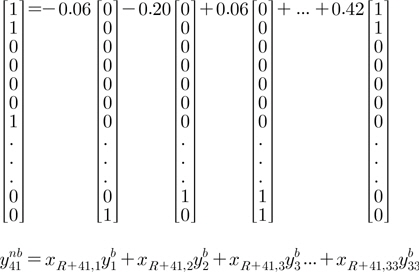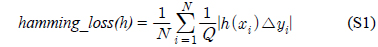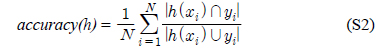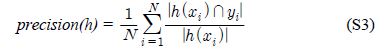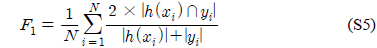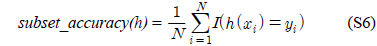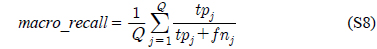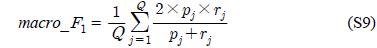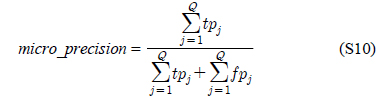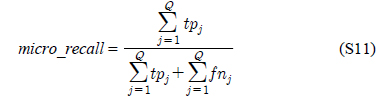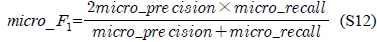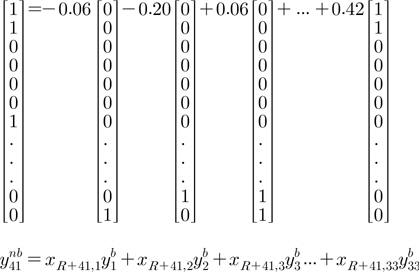Knowledge about protein subcellular localization provides important information about protein function. This paper improves a label power-set multi-label classification for the accurate prediction of subcellular localization of proteins which simultaneously exist at multiple subcellular locations. Among multi-label classification methods, label power-set method can effectively model the correlation between subcellular locations of proteins performing certain biological function. With constrained optimization, this paper calculates combination weights which are used in the linear combination representation of a multi-label by other multi-labels. Using these weights, the prediction probabilities of multi-labels are combined to give final prediction results. Experimental results on human protein dataset show that the proposed method achieves higher performance than other prediction methods for protein subcellular localization. This shows that the proposed method can successfully enrich the prediction probability of multi-labels by exploiting the overlapping information between multi-labels.
단백질을 구성하는 아미노산 서열정보로부터 단백질이 존재하는 세포내 위치를 예측하려는 연구 분야에서, 최근에는 여러 세포내 위치에 동시에 존재하는 단백질의 생물학적 기능이 중요하므로, 이를 예측하려는 시도가 커지고 있다[1-9]. 단백질의 세포내 위치에 대한 정보가 단백질의 기능과 효과적인 약물의 발견에 중요한데, 이는 동물, 식물, 곰팡이는 세포소기관으로 구획된 서로 다른 생화학적 환경에서 단백질이 세포내 위치에 특이적인 기능을 수행하기 때문이다[10]. 단백질이 존재하는 다중 세포내 위치의 예측에는 기존의 단일레이블 분류 방법을 적용할 수 없고, 다중레이블 분류를 적용하여야 한다. 다중레이블 분류는 이미지, 비디오, 텍스트, 음악, 마케팅, 생물학 분야에서 하나의 입력 자료에 대해 여러 가지 분류에 동시에 속하는 문제를 모델링하기 위하여 연구되고 있다[11-13]. 이 방법 중에 알고리즘 적응은 단일 분류 알고리즘인 최근접-이웃 분류기, 신경망, 결정 트리, 지지 벡터 기계 등을 다중레이블 분류에 적합하게 변형한 방법이고, 문제 변환은 다중레이블 분류를 여러 개의 단일레이블 분류로 변환하여 단일레이블 분류를 사용하는 방법이고, 메타 학습은 알고리즘 적응이나 문제 변환을 여러 개 조합하여 분류하는 방법이다[11-13].
