In this paper, we explore the hypothesis that learners are biased to the same phonological patterns that are preferred across languages of the world (Cristia & Seidl, 2008; Finley & Badecker, in press; Moreton, 2008; Wilson, 2006). Specifically, we explore typological variation in vowel height harmony, a phonological process whereby adjacent vowels in a word are required to share a common feature value for vowel height. We show that learners of a miniature, artificial height harmony language are biased towards the same height harmony patterns that are typologically frequent.
Understanding the nature of learning biases is an important endeavor for cognitive science. Because language is one of the fundamental systems that all human beings must learn, learning biases for linguistic processes are particularly important. Three related questions arise in the study of language learning. First, to what extent is the learning process driven by constraints specific to language, as opposed to domain general constraints? Second, to what extent does innate or pre-existing knowledge interact with the patterns that must be inferred from the language input? Third, to what extent can we explain the typological distribution of patterns of language in the world in terms of constraints on learning? In order to begin to answer any of these three questions, we must first understand more about the learning process, specifically the nature of biases that learners bring to the learning process. For example, some studies have suggested that learners use domain general heuristics to learn novel patterns (Christiansen & Chater, 2008; Finley & Christiansen, 2011). Other studies have shown learning biases that make use of language-specific patterns (Culbertson & Smolensky, 2010; Finley, in press; Finley & Badecker, 2008; Moreton, 2008). For example, Finley (in press) found differences in learning round vowel harmony patterns that differed only in terms of vowel height (i.e., high vs. mid). Because vowel height is a linguistic feature, any explanation for the differences in learning must be couched in terms of language. However, within phonological theory, there is debate as to whether learning biases are based on abstract structural properties, or gradient phonetic variables (Moreton, 2008). The existence of both domain general and language specific learning biases suggest that the question for linguistic theory (and cognitive science) is not whether language learning is domain specific or domain general, but the extent to which language specific and domain general constraints interact.
Because a complete theory of language involves a theory of how language is learned, understanding the aspects of learning biases is extremely important. For phonological patterns (patterns that involve systematic constraints on sounds in a language), the learner makes use of phonetic principles in learning, but must also be able to bypass phonetic grounding in order to infer a phonetically unnatural pattern. Several studies have shown that phonetically grounded patterns may be easier to learn than patterns that do not show phonetic grounding (Carpenter, 2005; Finley, in press; Finley & Badecker, 2009b; Moreton, 2008; Peperkamp, Skoruppa, & Dupoux, 2006; Pycha, Nowak, Shin, & Shosted, 2003; Schane, Tranel, & Lane, 1974; Seidl & Buckley, 2005; Wilson, 2003, 2006). Other studies have found no differences in the ability to learn phonetically grounded patterns versus patterns that lack phonetic grounding (Peperkamp & Dupoux, 2007; Seidl & Buckley, 2005). For example, vowel harmony shows greater phonetic grounding than vowel disharmony, but learners in an artificial setting were able to master both patterns (Pycha, et al., 2003; Skoruppa & Peperkamp, 2011). Other studies have shown that it is possible to learn patterns that have no phonetic grounding, and are not found in natural language (Koo & Callahan, in press). These variable results suggest that the learning mechanism for phonological patterns is robust enough to learn arbitrary phonological patterns, but may favor patterns that have a phonetic basis. As more biases (and lack of biases) are uncovered through learning experiments, we can better understand the precise nature of the learning mechanism and how it uses (or ignores) phonetic principles.
In the present study, we demonstrate that learners of a novel vowel height harmony pattern are biased to learn harmony patterns involving front vowels over patterns involving back vowels, correlating with the cross-linguistic typology. For the purposes of this paper, vowel height harmony refers to languages in which high (e.g., [u], [i]) and mid (e.g., [e], [o]) vowels may not appear together in the same word, creating alternations between mid vowels and high vowels. For example, in Buchan Scots English, final vowels alternate between [e] and [i], depending on the height of the vowel in the stem (Paster, 2004).
In Buchan Scots, only front vowels undergo harmony. Back vowels may trigger harmony, (as in [mom-e] ‘mommy’), but do not undergo harmony. This type of pattern demonstrates an asymmetry between front and back vowels undergoing harmony. Hyman (1999) notes that in Bantu, the canonical height harmony system follows an asymmetry whereby front vowels may undergo harmony following either a back or a front vowel, while back vowels only undergo harmony following another back vowel (e.g., Shona words /gobor/, */gobur/ ‘uproot’ vs. /serenuk/, */serenok/ ‘water (gums of mouth)’) (Beckman, 1995, 1997; Hyman, 1999; Riggle, 1999).
In Swahili, the applicative suffix appears as [i] following /i, u, a/ and [e] following /e, o/, but the reversive suffix appears as [u] after /i, e, u, a/ and [o] only following /o/ (Kula & Marten, 2000).
These data demonstrate the general asymmetry between front and back vowels undergoing harmony; front vowels undergo freely while back vowels tend to undergo only following another back vowel.
Linebaugh (2007) surveyed over one hundred languages with vowel height harmony from several different language families. 1 Linebaugh cites at least 59 languages with symmetric harmony (both front and back vowels undergo harmony equally), at least 52 languages with an asymmetry towards front vowels (whereby front vowels undergo harmony following both front and back vowels, but back vowels undergo harmony only following back vowels). Linebaugh cites only two languages with a potential bias towards back vowel undergoers. In Brazilian Portuguese /u/ triggers the raising of /o/ more often than the raising of /e/. In Menonimi, short vowels do not participate in height harmony, with the exception of the back vowel /o/, which raises following a glottal stop. While Hyman (1999) cites a group of Bantu languages that have height harmony involving back vowels only, this harmony is highly restrictive in that /u/ lowers to [o] only following another /o/, and is therefore constrained by identity. Among the height harmony languages surveyed, none involved a front vowel height harmony pattern that required identity.
There is some evidence that the restrictions on back vowels undergoing height harmony have a phonetic basis. Typological restrictions on height harmony patterns can be explained in terms of the perception and production of rounding based as a function of vowel height. Speakers produce greater degrees of rounding (measured in terms of vertical opening and lip protrusion) for high round vowels over mid round vowels 2 (Kaun, 2004; Linker, 1982). According to Terbeek’s (1977) scale of the perception of vowel rounding, 3 /u/ shows a higher degree of perceived rounding than /o/. These facts may induce a preference against mid round vowels. This bias against /o/ could lead to a bias against /u/ (a high back rounded vowel) from lowering as a result of height harmony. This possibility is especially salient because height harmony is most often characterized in terms of lowering (Harris, 1994; Hyman, 1998; Linebaugh, 2007; Riggle, 1999).
Another possible source for the asymmetry between front and back vowels undergoing harmony may result from the fact that [e] and [i] have the same constriction location but [o] and [u] often have different constriction locations (pharyngeal and velar, respectively). 4 It may be more difficult to lower back vowels if lowering a high /u/ to a mid /o/ requires an additional change in constriction.
In addition, differences in F1 coarticulation between front versus back vowels may provide an additional source for the preference for front vowels to undergo height harmony. Coarticulation is thought to be a significant phonetic precursor to vowel harmony (Beddor, Harnsberger, & Lindemann, 2002; Ohala, 1994). While coarticulatory effects depend on the language and the individual speaker (Beddor, et al., 2002; Manuel, 1990), there are reasons to believe that the coarticulatory precursors to height harmony are stronger for front vowels compared to back vowels. All else being equal, front vowels are less likely to experience interference from consonants in vowel-to-vowel F1 coarticulation than back vowels (Recasens & Pallares, 2000). This suggests that the coarticulation of F1 will be stronger for front vowels than back vowels.
In order to explain how these phonetic factors resulted in a crosslinguistic asymmetry between front vowels and back vowels undergoing height harmony, we must hypothesize that these phonetic factors were part of language change. One possibility is that vowel-to-vowel coarticulation becomes a categorical vowel harmony rule through a historical process called
If vowel harmony emerges as a phonologization of coarticulation between vowels, coarticulation of F1 should be more likely to be phonologized into a categorical rule where the cue is strongest (front vowels). Note that this simplified explanation of phonologization assumes that intervening consonants are ignored. However, this is not always the case. For example, some vowel harmony languages (e.g., Turkish (Clements & Sezer, 1982)) show systematic interactions between vowels and consonants.
