Publish:
Journal of the Korean BIBLIA Society for library and Information Science
Volume 24, Issue4, p99~113, 30 Dec
2013
ABSTRACT
An Analysis of the Intellectual Structure of the LIS Field: Using Journal Co-citation Analysis*
본 연구는 학술지를 이용한 동시인용분석을 통해 문헌정보학 분야의 지적구조를 분석하고자 하였다. Journal Citation Reports의 Journal Impact Factor를 바탕으로 선택한 문헌정보학 분야의 30개 학술지를 대상으로 조사된 동시인용 수치를 이용하여 네트워크 분석을 시행하였으며, 이 연구의 결과를 통해 어떤 학술지가 이 분야의 주요한(core) 학술지이며 그렇지 않은 학술지는 어떤 것들이 있는지 파악할 수 있다. 네트워크 분석을 통해 비교적 간단한 방법으로 얻어진 결과임에도 불구하고, 군집분석이나 다차원축적법 같은 통계적 접근법을 통한 대부분의 지적구조분석과 매우 유사한 결과를 보여주었다.
Thomas Kuhn's idea of scientific revolutions (Kuhn 1962) and the concept of paradigm shift made many researchers curious about the intellectual structure of their academic fields. Studies of the intellectual structure of an academic discipline provide ways to examine the discipline's current state as well as to show the changing structure as the field goes through modification in their subfields or subject specialties. In particular, the field of Library and Information Science has been using bibliometrics such as citation analysis in analyzing scientific literature and applying it to create a visualization of an academic discipline's underlying structure. As McCain (1991a, 290) mentioned, citation analysis can “identify the ‘core’ literature of various fields of scholarship as represented in their journal literature and study synchronous and diachronous patterns of literature aging.” The analysis can use individual documents, authors, or journals as the unit of analysis, and various methods for examining patterns of citations such as co-citation, inter-citation, and bibliographic coupling.
Influenced by Kuhn's structural view of scientific development, Small (1973) introduced the co-citation analysis as “a new measure of the relationship between two documents” in the scientific literature, and later applied the methodology across all the sciences “so that the full structure could be viewed on a single map” (Small 2003, 395). Unlike the basic citation analysis or bibliographic coupling examining the relationship between the citing unit and the cited unit, the co-citation analysis provides a dynamic view of a discipline's structure because it examines “the frequency with which two items of earlier literature are cited together by the later literature” (Small 1973, 265) and the result of co-citation analysis may vary dependent on the studied period. In other words, it can also be used as a means of investigating the scientific growth of a discipline by studying the changing structure of an academic discipline over time.
The purpose of this study is to investigate the intellectual structure of the library and information science field by identifying core journals of the field as well as their subject fields. Co-citation patterns of journals will be analyzed using network analysis, and subject categories of the journals will be used to help examining the intellectual structure of the field as well as discerning which subject specialties are related to the core journals.
Studies of the intellectual structure have been done in various academic fields, including economics (Kwak and Chung 2012), marketing research (Yoo et al. 2012), geography (Sluyter et al. 2006), biomedical informatics (Jeong and Kim 2010), and stem cell research (Zhao and Strotmann 2011), and library and information science (Yoon and Seo 2001; Yoo 2003; Moya-Anegon, Herrero-Solana, and Jimenez- Contreras 2006; Park 2013) and in subfields of Library and Information Science such as information retrieval (Rorissa and Yuan 2012), bibliometrics (Lee and Choi 2011) and diffusion of innovation (Kim and Park 2011). Especially, the intellectual structure of library and information science has been examined with diverse methodologies, including co-citation analysis and bibliographic coupling, combined with statistical approaches, such as cluster analysis and MDS. In a study comparing existing techniques with a new technique for using topics as a measure of relatedness, Lu and Wolfram (2012) reviewed five representative techniques for mapping bibliometric units; direct citation, bibliographic coupling, cocitation analysis, co-authorship analysis, and co-word analysis.
Yoon and Seo (2001) investigated the intellectual structure of Korean library and information science in 1990s using author co-citation analysis. They analyzed author co-citation data from three library and information science journals from 1990 through 1999, using MDS, cluster analysis, factor analysis, and crosstab analysis. MDS was used for mapping of 50 authors with a correlation coefficients matrix but not successful in distinguishing the relationships between authors because of the weak correlations tendency between authors. Cluster analysis was performed to generate clusters of authors with similar characteristics, and it yielded 13 distinct clusters representing subfields of library and information science, such as library management, information retrieval, reference service, cataloging and classification, bibliometrics, and bibliographies. Factor analysis was used for confirmation of the cluster analysis result and revealed that the result of the factor analysis and the cluster analysis were quite well matched. Lastly, crosstab analysis was used for investigating the interrelation between authors and their corresponding subject fields. According to the result of their crosstab analysis, library management and information retrieval were two of the most highly cited subject fields among 20 subfields of library and information science. Among other things they found out from this study, changes in the intellectual structure of library and information science seemed to be brought by social and technological changes.
