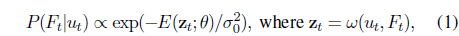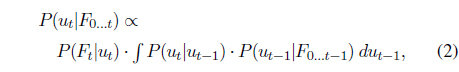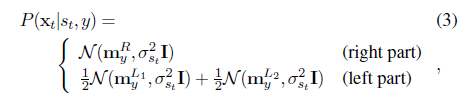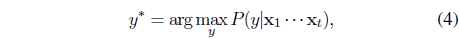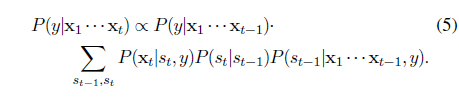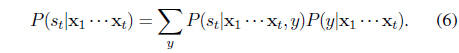In recent years, the barcodes have become ubiquitous in many diverse areas such as logistics, post services, warehouses, libraries, and stores. The success of barcodes is mainly attributed to easily machine-read representation of data that aautomates and accelerates the tedious task of identifying/managing a large amount of products/items.
In barcodes, data are typically represented as images of certain unique and repeating onedimensional (1D) or two-dimensional (2D) patterns. The task of retrieving data from these signal patterns is referred to as
Because of the availability of inexpensive camera devices (e.g., in mobiles or smartphones), image-based barcode recognition has become considerably attractive. Recently considerable research work has been conducted on this subject. Here we briefly list some recent imagebased barcode localization/recognition methods. In [1] block-wise angle distributions were considered for localizing barcode areas. A region-based analysis was employed in [2] whereas discrete cosine transformation was exploited in [3]. Image processing techniques including morphology, filtering, and template matching were serially applied in [4]. The computational efficiency was recently considered by focusing on both turning points and inclination angles [5].
However, most existing image-based barcode recognition systems assume a
In this paper, we consider a completely different yet realistic setup: the input to the recognizer is a
Perhaps the most straightforward approach for recognizing barcodes in video frames is a key-frame selector, that basically selects the so-called key frames with least blur/noise, and then applying off-the-shelf single-image recognizer in series. The potential conflict of differently predicted codes across the key frames can be addressed by majority voting. However, such approaches can raise several technical issues: i) how would you judge rigorously which frames should be preferrably selected and ii) which voting schemes are the most appropriate with theoretical underpinnings? Moreover, the approach may fail to exploit many important frames that contain certain discriminative hints about the codes.
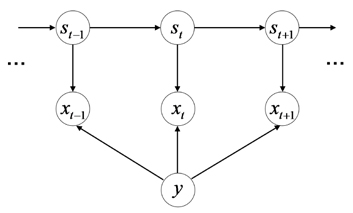
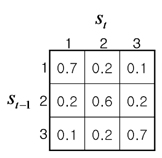
Instead, we tackle the problem in a more principled manner. We consider a temporal model for a sequence of barcode image frames, similar to the popular hidden Markov model (HMM). The HMMs were previously applied to visual pattern recognition problems [6-10]. In our model, we introduce hidden state variables that encode the blur/noise levels of the corresponding frames, and impose smooth dynamics over those hidden states. The observation process, contingent on the barcode label class, is modeled as a Gaussian density centered at the image/signal pattern of the representing class with the perturbation parameter (i.e., variance) determined from the hidden state noise level.
Within this model, we perform (online) sequential filtering to infer the most probable barcode label. As this inference procedure essentially propagates the belief on the class label as well as the frame noise levels along the video frames, we can exploit all cues from noisy frames that are useful for predicting the barcode label in a probabilistically reasonable sense. Thus the issues and drawbacks of existing approaches can be addressed in a principled manner.
The paper is organized as follows. We briefly review barcode specifications (focusing on 1D EAN13 format) and describe conventional procedures for barcode recognition in Section 2. In our video-based data setup, the task of barcode localization (detection) must be performed for a series of frames, and we pose it as a tracking problem solved by a new adaptive visual tracking method in Section 3. Then in Section 4, we describe the proposed online sequence filtering approach for barcode recognition, The experimental results follow in Section 5.
Although 2D barcode technologies are now emerging, in this paper we deal with 1D barcodes for simplicity. As it is straightforward to extend it to 2D signals, we have left it for future work. In 1D barcodes, information is encoded as a set of digits where each digit is represented as parallel black and white lines of different widths. Although there are several different types of coding schemes, we focus on the widely-used EAN-13 format. The detailed specifications of EAN-13 barcodes are described here.
