People consult dictionaries for various purposes. Receptive linguistic users, readers or listeners, need a reference book to find the meaning of a word they have read or heard. However, in the active linguistic state, writers or speakers require wordbooks to satisfy the need to go from meaning or concept to a corresponding word.
Onomasiological dictionaries have been created precisely to help authors in a “tip of the tongue” state (Brown & McNeill, 1966), that is, a state in which they do not remember a word, or for authors who ignore the word expressing the meaning they have in mind.
According to the kind of information contained, the structure, and the search strategy, onomasiological dictionaries can be classified as Thesauri, Synonym Dictionaries, Reverse Dictionaries, and Visual Dictionaries. Despite this great variety of options, people still have problems finding the correct word because these resources still assume too much from the user. For example, these dictionaries expect that users know the precise words to describe the object for which they would like to find the corresponding word. This is why some researchers have proposed to use natural language searching, also known as free-text searching (Lancaster, 1972). Onomasiological dictionaries allow users to input their descriptions of a concept or idea through more than one word in a search instead of using isolated words.
The main problem with this solution is that people express the same concept (say
One way to solve this problem is to obtain many descriptions from people with various backgrounds (academics, journalists, non-professionals, etc.). This would allow one to create a rich Knowledge Base likely to fit most users.
Since the Internet is the richest source of information available, it makes sense to use it to extract automatically term descriptions. To this end we use DESCRIBE, a tool to look for definitions of terms available on the web. DESCRIBE uses a set of Spanish language patterns commonly used when giving a definition. These patterns, known as Definitional Patterns, are classified in typographic and syntactic patterns. The first ones refer to the punctuation marks that usually connect the term with its definition, while the second ones allude to the verbs that introduce a defining predicate, such as
2. Onomasiological Dictionaries
Most people have at some point experienced the so-called “tip of the tongue” problem (Brown & McNeill, 1966). This occurs when speaking or writing and consists in not being able to recall a term or a word one knows, when remembering the concept. Onomasiological dictionaries can be of help in dealing with this problem, as they allow word access on the basis of meaning. They operate in the reverse order of conventional (semasiological) dictionaries. Onomasiological dictionaries were designed to help the user to go from the concept to the term.
2.1 Typology of onomasiological dictionaries
We describe here the most representative kinds of wordbooks that claim to solve the need of writers who need to go from a meaning or a concept to a corresponding word. (1) Thesauri, representative of most conceptual reference books with a systematic table of subjects; (2) reverse dictionaries, with specific characteristics that allow a user to search directly from a clue word rather than from an index or a conceptual tree; (3) synonym and antonym dictionaries, sometimes confused with thesauri but quite unlike them, since they are differently structured and operate with words rather than concepts (Alvar-Ezquerra, 1984); and, finally, (4) pictorial dictionaries, that present concepts through pictures rather than words.
2.1.1 Thesauri
According to Shcherba (1995), thesauri were the first onomasiological dictionaries with
Thesauri can help users find “unknown words” for a given meaning (Hüllen, 1986); that is, the user can find other words related to a given concept. Hence, they allow users to extend their lexical competency by searching the most related themes and finding “new words.” Therefore, some lexicographers are convinced that thesauri fit writers’ needs (Riggs, 1982). Conversely, other studies have shown that it is very frustrating and sometimes almost impossible to find a target word in a thesaurus like
As a result, the usual steps for getting a target word from a concept are, first, to get an approximation to the concept, and, second, to choose a clue word to start the search. In other words, the process consists of homing in on words that characterize the concept and then selecting a small number of words that appear most relevant for a search. Nevertheless, sometimes users have difficulties in one or both steps as well as in the identification of the exact search words that match with the headwords of the thesaurus.
2.2.2 Reverse dictionaries
In using a “reverse dictionary,” users think of a concept and a clue word referring to it, then go to the main body of the dictionary. As the macrostructure is alphabetical, the user goes directly from the clue word to the entry with the target word, without an index. Every clue word has a reduced list of related words following a brief definition for each concept. This allows users to check whether it fits the meaning one has in mind.