Yoo (2003) investigated the intellectual structure of library and information science by clustering the index terms used in the LIS journals. The index terms were clustered based on the linkage of the terms and the co-occurrence frequency. The result indicated that KORMARC, information retrieval, public libraries, OPAC, and university libraries constituted the highest level clusters, which showed cataloging was still an important subject in the library and information science research. The study also investigated the very first used index terms of each year during the period between 1978 and 2001 and examined the frequency of each “first used” index term appeared in journal documents. Through the examination, the study found out that ‘public libraries’ were the most frequently appeared index term in 1978, and other types of libraries were also appeared as important research topics during those days. Some cataloging-related terms, such as OPAC and AACR, were frequently used in the late 1970s and early 1980s, and studies of information users started to appear in the mid 1980s. Specialty databases including MEDLINE started to appear in the index terms in 1990 and the term internet was obviously the most highly used as well as digital libraries in 1995. As a very logical and natural development, the term ‘document delivery’, ‘metadata’, and ‘retrieval engine’ were used as research topics in 1996, and research in 2000 showed changes of research trends and rise of other aspects of the field, such as ‘record management’ and ‘knowledge management’. As the researcher admitted, the indexing term-based analysis method was not very successful in explaining the intellectual structure of library and information science, but it confirmed that the intellectual structure of the traditional classification system served the purpose of classifying library materials.
There are other approaches to define the intellectual structure of information science by formulating a knowledge map (Zins 2007a/2007b; Zins and Santos 2011). Using a methodology called “Critical Delphi” with a panel of 57 scholars from 16 countries, the study incorporated reflections regarding schemes of classifying the knowledge structure of information science from 28 panel members. Some scholars used abstract and theoretical descriptions for each category, such as “epistemological”, “systematic”, “cognitive”, “psychological”, “communicative”, and “technological”, and others used more concrete and practical descriptions, including “information retrieval”, “information management”, “knowledge organization”, “user studies”, and “quantitative analysis in IS.” Although the study does not provide “one and only” gigantic scheme of information science, it does show how diverse the field of information science can cover as its topics with rationales provided for each scheme. With the same methodology and the panel, Zins (2007b) suggested a conceptual model of information science, composed of two main groups. The first group had one category, “foundations”, and the second group had nine categories, including “resources”, “knowledge workers”, “contents”, “applications”, “operations and processes”, “technologies”, “environments”, “organizations”, and “users.” The “Critical Delphi” methodology let the researcher formulate the knowledge map using three phases, starting from systematic conceptions of data, information, knowledge, and information science, and then the panel critically reflected on the conceptions, which lead to the construction of the knowledge map as a result. The first group represents the metaknowledge of the field or philosophical grounds of information science and the second group’s categories are considered as nine basics of information science. Nguyen and Chowdhury (2013, 1235) also used knowledge mapping to help researchers in “exploring and understanding the DL (digital library) knowledge domain and its evolution” and constructed a knowledge map of digital library research with 21 core topics, including social web, semantic web, mobile technology, and information retrieval, as well as 1,015 subtopics covering a period from 1990 to 2010. The research indicated that the digital library research topics came from various disciplines, including library and information science, computer science, knowledge management, and the social sciences. Lee et al. (2010) also investigated the digital library research field using journal and descriptor profiling methods, and generated maps with distinctive journal clusters and descriptor clusters. The results showed 11 descriptor clusters with representative journals, including knowledge management, online cataloguing formats, online information retrieval, world wide web, online reference work, and distance learning.
McCain (1991a/1991b/1998) introduced co-citation analysis using journals as the unit of analysis, instead of using individual documents or authors. In author co-citation analysis, “the raw data are counts of the number of times any two authors are cited together in later works” (McCain 1991a, 290). The co-citation patterns reveal major subject specialities of a discipline as well as central and peripheral authors within each subject specialty and the discipline. Journal co-citation analysis uses the same logic behind other co-citation analysis, which means that “a journal’s placement (central or peripheral) in the map should reflect the congruence between the content of that journal’s articles and the research interests of authors publishing (and citing) in the field represented by the set of journals studied” (McCain 1991a, 291). McCain applied journal co-citation analysis in an attempt to map Economics (1991a) and Genetics (1991b), and resulted in “clear, coherent, and reasonable” (1991a, 295) mapping of the fields. In the study for generating cocitation maps for Genetics, McCain (1991b) used journal cocitation patterns to compare the results with the core network analysis, which identified important journals using “the strong patterns of citations made and received by journals.” The study indicated that such bibliometric analyses using journals were helpful to “identify a manageable number of important journals at both the disciplinary and subdisciplinary levels” (McCain 1991b, 326) and journal co-citation analysis portrayed the subject structure of a discipline, offering collection specialists “the ability to map a reasonably representative set of journals rapidly, modify the map by adding additional titles, and identify journals likely to be of use to various constituencies represented by the clusters” (McCain 1991b, 326). Later, McCain (1998) used journal co-citation analysis in neural networks research, employing cluster analysis and MDS maps to identify foundation research areas in neural networks research.
Moya-Anegon, Herrero-Solana, and Jimenez- Contreras (2006) used the self-organizing map (SOM), clustering, and multidimensional scaling (MDS) to visualize the field of library and information science, based on author co-citation analysis (ACA) and journal co-citation analysis (JCA). Using 17 journals selected for the study based on impact factors in Journal Citation Reports 1996 edition, the ACA results showed 6 main domains in information science research, including scientometrics, citationist, bibliometrics, communication theory, soft information retrieval, and hard information retrieval. The MDS map of journal co-citation analysis showed 4 main clusters, including information science, library science, science studies, and management. Their result confirmed the subject domains identified in previous domain analysis studies (White and McCain 1998) and suggested the use of network analysis for other kinds of representations.
Åström (2010) investigated the relationship between library science and information science by comparing knowledge maps created for each field with author co-citation analysis and journal co-citation analysis, and produced a joint map for library and information science. The result showed a networked map of 37 most-cited journals with some journals in the center and others in the periphery. Journal co-citation analysis is also used for identifying core journals in other areas of research. Jo and Lee (2012) identified core journals for pharmaceutical researches in Korea using journal citation frequency analysis and journal co-citation analysis. They used factor analysis on journal correlation matrix which resulted in 116 core journals with 18 subject domains.