Hyman (1999) proposes that front height harmony was an innovation in Bantu languages. Given the phonetic bases for front vowels undergoing harmony, it follows that harmony would most likely be innovated for front vowels with minimal restrictions, while back height harmony would continue to involve the restriction that back vowels only undergo following a back vowel. In Buchan Scots, vowel height harmony emerged without involving back vowels, suggesting that front vowel height harmony is innovated separately from back vowel height harmony, and that the innovation of height harmony may be biased to apply to front vowels.
The specific process of phonologization is still unclear (and may apply differently for different languages, and different phonological patterns). One likely source for phonologization is through first and second language learning. Generations of learners may make use of general phonetic principles, as well as phonetic cues in the input, resulting in languages changing over time. If these innovations are easier to learn due to learning biases, then these innovations are more likely to ‘stick’ and become a regular part of the language. The question addressed in the paper is not whether learners innovate from phonetic grounding, but whether learners show biases towards phonetically grounded patterns. This would simulate the idea that phonetically grounded innovations are more likely to become part of the language than phonetically ungrounded innovations.
In this paper, we specifically address whether learners are sensitive to differences in front vowels versus back vowels in undergoing height harmony. A bias towards front vowels to undergo height harmony will be demonstrated if learners show increased selection of for harmonic items involving front vowel undergoers. This can be shown in two ways. First, if participants trained on front vowels undergoing harmony show evidence of learning the pattern (i.e., selecting the harmonic item at a level significantly greater than a Control condition), but participants trained on back vowels undergoing height harmony fail to do so, it suggests that height harmony involving front vowel undergoers is easier to learn (in the context of the experiment). Second, if participants extend the harmony pattern to novel front vowels, but not novel back vowels, it would suggest that participants were biased to learn a pattern in which front vowels undergo harmony, but back vowels do not. These predictions are borne out in two experiments.
1Linebaugh often cites languages as groups (e.g., at least 46 languages that exhibit canonical Bantu asymmetries between front and back vowels) making it impossible to cite a specific number. 2However, according to an anonymous reviewer, some speakers may show more lip rounding for /o/ than for /u/. 3This scale was based on fitting F1 and F2 measurements to triad judgments in which the listener chose the two vowels in a set of three that were most similar in English, German, Thai, Turkish and Swedish. 4Thank you to an anonymous reviewer for suggesting this possibility.
Experiment 1 tests for learning biases for front/back asymmetries in height harmony. Participants were trained on one of two artificial languages in which either front vowels undergo height harmony (via the suffix alternation [-i]/[-e]) or back vowels undergo height harmony (via the suffix alternation [-u]/[-o]). Note that the morphological terminology ‘stem’ and ‘suffix’ are used throughout the description of the experiments to conform to the fact that vowel harmony processes are typically instantiated as morphophonological alternations of affixes. No explicit mention of morphology or semantics was provided to participants, nor were participants tested for morphological awareness.
If participants are biased towards front vowels undergoing height harmony, we expect both that participants trained on front vowels undergoing height harmony will select harmonic items at a level greater than chance, while participants trained on back vowels undergoing height harmony will fail to do so. In addition, we expect that learners will select the harmonic item for novel front vowels (following exposure to back vowels undergoing harmony), but fail select the harmonic item for novel back vowels (following exposure to front vowels undergoing harmony).
All participants were adult native English speakers with no knowledge of a vowel harmony language. Sixty-one Johns Hopkins undergraduate students participated for extra course credit and had not participated in previous vowel armony learning experiments. Participants were randomly assigned to one of three training conditions: a Control condition (exposed only to stems, half of which followed height harmony), a Front Vowel (Stem) Training condition (exposed to stem-suffix alternations in which the suffix was always a front vowel) and a Back Vowel (Suffix) Training condition (exposed to stem-suffix alternations in which the suffix was always a back vowel). Participants were screened with a perceptual (AXB) task (described in detail below); the data for those scoring less than 75 percent on this screening task were discarded. This occurred for one participant, leaving 20 participants in each condition.
[Table 1.] Experiment 1 Design
Experiment 1 Design
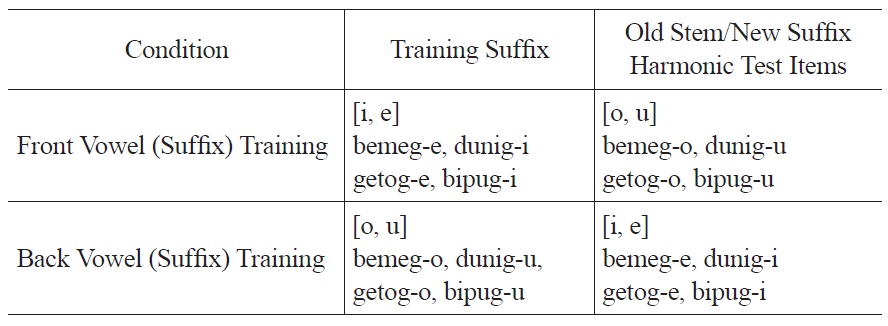
In the training phase, participants in the Front Vowel (Suffix) Training and Back Vowel (Suffix) Training conditions were exposed to a height harmony alternation. This height harmony alternation was presented as a series of CVCVg-V stem-suffix pairs (e.g., [genog, genoge]), such that the corresponding suffixed form immediately followed its corresponding harmonic ‘stem’ form. The height of the stem vowel always determined the height of the suffix vowel. The suffix vowel consisted of either a front non-round vowel ([-i] or [-e]) in the Front Vowel (Suffix) Training condition, or a back round vowel ([-u] or [-o]) in the Back Vowel (Suffix) Training condition. CVCVg stems were identical for both critical training conditions, and consisted of both front and back vowels equally. Examples of training stimuli for these two critical conditions are provided in Table 1. (Full stimulus lists appear in Appendix A.)
The Control condition was designed to measure participants’ responses to test stimuli when no consistent evidence of a harmony pattern in the training stimuli is given. In addition, the Control condition is used to identify potential artifacts of the stimuli and the test order (Redington & Chater, 1996). Specifically, the Control condition was designed to rule out the possibility that responses were based solely on phonetic differences between front and back vowels, rather than learning biases.
If participants show responses significantly different than the Control condition, we can assume that the participants in the critical conditions made their response choices based on the training they received. While there are many ways to provide training without a consistent harmony pattern (e.g., in Experiment 1B we used a No Training Control condition), we exposed participants in the Control condition to the same stems that participants in the critical condition were exposed to,
Following training, all participants were given a two-alternative forcedchoice test consisting of pairs of harmonic and disharmonic suffixed items (e.g., [bimugi vs. *bimuge]). Each test item belonged to one of three distinct categories: items that were heard during training (Old Stem/Old Suffix), novel items that contained a new stem and the training suffix vowel (New Stem/Old Suffix), and old stem items that contained a novel suffix vowel (Old Stem/New Suffix). The vowel that contained the novel suffixes always complemented the training suffix on the front/back dimension: Old Stem/ New Suffix test items in the Front Vowel (Suffix) Training condition always contained back vowel suffix, while Old Stem/New Suffix test items in the Back Vowel (Suffix) Training condition always contained a front vowels suffix.
Participants were instructed to choose which of the paired suffixed forms belonged to the language they had heard during the training phase of the experiment. We created a balanced control condition by splitting the Control condition into two sub-groups. Half of the participants in the Control condition received test items identical to the Front Vowel (Suffix) Training condition and the other half received test items identical to the Back Vowel (Suffix) Training condition. Note that the items used in for the Old Stem/ Old Suffix test items in the Front Vowel (Suffix) Training condition were identical to items used for the Old Stem/New Suffix test items for the Back Vowel (Suffix) Training condition. This means that participants in the Control condition responded to items that matched the Old Stem/Old Suffix and Old Stem/New Suffix items for both critical training conditions. Statistical analyses were always performed with respect to the test items that matched the critical condition.
