Cloud computing services have became an hot issues in business fields while the IT-related global company such as Amazon, MS, and Google took part in. The cloud computing makes it possible to share in the form of outsourcing of hardware and software through the Internet, to build a distributed computing environment via multiple terminals, and to reduce the cost using open source. Such a cloud computing services have not shown any significant growth in Korea yet compared to other countries.
Therefore, in this study focusing on public cloud computing services, it is intended to analyze the determinants of public cloud computing services using the technology model. Thus, for users using public cloud services, we conducted a questionnaire survey from the beginning of January 2013 to the end of February 2013.
And we derived a research model based on the Technology Acceptance Model(TAM). As a result of this study, it shows that personal aspects significantly impacts on the perceived usability, service aspects, systems aspects, and the intent of the technology acceptances. System aspects significantly effect on the intent of technology acceptances. Perceived usability significantly effects on the service aspects and the systems aspects. The main factors effecting on the intent of the technology acceptances are system aspects and perceived usability in order. And it shows that the personal aspects decreases the intent of the technology acceptances.
클라우드 컴퓨팅은 아마존, MS, 구글, IBM 등 IT 관련 글로벌 기업들이 참여하면서 이슈화되기 시작하였다. 클라우드 컴퓨팅은 인터넷을 통해 하드웨어와 소프트웨어를 아웃소싱 형태로 공유, 여러 대의 단말을 통해 분산형 컴퓨팅 환경을 구축하는 개념으로, 오픈소스를 통해 비용 절감 효과도 발생한다.
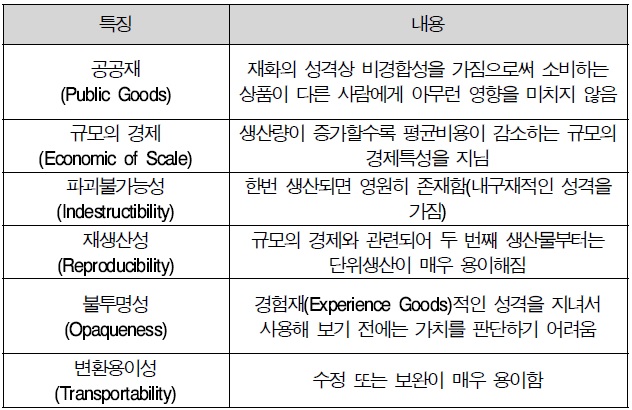
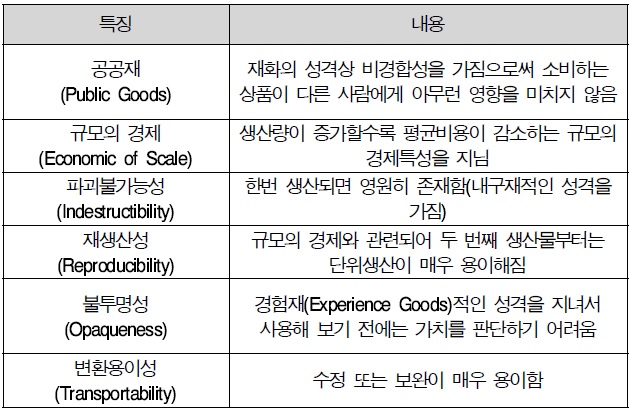
우리가 보편적으로 많이 사용하는 웹 메일, 웹 하드, 웹 호스팅, 블로그, 오라인 사진/비디오 데이터 저장서비스, MS나 구글에서 제공하는 웹기반 워드프로세싱 등이 모두 초기 형태의 클라우드 컴퓨팅 서비스들이다. 이런 클라우드 컴퓨팅 서비스는 물리적인 상품(Physical Good)과 달리 생산, 유통, 소비가 모두 네트워크 또는 정보처리 기기에서 이루어지며, 이러한 상품을 우리는 디지털 상품(Digital Goods)이라 부른다(전수용, 2010).
본 연구에서는 디지털 상품에 대한 연구를 주제로 한고 있다. 이 디지털 상품은 물리적인 상품보다 네트워크에 적용시키기 쉬우며 생산과 유통, 그리고 소비까지 모두 인터넷상에서 이루어질 수 있다. 이런 디지털 상품은 무형의 정보와 지식의 창출과 활용이 가능한 형태로서 소프트웨어, 부가가치 정보, e-Book, MP3, 온라인 게임처럼 물리적인 형태를 취하고 있지 않으며 디지털화하여 생산, 유통, 소비될 수 있는 상품으로 볼 수 있다. 또한 한번 생산되면 영구히 그 형태와 품질을 유지할 수 있다(Shapiro, 1998).
이런 디지털 상품의 예가 바로 클라우드 컴퓨팅 서비스이다. 클라우드 컴퓨팅 서비스는 다른 디지털 상품들, 예를 들어 소프트웨어, MP3, E-book처럼 정보처리기기를 기반으로 하고 있으며 인터넷을 이용하고 있다. 또한 생산자는 원천기술이나 아이디어를 갖고 인터넷상에 서버를 구축하여 고객에게 접근할 수 있다. 유통은 네트워크를 통해 고객에게 다운로드 되며 이 과정에서 생산자 측에 요금이 전달된다. 또는 서버에 고객이 접속하여 생산자가 제공하는 서비스를 이용하는 과정에서 요금이 부과되는 유통방식도 있다.
이와 같이 현재는 인터넷이라는 매체를 배경으로 탄생하는 새로운 상품이 등장하고 있다. 때문에 아직까지 미진한 디지털 상품에 대한 연구가 활발하게 필요한 시점이며 이 같은 연구는 기업의 인터넷 비즈니스에 대한 시장 접근을 활성화 시키고 아울러 인터넷을 활용하는 기업들의 새로운 시장 개척을 위한 기초 자료로서 제공될 것이라 생각한다.
디지털 상품의 특징
본 연구의 목적은 클라우드 컴퓨팅 서비스를 사용하는 이용자들의 기술수용의도를 연구하는데 그 목적이 있다. 이러한 연구목적을 달성하기 위해 문헌연구와 실증적 연구를 병행하였다.
문헌연구에서는 클라우드 컴퓨팅 서비스의 특성과 서비스 유형을 분석하였고, 기존 기술수용모델을 고찰하였다.
이러한 문헌연구를 통해 파악된 이론적 연구결과들을 토대로 구성개념간의 관련성을 반영하여 연구모형 및 가설을 설정하였다. 문헌연구를 통해 도출된 연구모형을 실증적으로 검증하기 위해 클라우드 컴퓨팅 서비스 중 공공 클라우드 서비스를 사용하는 이용자들을 대상으로 설문지를 통해 자료를 수집하고, 수집된 자료를 이용하여 기술수용의도에 이용 특성이 미치는 효과를 알아보았다.
실증분석은 PC용 통계 프로그램인 SPSS 18.0을 이용하였고, 연구목적을 달성하기 위하여 활용한 분석기법은 인구통계학적 특성을 분석하기 위하여 빈도 분석을 실사하였으며, 본 연구에 사용된 측정도구의 타당성과 신뢰성을 검증하고자 각 변수들의 내적일관성과 척도의 일관성을 측정하는 신뢰도 검증을 실시하였다. 분석대상이 되는 변수들 간의 관계를 설정해 높은 상태에서 항목간의 타당성을 검증하는 탐색적 요인 분석을 실시하였다. 또한 본 연구의 가설을 검증하기 위해서 구조방정식 분석을 실사였다. 구조방정식 분석에서는 AMOS18.0을 사용하였다.
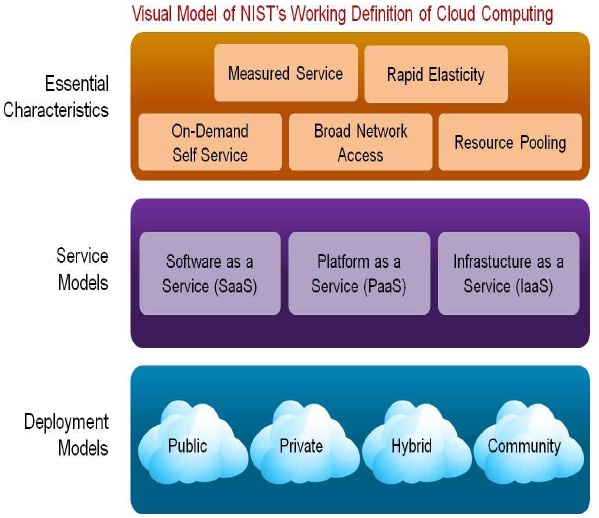
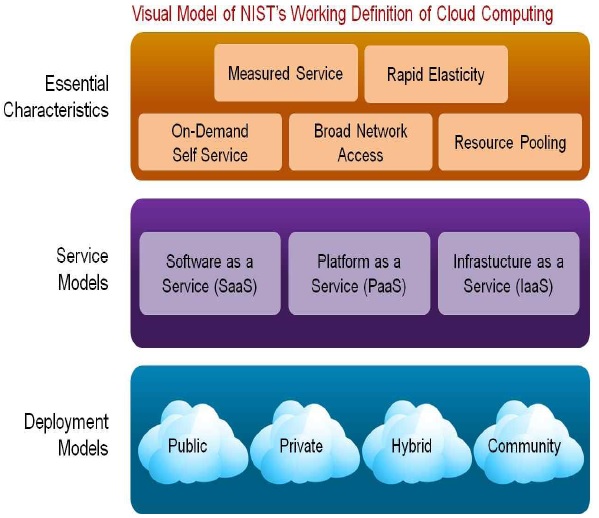
NIST(National Institute of Standard and Technology; 미국 표준 기술 연구소)는 클라우드 컴퓨팅을 ‘이용자는 IT 자원(소프트웨어, 스토리지, 서버, 네트워크)을 필요한 만큼 빌려서 사용하고, 서비스 부하에 따라서 실시간 확장성을 지원받으며, 사용한 만큼 비용을 지불하는 컴퓨팅’이라고 정의하고 있다. 이에 따르면 클라우드 컴퓨팅은 언제 어디서나 용이하게 구성이 가능한 정보자원, 즉 네트워크, 서버, 스토리지, 애플리케이션, 서비스들의 공유된 풀(shared pool)에 언제 어디서나, 편리하고, 이용자의 요구에 따라 사용할 수 있는 네트워크 접근을 통한 온디맨드(on-demand) 이용이 가능한 모델이며, 사용한 만큼 과금하는 형태(pay-per use model)이다. 또한 이 컴퓨팅 자원들이 최소한의 관리 노력 혹은 서비스 제공자와의 상호작용을 통해 원할 때 신속히 제공되고, 회수(rapidly provisioned and released)할 수 있는 모델이기도 하다. NIST는 이 정의를 고정되어 있는 개념이 아니라 계속적으로 진화하는 개념(evolving paradigm)이라고 강조하며, 새로운 버전을 통하여 그 정의를 업데이트시켜 나가고 있다. 즉, 현재 개인 비즈니스나 공공 분야에서 클라우드 컴퓨팅에 대해 지속적으로 기술 분석을 하고 있으며, 기회와 위험성에 대해 포괄적으로 검토해 가고 있는 내용일 뿐만 아니라, 기술적으로나 개념적으로도 지속적으로 진화되고 있는 개념으로 전제하고 있는 것이다. 더불어 특정 기술로 정의되기보다는 다양한 모델과 시스템, 마켓 등 전체 IT 생태계(IT ecosystem)의 개념으로 접근하고 있다는 것을 전제로 하고 있는 부분도 인상적이다. NIST는 클라우드 컴퓨팅을 5가지 특징, 3가지 서비스 모델, 4가지 배치 모델로 구분하여 설명한다.
