IT technology development and smart appliances due to the increased use of a lot of data on production and consumption has become in the internet. Because this is why importance of information retrieval technology although the growing becoming aware of the difficult techniques to access the required of lot a background knowledge on information retrieval technology. However, the Lucene due to emerge provide to background can implement on search engine by using the Lucene of lack background knowledge for search technology.
In this paper, suggest to implement on search engine by using the developed a framework on Lucene-based. Suggest a frameworks are use in the search engines on have guarantee in server environment support on distributed processing and distributed storage, and high availability by using the Hadoop and Nutch, Solr, Zookeeper.
검색엔진은 웹에 존재하는 사이트나 문서들을 검색 하기 위한 프로그램이다[1]. 검색엔진은 기본적으로 웹사이트나 문서를 크롤링하는 웹 크롤링과 크롤링한 데이터를 인덱싱 작업을 담당하는 인덱서, 마지막으로 사용자 검색요구에 맞게 인덱싱된 데이터와 비교해주는 검색기로 분류된다[2,3]. 검색엔진을 구현하기 위해서는 많은 배경 지식을 갖춘 전문 인력과 많은 개발 비용이 소모되어 IT 선도 기업이나 전문기관의 소유물로 인식되었다. 하지만 Lucene 등장으로 인해 배경 지식 없이 소수의 개발자도 검색엔진을 구현할 수 있는 배경을 마련하였다.
본 논문에서는 Lucene 기반으로 개발된 웹 크롤러인 Nutch와 Solr, Tomcat, Zookeeper, Hadoop을 사용하여 검색 엔진을 구현하는 방안에 대해 제안한다. 제안하는 검색엔진은 기존의 고가의 서버를 요구하는 검색엔진과 달리 다수의 저가 서버나 일반 PC 등을 사용하여 검색엔진을 구현할 수 있고, 사용 용도에 따라 단일 환경과 분산 환경에서 크롤링하고 검색할 수 있는 검색엔진이다.
2005년 Nutch 오픈 소스 검색 엔진의 분산 확장 문제에서 시작한 Hadoop은 2006년 야후(Yahoo)의 전폭 적인 지원과 많은 개발자의 참여로 인해 개발되었다[4]. Hadoop은 2003년 구글(Google)의 구글 파일 시스템 논문(The Google File System)에서 영감을 얻어 자바 언어로 개발된 프레임워크이며 HDFS(Hadoop Distributed File System)와 MapReduce로 구성되어 있다[5]. Hadoop은 HBase나 Spark, Storm 같은 다른 프레임워크들과 연동하여 사용할 수 있다.
Hadoop 2는 Hadoop 1이 가지고 있던 설계 구조와 노드 병목 현상, 제한된 네임노드에서 발생하던 문제들을 개선하기 위해 개발되었다[6]. Hadoop 2를 YARN(Yet Another Resource Negotiator)이라고 불리며 잡 트래커의 주요 기능인 자원 관리와 잡 생명주기 관리를 새로운 컴포넌트로 분리하였다.
Lucene 기반으로 개발된 Nutch는 웹사이트나 웹 문서를 크롤링하는 오픈 소스 웹 크롤러 소프트웨어이다[7]. Nutch는 특정 도메인에서 크롤러를 대상으로 하는 정규 표현식 기반의 도메인 필터를 가지고 있으며 동적 URL 필터와 내용, 형식 등의 다른 종류와 다양한 플러 그를 지원한다. 그리고 정규식과 지명 사전에 따라 새로운 정보들을 추출한다.
Nutch의 큰 이점은 투명성과 이해하기 쉽고 확장성이 뛰어나다. 또한, Nutch는 검색엔진에서 가장 주요한 부분인 순위 알고리즘이나 구조들이 공개되어 있어 다른 검색엔진에 비해 쉽게 확장할 수 있다.
Lucene 기반으로 개발된 Solr는 검색엔진으로 단독 서버 형태로 동작한다[8]. 그리고 다양한 API와 플러그인을 할 수 있어 확장성이 뛰어나다. 문서들은 HTTP를 사용하여 XML이나 JSON, CSV, 바이너리 형태 등으로 인덱싱 요청을 할 수 있다. 또한, 검색 역시 HTTP GET으로 요청할 수 있다.
