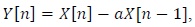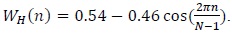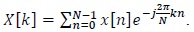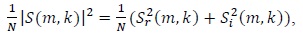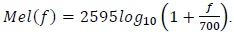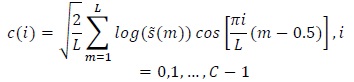In recent times, the demand for speech recognition technology has dramatically increased for easier use of machines. The development of new interfaces performing exactly what humans want to do has been in the spotlight. Scientists first began to explore the possibilities of speech recognition in the 1970s, but because of the algorithm complexity, the development of speech recognition slowed down considerably. Then, in the late 2000s, the development of speech recognition picked up pace because of the use of high-speed computers, improvement in the digital signal process, and a drop in the prices of mass memories.
The mel-frequency cepstrum coefficient (MFCC) method has been widely used for feature extraction in automatic speech recognition (ASR). In the past few decades, the MFCC process was optimized for CPU-based ASR systems [1-5]. Recently, highly optimized MFCC algorithms for the Field-Programmable Gate Array (FPGA), Graphics Processing Unit (GPU), and Advanced RISC Machine (ARM) have been proposed. In particular, highly parallelized MFCC architectures on the FPGA and GPU platforms have been shown to exhibit very low execution times [6-12].
In [6], the MFCC process was implemented on the NVIDIA GTX580 GPU platform, which demonstrates a 90× speedup as compared to the CPU-based system at less than 0.01% in real time. In [10], the MFCC process was implemented on the Xilinx Virtex-II XC2VP100 FPGA platform, which demonstrates a 150× speedup as compared to a CPU-based system at less than 0.09% in real time. In [5,14], researchers attempted to optimize the ASR system on an ARM-based platform, which has been studied extensively because of the considerable increase in the use of mobile devices.
According to previous studies [4-6,10], a highly parallelized and optimized MFCC architecture on the FPGA platform can improve the execution time of an automatic speech recognition (ASR) system as compared to the CPU.
In this paper, we propose a highly parallelized and optimized MFCC architecture implemented on the Xilinx Zynq-7000 system on a chip (SoC) platform and demonstrate that it is considerably faster than the CPU and the ARM processor. A C-based MFCC algorithm is executed on the CPU and the ARM, and the Verilog HDL MFCC algorithm is implemented on FPGA [13].
The rest of this paper is composed of the following four sections: background, design description, analysis and verification of results and performance, and conclusion.
Feature extraction is a process that extracts valid feature parameters from an input speech signal. Even if the same word is spoken, no two speech instances can produce the same speech waveform. The reason for this phenomenon is that the speech waveform includes not only speech information but also the emotional state and tone of the speaker. Therefore, the goal of speech feature extraction is to extract feature parameters that represent speech information. Further, this process is a part of compressing speech signals and modeling the human vocal tract. The feature parameters are devised to represent the phonemes accurately for speech recognition. Linear predictive coefficients (LPCs) and MFCCs are commonly used for the abovementioned feature extraction [3].
LPC feature extraction starts with attempts to predict the value of the current sample from the total sum of a certain number of past samples multiplied with certain coefficients. The coefficients are called LPCs when in terms of the transfer function, the coefficients are formed in an electrode model (all-pole). Each polarity represents the position of the resonance frequency in the frequency domain and the transfer function of the vocal tract in the form of a spectral envelope approximation. For extracting the LPCs, the Levinson–Durbin algorithm was developed; it obtains the autocorrelation for a segment of speech and efficiently computes the LPCs by using a recursive method [1,3].
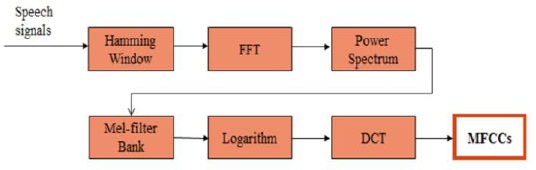
MFCC feature extraction is a cepstral coefficient extraction method that reflects the characteristics of hearing. The aspect of the human ear responding to a frequency change is not linear but in the mel scale, which is similar to the logarithmic scale. According to the mel scale, a low frequency is sensitive to small changes, but the sensitivity decreases with an increase in the frequency. Therefore, MFCC is a correlation method performed during the frequency analysis step of the feature extraction [8].