While useful, there are nevertheless two difficulties with these dictionaries: there may be no suitable clue word or, if one exists, it may not lead to the target word. For example, Bernstein’s Reverse Dictionary (Bernstein, 1975) has 13,390 entries which can be accessed via approximately 8,000 clue words: about two entries for every clue. This is insufficient because there are many ways of thinking of a concept.
2.2.3 Synonym dictionaries
Synonym dictionaries contain a list of words that are related by their meaning (Miller, 1995). The entries are usually ordered alphabetically, while the internal list of words related to each entry might be sorted alphabetically, by senses, or otherwise.
With these dictionaries users must think in terms of clue words with a similar meaning to the target word, rather than that of associated words leading to the concept. The main purpose of such dictionaries is to give users an alternative word for the one they already know. In this way users increase their lexicon, and second language learners can use it as a learning tool. Unfortunately, it seems they are not the most appropriate tools to find a target word expressing a given concept (Sierra, 2000).
2.3.4 Pictorial dictionaries
Like thesauri or reverse dictionaries, pictorial dictionaries organize words in terms of topics, but for every topic there is a series of images rather than words to represent the topic or its elements. Since words are represented by images, there is no need for definitions. Pictures represent the vocabulary of an entire subject within the classification. In order to help users identify related words, there is usually an alphabetically sorted index.
This type of dictionary can help to find a word one has forgotten, because their onomasiological approach permits the user to look up an image of the concept and get the target word. However, a drawback of these dictionaries is that they are only suitable for physical objects and those parts or species that can be represented visually. Most pictorial dictionaries only list nouns, but in some cases verbs representing actions and a few adjectives can be illustrated as well. It seems that the subjects and the information given in each picture depend on the imagination of the draughtsman. It is for example possible to find 40 kinds of hats and caps. In this way, the dictionary becomes an encyclopedia.
In spite of the variety of approaches for trying to facilitate onomasiological search, there is no dictionary that fully enables users to find a word by expressing their idea. Existing dictionaries, simply provide a list of related terms sorted either alphabetically (e.g., synonym dictionaries) or by concepts or topics (e.g., thesauri). Pictorial dictionaries cannot help with concepts that cannot be drawn, while in reverse dictionaries there are only one or two ways to get to the target word, but the user may not always think precisely in those terms (Sierra, 2000). There have been other works in this area, such as Bilac
The first problem for the user arises with the conceptual input, that is, the way in which the concept is expressed in order to start the search (Moerdijk, 2008). The user must be able to translate her idea in terms of words, and then select the one(s) that in her opinion are most relevant for the main idea that needs to be expressed but is forgotten (Zock, Ferret, & Schwab, 2010). Once a user has these words, she must check to see whether or not they match the ones found in the dictionaries. However, users are not always able to express their concepts clearly and unequivocally, so they do not always get the expected result.
There is also the problem that there are many ways to express an idea. The vocabulary of ordinary people is too extensive and their experience of the words’ usage too diverse to expect everyone to come up with the same description, using exactly the same clue words to refer to a particular concept (Alcina, 2009). Aitchison (1994) does not consider the obvious fact that experts and laymen make a distinction between essential and nonessential features. Despite the fact that experts might be able to specify the true nature of things, they sometimes provide information which is irrelevant for the mental lexicon. Conversely, ordinary people disagree among each other, and sometimes even among themselves, i.e. they change their minds.
Evidence for this can be found in an experiment carried out by Sierra (2008). This experiment reveals how linguistic and cultural differences affect the expression of a concept. For example, descriptions of a word, say squirrel, may vary from person to person:
In this experiment Sierra also showed how social, cultural, and geographical factors influence the way in which people acquire knowledge and, thus, perceive the world. These differences in perception make it clear that a helpful onomasiological dictionary has to take into account not only the lexicographers’ point of view, but also the many ways in which users can see the world.