The naturally produced stimuli were recorded in a sound-attenuated booth at 22,000kHz from an adult male speaker of American English with basic phonetic training (he had completed a graduate-level phonetics course), and all sound editing used Praat (Boersma & Weenink, 2005). While the speaker had no knowledge of the specifics of the experimental design, he was aware that the items would be used in an artificial language learning task. All stimuli were phonetically transcribed, and presented to the speaker in written format. The speaker was instructed to produce all vowels as clearly and accurately as possible, even in unstressed positions. Stress was produced on the first (stem) syllable in all forms. All consonants were drawn from the inventory: [p, b, t, d, k, g, m, n]. The inventory of vowels was [i, e, u, o]. Because the speaker was told to produce the vowels naturally, there was natural diphthongization in the vowels
All suffixes were recorded separately from stems, and spliced together. For example, [bidigi] was recorded by combining [bidi] from [bidigə] and [gi] from [bəbəgi] (which was also stressed on the first syllable). Splicing the suffixes ensured that the only distinction between the two test items was the stem, thereby removing coarticulatory effects between the final stem vowel and the suffix.
F1 and F2 measurements for the final stem vowel were made to ensure that the cues for the front/back vowel dimension were acoustically present. We compared the F1 and F2 values for front and back vowels using a 2 X 2 ANOVA (height by backness). Both front and back high vowels had significantly lower F1 values than corresponding mid vowels,
The training stimuli were counterbalanced to contain all possible heightharmonic combinations of vowel sounds, both with equal numbers of identical (repeated) and non-identical (non-repeated) pairs of stem vowels across all conditions, but all stem items in the critical conditions were harmonic. For the four vowels in the training set, the 8 possible harmonic vowel pairs were repeated three times each for a total of 24 training items ([i, i], [i, u], [u, i], [u, u], [e, e], [e, o], [o, e], [o, o]). The consonantal skeletons (CVCVg) were prepared for each of the eight vowel pairs for a total of 24 training words. Consonant skeletons were constructed so that each of the eight consonants ([p, b, t, d, k, g, m, n]) occurred in word initial position three times and word-medial position three times. Stem-final consonants were [g] 5 throughout, to ensure that the VCV co-articulation from stem to suffix was the same for all stem vowels. Vowel pairs were assigned to consonant skeletons semi-randomly with the condition that any word too closely resembling an English word was excluded (the final profile of the stimuli was counterbalanced to appropriately contain equal numbers of consonant pairs and a consistent number of vowel pairs). Consonant skeletons were created in the same manner for all training and test items.
All phases of the experiment were presented in PsyScopeX (Cohen, MacWhinney, Flatt, & Provost, 1993). Participants were given written and verbal instructions. They were told that they would be listening to a language they had never heard before, and that they would later be asked about the language, but they need not try to memorize any forms they heard. Participants were presented with a bare stem followed by its heightharmonic suffixed form (e.g., [bimug, bimugi]). There were 24 items for each participant, each repeated 5 times in a random order.
Training was followed by a two-alternative forced-choice test phase in which participants heard two (tri-syllabic) suffixed items, one harmonic and one disharmonic (e.g., [bimugi vs. *bimuge]), presented in a random order. Participants were instructed to press the ‘a’ key if the first item belonged to the language, and to press the ‘l’ key if the second item belonged to the language. Participants were told to respond as quickly and accurately as possible, and to make their responses after hearing both items.
Following the test phase, participants were given an AXB perception task for English vowels. The test was designed so that anyone with normal hearing, knowledge of English vowels, and the ability to follow directions (all required for the task) would perform well. Participants were asked to distinguish between various CV syllables. Consonants were drawn from the set /p, t, k, b, d, g/ and vowels were drawn from the set /a, i, e, o u, æ/. For each set of three syllables, two vowels were the same; the second vowel was the same as either the first or the third syllable. Consonants varied randomly. Participants were told that they would hear three syllables, and their job was to select which syllable had the same vowel as the second syllable; if the first vowel was the same as the second, they were to press the ‘a’ key; if the second vowel was the same as the third vowel, they were to press the ‘l’ key. For example, if participants heard [pa bu ku], the correct response would be ‘l.’ The entire experiment took approximately 15 minutes.
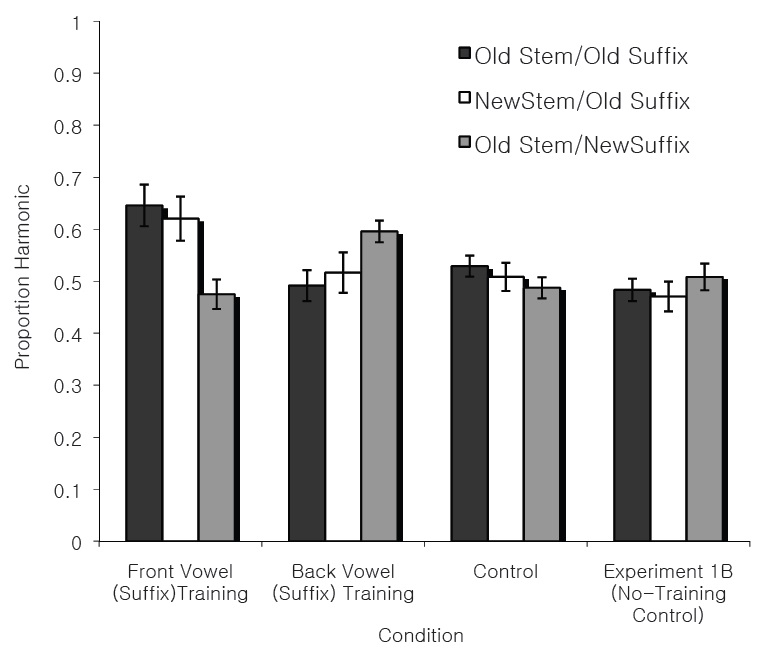
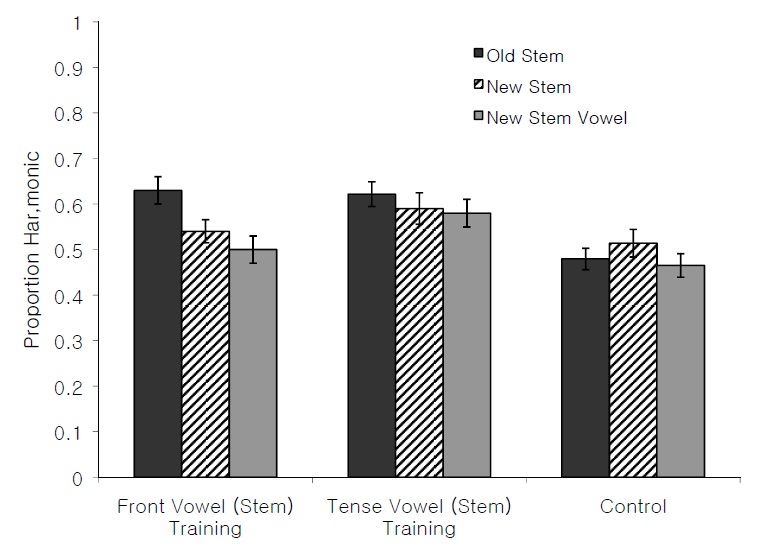
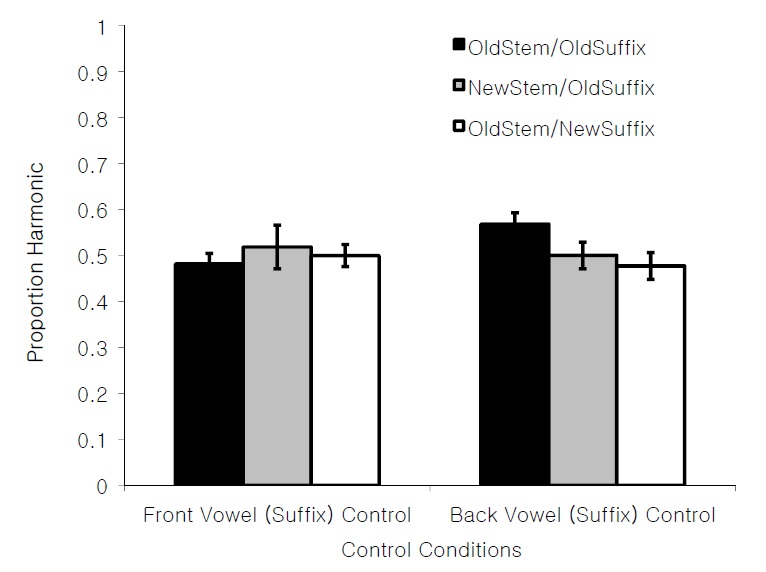
Proportions of vowel height harmonic responses were recorded for each participant. The means and standard errors for each test condition are presented in Figure 1. We performed several statistical tests in order to determine whether participants in the critical conditions (i) learned the harmony pattern (at a rate greater than that of the Control condition), (ii) responded at above-chance rates to items with a novel suffix vowel (Old Stem/New Suffix) items, and (iii) showed differential learning for each of the two critical conditions.