1) Pre-emphasis
The input speech signal goes through a pre-emphasis filter, which has high-pass filter characteristics. The reason for using this high-pass filter is to model the frequency characteristics of the human external ear and middle ear. The high-pass filter compensates the attenuation by 20 dB/dec of the speech signal from the lips in order to obtain the vocal tract characteristics. Further, the high-pass filter compensates for the fact that the human auditory system is sensitive in the spectral region over 1 kHz. Once the input speech signal goes through a pre-emphasis filter, lowfrequency values decline but high-frequency values get emphasized and boost the vocal tract characteristics. The pre-emphasis filter can be expressed by the following equation:
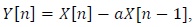
where
2) Frame Blocking and Hamming Windowing
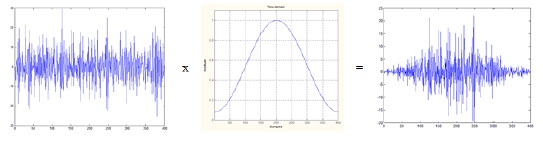
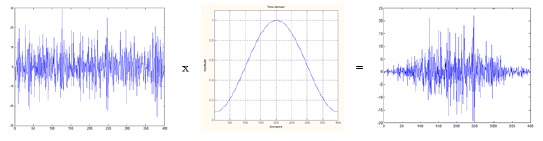
After the pre-emphasis process, the input speech signal is divided into frame blocks of 16 ms in order to extract the feature parameters of the signal. The reason for dividing the input signal into frames of 16 ms is that the human voice has a stationary feature in a 16-ms frame. After dividing the input signal into frames, we extract the frequency feature of each frame. At the edges of each frame, there are discontinuities in the input signal that contain unnecessary information. In order to minimize the discontinuities at the edges of the frames, each frame is multiplied with the window coefficients, as shown in Fig. 1. For the window process, we can use the Hanning, Hamming, Blackman, and Kaiser methods. In this study, we applied the commonly used Hamming window method as follows:
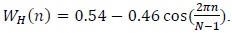
3) Fast Fourier Transform (FFT)
In order to extract the feature parameters of the input speech, the FFT algorithm can be applied to convert the time domain into the frequency domain to figure out the frequency characteristics of the input. In the time domain, a speech signal has discrete non-periodic features. Through a FFT, which converts the time domain into the frequency domain, a speech signal is transformed into a continuous periodic signal. The FFT algorithm is an efficient and fast algorithm for executing a discrete Fourier transform (DFT) and its inverse transform.
The N-point DFT equation of a sequence
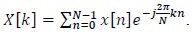
In the above equation, rotates clockwise along the
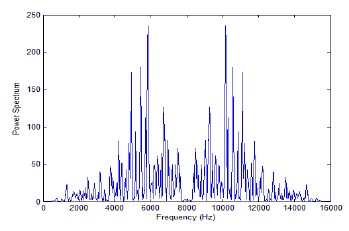
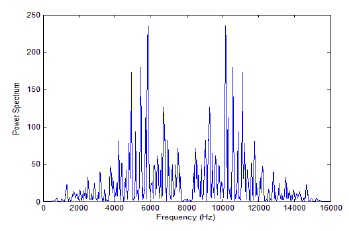
In order to calculate the magnitude of the output of the FFT to emphasize a specific frequency feature, the energy spectrum is estimated. The energy spectrum is found to be real and symmetric (see Fig. 2). Because of its symmetric properties, we can use only half of the output points in the next step, and doing so helps to reduce the computational complexity.
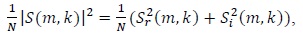
where
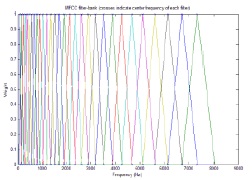
The human ear responds non-linearly to a speech signal. When the speech recognition system performs a non-linear process, it improves the recognition performance. By applying a mel-filter bank, we can obtain a non-linear frequency resolution. The mel-filter bank method is widely used in the speech recognition process.