2.3 The conception of a dictionary
Dictionaries are generated according to the criteria of authors or publishing houses. While there is some consensus, lexicographers nevertheless often disagree with respect to the structure of the dictionaries due to the different conceptions of how the world is organized. And it is unlikely to think that users conceive of the world in the same ways that dictionary makers do (Zock, Wandmacher, & Ovchinnikova 2010).
Hence, for an onomasiological dictionary to be truly useful, it must allow users to express their ideas in their own terms, relying on words they know and forming sentences (queries) the way they would normally do when asking others for help in recalling a forgotten word. Put differently, dictionaries must accept a great variety of words in order to retrieve the missing word even if the user does not use exactly the same terms given by the lexicographer’s definitions.
3. The Lexical Knowledge Base (LKB)
As noted by Zock & Schwab (2008), an onomasiological dictionary must consider the various properties of the concepts it is meant to express, as well as the diversity of forms allowing reference to these concepts. Hence, the foundation of this dictionary is the lexical knowledge base which will contain all the knowledge that is required for an onomasiological search.
Before talking about the LKB of an onomasiological dictionary it is necessary first to consider the dictionary that will implement it. DEBO is the electronic dictionary for onomasiological search that has been developed by our
DEBO works with user queries given in natural languages. This means that users can define concepts in their own words. The dictionary will “interpret” a query and retrieve the terms whose definitions matches best the concept given by the user. In this manner, users can express their ideas or concepts in a similar way as they would do if they were asking other humans for help in recalling an elusive word. DEBO is a specialized dictionary and its LKB is focused only on certain areas of expertise such as “Linguistics, Sexuality, Veterinarian, Natural Disasters, etc.”
In order to allow users to convey their ideas freely as in DEBO, one needs a LKB containing a rich set of equivalent terms. In other words, the lkb must take into account a great variety of conceptions or definitions of a particular term. This allows users to enter a query using a large set of (semantically equivalent) terms. It is highly convenient to have for each term in the LKB an important number of definitions since it allows access to the same word using different terms.
Given the variety of definitions users are likely to employ to refer to the same term, it is natural to think of the LKB as a rich pool with a wide assortment of definitions coming from an extended diversity of sources, both normative and non-normative. Thus, the lkb will be built by drawing on the following sources:
From these sources it is possible to generate a specialized corpus with a sufficiently powerful and flexible lexicon to accept various queries in natural languages.
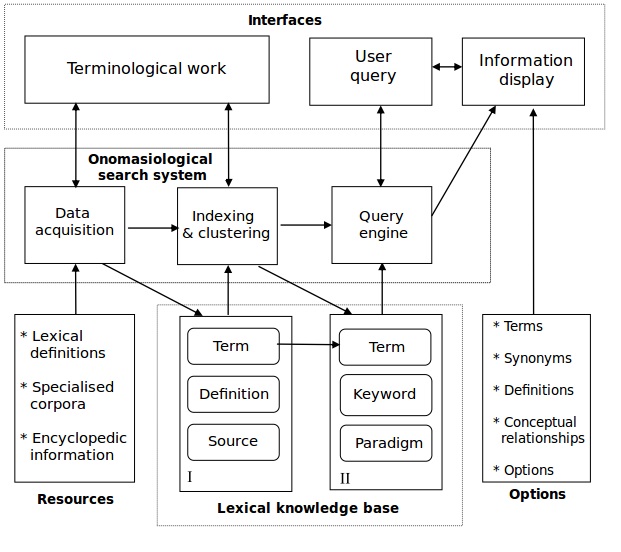
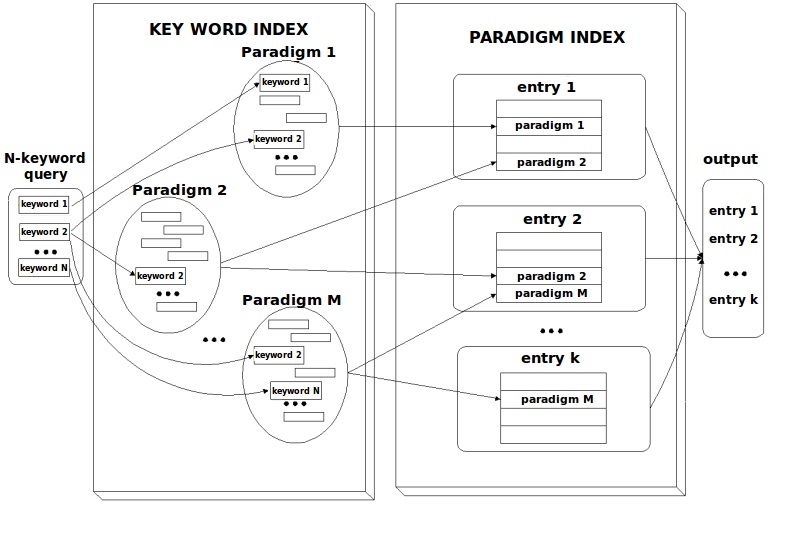
The LKB is organized in such a way as to allow DEBO to “understand” users’ queries and retrieve reasonable responses (Fig. 1). This architecture is comprised of the following modules.