>
Comparison of Critical Conditions to Control Condition
To assess overall effects of training, participants in the Control condition were compared to participants in each of the training conditions via separate mixed design ANOVAs.6 The between-subjects factor was Training, with two levels in each ANOVA: the Control condition and each training condition. Test Items (Old Stem/Old Suffix, New Stem/Old Suffix, Old Stem/New Suffix) was a within-subjects factor nested within Training. All conditions involved between-item comparisons. Overall means and 95% confidence intervals (
There was no significant effect of Training when the Back Vowel (Suffix) Training and Control conditions were compared, 0.51 vs. 0.53,
There was a significant effect of Training when the Front Vowel (Suffix) Training and Control conditions were compared; participants in the Front Vowel (Suffix) Training condition were more likely to select the harmonic response than the Control condition (0.58 vs. 0.51,
>
Comparison of Old Stem/New Suffix Items Between Critical and Control Conditions
To test for how participants respond to novel suffix vowels in the Old Stem/ New Suffix items, we compared responses in the Old Stem/New Suffix items to the corresponding Control condition for both the Front Vowel (Suffix) and the Back Vowel (Suffix) Training conditions, via
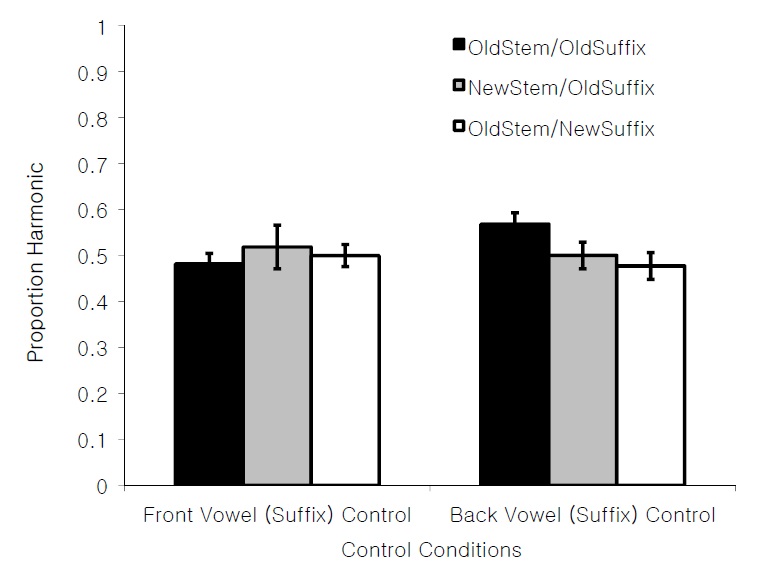
To ensure that the bias for front vowels found in the results was not simply due to a bias for or against forms with back vowel or front vowel suffixes, we separated responses in the Control condition according to whether the participants were tested with items from the Front Vowel (Suffix) Training condition or with items from the Back Vowel (Suffix) Training condition, as shown in Figure 2. For these two subgroups, there was no effect of Training,
>
Comparison of Critical Conditions
In addition, we compared each critical condition to each other via a third ANOVA. There was no effect of Training,
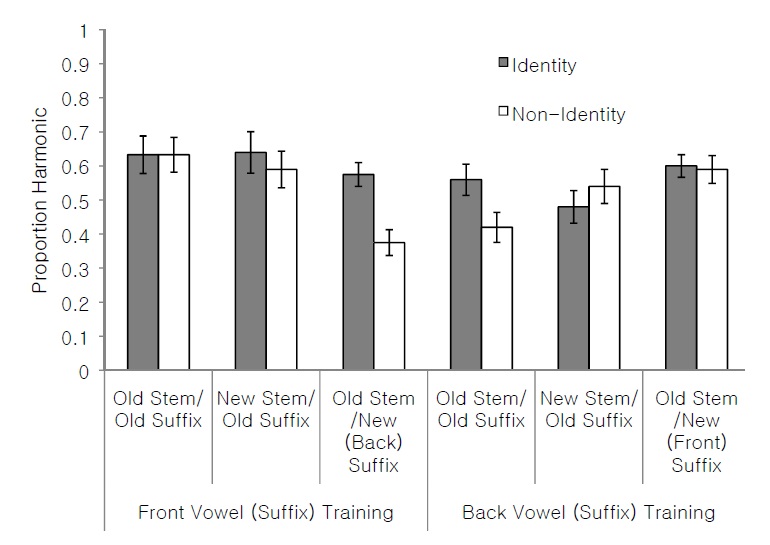
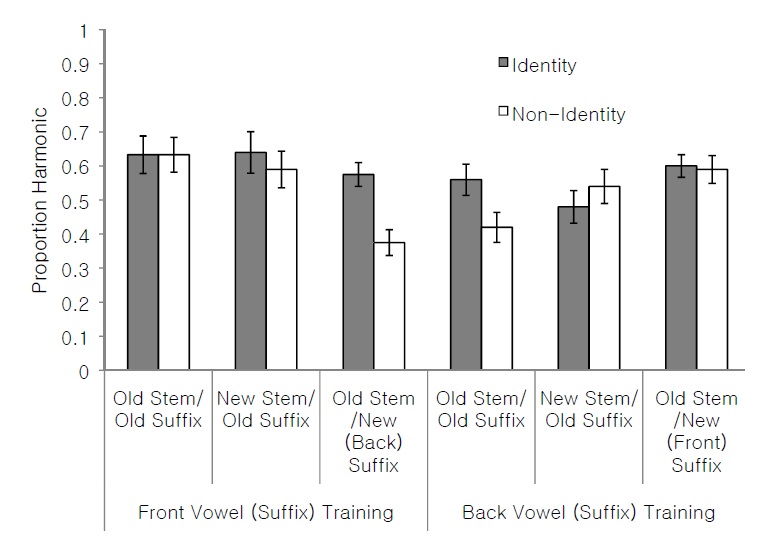
As mentioned in the introduction, one of the sources of the asymmetry between front and back vowels in height harmony is that in many Bantu languages, back vowels only undergo harmony when the trigger is also the back vowel /o/, resulting in harmony applying for back vowels when the result is two identical vowels. If learners are sensitive to this asymmetry, we expect participants to be more likely to respond to the harmonic item when the final stem vowel and the harmonic suffix vowel are identical. We compared harmonic responses for identical (final stem vowel and suffix vowel are identical) and non-identical test items for all test conditions in both the Front Vowel (Suffix) Training condition and the Back Vowel (Suffix) Training condition via paired samples t-tests. Means and standard errors can be found in Figure 3.