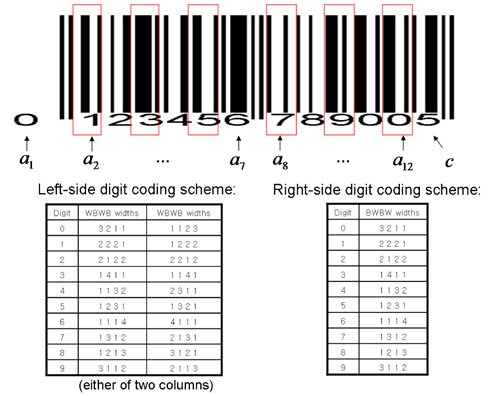
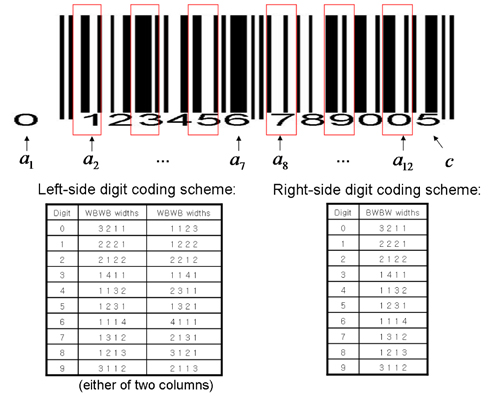
An example EAN-13 barcode image is shown in the top panel of Figure 1, where the black and white stripes encode 12-digit barcodes (
How each digit is encoded is determined by the widths of the alternating 4 B/W bar stripes (red boxes in the figure). The specific digit encoding scheme is summarized in the bottom panel, for instance, the digit 7 in the right part is encoded by BWBW with widths proportional to (1, 3, 1, 2). Note that each digit in the left part can be encoded by either of two different width patterns (e.g., digit 1 can be depicted as WBWB with either (2, 2, 2, 1) or (1, 2, 2, 2) widths).
Hence the barcode recognition mainly estimates the bar widths accurately from the image/signal. Of course, in an image-based setup, one first needs to localize the barcode region, a task often referred to as
In this section we deal with the visual barcode tracking problem. Although one can invoke a barcode detector for each frame from scratch, one crucial benefit of tracking is computational speed-up that is critical for real-time applications. A similar idea has arisen in the field of computer vision, known as the object tracking problem. Numerous object tracking approaches have been proposed, and we briefly list a few important ones here. The main issue is modeling the target representation: a view-based low-dimensional appearance model [11], contour models [12], 3D models [13], mixture models [14], and kernel representations [15, 16], are the most popular among others.
Motivated by these computer vision approaches, we suggest a fairly reasonable and efficient barcode tracking method here. Tracking can be seen as an online estimation problem, where given a sequence of image frames up to current time
We consider a temporal probabilistic model for tracking states and target appearances. We setup a Gaussian-noise Markov chain over the tracking states, and let each state be related to an appearance model that measures the goodness of track (how much
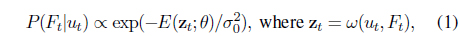
where
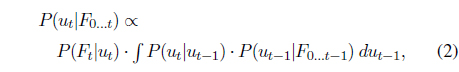
with initial track
Since the target barcode appearance can change over time (mainly due to changes in illumination and camera angles/distances or little hand shaking), it is a good strategy to adaptively change the target model. Among various possible adaptive models, we simply use the previous track z
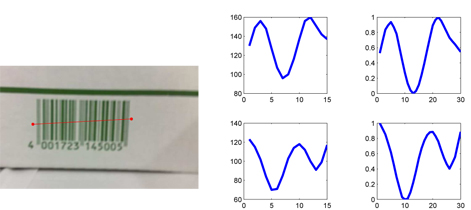
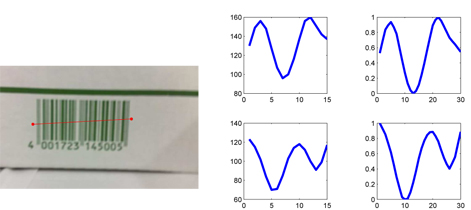
Once tracking is performed for the current frame, we have the tracked end points that tightly cover the barcode (an example is shown in the left panel of Figure 2). We read the gray-scale intensity values along the line segment, which are regarded as the barcode signal to analyze. Based on the prior knowledge of the relative lengths of the left/right-most boundary stripes as well as the middle separator, we can roughly segment the tracked barcode signal into 12 sub-segments, each of which corresponds to each digit’s 4 B/W stripes pattern. This can be done simply by equal division of the line segment.
