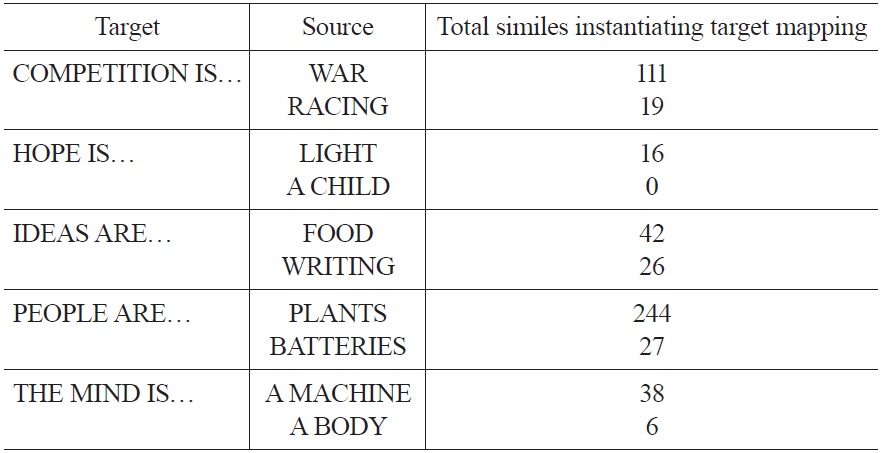
This section presents a method for assessing the corpus frequencies of conceptual metaphors. The data gleaned from it support the assertions, made in Sanford 2012, that metaphors differ from one another in their frequency and that some terminology from a given source domain is used more frequently than other semantically viable choices from the same domain. It also provides the frequency data upon which the experiments reported in §2 are based. The goal of the corpus study, predicated on the use of basic terminology from a given source domain as a means for sampling a corpus for instantiations of a particular metaphor, is to determine the overall frequency of a number of metaphorical mappings. Accordingly, a preliminary study, based on the timed survey method used by Rosch in classic prototype theory experiments (Rosch & Mervis 1975, Rosch 1978), was used to establish basic terminology for ten separate cognitive domains which are of recurrent use as metaphorical sources: WAR, RACING, LIGHT, CHILDREN, FOOD, WRITING, PLANTS, BATTERIES, MACHINES, and THE BODY. The ten metaphors of which the project presented here assesses the frequency represent ten mappings from the above source domains. The method searches for similes in a large (385+ million word) corpus for the purpose of ascertaining quantitative data for underlying conceptual metaphors.
2.1 Metaphors Used in the Study
In order to provide meaningful comparisons of the overall frequencies of metaphorical mappings in discourse, it was necessary to select mappings that could be meaningfully compared. In selecting metaphors to be used in the study, the following criteria were applied.
To this end, all metaphors used are taken from the Master Metaphor List (MML) (Lakoff, Espenson, & Schwartz 1991). The MML is described by its compilers as an “attempt to compile in one place the results of metaphor research since the publication of Reddy’s The Conduit Metaphor and Lakoff and Johnson’s Metaphors We Live By. [The] list is a compilation taken from published books and papers, student papers at Berkeley and elsewhere, and research seminars” (p. 1). While the list is far from complete (comprising, by the best estimates of its compilers, about 20% of conceptual metaphors currently reflected in English), those entries that are included represent conceptual metaphors that are widely accepted as such within the community of metaphor researchers, and which are relatively uncontroversial with respect to their formulation.1
Families of metaphors are characterized by hierarchical relationships (an idea fully explored in Kövecses 1995), such that many metaphors have submetaphors. To as great an extent as possible, however, all of the metaphors selected for the study are relatively isolated, neither instantiating more general metaphors, nor having clearly patterned special cases.
On this basis, pairs of metaphors were selected which share a single target domain (e.g., “COMPETITION”), but draw on different source domains (e.g., “WAR”, “RACING”). In the experiments reported in §3, the approach will allow a direct comparison of stimuli, instantiating each of the mappings, that are identical except for a single word or phrase, the difference determining whether the stimulus instantiates a more or less frequent metaphor (e.g., “he argues like a soldier” vs. “he argues like a racer”).
Based on these three criteria, the ten metaphors selected for use in the study are as follows (examples from the Master Metaphor List are provided below each entry):
COMPETITION IS WAR
COMPETITION IS RACING
HOPE IS A CHILD
HOPE IS LIGHT
IDEAS ARE WRITING
IDEAS ARE FOOD
PEOPLE ARE BATTERIES
PEOPLE ARE PLANTS
THE MIND IS A MACHINE
THE MIND IS A BODY
A timed survey task was used to arrive at ‘basic’ concepts and vocabulary for each of the ten metaphorical source domains, to be used as search terms in the method outlined below. The approach is based on both the methods and theoretical underpinnings of classic prototype theory (Rosch & Mervis 1975, Rosch 1978), which maintains that when subjects are asked to list features or examples of a category, those features/examples which are listed most frequently, and which tend to occur higher on lists, correspond to those examples/features which are closest to the core of a prototypically defined category2. The guiding assumption of the approach used here is that the terms that are listed most frequently by participants correspond to concepts that are basic to speakers’ understanding of a given domain.
40 students, undergraduates at a large research university offered a small amount of extra credit in exchange for participation, were used as participants in the task. Participants were all adult native speakers of American English.
The survey instrument began with the following instructions, adapted from Rosch & Mervis (1975):
The following ten pages, presented in one of five different random orders to each participant, each bore a heading corresponding to one of ten metaphorical source domains (“WAR”, “RACING”, “LIGHT”, “CHILDREN”, “FOOD”, “WRITING”, “PLANTS”, “BATTERIES”, “MACHINES”, and “THE BODY”). The instructions were read aloud, and then participants had two minutes to write a relevant list for each domain.
In analysis, those words occurring on the most participants’ lists for each domain were isolated. For “LIGHT”, for example, the five terms that occurred on the most participants’ lists were, in descending order of frequency,
In the corpus component of the study, a large corpus was searched for similes instantiating the target mappings.3 Similes are operationally defined here as ‘x is like y’ expressions that fit the criteria for metaphor offered above.
The corpus used for this method was the Corpus of Contemporary American English (COCA) (Davies 2008), a corpus of (at the time of study) 385 million words. With respect to content, the corpus is equally divided across the years spanning 1990 to 2011, and also between spoken language, fiction, popular magazines, newspapers, and academic texts.
The simile form favors the use of nouns as source terms. In the similes method, the six most frequently occurring nouns from the key terms experiment, for each metaphorical source domain, were used as search terms (for example, for WAR the search terms used were
Table 1 presents the results of the large-corpus method, totaling results for individual search terms within the mapping overall.
[Table 1.] Large-corpus method results by domain
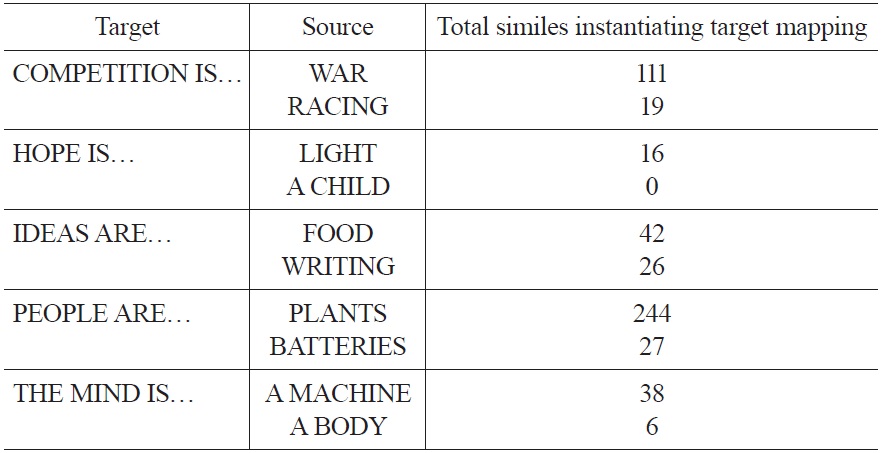
Large-corpus method results by domain
These data clearly indicate a significant, clear difference in the frequencies of metaphorical mappings. They also indicate a marked difference in the frequencies with which specific terminology is used to invoke a given source domain. Table 2 presents results for individual search terms for PEOPLE ARE PLANTS, typical in the spread of frequencies for individual search terms within a single metaphor that it represents.

Instances of similes instantiating the target metaphors PEOPLE ARE PLANTS, by search term.
All of the search terms for PEOPLE ARE PLANTS returned some results; people are compared to trees and flowers, specifically, with a very high degree of frequency, although
1‘Relatively’ is the key term. The formulation of labels for cross-domain mappings is notoriously contentious; it’s unlikely that there is any wholly undisputed mapping in the literature. Many readers will disagree with the formulation of individual metaphors posited by the MML. The use of mappings proposed by the MML for the purposes of this study is advanced as the least of many evils, rather than as a perfect solution. 2A similar method has been previously applied to finding words basic to a concept in studies such as Diaz-Guerrero, Rogelio, & Szalay (1991), which adapted the methodology to analyze cross-cultural conceptions of race. 3The major advantage of using similes in trawling corpora for figurative language is their eminent searchability: the addition of ‘like’ to figurative search terms creates a much smaller set of returns, as well as a set of returns which contains a far higher percentage of target mappings. As an example, a search for shark in the 385+ million-word Corpus of Contemporary American English (Davies 2008) yields 3383 hits, of which only a small portion can be expected to be figurative— a sampling of the first 100 hits yielded four figurative uses. like a shark, on the other hand, yields 62 hits, 60 of which are figurative. The approach therefore makes a far larger corpus accessible for study. Several lines of research support the idea that metaphors and similes perform similar functions: the career of metaphor hypothesis (Bowdle & Gentner 2005), for example, suggests that both similes and novel metaphors are processed analogically. Chiappe & Kennedy (2000) argue that the two forms are functionally equivalent when they are not purposefully used to contrast one another. In experimental research that does argue for a difference between the two as to processing (Aisenman 1999, Haught 2005), subjects’ preference for one form over another seems to be more dependent on the specific source domain terminology used, rather than on the cross-domain mapping itself. Metaphors and similes are not equivalent; they differ in both linguistic form and pragmatic function. The view is, however, taken here, following Conceptual Metaphor Theory, that both similes and metaphors prompt cross-domain mappings (Lakoff & Johnson 1980). These mappings are the object of inquiry here.
