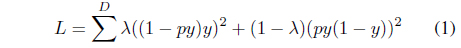As the number of resources for documents is growing continuously, our need to acquire useful information from them is also growing everyday. Keyphrase, which is the smallest unit of useful information, can concisely describe the meaning of content in documents. Moreover, keyphrases can also be used in text mining applications like information retrieval, summarization, document classification, and topic detection. However, only a small portion of documents contains author-assigned keyphrases and a majority of documents do not have keyphrases. Therefore, extracting keyphrases from documents has become one of the main concerns in recent days, and there have been several studies on automatic keyphrase extraction task [1–14].
Most of the previous studies focused only on selecting keyphrases within the body of input documents. These studies overlooked latent keyphrases that did not appear in documents, extracted candidates only from the existing phrases in the document, and evaluated them under the assumption that they appear in the document. Therefore, those methods were not suitable for the extraction of latent keyphrases. In addition, a small number of studies on latent keyphrase extraction methods had some structural limitations. Although latent keyphrases do not appear in documents, they can still undertake an important role in text mining as they link meaningful concepts or contents of documents and can be utilized in short articles such as social network service (SNS), which rarely have explicit keyphrases.
In this paper, we propose a new approach that selects reliable latent keyphrases from input documents and overcomes some structural limitations by using deep belief networks (DBNs) in a supervised manner. The main idea of this approach is to capture the intrinsic representations of documents and extract eligible latent keyphrases by using them. Additionally, a weighted cost function is suggested to handle the imbalanced environment of latent keyphrases compared to the candidates.
The remainder of this paper is organized as follows. Section 2 provides a brief description of previous methods in relation to keyphrase extraction. Section 3 provides a background on the proposed method. Section 4 introduces a method of latent keyphrase extraction. Section 5 describes the experimental environment and evaluates the result. Section 6 provides a conclusion inferred from our work and indicates the direction of future research.
The algorithms for keyphrase extraction can be roughly categorized into two type: supervised and unsupervised. Initially, most of the previous extraction methods focused only on selecting the keyphrases within the body of input documents.
Supervised algorithms proposed a binary approach, that is, determine whether a candidate is a keyphrase or not. In general, supervised algorithms extracted multiple features from each candidate and applied machine learning techniques such as naive Bayes [1], support vector machine [2], and conditional random field [3]. The commonly used features were TF-IDF [4], the relative position of the first occurrence of a candidate in the document [1], and whether a candidate appeared in the title or subtitle [2]. However, these features were extracted under the assumption that the candidates appear in the document, so these algorithms are not suitable to evaluate and select latent keyphrases.
In the case of an unsupervised algorithm, a notable approach was to use a type of graph ranking model called, TextRank [5]. The major idea of this approach was that if a phrase had strong relationships with other phrases, it was an important phrase in the document. This algorithm marked the phrases of the document as vertexes and assessed each vertex with their connected links, which was called a co-occurrence relationship. Subsequently, this algorithm was expanded in a variety of ways [6, 7]. However, again, such algorithms only selected the existing phrases from documents as candidate phrases, and latent keyphrases that does not appear in documents have no likelihood of being selected under the set of final keyphrases. In addition, they evaluated the candidates with co-occurrence relationship that assuming candidate appear.
However, to the best of our knowledge, there have been four studies that handle latent keyphrases. Wang et al. [8] considered latent keyphrases as abstractive keyphrases. Their algorithm conjugated single word embeddings as an external knowledge to select semantically similar word embeddings with the document embedding as abstractive keyphrases. Cho et al. [9] extracted primitive words that are important single words in the document and combined the two contextually similar primitive words as latent keyphrases. However, both methods had a limitation on length. They could only select single word keyphrases or twoword keyphrases. Liu et al. [10] tackled the translation problem between title/abstract and body so as to evaluate the importance of a single word and assessed candidates by summing up the importance of their components. However, this algorithm had a problem when it came to overlapping candidates, which means one candidate included in the other candidate. Similarly, Cho and Lee [11] used latent dirichlet allocation (LDA) to evaluate the importance of single words by considering topics of document and assessed candidates by calculating the harmonic mean of their component’s importance. By averaging, this method alleviated the overlapping problem; however, it did not consider the relationship between components during averaging. As a result, the performance deteriorated with a little bit much of candidates.
As described above, previous studies on latent keyphrases had some structural limitations. To handle these problems, this study considers a candidate as one complete element, and not separate words. With the one complete element perspective, we can have varying lengths of candidates and avoid the relationship issue.