As a result, we get 12 digit patterns, one for each digit. We show, for instance, the intensity patterns of the two digits 1 and 7 on the left part in the middle panel of Figure2. Then for each digit, we normalize its intensity pattern with respect to: 1) a fixed value x-axis length (say, 30) and 2) intensity normalization such that scales up/down the intensity values to range from 0 to 1. The former can be done by interpolation/extrapolation, while we use a simple linear scaling for the latter. The right panel of Figure 2 depicts the normalized signals for the example digits. In this way, the digit signals have the same length and scale across different digits, and hence they can be contrasted meaningfully with each other. We denote by x
From the tracking and the feature extraction procedure, we obtain a sequence of digit pattern signals, X = x1x2 ...x
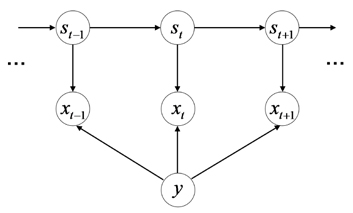
Instead of heuristic approach such as key-point selection, we tackle the problem in a more principled manner. We con-sider a temporal model augmented with the class variable
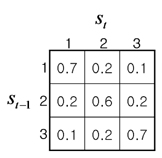
In our model, we introduce the hidden state variables
The crucial part is the observation modeling, where we employ a Gaussian density model whose mean and variance is determined by the digit class
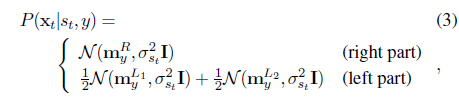
where is the normalized signal code vector for the digit
Within this model, we perform online sequential filtering to infer the most probable barcode label
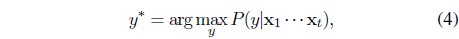
where the posterior of
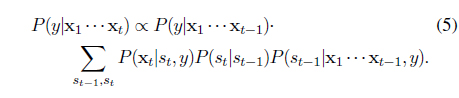
The last quantity, namely
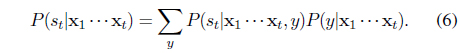
In essence, the inference procedures in our model consider the propagating beliefs on the class label as well as the framewise noise levels of the video frame sequence. In turn, we are able to exploit all the cues from noisy signal frames potentially useful for predicting the barcode label in a probabilistically reasonable sense. Thus the drawbacks of existing heuristic approaches such as key-frame selection can be addressed in a principled way.