A series of experiments tests three key predictions of the view of metaphorical cross-domain mappings as cognitive entities upon which frequency effects operate in language. According to the view of metaphor outlined here, every time that an individual is exposed to a metaphorical utterance, it represents a token of use. ‘Clouds’ of tokens form around cross-domain mappings that are common in a language, as speakers are exposed to metaphorical systems in use. Schemata emerge around common metaphors as speakers generalize across tokens of use, leading to conventional cross-domain mappings and stock metaphorical interpretations. Additional tokens of use further entrench the schema. Metaphors with particular target domains in common (for example, LOVE IS MADNESS, LOVE IS A JOURNEY) are, in some sense, in competition with one another. Speakers make on-line choices, in language use, regarding what source domain to use to refer to a particular target domain. These decisions are based on a host of factors, including the concreteness of the source domain (Stefanowitsch 2005, Sanford 2008), and are dependent on the speaker’s previous exposures to each metaphor. These choices, across time and across many speakers, contribute to the overall frequency, in the language, of each metaphorical mapping.
The dependence of schema formation and entrenchment on frequency means that schematic strength is directly tied to numerical probability: if
The literature on frequency effects in language (Bybee 1985, Moder 1992, Pierrehumbert 1994, Dabrowska & Szczerbinski 2006, Wang & Derwing 1994) speaks to three main effects from frequency (see §1.1). Accompanying an increase in token frequency (i.e., an increase in the tokens of use to which to the typical speaker of a language is exposed), there is an increase in:
The experiments reported below test these effects for metaphor, evaluating metaphorical mappings as cognitive representations that are acted upon by linguistic frequency. These experiments demonstrate an effect from frequency not at the level of lexical entrenchment for figurative meanings for individual words and expression, but for schemata that have emerged over multiple stored tokens of use from the sum of a speaker’s history of language exposure. As language users encounter novel utterances, they are processed through a process of analogy to existing schemata, with proximity to and the strength of such schemata having a direct effect on how novel utterances are processed.4
These effects have not previously been tested for metaphor; doing so requires some rethinking of experimental methods by which they can be addressed. The methods outlined below build on experimental approaches to confirming these effects at other levels of linguistic structure, as well as experimental work addressing other aspects of metaphor.
3.1 Experiment 1: Acceptability
The first experiment is an acceptability-judgment task in which participants are presented with sentences the meaning of which is predicated on an underlying metaphor, and asked to rate each sentence on a scale from 1-5 with respect to its acceptability as a sentence. It is hypothesized that sentences instantiating more frequent cross-domain mappings are deemed more acceptable than sentences instantiating less frequent ones. The effect assumes an approximately similar level of frequency for the instantiations themselves, accomplished here by using novel comparisons (presumed to have a token frequency of ‘0’ in participants’ history of exposure to metaphor). This is predicted to occur as a result of acceptability judgments being made on the basis of previous exposure: the more that speakers have been exposed to the metaphorical schema (a particular source-domain mapping) sanctioning a particular utterance, the more likely they are to determine a sentence instantiating the schema to be acceptable. The results of the experiment will be interpreted as supporting this hypothesis if, as a group, the stimuli instantiating more frequent metaphors are judged to be more acceptable than the group of stimuli instantiating less frequent metaphors.
3.1.1 Methods
18 students from a large public research university (11 males and 7 females) participated in the experiment. The participants were native speakers of English between the ages of 18 and 30 and were offered a small amount of extra credit for their participation by the instructors of their introductory Linguistics classes.
Stimuli (see Table 1) comprise 40 sentences: for each of five frequent/ infrequent metaphor pairs, there are eight stimuli. Four instantiate the more frequent metaphor, applying terminology from a given source domain to a given target domain (e.g., ‘When it comes to people, kids are like small plants,’ instantiating PEOPLE ARE PLANTS), while the other four sentences use source terminology from the less frequent metaphor (‘When it comes to people, kids are like AAA batteries,’ instantiating PEOPLE ARE BATTERIES). Stimuli occur in matched pairs, embedding words triggering either infrequent or frequent mapping in otherwise identical sentences.
All stimuli are of the form ‘When it comes to
The introductory clause of each stimulus sets up a clear target domain; the main clause identifies something from the source domain (e.g.,
To prevent biasing the stimuli in either experimental group towards either a more straightforward or difficult-to-interpret form, all stimuli were written previous to the corpus component of the study. The researcher therefore did not know, at the time that the stimuli were composed, which metaphors were more frequent and which were less frequent.
Subjects were given the following instructions for the experiment:
Participation was untimed. Stimuli were presented on a two-page instrument, printed to present the stimuli in one of five different random orders to each participant.
3.1.2 Results
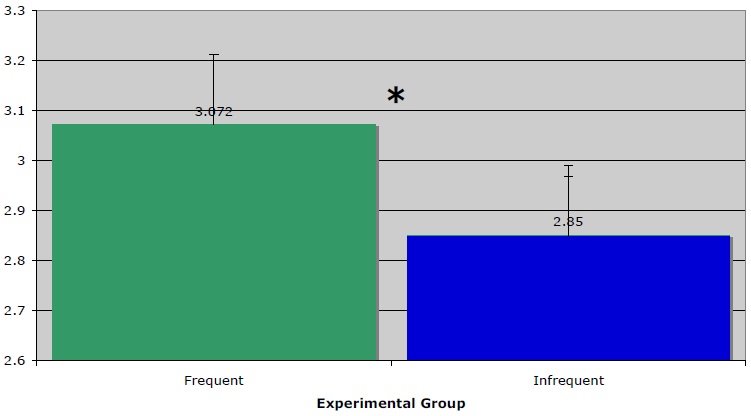
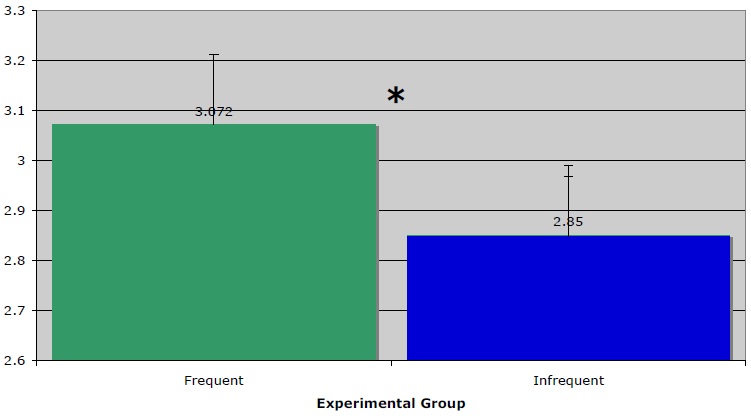
Figure 1 provides the results of Experiment 1. Averaging across both participants and stimuli, acceptability ratings were .25 higher (5% higher on the 1-5 scale) for the frequent group than for the infrequent group of stimuli. In the subject analysis, a paired t-test of mean acceptability ratings demonstrated that participants judged frequent items to be more acceptable than infrequent items at a level that reaches significance,
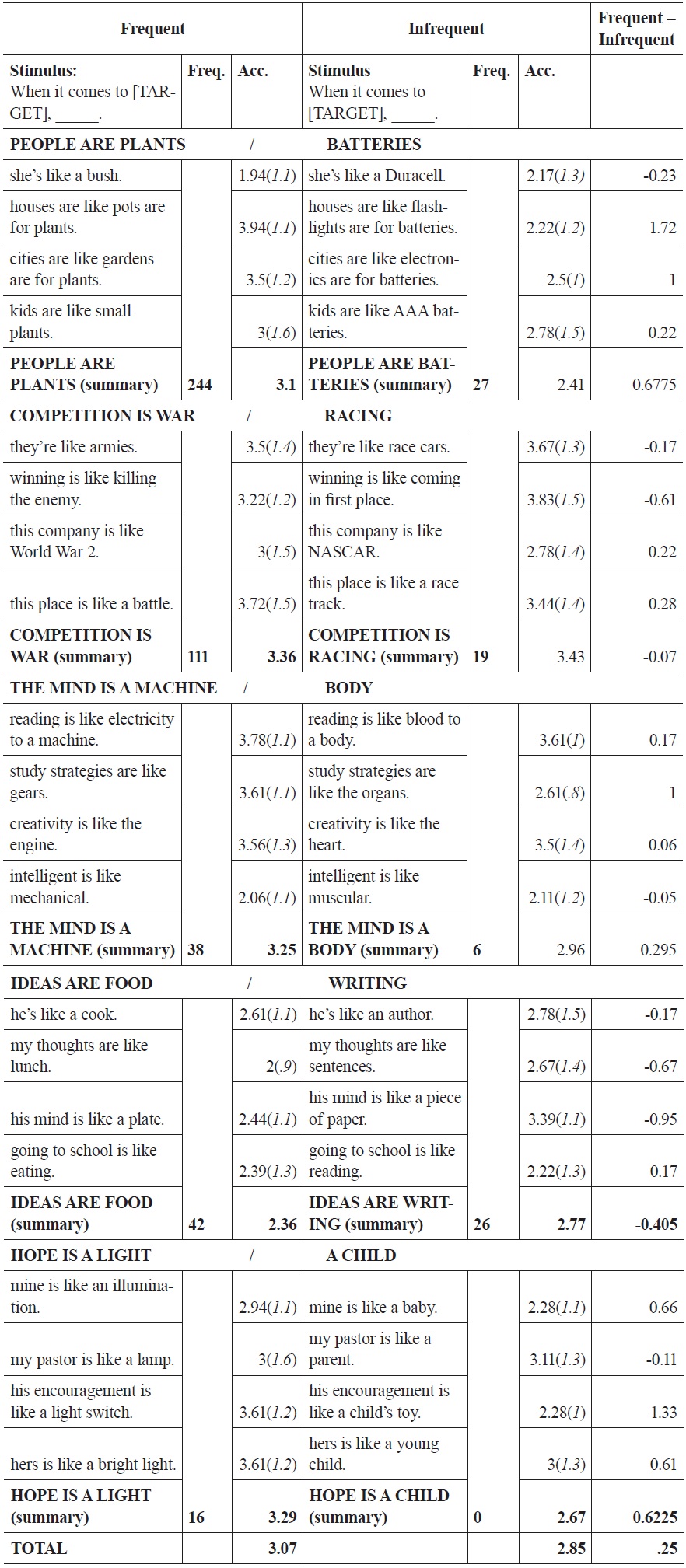
Table 3 presents a more detailed view of the results of Experiment 1. The table is divided into two main data columns, with more frequent mappings on the left and less frequent mappings on the right. Pairs of mappings, reflecting a more and less frequent metaphorical cross-domain mapping, are presented side by-side, so that the more frequent mapping is on the left, the less frequent mapping in the column adjacent.