Solr는 텍스트 위주의 검색 방식을 지향하며 높은 웹트래픽을 감당할 수 있도록 최적화를 할 수 있다. 또한, 표준 인터페이스를 제공하며 선형 확장이나 인덱스를 자동 복제하고 자동으로 복구할 수 있다. 그리고 Solr 환경 설정은 XML 파일 기반으로 설정하여 유연하고 최적화를 할 수 있다[9].
Zookeeper는 분산 코디네이터 서비스를 제공하는 프레임워크이다[10]. 분산 환경에서는 락이나 네이밍 서비스, 클러스터 등을 쉽게 구현할 수 있는 기능을 제공 해야 하며 다양한 운영상황과 장애 발생 시 피해를 최소해 해야 한다. Zookeeper는 이러한 문제들을 쉽게 해결해주는 역할을 하고 분산 처리 시스템에서 일과적으로 관리해주는 시스템이다. 주요 용도는 분산 락킹과 분산 시스템의 통합 설정 관리, 네이밍 서비스, 분산 시스템의 단일 스퀸스, 활동과 대기 관리, 클러스터의 맴버쉽을 관리한다. 또한, 분산 환경에서 각 머신들의 상태들과 자원을 모니터링 할 수 있다[11].
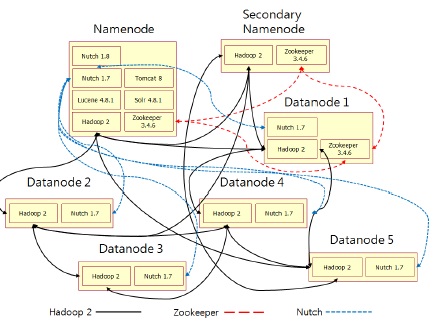
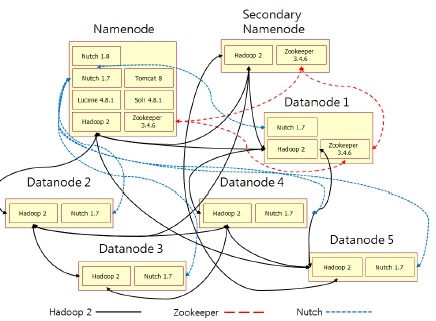
검색엔진에는 일반 PC 7대를 사용하여 네임노드와 보조 네임노드, 데이터 노드로 구현하였다. 제안하는 검색엔진의 구조는 그림 1과 같다.
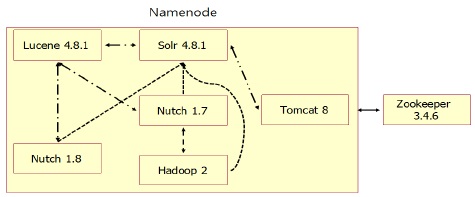
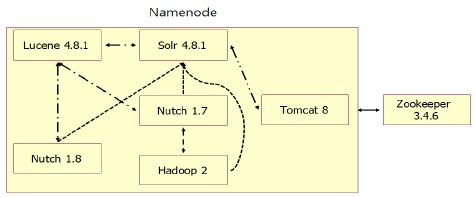
네임노드는 Nutch와 Solr, Tomcat, Lucene을 사용하여 검색엔진을 구현하고 Hadoop과 Zookeeper를 사용 하여 분산 환경을 구축하였다. 보조 네임노드는 네임노드가 효과적으로 운영할 수 있게 보조하며 데이터 노드는 분산 처리와 분산 저장을 담당한다. 네임노드의 주요 구성은 그림 2와 같다.