NIST에서 이야기하는 다섯 가지 특성은 다음과 같다. 이 중 대다수의 특징이 이미 정의를 통해서 언급된 내용이다
(특성 1) 온디맨드 서비스(On-Demand Service);
(특성 2) 네트워크 접속(Broad network access);
(특성 3) 리소스 풀링(Resource pooling);
(특성 4) 정보자원 제공의 빠른 탄력성(Rapid Elasticity);
(특성 5) 측정되는 서비스(Measured Service);
각각의 특징에 대해 살펴보면, 먼저 ‘온디맨드 서비스’, 즉 요청 기반 서비스라는 것은 이용자가 클라우드 서비스를 필요한 만큼 이용할 수 있는 서비스를 말한다. 이는 서비스 제공자와의 상호작용 없이 서버 시간이나 네트워크 저장 등의 컴퓨팅 능력(capability)을 사용자가 자동화하여 사용하는 것이다. ‘네트워크 접속’은 클라우드 제공자의 기능과 성능을 클라이언트의 성능과 상관없이 표준 절차에 의해 접근 가능하며 네트워크상에서 이용할 수 있다는 것을 의미한다. ‘리소스 풀링’은 위치로부터 독립된 정보자원의 풀을 의미한다. 위치가 독립적이라는 것은 고객은 제공되는 자원의 정확한 위치에 대해 알 수도 없고, 제어할 수도 없으며, 할 필요도 없다는 것이다. 그러나 높은 레벨의 추상적인 위치는 지정할 수 있다. 이러한 컴퓨팅 모델은 클라우드 제공자로 하여금 그들의 소비자들을 공유(multi-tenant) 모델로 서비스할 수 있게 한다. 물리적이고 가상화된 정보자원들은 소비자의 요청에 따라 할당된다. 클라우드 컴퓨팅의 장점 중 하나는 이용자들이 필요에 따라 사용량을 증가시키거나, 감소시킬 수 있다는 것이다. 최대 요구치에 맞추어 정보자원을 준비해 놓았던 과거와 비교해서 필요한 만큼만을 필요한 시기에 언제든 획득하여 쓸 수 있다는 점에서 정보자원 제공․획득의 ‘빠른 탄력성’은 클라우드 컴퓨팅의 가장 큰 장점으로 설명되기도 한다. 그리고 빠르게 탄력적으로 정보자원이 거래가 이루어지더라도, ‘측정되는 서비스’라는 특징으로 인하여 서비스 제공자와 이용자 사이에 거래될 수 있는 정보자원 서비스로서 자리매김하고, 이를 거래하는 시장이 형성될 수 있음을 의미한다.
정리하면, 이용자의 요청에 따라 필요한 규모의 정보자원을 낮은 비용에 유연하고 탄력적으로 제공하는 것이 클라우드 컴퓨팅의 요체이다. 클라우드 컴퓨팅의 의미가 계속 변화하고 있다는 것에 착안하여, 클라우드 컴퓨팅은 최소한의 관리 노력이나 서비스 제공자와의 상호작용을 통해 신속하고 탄력적으로 제공되거나 방출될 수 있는 정보자원의 공유 풀(pool)에 이용자가 네트워크를 통해 접속하여 자신이 원하는 만큼 이용할 수 있는 편리한 주문형 IT 서비스 모델이라는 정의를 도출할 수 있다.
클라우드 컴퓨팅의 3가지 서비스 모델은 SaaS(Software as a Service), PaaS(Platformas a Service), IaaS(Infrastructure as a Service)이다. SaaS는 소프트웨어를 서비스로 제공하는 것으로 소비자에게 제공되는 컴퓨팅 능력은 인프라에서 가동되는 서비스 제공자의 애플리케이션을 사용하는 것이다. 애플리케이션은 웹 브라우저와 같은 신 클라이언트 인터페이스(thin client interface)이나, 프로그램 인터페이스와 같이 다양한 클라이언트 디바이스를 통해 접속이 가능하다. 소비자는 사용자와 특화된 환경 설정과 같은 경우를 제외하고는 클라우드 인프라(네트워크, 서버, OS, 스토리지, 애플리케이션 관련한 것까지도)를 관리하거나, 통제하지 못한다. PaaS는 플랫폼을 서비스로 제공받는 것으로 서비스 제공자에 의해 지원되는 프로그래밍 언어나 도구를 사용하여 만들어진 애플리케이션을 클라우드 인프라상에서 배포하는 것이며, 소비자는 클라우드 인프라를 관리하거나 통제하지 못하나 배포된 애플리케이션과 애플리케이션 호스팅 환경설정은 통제할 수 있다. 인프라스트럭처를 서비스로 제공하는 IaaS는 소비자가 OS나 애플리케이션을 배포하고 구동할 수 있는 주요 컴퓨팅 자원을 제공하는 것이며, 소비자는 클라우드 인프라를 관리하거나 통제하지 못하나, OS, 저장, 애플리케이션의 특정 네트워킹 컴포넌트를 통제할 수 있다.
IaaS란 클라우드를 통해 제공되는 IT 인프라스트럭처 서비스이다. IaaS 서비스를 고객에게 제공하기 위해서는 이 IaaS 서비스를 어딘가에 배치(deployment)해야 하는데, 그 배치 방식에 따라 4가지로 분류한 것이 바로 공공 클라우드(public cloud), 사설 클라우드(private cloud), 커뮤니티 클라우드 (community cloud), 하이브리드 클라우드(hybrid cloud)이다.
IaaS의 각 배치 모델별 장단점이 있지만, 클라우드 컴퓨팅의 가장 큰 장점인 단위 수요당 비용 절감, 긴급 수요에의 빠른 대응, 수요 없는 자원의 낭비 최소화, 초대용량 지원, 서비스 연속성 등을 가장 잘 실현시킬 수 있는 배치 모델은 공공 클라우드다. 정리하면, 퍼블릭(공공) 클라우드는 IT 인프라가 일반 공중이나, 대기업에게 제공되고 클라우드 서비스를 판매하는 조직에 의해 소유되는 형태를 의미한다. 외부 데이터센터를 사용하고, 이용자는 사용한 만큼 사용료를 지불한다. 이 장점들을 실현하기 위해서는 공공 클라우드가 제공하는 서비스를 매우 단순․규격화(commoditized) 시켜야 하며 초저비용으로 많은 용량 및 다중 고객을 처리할 수 있는 IT 아키텍처를 채택해야 한다. 이는 필연적으로 기업이 기존에 보유한 서비스 수준 협약 (SLA: Service Level Agreement)의 관점에서 볼 때 서비스 종류와 수준에 일정 정도의 제한을 가져올 수밖에 없다. 특정 회사 상황, 특정 부서 상황, 비즈니스/IT 현업의 요구 사항에 맞도록 커스터마이징되고, 복잡하게 설정된 서비스 요건 모두를 표준화된 공공 클라우드 서비스가 충분히 만족시키기는 어렵기 때문이다. 또한 높고 복잡한 보안 요건도 그 중 하나이다. 이를 극복하기 위해 사설 클라우드를 함께 활용 할 필요가 있다.
프라이빗(사설) 클라우드는 인프라가 특정 조직 내에서만 운영되고, 직접 혹은 위탁되어 운영되는 것을 말한다. 회사 내부에 클라우드 컴퓨팅 환경을 구성해 내부 고객에게 IT 서비스를 제공하는 것으로, 프라이빗 클라우드는 기업 내의 클라우드 데이터센터를 운영하면서 내부 직원들의 개인 컴퓨터로 데이터 자원을 사용하도록 하는 개념이다. 이를 통해 회사 각 구성원들의 각각의 시스템 관리 부담이 해결되고, 기업 입장에서는 기업 내 자료 통합 관리의 장점을 가진다. 퍼블릭 클라우드가 클라우드 서비스를 사용하는 대상을 제한하지 않는 방식을 의미한다면 프라이빗 클라우드는 클라우드 서비스를 사용하는 대상을 제한하는 방식으로 주로 대기업에서 데이터의 소유권을 확보하고 프라이버시를 보장받고자 할 때 구축되는 방식이라는 차이점이 있다. 한편, 사설 클라우드만 사용하게 되는 경우 단일 조직 내부의 클라우드는 상기한 공공 클라우드의 장점을 충분히 활용하지 못한다. 클라우드는 철저히 규모의 경제, 효율의 경제에 기반을 두기 때문이 다.
공공 클라우드 보다 덜 단순․규격화되지만 사설 클라우드보 다는 덜 복잡하고 덜 커스터마이징 되어도 되는 서비스를 위해 커뮤니티 클라우드(Community Cloud)를 활용할 수 있다. 이는 공공기관들, 동종 산업 내 기업들 등 일정 정도의 동질적인 비즈니스 목적을 가진 조직들이 활용할 수 있는 배치 모델이다. 그리고 특별한 보안요구나 공통 미션같은 관심사를 공유한 조직이나, 그룹에 의해 이용되는 방식이라고 할 수 있다. 커뮤니티 클라우드는 인프라가 몇몇 조직에 의해 공유되고, 직접 혹은 위탁 운영된다는 점에서 프라이빗 클라우드와 유사하다.
