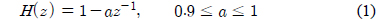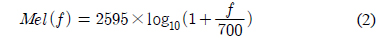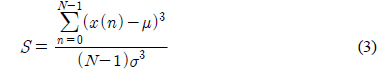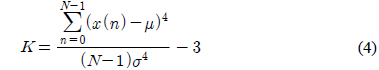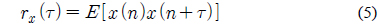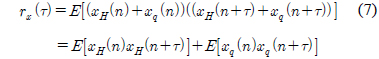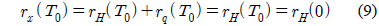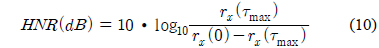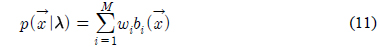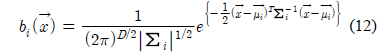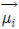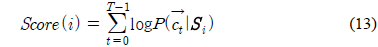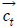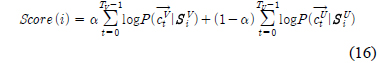In this paper, separate probabilistic distribution models for voiced and unvoiced speech are estimated and utilized to improve speaker recognition performance. Also, in addition to the conventional mel-frequency cepstral coefficient, skewness, kurtosis, and harmonic-to-noise ratio are extracted and used for voiced speech intervals. Two kinds of scores for voiced and unvoiced speech are linearly fused with the optimal weight found by exhaustive search. The performance of the proposed speaker recognizer is compared with that of the conventional recognizer which uses mel-frequency cepstral coefficient and a unified probabilistic distribution function based on the Gassian mixture model. Experimental results show that the lower the number of Gaussian mixture, the greater the performance improvement by the proposed algorithm.
사회가 발달함에 따라 삶의 편리성을 위해 음성을 기반으로 통제 가능한 인터페이스가 TV, 핸드폰, 자동차 등 많은 분야로 확산·적용되고 있으며, 향후에는 거의 모든 부분에서 보편화될 것으로 예상되고 있다. 그로인해 개인의 인터페이스를 타인으로부터 안전하게 사용하기 위해 인터페이스 보안에 대한 필요성이 대두되고 있다. 현재 음성을 기반으로 한 인터페이스 보안방법으로 화자인식 기술이 사용되고 있다. 화자인식이란 사람에 의해 발성되는 음성이 고유한 특색을 갖는다는 성질을 이용하여 각 화자의 음성신호에서 특징 정보를 추출하여 화자를 확인하는 것을 말한다. 화자인식 기술은 일반적으로 신분을 확인하는 방법인 신분증, ID 카드보다 편리하며, 생체기반의 보안방법이므로 분실할 위험이 없어 매우 안전하다[1]. 기존의 화자인식에 가장 널리 사용되는 특징 파라미터로서 선형 예측 계수(LPC: linear predictive coefficients)와 멜-주파수 캡스트럼 계수(MFCC: mel-frequency cepstral coefficients)특징 파라미터가 있으며, 본 논문에서는 기존의 MFCC 특징 파라미터에 화자의 음성신호를 특징지을 수 있는 왜도, 첨도, 하모닉대 잡음비(HNR: harmonic-to-noise ratio)를 추가적으로 사용하여 화자인식 성능 개선을 도모하였다.
화자가 갖는 파라미터를 확률적으로 모델링하기 위하여 가우시안 혼합 모델(GMM: Gaussian mixture model)이 가장 많이 사용되고 있는데, 본 연구에서는 스코어의 변별력을 높이기 위해서 음성신호를 유성음과 무성으로 분류한 후 각각의 파라미터를 GMM으로 모델링 하였다. 입력된 음성에서 계산되는 유성음 및 무성음에 관한 평균 스코어는 실험적으로 최적화된 가중치를 이용하여 선형 결합되어 최종적인 후보 화자의 스코어가 계산된다. 제안된 방법의 성능을 확인하기 위하여 기존의 MFCC를 이용한 GMM 기반의 화자인식 성능과 비교하였다.
본 논문의 구성은 다음과 같다. 제 2장에서는 GMM 기반의 특징 파라미터를 이용한 화자인식과 관련된 기존의 연구에 대하여 간략하게 설명하고, 제 3장에서는 본 논문에서 제안하는 방법에 대하여 소개한다. 제 4장에서는 제안된 새로운 방법을 적용한 실험 결과를 분석하고 마지막으로 제 5장에서 본 논문의 결론을 맺는다.
