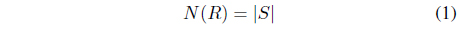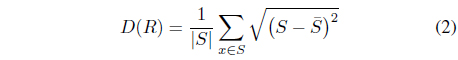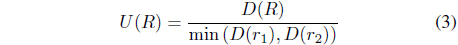Recently, the number of music clips encountered in daily life has grown rapidly with social network services for music, giving popularity to music categorization based on music tags such as genre and theme. In addition to conventional tags, many people often categorize music by mood or expressed emotions, ranging from happiness to sadness. This is why music emotion recognition (MER) has gained popularity and has been applied to music information retrieval for improving the effectiveness of several applications that search for and recommend music [1]. The goal of MER is to identify the intended or perceived music emotion of a given music piece [2–8]. The process of MER can be described as 1) annotating music emotions, 2) extracting acoustic features, and 3) recognizing music emotions [9]. One aim of this paper is to discuss the issues related to each process and their effects on MER performance by reviewing different MER techniques.
However, the limitation of music tags is the ambiguity that comes from the fact that a single music tag covers too many subcategories [4]. To overcome this, users may use multiple tags simultaneously to specify their target music clips more precisely. Because this also increases the number of possible tags to be considered by users, the recommendation system may allow or suggest a proper subset of tag combinations for users. In this paper, we propose a novel technique to rank the proper tag combinations based on acoustic similarity of music clips.
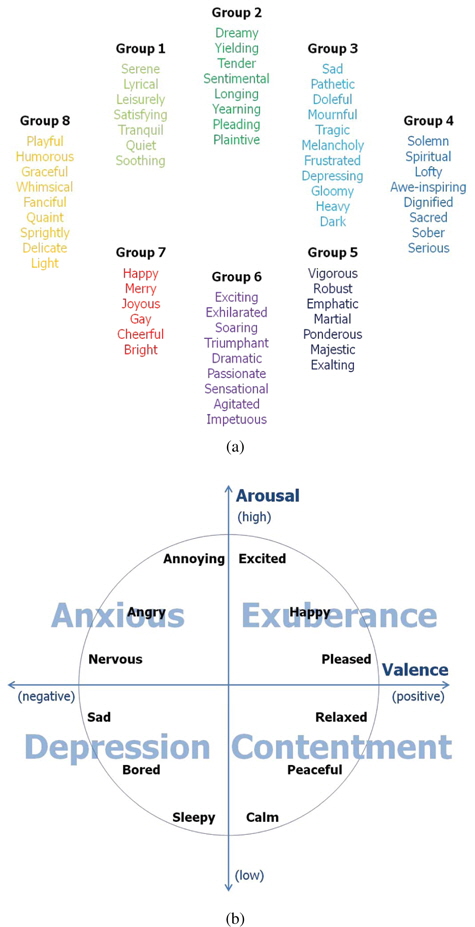
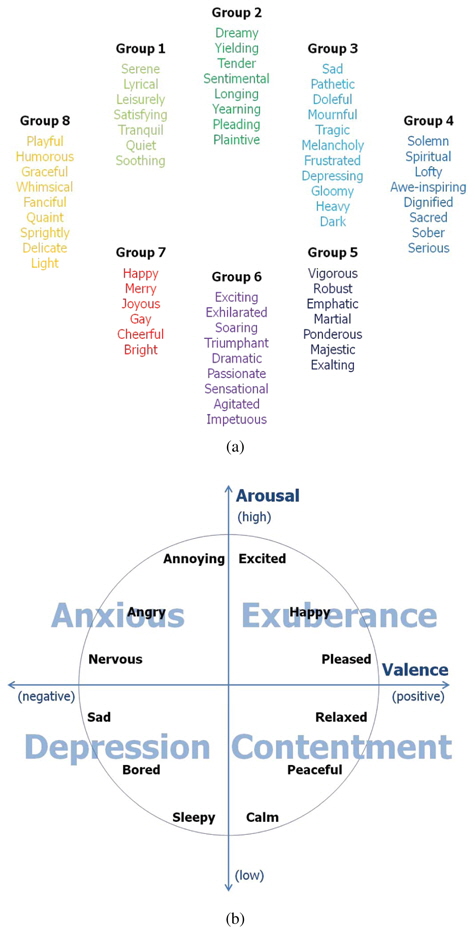
One of the most important issues of MER is how to describe music emotions. In early psychological research, Hevner proposed an adjective checklist that was divided into eight mood clusters to represent music emotions [3]. This study was performed with ordinary people from several cultural backgrounds based on adjectives that were selected by subjects. As shown in Figure 1(a), Hevner summarized the words used by the subjects to an impressive 66 adjectives, and these words were further extended [10]. Because of its intuitive representation, there are a series of studies using these emotional adjectives to represent music emotions [3].