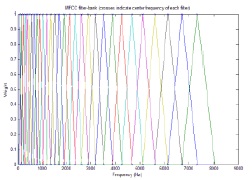
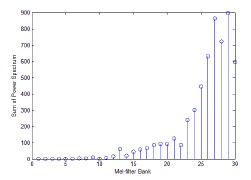
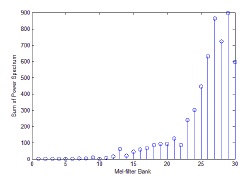
As shown in Fig. 3, the mel-filter bank has a triangular shape and is applied to the output of the energy spectrum. The number of items in a mel-filter bank set is normally between 20 and 40. In this study, we use 19 mel-filter banks. These mel-filter banks are placed on the frequency axis on the basis of the mel scale, which is defined below. In order to calculate the energy of each mel-filter bank, the output of the energy spectrum is multiplied by the mel-filter bank coefficients and accumulated. By applying the mel-filter bank, we obtain 30 mel-filtered energy coefficients to ensure useful signal energy, as shown in Fig. 4.
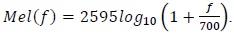
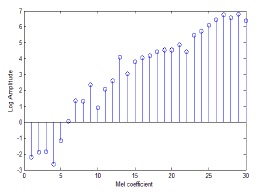
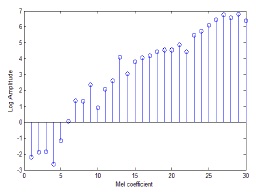
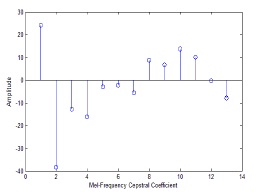
Mel cepstrum is the final output of the MFCC process. The logarithm and discrete cosine transform (DCT) of the mel-filter bank energy are computed to extract the required minimum information. The reason why the log value of the mel-filter energy is taken is that the human ear responds to the loudness of the sound as a function of the logarithm (see Fig. 5). In the next step, DCT is applied to the log filter bank parameters in order to extract the appropriate features. The DCT equation is defined as follows:
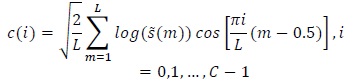
where
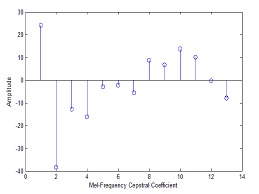
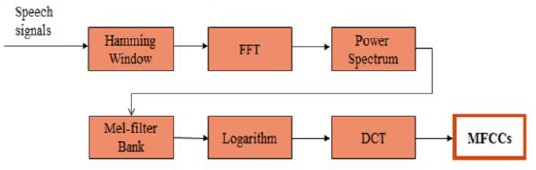
Eventually, the MFFCs are obtained through all the steps, as shown in Fig. 7.
In this study, the MFCC architecture has been designed to be parallelized and optimized on the Xilinx Zynq-7000 SoC platform in order to speed up the real-time speech recognition. Further, in order to improve the execution time of the MFCC process, a well-designed FFT algorithm was developed as part of Carnegie Mellon University (CMU)’s Spiral Project [15]. The C-based MFCC architecture for the CPU and ARM experiment was developed as part of Massachusetts Institute of Technology (MIT)’s feature extraction project [13].
In order to simulate and implement the feature extraction process on CPU, ARM, and FPGA, MATLAB v7.11 (R2020b), Microsoft Visual Studio Express 2013, and Xilinx Vivado Design Suite (v2013.2), Integrated Software Environment (ISE), Software Development Kit (SDK), and High-Level Synthesis (HLS) tools were employed.
The objective of this study is to determine the improvement of the speech recognition system in terms of speed by implementing a parallel MFCC process on FPGAs to perform the feature extraction process.