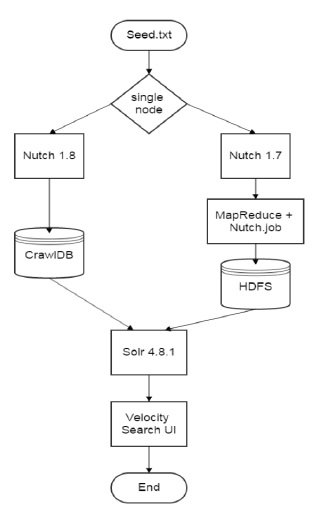
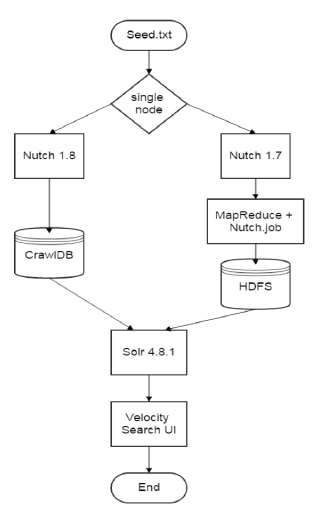
네임노드에는 단일 노드로 크롤링하는 Nutch와 Hadoop 환경에서 분산 노드로 크롤링하는 Nutch로 구성되어 있다. 그리고 인덱싱을 담당하는 Solr와 웹서버로 사용하는 Tomcat, 분산 처리와 분산 저장을 담당하는 Hadoop, 고가용성을 위한 Zookeeper로 구성된다. 단일 노드와 분산 노드로 실행되는 Nutch의 작업 순서도는 그림 3과 같다.
실행 명령어에 의해 단일 노드와 분산 노드로 분류되어 크롤링이 실행되며 크롤링된 데이터는 Solr에서 인덱싱 작업을 진행한다. 사용자는 Solr에 내포된 Velocity Search UI를 사용하여 검색할 수 있다.
검색엔진에 사용된 운영체제는 Ubuntu 12.04를 사용하고 네임노드와 보조네임노드, 데이터 노드에 사용된 하드웨어 사양은 다음과 같다.
검색엔진에 사용된 프레임워크들은 자바 기반으로 동작하기 때문에 JVM 환경을 지원해야 한다. 논문에서는 Oracle JDK 7를 사용하고 리눅스 환경 변수로 사용되는 “.bashrc” 파일에 JVM과 각각의 프레임워크들을 환경 설정하였다.
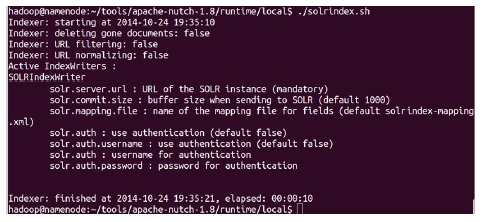
분산 노드로 운영하는 검색엔진은 SSH 기반으로 다른 노드들과 통신하여 데이터들을 분산 처리한 뒤 저장 한다. SSH은 “/etc/hosts” 파일에 PC들의 IP 주소와 호스트명을 환경 설정한다. 그리고 각각의 노드에서 SSH 키를 생성한 뒤 네임노드의 “authorized_keys”에 노드들의 공개키를 통합하고 재배포하여 노드 간에는 비밀 번호 없이 접속할 수 있도록 설정한다. 그림 4는 SSH를 사용하여 각각의 노드로 환경 설정 파일을 배포하는 화면이다.
정상적으로 분산 노드가 실행되는지 확인하는 방법은 “jps” 명령어를 사용하여 확인할 수 있다.
Zookeeper는 “zoo.cfg” 파일에 환경 변수를 설정한 다. 그리고 각각의 노드로 배포하고 서버명에 맞게 “myid” 파일에 식별 번호를 부여한다.
Nutch는 “nutch-site.xml” 파일에 환경 변수를 설정 하고 Ant를 사용하여 빌드를 한다. 빌드가 성공적으로 완료되면 “Runtime” 폴더가 생성되는데 생성된 폴더 안에 “urls” 폴더를 생성하고 “seed.txt”를 생성하여 검색하고자 하는 웹 사이트의 URL을 설정한다. 그리고 Nutch와 Solr 연동을 위해서는 Nutch의 “schema.xml” 파일을 Solr의 “schema.xml” 파일로 복사한 뒤 환경 변수를 설정한다.