There were no significant differences for identical and non-identical test items for any test condition involving front vowels. These included Old Stem/New Suffix conditions in the Back Vowel (Suffix) Training condition (0.59 vs. 0.60,
It is important to note that the results discussed above hold for the majority of participants, rather than a few outliers. Harmonic responses for Old Stem/New Suffix items with a novel front vowel in the Back Vowel (Suffix) Training condition were relatively robust across participants. Of the 20 participants, 13 performed above 50% (two at 0.75, six at 0.667 and five at 0.58), and six performed exactly at 50%. Only one performed below 50% (0.417). Only one participant was below the mean of the Control condition (0.48). Failure to select the harmonic response for Old Stem/Old Suffix and New Stem/Old Suffix conditions in the Back Vowel (Suffix) Training condition was relatively stable across participants. Of the 20 participants, 15 were at or below 50% for Old Stem/Old Suffix and 13 individuals were at or below 50% for New Stem/Old Suffix items. The stability of the overall pattern of results across participants suggests that the results cannot be attributed to a small number of outliers, or to an averaging effect.
Results of the AXB perception task were at ceiling. Those who scored above the 75% threshold scored an average of 94% on the task.
The results of Experiment 1 suggest that learners of a novel height harmony pattern are biased towards front vowels undergoing harmony. Analysis of vowel identity suggest that participants may have learned a pattern in which back vowels only undergo harmony when the trigger is also back, creating two identical vowels. This is analogous to the front-back asymmetry found in many Bantu languages.
While perception of can play an important role in vowel harmony, participants’ performance on the AXB perception task verified that the direct perception of contrasts does not appear to be a significant factor for learning height harmony in this experiment. This is further supported by the fact that English speakers have little to no trouble perceiving the contrasts [i, e] and [u, o] (Hillenbrand, Getty, Clark, & Wheeler, 1995; Hillenbrand & Nearey, 1999). Hillenbrand et al.’s confusability studies showed little difference in the rates at which listeners mistakenly identified [i] and [e] for one another, compared to [u] and [o]. Hillenbrand and Nearey (1999) showed that the vowels [i] and [u] are more likely to be confused with their lax counterparts [ɪ] and [ʊ] than with their non-high counterparts [e] and [o]. Further, Singh and Wood’s (1970) study on vowel similarity showed small differences between [i, e] contrasts and [u, o] contrasts, suggesting that the perception of contrasts should not play a role in English speakers learning height harmony.
Participants in the Back Vowel (Suffix) Training condition showed abovechance harmonic performance on novel front-vowel items, despite their lack of exposure to front vowel suffixes in training. While participants were not exposed to the front vowel alternation in the suffix, participants were exposed to harmonic stems, many of which contained all front vowels. The harmonic front vowels in the stems may have helped learners infer a harmony rule that could be applied to the novel suffix vowels.
The results of Experiment 1 support the hypothesis that learners are biased to learn a vowel harmony pattern in which front vowels undergo height harmony, but back vowels do not (or only undergo when the trigger is also back). The experimentally induced bias towards front vowels undergoing height harmony appears as a result of exposure to a height harmony pattern, regardless of which vowels exemplified that pattern. Participants in the Control condition showed no bias towards height-harmony among front vowels. While there was a significant difference between sub-group controls in Old Stem/New Suffix item responses,
One possibility worth considering is that exposure to Control stimuli(even though it did not show any harmony pattern) altered how participants responded to the test items, thus not accurately reflecting pre-existing biases towards front or back height harmony. This possibility is explored in Experiment 1B.
5The choice of [g] as the final consonant was arbitrary. However, we note (from the information of an anonymous reviewer) that [g] may have a rising effect on F2. As long as the effects are equal for front vowels compared to back vowels, it seems that this should not have an influence on the outcome of the experiments 6Note that the use of ANOVA in these experiments followed previous studies (e.g., Finley and Badecker, 2009). A mixed effects model was performed on the data with the same results. We chose to report the results of the ANOVA for clarity and consistency with previous studies.
It is possible that the results of Experiment 1 are due not to learning biases, but to biases that existed prior to learning. To test the effectiveness of the Control condition in Experiment 1, we ran a separate ‘no-training’ control condition. In this ‘no-training’ condition, participants were given the same test items without any exposure to the harmony language. If these participants show no bias for front vowels undergoing harmony, it suggests that the results of Experiment 1 are due to learning, and not prior biases based on experience with the English language.
All participants were adult native English speakers with no knowledge of a vowel harmony language. Twenty University of Rochester undergraduate students participated for $5 and did not participate in any previous vowel harmony learning experiments.
The present experiment compared the results of Experiment 1 with an alternative control condition in which participants received no training.
Test materials were identical to the test items used in Experiment 1.
The test instructions were modified from Experiment 1 to accommodate the fact that participants only performed the test portion of the experiment and did not receive any exposure to the harmony language. Participants were told to make judgments about words from a language they had never heard before. They would hear two words, and they were to decide which word they ‘preferred’ based on whatever criteria they decided. We believe that this preference task was the best way to match any responses in the critical conditions that were made without reference to the training set (e.g., using a bias or preference that was not found in their training stimuli). There could be several reasons for this (sounding exotic, following some harmony pattern, more like English, etc.). If there is no overall strategy across participants, it suggests that there is no specific preference/bias for or against harmony. When the critical condition is significantly different from the Control condition, it suggests that the participants in the critical condition are using a different criterion than participants in the control.
We performed all statistical analyses comparing the critical to the Control condition, as well as a comparison between the Control condition for Experiment 1 with the No-Training Control that comprised Experiment 1B.
>
Comparison of No Training Control (Experiment 1B) to Stem-Only Control (Experiment 1)
We compared the Control condition used in Experiment 1 to the ‘no-training’ Control used in Experiment 1B. There was no effect of Training (0.49 vs. 0.51,
>
Comparison of Critical Conditions to Control Condition
There was a reliable effect of Training in the comparison between the Front Vowel (Suffix) Training and the No Training Control conditions: participants in the Front Vowel (Suffix) Training condition were more likely to choose the harmonic candidate than participants in the No Training Control condition (0.58 vs. 0.49,
There was no significant effect of Training in the comparisons between the Back Vowel (Suffix) Training and Control condition: participants in the Back Vowel (Suffix) Training condition were no more likely to choose the harmonic response option than participants in the Control condition (0.49 vs. 0.53,
>
Comparison of Old Stem/New Suffix Items Between Critical and Control Conditions
To test for how participants respond to innovations in harmony undergoers, we compared responses to the Old Stem/New Suffix items to the No Training Control condition for both the Front Vowel and the Back Vowel (Suffix) Training conditions, via t-tests. As in Experiment 1, there was no significant difference between Old Stem/New Suffix test items for the Front Vowel (Suffix) Training condition,
Overall, the use of a No-Training Control condition in Experiment 1B did not change the results of the experiment. Comparisons to participants in the critical conditions of Experiment 1 revealed the same general pattern of results, and there were no differences between the responses between the No Training Control condition of Experiment 1B and the Control condition of Experiment 1.
The results of Experiments 1 and 1B provide evidence that learners are biased towards front vowels as undergoers for height harmony. It is possible that in addition to a bias towards learning height harmony in which front vowels undergo harmony, learners are biased towards languages in which the trigger and the target share the same back feature. As discussed above, there are two general restrictions on height harmony languages. One is that front vowels undergo harmony (as tested in Experiment 1); the other is that vowels must share the same feature value of backness (this is especially true for back vowels).
There is some evidence that learners in Experiment 1 inferred a language in which back vowels undergo harmony only when the trigger for harmony is also back, and therefore identical. There were significant differences for two of the three conditions with back vowel suffixes (the Old Stem/ New Suffix items of the Front Vowel (Suffix) Training condition, and the Old Stem/Old Suffix items of the Back Vowel (Suffix) Training condition). However, because there was no significant difference for the New Stem/Old Suffix items in the Back Vowel (Suffix) Training condition, the evidence for shared backness driving the asymmetry between front and back vowels in height harmony is not conclusive. One possible reason that we did not find an effect of identity for all conditions is that there were only six front vowel items and six back vowel items in each test condition, making it difficult to assess differences in response rates. In addition, shared backness and vowel identity were confounded in Experiment 1. With only four vowels in the language inventory, the only way for vowels to share both height and back features was to be identical (e.g., [o] with [o]). Thus, it is not clear if the bias for shared backness was mediated by vowel identity.