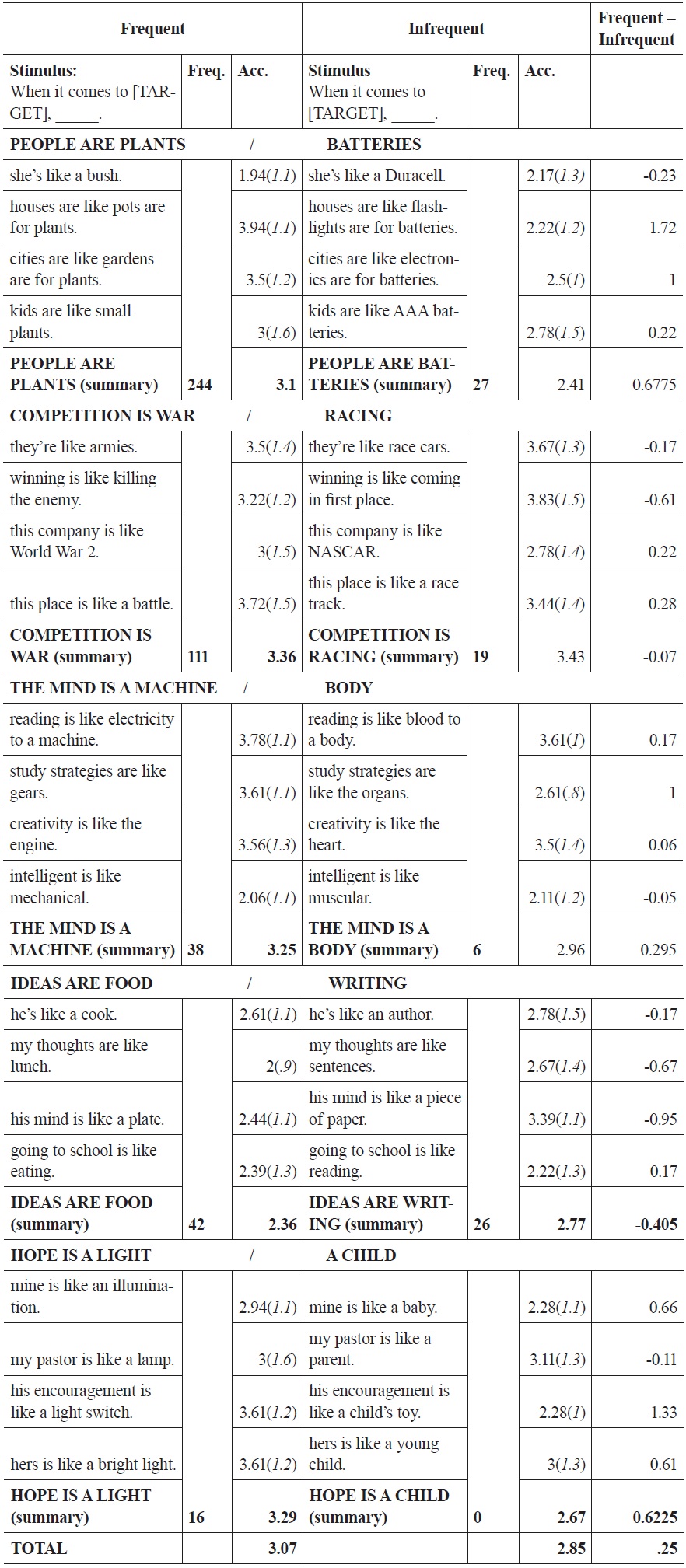
Experiment 1 Data
The ‘stimulus’ columns provide, for brevity’s sake, only the main clausethe first part of the sentence is ‘When it comes to
‘Frequency’ provides the corpus frequency for each source-target mapping, based on the results of the corpus component of the study. The ‘acceptability’ (Acc.) column provides, for each stimulus, the mean acceptability rating across all 18 participants. A higher number corresponds to a higher degree of acceptability. Stimuli are grouped into the source-target mappings that they instantiate, with the final row in each grouping reflecting an average for the mapping overall. The members of each frequentinfrequent pair appear side by side; the right-most column subtracts the ‘Infrequent’ values from values for the corresponding ‘Frequent’ values. Positive values are therefore in line with the predicted experimental effect; negative values are not. Standard deviations are reported in parentheses to the right of the average rating, across participants, for each stimulus. The frequency (F) column provides (both here, and also in the data tables for each of the other two experiments) the corpus frequency of each mapping, from the large-corpus study, in order to allow the reader to compare the mean results for each group of stimuli with the frequency of the sanctioning mapping.
Turning to judgments of individual item pairs, there were exceptions to the general pattern for two of the groups of stimuli (relating to COMPETITION and to IDEAS). In explaining these results, it seems likely that participants found some of the sentences for COMPETITION IS RACING and IDEAS ARE WRITING to be more or less literal: sentences predicated on these mappings rated high in acceptability because the terminology of competition applies literally to racing (i.e., winning isn’t just
Large differences, for a given pair of stimuli, between the stimulus instantiating the more vs. the less frequent mappings tend to be accounted for by the higher-frequency item ranking extremely high in acceptability, as is the case for
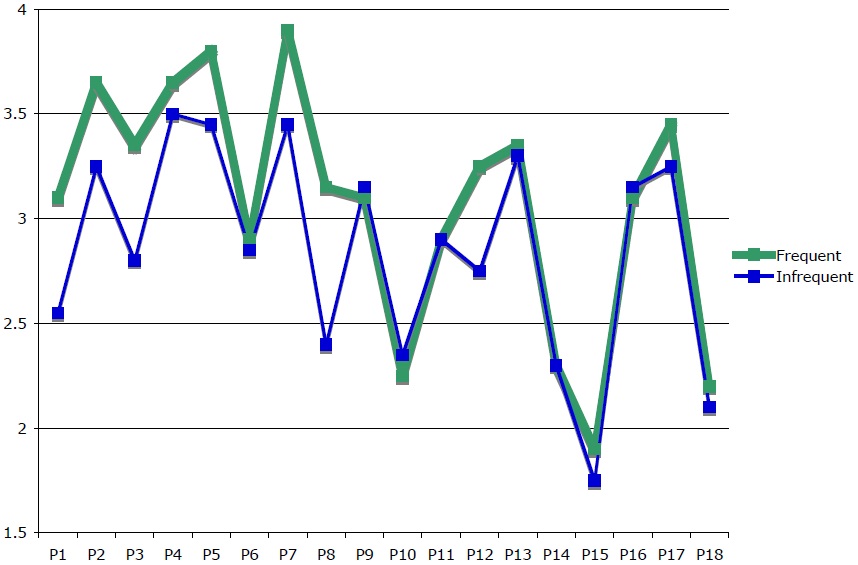
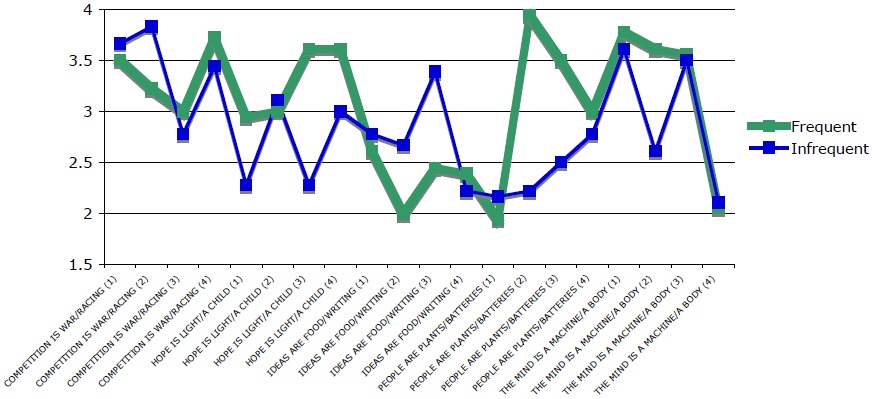
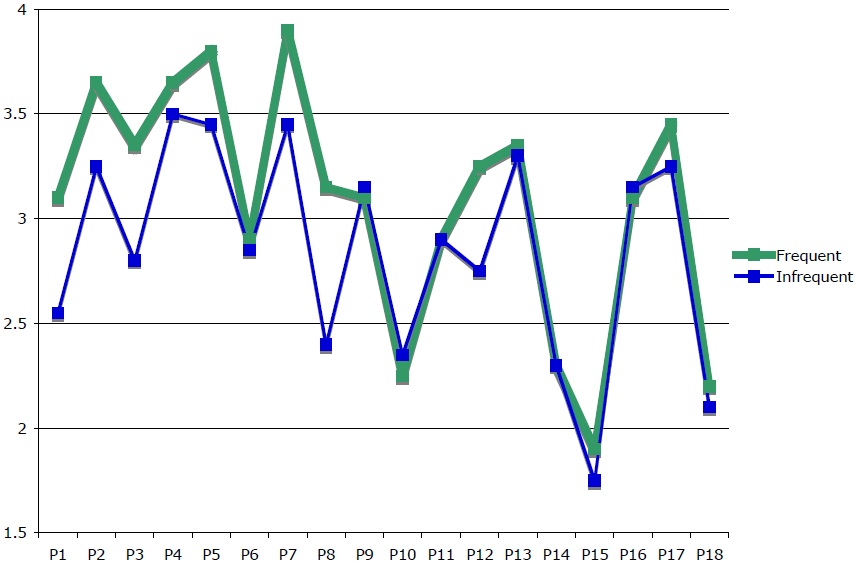
Figure 2 shows the results of the study by participant. For 15 of the 18 participants, mean ratings for the frequent stimuli were greater than or equal to mean rating for the infrequent group. The large portion of participants for which frequent stimuli were more acceptable than infrequent stimuli, as well as the closely matched curves for frequent and infrequent stimuli, attest to a clear difference across the two levels of the independent variable ‘frequency.’