마지막으로 클라우드 서비스를 이용하게 되면 공공 클라우드, 커뮤니티 클라우드, 사설 클라우드가 적절히 필요하게 되는데, 2-3개의 배치 모델을 적절히 섞어서 활용하는 것이 하이브리드 클라우드이다.
앞서 NIST에 의한 클라우드 컴퓨팅의 개념을 규정한 부분에서 클라우드 컴퓨팅의 서비스 종류에 따른 분류를 간단히 설명하였다. 클라우드 컴퓨팅은 제공되는 컴퓨팅 자원의 종류에 따라 소프트웨어 및 애플리케이션을 서비스하는 SaaS, 개발자용 플랫폼 및 개발툴을 제공하는 PaaS, 데이터 저장 및 처리를 위한 스토리지와 서버 시스템을 대여하는 IaaS로 구분된다.
2.2.1 선행 연구 분석
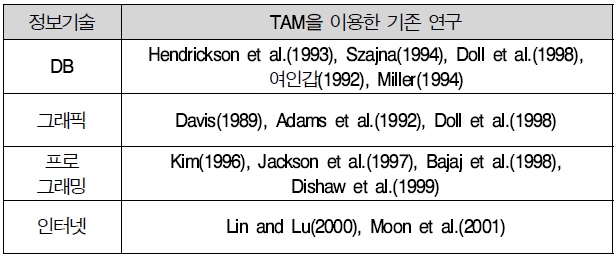
본 연구의 기본적인 전제는 디지털 상품은 물리적인 상품과는 달리 컴퓨터와 같은 정보기기를 이용해서만 사용이 가능한 특징을 갖는다는 것이다. 또한 이를 전통적인 소매쇼핑과는 달리 개인의 자발적인 의상에 의해서 수용되는 하나의 정보기술이라고 파악하는데 있다(구동모 외, 2001). 따라서 웹과 디지털 상품은 정보기술(Intelligent Technology: IT)의 일부로 볼 수 있으며(Chin, 2000), 디지털 상품에 대한 개념을 마케팅의 상품학적인 관점이 아닌 정보 기술이라는 측면에서 접근하고자 하는 것이다. 이러한 정보기술의 수용을 측정하기 위한 기존의 접근법으로는 기술수용모형(Technology Acceptance Model: TAM)이 있다. 대체로 TAM은 정보시스템의 기술수용을 설명하기 위한 모형으로 사용되지만 최근에는 정보기술에서 인터넷이 차지하는 범위가 넓어짐에 따라 모형의 활용범위도 인터넷과 같은 정보기술로까지 확대되었다(박순창 외, 2000: 구동모 외 2001). TAM을 활용하여 정보기술 수용요인을 측정한 주요 연구들은 아래 <표 2>와 같다.
[<표 2>] TAM을 응용한 정보기술 수용요인을 측정한 주요 연구
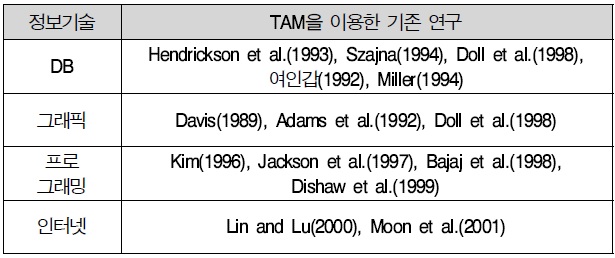
TAM을 응용한 정보기술 수용요인을 측정한 주요 연구
<표 2>의 TAM을 응용한 정보기술 수용요인을 측정한 선행 연구를 살펴보면 Davis(1989)는 기술수용모형과 계획된 행동 가설 모형이 사용의도의 예측에 잘 맞는다는 것으로 보여 주었으며, 특히 기술수용모형은 계획된 행동가설보다 적용이 쉬우나 일반적인 정보만을 제공한는 것으로 보여주었다.
Adams et al(1992)은 이메일과 음성메일, 사무용 소프트웨어에 TAM을 적용하여 지각된 용이성과 지각된 유용성 요인에 신뢰성이 있으며 유효하다는 것으로 보여주었다. 그룹지원 시스템에 적용한 결과, 모두 지각된 유용성과 지각된 용이성 변수가 정보 시스템 사용에 유의미한 연광성이 있다고 밝혔다.
Moon(2001)은 TAM을 웹사이트에 적용하여 지각된 용이성과 지각된 유용성이 웹사이트 사용에 유효하다는 것으로 보여주었다. 이 연구는 웹사이트에서의 편리성과 유용성에 기여하는 요인의 특징을 알아보고 웹사이트 개발자에게 지각된 유용성과 지각된 용이성에 대한 중요한 지침을 제공하였다.
Davis(1989)에 의하면, 사용자들이 새로운 정보기술을 수용하거나 거부하는 기본모델로써, 특히 유용성과 용이성에 큰 영향을 받는 것으로 알려졌다. 지각되는 유용성은, 사용자들이 어떤 신기술이 자신의 업무성과를 높이는데 도움을 줄 수 있을 것이라고 믿는 정도에 따라 그것을 사용하는 거나 사용하지 않는 것을 결정하는 요인이다. 지각된 용이성은, 사용자들이 새로운 신기술이 유용하다고 믿지만 그것이 사용하기에 어렵거나 사용하는데 드는 노력을 많이 필요로 한다면 그 기술에 대한 사용을 거부하는 것을 말한다.
2.2.2 연구 모형 분석
정보기술의 사용자가 어떤 요인으로 정보기술을 수용하는지는 1990년대의 경영정보시스템 연구의 가장 중요한 분야 중 하나였다. 이러한 기술수용을 연구하는 이론적 바탕은 합리적 행동이론(Theory of Reasoned Action : TRA), 계획행동이론(Theory of Planned Behavior), 그리고 기술수용모형(Technology Acceptance Model : TAM)의 3개의 모형에 그 기초를 두고 있다(박순창 외, 2000; 구동모 외 2001).
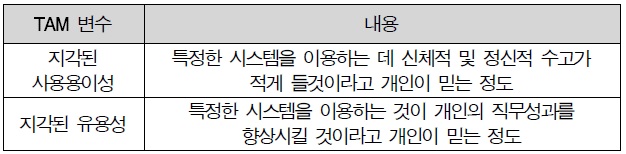
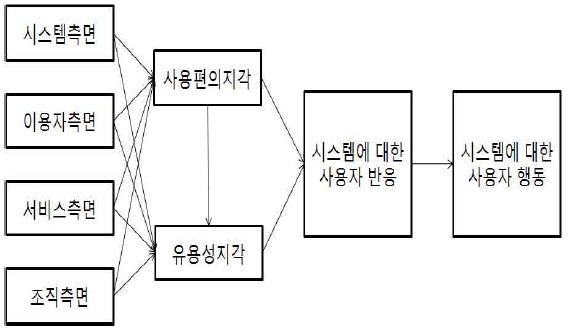
기술수용모형은 Davis(1989)에 의하여 TRA를 변형하여 도입되었다. 정보기술(IT)의 사용자 수용을 모형화 시키기 위하여 만들어 졌으며 정보시스템의 사용자 수용을 예측하고 설명할 목적으로 사용되었다. Davis는 정보기술을 수용하는 주요 행동변수로서 지각된 유용성과 지각된 사용용이성 변수를 사용 하였다. 이들 TAM의 해식변수들의 정의는 아래의 Table 3과 같다. TAM의 기본 모형은 다음의 <그림 3>과 같다.
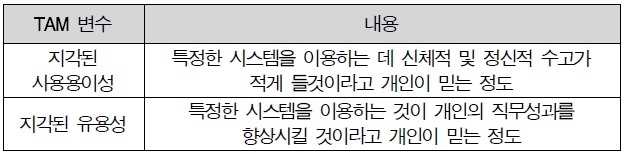
TAM 변수의 정의
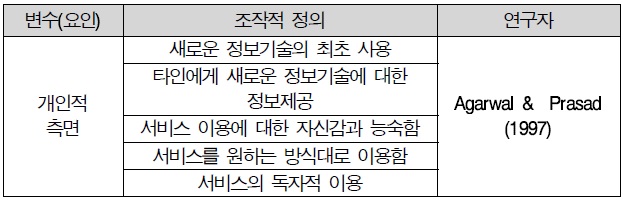
김영기(2010)는 상황인지 컴퓨팅 서비스사용자 수용에 관한 실증적 연구에서 Agarwal and Prasad(1997)의 연구를 토대로 정보기술 영역에서의 개인적 측면은 새로운 정보기술을 시험해 보려는 개인의 자발적 의지라고 하였고, 개인적 측면이 새로운 기술을 사용하려는 의도에 영향을 미칠 것이라고 하였다 또한 Agarwal and Karahanna(2000)등에서는 개인적 측면이 인지적 몰입의 중요한 결정요인으로 간주하고 지각된 유용성과 용이성에 영향을 미친다고 하였으며, 개인적 측면을 5 가지 항목으로 측정한 바 있다. 따라서 본 연구에서는 개인적 측면을 “새로운 정보기술을 시험해 보려는 개인의 자발적 의지 정도”라고 정의하였고, 선행연구를 기반으로 5 문항을 작성하였다.
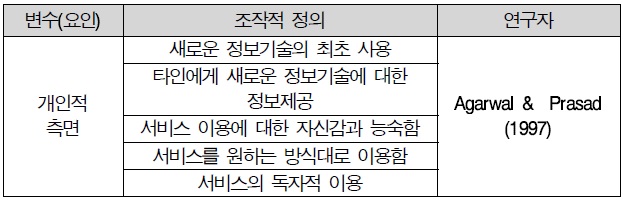
개인적 측면 조작적 정의
3.2.1 서비스 측면
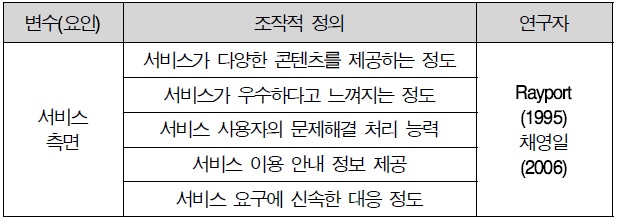
Rayport(1995)에 의해 시도 가능성은 혁신을 한정된 기반에서 시험적으로 사용해 볼 수 있는 정도로 정의되었다(채영일, 2006) 따라서 본 연구에서는 시도 가능성을 “서비스 사용기회의 제공여부 및 기능시험의 기호 정도”라고 정의하였고, 선행연구를 기반으로 5 문항을 작성하였다.