Solr와 Tomcat의 연동하기 위해서는 Solr의 “Solr.war” 파일을 Tomcat의 “/webapps/” 폴더 안에 복사한 뒤 압축을 해제한다. 그리고 Tomcat의 “tomcat-user.xml” 파일과 “web.xml” 파일에 환경 변수를 설정한다.
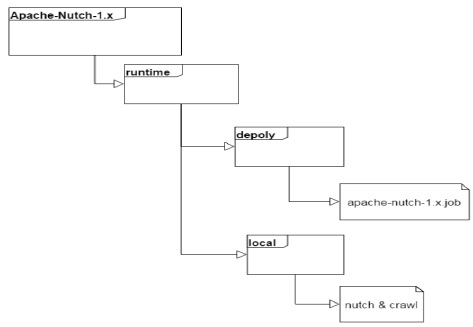
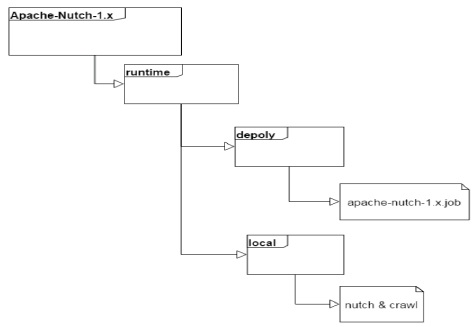
검색엔진에서 웹 크롤링을 담당하는 Nutch의 디렉토리 구조는 그림 5와 같다.
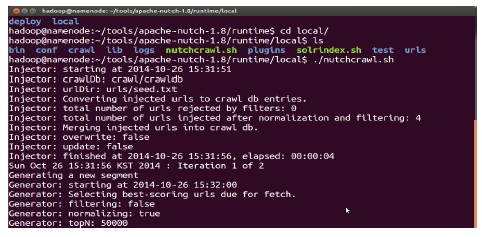
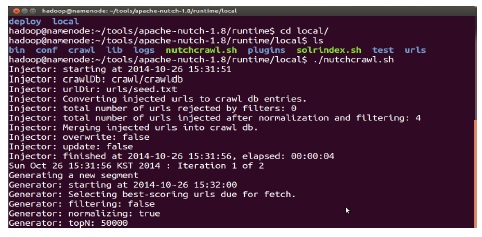
단일 노드로 실행할 때는 local 폴더 안에서 진행되고 분산 노드로 실행할 때는 depoly 폴더에서 진행된다. 명령어는 두 가지로 분류되어 용도에 맞게 사용할 수 있다.
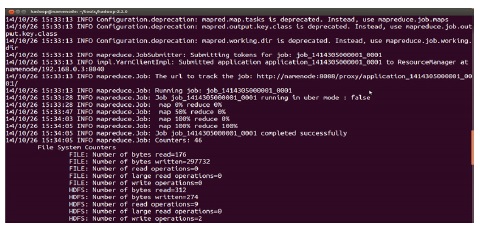
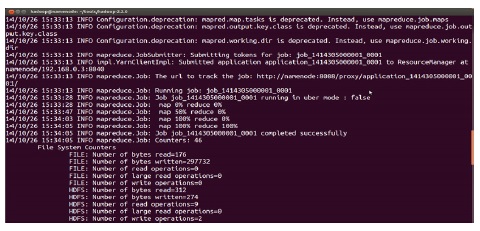
분산 노드로 크롤링하는 Nutch는 Hadoop의 Map Reduce 기반으로 실행되고 실행하는 화면은 그림 7과 같다.
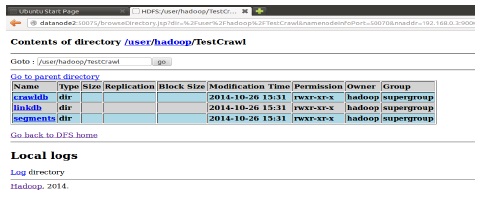
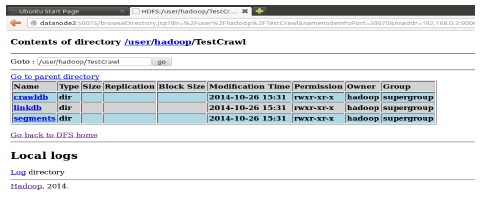
MapReduce로 실행된 Nutch의 크롤링 데이터는 HDFS에 저장되며 그림 8과 같이 웹 브라우저를 통해 확인할 수 있다.