In this section we empirically demonstrate the effectiveness of the proposed video-based barcode recognition approach.
5.1 Synthetically Blurred Video Data
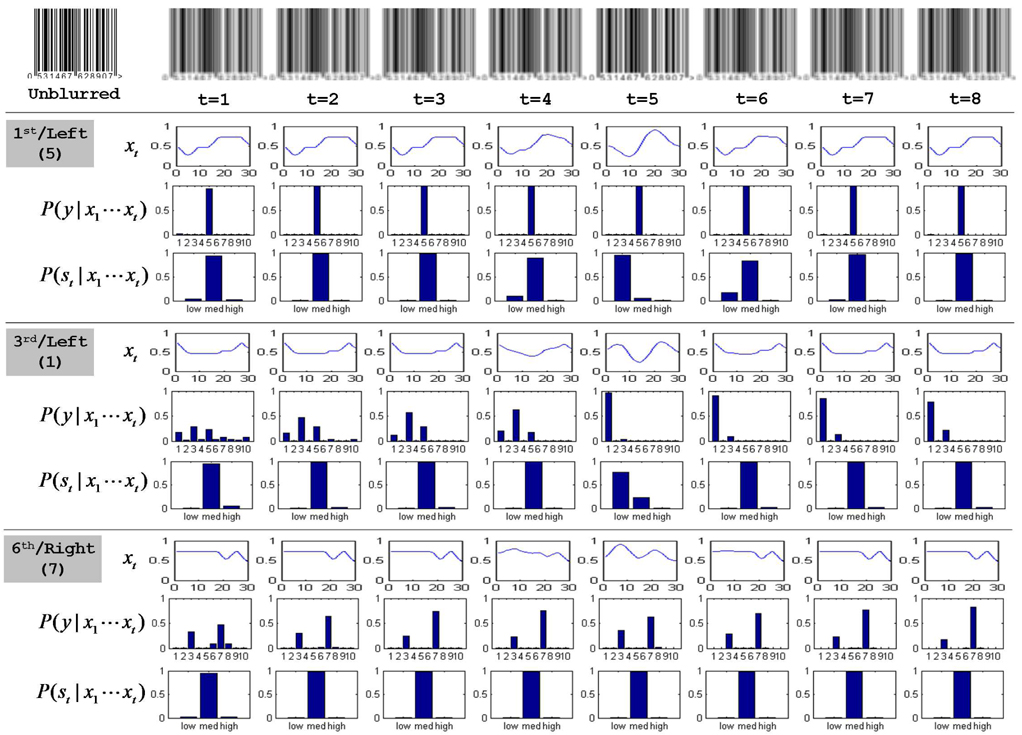
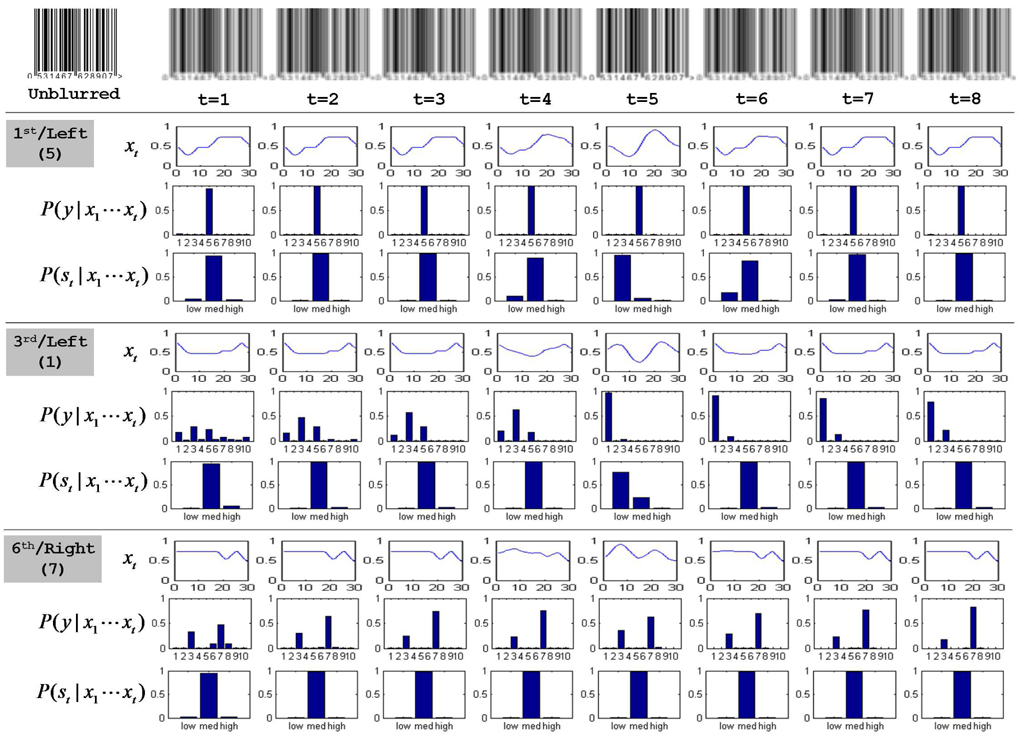
To illustrate the benefits of the proposed method, we consider a simple synthetic experiment that simulates the noise/blur that can be observed in real video acquisition. First, a clean unblurred barcode image is prepared as shown in the top-left corner of Figure 5. We then apply Gaussian filters (i.e.,
As described in the previous section, we split each barcode frame into 12 areas, one for each digit, normalize regions, and obtain sequences of observation signal vectors x1 · · ·x
The online class filtering (i.e.,
In addition, in the middle panel (for the 6th/right digit case), as the model observes more frames, the belief to the correct class, that is,
We next apply our online temporal filtering approach to the real barcode video recognition task. We collect 10 barcode videos by taking pictures of real product labels using a smartphone camera. The video frames are of relatively low quality with considerable illumination variations and pose changes, most of which are defocused and blurred. Some of the sample frames are shown in Figure 6. The videos are around 20 frames in length on average.
After running the visual barcode tracker using a conventional detector, we obtain the cropped barcode areas. We simply split the area into 12 signals for digits according to the relative boundary/digit width proportions. Then the proposed online filtering is applied to each digit signal sequence individually. For a performance comparison, we also test with a baseline method, a fairly standard frame-by-frame based barcode recognizer, where the overall decoding for a whole video can be done by majority voting.