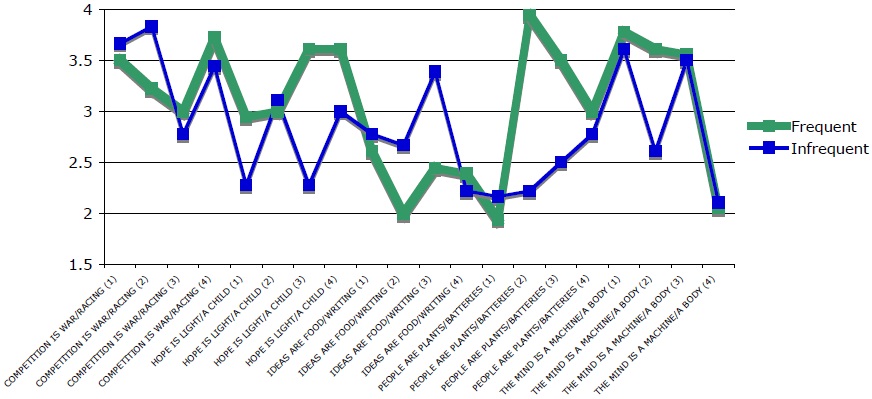
Figure 3 shows the results of Experiment 1 by stimulus. Within each group of metaphorical stimuli (as defined by target domain), each pair of stimuli is numbered one through four, in the order in which they appear in Table 1.
For 12 of 20 stimuli, and for three of the five groups of stimuli, frequent stimuli were deemed more acceptable than corresponding infrequent stimuli. A by-stimulus analysis is not significant,
The clear difference in acceptability between the two levels of the independent variable (frequency) observed here provides support for the entrenchment of metaphorical mappings as schema which operate on the same principles as schema posited at other levels of linguistic structure.
3.1.3 Discussion
These results are interpreted as providing strong support for the proposed hypothesis, that metaphorical utterances will be judged to be more acceptable by speakers when they are predicated on underlying metaphors to which they have had frequent exposure. The data reported here correspond to experimental findings which have been reported for other levels of linguistic structure, that grammatical judgments aren’t absolute, but probabilistic, based on speakers’ previous experience with language (Pierrehumbert 1994, Vitevich et al. 1997, Bybee & Eddington 2006). In the case of speakers’ acceptability judgments regarding metaphorical stimuli, participants appear to be making determinations as to semantic felicity—essentially, how easily an utterance can be associated with a literal meaning—rather than grammaticality. In both cases, however, language users are making determinations as to how acceptable an utterance is based on its probability.5 The less frequent the pattern underlying an utterance (whether said pattern be a particular sequence of segments, a string of morphemes, or a particular source-target metaphorical mapping), and therefore the less its probability, the less such a pattern will have likelihood and strength of entrenchment as a schema. This lack of participation in a highly entrenched schema corresponds to ‘oddness’ in an utterance- that is to say, a lack of acceptability, whether such a lack of acceptability be labeled grammatical or semantic.
3.2 Experiment 2: Comprehension Time
The second experiment is a computer-based comprehension-time (CT) task in which participants were presented with metaphorical stimuli (e.g., ‘When it comes to love, he’s a magician’) and asked to press a button when they understand the sentence. It is hypothesized that sentences instantiating more frequent metaphors are processed more quickly than sentences instantiating less frequent ones, as a result of frequent mappings having been entrenched in speakers’ minds due to frequent activation. This hypothesis is tested in two ways, with the experimental results interpreted as supporting the hypothesis stated above if 1) there is an overall correlation between frequency and reaction time, and 2) as a group, the stimuli instantiating frequent metaphors are processed more quickly than the stimuli instantiating less frequent metaphors.
3.2.1 Methods
26 students from a large public research university (14 males and 12 females) participated in the experiment, a group different from those who participated in Experiment 1. The participants were native speakers of English between the ages of 18 and 30 and were offered a small amount of extra credit for their participation by the instructors of their introductory linguistics classes. Stimuli (see Table 5.2) comprise 30 sentences, occurring in matched pairs: for each frequent/infrequent metaphor pair, there are six stimuli. Three instantiate the more frequent metaphor, applying terminology from a given source domain to a given target domain (e.g., ‘Her mind has gears,’ instantiating THE MIND IS A MACHINE), while the other three sentences are identical except that they use source terminology from the less frequent metaphor (‘Her mind has muscles,’ instantiating THE MIND IS A BODY). Stimuli were constructed using terminology which emerged as basic to the domain in the key terms survey, with the first pair of stimuli constructed around the metaphorical use of nouns from the source domain, the second around the metaphorical use of verbs from the source domain (although in some cases applying them in present participle form), and the third around the metaphorical use of adjectives from the source domain. The words selected for use in each matched pair were analogous with respect to their role in the domain.6 Stimuli were controlled for mean lexical frequency, as assessed using the Corpus of Contemporary American English (Davies 2008). While the mean lexical frequencies for the members of each stimulus pair are in many cases unequal, there was no significant difference in mean lexical frequency between the two groups of experimental items overall:
The experiment was computer-based, with all participants completing the experiment on the same machine (a Macintosh G4 MacBook). The experiment was designed and run using PsyScope X, and the machine’s track button was used as an input device. This setup guaranteed timing accuracy to within 17ms (more than sufficiently accurate for the relatively long reaction times recorded in the experiment).
Participants first read an introductory screen on which they were advised that they would be presented with a series of sentences, and that they were going to be asked to assess each sentences’ meaning. On beginning the experiment, participants viewed, for each stimulus, the following series of screens: an initial screen advises them that for the following screen, they are being asked to press a button as soon as they feel that they understand the sentence. Once they press a button to advance to the screen containing the stimulus, a screen appears containing the stimulus. Once the button is pressed a second time, indicating the sentence has been read and understood, a screen appears which prompts them to write in a brief description of the meaning of the sentence, and to press a specific key (cueing the introductory screen for the next stimulus) when their description is complete.
All trials began with a block of 5 ‘warm-up’ items, from which data were not recorded, following which the stimuli were presented to each participant in a different random order. For each stimulus, the time recorded was the time between the stimulus appearing on the screen, and the button being pressed.
3.2.2 Results
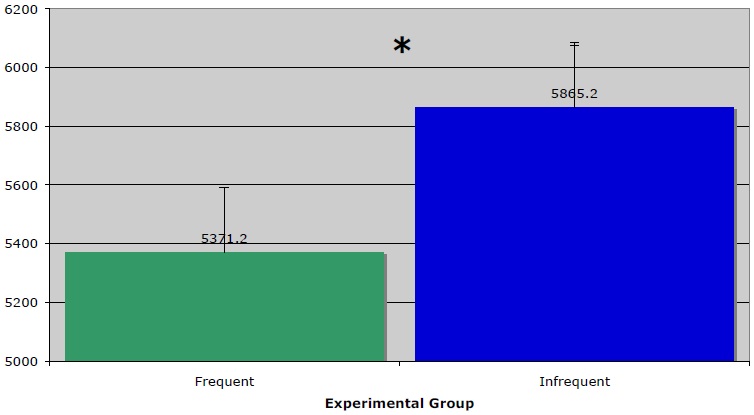
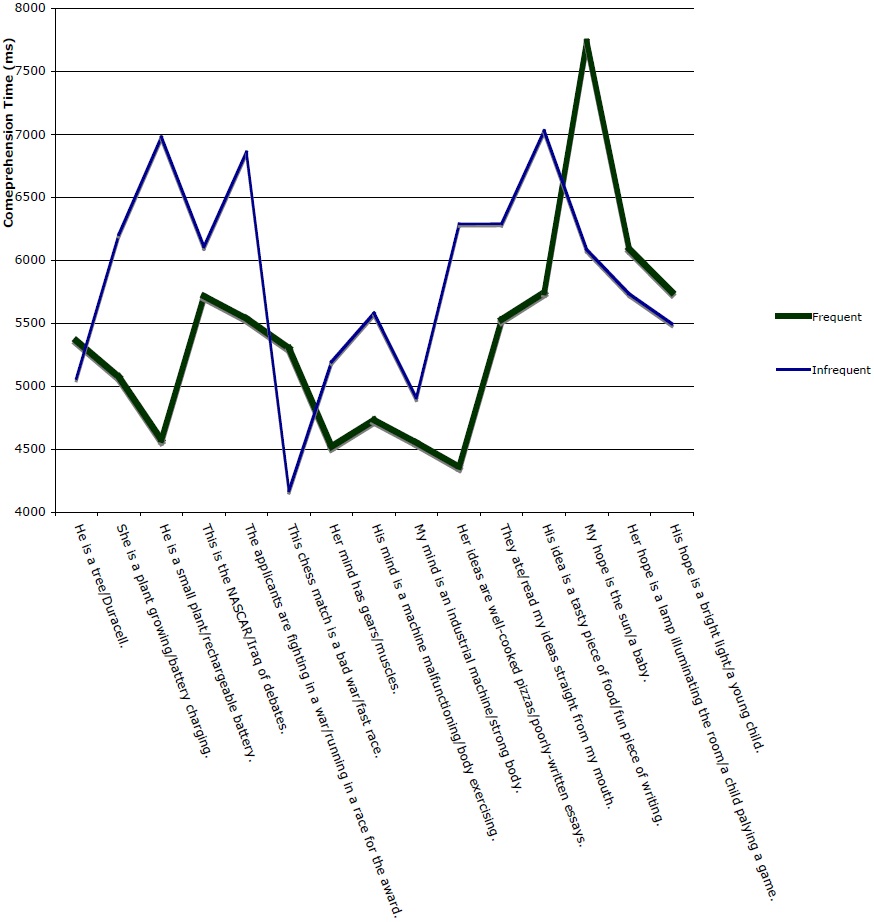
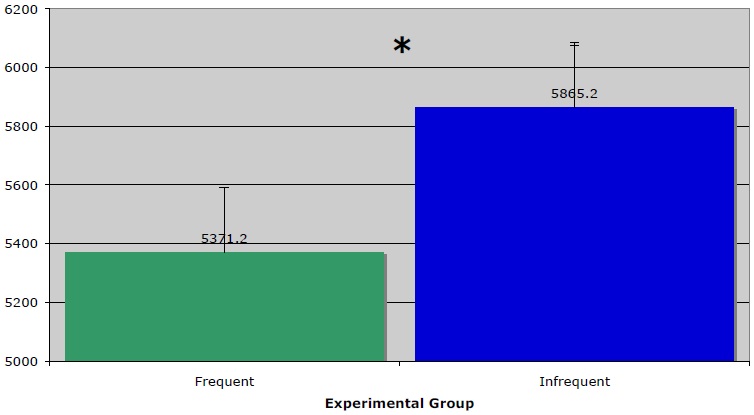
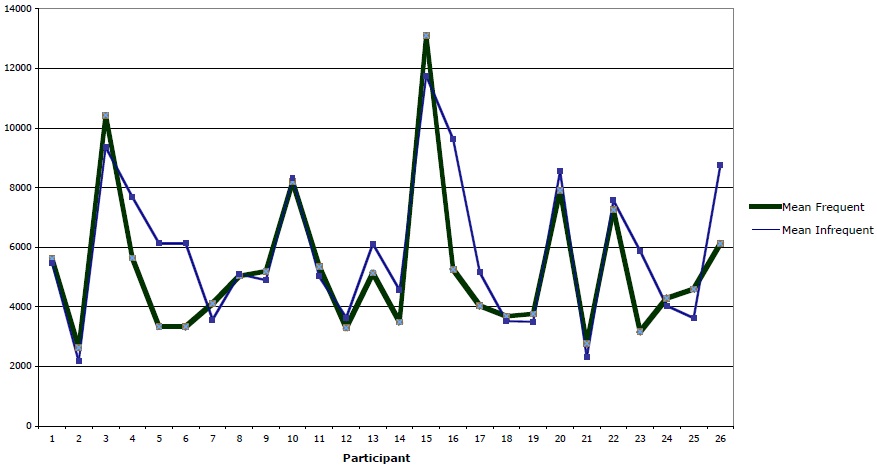
Figure 4 provides the results of Experiment 2. Comparing results across the two levels of the independent variable, corresponding to the average of responses for the more frequent and less frequent items for each participant, the experiment bears out the prediction that utterances instantiating more frequent metaphors are processed more quickly than utterances instantiating less frequent ones. Mean reaction time for the infrequent stimuli is 5865.2 ms, while mean reaction time for the frequent stimuli was 5371.2 ms—almost 500 ms less. These results are statistically significant for a by-subjects analysis,
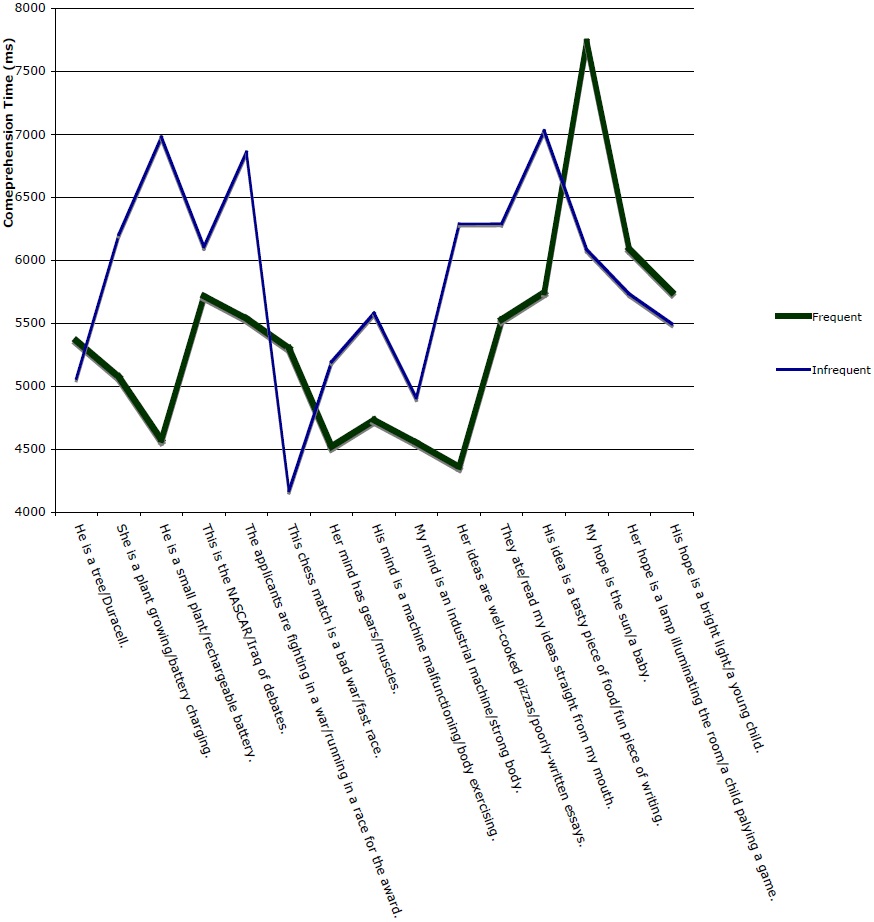
Table 4 presents a more detailed view of the results of Experiment 2, averaged by stimulus. Both Table 4 and Figure 4 reflect a preliminary cleaning up of the data in which all responses under 100 ms (assumed to represent a ‘double-click’ from the previous response) and over 100,000 ms (assumed to represent a distraction from the experimental task) were excluded. Data were also excluded from items for which there was a null response in the paraphrase (i.e., items for which participants entered nothing in the field where they were prompted to explain the meaning of the sentence). A total of 35 responses (4% of the data) were discarded based on these criteria. Values for each item are averaged across participants. The values in the right-most column are differences yielded by subtracting values from the first column from values in the second. Positive numbers in the right-most column are therefore in accord with the predicted phenomenon that utterances instantiating frequent metaphors are processed more quickly than those instantiating less frequent metaphors. Negative numbers reflect instances where the predicted effect is not borne out.
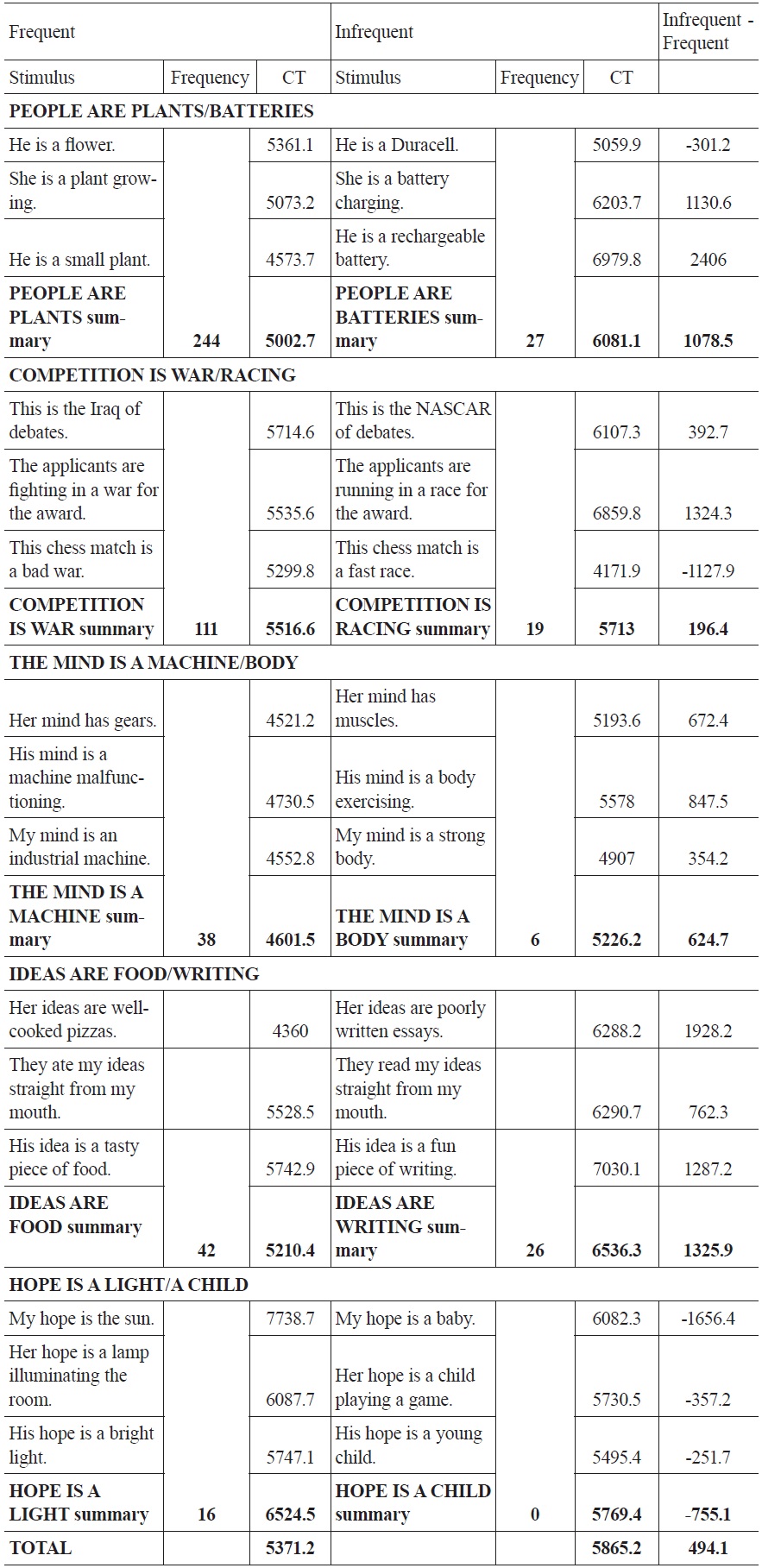
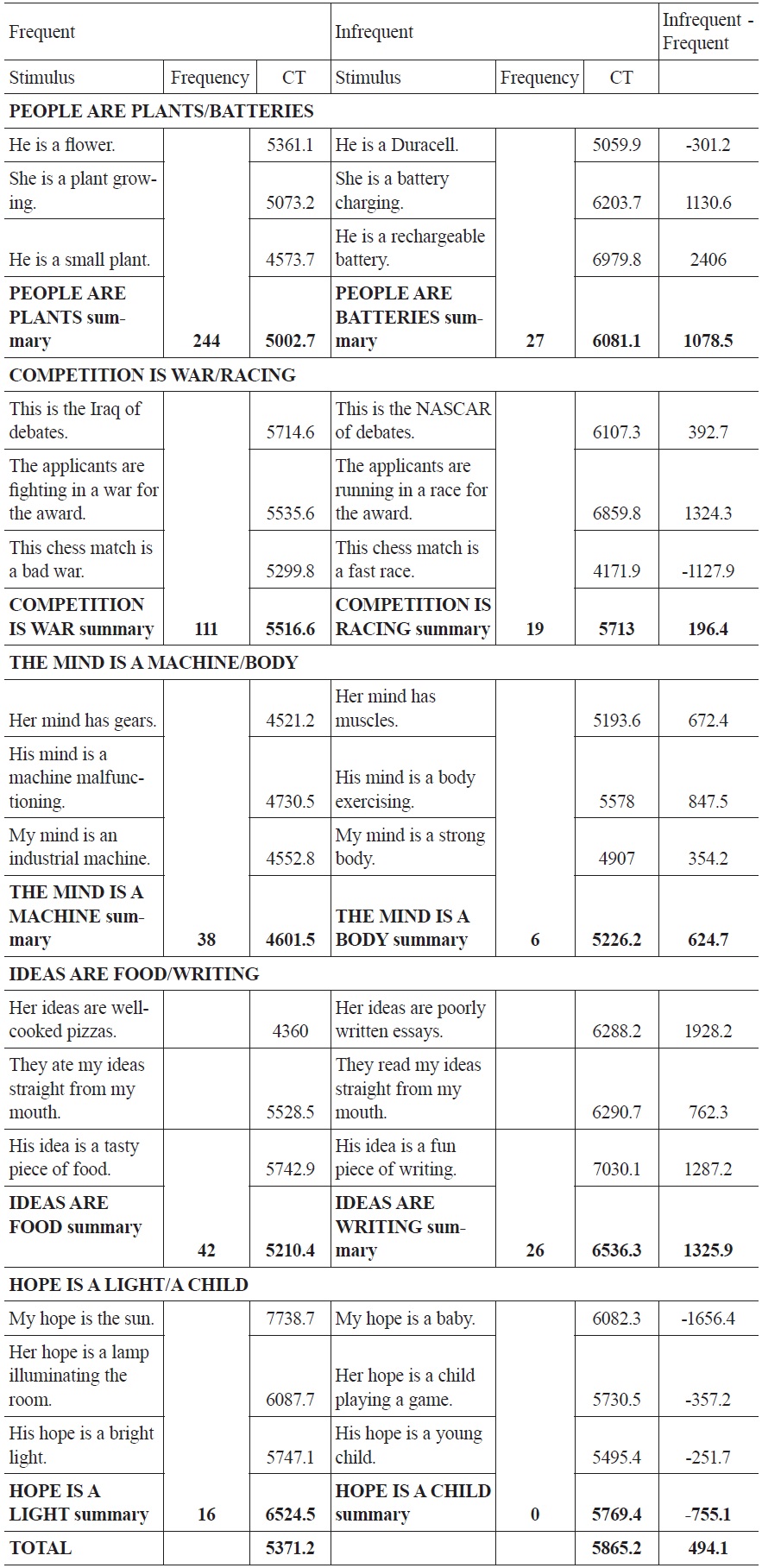
Experiment 2 Data
The results corroborate, in several ways, the results gleaned from Experiment 1. Three of the five groups of stimuli agree directly with the results of the acceptability experiment. Mean scores COMPETITION IS WAR/COMPETITION IS RACING, separated by a narrow margin in Experiment 1, are again close in Experiment 2. The final group of stimuli, those instantiating HOPE IS A LIGHT/HOPE IS A CHILD, represent a notable exception to the trend observed elsewhere: for this one group, the items instantiating the less frequent metaphor has, across subjects, a lower mean comprehension time. This may indicate that the frequency method used may not be fine-tuned enough to determine the difference in frequency between relatively low-frequency metaphors, or it may indicate that below a certain threshold of frequency, no meaningful differences in processing take place. When HOPE is excluded from the analysis, the difference between the two groups increases to 645 ms, significance to