단백질의 세포내 위치 예측에 적용된 알고리즘 적응은 가우시안 과정 모델과 공분산 행렬로 레이블간의 연관성을 표현하는 방법[3]이 있고, 문제 변환은 세포내 위치의 모든 쌍들에 대한 분류기를 구성하여 분류결과를 투표를 통하여 최종 결과를 얻는 방법[2]과 각 단일 레이블에 관련된 사례들과 관련되지 않은 모든 사례들로 학습하고 분류를 위해서 투표를 하는 방법[4, 6]이 있다. 또한, 여러 개의 이진 분류기를 체인으로 연결하고,
다중레이블 분류를 단백질의 세포내 위치 예측에 적용한 연구들을 살펴보면, 레이블들의 상호연관성을 모델링에 직접적으로 반영하는 분류체인 방법[14]과 멱집합 방법[15]이 성능이 높다[5, 8, 9]. 이러한 이유는 특정 생물학적 기능을 수행하는 단백질의 세포내 위치들의 관계는 독립적이지 않고 서로 관련되어 있다는 특징을 효과적으로 분류기에 반영하였기 때문이다. 본 논문에서는 기존의 레이블 멱집합 방법을 더욱 개선하기 위하여 다중레이블간의 중복 정보를 활용하여 각 다중레이블의 예측 정확도를 상호 강화한다. 이를 위하여 하나의 다중레이블을 다른 다중레이블들의 선형조합으로 나타낼 때의 조합가중치를 제약조건이 있는 최적화 방법을 사용하여 구하였다. 분류시에는 여러 다중레이블의 예측 확률을 조합가중치로 선형조합하여 최종적인 다중레이블을 예측하였다.
본 논문에서는 단백질의 다중 세포내 위치에 효과적인 다중레이블 분류 방법 중에 하나인 레이블 멱집합(label power-set) 방법[11-13]을 개선한다. 분류기를 학습하는 자료에 나타나는 모든 레이블들의 집합을
PS 방법을 구체적으로 살펴보면, 먼저 학습 자료에 나타나는 모든 상이한 다중레이블과 각 다중레이블을 가지는 사례의 수를 계산한다. 최종 선택되는 다중레이블의 수를 축소하기 위하여 파라미터
EPS(ensemble of PS)[15]는 PS방법 여러 개를 조합하여 분류기를 구성하는 방법이다. 이러한 앙상블 방법은 개개 분류기가 과도하게 적합(over-fitting)하는 것을 완화시킬 수 있고, 학습 자료에 나타나지 않는 새로운 레이블 부분집합을 예측할 수 있는 장점이 있다. EPS를 구성하기 위해서 학습 자료의 부분 집합 (63%가 사용됨)을 표본 추출하여 학습에 사용하여 PS 분류기를 구성하는 과정을
III. 기초 다중레이블들의 조합을 사용한 다중레이블 분류
본 논문에서는 다중레이블 분류를 위하여 레이블 멱집합 방법을 이용한다. 즉, 분류의 첫 단계에서 학습에 충분한 개수의 자료와 관련된 다중레이블만을 학습과 분류에 사용하여, 각 다중레이블로 분류될 확률을 얻는다. 두 번째 단계에서 이러한 확률들을 조합하여 최종적으로 분류될 다중레이블을 결정한다.
다중레이블의 분류 확률을 조합하기 위하여 먼저 각 다중레이블을 다른 다중레이블들의 선형조합으로 나타내었고, 이러한 선형조합에서 나타나는 조합가중치를 사용하여 확률을 조합하였다. 학습 자료에 나타나는 모든 레이블의 집합을
그림 1에서 기초 다중레이블들에 대한 조합가중치
본 논문에서 다중분류의 첫 번째 단계는 기초 다중레이블과 관련된 자료만 학습에 사용하여 다중분류기를 구성하고, 분류를 수행하여 각 평가 자료가 기초 다중레이블로 분류될 확률
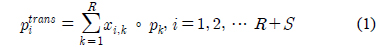
이러한 (
이번 장에서는 단백질의 세포내 위치 예측에 제안한 방법이 효과적인지를 검증한다. 먼저, 실험 자료, 실험방법, 다중레이블 분류의 평가척도에 대해서 설명한 후에, 실험 결과에 대해서 알아본다.
단백질 자료를 분류를 위한 특징벡터로 변환하기 위해서, 실험 자료의 각 단백질 서열과 가장 유사한 단백질을 유전자 온톨로지를 가진 단백질 데이터베이스(http://www.ebi.ac.uk/GOA)에서 찾아, 그것의 유전자 온톨로지로 각 단백질을 나타내었다[1, 2, 4-7, 16]. 유전자 온톨로지는 분자적 기능, 생물학적 과정, 세포 요소의 관점에서 특징화한 용어로 유전자를 표현한 것으로, 각 단백질의 특징을 표현할 수 있다. 본 연구에서는 단백질의 특징을 보다 효과적으로 표현하기 위해서, 단백질의 세포내 위치에 따라 보다 판별력이 높게 나타내는 유전자 온톨로지를 가중하는 방법[16]을 사용하였고, 가장 유사한 두 개의 서열에서 나타나는 유전자 온톨로지의 빈도를 이용하였다[9].