>
A. MFCC Simulation on CPU and ARM
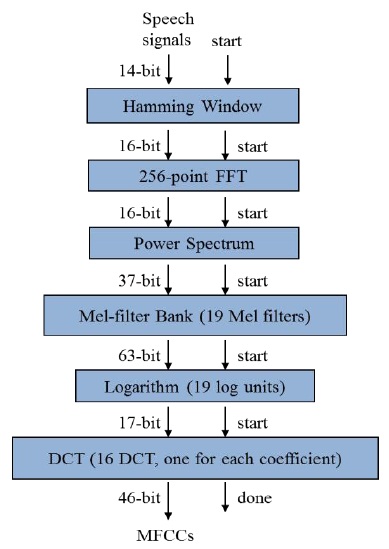
As mentioned above, the C-based MFCC architecture was developed as part of MIT’s feature extraction project. For this experiment, a 6-s Wall Street Journal wave file was used as the MFCC input voice. The sample frequency of the speech signal was 16000 Hz. In order to extract the frequency feature, the speech signal was divided into 16-ms samples. When the sample frequency was 16000 Hz, we obtained 256 16-ms samples (0.016 s × 16000 Hz = 256 samples). The 16-ms signal block had a 10-ms overlap with the next 16-ms signal block because the signal overlap was required to recover the discontinuity of the signal. However, when the overlap was applied to the signal, signal distortion occurred. To prevent the signal distortion due to the signal overlap, the hamming window module was applied. In order to apply the MFCC process to the 6-s Wall Street Journal waveform speech signal with the signal overlap, the speech signal was divided into 1025 frames (6 s × 16000 Hz = 104711 samples, 0.016 s × 16000 Hz = 256 samples, (1 + ((104711 – 256)/100) = 1044.55)). The CPU experiment was conducted using Microsoft Visual Studio, and the ARM experiment was performed using Xilinx SDK.
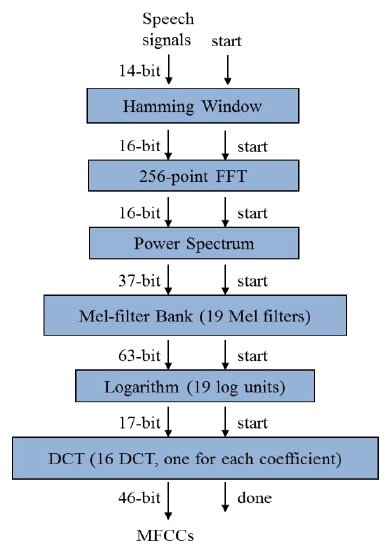
The MFCC process was implemented in the Verilog hardware description language (HDL); it included the hamming window, FFT, power spectrum, mel-filter, logarithm, and DCT processes. The FPGA experiment was executed in the Xilinx ISE tool.
Fig. 8 describes the MFCC process. Overall, the MFCC process consisted of 39 distinct modules (1 hamming window, 1 FFT, 1 power convertor, 19 mel-filters, 1 log calculator, and 16 DCTs) and 57 total module instances (1 hamming window, 1 FFT, 1 power convertor, 19 mel-filters, 19 log calculators, and 16 DCTs). As mentioned before, in order to improve the execution time of the MFCC process, a well-designed 16-bit 256-point FFT algorithm was developed as part of CMU’s Spiral Project. For a highly parallelized and optimized MFCC structure, the mel-filter, log calculator, and DCT modules were implemented as a parallel structure.
IV. ANALYSIS AND VERIFICATION OF RESULTS AND PERFORMANCE
We verified the speed improvement of the MFCC process on FPGA as compared to the CPU and ARM process. For the test, the 6-s Wall Street Journal wave file was used, which consisted of 1025 frames. The result was analyzed by comparing the MFCC execution time of one frame.
The experiment uses Intel Core i5 M 480 CPU at 2.67 GHz, Dual ARM Cortex-A9 MPCore at 667 MHz, and Zynq-7000 FPGA at 111 MHz. In order to simulate and evaluate the MFCC process time on the CPU, ARM, and FPGA, we used Microsoft Visual Studio Express 2013 for the CPU evaluation, Xilinx SDK v2013.4 for the ARM evaluation, and the Xilinx ISE v14.7 tool for the FPGA evaluation.