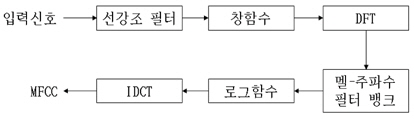
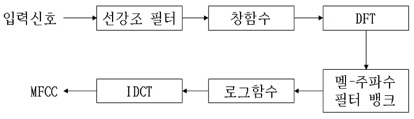
주파수 축에서의 응답의 인지적 변화도를 나타내는 MFCC는 음성 신호 분석을 위한 대표적인 특징 파라미터이다. MFCC 파라미터는 잡음환경에서 강하며 비 균일한 스케일로 주파수를 나눌 수 있다는 장점으로 화자 인식에 널리 사용되고 있다. MFCC 특징 벡터를 얻기 위한 일련의 과정은 그림 1의 블록다이어그램과 같다. 입력 신호를 식 (1)로 주어지는 선강조(pre-emphasis) 필터를 이용하여 고주파 성분을 높여주고 창함수를 씌워서 신호를 프레임 단위로 나누어 준다.

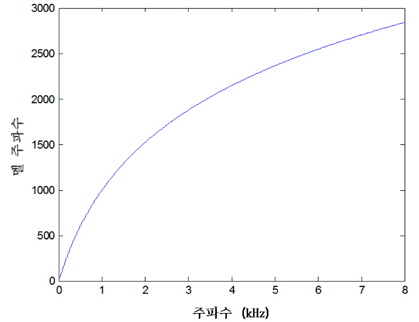
나누어진 분석 프레임은 각각 이산 푸리에 변환 (DFT: discrete Fourier transform)을 이용하여 주파수 영역의 응답으로 변환되며 응답의 절대치를 멜-주파수 필터뱅크로 적분하여 인간의 청각특성을 반영하도록한다. 즉, 멜-주파수 필터뱅크는 인간의 청각 시스템이 갖는 비선형적 특성을 반영하기 위한 블록이다. 식 (2)에서 보편적으로 사용되고 있는 멜-주파수 변환을 나타내었다.
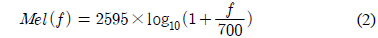
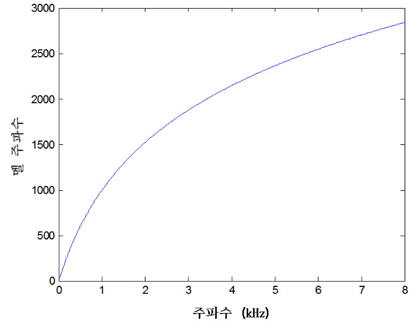
식 (2)에 의해서 변환되는 선형 주파수에 대한 멜 응답을 그림 2에 나타내었다. 그 후, 로그를 취한 응답에 대해서 역 이산 코사인 변환(IDCT: inverse discrete cosine transform)를 취하여 최종적으로 MFCC 특징 파라미터를 추출한다[2].
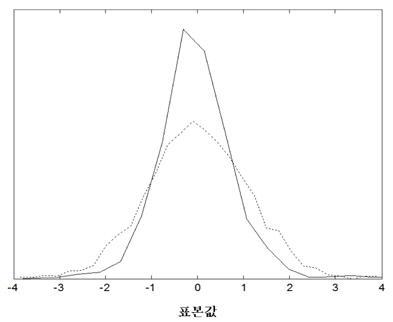
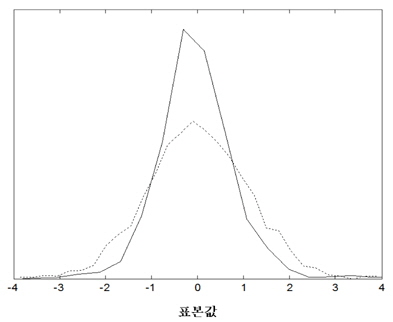
인간의 음성은 성대의 떨림 여부에 따라서 유성음 및 무성음으로 구분된다. 무성음의 경우 성대가 열린 상태에서 진동 없이 발성기관을 통과하면서 소리가 발생된다. 따라서, 무성음의 경우에는 시간 영역에서 신호의 분포가 정규분포에 가깝다고 알려져 있다. 유성음의 경우 기본적으로 성대의 진동음이 발성 기관을 통과하여 소리가 발생한다. 즉, 유성음의 근원에 해당하는 음파는 주기적인 펄스 형태로 예상할 수 있으므로 생성되는 유성음은 시간 영역에서의 분포는 정규분포보다 뾰족할 것으로 예상할 수 있다. 그림 3에서 유성음과 무성음의 시간영역에서의 분포를 예시하였다. 그림 3에서와 같이 무성음의 표본 값은 평균치가 0에 가깝고 어떤 분산 값을 갖는 정규분포에 가까움을 알 수 있다[3]. 일반적으로 분산의 의미는 신호의 크기 정보에 불과하므로 화자를 구분할 수 있는 특징파라미터로 사용하기에는 적합하지 않을 수 있다. 이에 반해서 유성음의 분포는 그림 3에서 예시하였듯이 무성음에 비해서 조금 더 뾰족하며 왼쪽 혹은 오른쪽으로 상대적으로 치우쳐 있다고 알려져 있다[4]. 이러한 유성음의 분포 특성은 성대의 떨림 특성과 관련이 있겠고 개개인 목소리의 음색을 결정짓는 중요한 요소로 판단할 수 있으므로 화자 인식을 위해서 유용하게 활용될 수 있을 것이다. 앞서 언급 한 분포의 왜도 및 첨도의 정도에 관한 파라미터는 각각 3차 혹은 4차 모멘트로부터 추정이 가능하다[5]. 식(3), (4)에서 주어진 표본 집합의 분포가 갖는 왜도와 첨도의 측정 방법을 나타내었다.