Experiment 2 directly tests for the effect of shared backness in learning height harmony patterns. If learners are biased towards height harmony patterns with shared backness, they should generalize to novel (non-identical) front vowel triggers when the suffix is a front vowel. Experiment 2 contrasts generalization to novel stem vowels in height harmony, comparing generalization to novel front lax vowels to generalization to novel back vowels.
Participants in Experiment 2 were divided into two distinct training groups. One condition was exposed to stems and affixed forms with only front vowels [i, e, ɪ, ε] (Front Vowel (Stem) Training condition), and another condition was exposed to stems with both front and back vowels [i, e, u, o], all tense (Tense Vowel (Stem) Training condition). Participants who were exposed only to front vowel forms in training were subsequently probed with stems containing novel back vowels in the test phase of the experiment; participants exposed to tense vowel stems during training were probed with stems containing novel front lax vowels. 7
If learners are biased towards a height harmony pattern in which the trigger and target share the same value for the back feature, they should generalize to front lax vowels that match the front stem vowel in backness (the Tense Vowel (Stem) Training condition), but fail to generalize to back vowels, which do not match the back features of the suffix vowel alternation (the Front Vowel (Stem) Training condition). Note that there is a possibility that participants are biased against lax vowels. If this is the case, learners may fail to generalize the harmony pattern to front vowels, cancelling out any bias towards front vowels.
While the cross-linguistic tendency for front triggers and targets of height harmony to share back feature values leads us to the hypothesis that learners will be more likely to generalize to front vowels than back vowels, there are additional reasons to expect this result. First, a language in which only front vowels trigger and undergo harmony creates a uniform phonological rule: all front vowels undergo harmony, which can lead learners to infer a rule involving only front vowels. Second, a pattern in which the more restricted back vowels trigger harmony may bias learners to form a general harmony rule in which all vowels undergo harmony. In contrast, a rule in which only unrestricted front vowels participate should lead learners to a narrower inference of the training data.
All participants were adult native English speakers with no knowledge of a vowel harmony language, and who had not participated in Experiment 1. Seventy-eight Johns Hopkins undergraduates participated for extra course credit. Participants were randomly assigned to one of three conditions: a Control condition exposed to mixed harmony stems, a Tense Vowel (Stem) Training condition and Front Vowel (Stem) Training condition. All participants were screened based on the same perceptual (AXB) task from Experiment 1. Data from participants scoring less than 75 percent on this task were discarded. Five participants fell below the cut-off on the perceptual task, and one subject was dropped due to a program error, leaving 24 participants in each condition.
[Table 2.] Experiment 2 Design
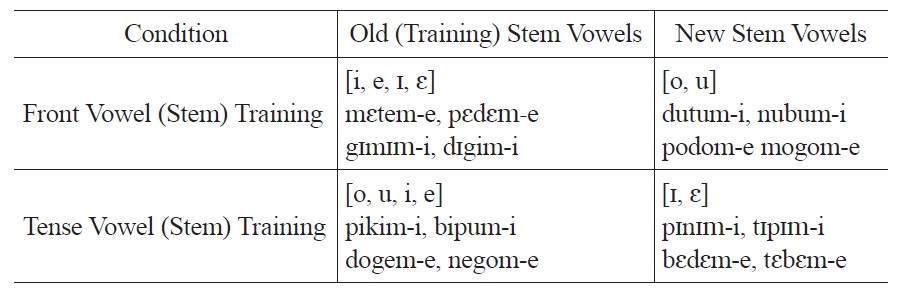
Experiment 2 Design
Experiment 2 tested for generalization to back and front lax stem vowels in order to assess the basis for vowel height harmony alternations that are dependent on shared backness values, as mentioned in Experiment 1. Participants in the Tense Vowel (Stem) Training condition were exposed to stems containing only tense vowels [i, u, e, o], and tested for generalization to front lax vowels not heard in training. Conversely, participants in the Front Vowel (Stem) Training condition were exposed to stems containing only front vowels [i, e, ɪ, ɛ],8 and tested on their generalization to back vowels not heard in training. All suffixes were tense front vowels ([i]/[e]). Examples of training and test stimuli can be found in Table 2.
As in Experiment 1, the present experiment included a simple AXB perception task for the vowel contrasts that played a critical role in the experimental manipulations (which here included lax vowel alternations).
The stimuli were similar to those in Experiment 1 with the exception that the stimuli included lax vowels, the stem form shape was CVCVm,9 and the suffix alternation was [–i]/[–e] for all critical training and test conditions. (Appendix B contains full stimulus lists for Experiment 2.)
The procedure was identical to Experiment 1.
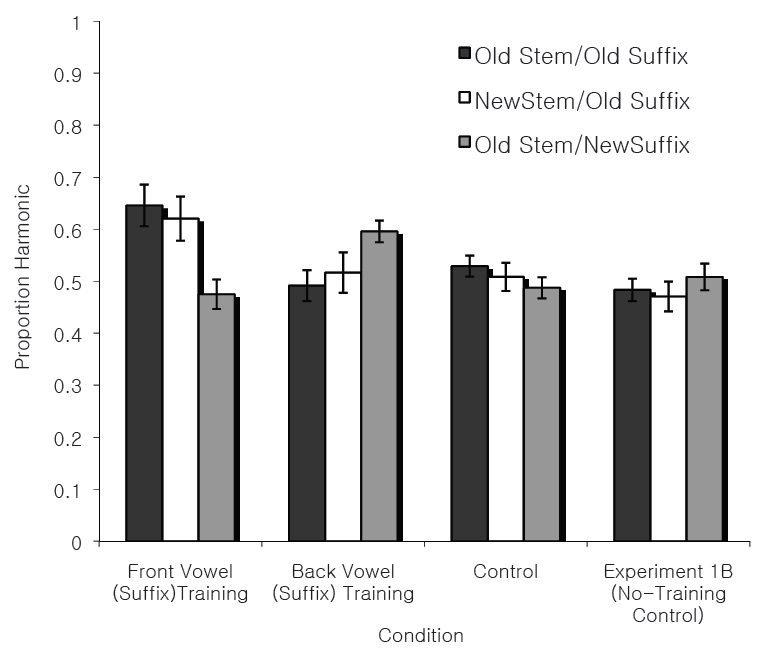
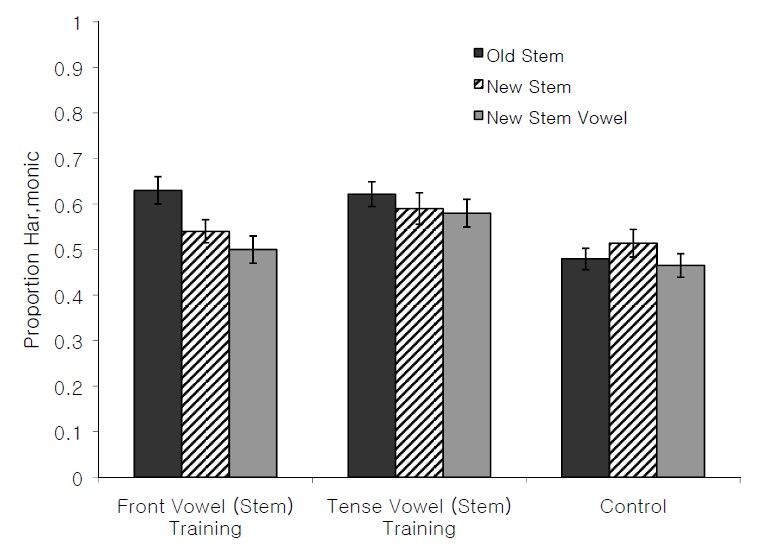
The present experiment tests the hypothesis that learners are biased towards height harmony languages in which the trigger and target share the same front/back feature values. Given that all suffixes contained front vowels, the bias should emerge with the Novel Stem Vowel items, with extension of the harmony pattern to novel front vowel stems (in the Tense Vowel (Stem) Training condition) but no extension of the harmony pattern to novel back vowel stems (in the Front Vowel (Stem) Training condition). Proportions of height harmonic responses were recorded for each participant in each of the training conditions. Mean and standard errors for each test condition are presented in Figure 4.