3.2.1 Terms
This module refers to the terms the dictionary contains, terms which the user will be able to access through consultation. These terms are relative to a specific domain since DEBO is a specialized dictionary. Each term stored in the LKB will be related to its definitions and a set of key words by means of unique identifiers.
3.2.2 Definitions
The definitions were obtained from the different sources, and they are used for matching the users’ queries. Success or failure during search depends on the quality (i.e. variety and accuracy) of these definitions. In consequence, they ought to be rich and diverse. As mentioned already, they must consider both normative and colloquial denotations in order to be representative for the many ways in which a concept might be defined. We have noticed experimentally that the greater the number of definitions, the more representative the data of debo are, and in consequence, the better its performance is.
3.2.3 Reference sources
In order to determine the reliability of the source from which each definition is obtained, it is important to keep a record of the origin of all data. This module is important, since the LKB is filled with data coming from many kinds of sources, each one with a different level of formality. Therefore, it is important to have a means to verify the reliability of the source.
3.2.4 Key words
Not all words are alike. Some are more important than others, and this applies also for definitions, especially when launching a search. These important terms are named key words and are distinguished from the rest by the fact that they provide the essential information that allows the system during search to make a choice between competing terms. The search engine extracts the key words of every definition and clusters them according to the term to which they refer. So when users introduce their queries, the system is capable of comparing the key words from the users’ entry with the key words of the terms known by the system to see whether it can find a match. The remaining terms (called functional words) are discarded, as they do not contain relevant information with respect to the search. These words are stopwords, which include determiners, prepositions, conjunctions and other kind of nexus words used in natural language to link words and ideas.
3.2.5 Paradigms
Another important point is the fact that users do not always use the same words to define a concept. Given the diversity of social backgrounds, users may have a highly heterogeneous vocabulary and use both specialized and colloquial words with similar meanings. Consequently, DEBO must have a way to associate these words and to be able to interpret them as pointing to a single type of notion.
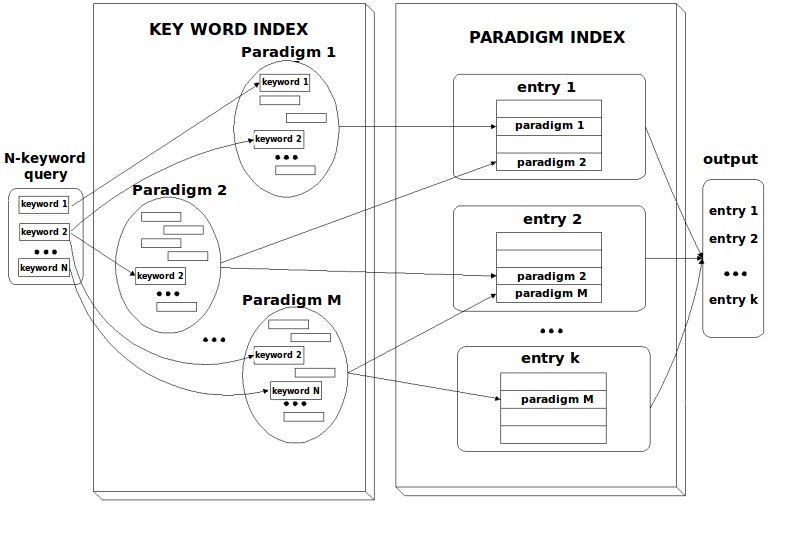
The LKB has a repository of grouped words (semantic paradigms) from which DEBO makes the necessary associations between the users’ definitions and its own knowledge (acquired previously from different sources). For example, a user might have a definition such as “
This group of words may be obtained automatically from regular synonym dictionaries or through clustering algorithms. It is also possible to capture manually topic-related words or localisms, which allow the dictionary to provide more accurate output and more versatility. The scheme according to which our dictionary will work using paradigms is shown in Figure 3.