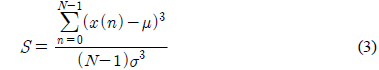
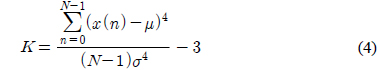
여기서,
2.2절에서도 언급했듯이 사람의 성대는 화자마다 고유한 특색을 가지고 있다. 그러므로 성대가 진동하는 주기도 다르며, 음성신호에 포함되어있는 잡음의 비율도 다르다. 이 때, 잡음이란 주기성이 없는 신호를 말한다. 인간이 유성음의 경우 완벽한 주기성을 갖는다고 말하기 어려우므로 이러한 현상은 잡음이 섞여 있는 것으로 간주할 수 있다. 즉, 이러한 주적인 신호에서 잡음성분이 얼마만큼 포함되어 있느냐를 나타내는 파라미터로서 HNR이 있다[6]. HNR의 측정은 신호의 자기상관도 함수의 계산에서 시작된다. 식 (5)에 자기 상관도를 구하는 방법을 나타내었다.
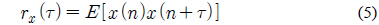
여기서,

여기서,
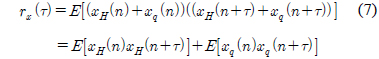
이때,

여기서,
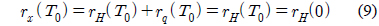
여기서,
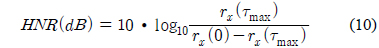
가우시안 혼합 모델(GMM: Gaussian mixture model)은 구조가 간단하고 광범위한 음향학적 특성을 모델링 할 수 있다는 장점이 있어서 화자를 모델링하는 가장 효과적인 방법으로 사용되고 있다. GMM은 식 (11)와 같이 M개의 가우시안 확률 분포들의 가중된 합으로 구성된다[7].
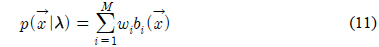
λ는 확률분포를 구성하는 파라미터 집합, 는
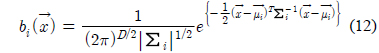
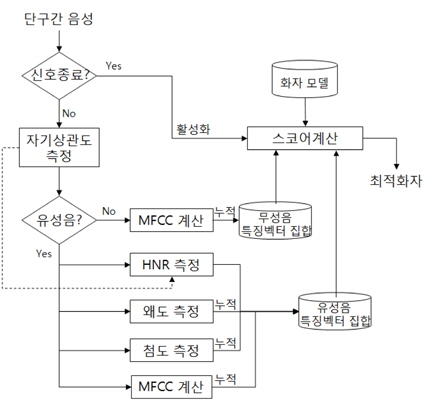
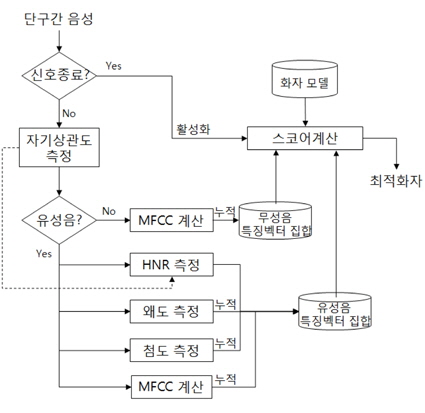
본 연구에서 제안하는 화자 인식 시스템에서는 스코어의 변별력을 높이기 위해서 각 화자를 모델링할 때 유성음 및 무성음에 대한 확률 분포 모델을 별도로 만든다. 또한, 유성음 구간에 대해서는 제 II장에서 설명한 왜도 및 첨도에 관한 파라미터를 추가적으로 추출하여 화자 인식에 활용하여 화자 인식 성능을 개선하는 것이다. 그림 4에서 본 논문에서 제안하는 화자인식 시스템의 블록다이어그램을 나타내었다. 주요 블록에 대한 설명은 다음과 같다.
