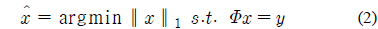In this paper, an orthogonal matching pursuit (OMP) method combined with genetic algorithm (GA), named GAOMP, is proposed for sparse signal recovery. Some recent greedy algorithms such as SP, CoSaMP, and gOMP improved the reconstruction performance by deleting unsuitable atoms at each iteration. However they still often fail to converge to the solution because the support set could not avoid the local minimum during the iterations. Mutating the candidate support set chosen by the OMP algorithm, GAOMP is able to escape from the local minimum and hence recovers the sparse signal. Experimental results show that GAOMP outperforms several OMP based algorithms and the
최근에 압축 센싱(compressive sensing)은 많은 연구자들로부터 신호의 획득과 복원 분야에서 새로운 대안으로 심도있는 관심을 받고 있다. 나이퀴스트 표본 이론은 신호 처리 분야에서 오랫동안 기본 이론으로서 중요한 역할을 수행해 왔다. 그러나 그 이론은 단지 아날로그 신호를 획득할 때에 완벽한 복원을 보장하는 충분조건일 뿐이다. 특정 신호의 경우 나이퀴스트 비율로 표본화하면 매우 비효율적인 처리 과정을 겪게 된다.
만약 어떤 실수 값을 갖는 신호

이다.
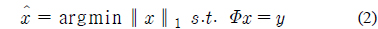
그러나 이 방법의 계산량도
계산량을 줄이기 위해 많은 연구가 수행되었으며 탐욕 알고리듬 기반의 여러 방법들이 제안되었다. Matching pursuit (MP) [4]와 orthogonal matching pursuit (OMP) [5]가 선구적인 연구이며, 신호 복원 성능과 수렴 속도 및 계산량을 줄이기 위한 많은 연구가 이어졌다. Stagewise OMP (StOMP) [6], Compressive Sampling Matching Pursuit (CoSaMP) [7], Subspace Pursuit (SP) [8], generalized Orthogonal Matching Pursuit (gOMP) [9], Backtracking base Adaptive OMP(BAOMP) [10] 등이 그 결과이다.
그러나 이 알고리듬들의 공통된 특징은 희소도가 증가함에 따라 해를 찾지 못하는 빈도가 늘어난다는 점이다. 가장 근본적인 이유는 반복과정에서 support set이 잔차의 크기는 작지만 잘못된 atom을 포함하고 있는, 즉 국소 최저에 빠져서 이후의 반복과정에서도 그 국소최저에서 벗어나지 못하기 때문이다. 이는 탐욕 알고리듬의 근본적인 문제이기도 하다. 본 논문에서는 이러한 국소최저 문제를 회피할 수 있는 새로운 희소 신호 복원 알고리듬을 제안한다. 다른 OMP 기반의 알고리듬과 같이 매 반복과정에서 잔차 신호로부터 새로운 atom을 찾아 내어 희소도도 추정하고 support set도 갱신한다. 또한, CoSaMP, SP, BAOMP처럼 그 유효성이 입증되지 않는 atom들은 support set에서 제거한다. 제안된 방법에서는 추가적으로 유전 알고리듬의 주요 도구인 확률적 변이를 support set에 적용하여 국소 최저를 벗어 날 수 있는 기능을 보강하였다.
제 2장에서는 제안된 유전 알고리듬 기반 OMP(GAOMP) 방법의 단계별 동작을 설명한다. 제 3장에서는 GAOMP의 성능을 거론된 몇몇 알고리듬들과 모의실험 결과를 이용하여 비교하고, 마지막으로 본 논문의 기여를 제 4장에서 요약한다.
식 (1)의 Φ의 열벡터는 atom이라 정의되며 모든 atom들의 집합은 dictionary라고 한다. 희소 신호
비록 탐욕 알고리듬이 일반적으로 비용을 최소화하기 위한 효율적인 방법이기는 하지만 국소 최저 문제를 겪기도 한다. 탐욕적인 OMP 기반 알고리듬들도 이 문제에 취약하다. Support set을 갱신해 나가면서 잔차의 크기를 줄여 나가지만 국소 최저에 빠질 수 있으며, 그 경우에 오랜 반복 과정으로도 희소한 원 신호를 복원할 수 없게 된다. 최근에 보고된 gOMP나 BAOMP도 국소 최저 문제로 인해 희소 신호를 복원하지 못하는 경우가 발생한다.