Instead of describing music emotions as a set of adjectives, Thayer proposed a circumflex model of music emotion by adapting a basic motion model to music using a two-dimensional energy-stress emotion model [4]; this dimensional approach indicates two underlying stimuli involved in music emotion responses (Figure 1(b)). Based on the level of stress and energy, Thayer’s emotional model (TEM) divides music emotions into four clusters (each in one quadrant): contentment, depression, exuberance, and anxiety. Although a considerable number of works have been conducted based on TEM [11, 12], the limitation of TEM is that it is not intuitive to untrained subjects. To represent music emotions using this model, the subject must understand the role of each axis. Thus, most research using TEM has used a small number of musical experts with substantial knowledge about musicology and psychology. As a result, it may not be scalable to the real-world music corpus.
In MER research, music emotions are often divided into two categories: intended emotion and personalized emotion [1]. Intended emotion (IE) is usually described by the performer or songwriter, primarily in the way they express their feelings. When a listener hears those music clips, they may evoke certain feelings based on cultural agreement and personal experience, namely, personalized emotion (PE). Although most current MER research focuses on IE, a few studies have attempted to directly attack the difficulty involving PE; these studies have attempted to solve or avoid the subjectivity problem associated with cultural agreement or modeling the individuality of listeners [1, 13]. However, this also reduces the coverage of the MER system; for example, the MER system may specialize into western classical music [5]. Because of the subjective nature of music emotion, it is difficult to obtain a general response to the same music clip [13]. Typically, the responses of music emotion are obtained by two approaches: one is annotation by music experts, and the other is annotation by crowdsourcing [14]. Annotation by experts refers to emotional responses obtained by experts who have been trained in musicology. Therefore, it is difficult to recruit a large number of such experts. In contrast, annotation by crowdsourcing refers to emotional response collected from social tags, resulting in difficult quality control of the gathered responses.
2.2 Extracting Acoustic Features
Different emotional expressions are usually associated with different patterns of acoustic music signals [2]. It has been recognized that some acoustic features extracted from music signals are typically relevant to music emotions: dynamics, timbre, harmony, register, rhythm, and articulation [9]. It is noteworthy that although the exact words and symbols are different, such as rhythm versus tempo and intensity versus sound level, the meanings of these concepts are very similar. Here, we briefly explain the basic principle of how to extract those features. Timbral features are based on a spectrogram with statistically divided stationary frames. Some features are developed for timbre analysis in current literature, such as Mel-frequency cepstral coefficients, short-time energy, and zero-crossing rate [16]. Moreover, feature extraction methods specialized in music signal analysis have also been proposed [3]. In addition to signal-level extractions, high-level musical properties such as rhythm, harmony, and articulation may contribute to expressing music emotions. These musical properties are extracted by using acoustic feature recognizers that analyze music signals based on musical theories [2, 12, 17]. For example, harmony features are extracted from a viewpoint of spectrogram roughness, harmonic change, key clarity, and majorness. To extract these acoustic features, readers may use acoustic feature extraction tools such as MIR-Toolbox [16]. These tools have demonstrated effectiveness in several MER studies [4, 5, 8].
Several signal transforming techniques have been proposed to handle acoustic waveform inputs of music clips. Although individual acoustic features have been tested and are shown to have emotion representation power, it is known that optimal MER performance can be achieved by using them in combination. Therefore, the issues of how to select the optimal acoustic feature subset should be addressed carefully because too many acoustic features can also degrade the performance of MER [20].