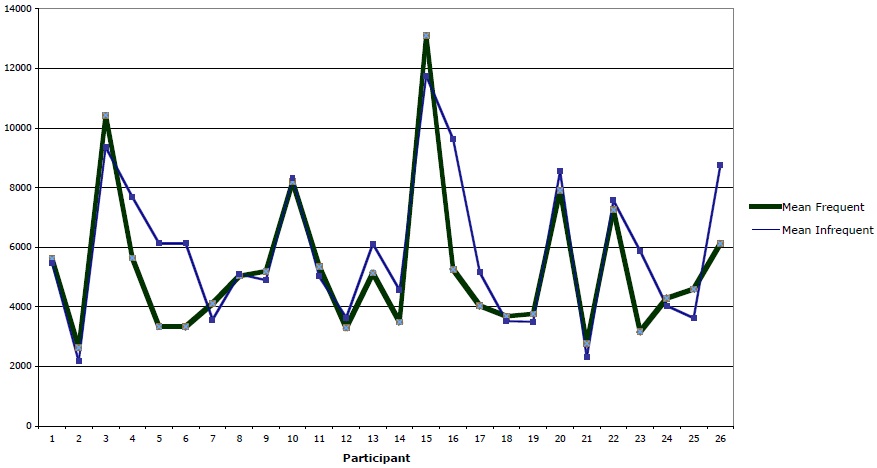
Figure 5 represents the data from Experiment 2 in a chart that plots, for each of the 26 subjects that participated in the experiment, mean comprehension for the frequent against the infrequent sets of stimuli. For 14 of the 26 participants, reaction time for the infrequent items exceeded reaction time for the frequent items (a slim majority, following from the small margin separating the two groups). The difference between the two groups was significant, as reported above.
Figure 6 plots, for each stimulus pair, the mean comprehension time across participants for the frequent vs. the infrequent stimulus.
In a by-stimulus analysis, the difference between the two groups of stimuli approached, but failed to reach, significance,
3.2.3 Discussion
These results are interpreted as supporting the stated hypothesis that sentences instantiating more frequent metaphors are processed more quickly than sentences instantiating less frequent ones as a result of their having been entrenched by previous usage. These findings mirror those such as Vitevich et al. (1997) and Hare et al. (2001), which indicate for phonotactic and morphological sequences that processing speed is more rapid when such sequences instantiate patterns which are frequent. This suggests a common explanation for both sets of findings: that patterns to which subjects have had frequent previous exposure are entrenched as schemata, and that increasing frequency is accompanied by increasing speed of access. With respect to accessibility, frequency has the same effect on metaphorical schemata as it has on schemata at other levels of linguistic structure.
3.3 Experiment 3: Productivity
The third experiment is a timed sentence completion task in which participants are presented with the first portion of a sentence which specifies an entity from a given target domain, and they are prompted to write down as many metaphorical completions as they can think up in a specified period of time. It is hypothesized that completions instantiating more frequent source-target mappings will appear with more frequency, across subjects, than completions instantiating less frequent ones, as a result of frequent mappings having been entrenched in speakers’ minds due to frequent activation. This experiment will be taken as supporting the hypothesis if there is a significant difference in the number of completions instantiating frequent vs. infrequent metaphors, such that there are significantly more completions instantiating the group of frequent metaphors identified in the corpus component of the study relative to the corresponding related infrequent metaphors.
3.3.1 Methods
18 students from a large public research university (8 males and 10 females) participated in the experiment, a group distinct from those who participated in Experiments 1 or 2. The participants were native speakers of English between the ages of 18 and 30 and were offered a small amount of extra credit for their participation by the instructors of their introductory linguistics classes. The five stimuli used in the experiment (see Table 3) correspond to the five target domains (PEOPLE, COMPETITION, THE MIND, IDEAS, HOPE) that are attested in the ten metaphors (five matched pairs) the frequency of which were assessed in the corpus component of the study. The initial portion of the stimulus sets up a situation, describing literally an attribute of a member of a category defined by a particular target domain (e.g, PEOPLE). The second portion of the stimulus, an uncompleted simile of the form “[Target] is like ____,” prompts a figurative description of the assertion made literally in the first portion of the stimuli. The first stimulus, then, reads as follows:
The first portion of the stimulus makes a literal assertion, attributing a quality (awake) to a member (Mary) of a category aligning with a metaphorical target domain (PEOPLE). The second portion prompts the figurative use of a term to provide an alternate description. The information being coded for analysis is the source domain of the terms used to complete the sentence: a
Participants were provided with the following instructions:
Subjects had two minutes to complete each page of the instrument. The five stimuli were presented in a different random order to each participant. Data coded are the number of items, totaling across all participants’ lists, items instantiating each of the two metaphors (the frequent and the infrequent one) for each target domain.