유성음과 무성음은 식 (8)과 식 (9)의 자기상관도 영역에서 구분된다. 구분을 위해서
특징 파라미터의 구성은 유성음과 무성음에 대하여 다르게 구성되어있다. 3.1절을 토대로 신호가 무성음일 경우 특징 파라미터는 2.1절의 MFCC 특징 파라미터 추출 과정에서 추출된 파라미터와 2.2절의 식 (3),(4)을 이용하여 구한 왜도와 첨도를 파라미터로 추가 구성된다. 신호가 유성음일 경우 특징 파라미터는 무성음과 같이 MFCC 파라미터와 왜도, 첨도를 특징 파라미터로 사용하고 별도로 2.3절의 식 (10)을 이용하여 구한 HNR 파라미터가 추가되어 구성된다.
각 화자의 발성으로 만들어진 GMM에 대하여 임의의 화자의 발성에서 구해진 특징 파라미터를 이용하여 스코어가 식 (13)과 같이 계산된다.
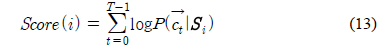
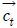
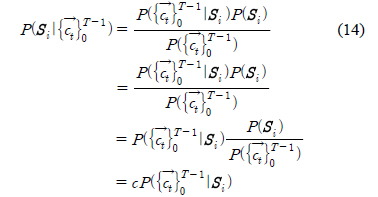
이 때,
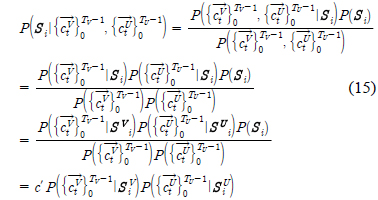
각 기호에 대한 설명은 식 (14)의 것과 동일하다. 다만, 위첨자 ‘
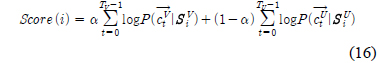
본 실험에서 사용된 음성 데이터베이스는 화자 당 16kHz/16 bit로 녹음된 고립어 160개이며, 화자는 남자 15명, 여자 15명로 구성되어있다.화자는 20대 ~30대의 한국인으로 구성되었으며 발성당 지속시간은 1~2초 사이의 3~5음절 고립어였다. 화자와 고품질 마이크간의 거리는 30cm 미만의 근거리였으며 36
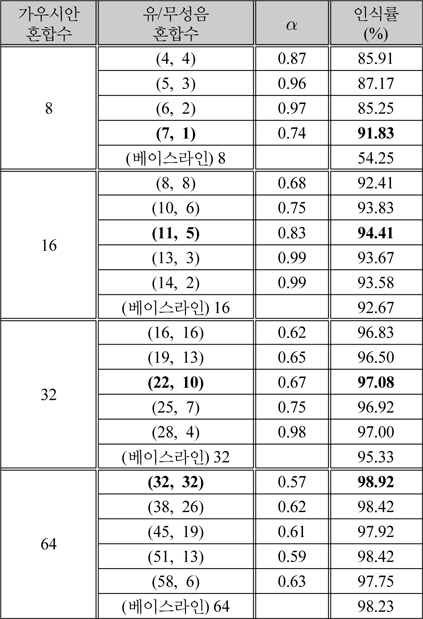
전체 GMM 가우시안 혼합 개수에 대하여 유성음과 무성음의 가우시안 혼합 비율을 달리하여 화자인식률을 비교하였다. 화자인식률을 비교한 결과는 표 1에 나타내었다. 이때, 화자 훈련 DB에서의 유/무성음 분리성능은 평균적으로 77.2%를 얻을 수 있었다. 표 1의 결과를 도출하기 위하여 주어진 총 GMM 혼합 수를 유지하면서 유성음 GMM 혼합수의 비를 50%, 60%, 70%, 80%, 90%에 근사화 되도록 증가시켰으며 각 조합에 대해서 식 (17)에서 유/무성음 스코어 결합을 위해서 제안한 α값을 0에서 1사이에서 0.01 단위로 전수검사하여 최적 인식률을 측정하였다.