Like in Experiment 1, we performed several statistical tests to compare learning and generalization of the height harmony pattern. We compared the critical training condition to the Control condition, the New Vowel items for each critical condition, as well as the two critical conditions to each other.
>
Comparison of Critical and Control Conditions
Overall effects of training were identified by comparing participants in the Control condition to participants in each of the training conditions via separate mixed design two-factor ANOVAs. When we compared the Front Vowel (Stem) Training condition to the Control condition, we found a significant effect of Training, 0.56 vs. 0.49,
When we compared the Tense Vowel (Stem) Training condition to the Control condition, we found a significant effect of Training, 0.58 vs. 0.49,
>
Comparison of New Vowel Items Between Critical and Control Conditions
To assess generalization to novel back vowel stems in the Front Vowel (Stem) Training condition, a t-test was performed comparing the New Vowel items of the Control condition to the New Vowel items for the Front Vowel (Stem) Training condition; there was no difference,
To assess generalization to novel front lax vowel stems, a t-test was performed comparing the New Stem Vowel items of the Control condition to the New Stem Vowel items for the Tense Vowel (Stem) Training condition; there was a significant difference,
>
Comparison of Critical Conditions
When we compared the Tense Vowel (Stem) Training to the Front Vowel (Stem) Training condition, there was no effect of Training,
As in Experiment 1, results of the AXB perception task were at ceiling. Those who scored above the 75% threshold scored an average of 92% on the task.
Participants in Experiment 2 learned a height harmony language in which either stems containing tense vowels only or stems containing front vowels only triggered height harmony with front tense suffix vowels ([–i]/[–e]). Learners displayed generalization to novel front lax vowels but not to novel back vowels. Learning occurred for both Front and Tense Vowel (Stem) Training.
One possible interpretation of the failure to generalize to back vowels in Experiment 2 is that learners only apply the novel pattern to contrasts within the training set, rather than using a general natural class. For example, in the Front Vowel (Stem) Training condition, learners were exposed only to front vowels, and thus may have posited a height harmony rule that applies to front vowels only. However, in the Tense Vowel (Stem) Training condition, learners were only exposed to tense vowels, and thus may have posited a rule in which only tense vowels participate in height harmony, but were able to apply the rule to both tense and lax vowels. This would suggest that participants in the Tense Vowel (Stem) Training condition may have extended the harmony pattern to back vowel stems as well.
In Experiment 1, learners were able to generalize height-harmony to front vowels despite only having been exposed to back vowels undergoing height harmony. Finally, Finley and Badecker (2009a) demonstrated that learners are able to generalize a vowel harmony pattern to vowels outside of the training space. In their experiment, learners generalized a front-back harmony system to novel high vowels despite only having exposure to mid and low vowel stimuli in training. This suggests that learners are able to form general vowel harmony rules using features of vowels not heard in training.
7Because the majority of height harmony languages have vowel systems that do not contain height contrasts over lax vowels, the typology for height harmony that does not interact with ATR harmony is relatively unknown. In the case of the present experiment, we hold tense-lax distinctions constant, only varying height. For example, high tense /i/ contrasts with mid tense /e/; lax high /ɪ/ contrasts with lax mid /ɛ/. While lax vowels are not generally found in height harmony languages, there is no reason a priori to exclude lax vowels from harmony languages, so long as the vowel inventory is large enough to handle the necessary contrasts. Given that the majority of height harmony languages have only 5 or 7 vowel phonemes (and do not have a wide range of tense lax contrasts), height harmony typically does not separate out tense and lax vowels. 8While including lax back vowels would have provided a nice symmetry for the experiment, this was not possible given that many speakers of American English (including the first author and the talker who produced the stimuli) do not show a clear distinction between low and mid back lax vowels (i.e., the caught/cot merger). 9The choice of particular consonant (i.e., the switch from /-g/ to /-m/ in Experiment 2) was arbitrary. While /m/ may increase coarticulation for rounding, this should increase learner’s awareness of back vowels, and any effect of this coarticulation will not favor our hypothesis.
The present experiments explore the nature of learning biases with respect to the cross-linguistic distribution of phonological patterns. In languages with vowel height harmony, front vowels are more likely to participate in height harmony than back round vowels. The results of Experiment 1 (and 1B) demonstrate that English-speaking learners of artificial height harmony languages exhibit a bias towards front vowels undergoing height harmony and a corresponding bias against back vowels undergoing height harmony.
Experiment 2 tested learners’ sensitivity to whether the trigger and target of height harmony share backness feature values. Many height harmony languages restrict harmony such that back vowels only undergo harmony when vowels share the same backness feature value. When learners were exposed to only front vowels, they failed to generalize to back vowels, but when learners were exposed to a mix of front and back vowels, participants selected the harmonic response to stems containing novel front lax vowels. This suggests that learners are biased towards front vowels participating in height harmony, and that they are sensitive to whether the trigger and target share the same value for the feature [Back]. This also predicts that participants would generalize to back vowel stems if given a mixture of front and back vowels in training. Thus, there is a possibility that learners may overcome a bias for features to share the same value of backness if given a rich inventory during training. However, it is up to future research to tease this possibility apart.
Together, the results of Experiments 1 and 2 suggest the possibility that learning biases may play a role in shaping the cross-linguistic distributions of phonological patterns. The learners in our study had no prior knowledge of a vowel harmony language, but still showed biases in the same direction as the cross-linguistic typology. The use of experiments like the ones presented in this paper provide a major step forward into uncovering the relationship between learning and cross-linguistic typology. For phonological patterns, phonetic grounding plays a key role. By understanding when learning biases occur in an experimentally controlled setting, we can begin to understand how language learners have shaped cross-linguistic typology. From this, it is possible to form a more complete theory of language, one that includes how languages might be learned, as well as the role of phonetics in phonological patterns. While the present study cannot answer these questions, the experiments presented here provide foundation for future research that will begin to fully understand language as a cognitive process.
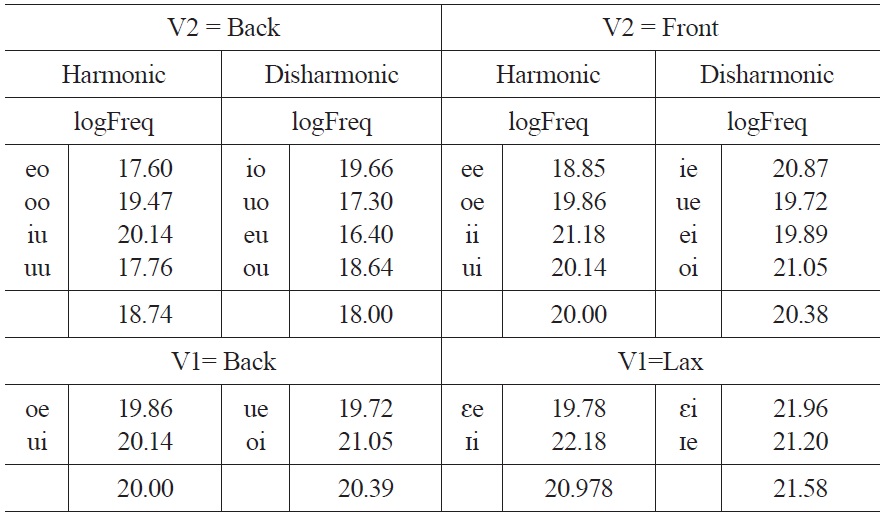
One concern is the extent to which learners used their knowledge of English to guide their learning behavior. There are two reasons to believe that this is not the case. First, participants in the Control condition were at chance, suggesting that the performance in the present study was a result of learning, as opposed to latent statistical tendencies in the lexicon. Second, there is no evidence for a residual bias towards height harmony in the English lexicon. To verify this, we compared the log frequency10 for bigrams ending in a front vowel versus bigrams ending in a back vowel (we separated words by the second vowel because the crucial manipulation in Experiment 1 varied the vowel in terms of front/back). The frequencies of the bigrams used in training and (disharmonic) test items for Experiment 1 can be found in Table 3. While there were relatively more sequences ending in front vowels, disharmonic sequences involving front vowels were slightly more frequent than harmonic sequences. Harmonic sequences for back vowels were slightly more harmonic than bigrams with a back vowel in second position. If this relative frequency were driving learning, we should expect that learners would find height harmony with back undergoers easier to learn, but we found the more harmonic bigrams involving front vowels than disharmonic bigrams, the opposite of what one would expect if there were a latent statistical preference for height harmony.