In this paper, a latent keyphrase is defined as a keyphrase that does not appear in the document. Most previous works gave little consideration to latent keyphrases. In addition, those studies treated latent keyphrases as missing or inappropriate keyphrases, thereby eliminating the latent keyphrases from the answer set or excluding when evaluating.
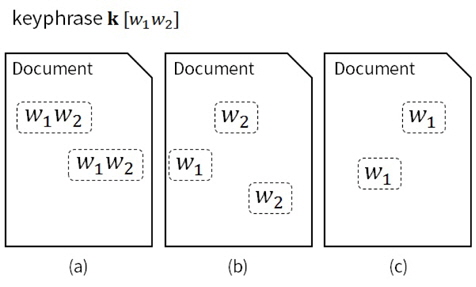
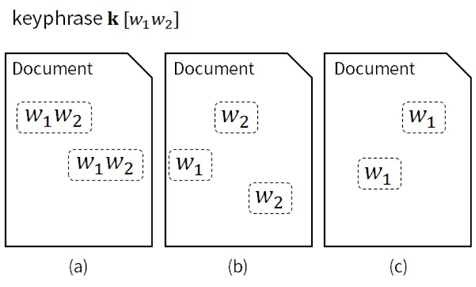
Figure 1 shows three documents that have
Although latent keyphrases do not appear in documents, they can still undertake an important role in text summarization and information retrieval because they link meaningful concepts or contents of documents. Latent keyphrases cover more than one-fourth of the keyphrases in real-world datasets [14–16] and can be utilized in short articles such as SNS, which rarely have explicit keyphrases.
3.2 Deep Belief Networks (DBNs)
Hinton et al. [17] introduced a greedy layer-wise unsupervised learning algorithm for DBNs. This training strategy for deep networks is an important ingredient for effective optimization and training of deep networks. While lower layers of a DBN extract low-level factors from the inputs, the upper layers are considered to represent more abstract concepts that explain the inputs.
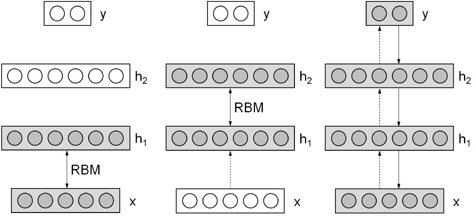
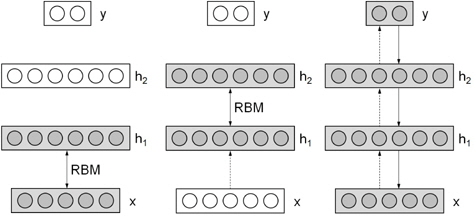
DBNs are pre-trained by multiple restricted boltzmann machine (RBM) layers, and then, fine-tuned, which is similar to back-propagating networks. The entire procedure of training DBNs is illustrated in Figure 2.
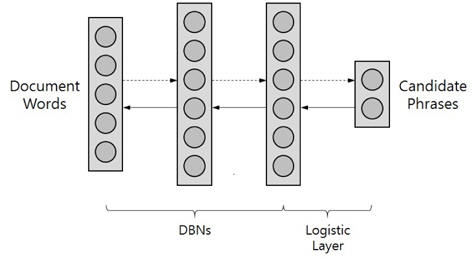
In this section, we introduce our proposed method for latent keyphrase extraction that uses the DBNs and a logistic regression layer. The main idea of this approach is to capture the intrinsic representations of documents and extract eligible latent keyphrases by using them. The inputs of the DBNs are 0 or 1 of bag-of-words representation of the input document and the outputs of the logistic regression layer are candidate phrases. Figure 3 shows a simple structure of the algorithm.
For inputs, we do not use all of the words in a document set. As the corpus is generally composed of the same type of documents, they share words that are commonly used but have meaningless information. These common words, similar to stopwords, may act as noise and disturb the DBNs from capturing the intrinsic representations. Therefore, a number of
The outputs of the logistic regression layer are candidate phrases. The candidate phrase indicates a phrase that has the possibility of becoming a final keyphrase. Therefore, for phrases that do not appear in the document to become final keyphrases, candidate set must have phrases that do not appear in the input document. However, the input document has limited information to provide various form of phrases, so there is a need to utilize other information beyond the input document. In this study, all of the answer keyphrases of the corpus are used as candidate phrases for outputs of the logistic regression layer. And each candidate is considered as one complete element to overcome some structural limitations like varying length of candidates and the relationship issue.