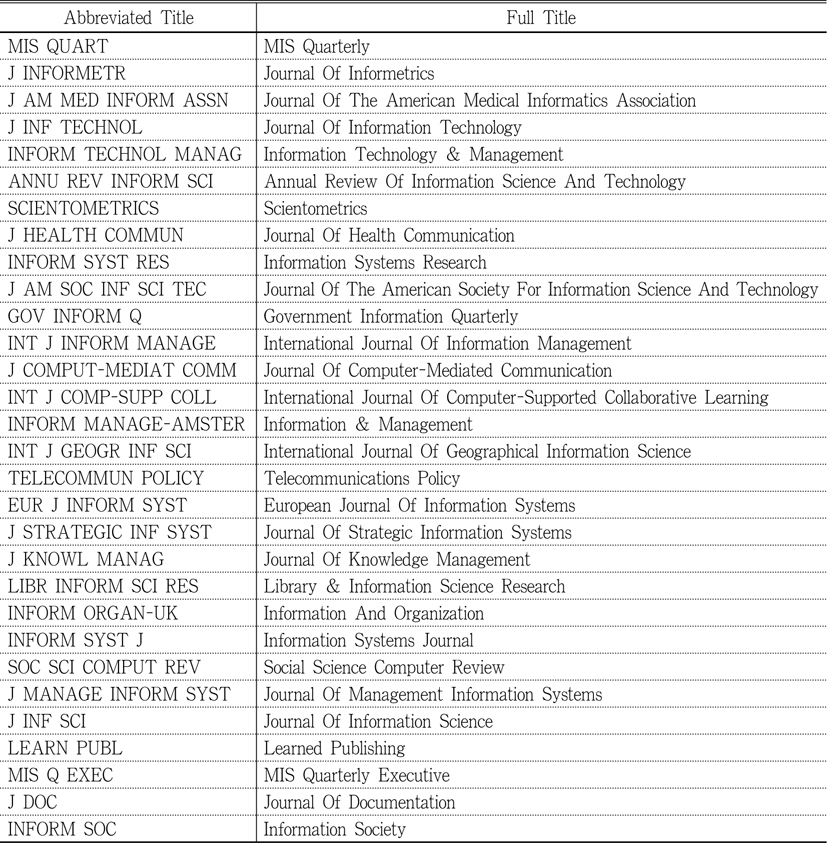
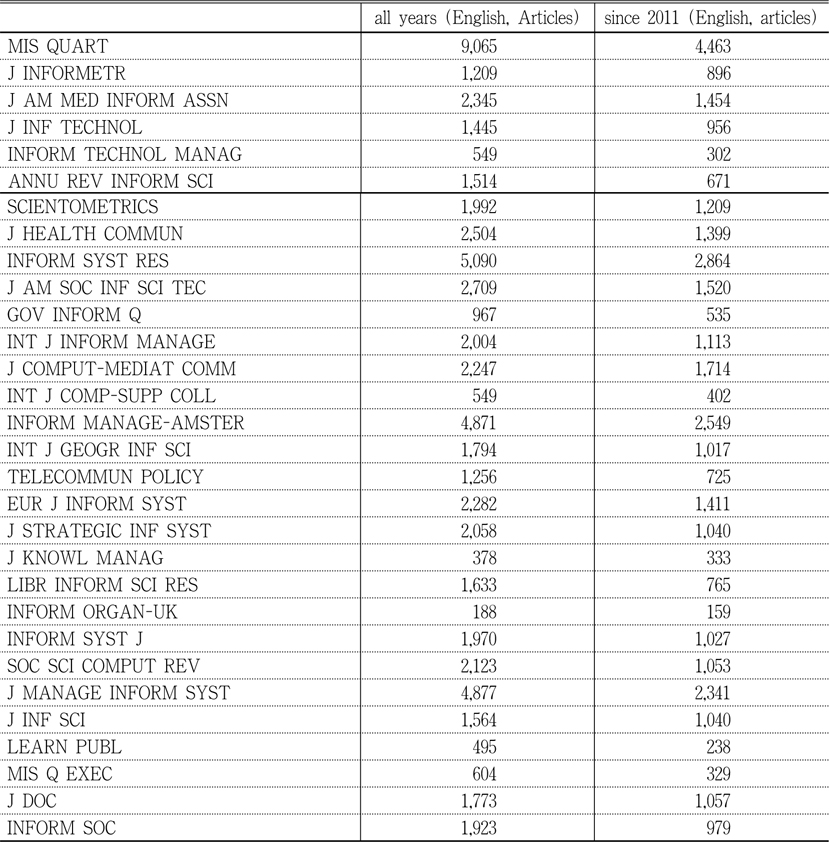
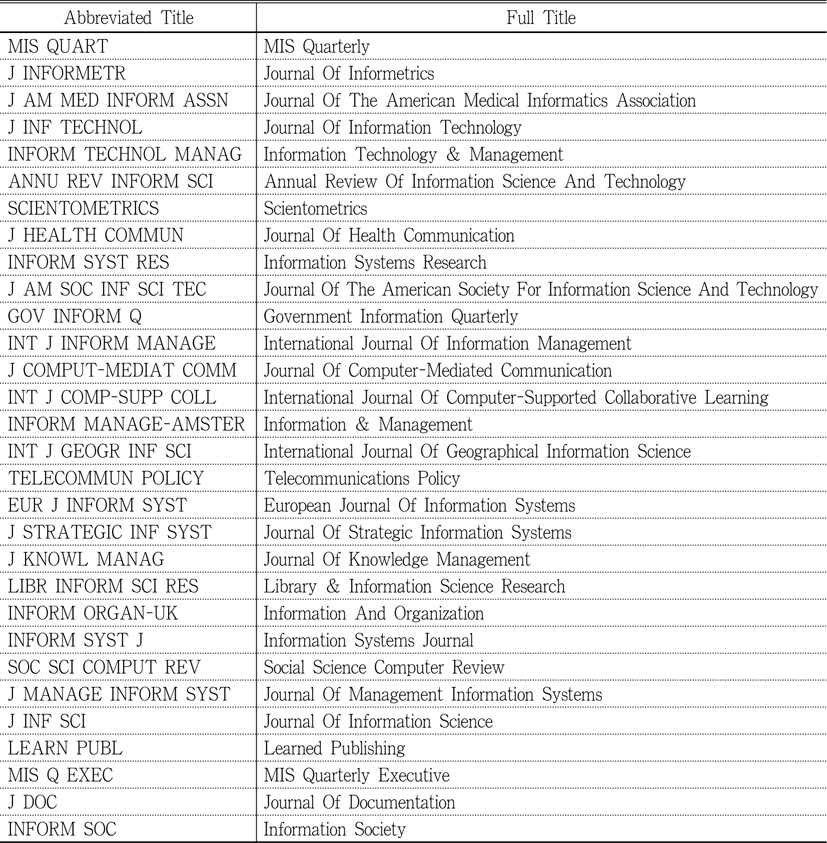
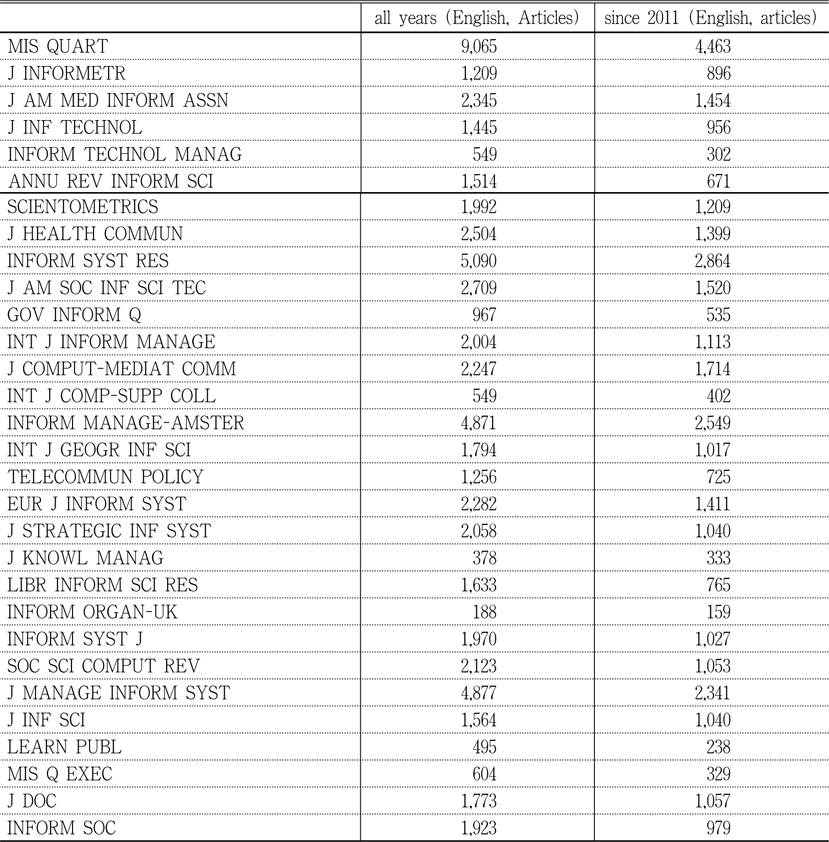
The data for this study was collected using Social Science Citation Index from Web of Science. Thirty journals were selected based on the Journal Impact Factor in 2012 Journal Citation Reports Social Science Edition for Information Science & Library Science as the subject category. The list of journals with the abbreviated and full title is shown in Table 1. First, raw counts for “cited references search” results for each journal were recorded. Initially, timespan for the search was set as “All Years” but later changed into “from 2011 to 2013” because the initial search yielded too many results for most of the journals. The selected two-year period yielded sufficient but not too many number of cited references, based on subjective judgment by the researcher. Because of the limitations that restrict the first 500 cited references to be included in the final result, too many results may not be suitable for distinguishing highly cited references. Table 2 shows the comparison between raw “cited references” counts when all years were counted and when references since 2011 were included. For the same reason, the language of the references was restricted to English, and the type of references was limited to articles.
The cited reference search shows the list of cited references with the particular journal as the “cited work”, and all of the results should be selected to get the final set of references that are citing the cited references. The search history page shows the number of references, or articles, that cite the journal’s articles. The co-citation counts were obtained by “AND”ing the search results for each pair of journals at the search history page. For example, there were 152 references that cited articles in MIS Quarterly and Information Technology & Management, but only 9 references cited articles in MIS Quarterly and Journal of Health Communication. The co-citation counts were used for constructing a 30 by 30 matrix, consisting of co-citation counts for each pair of journals. It was a symmetrical non-directional matrix, with diagonal values set at 0.