>
B. Analysis of Feature Extraction
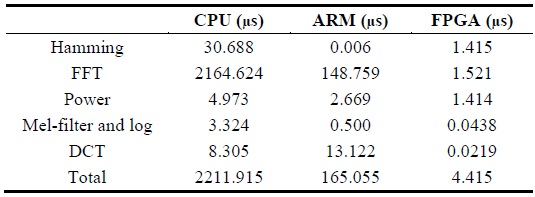
For the analysis, the execution time per frame in the MFCC process was compared among the CPU, ARM, and FPGA. The MFCC process was divided into the following five steps: hamming window, 256-point FFT, power convertor, mel-filter and log convertor, and DCT.
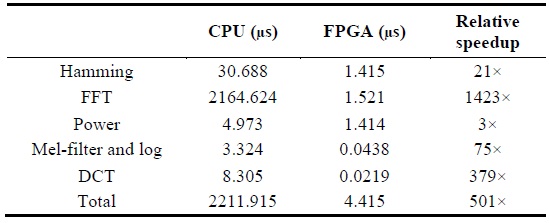
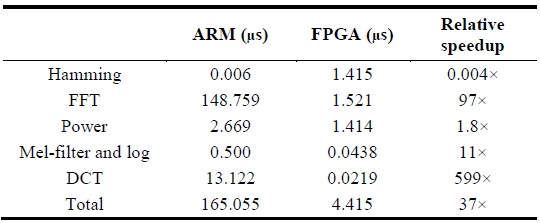
Table 1 denotes the execution time on each platform in micro-seconds. Tables 2 and 3 describe the relative speedup of the MFCC process on FPGA compared to that on the CPU and ARM platforms.
[Table 1.] Average elapsed time per frame in MFCC process
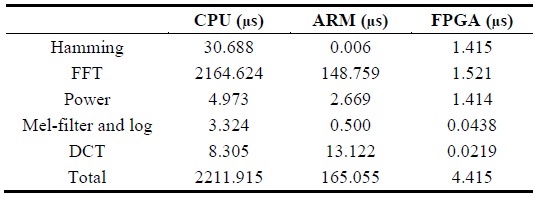
Average elapsed time per frame in MFCC process
[Table 2.] Relative speedup of MFCC process compared to CPU
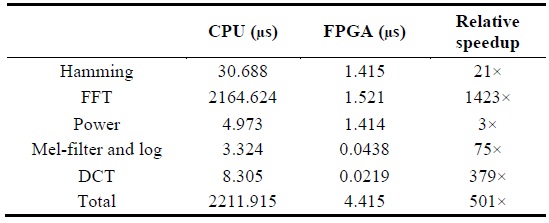
Relative speedup of MFCC process compared to CPU
[Table 3.] Relative speedup of MFCC process compared to CPU
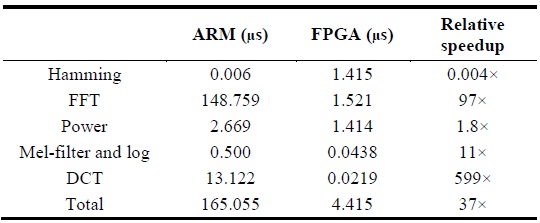
Relative speedup of MFCC process compared to CPU
Through the analysis, we confirmed that the FPGA platform is approximately 500× faster than a sequential CPU platform and 60× faster than a sequential ARM platform, and verified that a highly parallelized and optimized MFCC architecture on the FPGA platform significantly improves the execution time of an ASR system as compared to the CPU and ARM platforms. In order to improve the execution time of the MFCC process on FPGA, a well-designed 256-point FFT algorithm was developed as part of CMU’s Spiral Project [15]. The C-based MFCC architecture for the CPU and ARM platforms was developed as part of MIT’s feature extraction project [6].