The pre-training process of the DBNs are similar to the method developed by Hinton et al. [17]; however, the finetuning process is slightly different. Because the number of answer keyphrases is less than that of the candidates, we require the DBNs to train more dependent on the answer keyphrases. Therefore, we apply the weighted cost function shown in Eq. (1). This equation is a variation of mean squared error. In Eq. (1),
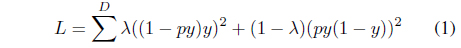
5.1.1 Dataset description
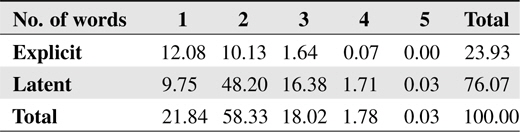
The INSPEC database stores abstracts of journal papers belonging to computer science and information technology fields. Hulth [14] built the dataset using English journal papers from the years 1998 to 2002. Each document has two kinds of keyphrases: controlled keyphrases, which are restricted to a given dictionary, and uncontrolled keyphrases, which are freely assigned by the experts. Because uncontrolled keyphrases have lots of appearing only once keyphrases and these keyphrases cannot be found by supervised method, controlled keyphrases are used for this experiment. The following Table 1 shows the distribution of controlled keyphrases.
[Table 1.] Distribution of controlled keyphrases (%)
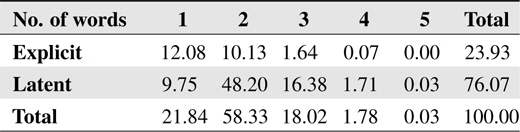
Distribution of controlled keyphrases (%)
The entire dataset has 1,500 training and 500 testing documents; however, we exclude small documents that are composed of less than 70 words. Therefore, 1,165 training and 376 testing documents are used for the experiment. Each document has 3.68 latent keyphrases in average.
5.1.2 Text Preprocessing
The purpose of preprocessing is to normalize the documents. The following modifications are applied to the entire corpus:
• Stopwords such as prepositions, pronouns, and articles are eliminated by referencing the commonly used stopword list [18]. • Only the tagged words NN, NNS, NNP, NNPS and JJ by the Stanford log-linear POS tagger [19] are used by following Hulth [14] that the majority of the keyphrases was noun phrases with adjective or noun modifier. • Porter stemmer [20], which is commonly used in keyphrase extraction field, is used for the experiment.
5.1.3 Parameter Setting
As the DBNs has various parameters to determine, it is very hard to test all the cases of parameter settings and find the best one. Therefore, the guidelines by Hinton [21] are initially adopted for the experiments and later some modifications are done. Finally, the DBNs have three hidden layers with nodes of 1,300 each. The epochs of pre-training and fine-tuning are equally set to 150, learning rate is set to 0.01 and 0.1 each. The batch size is set to 10. Additionally, the number of input and output nodes is set to 9,784 and 1,921, respectively, following the corpus. The number of eliminated common words is 100. Explicit keyphrases are excluded for the valid evaluation after the training step, as the proposed method only targets latent keyphrases. Theano [22] based DBNs for classifying the MNIST digits are modified for the experiments.
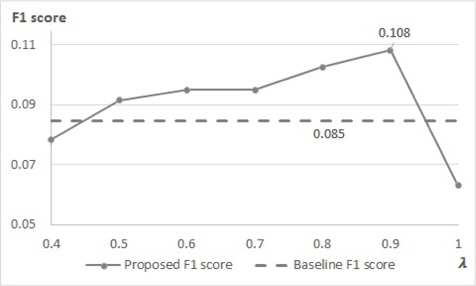
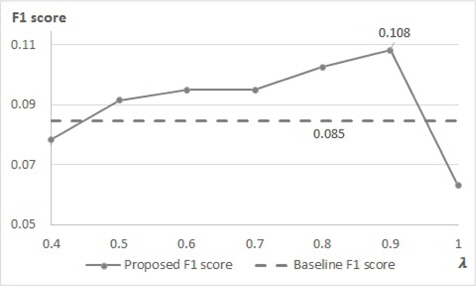
This section gives an evaluation of the proposed method, latent keyphrase extraction. The results are presented on the Figure 4 with the paper of Cho and Lee [11], which is for baseline. They proposed a latent keyphrase extraction method using LDA. The main ideas of the baseline are extracts candidate phrases by referencing neighbor documents and evaluates words of each candidate by considering topic.
Figure 4 shows the result with varying
This study focused on selecting qualified latent keyphrases of documents using DBNs in a supervised manner. The main idea of this approach was to capture the intrinsic representations of documents and extract eligible latent keyphrases by using them. Our experimental results showed that latent keyphrases can be extracted using our proposed method. Additionally, a weighted cost function is suggested to handle the imbalanced environment of latent keyphrases compared to the candidates. A more complex structure of deep learning with word embeddings is presumed to deliver better performance. This can be a part of future work.