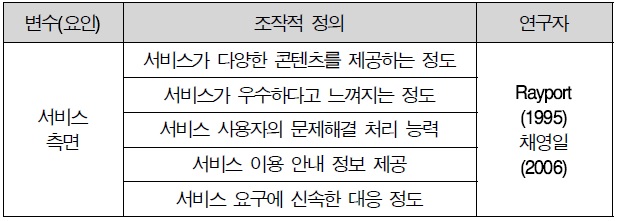
이용행태 측면 조작적 정의
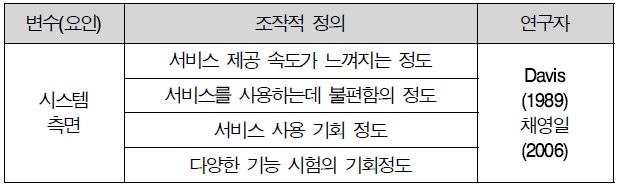
3.2.2 시스템 측면
시스템의 특성은 Davis(1989)의 정보시스템에서 사용하는 시스템의 성능과 속도를 비슷한 의미로서 사용하였다. 즉, 시스템 측면이란 사용자가 안정적이고 효율적으로 시스템을 사용할 수 있는 정도를 말한다 따라서 본 연구에서는 시스템 측면을 “시스템(서비스)의 안정성과 속도”로 정의하였고, 선행 연구를 기반으로 4문항을 작성하였다.
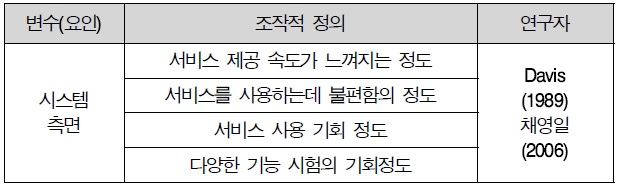
이용행태 측면 조작적 정의
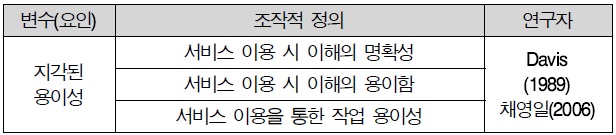
3.3.1 지각된 용이성
지각된 용이성은 Davis(1989)의 기술 수용 모형(TAM)에서 제시한 핵심적인 개념을 그대로 이용하였다. 지각된 편이성이란 “특정 시스템을 이용하는 것이 사용자의 노력을 감소시킬 것 이라고 사용자가 믿는 정도”라고 정의하였고, 선행연구를 기반으로 3문항을 작성하였다.
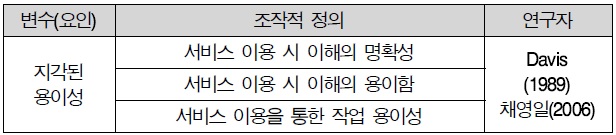
지각된 용이성 조작적 정의
3.2.2 지각된 유용성
지각된 유용성 또한 Davis(1989)의 기술 수용 모형(TAM에서 제시한 핵심적인 개념을 그대로 이용하였다. 지각된 유용성이란 “특성 시스템을 이용하는 사용자의 직무 성과를 향상시킬 것이라고 사용자가 믿는 정도”라고 정의하였고, 선행연구를 기반으로 3문항을 작성하였다.
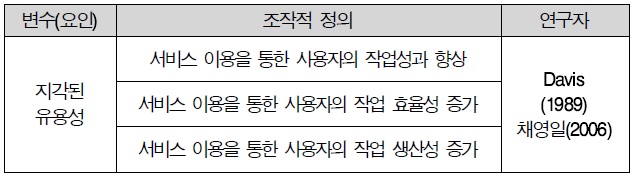
지각된 유용성 조작적 정의
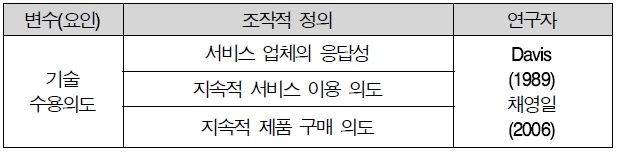
Davis et al(1989)의 연구에 의하면 수용 의도는 “특정한 정보시스템을 이용하려는 의도의 강도”라고 정의하였다. 수용 의도는 실제 행동을 결정하는 주요한 요인으로서 사용의도로부터 실제 행동이 예측 가능하도고 하였다(채영일, 2006, 서필수, 2008) 본 연구에서는 “서비스를 이용할 의도나 가능성”이라고 정의하였고, 선행연구를 기반으로 3문항을 작성하였다.
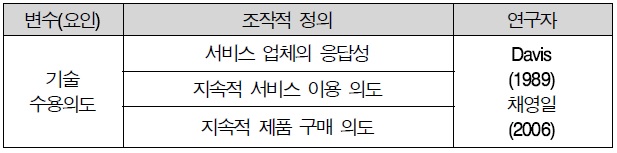
기술 수용의도 조작적 정의
4.1.1 연구모형 도출
앞서 기술했던 것처럼 TAM은 정보기술을 사용자가 수용하는 요인에 대해 설명하는 모형이다. 현재 인터넷과 컴퓨터는 광범위하게 사용되고 있으며 기업의 정보기기 시스템뿐만 아니라 개인의 여가활용에 이르기까지 최종사용자의 범위가 넓다. 또한 인터넷상에서 거래되는 디지털 상품을 사용하기 위해서는 정보기기, 즉, 컴퓨터와 인터넷과 같은 정보기술을 다룰 수 있는 기초적인 지식이 있어야만 가능하다. 그러므로 컴퓨터와 인터넷을 정보기술로 보고, 정보기술을 수용하는데 영향을 미치는 요인이 무엇인지 설명하는 TAM의 사용이 적합하다고 판단되어 연구모형으로 TAM을 도입하게 되었다.
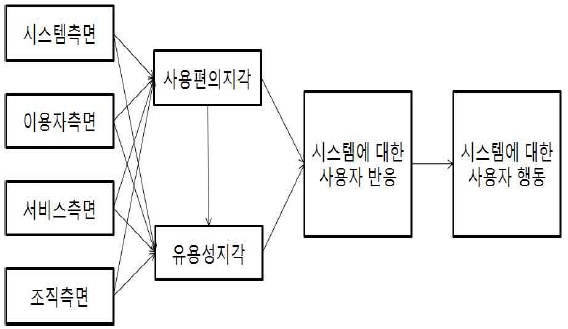
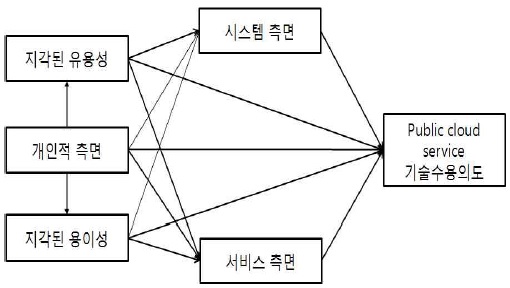
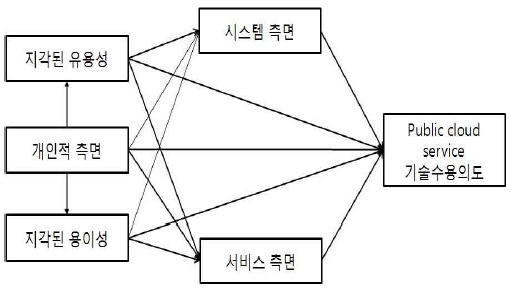
하지만 기존의 TAM을 이용하여 분석을 해본 결과 연구모형의 적합도가 수용불가능으로 나타났다. 수정지수 등을 이용하여 연구모형의 적합도 향상을 위해 다양한 시도를 해본 결과 인과관계의 논리성이 떨어지는 것으로 나타나 <그림 4>의 TAM을 응용한 연구 모형을 도출하게 되었다.
기존 TAM과 차이점으로 기본 TAM은 이용행태 변수인 개인적 측면과 시스템 측면 그리고 서비스 측면에서 인과관계가 출발하지만 본 연구 모형에서는 개인적 측면을 기준으로 인과관계가 시작된다.
개인적 측면의 내용은 개인의 디지털 상품에 대한 얼리어답터(early adopter)의 내용으로 신규 기술의 개발에 대해 얼마나 적극적으로 수용하려고 하는지에 대한 잠재적 인식을 의미한다. 이 변수를 기준으로 삼은 이유는 기본적으로 본 연구에서 응답한 응답자들이 SNS 등을 통해 조사가 이루어지다보니 기본적으로 컴퓨터 활용 능력이 높으며 신규 기술에 대한 욕구가 굉장히 높기 때문이다. 또한 신규 기술에서 제공되는 시스템 측면과 서비스 측면은 그 차이점을 두기 어려울 정도로 차이가 없어 그 변수들을 중간의 매개 변수로 설정하는게 더 타당한 것으로 나타났다.
4.1.2 연구 가설 설정
4.1.2.1 디지털 상품의 서비스 측면과 개인적 측면,
시스템 측면 TAM의 인과관계 디지털 상품의 서비스 측면과 개인적 측면, 그리고 시스템 측면이 TAM의 용이성지각과 유용성지각 사이에 갖는 인과관계는 기존의 선행연구를 통하여 설명하도록 하였다. TAM의 주요 연구들에서 나타난 독립변수들은 크게 개인관련 요인, 서비스 관련 요인, 시스템 관련 요인, 조직관련 요인의 4개의 범주로 나누어진다(Davis, 1989; 박순창 외, 2000). 본 연구에서는 이 중 TAM의 조직관련 요인은 일반 개인 사용자를 대상으로 하는 본 연구에 맞지가 않아 제외 시켰다. 그리고 사용자가 디지털 상품을 사용하면서 다루게 되는 컴퓨터와 같은 정보처리기기를 이용 환경으로 정의하여 시스템 측면으로 포함시켰다.