In the psychological domain, two words, mood and emotion, have different meanings [6]; emotion refers to a strong response of a relatively short duration, whereas mood indicates a longterm response. Most MER research has assumed that if a music clip is segmented in statistically stable frames, then this music clip expresses a unique emotion [19]. For each music segment in each frame, the MER system was trained to detect the emotion type in each segment. In contrast, an MER system is able to assume that music emotion is continuously changing according to time [10]. This approach expresses the emotional content of a music clip as a function of time-varying musical features [5].
A second issue that should be considered in MER systems is the ambiguous nature of music emotion. It is easily understood that people may use multiple adjectives to describe the emotion of a music clip. To solve this problem, MER systems employed fuzzy or multi-label schemes [2, 8]. However, it can be claimed that even when multiple adjectives are allowed to describe music emotion, the categorical taxonomy of emotion is still inherently ambiguous [4]. For example, the first quadrant of TEM contains emotional adjectives such as excited, happy, and pleased, which are different in nature. This ambiguity confuses the subjects in the subjective test and confuses the users when retrieving a music piece according to their emotional states. An alternative is to view the emotion plane as a continuous space and recognize each point of the plane as an emotional state.
The last issue originated from the prediction difficulty for each stimulus of music emotion. For example, an MER system may take the form of a hierarchical structure [6]; according to empirical results, arousal (or energy) in TEM is more computationally tractable and can be estimated using simple amplitudebased acoustic features. In the experiments, a hierarchical MER system outperformed its non-hierarchical variant. Moreover, support vector machines (SVMs) were employed to detect complicated relations between the distribution of music features and the music emotion [20]. Based on the empirical tests, they reported that arousal of music emotion was predicted quite accurately (95%), whereas the overall prediction accuracy was degraded owing to the difficulty of predicting valence. Moreover, it has been found generally that valence is much more difficult to predict than arousal [13]; based on the comparison between group-wise experiments and individual experiments, it has been observed that the difference for valence is larger than that for arousal.
3. Tag Combinations for Recommendation
To describe our proposed method for discovering proper tag combinations, we first introduce some mathematical definitions. Let
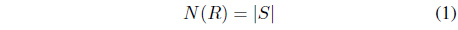
where | · | represents the cardinality of the given set. After all possible tag combinations are identified, tag combinations with higher
Because our goal for combining tags is to specify music clips in more detail, the acoustic similarity of music clips annotated by multiple tags should be larger than that of music clips annotated by each tag. In this paper, we propose a new ranking method for tag combinations based on the acoustic similarity of music clips. Let
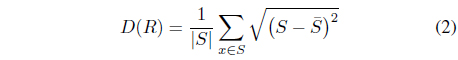
where is the centroid of music clips in
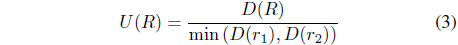
where
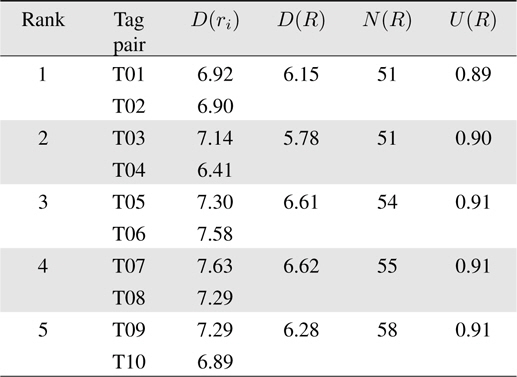
To verify the effectiveness of the proposed method, we employed a CAL500 dataset that is well known in the music information retrieval community [22]; the CAL500 dataset is composed of 502 music clips, 68 acoustic features, and 174 corresponding tags that are annotated by 66 undergraduate students of California University in the USA. Among 15,000 possible tag pairs, 14,000 tag pairs were filtered at the first step because they covered less than 10% of music clips. Table 1 shows the top five tag pairs selected by our ranking method.