2.2. 유전 알고리듬 (genetic algorithm, GA)
유전 알고리듬은 국소 최저를 갖는 비용 함수의 전역최저를 찾을 수 있는 확률적인 반복 방법이며, 일반적인 최적화 문제에서 gradient search 방법보다 우수한 성능을 보인다[11]. “세대”라고 불리는 매 반복 과정마다 각 “개인”의 적합도를 평가한다. 높은 적합도를 갖는 개인을 확률적으로 선택하고 그 후보의 유전자를 변형하여 다음 세대를 준비한다. 변이(mutation)가 선택(selection)이나 교차(crossover)보다 우수한 유전 알고리듬의 연산자임이 잘 알려져 있다. 적절한 확률로 변이 과정을 거치면 자신과 유사한 특성을 피할 수 있다. 이로 인해 국소최저를 빠져 나올 수 있으며 결과적으로 알고리듬의 수렴이 늦어지거나 멈추는 상황을 개선할 수 있다.
표 1에 나와 있는 제안된 GAOMP 알고리듬은 두 부분으로 이루어져 있다. 1단계부터 3단계는 OMP 부분으로 least squares 방법으로 support set을 원 신호에 가깝게 보완해 나가며, 4단계는 GA 부분으로 확률적 변이를 통해 원 신호를 향한 다양성을 제공한다. x

GAOMP 알고리듬
두 번째 단계에서는
제안된 GAOMP는 support set을 확률적으로 변이시킴으로써 국소 최저를 피할 수 있다. 4b 단계에서는
SP나 CoSaMP와 달리 GAOMP는 신호 복원의 실행을 위해 희소도 정보를 요구하지 않는다. 대부분의 응용 예에서도 희소도는 사전에 알 수 없다. Needell이 실행에 앞서 희소도를 추정하는 방법을 제안하였지만 [7] 잘못 추정된 희소도는 신호 복원 실패로 이어짐을 유의해야 한다.
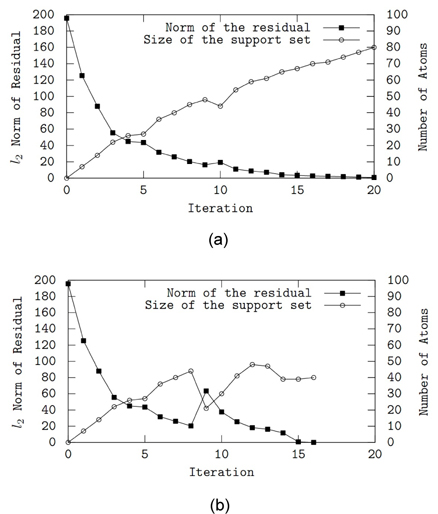
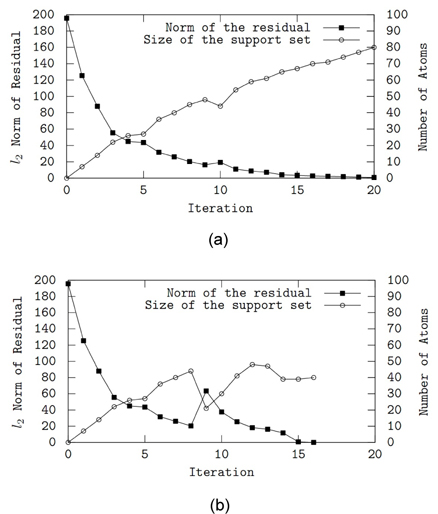
그림 1은 제안된 알고리듬과 BAOMP의 동작 특성을 비교하고 있다. 희소 신호와 측정 신호의 크기는 각각 200과 100이고 (