[표 1.] 유성음과 무성음의 가우시안 혼합 수에 따른 최적 화자 인식률
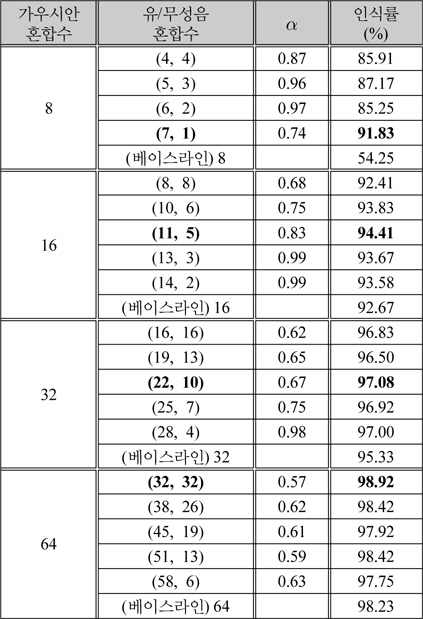
유성음과 무성음의 가우시안 혼합 수에 따른 최적 화자 인식률
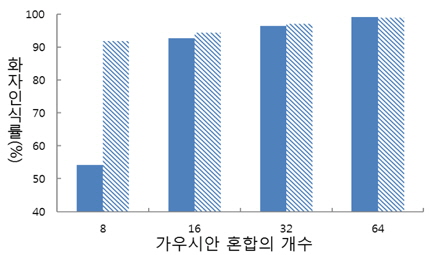
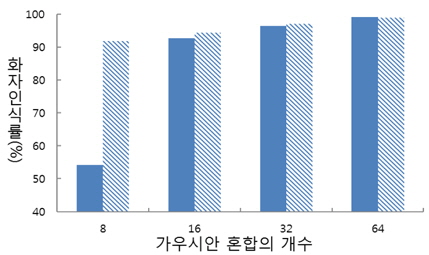
표 1을 통해서 알 수 있는 것은 첫 째, 유성음 파라미터만을 이용하여 화자인식을 하였을 때 보다 유성음과 무성음 파라미터를 모두 사용하여 화자인식을 할 때 인식률이 더욱 상승한다는 것이다. 둘 째, 전체 GMM 가우시안 혼합 개수가 많아질수록 무성음에 가해지는 가중치가 전반적으로 올라가는 것을 볼 수 있다. 이는 가우시안 혼합의 개수가 많아지면 유성음 파라미터만으로 화자를 모델링하는데 한계가 있음을 의미한다. 가우시안 혼합 개수에 따른 제안된 방법과 베이스 라인의 최대 인식률을 그림 5에서 나타내었다.
제안된 방법은 그림 5에서 볼 수 있듯이 가우시안 혼합 8, 16, 32, 64일 때, 제안된 방식은 베이스라인 보다 37.58%, 1.74%, 1.75%, 0.69% 더 높은 인식률을 나타내었다. 가우시안 혼합 개수가 일정개수 이상 증가하면 제안된 방법과 베이스 라인의 화자인식률이 거의 99%에 도달하므로 더 이상 혼합개수의 증가에 대한 실험은 수행하지 않았다. 제안된 방식에서 왜도, 첨도, HNR의 파라미터를 사용하지 않고 단순 유성음 및 무성음 분리만을 활용하였을 때의 제안된 방식에 의한 인식률은 가우시안 혼합수가 각각 8, 16, 32, 64 일 때, 84.48%, 94.05%, 96.67%, 98.78% 였다. 이 때, 표 1에서 구한 최적의 유/무성음 혼합수를 변동없이 활용하였다. 즉, 제안된 방식의 화자 인식 시스템에서는 이종적 특징 파라미터가 인식 성능 향상에 다소 영향을 준 것은 사실이지만, 유/무성음 분리 기법이 더욱 효과적이었음을 알 수 있다.
본 논문에서는 화자인식의 성능을 개선하기 위하여 음성의 특징 파라미터를 유성음과 무성음의 파라미터로 분류하고, 사람의 성대가 갖는 성질을 이용하여 특징 파라미터로 왜도, 첨도, HNR을 추가하여 파라미터를 구성 방법을 제안하였다. 유/무성음 스코어의 최적 가중치를 살펴봤을 때 혼합의 수가 낮을수록 유성음의 역할이 중요함을 알 수 있었다. 화자인식률 측면에서 가우시안 혼합의 수 8일 때, 즉 낮은 혼합일 때, 제안된 방식은 베이스라인에 비해서 최대 37.58% 더 높은 성능을 보였다. 향후, 제안된 방법을 이용하여 100명 이상의 화자에 대한 화자인식과 임베디드 시스템에서의 화자인식 연구를 계획하고 있다.