It is worth mentioning that the amount of information required for the LKB is very large and very broad. As such, it would be expensive and time consuming to acquire this kind of knowledge manually. This is the main reason why our group developed DESCRIBE, which uses ECODE, a tool previously developed by our group and the key to populate the LKB.
3.3.1 ECODE
ECODE was developed for written Spanish and its main action fields are Terminography and specialized knowledge. Its purpose is to obtain definitional contexts both for specialized and general vocabulary (Alarcón, Bach & Sierra 2008).
According to Alarcón, Bach & Sierra (2008), a definitional context (DC) is a textual fragment in which the definition of a term occurs. It is structured by a term and its definition, both being connected typographically by means of a syntactic pattern.
Analyzing this example, the following features can be obtained:
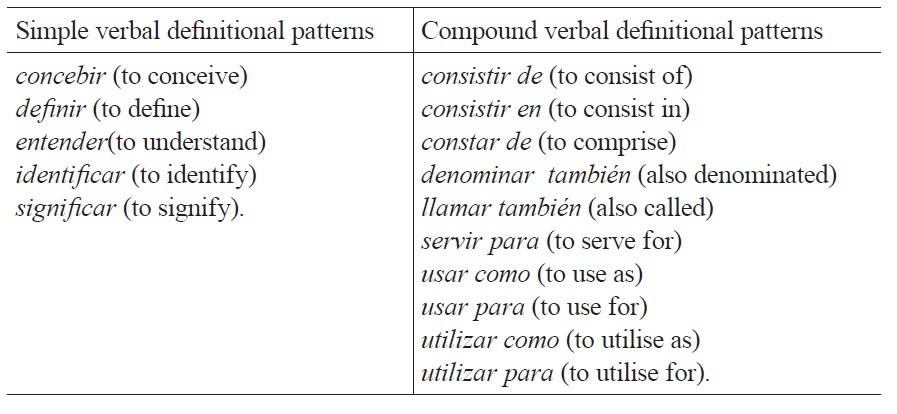
There are fifteen definitional verbal patterns, which we have divided into simple and compound patterns (Table 1). Due to space limitations, it is not possible to elaborate on how these patterns were obtained (for further details, see Alarcón, Bach & Sierra, 2008). These are the most commonly used verbal patterns for definitional contexts in the IULA’s Technical Corpus and its search engine bwanaNet. This corpus is composed of specialised documents in Law, Genome, Economy, Environment, Medicine, Informatics, and General Language.