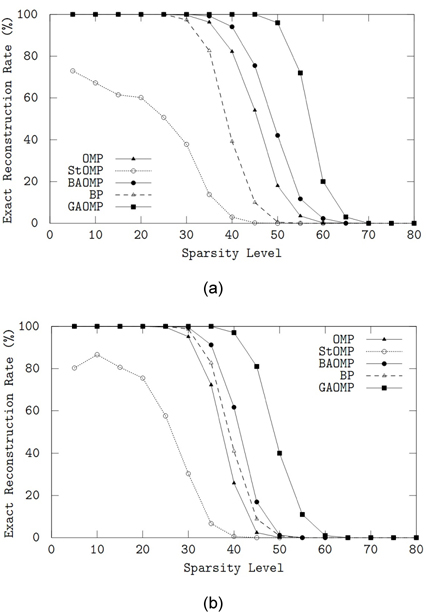
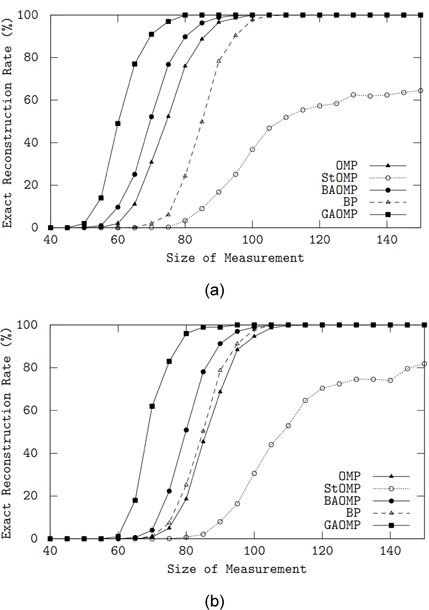
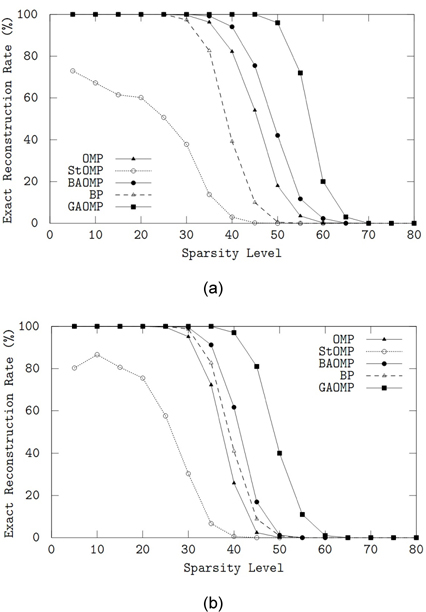
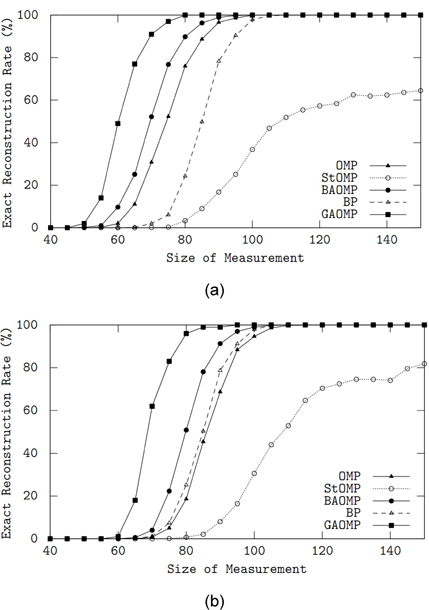
제안된 GAOMP의 복원 성능을 탐욕 방법의 OMP, StOMP, BAOMP 및
희소도
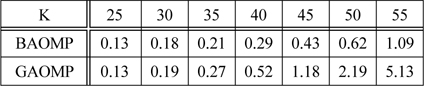
표 2에서는 BAOMP와 GAOMP의 Matlab 수행 시간을 비교하였다.
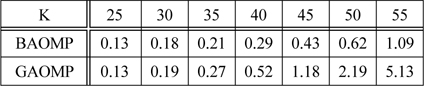
평균 신호 복원 실행 시간 (초)
입력 신호가 PAM 희소 신호인 경우는 그림 2(b)에 나타내었다. 모든 알고리듬이 가우시안 신호의 경우(그림 1(a))보다 다소 낮은 복원 성능을 보이지만 BP만이 거의 유사한 성능을 유지하였다. PAM 신호에 대해서도 GAOMP가 가장 우수한 복원 성능을 보였다.
두 번째 모의 실험에서는 가우시안 신호와 PAM 신호에 대한 복원 성능의 변화를 측정값의 크기
본 논문에서는 희소 신호의 복원을 위해서 GAOMP라 불리는 유전 알고리듬을 활용한 직교 정합 추구 방법을 제안하였다. 원 신호가 덜 희소하거나 또는 측정치의 개수가 부족한 경우에 OMP 변종 알고리듬들은 국소 최저 문제로 인해 신호의 복원에 실패하는 확률이 높아진다. 이는 support set에 잘못 포함된 atom이 반복과정을 통해서 제외되지 않기 때문이며, 특히 잔차의 크기가 작을 때 더욱 복원 가능성은 떨어진다. 이러한 국소 최저 문제는 탐욕 알고리듬의 원천적인 약점이기도 하다. 제안된 GAOMP는 support set에 확률적 변이를 적용하여 잔차의 크기가 작더라도 국소 최저에서 빠져나와 희소 신호를 완벽하게 복원할 수 있는 확률을 향상시켰다. 모의실험 결과로부터 GAOMP가 실험에 사용된 모든 OMP 기반의 방법과