3.3.2 Results
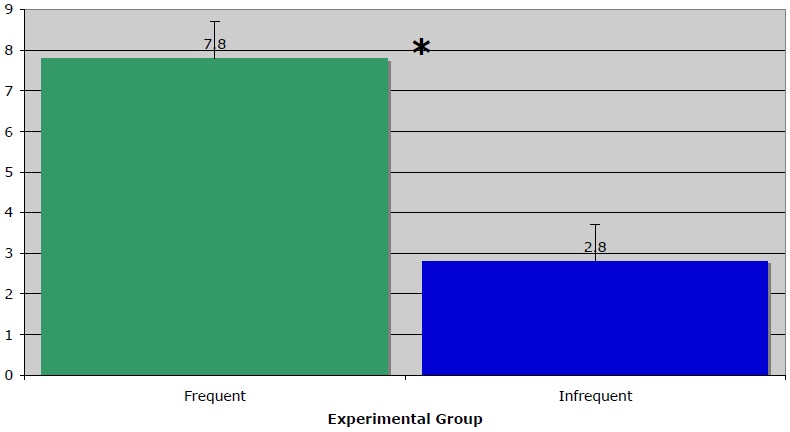
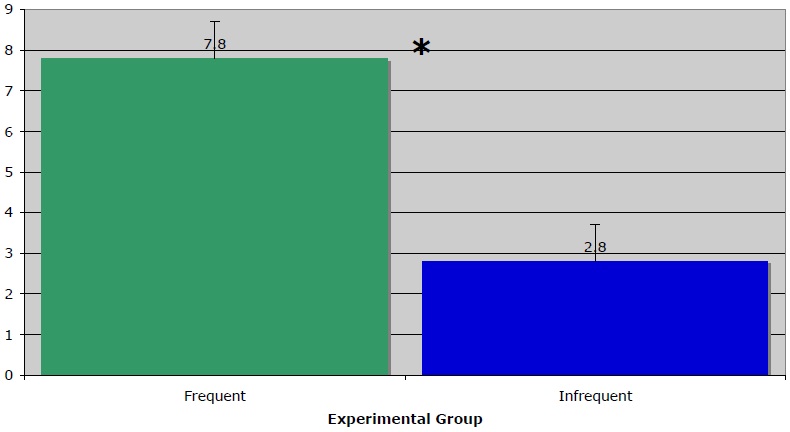
Figure 7 provides a comparison of the mean production tokens (a single instantiation, within a list of completions for a given target domain, of a particular mapping) across all participants, and all stimuli. The average number of production tokens is higher, averaging across subjects, for the frequent than the infrequent metaphorical mappings (7.8:2.8), which bears out the predicted experimental effect. These results are significant,
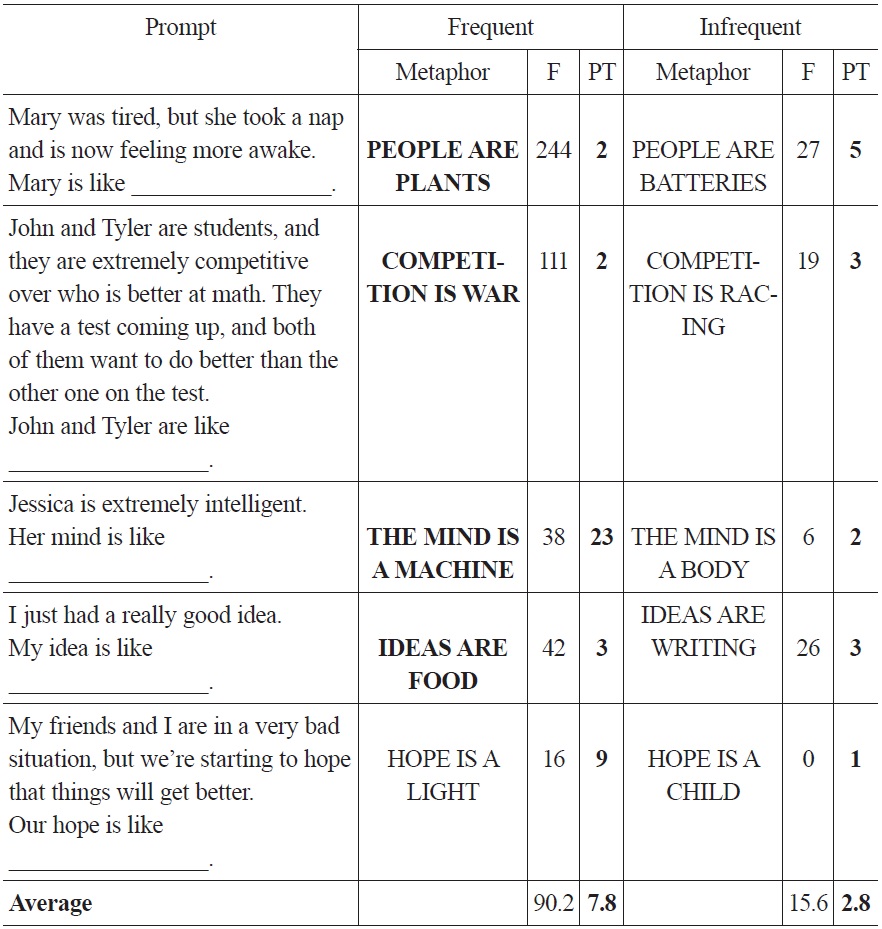
Table 5 presents a more detailed version of the results of Experiment 3. There is a single prompt corresponding to each of the five target domains; the ‘frequent’ and ‘infrequent’ columns correspond to the source domains which are used more and less frequently in relation to the given target domain. The column labeled PT provides a sum, across the 18 participants, of production tokens for each mapping.
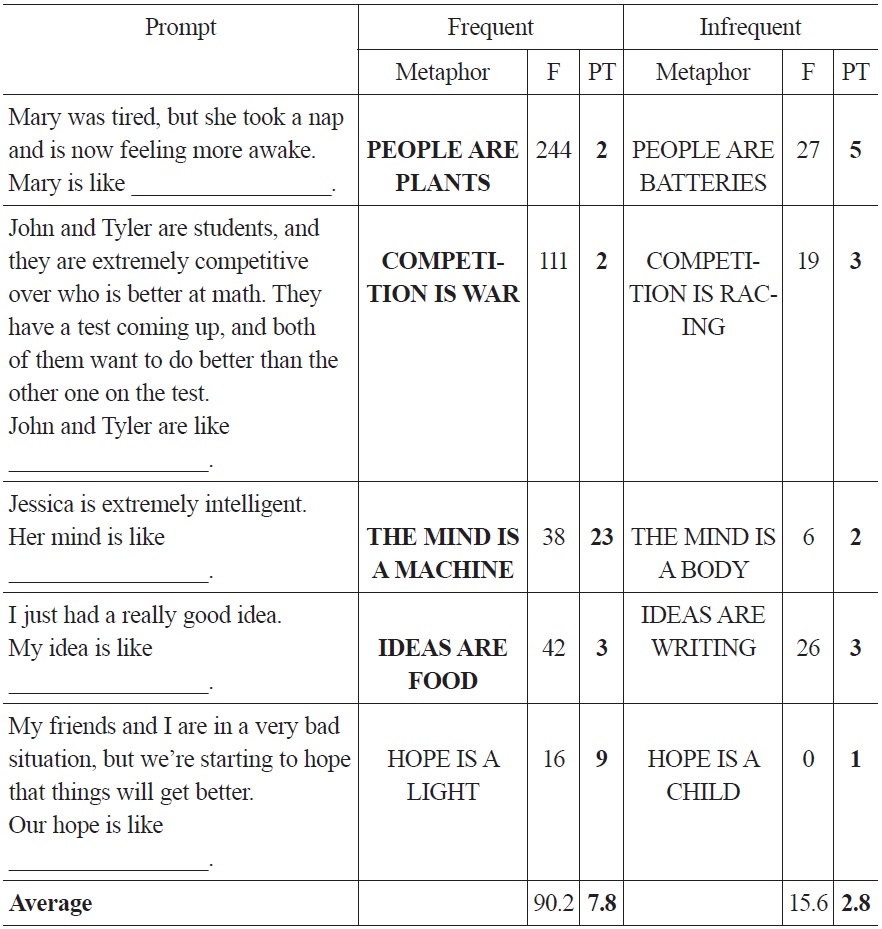
Experiment 3 Data
Looking at the results across each of the five target mappings, it’s the case for three of the five target domains that PTs for the more frequent mapping are lower than, or equal to, PTs than for the infrequent mapping. In the two categories for which there are, as predicted, more PTs for the frequent than for the infrequent mapping, the difference across the two categories is extremely high relative to the other categories (23:2, 9:1). In the three categories for which PTs for the infrequent mappings exceed PTs for the frequent ones, the ratio is at most 5:2. This pattern accounts for the higher average PTs for the category of frequent mappings.
As an example of the types of entries that were included as tokens of the target mapping, the prompt corresponding to PEOPLE ARE PLANTS and PEOPLE ARE BATTERIES is:
Across all subject’s lists, the two completions that were coded as instantiations of PEOPLE ARE PLANTS were ‘a fresh lettuce’ and ‘a daisy.’ The five items that were coded as instantiations of PEOPLE ARE BATTERIES were ‘a recharged battery,’ ‘a charged battery,’ ‘a device that needs to be recharged,’ and two instances of ‘battery.’ Metaphorical completions that don’t instantiate either target metaphor abound (as they do across all ten target metaphors), and responses such as the following were common: ‘a new penny,’ ‘a million bucks,’ ‘a deer after being shot at,’ and ‘a lightbulb.’ So, too, were non-metaphorical responses, such as ‘a person who had just slept for 24 hours,’ or ‘a workaholic freak.’ Across all 18 subjects and all five target domains, the average number of responses for each list was seven.