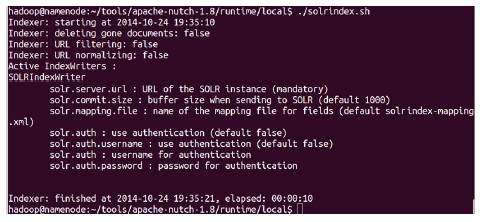
Nutch로 크롤링한 데이터는 Solr를 사용하여 인덱싱 할 수 있다. Solr를 사용하여 인덱싱을 진행하는 화면은 그림 9와 같다.
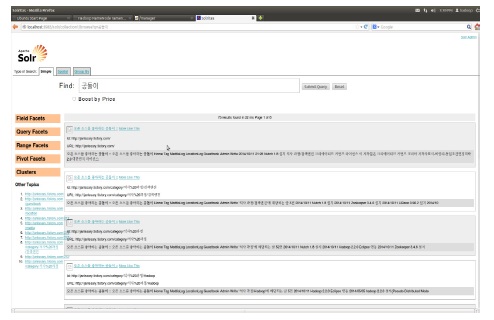
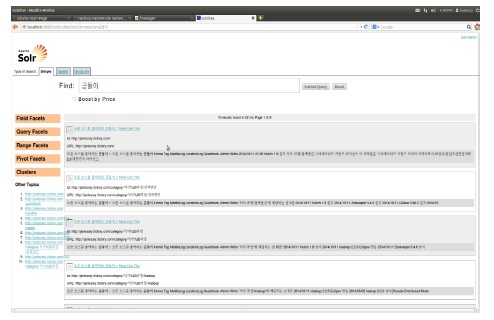
인덱싱된 데이터는 Solritas를 사용하여 사용자가 검색할 수 있다. 사용자가 Solritas 기반으로 검색하는 화면은 그림 10과 같다.
IT 기술의 발전으로 인해 데이터 생산과 소비가 급격하게 증가하고 있다. 이로 인해 많은 데이터 속에서 사용자가 원하는 정보를 효과적으로 찾을 수 있게 해주는 검색엔진의 기술 중요성이 높아지고 있다. 검색엔진은 인터넷을 검색하는 공용 검색엔진과 내부 인트라넷을 검색하는 내부 검색엔진으로 분류된다. 기존의 검색 엔진을 구현하기 위해서는 많은 개발 비용이 소모되어 접근하기 어려운 기술로 인식되고 있었다. 하지만 Lucene의 등장으로 인해 적은 개발 비용으로 검색엔진을 쉽게 구현할 수 있게 배경을 마련하였다.
본 논문에서는 Lucene 기반으로 개발된 프레임워크들을 사용하여 대용량의 데이터를 검색할 수 있는 검색 엔진의 구현 방법과 사용 방법을 제안하였다. 논문에서 구현한 검색엔진은 Lucene기반으로 개발된 자바 프레 임워크들을 사용하여 이식성이 뛰어나고 적은 개발 비용과 소수의 개발자로 구현할 수 있다. 그리고 제안하는 검색엔진은 분산 처리 환경을 지원하기 때문에 상황에 맞게 하드웨어 장비를 추가하거나 제거할 수 있는 유연성을 제공한다. 또한, 논문에서 사용하는 자바 프레임워크들은 모듈별로 연동하여 사용하기 때문에 각각의 프레임워크들을 독립적으로도 실행할 수 있어 사용의 유연성도 제공한다.
논문에서는 제안하는 검색엔진의 성능을 검증하기 위해 단일 노드와 분산 노드 환경에서 웹 크롤링을 실시하고 인덱싱 작업과 한글 키워드로 검색을 하여 논문의 적합성을 입증하였다.
향후 연구과제로는 Solr와 Hadoop을 연동하여 분산 노드에서 실시간으로 인덱싱할 수 있는 기능에 대한 연구가 필요하다.