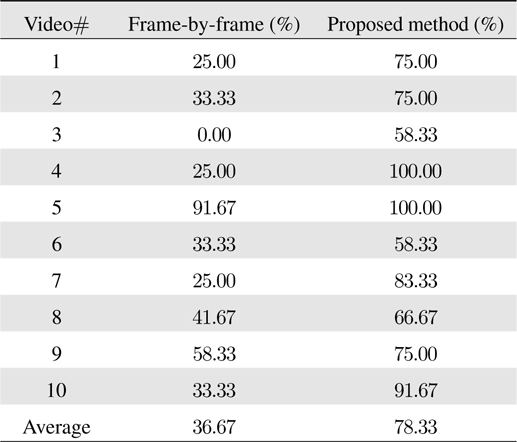
In Table 1 we summarize the recognition accuracies of the proposed approach and the baseline method over all videos. As there are 12 digits for each video, we report the proportions of the accurately predicted digits out of 12. The proposed approach significantly improves the baseline method with nearly 80% accuracy on average, which signifies the impact of the principled information accumulation via sequential filtering. On the other hand, the heuristic majority voting scheme fails to decode the correct digits most of the time, mainly due to its independent treatment of the video frames with potentially different noise/blur levels.
[Table 1.] Barcode recognition accuracy on real videos
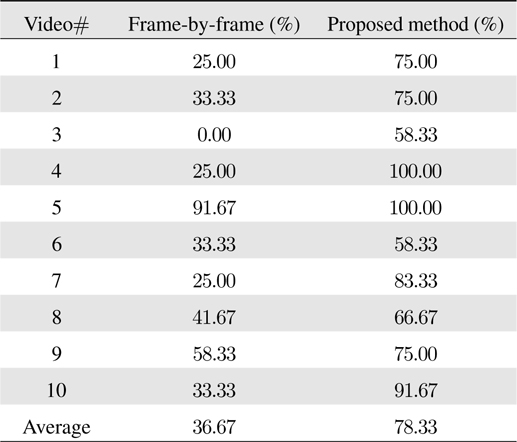
Barcode recognition accuracy on real videos
5.2.1 More Severe Pose/Illumination Changes
We next test the proposed barcode tracking/recognition approaches on the video frames with more severe illumination and pose variations. We have collected additional seven videos (some sample video frames illustrated in Figure 7), where there are significant shadows, local light reflections, in conjunction with deformed objects (barcode on plastic or aluminum foil bag containers) and out-of-plane rotations.
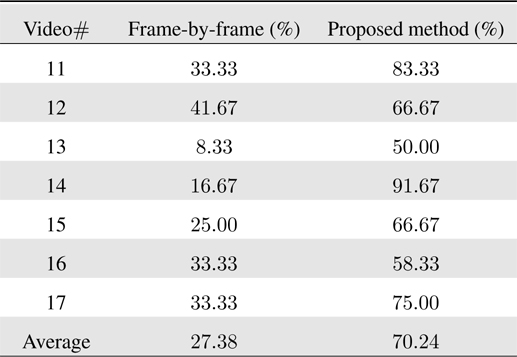
The recognition results are summarized in Table 2. The results indicate that the proposed sequential filtering approach is viable even for the severe appearance conditions. In particular, the partial lighting variations (e.g., shadows) can be effectively handled by the intensity normalization in the measurement processing, while the pose changes (to some degree) can also be effectively handled by the noisy emission modeling in HMM.
[Table 2.] Barcode recognition accuracy on real videos with severe illumination and pose variations.
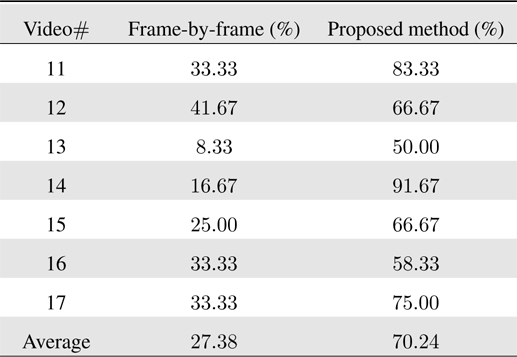
Barcode recognition accuracy on real videos with severe illumination and pose variations.
In this paper we proposed a novel video-based barcode recognition algorithm. Unlike single-frame recognizers the proposed method eliminates the extra human effort needed to acquire clean, blur-free image frames by directly dealing with a sequence of noisy blurred barcode image frames as an online filtering problem. Compared to a frame-by-frame based approach with heuristic majority voting scheme, the belief propagation of the class label and frame-wise noise levels in our model can exploit all cues from noisy frames. The proposed approach was empirically shown to be effective for accurate prediction of barcode labels, achieving significant improvement over conventional single-frame based approaches. Although in practice, the current algorithm needs frames of higher quality to achieve 100% accuracy, the results show that the proposed approach can significantly improve the recognition accuracy for blurred and unfocused video data. be effectively handled by the noisy emission modeling in HMM.
No potential conflict of interest relevant to this article was reported.