The co-citation matrix was analyzed with UCINET 6 (Borgatti, Everett, and Freeman 2002). UCINET 6 is a software package for the analysis of social network data, with the NetDraw network visualization tool. Network analysis is “a set of research procedures used to identify structures in social systems based on the relations among the system’s components (nodes) rather than the attributes of individual cases” (Barnett 2001, 1640), and citation can be a good example of a network because it involves relationships between the citing and the cited. The co-citation data can be entered directly to a matrix using data editors of UCINET 6, or copied from an Excel spreadsheet. When copied from an Excel spreadsheet, UCINET 6 can symmetrize the data by filling the empty cells with corresponding symmetric data and setting the diagonal to 0s, if necessary. Then the entered matrix data can be turned into a networked map using NetDraw, as well as generating network- related descriptive statistical analysis such as centrality and cohesion.
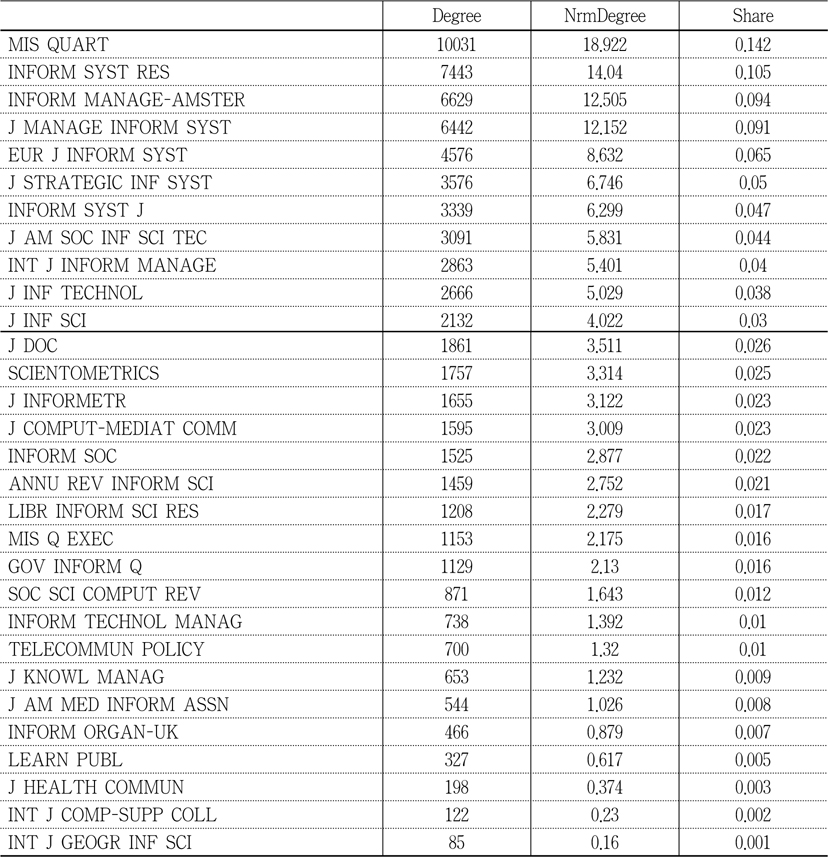
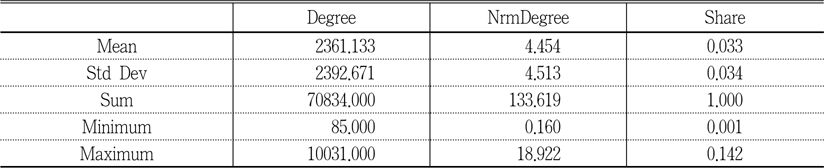
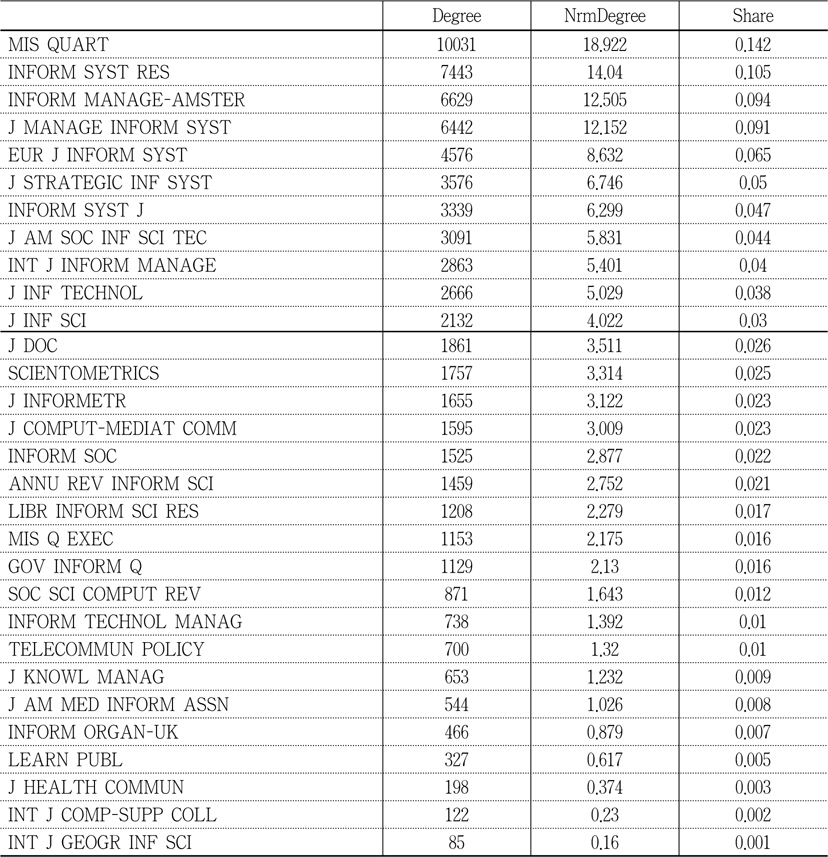
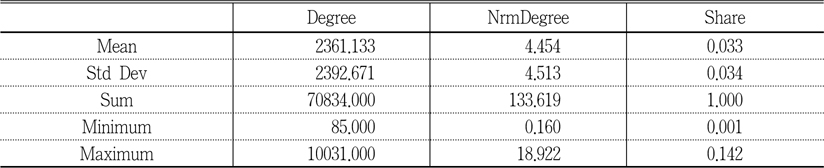
Table 3 shows a ranked list of journals, based on their degree centrality measures, where NrmDegree denotes “normalized degree centrality, as a percentage for each vertex” and Share represents “the centrality measure of the actor divided by the sum of all the actor centralities in the network.” Centrality is one of the measurements that represents a node’s prominence in network analysis. It can be measured based on degree, closeness, betweenness, and information, where degree centrality measures the degree of a particular actor’s connectivity with other nodes. In other words, actors or nodes with higher degree centrality show prominence in their activities. Closeness centrality measures “how close an actor is to all other actors in the set of actors” (Wasserman and Faust 1997, 183) and Freeman (1979) defined it as “the sum of graph-theoretic distances from all other nodes, where the distance from a node to another is defined as the length (in links) of the shortest path from one to the other” (Borgatti 2005, 59). Betweenness centrality measures the degree of dependence when there are interactions between two nonadjacent actors or nodes who might depend on the actors in the middle. Those actors “who lie on the paths between the two” (Wasserman and Faust 1997, 188) have the high