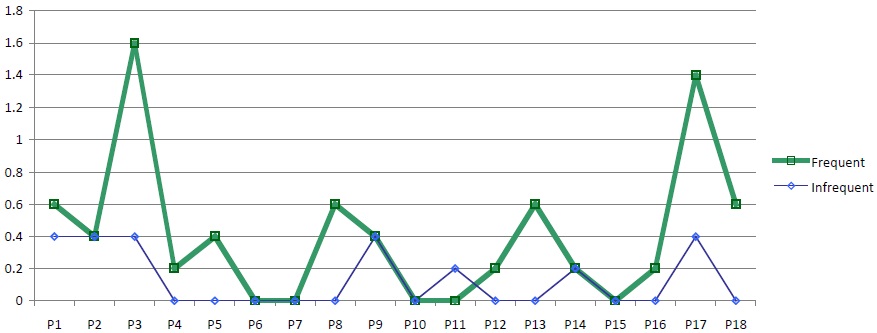
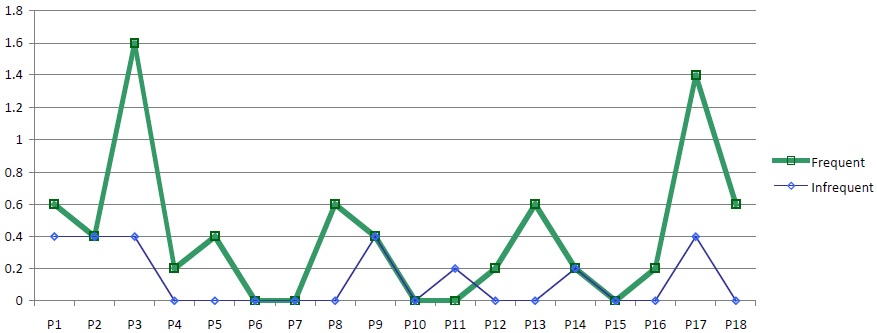
Figure 8 shows the results of Experiment 3 by subject.
For 3 subjects, there were no PTs for either metaphorical category. For 7 subjects there were no responses for the infrequent mapping and at least 1 for the frequent mapping, while the reverse is true for only 1 subject. 14 subjects gave a pattern of responses in line with the predicted effect, productivity for the frequent category exceeding productivity for the infrequent category.
A by-stimulus analysis fails to reach statistical significance,
3.3.3 Discussion
The results of Experiment 3 are in line with the predicted experimental effect, providing direct support for the hypothesis that frequent metaphors are more productive than infrequent metaphors. The difference in averages between the two groups, as well as the by-subjects analysis, are highly consistent with the predicted effect that more frequent metaphors will, relative to less frequent metaphors, more commonly serve as templates for new constructions.
Overall support notwithstanding, in some cases results for specific frequent-infrequent metaphor pairs fails to corroborate the general pattern of frequent metaphors being more productive than their less-frequent ones, pointing to two weaknesses in the experimental design that should be addressed in follow-up experiments. First, the low numbers of responses for each metaphor (eight of the ten having five responses or fewer), even totaling across all participants, makes the results difficult to interpret. This issue is inherent to the nature of the study- the prompts were very open-ended, and metaphorical completions of all sorts, and in very high numbers, were attested. Only a small subset of these (those completions, for each target domain, that instantiated one of the metaphors the frequency of which was assessed in the corpus component of the study) were coded, which necessarily means that only a small number of responses were recorded. A follow-up study, or any experiment with a methodology similar to the one reported here, would do well to seek a much higher number of participants. Second, there was only a single prompt corresponding to each target domain, which made the results for each domain highly dependent on the particular stimulus used. The results would be more powerful were they averaged, for each domain, across a number of prompts for the domain. This change will also be instituted in any follow-up studies.
The experiments reported here indicate that metaphorical entrenchment can and does take place at the level of underlying metaphorical schemata. The corpus frequency of a given mapping provides a diagnostic of speakers’ previous exposure to an utterance, which is demonstrated here to be a factor in processing, with respect to acceptability, accessibility, and production. The finding that manipulation of utterances with respect to the frequency of the metaphors underpinning them has a direct effect on processing indicates that speakers’ previous exposure to particular metaphors influences their online processing of such metaphors. Experiments 1 and 2 directly support the predictions that instantiations of higher-frequency metaphors are deemed more acceptable and processed more quickly (respectively) than instantiations of lower-frequency mappings. Experiment 3 confirms that higherfrequency mappings are more productive than lower-frequency mappings, suggesting a strong role for the token frequency of a metaphorical mapping in determining such productivity.
Both Experiments 1 and 3 make use of stimuli in the grammatical form of similes, rather than of metaphor. In addition, the corpus study uses similes to assess the frequency of mappings. The functional equivalence of metaphors and similes, with respect to processing, does not mean that metaphors and similes are identical, nor should any statement made above be interpreted as claiming as such. Different grammatical forms have associations with different types of metaphorical affect and pragmatic functionthe piloting of stimuli for all three experiments indicated that the simile form is more effective than the metaphor form in biasing language users towards a figurative interpretation. Croft & Cruse (2004) note that the categories of metaphor and simile overlap to a great extent, but have distinct prototypes. Similes tend towards restricted mappings, making a single, narrow assertion about the target, and prototypically treat the source and target being treated as discrete. Metaphors tend towards open mappings, inviting a limitless number of inferences about the target based on the source, and prototypically ‘mix’ the source and target into a single conceptual space. Nonetheless, several lines of research (Bowdle & Gentner 2005, Chiappe & Kennedy 2000) support the view that novel similes and novel metaphors are processed in essentially the same way, supporting the view from Conceptual Metaphor Theory that both forms represent linguistic instantiations of cross-domain mappings. The most relevant evidence, however, comes from the experiments reported here: Experiments 1 and 3 make use of grammatical similes as stimuli, while Experiment 2 uses grammatical metaphors. All three experiments, however, point towards the same relationship between processing for the stimuli, and the metaphorical schemata upon which they are based.
As discussed in Sanford 2012, the factors bearing on the productivity of metaphors are many, including both cognitive (e.g., the embodiment of metaphors, as described by Lakoff & Johnson 1980, whereby metaphors often draw on the physical experience of inhabiting a body) and stylistic (e.g., novelty and cleverness) constraints. Frequency is one among these. The usage statistics reported here are therefore inherently limited in explaining real creative novel metaphors.
In several cases, results for specific pairs of domains point to cases in which the metaphors used in the study were not stated at a level of schematicity that accurately captures the productive range of the metaphor (a criticism elaborated in Clausner & Croft 1997), leading to stimuli that are questionable in their relation to an overarching schema. In Experiment 2, for example, results relating to the source domain HOPE run contrary to both the corpus study, and the other two experiments- apparently, because utterances such as ‘my hope is the sun,’ predicated directly on HOPE IS LIGHT, run contrary to a metaphor that might be more accurately described as profiling light sources as things that nourish hope. PEOPLE ARE BATTERIES might be more accurately phrased PEOPLE RUN ON BATTERIES, leading to issues with the aptness of a stimulus such ‘kids are AAA batteries.’ Metaphors were drawn from the Master Metaphor List (Lakoff, Espenson, & Schwartz 1991) for reasons elaborated in §4.1 (in short, if the metaphors on which the experiments in based are in error, they at least aren’t flawed in a way that reflects researcher bias). The issue underscores the need for all posited metaphors to be evaluated closely against corpus usage; that the experiments found an effect despite such issues points towards a significant effect outweighing issues relating to specific groups of stimuli.
These results are interpreted as providing strong support for the view of metaphor outlined here and in Sanford 2012. Speakers’ repeated exposure to utterances predicated on a particular cross-domain mapping license the formation of a metaphorical representation—a conventionalized link between two domains, corresponding to ‘X IS Y’ Lakovian conceptual metaphors. For language users in the act of engaging in figurative speech, previous exposure to metaphorical systems has a direct, measurable effect on the way in which they use and process metaphorically predicated utterances.
The corpus study reported here indicates that metaphors vary widely from one another in their frequency of use. This variation is not surprising of itself (although the extent of this variation is something that I, at least, have found startling), but the implications of this variation for our understanding of metaphor are both diverse— relating not only to the processing of metaphorical utterances, but also to changes in metaphorical systems over time as usage affects the structure of the system itself in ways that have been well-attested at other levels of linguistic structure— and largely unexplored. In accounting for both the ways in which individual speakers use metaphor and the distribution of metaphor in discourse, this study points towards deeper insight to be gained from enriching our current understanding of metaphor with a greater awareness of the effect of speakers’ previous exposure to metaphor on the processing of metaphorical utterances, and the ways in which this bears, cumulatively, on the emergence and diachronic development of metaphorical systems in human conceptual systems.
4While these hypotheses may appear patent from the perspective of learning theory, which has long embraced the effect of frequency on storage and processing, they are far from accepted within linguistics, within which the role of repetition has not widely been attributed a significant role in shaping metaphorical systems (indeed, the role of frequency in shaping linguistic structure is itself very far from universally recognized). In addition, while a number of studies (see §1) have indicated a role from repetition on the processing of specific metaphorical words and utterances, the effect of repetition on processing for metaphorical mappings themselves is neither well researched nor well understood. 5Semantic factors are themselves important in syntactic schemata. Bybee & Eddington (2006), in a study of Spanish verbs meaning ‘become’ and accompanying adjectives, demonstrate that the token frequency of constructions has a direct effect on how speakers rate the acceptability of sentences. Moreover, they show that expressions semantically similar to highly frequent ones are also judged to be more acceptable, demonstrating that semantic relations play a primary role in formation of exemplar-based representations. 6For example, the words selected for PLANTS and BATTERIES are flower and Duracell (a type of plant, and type of battery), growing and charging (things that plants and batteries do, respectively), and small and rechargeable (traits that can apply to members of the category). 7In an initial version of the experiment, the prompt portion of the stimulus took the form of a metaphor rather than a simile, lacking the word ‘like’ (i.e., “Mary is ____”). Despite instructions that directed participants towards figurative completions, metaphorical completions were almost unattested in trials of the experiment in its original form. The current version is much more successful in prompting figurative responses, which follows from and provides support for Gentner & Bowdle’s (2001, 2005) assertion that the simile sentence form prompts figurative processing.