다중레이블 분류의 평가는 단일레이블 분류처럼 예측된 레이블이 실제 레이블과 일치하는 것만을 판단하면 지나치게 엄격한 평가 척도가 되므로, 일부만 일치하는 경우도 고려하는 여러 관점의 평가 척도가 사용된다. 평가 척도는 사례기반(example-based)과 레이블기반(label-based)으로 나눌 수 있다[11-13]. 부록의 식 (S1)~(S6)의 사례기반 방법은 각 사례에 대해 실제 레이블과 예측된 레이블간의 차이를 평균하고, 식 (S7)~(S12)의 레이블기반 방법은 각 레이블에 대해 개별적으로 예측성능을 구하고 이를 평균한다. 본 논문에서는 여러 평가척도를 합한 부록의
본 논문에서 제안한 방법을 CML(Combination of Multi-Labels)이라 하면, CML은 분류의 첫 단계에서 얻은 기초 다중레이블들의 확률을 그림 1의 알고리즘으로 계산한 조합가중치
그림 2는 5번째 실험에서 41번째 비기초 다중레이블을 33개의 기초 다중레이블의 조합으로 나타낸 것의 일부를 보여준다(표시 안된 세로 … 부분은 모두 0임). 와 유사한 의 계수는 0.42로 크고, ,,의 경우에는 −0.06, −0.20, 0.06으로 작으므로 다중레이블의 유사성에 따라 조합가중치가 할당되었음을 알 수 있다. 그러나 보다 이 더욱 과 상이하지만 같은 절대치의 조합가중치를 주는 문제점이 존재한다.
단백질 세포내 위치예측에 다중레이블 분류를 적용한 연구[5, 8, 9]에 따르면, 다중레이블을 구성하는 각 레이블들의 연관성을 반영하는 분류체인 방법[14]과 레이블 멱집합 방법[15]을 앙상블로 사용하는 ECC(Ensembel of Classifier Chain), EPS (Ensemble of Pruned Sets)가 성능이 높았다. 이는 특정 생물학적 기능을 수행하는 단백질은 서로 관련되어 있는 세포내 위치에 존재한다는 특징을 효과적으로 분류기에 반영하였기 때문이다. 따라서, 본 연구에서는 ECC, EPS를 비교실험에 사용하였고, Mulan 라이브러리[18]를 사용하였다. 또한, 이 방법들에서 내부적으로 사용되는 분류기로 트리기반 분류기 대신에 실험을 통해 성능이 더 높은 것으로 확인한 지지벡터기계를 사용하였고, 나머지는 기본 설정을 사용하였다. CML의 분류기는 지지벡터기계 라이브러리[19]를 사용하였는데, 가우시안 커널을 사용하였고, 최적의 파라미터 설정을 위해서 그리드 탐색을 통하여 γ와
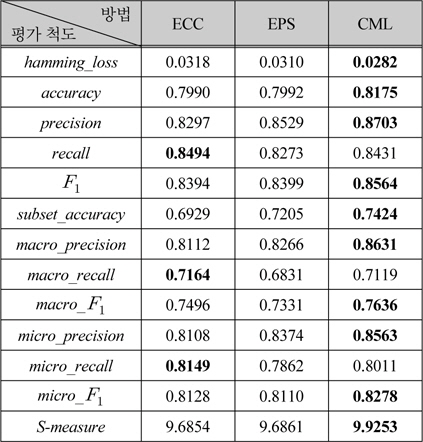
ECC, EPS와 CML의 성능비교
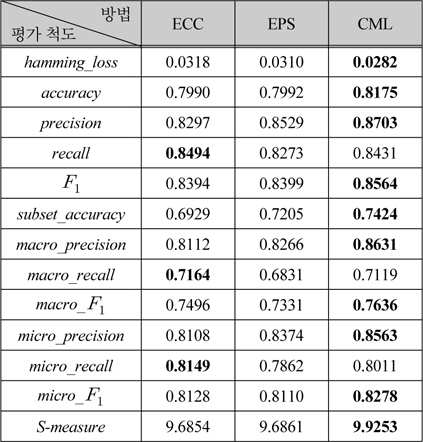
표 1에서 각 방법의 성능은 부록에서 설명한 평가척도를 사용하였다. 표 1에서 보듯이 본 논문에서 제안한 방법인 CML이 대부분의 척도에서 ECC나 EPS보다 높았고, 총괄적인 평가 척도인
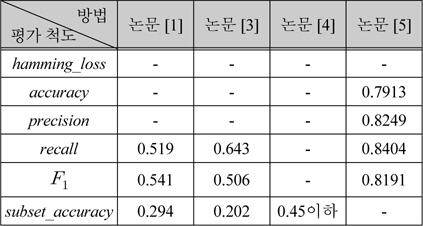
표 2는 동일한 평가척도와 단백질 자료를 사용하는 다른 방법들의 성능이다. 논문[3]의 실험결과에 따르면, 여러 최근접-이웃 분류기를 조합하는 방법인 HummPLOC 2.0[1]과 알고리즘 적응 방법인 논문[3]은 표 1의 방법들보다 성능이 크게 저조하다. 이밖에 논문[4]는 문제 변환 방법의 일종인 BR(Binary Relevance)을 사용하였고, 논문 [5]에서는 ECC를 사용하였는데, 표 1의 실험 결과보다 예측정확도가 떨어짐을 알 수 있다.