4.1.2.2 개인적 측면에 따른 가설
본 연구에서 개인적 측면은 원래 TAM에서 개인관련 요인으로 판단하였다. Parasuraman(1988)의 연구에서 개인의 컴퓨터의 이용도는 시스템이용도에 직접적으로 영향을 미친다고 하였다. 이미 많은 기존의 TAM을 활용한 연구들에서 개인의 컴퓨터 또는 정보기술의 사용경험이 정보기술의 수용 및 인터넷쇼핑에서 중요한 변수로 사용된다는 연구결과를 제시하고 있다(Igbrarua, 1990; Taylor et al., 1995; Igbrarua et al., 1995). 또한 디지털 상품을 이용하기 위한 컴퓨터통신은 다른 매체의 특성과는 달리 이용방법의 습득시간이 적고 이용능력이 적정수준에 도달하면 친밀하게 지각하는 동시에 유용성에 대한 평가를 하기 시작하며(Trevino, 1992), 이용량이 많아지면서 그에 대한 좀 더 긍정적인 평가를 내리게 된다(Schmitz, 1991). 따라서 본 연구에서는 다음과 같은 가설을 설정하였다.
4.1.2.2 사용 용이성 지각에 따른 가설
앞서 TAM을 정의한 바와 같이 사용 용이성은 ‘특정한 시스템을 이용하는 데 신체적 및 정신적 수고가 적게 들 것이라고 개인이 믿는 정도’로서 기술하였다(Davis, 1989). 본 연구에서는 Davis(1989)가 정의한 특정한 시스템을 디지털 상품이라고 구성하여 사용 용이성 지각은 ‘디지털 상품을 이용하기 위해 개인이 믿는 정도’라고 재정의 하였다(채영일, 2006). 사용 용이성 지각과 유용성지각 모두 개인의 기술수용에 대한 태도를 말하는 구체적인 신념이며, 정보기술의 수용의도와 서비스측면 그리고 시스템 측면은 지각된 용이성에 영향을 받아 형성된다(Davis et al.; Davis, 1989; 구동모 외, 2001). 따라서 본 연구에서는 다음과 같은 가설을 설정하였다.
4.1.2.3 유용성지각에 따른 가설
유용성지각은 ‘특정한 시스템을 이용하는 것이 개인의 직무 성과를 향상시킬 것이라고 개인이 믿는 정도’라고 정의한다(Davis, 1989). 하지만 본 연구에서는 원래 TAM에서 특정한 시스템을 디지털 상품이라고 해석하여 ‘디지털 상품을 사용하는 것이 같은 목적의 상품을 이용하는 것보다 성과를 향상시킬 것이라고 개인이 믿는 정도’라고 재정의 하였다(채영일, 2006). 유용성지각은 정보기술의 수용의도에 직접적인 영향을 미치는 것으로 보고되고 있으며(Davis, 1989; Chin, 2000) 정보 기술의 이용행태에도 직접적으로 영향을 미치고 있다(Adams et al., 1992; Ruth, 2000). 또한 Agarwal et al.(2000)은 유용성 지각이 인터넷, 전자메일 등 최근의 정보기술의 사용에도 직접적인 영향을 끼친다는 연구결과를 제시하였다. 이와 같은 연구를 결과를 기반으로 본 연구에서는 다음과 같은 가설을 설정하였다.
4.1.2.4 이용특성에 따른 가설
인터넷상의 물리적인 상품의 구매 및 이용에 대한 요인으로서 서비스 측면과 시스템 측면에 대한 영향요인이 구매 및 사용에 영향을 미친다는 사실은 이미 기존의 많은 연구에서 증명된바 있다(Javenppa & Todd, 1996, 채영일, 1997). 따라서 본 연구에서는 디지털 상품의 이용특성이 기술수용의도에 미치는 영향관계를 분석하려고 한다. 이에 다음과 같은 가설을 설정하였다.
3.1.1 자료모집 방법
제시된 가설을 검증하기 위하여 클라우드 컴퓨팅 서비스에 관한 설문조사를 실시하였는데, 표본추출방법으로는 비확률 표본추출방법을 선택하였으며, 임의표본추출방법으로 다음과 같은 과정을 통해 진행하였다. 우선 클라우드 컴퓨팅 서비스 중 공공 클라우드 컴퓨팅 서비스를 이용하는 인터넷 사용자들을 중심으로 인터넷 포탈 업체인 구글의 구글 독스를 이용하여 온라인 설문조사를 실시하였다.
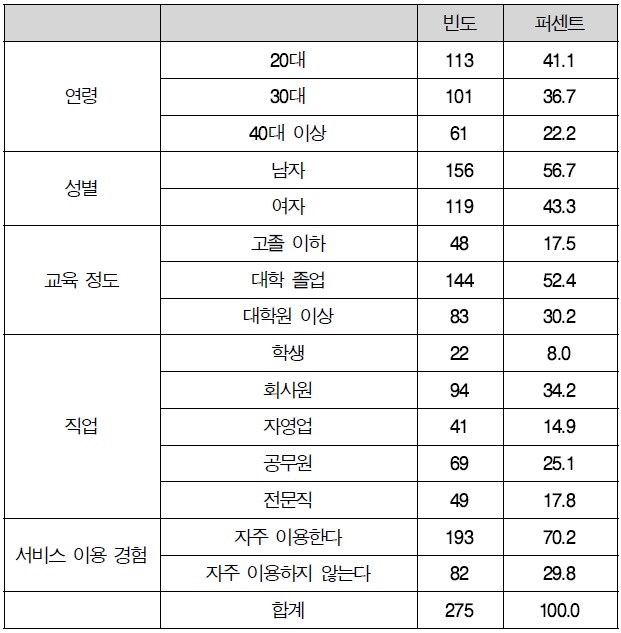
조사 기간은 2013년 1월 초부터 2월 말까지 두 달 동안 진행되었다. 회수된 설문지는 총 310부였으며, 이 중에서 무성의한 응답 또는 결측치가 있는 설문지는 연구에 부적당하다고 판단되어 제외하고 총 275부 응답표본을 분석에 사용하였다.
3.1.2 표본의 특성
연령에서는 20대가 41.1%로 가장 높게 나타났으며, 30대가 36.7%, 40대 이상이 22.2% 순으로 나타났다. 성별에서는 남자가 56.7%, 여자가 43.3%로 나타났다. 교육 정도에서는 대학 졸업이 52.4%로 가장 높게 나타났으며, 대학원 이상이 30.2%, 고졸 이하가 17.5% 순으로 나타났다. 직업에서는 회사원이 34.2%로 가장 높게 나타났으며, 공무원이 25.1%, 전문직이 17.8%, 학생이 8.0% 순으로 나타났다. 서비스 이용 경험에서는 자주 이용한다가 70.2%, 자주 이용하지 않는다가 29.8%로 나타났다.
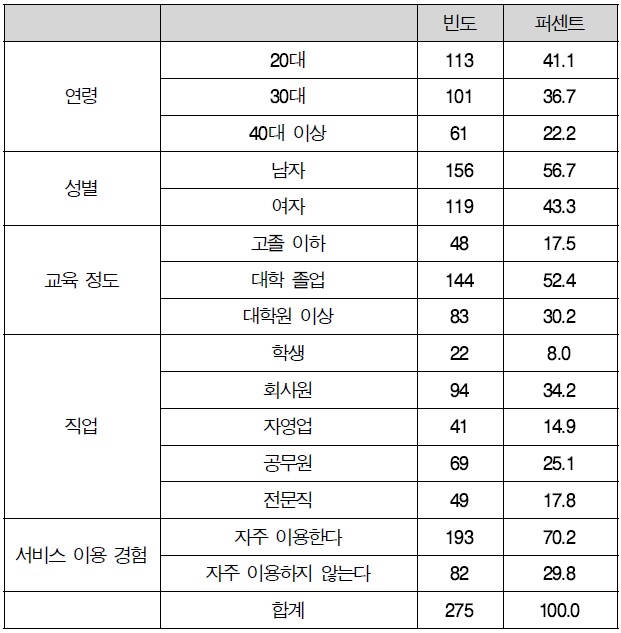
인구통계학적 특성
본 연구는 가설검증을 위해서 타당성 분석, 신뢰성 분석 및 요인분석, 그리고 구조방정식 모형을 통해 경로분석을 수행하였다. 또한 기술통계량과 척도 분석, 그리고 상관관계 분석을 통하여 각 변수들 간의 관계와 구조를 설명하였으며 구체적인 가설들을 규명하기 위해서 경로분석에 의한 회귀분석방법을 이용하였다.
3.2.1 타당성 분석
타당성 분석(Validity Analysis)이란, 측정하는 개념이나 속성을 측정도구가 정확하게 측정할 수 있는가를 나타내는 개념이다(김계수, 2001). 즉 측정개념이나 속성을 측정하기 위해 개발된 측정도구가 해당속성을 정확하게 반영하고 있는가와 관련이 되어 있다. 타당도에는 세 가지의 종류가 있으며 다음과 같다.
첫째, 내용타당도(contents validity)는 측정도구를 구성하고 있는 항목들이 측정하고자 하는 개념을 대표하고 있는 정도를 말한다. 이것은 전문가나 연구자의 주관적인 판단에 의해서 측정된다.
두 번째, 예측타당도(predictive validity)는 한 가지 속성이나 개념에 의한 측정값이 다른 속성의 변화를 예측하는 정도를 말한다.
세 번째, 구성타당도(construct validity)는 측정도구가 연구하고자 하는 개념이 구성을 측정하였는지를 검증하는 방법이다.