After identifying these verbal patterns, there is a process of automatic tagging via Perl scripts. These contextual tags consist in the annotation of the verbal pattern with the tags “
[Table 1.] definitional verbal patterns used by ECODE
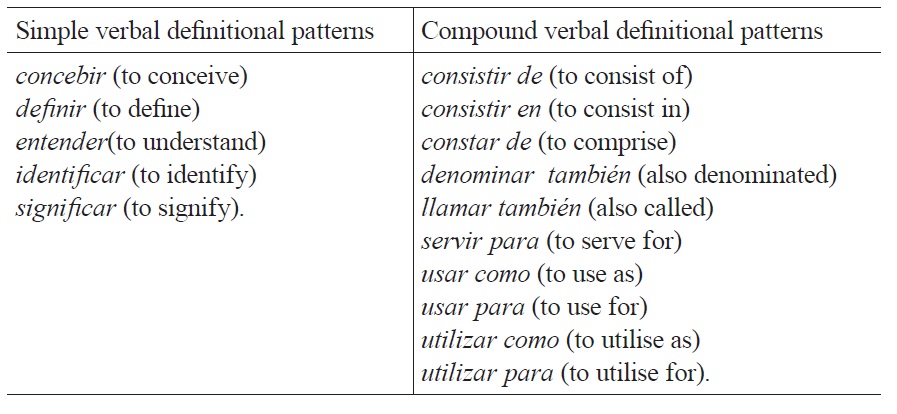
definitional verbal patterns used by ECODE
Once the occurrences are extracted and annotated with definitional verbal patterns, irrelevant contexts are filtered out. This step is based on the fact that these patterns are used not only in definitional sentences. In the case of definitional verbal patterns, some verbs tend to have a richer metalinguistic meaning than others; some of them could be used in a wider variety of sentences. Moreover, the verbs with a rich metalinguistic meaning are used not only for defining terms.
Alarcón, Bach & Sierra (2008) attempted to determine what sorts of grammatical particles or syntactic sequences could appear in those cases in which a definitional verbal pattern is not used to define a term. Those particles and sequences were found in specific positions. For example, some negation particles like
As noted by Alarcón, Bach & Sierra (2008), once the irrelevant contexts are eliminated, the next step consists in identifying the main terms, definitions, and pragmatic patterns. In Spanish, definitional contexts and, depending on the definitional verbal pattern, terms and definitions can appear in some specific positions. Thus, during this phase the process consists mainly in identifying the positions in which the constitutive elements appear.
Alarcón, Bach & Sierra (2008) proposed to use a decision tree to solve this problem. There are some simple, well established, regular expressions to represent each constitutive element:
Just as during the filtering process, the job of the contextual tag is to establish the borders of the decision tree’s instructions. Regular expressions can also function as borders.
In order to summarize, the next image shows broadly the architecture of ECODE
3.3.2 DESCRIBE
ECODE was initially developed to extract definitional contexts from specialized documents. Nevertheless, the same definitional verbal patterns that work while introducing definitions in formal writings are often used in informal documents to the same ends. At GIL, we took advantage of this fact, which allowed us to extend the scope of ECODE.
As stated previously, the LKB needs a wide variety of definitions from speakers coming from many backgrounds in order to cover as many expressions as possible. The widest and greatest source of information available nowadays is the Internet, which allows everyone with a computer and a web connection to express ideas and share knowledge. By analyzing Internet contents, it is possible to obtain a sufficient stock of definitions, both formal and colloquial.
At GIL we adapted ECODE to work with and analyze documents downloaded automatically from the web in order to find definitions of a specific term. Given the diversity of on-line information, it is possible to obtain thousands of definitions in a very short time and store them in a data base from which the LKB could obtain its data and allow the onomasiological dictionary to give more satisfactory and accurate answers. This new form of ECODE called DESCRIBE (Sierra
The design of an onomasiological dictionary must foresee first a multiplicity of properties for each concept and secondly the diversity of words that can be used to name them. The task of the LKB consists in accurate interpreting the description of the concept and providing the word or probable words the user is looking for. The LKB is currently being used to implement and develop the search engine of an onomasiological dictionary.
Given the architecture of the LKB for the onomasiological dictionary, it is necessary to have as many definitions as possible, taking different speakers into account. DESCRIBE has proven to be an excellent information retrieval resource that populates automatically the database needed for the onomasiological search process. Using DESCRIBE one can build a knowledge base covering a wide range of academic issues and opinions. This in turn allows one to create a valuable linguistic resource that takes into account diverse individual and cultural points of view concerning concept definitions.
The current status of DESCRIBE allows us to obtain hundreds of definition candidates for each term, but they must be evaluated manually by someone. The results obtained vary depending on the term that is being analyzed, and there is no an evaluation methodology. At the present time we are still working on improving the results and simplifying the evaluation process.