betweenness centrality. Since this study is about journals prominence in co-citation activity, degree centrality is the proper measure of distinguishing core journals from others in the subject discipline. MIS Quarterly has the highest degree centrality, and Information Systems Research, Information & Management, European Journal of Information Systems, Journal of Strategic Information Systems, Information Systems Journal, Journal of the American Society for Information Science and Technology, and Journal of Information Technology are the rest of the journals ranked in top 10 of degree centrality. Table 4 was added to show the descriptive statistic for each of the centrality measures.
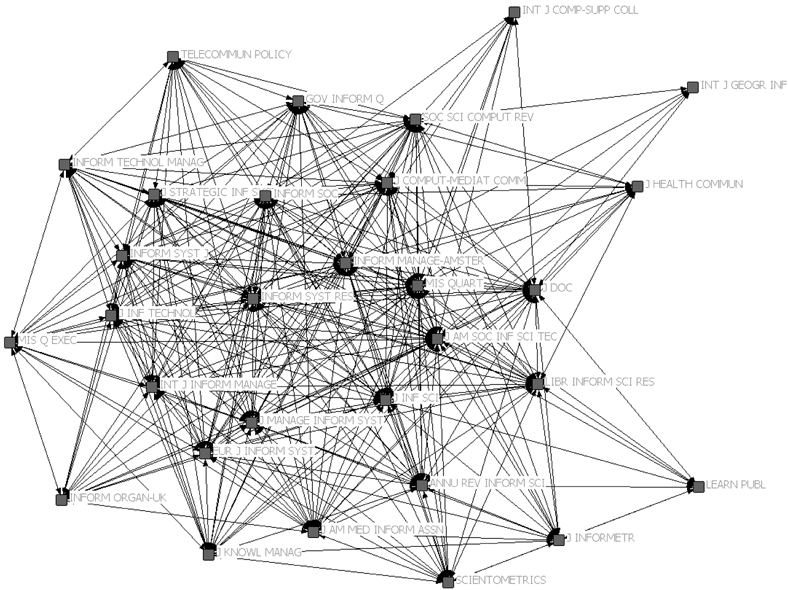
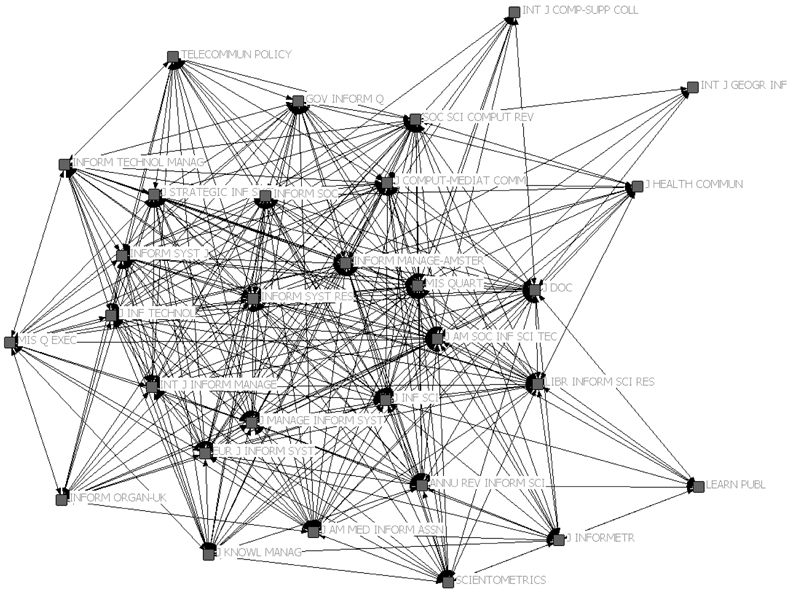
Figure 1 is the networked map of journals, generated with NetDraw (Borgatti 2002) of UCINET 6. The original data contains raw counts of journal co-citations, but the links on the map represent binary relationships between linked journals. The map shows a cluster of journals that can be identified as central, or core, as well as some other journals that can be considered as peripheral. First of all, a group of journals sub-categorized as “management” under the main category of “information science & library science” in Web of Science can be seen in the center of the map; MIS Quarterly (1), Information Systems Research (10), International Journal of Information Management (13), and Information & Management (16). The numbers in parentheses denote their impact factor ranks. Second group of journals consists of journals covering general areas of library and information science, and they are also located in the middle section of the map, hence they can be considered as another core group of journals; Journal of the American Society for Information Science and Technology (11) and Journal of Information Science (27). The third group of journals, although they are in the area of periphery on the map, consists of journals covering studies based on bibliometric research; Journal of Informetrics (2) and Scientometrics (8). The notable aspect of the third group is that their impact factor scores are higher than the journals in other groups, but the co-citation map shows they are in the periphery. In addition, Journal of Computer-Mediated Communication (15) and Journal of Health Communication (28) are linked to each other, which shows possibility of the fourth group under the subject category of communication.