[Table 3.] Harmonic vs. Disharmonic Frequencies in English: Experiment 1
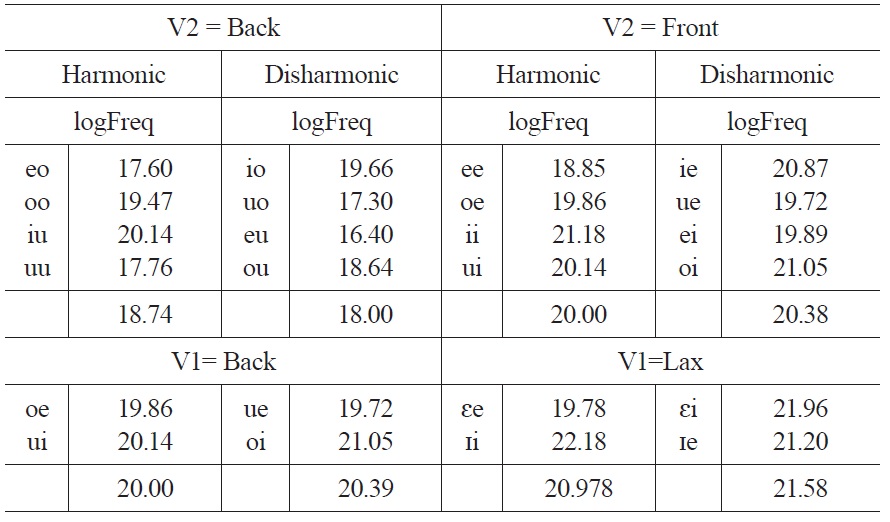
Harmonic vs. Disharmonic Frequencies in English: Experiment 1
The relevant frequency of bigrams in Experiment 2 is less clear because the suffix vowel was always front, and both conditions had front vowels in stems; the difference was whether stems contained back vowels or lax vowels. Thus, we compared the frequency of bigrams where the first vowel was back or the first vowel was lax. In both cases, disharmonic sequences were slightly more frequent than harmonic sequences.
While there are many ways to measure and compare the role of frequency in affecting learning (e.g., bigrams vs. trigrams; vowels from the experimental stimuli vs. all English vowels; spoken corpora vs. written corpora), there is no reason to believe that another method for counting frequency would yield a different result. Thus, we assume that the present measurements are representative of the frequency of harmonic items found in the English language. The results of the present experiment, with the corresponding frequency analyses, demonstrate that English vowel bigram frequency does not play a role in learning vowel height harmony. If anything, learners have a bias towards disharmony that they must overcome in the learning process.
One possible explanation for the failure to generalize to back vowels in Experiment 1 is that front vowels have a perceptually stronger contrast for the feature [High] than back vowels. If learners infer a height harmony process that only applies to contrasts that are as strong as or stronger than the contrasts that they are exposed to during training (front vowels in this case), then they will fail to generalize to back vowels, which are perceptually weaker than front vowels. However, in Experiment 2, the height contrasts for front lax vowels are weaker than the height contrasts for back vowels. If learners rely only on the strength of the contrast to infer a height harmony pattern, learners should have been able to extend the height harmony pattern to back vowels when weak contrasts (of lax vowels) were introduced. However, this did not occur; participants failed to generalize to back vowels even when weaker contrasts among front lax vowels were provided in the learning phase of the experiment.
Many languages with height harmony (e.g., Shona) have vowel inventories and vowel qualities that are very different from English vowels, which were used in the present experiment. First, English tense vowels (/i, e, u, o/) tend be pronounced as diphthongs, which differ from the vowels found in many Bantu languages. Second, many height harmony languages of the Bantu family have relatively small vowel inventories, and do not have as many tense-lax distinctions as those found in English (Maddieson, 2003). The fact that the results of the present experiment mirror the patterns found languages with highly dissimilar vowel inventories suggests that the biases found in the present paper transcend the properties of the vowels involved in natural languages that undergo harmony, but are more about the abstract properties of the vowel categories involved. Given that the present experiments test for biases independent of language family, it is important to establish that the results hold for vowels outside of the Bantu language family.
The overall effects of training in Experiments 1 and 2 are less robust compared to he effects of training found in previous vowel harmony learning experiments, where mean proportion harmonic responses were around 70-80% compared to about 60% in the present experiments (Finley & Badecker, 2008, 2009a, 2009b, in press; Pycha, et al., 2003). The major difference between the current study and previous studies is that the present study tested height harmony, while most previous studies tested back and round harmony. Height harmony is perceptually disfavored and typologically more restrictive than back and round harmony (Linebaugh, 2007). According to Linebaugh (2007) there is greater vowel-to-vowel (V-V) coarticulation for the feature [Back] than for the feature [High]. Hence, the back feature may be more prone over time to participate in a phonological vowel harmony pattern as a result of increasing V-V co-articulation. In addition, the primary phonetic correlates to height harmony (F1) are weaker than the correlates to back harmony (F2) (Linebaugh, 2007). These asymmetries parallel an asymmetry in the typology of harmony systems found cross-linguistically. Back harmony systems are both prevalent and relatively invariant, whereas height harmony systems are comparatively rare and highly variable. Based on these articulatory and perceptual-phonetic differences between height and backness contrasts, we expect that height harmony patterns should be relatively more difficult to learn than back harmony patterns. This falls in line with the fact that previous studies showed numerically greater proportions of correct responses compared to the current study, despite similar stimuli and measures.
In the present experiments, the AXB perception results were all at ceiling. This is mainly because the task was designed to be very easy for native English speakers, so that we could have a measure of attentiveness and ability to follow directions. The perception test was not used to measure subtle differences in perception across speakers. However, future research may make use of a more complex AXB perception task to study the role of perception in learning.
Gerken and Bollt (2008) demonstrate that infants may develop phonological learning biases following exposure to their native language. This suggests that learning biases may be a result of bootstrapping existing knowledge of language to novel language learning situations. If phonetic biases emerge as a result of learning, it makes sense to test adults, who have developed a complete set of biases. It also suggests that adults, who have enough input to fully form phonetically based biases, are an ideal group to study. In addition, language learning does not typically stop with the first language. Second language learning occurs at a variety of ages. It is therefore doubtful that the learning biases of the child are the only learning biases that play a role in shaping the typology of languages in the world.
Both children and adults serve as moderators for language change, in the form of social pressures and language contact (Mufwene, 2005), supporting the notion of studying learning biases for both children as well as adults. Bilingualism and second language learning can also influence language change (Luraghi, 2010). This influence may be direct, such as the effect of Scandinavian immigrants on the English spoken in Minnesota (Simley, 1930). The influence may also be indirect, emerging through the biases that learners bring to the learning task. Such biases may influence the type of patterns that are most easily learned, which may become part of the sociolinguistic environment, and subsequent input for child learners. An important area for future research is to uncover how learning biases develop and change throughout life.
The work presented in this paper supports the hypothesis that the distribution of sound patterns across the world’s languages arises with contributions from learning biases. Learners show biases to learn the patterns that are phonetically grounded and typologically frequent. Artificial grammar learning experiments represent a promising methodology to uncover precisely the nature of those biases.
10Thank you to Judith Degen for calculation of the log frequencies for various bigrams in English.