[Table 1.] Top five tag pairs with highest utility value
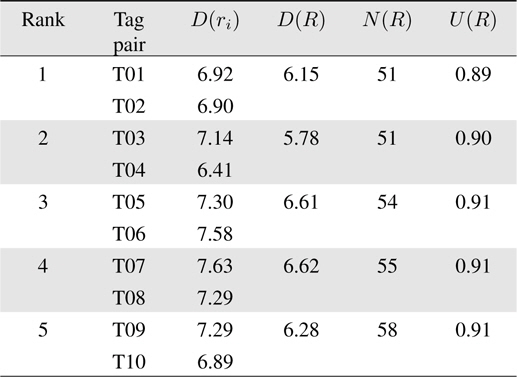
Top five tag pairs with highest utility value
Table 1 contains six columns; each column represents the rank of each tag pair, the name of each tag in the tag pair, the acoustic dissimilarity value of each tag, the acoustic dissimilarity value of the tag pair, the number of music clips, and the utility value of the tag pair. For example, the best tag pair is composed of (Not-Emotion-Calming-Soothing, Usage-Driving) because it reduces the acoustic dissimilarity of music clips by approximately 11% compared to that of music clips annotated with (Usage-Driving) alone.
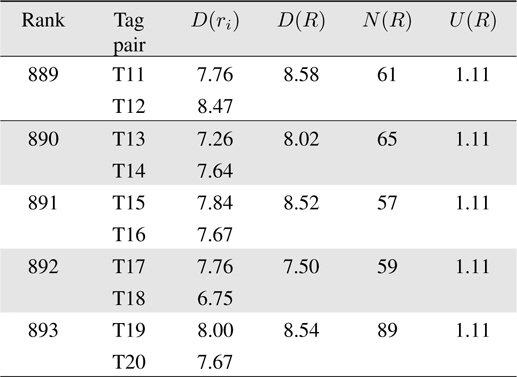
Table 2 shows the characteristics of five low-ranked tag pairs. Because
[Table 2.] Top five tag pairs with highest utility value
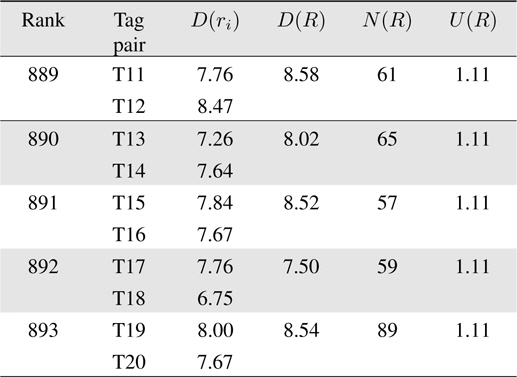
Top five tag pairs with highest utility value
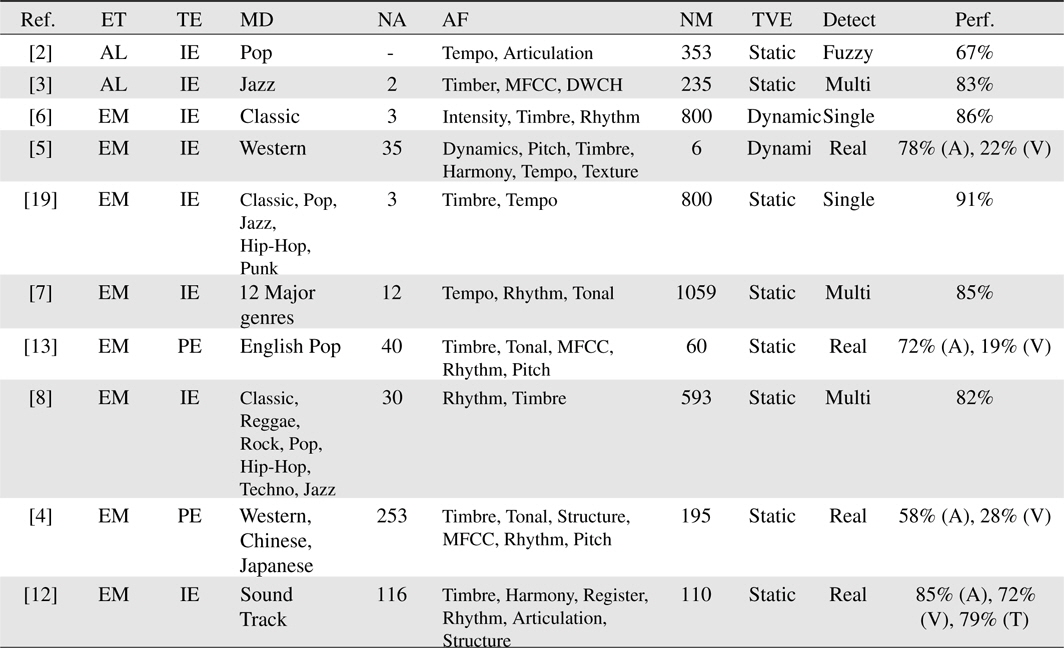
In this paper, many techniques involved in MER were presented. Despite the subject nature of music emotion and ambiguity in the emotional state, there were many favorable achievements in this domain. As shown in Table 3, a common effort of MER research was invested to solve the ambiguity in music emotions using music emotion models and detecting real valued emotional states. Moreover, to enlarge the applicability of MER systems, research tends to recognize a wide range of music. To recognize a wide range of music, researchers have focused on more relevant and novel acoustic features and incorporated more features into their research.