The clusters of journals correspond quite well with an MDS map of journal co-citation analysis in Moya-Anegon et al. (2006). Their MDS map shows four main clusters covering such subjects as management, science studies, information science, and library science. Although the networked map of journals does not have a group of journals under the subject category of science studies, the difference might have been caused by the selection of the journals in the data. Other than the science studies group, other clusters of journals are not far from the ones in the MDS map, despite the fact that the selected journals for each study are rather different. In addition, the core journals in the networked map show some similarity with the result of Åström (2010), which included the Journal of the American Society for Information Science and Technology, Journal of Documentation, The Library Quarterly, and Information Process Management as the “central” group of journals and Scientometrics, Nature, and ACM Transactions on Information Systems in the periphery.
The purpose of the study was to investigate the intellectual structure of the library and information science field by identifying core journals of the field as well as their subject fields. The study analyzed co-citation patterns of 30 journals in the library and information science field using network analysis, and the result showed four main subject clusters including management, general area of the LIS, bibliometric studies, and communication. Among those four clusters, journals categorized under the subject of “management” and general area of the LIS were located in the center of the networked map, and journals related to other areas of research were located in the periphery of the network.
Using journals as the unit of analysis has some advantages over using authors as the unit of analysis. When using authors as the unit of analysis, the researcher has to deal with issues of name disambiguation (Kim 2012). The first step in collecting data for author co-citation analysis is to identify each author’s indexed name for more accurate searching. Still, there are some names that cannot be distinguished easily, especially many Asian names have the same last name with the same initials. In such cases, further verification processes are required to search for publications created by the specific author. However, journals are abbreviated as indexed in the database, which relieves the need for verification. Jo and Lee (2012, 169) also pointed out that journal co-citation resolves the issue of name disambiguation that can occur in author co-citation analysis. Moreover, subject specialties or topics are also difficult to identify for authors while it is rather obvious to recognize main subject specialties of journals. While additional information is required to identify each author’s subject specialties, such as the membership to interest groups of a certain professional association, no further identification is required for journals’ subject specialties because usually their titles give out suggestions of their subject fields.
In addition, using network analysis turns out to be very efficient and effective in obtaining quite similar results to other domain analyses employing statistical approaches such as cluster analysis and MDS. Collecting data for co-citation analysis can be tedious and laborious as it involves many mouse clicks, but once the data is collected, the networked map can be obtained almost immediately using network analysis tools such as UCINET. In addition, if more data is available for attributes of the actors, network analysis can be used to generate more detailed networked map of the data such as weighted links or nodes with different colors.
Still, there are issues relating to the technical aspect of Web of Science, because it only allows the first 500 results to be included as the citing reference. When using authors as the unit of analysis, the first 500 results may be sufficient to include all the publications citing the author, but most journals usually have more than 500 references that are citing articles in the journal even though the timespan is limited to less than two years. Also, further research is suggested for more complete analysis on the growth of knowledge in the library and information science field. In addition, although using network analysis appears to be useful in distinguishing core journals from peripheral journals in the field, it does not provide more detailed information about underlying structure beyond the core-periphery distinction. If a research involves vast amount of items, additional analysis techniques are necessary to support more detailed investigation on the intellectual structure, such as Parallel Nearest Neighbor Clustering (PNNC) as suggested by Lee (2006). PNNC is a “fast and powerful clustering method” (Lee 2006, 215) that uses an algorithm generating clusters based on the network’s links and determining the number of clusters based on similarity distributions of the data. Studies of an academic discipline’s intellectual structure will be continued using various methods and techniques, which can be helpful to examine the current state of the discipline and identify its subfields that need more improvements.
참고문헌
1.
곽 선영, 정 은경
2012
복수저자기반 동시인용분석을 활용한 지적구조 분석: 경제학 분야를 중심으로
[『정보관리학회지』]
Vol.29 P.115-134
2.
김 광재, 박 종구
2011
저자동시인용 분석방법을 이용한 혁신확산 연구의 지적구조
[『한국방송학보』]
Vol.25 P.52-87
3.
김 현정
2012
인용분석에서의 모호한 저자명 식별을 위한 방법들에 대한 고찰
[『한국비블리아학회지』]
Vol.23 P.5-17
4.
박 지연
2013
『문헌정보학의 지적구조 분석에 관한 연구』. 박사학위논문
5.
유 경옥, 김 향미, 김 재욱
2013
연결망 분석을 이용한 마케팅 분야의 고객가치 연구의 진화 및 발전과정에 관한 연구: 저자 동시 인용 분석방법을 이용한 SSCI 상위 20위권 저널을 대상으로
[『한국경영과학지』]
Vol.38 P.1-24
6.
유 영준
2003
문헌정보학의 지식 구조에 관한 연구
[『정보관리학회지』]
Vol.20 P.277-297
7.