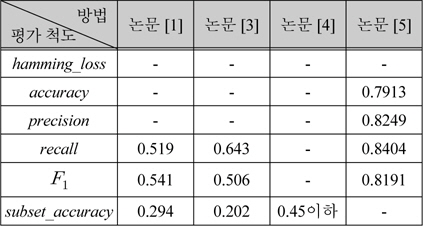
단백질 세포내 위치예측의 성능 비교
표 2의 방법에서 단백질 자료를 특징벡터로 변환하여 유전자 온톨로지를 이용하는 방법이 본 논문과 동일하지 않으므로, 정확한 다중레이블 분류기의 성능 비교는 아니다. 하지만, 표1과 표2의 결과에서 보듯이 제안한 방법인 CML이 다른 방법들에 비하여 전반적으로 효과적임을 알 수 있다.
단백질의 다중 세포내 위치 예측에는 세포내 위치간의 연관관계를 학습 모델에 포함하는 방법이 성능이 높은 것으로 알려져 있다[5, 8, 9]. 즉, 이러한 연관관계를 자료의 속성에 추가하거나, 관련된 레이블 부분 집합자체를 새로운 단일 레이블로 만드는 ECC, EPS 방법이 효과적이었다. 본 논문에서는 EPS 방법처럼 다중레이블 자체를 하나의 단일레이블로 구성하지만, 이러한 새로운 레이블들간에 나타나는 정보의 중복성을 활용하여 분류정확도를 향상시킨다. 기초 다중레이블을 조합하여 여러 다중레이블을 표시하기 위하여 제약 조건을 가진 최적화를 수행하였다. 최적화를 통하여 얻은 조합 가중치를 사용하여 기초 다중레이블의 분류확률을 조합하여 최종적인 분류확률을 계산하였다.
제안한 CML 방법은 같은 레이블 멱집합 방법인 EPS에 비교하면 모든 평가척도에서 향상된 결과를 얻었고, ECC에 대해서는 12개 평가척도 중에서 9개가 높았다. 이러한 결과는 레이블 멱집합 방법처럼 레이블간의 연관성을 나타내면서, 동시에 다중레이블간의 중복된 정보를 분류에 활용하였기 때문이다.
본 논문은 다중레이블간의 정보 중복을 활용하여 다중레이블 분류를 시도하였다. 제안한 방법에 ECC나 EPS처럼 앙상블 방법을 추가적으로 적용하면 여러 다중레이블 분류의 응용분야에 적용될 수 있으리라 판단된다. 그러나, 여러 분야에 응용하기 위해서는 조합가중치의 계산에 보다 정교한 제약조건을 사용하여 다중레이블간의 중복도를 효과적으로 추출할 필요성이 있다. 향후에는 제안한 방법을 개선하여 동물, 식물, 곰팡이, 바이러스 등의 여러 영역의 세포내 위치 예측에 적용할 예정이다.
다중레이블 평가척도는 다음과 같다[11-13]. 사례
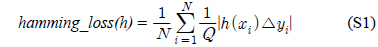
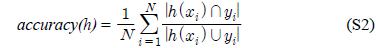
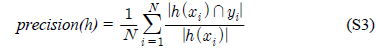
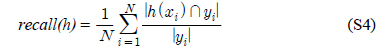
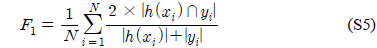
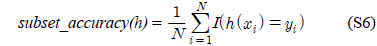
아래 식들에서
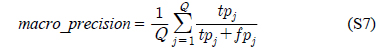
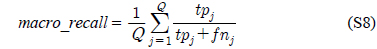
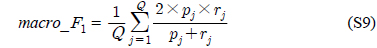
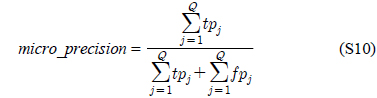
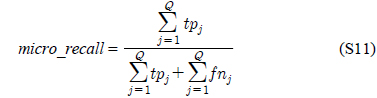
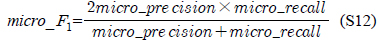
본 연구에서는 많은 평가척도를 요약하기 위하여 평가척도의 합을 사용하였는데,