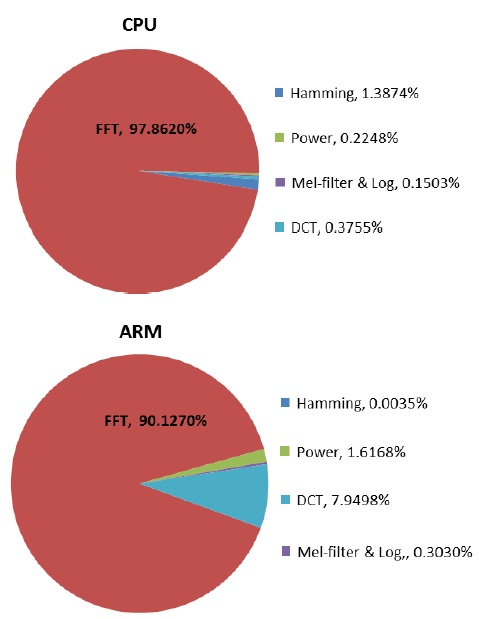
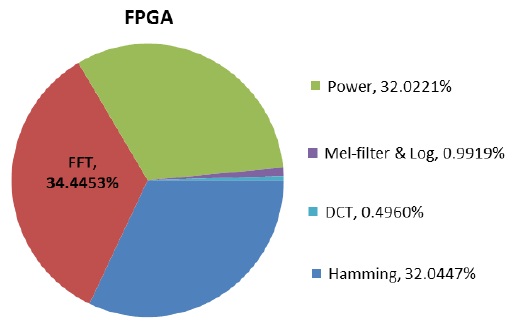
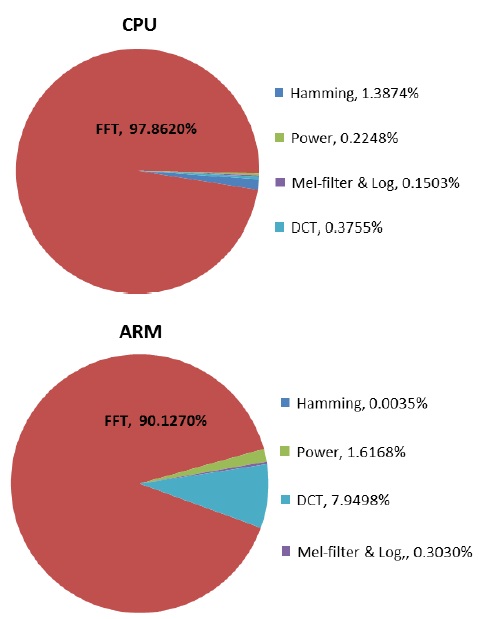
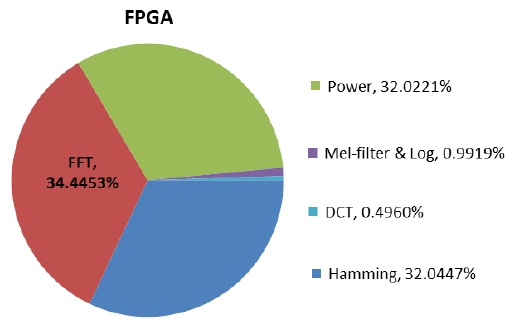
As seen in Fig. 9, the FFT process consumes a large amount of computational time on the CPU and ARM. CPU and ARM consume 97.8% and 90.1% of the execution time, respectively, in the MFCC process. On the other hand, as shown in Fig. 10, on the FPGA platform, the FFT process consumes 34.4% of the execution time in the MFCC process and significantly reduces the computational time compared to CPU and ARM.
The objective of this study was to determine the improvement of the speech recognition system in terms of speed by implementing a parallel feature extraction process on FPGA for feature extraction. The Xilinx Zynq-7000 SoC platform was used for demonstrating the MFCC implementation for the feature extraction process. We confirmed that the FPGA platform is approximately 500× faster than a sequential CPU platform and 60× faster than a sequential ARM platform, and verified that a highly parallelized and optimized MFCC architecture on the FPGA platform significantly improves the execution time of an ASR system compared to the CPU and ARM platforms.