윤 구호, 서 말숙
2001
저자동시 인용분석에 의한 1990년대 한국문헌정보학의 지적구조에 관한 연구
[『한국도서관?정보학회지』]
Vol.32 P.169-197
8.
이 재윤
2006
지적 구조 분석을 위한 새로운 클러스터링 기법에 관한 연구
[『정보관리학회지』]
Vol.23 P.215-231
9.
조 선례, 이 재윤
2012
약학 분야 학술정보서비스를 위한 학술지 동시인용 분석
[『정보관리연구』]
Vol.43 P.159-185
10.
Astrom Fredrik
2010
“The Visibility of Information Science and Library Science Research in Bibliometric Mapping of the LIS Field.”
[The Library Quarterly]
Vol.80 P.143-159
11.
Barnett G. A.
2001
“A Longitudinal Analysis of the International Telecommunication Network, 1978-1996.”
[American Behavioral Scientist]
Vol.44 P.1638-1655
12.
Borgatti Stephen P.
2005
“Centrality and Network Flow.”
[Social Networks]
Vol.27 P.55-71
13.
Borgatti Stephen P.
2002
NetDraw: Graph Visualization Software
14.
Borgatti Stephen P., Everett M. G., Freeman L. C.
2002
Ucinet 6 for Windows: Software for Social Network Analysis
15.
Freeman L. C.
1979
“Centrality in Networks: I. Conceptual Clasification.”
[Social Networks]
Vol.1 P.215-239
16.
Jeong Senator, Kim Hong-Gee
2010
“Intellectual Structure of Biomedical Informatics Reflected in Scholarly Events.”
[Scientometrics]
Vol.85 P.541-551
17.
Kuhn Thomas S.
1962
The Structure of Scientific Revolutions
18.
Lee Jae Yun, Choi Sanghee
2011
“Intellectual Structure and Infrastructure of Informetrics: Domain Analysis from 2001 to 2010.”
[Journal of the Korean Society for information Management]
Vol.28 P.11-36
19.
Lee Jae Yun, Kim Heejung, Kim Pan Jun
2010
“Domain Analysis with Text Mining: Analysis of Digital Library Research Trends using Profiling Methods.”
[Journal of Information Science]
Vol.36 P.144-161
20.
Lu Kun, Wolfram Dietmar
2012
“Measuring Author Research Relatedness: A Comparison of Word-Based, Topic-Based, and Author Cocitation Approaches.”
[Journal of the American Society for Information Science and Technology]
Vol.63 P.1973-1986
21.
McCain Katherine W.
1991
“Mapping Economics through the Journal Literature: An Experiment in Journal Cocitation Analysis.”
[Journal of the American Society for Information Science]
Vol.42 P.290-296
22.
McCain Katherine W.
1991
“Core Journal Networks and Cocitation Maps: New Bibliographic Tools for Serials Research and Management.”
[The Library Quarterly]
Vol.61 P.311-336
23.
McCain Katherine W.
1998
“Neural Networks in Context: A Longitudinal Journal Cocitation Analysis of an Emerging Interdisciplinary Field.”
[Scientometrics]
Vol.41 P.389-410
24.
Moya-Anegon Felix, Herrero-Solana Victor, Jimenez-Contreras Evaristo
2006
“A Connectionist and Multivariate Approach to Science Maps: The SOM, Clustering and MDS Applied to Library and Information Science Research.”
[Journal of Information Science]
Vol.32 P.63-77
25.
Rorissa Abebe, Yuan Xiaojun
2012
“Visualizing and Mapping the Intellectual Structure of Information Retrieval.”
[Information Processing & Management]
Vol.48 P.120-135
26.
Sluyter Andrew, Augustine Andrew D., Bitton Michael C.
2006
“The recent intellectual structure of geography.”
[Geographical Review]
Vol.96 P.594-608
27.
Small Henry
1973
“Co-citation in the Scientific literature: A New Measure of the Relationship between Two Documents.”
[Journal of the American Society for Information Science]
Vol.24 P.265-269
28.
Small Henry
2003
“Paradigms, Citations, and Maps of Science: A Personal History.”
[Journal of the American Society for Information Science and Technology]
Vol.54 P.394-399
29.
Wasserman Stanle, Faust Katherine
1997
Social Network Analysis: Methods and Applications
30.
White Howard D., McCain Katherine W.
1998
“Visualizing a Discipline: An Author Co-citation Analysis of Information Science, 1972-1995.”
[Journal of the American Society for Information Science]
Vol.49 P.327-355
31.
Zhao Dangzhi, Strotmann Andreas
2011
“Intellectual Structure of Stem Cell Research: A Comprehensive Author Co-Citation Analysis of a Highly Collaborative and Multidisciplinary Field.”
[Scientometrics]
Vol.87 P.115-131
32.
Zins Chaim
2007
“Knowledge Map of Information Science.”
[Journal of the American Society for Information Science and Technology]
Vol.58 P.526-535
33.
Zins Chaim
2007
“Classification Scheme of Information Science: Twenty-Eight Scholars Map the Field.”
[Journal of the American Society for Information Science and Technology]
Vol.58 P.645-672
34.
Zins Chaim, Placida L.V.A.C. Santos
2011
“Mapping the Knowledge Covered by Library Classification Systems.”
[Journal of the American Society for Information Science and Technology]
Vol.62 P.877-901
OAK XML 통계
이미지 / 테이블
[
<Table 1>
]
List of Journals with Abbreviated Titles and their Full Titles
[
<Table 2>
]
Number of Cited References for Each Journal
[
<Table 3>
]
Journals Ranked with Degree Centrality
[
<Table 4>
]
Descriptive Statistics for Degree Centrality