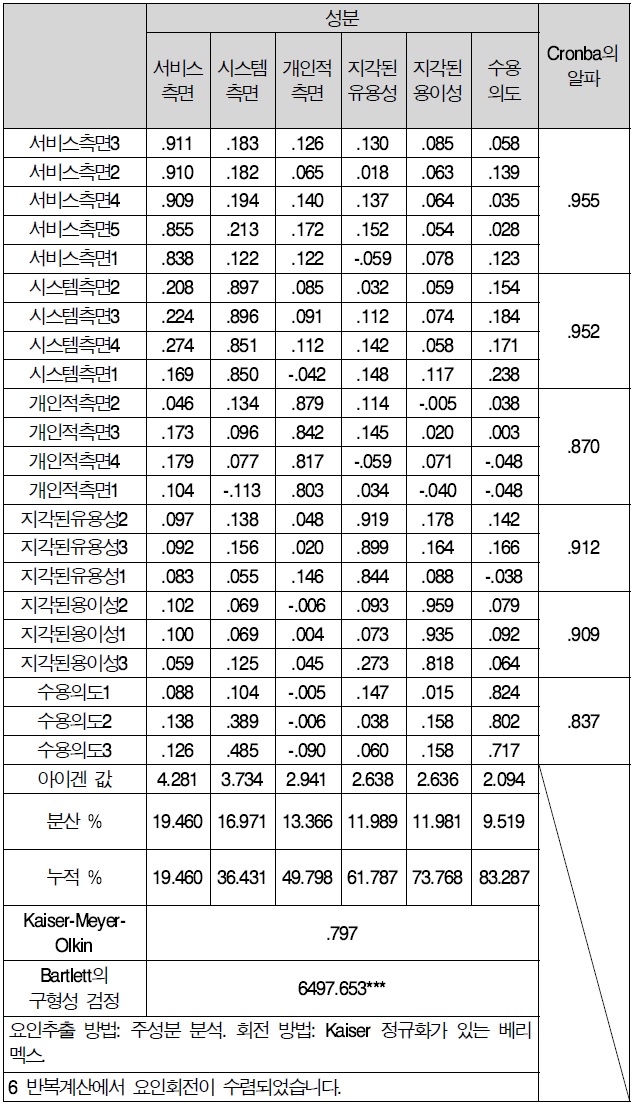
먼저 본 연구는 구성타당도를 측정하기 위해서 요인분석을 실시하였다. 요인분석은 항목들 간의 상관관계가 높은 것끼리 하나의 요인으로 묶어 내며 요인들 간에는 상호 독립성을 유지하도록 할 수 있다. 요인분석을 실시하는 경우, 표본의 수는 적어도 변수 개수의 4~5배가 적당하며, 등간척도나 비율척도 등으로 정량적으로 측정된 것이어야 한다(강병서, 1999). 요인추출모형에는 주성분 분석(PCA: Principle Component Analysis)과 CFA(Common Factor Analysis)등이 주로 사용된다. 본 연구에서는 정보의 손실을 최소화하면서 보다 적은 수의 요인을 구하고자 할 때 자료의 총분산을 분석하는 PCA 분석을 사용하였다.
PCA 분석의 수행 후에 초기 요인패턴의 해석상의 어려움으로 인해 요인의 회전을 수행했으며 요인구조를 회전시키는 방법으로는 요인 내의 상관은 높이면서 독립성을 유지시켜 주는 배리멕스(varimax rotation)방법을 사용하였다. 변수 내의 요인 수 결정은 요인이 설명할 수 있는 변수들의 분산크기를 나타내어 일반적으로 사회과학 분야에서 널리 인정되고 있는 고유치, 즉 아이겐 값(eigen value)이 1 이상이 되는 요인만을 추출하였다.
요인적재량(factor loading value)은 각 변수와 요인 사이의 상관관계의 정도를 설명하므로, 각 변수는 요인적재량이 가장 높은 요인에 속하게 된다. 요인분석 결과, 요인이 추출되었을 때 요인적재량이 0.4 미만인 항목은 타당성이 없는 것으로 간주하고 연구에서 제외하는 것이 일반적이다. 각 개념이 측정에 사용될 연구변수들은 비교적 안정된 요인적재량을 나타내었다. 그러나 개인측면 5번 항목이 구성 타당도를 저해하는 것으로 나타나 삭제 후 연구를 진행하였다.
3.2.2 신뢰성 분석
신뢰성 분석(reliability analysis)을 하는 이유는 다음과 같다.
첫째, 측정하고자 하는 개념이 조사대상자로부터 정확하고 일관되게 측정되었는지를 확인하는 것이고, 둘째, 설문에 응답하는 사람이 정확하게 일관되게 측정에 응했는지를 분석하는 데 이용된다(성태제, 1999). 즉, 추출된 요인구조에서 각각의 요인들이 독립된 개념을 가지는지를 신뢰할 수 있는지 알아보는 분석방법이다. 본 연구에서 사용한 설문을 하나의 검사도구로 봤을 때 그 검사 도구를 지지해 주는 측정변수들이 요인 내에서 얼마나 일관성(consistency)있게 측정되었는지 알아보는 내적 일관성 신뢰도를 측정하는 것이다.
내적 일관성을 측정하는 방법은 일반적으로 Cronba's α 값에 의한 내적 일관성 분석을 실행하였다. 일반적으로 이를 통해서 타당하고 신뢰할 수 있는 문항은 선정하고 일관성을 해치는 문항은 제거함으로써 각 요인에 대한 요인점수를 산출하는 과정을 거치게 된다. 사회과학에서는 대체로 Cronba's α값이 0.6 이상이 되면 비교적 신뢰도가 높다고 판단한다.
신뢰도 분석 결과를 보면 서비스 측면이 신뢰도 계수 .955로 가장 높게 나타났으며, 시스템 측면이 .952, 지각된 유용성이 .912, 지각된 용이성이 .909, 개인적 측면이 .870, 수용의도가 .837 순으로 나타났다. 전체적으로 0.8 이상의 높은 신뢰도를 나타냈다.

연구 변수 탐색적 요인분석
3.2.3 상관관계 분석
상관관계 분석(correlation analysis)은 연구하고자 하는 변수간의 관계를 분석하기 위해 사용하는 분석방법으로, 특정 변수와 다른 변수간의 관계 및 그 관계의 크기, 그리고 변화의 방향성에 대하여 파악할 수 있다. 일반적으로 회귀분석 전에 실시하는 중요한 분석방법으로, 연구에서 결정된 가설의 검증 관계를 예측할 수 있는 선행 자료가 된다는 점에서 매우 중요한 의미를 갖는다. 이와 같은 변수간 관련성을 알아보기 위해 상관관계 분석에서는 Person 상관계수를 이용한다.
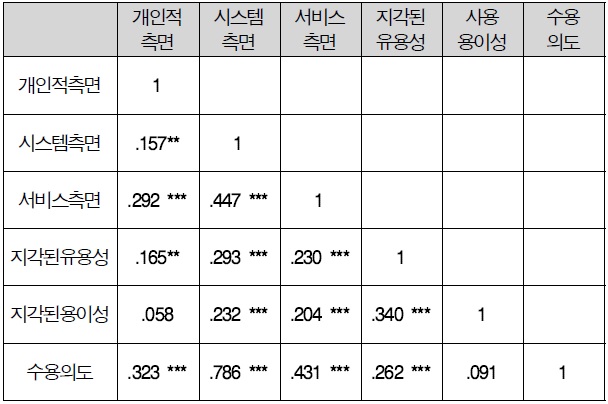
Person 상관계수는 -1부터 1까지의 값을 가지며, 상관계수의 부호는 변수간 관계의 방향성을 의미한다. 또한 상관계수의 절대 값은 관계의 크기를 나타내며, 절대 값이 클수록 변수 간에는 강한 상관관계가 있다는 것을 의미한다. 일반적으로 Person 상관계수의 값이 ± 0.7-±1.0일 경우 매우 높은 상관관계,±0.4-±0.7일 경우 비교적 높은 상관관계, ±0.2-±0.4일 경우 보통 수준의 상관관계가 있으며, 0-±0.2일 경우에는 매우 낮은 수준의 상관관계가 존재한다고 해석한다.
변수들 간의 상관관계를 보면 개인적 측면과 사용 용이성 간에는 통계적으로 유의한 상관관계가 존재하지 않는 것으로 나타났다. 또한 사용 용이성과 수용의도 간에도 통계적으로 유의한 상관관계가 존재하는 않는 것으로 나타났다. 그 외 변수들 간에는 통계적으로 유의한 정의 상관관계가 존재하는 것으로 나타났다.
그중 시스템 측면과 수용의도 간에는 가장 높은 정의 상관관계를 나타냈으며, 개인적 측면과 시스템 측면이 가장 낮은 정의 상관관계를 나타냈다.
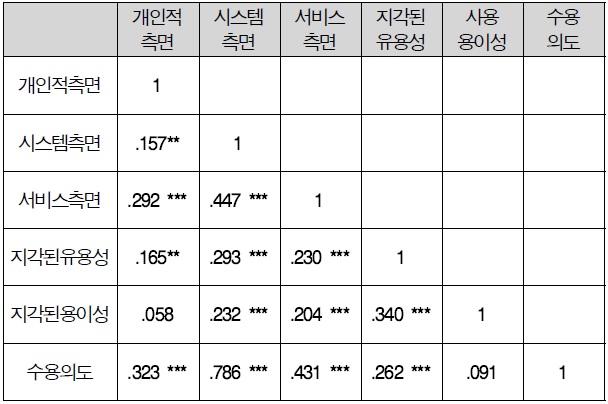
연구 변수 상관관계 분석
3.2.4 인과관계 분석
3.2.4.1 연구모형의 적합도 평가
본 연구에서 설정한 가설적 연구모형과 각 가설을 검증하기 위하여 경로분석(path analysis)을 통해 전반적인 연구모형의 적합도 모수들을 추정하였으며, 결오 모형의 모수추정을 위해 사용된 모수추정방법은 최우도추정방법(ML)을 이용하였다. 경로분석이나 구조방정식모형 분석에서 연구모형의 전반적인 적합도를 평가하기 위한 적합도 지수는 크게 절대적합 지수, 간명적합지수 그리고 증분적합지수등으로 나눌 수 있다.
절대적합지수는 구조모형과 측정모형의 두 모델에 대한 전반적인 적합도를 평가하는 것으로 χ² , NCP, GFI, RMR, RMSEA, ECVI 등의 값으로 평가하고, 간명적합지수는 모수 추정 시 추정된 계수에 의해 달성된 적합도의 양을 결정하기 위한 목적으로 각기 다른 추정계수의 수를 갖는 모형을 비교하기 위해 적합도 측정치를 조정한 것으로 AGFI, PNFI, PGFI, 표준 χ² , AIC, CAIC 등이 있다. 아울러 증분적합지수는 제안모형과 대안모형의 두 모델에 대한 전반적인 적합도를 비교한 것으로 TLI, NFI, NNFI, RNI, BFI, CFI, IFI 등의 값으로 평가한다(김계수, 2001; 노형진, 2002).