[Table 3.] Summarization of experimental setup and music emotion recognition results
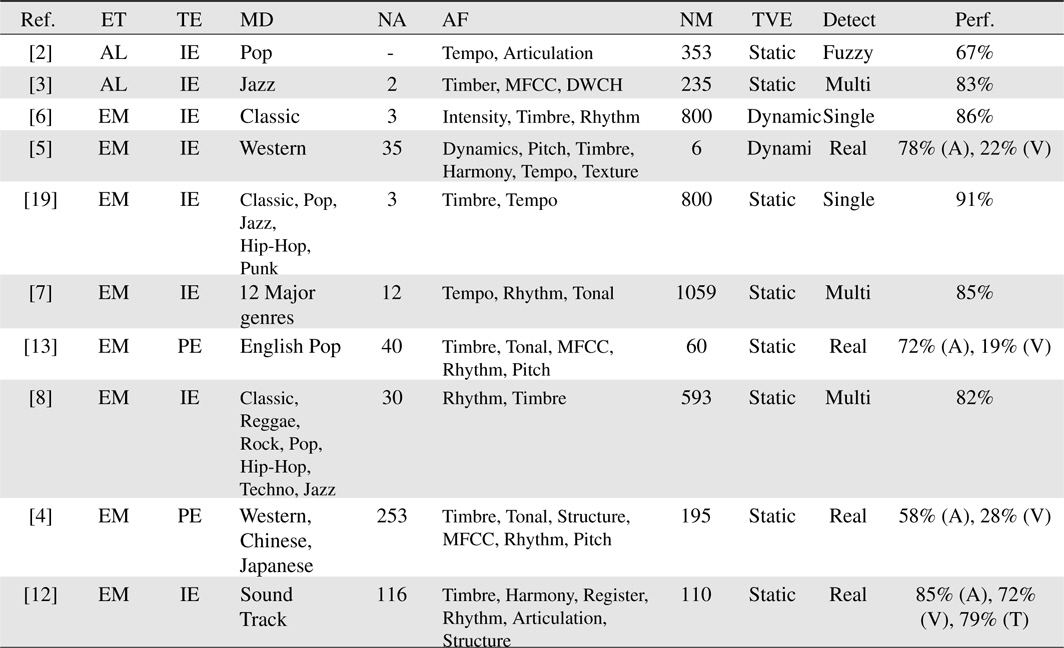
Summarization of experimental setup and music emotion recognition results
Although music emotion research has shown how to solve the intrinsic problems in the MER domain, such as subjectivity of music emotion, time-varying emotion, and ambiguous problems, there are some limitations due to unsolved problems. Extensive and fruitful efforts have been made in recent years in the disambiguation of music emotions by emotion state modeling. In general, we observed that many researchers have successfully used TEM. This model eliminates the ambiguity in music emotion by sacrificing the intrinsic use of adjectives. For example, if we attempt to model emotion through the dimensional model, then the problem of how to exactly measure the quantity of valence or arousal arises. Thus, there still needs to be an advancement of the emotional model or the development of a new emotional model for describing and annotating music emotion. In this case, a hybrid model that combines adjectives on emotional space may be an attractive solution.
Moreover, we proposed a new method of ranking music tag combinations for music categorization. Experimental results demonstrated that our proposed method is able to rank the proper tag combinations based on acoustic similarity of music clips and filter tag combinations which leads to acoustically inconsistent music clips.