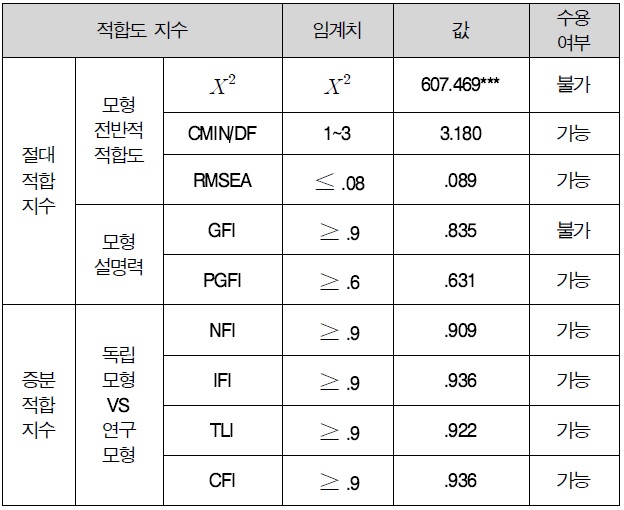
이론적 근거한 기초모형의 적합도를 살펴보면, <표 13>에 제시된 바와 같이 χ²=607.469(p=.000), GFI=.835, RMSEA=.089, PGFI=.631, NFI=.909, IFI=.936, TLI=.922, CFI=.936로 나타났다. 기초모형의 적합도 결과에 의하면 이 연구에서 설정한 경로모형의 적합도 기준 수치가 수용 수준을 대체로 충족시키지 못하고 있어 모형수정을 위해 제안모형의 적합도를 개선시키기 위하여 보조지표인 수정지수(Modification Index)를 이용하여 모형을 수정하였다.
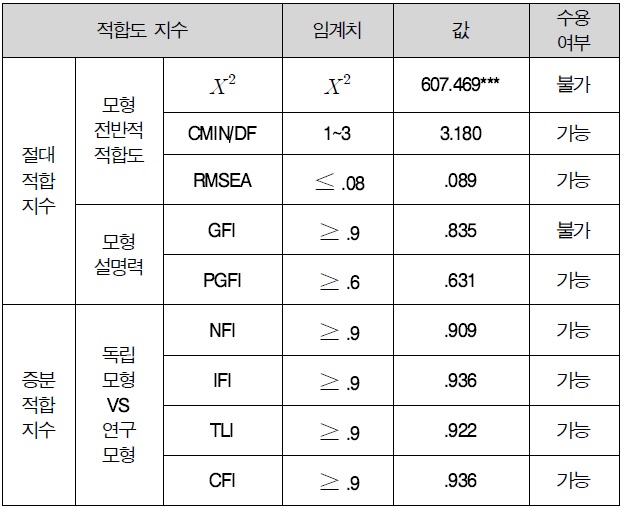
연구 모형 적합도 검정
수정지수는 각 변수들 간에 추정되지 않고 남아있는 고정모수를 자유스럽게 추정했을 때 적어도 그 지수의 값만큼 감소 할 것으로 기대되는 χ²값을 의미하며, 수정지수는 χ²분포를 따르기 때문에 계수 추정시에 χ²값의 감소와 거의 일치한다. 또한 수정지수가 3.84~5.0이상, 또는 매우 보수적인 수준인 10.0이상의 값을 가질 때는 그 고정모수를 추정해야 함을 의미한다. 따라서 두 변수들 간에 수정지수가 높게 나타난다면 두 변수들 간에는 추정되지 않고 남아있는 관계가 있다는 것을 암시해 주기 때문에 이론적 정당성이 충분히 뒷받침 된다면 이들 간의 관계를 새로 추가함으로서 수정지수만큼의 χ²값의 감소를 가져올 수 있다(김계수, 2001; 노형진, 2002).
이러한 근거에 준하여 모형의 적합도 수준을 확보하기 위해 연구모형에서 관계 가능성을 나타내고 있는 수정지수(Modification Index)에서 추정되지 않고 남아있는 고정모수로 확인된 변수인 인지적 반응과 감정적 반응 변수에 대한 이론적 배경을 고려하여 기초모형에서 인지적 반응과 감정적 반응의 error를 서로 쌍방향으로 연결하여 공변량을 자유화 시켰다. 이 두 변수는 서로 대치되는 용어이지만, 그 개념적 특성은 서로 연관성이 존재하고 있는 개념이다.
이와 같은 수정과정을 거쳐 수정한 경로 모형의 최종 적합도는 χ²=68.564(p=.000), GFI=.901, RMR=.049, AGFI=.897, NFI=.918, NNFI=.909로 나타났다. <표 13>에 제시된 바와 같이 수정 모형의 적합도는 모두 기초 모형보다 향상되었으며, 각각의 적합도 기준 수치가 수용 수준을 대체로 충족시키고 있는 것으로 나타났다. 따라서 본 연구에서 설정한 가설적 연구모형은 전반적으로 실증자료를 잘 나타내고 있다고 볼 수 있다.
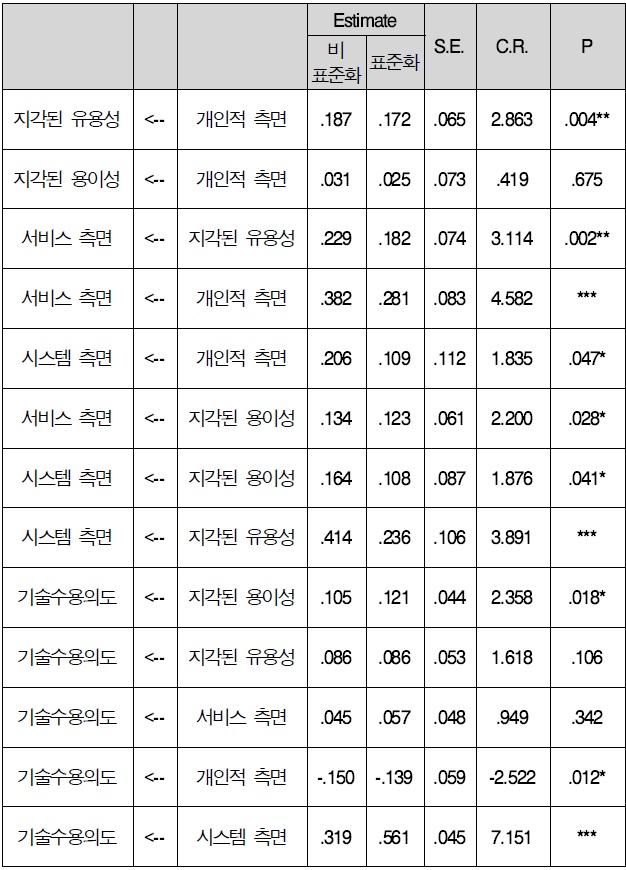
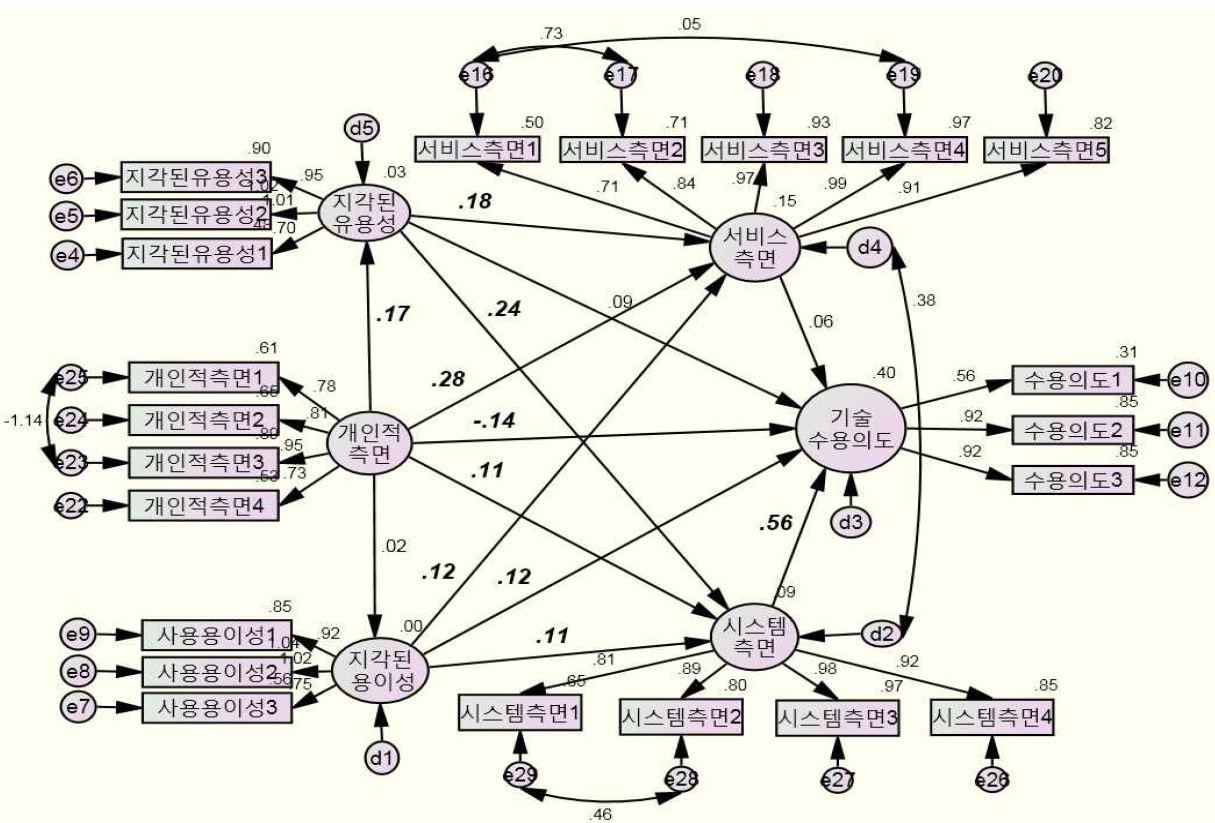
3.2.4.2 연구 모형 모수 추정치
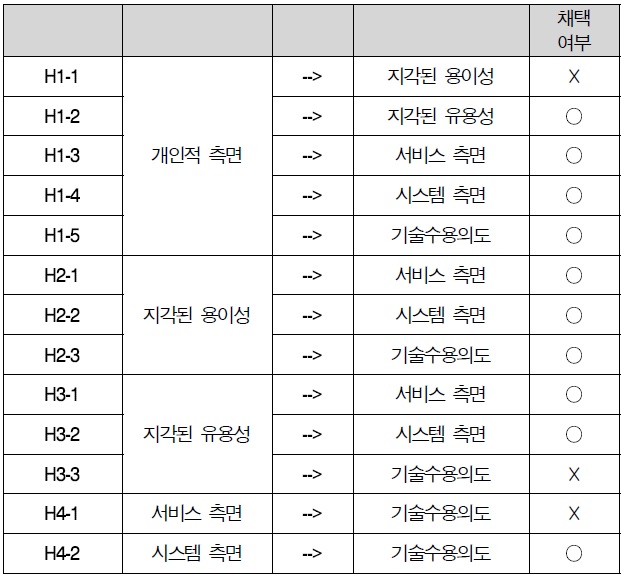
연구 모형 모수 추정치를 보면 개인적 측면은 지각된 유용성에 통계적(C.R=2.863, p<.01)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 개인적 측면이 증가하게 되면 지각된 유용성은 17.2% 증가하는 것으로 나타났다.
지각된 유용성은 서비스 측면에 통계적(C.R=3.114, p<.01)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 지각된 유용성이 증가하게 되면 서비스 측면은 18.2% 증가하는 것으로 나타났다.
개인적 측면은 서비스 측면에 통계적(C.R=4.582, p<.001)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 개인적 측면이 증가하게 되면 서비스 측면은 28.1% 증가하는 것으로 나타났다.
지각된 용이성은 시스템 측면에 통계적(C.R=2.200, p<.05)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 지각된 용이성이 증가하게 되면 시스템 측면은 12.3% 증가하는 것으로 나타났다.
지각된 유용성은 시스템 측면에 통계적(C.R=3.891, p<.001)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 기각된 유용성이 증가하게 되면 시스템 측면은 23.6% 증가하는 것으로 나타났다.
지각된 용이성은 기술 수용의도에 통계적(C.R=2.358, p<.05)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 지각된 용이성이 증가하게 되면 기술 수용의도는 12.1% 증가하는 것으로 나타났다.
개인적 측면은 기술 수용의도에 통계적(C.R=-2.522, p<.05)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 개인적 측면이 증가하게 되면 기술 수용의도는 13.9% 감소하는 것으로 나타났다.
시스템 측면은 기술 수용의도에 통계적(C.R=7.151, p<.001)으로 유의한 영향을 미치는 것으로 나타났다. 즉, 시스템 측면이 증가하게 되면 기술 수용의도는 56.1% 증가하는 것으로 나타났다.
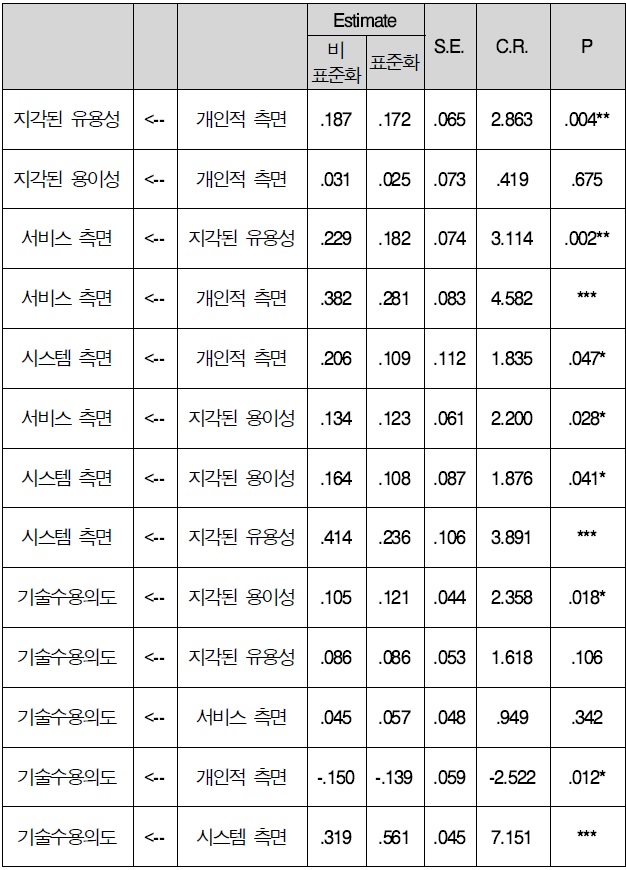
연구 모형 모수 추정치
본 연구는 공공 클라우드 컴퓨팅 서비스를 디지털 상품에 대한 정보기술의 하나로 전제하고 TAM을 활용하여 개인이 기술을 수용하려는 신념이나 태도에 따라서 디지털 상품을 구매 또는 이용, 즉 수용하려고 할 것이라는 가정에서 시작하였다. 또한 어떠한 속성이 디지털 상품의 고객 수용도를 높이는지를 분석하였다. 나아가 상품 특성과 이를 이용하는 사용자 특성, 그리고 사용자가 갖춘 시스템의 특성이 기여하는지 확인하고자 하였다.
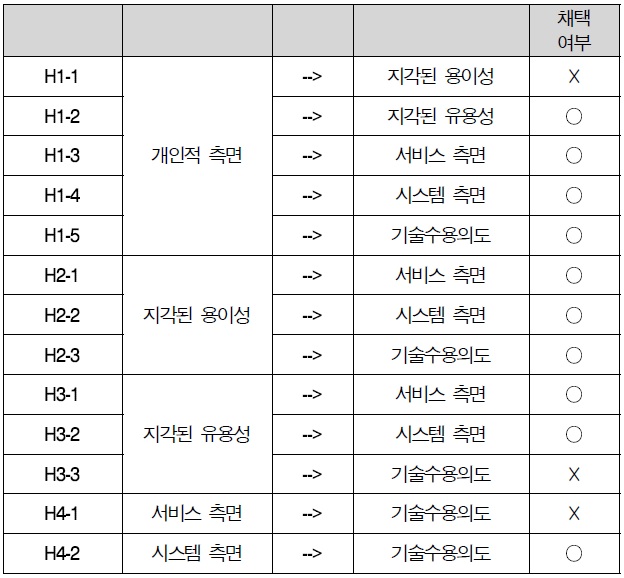
인과관계의 결과를 살펴보면 다음과 같다. 개인적 측면은 지각된 유용성과 서비스 측면 시스템 측면 그리고 기술 수용 의도에 유의한 영향을 미치는 것으로 나타났다. 시스템 측면은 기술 수용의도에 유의한 영향을 미치는 것으로 나타났다. 지각된 용이성은 서비스 측면과 시스템 측면 그리고 기술 수용의도에 유의한 영향을 미치는 것으로 나타났다. 지각된 유용성은 서비스 측면과 시스템 측면에 유의한 영향을 미치는 것으로 나타났다.
기술 수용의도에 가장 큰 영향요인은 시스템 측면으로 나타났으며, 지각된 용이성 순으로 나타났으며, 개인적 측면은 기술 수용의도를 감소시키는 것으로 나타났다.
전반적인 인과분석의 결과를 종합해봤을 때 기존 TAM 연구는 외부환경 변수에서 기술수용의도에 영향을 미치는데 본 연구에서는 외부환경 변수 중 개인적 측면을 중심으로 연구 모형이 시작되는 차이점을 가지고 있다. 이는 근본적으로 기존 연구와 다른 결과를 제시하고 있다. 기존 연구에서는 환경적 변수를 독립변수로 그리고 지각된 용이성과 유용성을 매개로 기술수용의도에 영향을 미치는지를 규명하고자 하였다. 하지만 본 연구에서는 외부 환경적 변수인 개인적 측면을 1차적 독립변수로 설정하여 인과관계가 시작이 되면 매개 변수로 시스템 측면과 서비스 측면을 두고 있다. 지각된 용이성과 유용성은 2차적 독립변수로 설정하였다. 그 이유는 조사 기법에서 SNS만을 활용하다보니 컴퓨터의 활용 능력이 높은 조사대상자만을 연구 대상으로 하다 보니 상대적으로 기존 TAM과 달리 조사대상장의 특징이 강하게 나타났으며, 또한 공공 클라우드 컴퓨팅 서비스가 제공되는 시스템 측면과 서비스 측면에서 기업 간 차별성이 떨어진다는 점도 있다.
이는 결과적으로 클라우드 컴퓨팅 서비스는 새롭게 개발되는 신기술에 대해 사용자가 얼마나 능동적으로 활용하고자 하는 개인적 의지가 중요하다는 것을 말하고 있다. 즉, 아직 클라우드 컴퓨팅이 대중적으로 보급되지 않는 한국 현실에서 특히 중요한 의미를 가진다.
따라서 클라우드 컴퓨팅 서비스의 확대를 위해서는 얼리어답터(early adopter)가 먼저 이를 이용하고 이의 유용성과 용이성이 확인 되었을 때 그 기술의 수용의도는 확대된다는 것을 알 수 있다.
연구 모형 모수 추정치 결과
본 연구의 시사점은 다음과 같다. 시사점을 제공하고 있다. 첫째, 현재까지 물리적인 상품의 비교수단으로만 사용되던 디지털 상품을 물리적인 상품처럼 디지털 상품도 속성에 따라 분류하여 비교할 수 있는 기준을 제공하였다. 둘째, 디지털 상품에 대한 학술적인 접근을 마케팅적인 측면에서 정보 기술의 수용으로 바라보는 관점의 전환을 제공하였다. 디지털 상품을 컴퓨터, 전자우편과 같은 개인이 자발적으로 선택하고 사용하는 기술수용의 행동으로 설명하는 데 도움을 주고 다각적으로 디지털 상품에 접근할 수 있는 다양성을 제시하였다. 셋째, 디지털 상품을 판매 또는 서비스하는 인터넷 기업들에게 정보기술을 사용하는 개인의 특성과 별개로 기술 수용의 신념과 태도가 디지털 상품을 선택하는 데 영향을 준다는 정보를 제공해 주었다. 이것은 각 디지털 상품의 속성별로 다른 특성을 갖으며 디지털 상품을 통한 e-비즈니스 또한 좀 더 세분화되어 상품의 속성을 활용하는 방향으로 수행하여야 한다는 의미이기도 하다.